
Community service-oriented spatiotemporal crowdsourcing task allocation with role awareness
-
摘要: 为了适应社区众包配送中投递箱或代收点收纳量有限等情况,本文提出社区服务型时空众包任务分配问题,根据用户定义的时间将物品较为实时地配送到地。针对该问题,本文通过基于角色的协作模型E-CARGO(environments-classes, agents, roles, groups, objects)形式化问题,针对高资格值工人配送高价值量订单集的目标,提出基于贪婪分配的PQGR(places-qualification-based greedy)算法、基于考虑代理和角色冲突的团队多角色分配方法的PQGM(places-qualification-based GMAC)算法以及进一步缩短运行时间的改进PQGM算法。数据处理和量化方面,提出基于核密度聚类的新型角色感知方法以实现任务的有效划分,提出基于学习遗忘曲线的代理地点资格值多阶段量化模型,实现代理地点资格值的在线学习和自适应更新。最后,本文在gMission数据集和合成数据集上进行实验,验证了算法的有效性和效率。Abstract: This paper proposes the community service-oriented spatiotemporal crowdsourcing task allocation problem to adapt to the limited amount of delivery boxes or collection points in community crowdsourcing. The articles will be relatively delivered to the ground in real time according to the user-defined time. This paper proposes a PQGR algorithm based on greedy allocation, a PQGM algorithm based on the GMRACRA method, and a PQGMA algorithm that further shortens the running time to address the aforementioned problem. This algorithm aims to realize the objective of delivering high-value order sets by workers with high qualification value through the formalization problem of E-CARGO based on the role cooperation model. Considering data processing and quantification, a new role perception method based on kernel density clustering is proposed to realize effective task division. The places-qualification-based multistage quantitative model of an agent is proposed on the basis of learning and forgetting curves to realize online learning and adaptive updating of agent location qualification value. Finally, experiments on gMission and synthetic datasets are conducted to verify the effectiveness and efficiency of the algorithm.
-
近年随着我国大力推进扶贫惠农和社区文明建设,通过网络对产品进行售卖并以社区为基本单位配送成为一种迅速普及的消费方式,较为常见的有美团优选、多多买菜等。这类众包的配送模式有配送到户模式、直营便利店模式、社区店加盟代收点模式和冷链改造的智能快递投递箱模式等。
其中,对于应用普遍的社区店加盟代收点和智能快递投递箱等模式配送时存在一些问题:1)各平台在店租压力大、消费水平高的一线城市,会受到高额的设备维护费用和店铺租赁费用的限制,代收点容量和投递箱数量有限,可能存在物品数量超出投递箱收纳量或消费高峰期店家储存不当的情况;2)虽在代收地点设置冷链技术改造的冷箱或保温箱,代收点可以一定程度上保证新鲜度和安全性,但较发货点仍差异较大;3)所送达的物品包括及时性相对较强的物品。考虑到以上问题,本文提出社区服务型时空众包(community service-oriented spatiotemperal crowdsourcing,CSSC)任务分配问题,实时地安排工人将物品在收货时间的软时间窗内放入代收点。另外,现疫情阶段,封控区的变化以及各种不确定因素对工人的熟悉度以及应变能力要求提高,本文提出以熟悉度为基础的代理地点资格值并纳入分配考虑,任务多时高地点资格值代理可确保本次以及后面任务的顺利完成。
因此,本文所面向的问题是带冲突的同起点不同时不同固定终点的任务分配问题,目标是对于高价值量的订单集派遣高地点资格值的工人配送。针对上述目标,本文基于贪婪分配策略和GMRACRA方法提出CSSC问题任务分配方式,数据处理和量化方面,基于核密度聚类进行角色划分,基于学习遗忘曲线多阶段量化代理的地点资格值。
1. 相关工作
现时空众包任务分配问题的研究中,融入群体智能思想的多工人协作场景具有较好的适应性和效果。朱海滨博士等[1]提出的基于角色的协作(RBC)是处理协作问题的一种有效方法。RBC为适应性协作(adaptive collaboration,AC)[2-4]的一种,使用角色作为底层机制,强调了角色的重要性,并提出了E-CARGO(environments-classes,agents, roles, groups, objects)模型[5],包括环境(Environment)、类(Class)、代理(Agent)、角色(Role)、组(Group)和对象(Object)。该模型囊括了一些基于角色的基本概念,可以基于此完成模型的搭建。
RBC实现任务分配主要基于以下模型及其拓展模型:基于KM算法,应用团队角色分配(group role assignment,GRA)[6-7] 将一个角色分配给多个代理来寻找最优的角色分配计划,使整个团队的绩效最大化;在GRA基础上加入一个代理可能被分配给多个角色的情况,通过线性规划工具包实现团队多角色分配(group multirole assignment,GMRA)[8];引入同角色代理可能冲突的情况[9],以及进一步引入同代理角色冲突的情况,实现考虑冲突的团队多角色分配GMRACRA[10]等。本文基于GMRACRA模型实现带有角色和代理冲突的任务分配。
以上方法可适用于多种工业工程[11-14]以及社会仿真[15-18]问题。与本文相关的社会仿真类研究有Zhu[19]提出通过带限制的GRA和模拟退火实现的代理分类,Huang等[20]针对最后一英里分配问题通过GRA方法进行建模分配,Jiang等[21]针对自服务时空众包问题提出QGRA(quasi group role assignment)并融入工人偏好对问题建模,通过GMRA方法进行分配等。受以上仿真的启发,本文针对CSSC模式任务分配问题通过角色建模,但由于终点是固定的,Huang等[20]的方法和Jiang等[21]中的多次分配不适用于本文的分配问题。且Huang等[20]中所采用的自适应角色方法是通过设置类的数量间接控制角色内的数量,若最后循环取最优值时类较少则类内数量无法保证,在实际生活中没有考虑代理所用配送设备问题。本文针对类的划分考虑了类内的任务数量,且考虑了多人完成一个角色的情况,适应性更强。
另外,现有涉及代理对某地点资格值的研究中,存在直接随机生成熟悉度前三名地点的熟悉度值[20],根据艾宾浩斯遗忘曲线定义[22](其中设定遗忘曲线的遗忘程度为
$\dfrac{{100h}}{{{{z}}(\lg t) + h}}$ )等方式。前者这类方法随机性太强,没有学习、变化的过程,后者根据艾宾浩斯遗忘曲线量化的每次学习程度都达到百分之百且没有累积的过程。本文模型中代理地点资格值量化同学习遗忘有着相似的变化过程,但对各个地点同时存在遗忘和累积的过程,适用性和可持续性强。2. CSSC问题定义
通过E-CARGO模型将CSSC问题形式化,系统
$\displaystyle\sum$ 可以描述为9元组$\displaystyle\sum {:: = }$ <C, O, A, M, R, E, G,$ {s_0} $ , H >,其中C是类集,O是对象集,A是代理集,M是消息集,R是角色集,E是环境集,G是组集,$ {s_0} $ 是系统的初始状态,H是用户集。本文使用m来表示代理集合A的大小,即$ m = \left| A \right| $ ,n表示角色集的大小,即$ n = \left| R \right| $ ,${i_1},\;{i_2},\; \cdots$ 表示代理的索引,${j_1},\;{j_2}, \cdots$ 表示角色的索引。定义1 任务被定义为t ::=<id, tName, time, location, value, place_id>,其中id、tName分别是任务t的序号和名称,后面4个属性分别代表了任务的预计交付时间、位置、价值和该任务所选择的代收点id。任务集用Tasks表示。
定义2 角色被定义为r ::=<id, place_id, value, task_set>,其中id是角色r的序号,即角色j(0
$\leqslant $ j<n),后面3个属性分别代表了角色j的代收点id、该角色的总价值以及所包含的任务集。角色集用R表示。本文角色定义为不同的任务集,这样可以将任务分配中一对多问题转换为一对一问题,各任务集中的任务相互独立且互不包含。本文设计角色感知模块定义任务到角色(任务集)的转换过程,具体内容在第3.1节中呈现。
定义3 代理被定义为a ::=<id,AP_list[i]>。其中id是代理的序号,即代理i(0
$\leqslant $ i<m);AP_list[i]表示代理i访问各代收点时间序列的列表,AP_list[i][p]存储代理i访问代收点p的时间序列。该序列用于多阶段量化代理地点资格值来作为任务分配的参考因素,具体定义及量化策略在第3.2节中呈现。代理集用A表示。定义4 组g中的一个元组<a,r>是指一个角色和代理的分配。
定义5 角色最小范围向量L是一个n维向量,表示一个角色j完成所需的最少代理数量。
$ {\boldsymbol{L}}\left[ j \right] = 1\left( {0 \leqslant j < n} \right) $ 表明角色j所需代理的数量为1,该角色(众包任务集)至少需要一个人完成。定义6 代理能力向量
$ {{\boldsymbol{L}}^{\boldsymbol{a}}} $ 是一个m维向量,表示每个代理所能接受的最大角色数量,本文中$ {{\boldsymbol{L}}^{\boldsymbol{a}}}\left[ i \right] = 1\left( {0 \leqslant i < m} \right) $ 表示一天内最多可以分配给代理i的角色数。例如,给定5个代理,${{\boldsymbol{L}}^{\boldsymbol{a}}}\left[ i \right] = [ 8,12, 9,9,11]$ 。定义7 T是大小为m×n的分配矩阵,
${\boldsymbol{T}}\left[ {i,j} \right] \in \left\{ {\left. {0,1} \right\}} \right.$ ,$ {\boldsymbol{T}}\left[ {i,j} \right] = 1 $ 表示将角色j分配给代理i,$ {\boldsymbol{T}}\left[ {i,j} \right] = 0 $ 则不分配。定义8 代理冲突矩阵
$ {{\boldsymbol{A}}^c} $ 是一个m×m的对称矩阵,$ {{\boldsymbol{A}}^c}\left[ {{i_1},{i_2}} \right] \in \left\{ {\left. {0,1} \right\}} \right.(0 \leqslant {i_1},{i_2} < m) $ ,其中$ {{\boldsymbol{A}}^c}\left[ {{i_1},{i_2}} \right] = 1 $ 表示代理i1和i2冲突,当值为0时表示不冲突。$ {{\boldsymbol{A}}^c}\left[ {i,i} \right] = 0\left( {0 \leqslant i < m} \right) $ 定义为一个代理与自身没有冲突。本文代理冲突考虑的是在一个多对一的分配问题中避免有合作的两个代理有较强的敌对情绪从而影响合作完成任务的情况。实验部分以5%的概率随机设置冲突情况。
定义9 角色冲突矩阵
$ {{\boldsymbol{R}}^{\boldsymbol{c}}} $ 是一个n×n的对称矩阵,$ {{\boldsymbol{R}}^{\boldsymbol{c}}}\left[ {{j_1},{j_2}} \right] \in \left\{ {\left. {0,1} \right\}} \right.\left( {0 \leqslant {j_1},{j_2} < n} \right) $ ,其中$ {{\boldsymbol{R}}^{\boldsymbol{c}}}\left[ {{j_1},{j_2}} \right] = 1 $ 表示角色$ {j_1} $ 与角色$ {j_2} $ 冲突,当值为0时表示不冲突。$ {{\boldsymbol{R}}^{\boldsymbol{c}}}\left[ {j,j} \right] = 0\left( {0 \leqslant j < n} \right) $ 表示一个角色与自身没有冲突。本文角色冲突考虑的是不同角色送货时间的冲突,考虑到一定半径内的移动距离与备货时间,当一个角色的送货时间与另一个角色的送货时间相差30 min以上则定义为不冲突,小于30 min则为角色冲突。
定义10 资格矩阵Q是一个m×n的矩阵,其中
$ {\boldsymbol{Q}}\left[ {i,j} \right] \in \left[ {0,1} \right] $ 表示代理$i( 0 \leqslant i < m )$ 对于角色$j( 0 \leqslant j < n )$ 的资格值。本文中,定义资格值受代理对该角色所在代收点资格值和该角色的总价值影响。本着在线学习、可持续的原则,第3.2节中定义代理地点资格值多阶段量化方法求得地点资格值
$ {F_{ik}} $ ,下标ik是代理i对第k个地点的表示。资格值矩阵计算公式如式(1)所示,其中$ {V_j} $ 为角色j的总价值。$$ {\boldsymbol{Q}}[i,j]{\text{ = }}{F_{ik}}\cdot{V_j}(0 \leqslant i < m,0 \leqslant j < n) $$ (1) 定义11 组效益
$ \sigma ' $ 定义为已分配代理的资格之和,如式(2)所示,$ \sigma ' $ 的意义是众包工作者在整个调度过程中使得高地点资格值的代理完成高价值任务的最大组效益。$$ \sigma ' = \sum\limits_{i = 0}^{m - 1} {} \sum\limits_{j = 0}^{n - 1} {{\boldsymbol{Q}}\left[ {i,j} \right]} \times {\boldsymbol{T}}\left[ {i,j} \right] $$ (2) 可行性定义 如果一个角色
$ j\left( {0 \leqslant j < n} \right) $ 被分配足够的代理,即$\displaystyle\sum_{i = 0}^{m - 1} {{\boldsymbol{T}}\left[ {i,j} \right]} \geqslant {\boldsymbol{L}}\left[ j \right]$ ,则该角色j是可行的。如果每个角色j都可行,即$\displaystyle\sum_{i = 0}^{m - 1} {{\boldsymbol{T}}\left[ {i,j} \right]} \geqslant {\boldsymbol{L}}\left[ j \right]\left( {0 \leqslant j < n} \right)$ 都成立,则该分配矩阵T是可行的,如果T可行那么该组g也是可行的。3. 数据处理方法与算法
3.1 角色感知算法
为实现从一对多分配到一对一分配的转换,简化分配过程,采用角色感知算法(role perception algorithm,RPA)将任务划分为不同的角色(任务集)。本文根据用户自己选择的代收点将任务划分,若没有选择则就近分配。然后在不同的代收点处根据时间对任务进一步划分,划分为不同的角色。为自动确定集群数量,本文应用核密度聚类定义具有类内数量限制的角色感知方法。
核密度聚类中核密度估计(kernel density estimation,KDE)可以无需假设密度分布或特征参数来估计数据集的可能分布。本文应用的核函数为高斯函数(即正态分布),核密度估计的公式如式(3),其中h为带宽。在概率密度估计曲线的基础上以极值为分界点划分区间,从而得到各个时间段,将各时间段内的任务划分为一个角色,完成角色的分配。
$$ \hat p\left( x \right) = \frac{1}{n}\sum\limits_{i = 1}^n {{K_h}} (x - {x_i}) = \frac{1}{{nh}}\sum\limits_{i = 1}^n {K\left( {\frac{{x - {x_i}}}{h}} \right)} $$ (3) 如算法1所示,输入为当天的众包任务集Tasks、核密度聚类带宽h和地点集P,输出为角色集R。
$ {T_p} $ 是以地点p为代收点的任务集,minNum、maxNum分别指当任务集过大需要分割时一个角色类中最大任务数和最小任务数(本文中设置最小、最大任务数为3和8)。KernelDensityClustering (Tp, h)是对任务集$ {T_p} $ 进行核密度聚类的函数。第1~3行将任务加入代收点任务集,第4~23行分别将各代收点的任务划分为角色集。第5行利用核密度聚类算法对该代收点的任务进行划分,第6行对划分结果进行进一步处理。第7~9行将任务数目小于最大限制的任务集打包为一个角色。否则,根据第10~22行将其进一步以(minNum, maxNum)内的随机数Temp为大小分块,直至最后一块数量小于maxNum。算法1 角色感知算法
输入 Tasks, h, P
输出 R
1) For t in Tasks:
2) 将t加入所选择代收点的任务集Tp
3) End for
4) For p in P:
5) Result=KernelDensityClustering (Tp, h)
6) For r in Result:
7) If r中包含的任务数小于maxNum:
8) 将r中的任务集打包为角色放入R
9) End if
10) Else:
11) Flag=0
12) While(Flag<r中包含的任务数):
13) Temp←取[minNum, maxNum]内的随机数
14) If Flag+ Temp<=(r中包含的任务数):
15) 将r[Flag,
Flag + Temp)打包为角色放入R 16) Flag←Flag +
Temp 17) End if
18) Else:
19) 将r[Flag, len (r))打包为角色放入
$ R $ 20) Flag←Flag+Temp
21) End while
22) End for
23) End for
24) Return R
3.2 代理地点资格值的多阶段量化模型
为了根据代理对代收点的出勤时间和次数定义地点资格值,本文受推荐系统中兴趣度量化的启发[23],根据学习遗忘曲线提出代理地点资格值的多阶段量化模型(places-qualification-based multistage quantitative model,PQMQM)。模型中,若近期频繁派送某代收点订单,则资格值较大。
在PQMQM中,每次到达代收点就是一次提升以熟悉度为基础的地点资格值的过程,多次到达同一代收点就是重复学习的过程。图1为代理3次重复学习时的地点资格值变化过程。
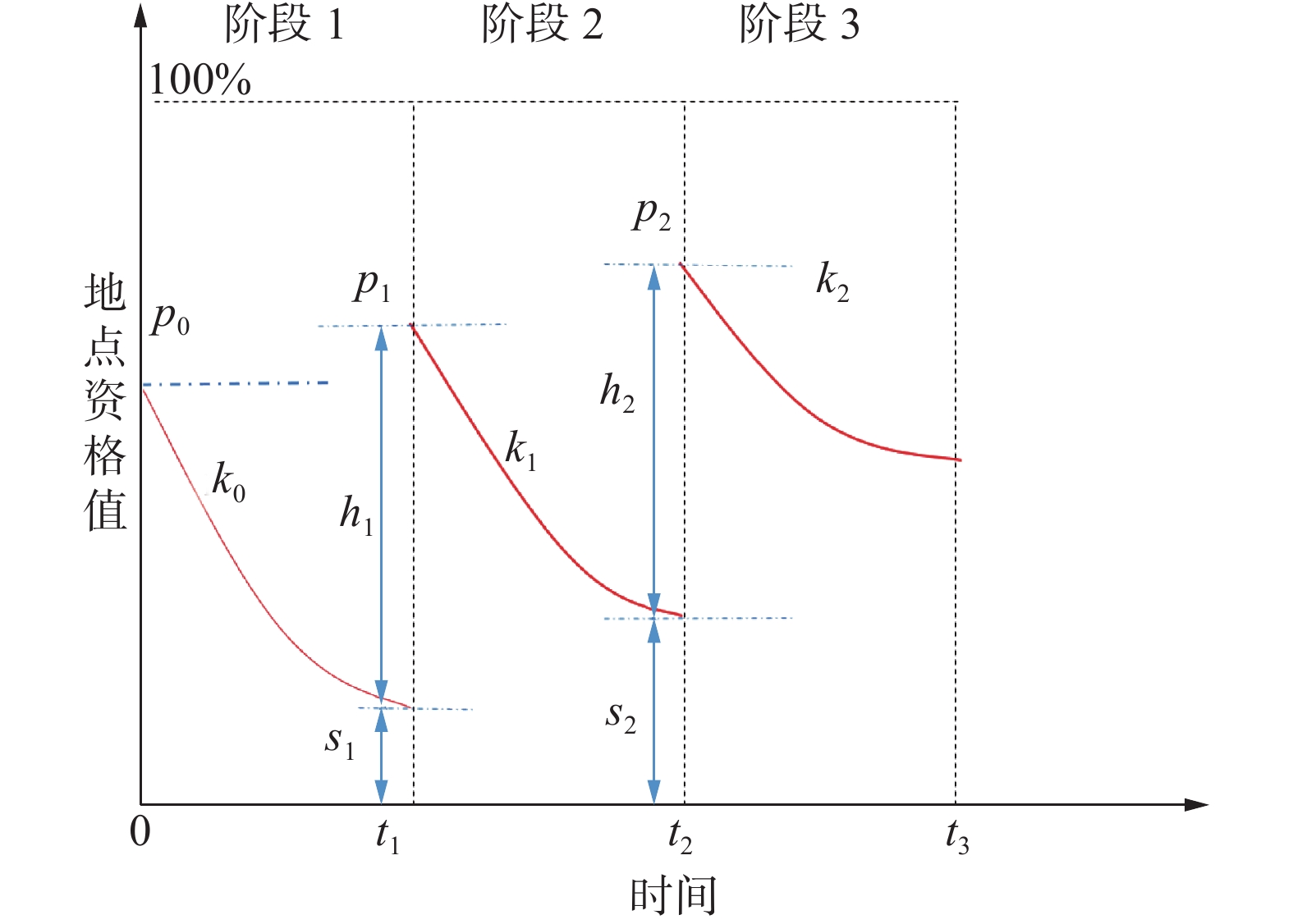 图 1 代理地点资格值变化过程Fig. 1 Agent place qualification value change process
图 1 代理地点资格值变化过程Fig. 1 Agent place qualification value change process 下载:
全尺寸图片
下载:
全尺寸图片
由图1可以看出每次学习后都是一个地点资格值降低的过程,但每次学习与遗忘时资格值的增加量和遗忘速率都是不同的。如图1,
$ {p_n} $ 是阶段初始值,$ {k_n} $ 为遗忘速率,$ {h_n} $ 是新一轮重复学习后资格值的增加量,$ {s_n} $ 为上一阶段经历遗忘后剩余的资格值。可以看出$ {p_n} = {h_n} + {s_n} $ ,$ {k_0} > {k_1} > {k_2} $ ,$ {h_1} > {h_2} $ ,随着代理一段时间内重复去往某个地点,每次新了解的内容(新增的资格值)逐渐减少,h的值逐渐减小。具体的计算公式如下:$$ {s_n} = {p_{n - 1}}{{\rm{e}}^{ - {k_{n - 1}}({t_n} - {t_{n - 1}})}} $$ (4) $$ {h_n} = {p_0}{{\rm{e}}^{ - \tfrac{n}{{{d_1}}}}} $$ (5) $$ {p_n} = {p_{n - 1}}{{\rm{e}}^{ - {k_{n - 1}}({t_n} - {t_{n - 1}})}} + {p_0}{{\rm{e}}^{ - \tfrac{n}{{{d_1}}}}} $$ (6) $$ {k_n} = \frac{{\ln (1 + (\theta - 1){{\rm{e}}^{^{ - {k_{n - 1}}({t_n} - {t_{n - 1}})}}}) - \ln \theta }}{{ - ({t_n} - {t_{n - 1}})}} $$ (7) $$ {\theta _n} = {({t_n} - {t_{n - 1}})^{{d_2}}}\cdot{\theta _0} $$ (8) $$ {d_2} = \left\{ {\begin{split} &{1 + 0.3\cdot({t_n} - {t_{n - 1}} - 1),\quad{t_n} - {t_{n - 1}} \leqslant 2} \\ & {0.5\cdot({t_n} - {t_{n - 1}}) ,\quad {t_n} - {t_{n - 1}} > 2} \end{split}} \right. $$ (9) 式中:
$ {d_1} $ 取值为4.5;$ {t_{n - 1}} $ 和$ {t_n} $ 为重复学习的任意相邻时刻;$ {k_{n - 1}} $ 为遗忘曲线从$ {t_{n - 1}} $ 到$ {t_n} $ 的遗忘速率。$ \theta $ 为惰性因子,根据时间差$ {t_n} - {\text{ }}{t_{n - 1}} $ 来调整$ {k_n} $ ,当两个时间差相差越大,则该代理当前阶段的$ \theta $ 值越大。式(4)通过指数函数定义前一阶段经历遗忘后的剩余资格值,式(5)定义当前阶段资格值的增加量,式(6)表示当前时刻经历过学习遗忘过程后的总资格值,式(7)调整式(6)中的遗忘速率,式(8)和(9)调整式(7)中的惰性因子。本文以天为单位,设定最大时间阈值
${T_{\rm max}}$ 表示参照历史信息的时间跨度。实验中${T_{\rm max}} = 15$ 对于每个工人根据近15天的历史数据中对5个代收点的访问情况进行计算。具体代理地点资格值的多阶段量化模型伪代码如下。算法2 PQMQM算法
输入 P,A,AP_list[][]
输出 F
1) For a in [0, 1, 2, …, len(A)]:
2) For p in [0, 1, 2, …, len(P)]:
3) 初始化k0、p0、θ0
4) M←AP_list[a][p]中时间点的数量
5) t0←AP_list[a][p]中第1个时间点的值
6) For i in [1, 2, …, M−1]:
7) ti←AP_list[a][p]中第i+1个时间点的值
8) 计算d2的值
9)
${\theta _i} = {({t_i} - {t_{i - 1}})^{{d_2}}}\cdot{\theta _0}$ 10)
${p_i} = {p_{i - 1}}{{\rm{e}}^{ - {k_{i - 1}}({t_i} - {t_{i - 1}})}} + {p_0}{{\rm{e}}^{ - \tfrac{i}{{{d_1}}}}}$ 11)
${k_i} = \dfrac{{\ln (1 + (\theta - 1){{\rm{e}}^{^{ - {k_{i - 1}}({t_i} - {t_{i - 1}})}}}) - \ln \theta }}{{ - ({t_i} - {t_{i - 1}})}}$ 12) End for
13) F[a][p]←计算当前时刻的地点资格值
14) End for
15) End for
16) Return F
算法2输入为地点集P、代理工人集A和存放每个工人对每个地点访问时间列表的AP_list[][],输出为当前时间每个工人对每个地点的地点资格矩阵F,AP_list[a][p]表示第a个工人对第p个代收点的访问时间列表。伪代码中第1~3行针对每个工人和每个地点进行遍历并初始化,第4行获取第a个代理对第p个地点的访问时间列表中时间点的数量M,第5行获取访问时间列表中的第一个时间点的值
$ {t_0} $ 。第6~7行获取时间列表中除$ {t_0} $ 外的每一个时间值,第8~11行迭代更新$ \theta $ 、$ {p_i} $ 、$ {k_i} $ ,计算每个阶段的地点资格值,第13行根据最后一个阶段的资格值计算当前时刻的资格值并赋值给资格矩阵,最终完成循环输出代理地点的资格矩阵F。该方法在实际考勤中有激励作用,一方面对于持续工作的工人存在缺勤也可以维持较高的资格值,另一方面对于没有持续工作的工人若在一段时间内持续工作其地点资格值会较快速增长。地点资格值以熟悉度为基础但不同于熟悉度,多次到达后资格值不一定呈现上升趋势。例如,当设置
$ {k_0} = 1.1 $ ,$ {p_0} = 0.5 $ ,$ {\theta _0} = 3.5 $ ,访问时间列表为[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]、[0, 5, 7, 9, 11, 12, 13, 14]和[0, 2, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]时,代理地点资格值变化如图2所示。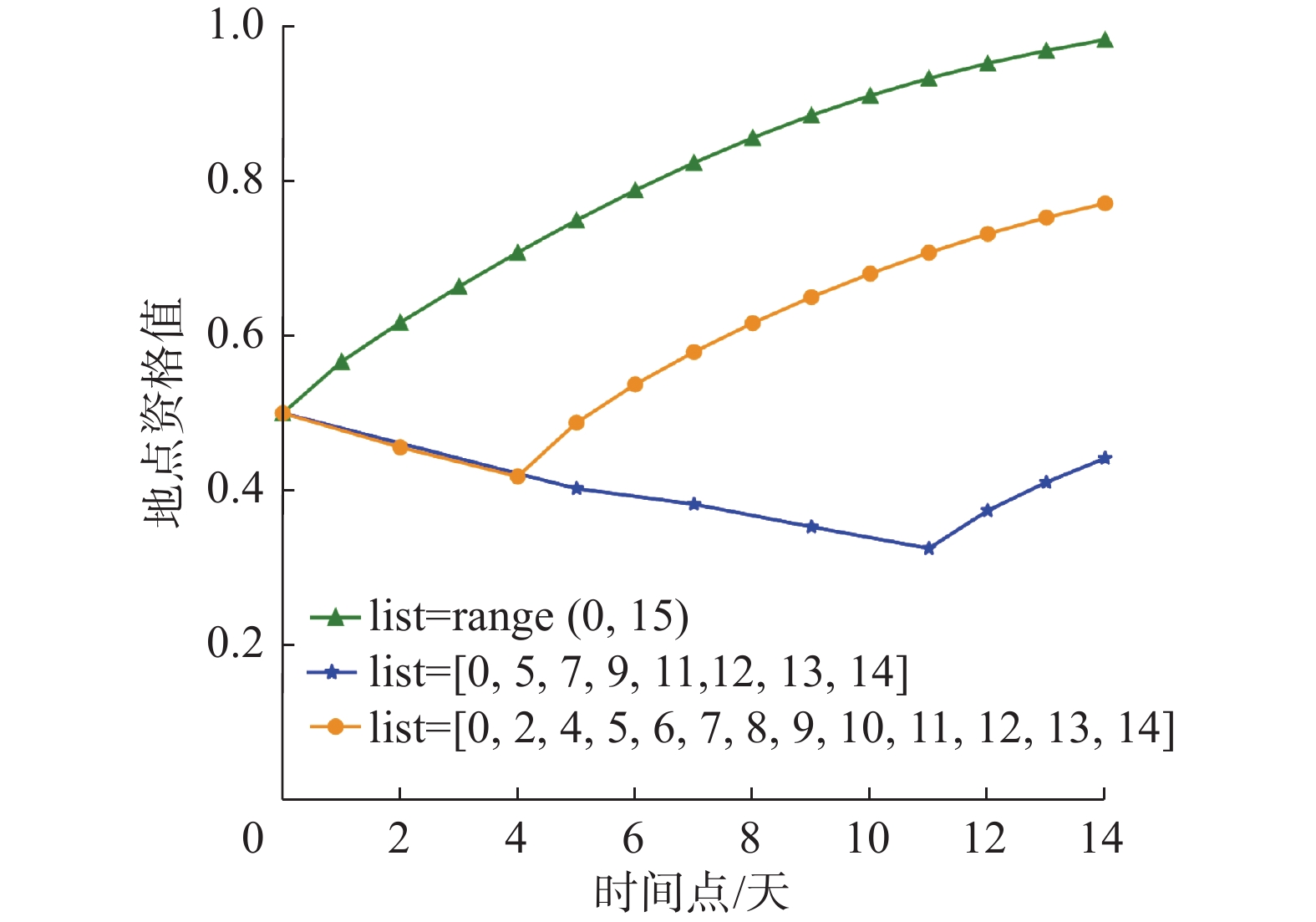 图 2 代理资格值变化情况Fig. 2 Changes in the agent’s qualification value下载:
全尺寸图片
图 2 代理资格值变化情况Fig. 2 Changes in the agent’s qualification value下载:
全尺寸图片
4. 问题解决方法与算法
4.1 基于贪婪的解决方法
对于CSSC模式的任务分配问题,针对地点资格值和价值这两个优化目标,本文提出了基于地点资格值的贪婪分配方法(places-qualification-based greedy algorithm,PQGR)。
该方法首先根据角色价值由高到低进行排序,然后优先为价值高的角色根据所需代理数量匹配资格值高的代理,匹配时需判断其是否存在代理和角色冲突。其具体的伪代码如算法3所示。
算法3中,输入为任务集Tasks、地点集P、代理集A、时间序列AP_list[][]、带宽h的最小取值minh和最大取值maxh,输出为分配矩阵T_max。具体实现中,第1行根据不同的h(具体取值范围在第5.2节中呈现)进行遍历,第2~5行计算并初始化角色集R、地点资格值矩阵F、m、n和分配矩阵T,第6~17行对角色集R中的每个角色r分配代理。第7行定义循环的次数为该角色所需代理的数量。第8~10行遍历代理集中的所有代理,找出满足以下4个条件的代理中地点资格值最大的代理:代理没有分配给该角色(所需代理数大于1时判断),代理和已分配的任务、已分配的代理没有冲突,代理所担任的角色数未达到最大值。第11~14行判断是否无法分配角色,若存在可以分配的代理则如15行进行分配并更新分配矩阵T。最后完成所有循环后返回组效益最大的T_max
。 算法3 PQGR算法
输入 Tasks,P,A,AP_list[][],minh,maxh
输出 T_max
1) F ←根据
PQMQM (A, P, AP_list)算法求得资格矩阵 2) For h in [minh, maxh]:
3) R←根据RPA(Tasks, h, P)算法求得划分的角色集
4) m←A中的代理数,n←R中的角色数
5) T←初始化值全为0的分配矩阵
6) For r in R:
7) For i in [0, 1, 2, …, L[r]):
8) Fora in A:
9) 找到一个符合条件的地点资格值最大的代理
10) End
for 11) If 没有符合条件的代理:
12) 恢复该角色已更改分配矩阵
${\boldsymbol{T}}$ 的项13) Break
14) End if
15) 将角色分配给代理并更新分配矩阵
${\boldsymbol{T}}$ 16) End for
17) End for
18) End for
19) T_max
←具有最大组效益的T 20) Return T_max
4.2 基于GMRACRA的解决方法
为使得高地点资格值的代理去完成高价值的角色,本文提出了基于地点资格值的GMRACRA分配方法(places-qualification-based GMRACRA algorithm,PQGM)。
定义12 根据定义1~11,给定
${\boldsymbol{Q}}、{\boldsymbol{L}}、{{\boldsymbol{L}}^{\boldsymbol{a}}}、 {{\boldsymbol{R}}^{\boldsymbol{c}}}、 {{\boldsymbol{A}}^{\boldsymbol{c}}}$ 和T,PQGM算法是通过GMRACRA方法找到一个可行的T来实现最大组效益。问题定义如下:$$ \max \sigma ' = \sum\limits_{i = 0}^{m - 1} {} \sum\limits_{j = 0}^{n - 1} {{\boldsymbol{Q}}\left[ {i,j} \right]} \times {\boldsymbol{T}}\left[ {i,j} \right] $$ (10) $$ {\boldsymbol{T}}\left[ {i,j} \right] \in \left\{ {\left. {0,1} \right\}} \right.\left( {0 \leqslant i < m} \right)\left( {0 \leqslant j < n} \right) $$ (11) $$ \sum\limits_{i = 0}^{m - 1} {{\boldsymbol{T}}\left[ {i,j} \right]} = {\boldsymbol{L}}\left[ j \right]\left( {0 \leqslant j < n} \right) $$ (12) $$ \sum\limits_{j = 0}^{n - 1} {{\boldsymbol{T}}\left[ {i,j} \right]} = {{\boldsymbol{L}}^a}\left[ j \right]\left( {0 \leqslant i < m} \right) $$ (13) $$ \begin{gathered} {{\boldsymbol{A}}^{\boldsymbol{c}}}\left[ {{i_1},{i_2}} \right] \times ({\boldsymbol{T}}\left[ {{i_1},j} \right] + {\boldsymbol{T}}\left[ {{i_2},j} \right]) \leqslant 1 \\ (0 \leqslant {i_1} \ne {i_2} < m,0 \leqslant j < n) \\ \end{gathered} $$ (14) $$ \begin{gathered} {{\boldsymbol{R}}^{\boldsymbol{c}}}\left[ {{j_1},{j_2}} \right] \times ({\boldsymbol{T}}\left[ {i,{j_1}} \right] + {\boldsymbol{T}}\left[ {i,{j_2}} \right]) \leqslant 1 \\ (0 \leqslant i < m,0 \leqslant {j_1} \ne {j_2} < n) \\ \end{gathered} $$ (15) 其中,式(10)是问题的目标——最大化组效益,式(11)是分配矩阵
$ {\boldsymbol{T}} $ 取值的0–1约束,式(12)表示按照角色所需的代理数量分配代理,式(13)表示分配给代理的角色数不超过该代理的能力范围,式(14)保证共同承担一个角色的两个或多个代理之间不会有冲突,式(15)保证一个代理所承担的角色之间不会发生冲突。通过问题建模,CSSC问题变成了一个0–1线性规划问题,可以通过IBM ILOG CPLEX工具包(CPLEX)[24]完成分配。必要条件定义 在GMRACRA方法下CSSC问题有可行解的必要条件为各角色所需的代理之和要小于各代理的代理能力值之和,如式(16)所示。在不考虑约束条件式(14)和式(15)的情况下满足这个条件才可以得到一个可行解。
$$ \sum_{j = 0}^{n - 1} {{\boldsymbol{L}}\left[ j \right] \leqslant \sum_{i = 0}^{m - 1} {{{\boldsymbol{L}}^{\boldsymbol{a}}}\left[ i \right]} } $$ (16) 算法4 PQGM算法
输入 Tasks,P,A,AP_list[][],minh,maxh
输出 T_max
1) F←根据PQMQM (A, P, AP_list)算法求得资格矩阵
2) For h in [minh, maxh]:
3) R←根据RPA(Tasks, h, P)算法求得划分的角色集
4) m←A中的代理数,n←R中的角色数
5) T← 初始化值全为0的分配矩阵
6) Q= GenerateQualificationMatrix(F, R)
7) RC= GenerateRoleConflictMatrix(R)
8) AC= GenerateAgentConflictMatrix(A)
9) L= GenerateRoleRangeVector(R)
10) LA= GenerateAbilityLimitVector(A)
11) T= doAssignment(m, n, Q, AC, RC, L, LA)
12) End for
13) T_max←T which has best performance
14) Return T_max
伪代码如算法4所示。输入输出与算法3中相同。其中第1行根据h取值范围进行遍历,第2~5行求得角色集R、地点资格值矩阵F、m、n 和分配矩阵T。第6行GenerateQualificationMatrix (F, R)通过地点资格值矩阵F和角色集R生成大小为m×n的资格矩阵Q的函数。同理,第7~10行生成角色冲突矩阵RC、代理冲突矩阵AC、角色范围向量L和代理能力范围向量LA,其中L和LA的值符合式(16)的约束条件。第11行调用分配函数doAssignment (m, n, Q, AC, RC, L, LA)进行分配,得到分配矩阵T。最后循环后返回最优组效益的分配矩阵T_max。流程图如图3所示。
 图 3 PQGM算法流程图Fig. 3 Flow chart of PQGM algorithm下载:
全尺寸图片
图 3 PQGM算法流程图Fig. 3 Flow chart of PQGM algorithm下载:
全尺寸图片
如表1所示存在15个订单t1~t15,订单位置和所需的送达时间如表,假定用户所选择的代收点为距离最近的代收点。订单横纵坐标范围为[0,100],时间以分钟定义,范围是[0,480],如表2所示设置5个代收点P1~P5,安排5个代理a1~a5进行分配。
表 1 订单的时间与位置分布Table 1 Time and location distributions of orders任务 时间/min 位置 价值/元 t1 0 (32,70) 41 t2 4 (21,22) 22 t3 7 (82,13) 10 t4 8 (55,85) 33 t5 8 (57,93) 65 t6 9 (65,75) 48 t7 10 (43,65) 11 t8 12 (27,45) 35 t9 15 (83,4) 19 t10 20 (99,21) 55 t11 23 (94,41) 30 t12 30 (34,59) 6 t13 32 (30,8) 23 t14 32 (28,1) 41 t15 35 (44,14) 32 表 2 收货地点的位置分布Table 2 Location distributions of receiving placesP1 P2 P3 P4 P5 (17,72) (47,82) (81,87) (34,40) (75,17) 首先,对于每个代收点根据时间将任务划分形成如图4所示的角色(任务集),角色分别为
${r_1} $ ~${r_5} $ 。其中${r_1}$ 包含任务${t_1}$ ;${r_2}$ 包含任务${t_2}$ 、${t_8}$ ;${r_3}$ 包含任务$ {t}_{3}、{t}_{9}、{t}_{10}、{t}_{11} $ ;${r_4}$ 包含任务$ {t}_{4}、{t}_{5}、{t}_{6}、{t}_{7} $ ;${r_5}$ 包含任务$ {t}_{12}、{t}_{13}、{t}_{14}、{t}_{15} $ 。然后根据随机生成的15天内代理对地点的访问时间序列生成如表3所示的地点资格值矩阵,进一步计算可得如表4所示的资格值Q矩阵。设置角色最小范围向量${\boldsymbol{L}} = \left( {1,1,1,1,2} \right)$ ,${{\boldsymbol{L}}^{{a}}} = \left( {8,5,6,6,5} \right)$ ,设置代理${a_1}$ 和${a_2}$ 冲突。调用本文提出的PQGM算法可得如表5所示的分配矩阵。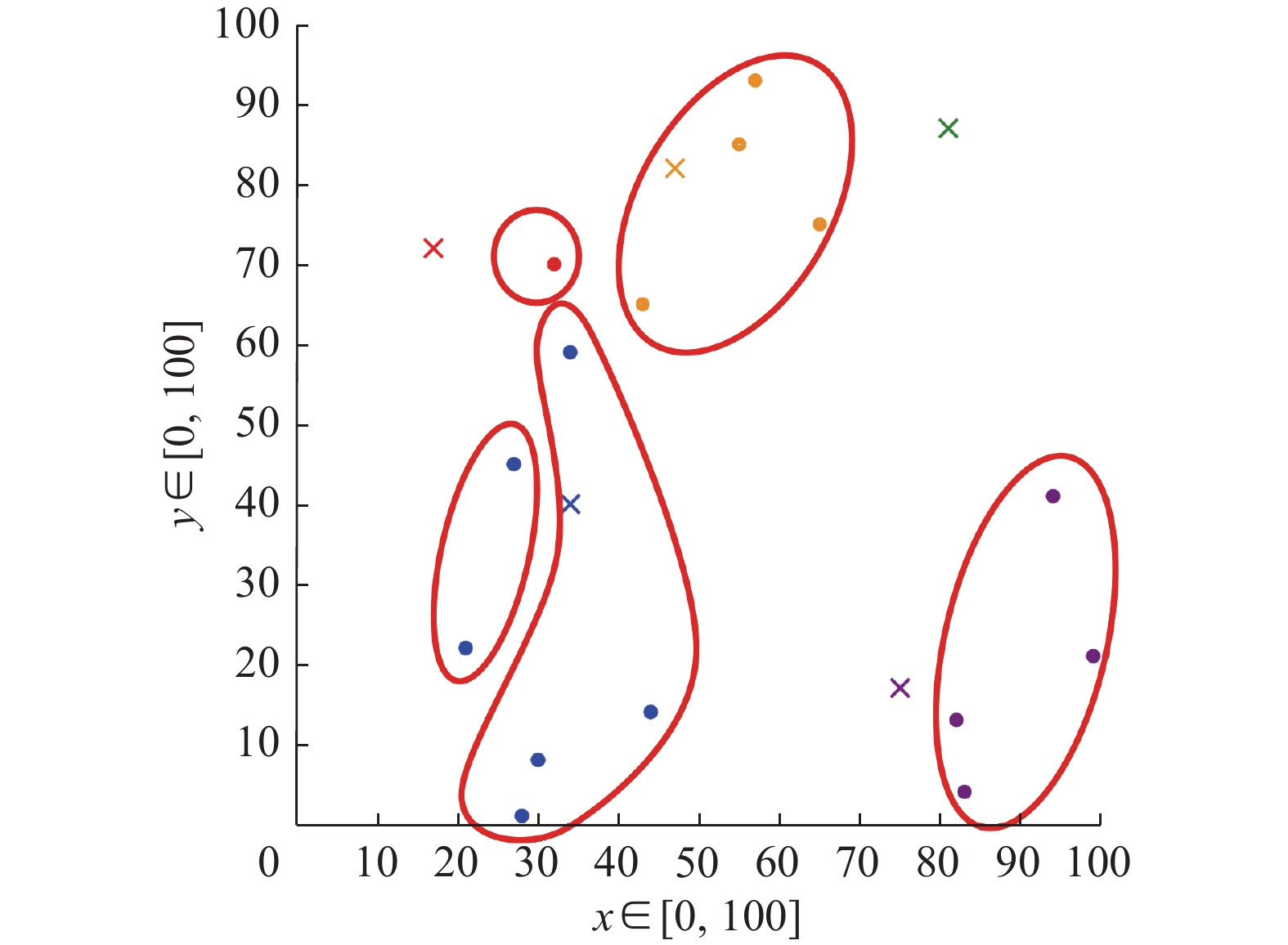 图 4 订单的位置分布和角色划分Fig. 4 Location distribution and role division of orders下载:
全尺寸图片
表 3 代理的地点资格值矩阵Table 3 The agent's place qualification value matrix
图 4 订单的位置分布和角色划分Fig. 4 Location distribution and role division of orders下载:
全尺寸图片
表 3 代理的地点资格值矩阵Table 3 The agent's place qualification value matrix代理/地点 P1 P2 P3 P4 P5 a1 0.66 0.12 0.65 0.98 0.21 a2 0.97 0.46 0.33 0.44 0.50 a3 0.32 0.63 0.91 0.51 0.49 a4 0.43 0.31 0.72 0.96 0.21 a5 0.17 0.55 0.56 0.59 0.79 表 4 资格值Q矩阵Table 4 Q matrix of qualification values代理/角色 r1 r2 r3 r4 r5 a1 27.06 55.86 23.94 18.84 99.96 a2 39.77 25.08 57.00 72.22 44.88 a3 13.12 29.07 55.86 98.91 52.02 a4 17.63 54.72 23.94 48.67 97.92 a5 6.97 33.63 90.06 86.35 60.18 表 5 PQGM算法分配矩阵TTable 5 Assignment matrix T of PQGM代理/角色 r1 r2 r3 r4 r5 a1 1 0 0 0 1 a2 0 1 0 0 0 a3 0 0 0 1 0 a4 0 0 0 0 1 a5 0 0 1 0 0 5. 实验与评估
5.1 实验设置
实 验 环 境 : 处 理 器 为Intel(R) Core(TM) i5-7200U CPU @ 2.50 GHz 2.70 GHz,内存容量为8 GB,Windows 10 操作系统,JDK为 Java 8。
本文实验采用的数据集为gMission数据集和遵循正态分布的合成数据集。gMission[25]是一个基于研究的通用空间众包平台,时间范围为[0, 480]。由于原数据量较大,所以所用的数据集都是从原数据集中等间隔取得。如图5、图6所示,以工人和任务的半径为1000 m的数据集为例得出该数据集任务数量随时间变化趋势,以及以半径为1000 m的数据集等间隔数取1000个任务统计t∈[120, 150),t∈[240, 270),t∈[360, 390) 3个时间段任务的地点位置分布。由图可见时间分布和位置分布较为均匀,因此随机生成5个地点
${P_1} $ ~${P_5} $ 作为货物代收点。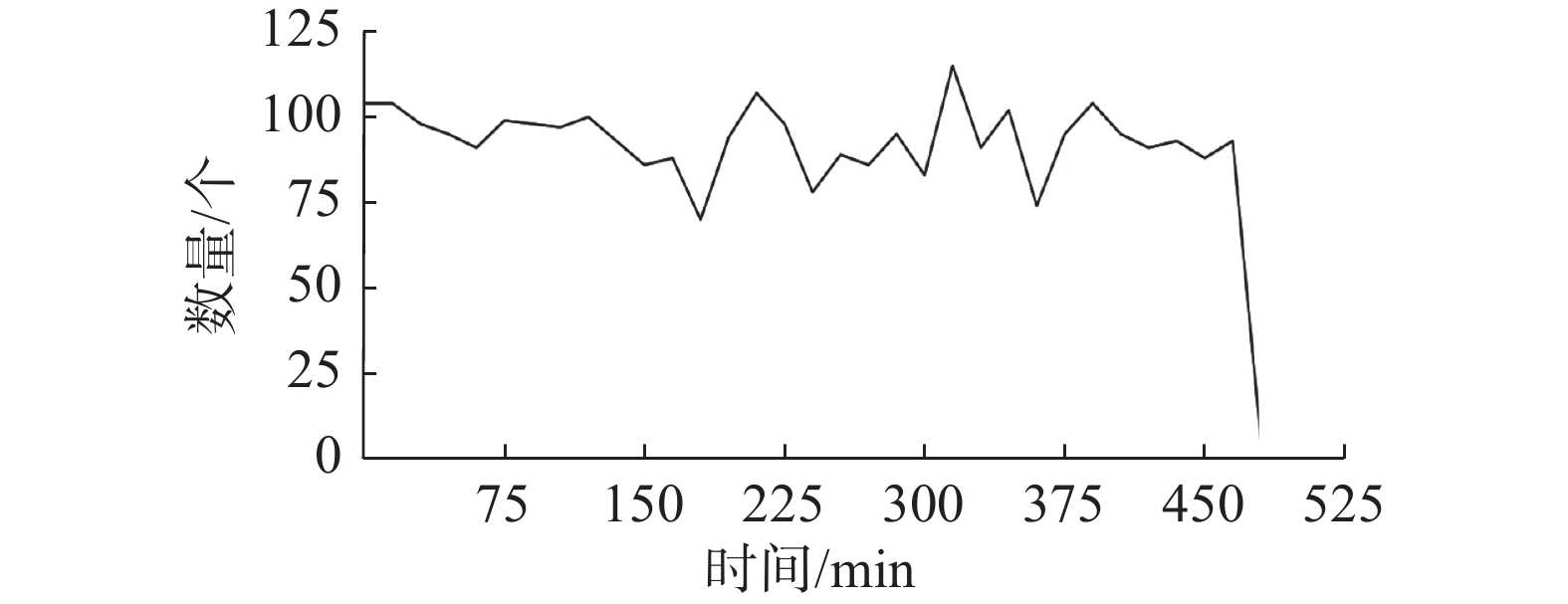 图 5 gMisson数据集中任务数量随时间变化趋势Fig. 5 Trend of the number of tasks in gMisson dataset over time下载:
全尺寸图片
图 5 gMisson数据集中任务数量随时间变化趋势Fig. 5 Trend of the number of tasks in gMisson dataset over time下载:
全尺寸图片
 图 6 gMission数据集中不同时间段任务地点分布Fig. 6 Tasks location distribution in different time periods in the gMission dataset下载:
全尺寸图片
图 6 gMission数据集中不同时间段任务地点分布Fig. 6 Tasks location distribution in different time periods in the gMission dataset下载:
全尺寸图片
实验变量设置如表6所示。另外,以5%的冲突概率生成代理间的冲突矩阵,以90%的概率设置角色所需的代理数为1,以10%的概率设置角色所需的代理数为2或3,假定任务选定的代收点为位置距离最近的代收点。
表 6 数据集变量设置Table 6 Datasets variable settings对于合成数据集,基于gMission真实数据集的观测,实验中生成任务的位置和时间均匀分布,位置产生在100×100的范围内,时间产生在[0, 480]的范围内。由于μ往往对性能有更大的影响,任务价值遵循μ=[15, 25, 45, 64, 85],σ =3.75的正态分布,其他变量的设置与gMission数据集中相同。由于
$ {k}_{0}、 {p}_{0}、{\theta }_{0} $ 的不同设置对该模型有着较大的影响,${k_0}$ 越大资格值函数下降速度越快,${p_0}$ 越大函数初始点越高。对于${\theta _0}$ ,由于时间差${t_n} - {t_{n - 1}}$ 越大,${k_n}$ 和$\theta $ 越大,$\theta $ 越大反而使得${k_n}$ 越小,因此${\theta _0}$ 决定了初始阶段工作强度对整个资格值的影响。基于本文分配问题的场景和激励的要求,经多次调试设置${k_0} = 1.1$ ,${p_0} = 0.5$ ,${\theta _0} = 3.5$ 。5.2 参数对算法的影响
核密度聚类算法中带宽h用作平滑参数,用来平衡结果中的偏差和方差。较大的带宽会使得概率密度曲线非常平滑,较小的带宽会使得曲线非常尖锐。
由于带宽设置不同时对聚类影响较大,现设置带宽取值[1,20],间隔为1。对于带宽范围的限制包括以下3个方面:一是角色数量不可多到任务无解;二是控制同一角色内时差不超60 min;三是随着带宽增加,角色数量无下降趋势。对角色划分后当任务数为100~500时应用PQGM算法分配后的组效益(组最优资格总值)如图7所示。
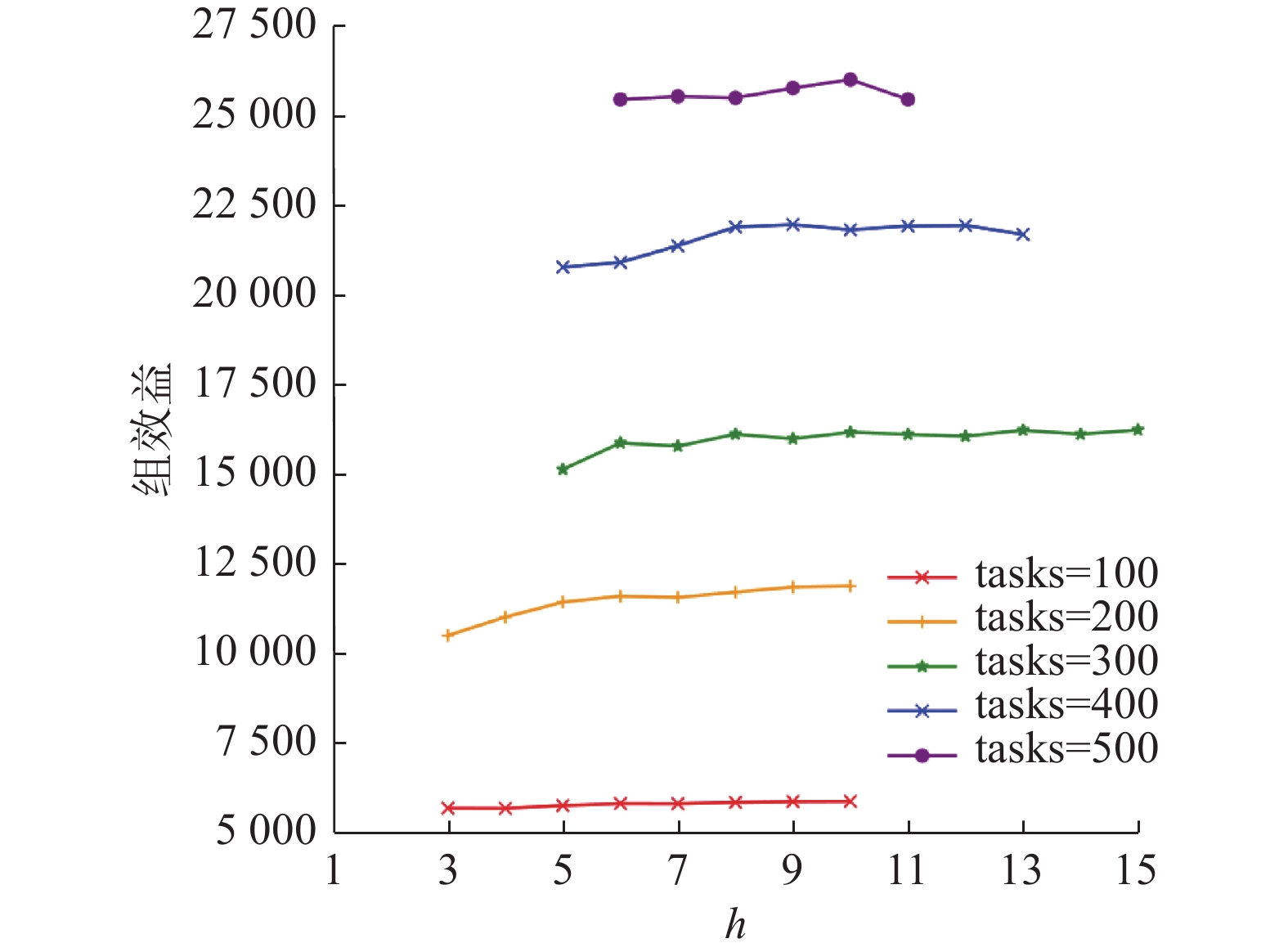 图 7 PQGM算法组效益Fig. 7 Group benefits of PQGM algorithm下载:
全尺寸图片
图 7 PQGM算法组效益Fig. 7 Group benefits of PQGM algorithm下载:
全尺寸图片
由图7可得,应用PQGM算法,当任务数为[100, 200, 300, 400, 500]时带宽h有效值为[3~10, 3~10, 5~15, 5~13, 6~11]。带宽有效范围的下限由3逐渐增加到6。开始下限为3是由于当任务数为100、200时小带宽角色划分不稳定导致超出角色内最大时差。下限逐渐增大是因为超出了12个工人能够担任的角色数,且随着任务数增多达到工人能完成的角色数范围所需的带宽逐渐增大。
另外由图7可看出,任务数为100、200时由于单个角色包含的任务数增多易超出最大时差,带宽的最大限制相对较小。任务数从100~300增加时带宽的最大限制有增长的趋势, 是因为任务数量增多时对于一个角色内最多8个任务的限制来说逐步不易超出最大时差。但300~500时带宽的最大限制逐步减小是由于对于较大的任务数带宽的增大对角色划分无明显改进作用。
由图8可得应用PQGR算法当任务数为[100, 200, 300, 400, 500]时,不同带宽组效益的变化趋势。图8与图7相比,由于PQGR算法在任务数量较多时虽然任务完成率不为100%,但不存在无解的情况,因此较小带宽也存在相对应的组效益值但值较小。任务数为100、200时小带宽对应的组效益缺失同样是由于超出角色内最大时差。
 图 8 PQGR算法组效益Fig. 8 Group benefits of PQGR algorithm下载:
全尺寸图片
图 8 PQGR算法组效益Fig. 8 Group benefits of PQGR algorithm下载:
全尺寸图片
综合上述2种方法组效益的变化幅度和范围,由于波动较小且为了降低核密度聚类划分角色的不稳定性,带宽取值范围均为[1,20],聚类后不符合限制条件的不进行下一步分配。
5.3 算法比较
本节在gMission数据集和合成数据集上进行了实验,对比算法为没有通过RPA算法划分角色,而是在时间范围内按顺序随机聚类的PQGM和PQGR算法,将4种算法进行对比,验证了算法的有效性和可行性。
图9是任务数为100~500时应用4种算法的组效益。可以看出PQGM算法效果相较于另外3种算法来说效果较好,且随着任务数量的增加优势逐渐增大,没有应用RPA的PQGR算法效果最差,另外两个相差不大。由于是循环取最优值,4种算法的任务完成率都较高,PQGM系列算法都为100%,PQGR系列算法在98%~100%。
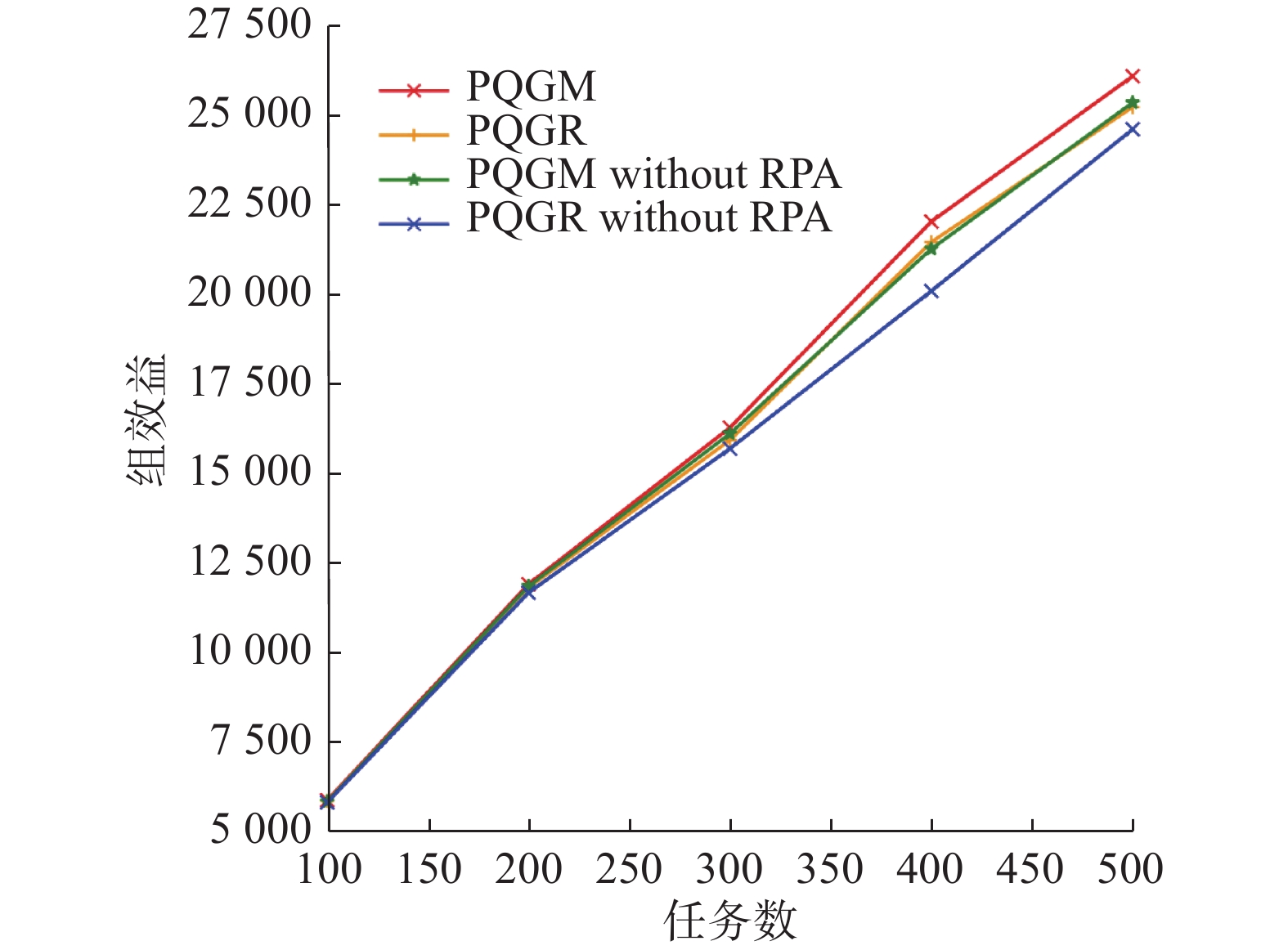 图 9 gMission数据集组效益Fig. 9 Group benefits of gMission datasets下载:
全尺寸图片
图 9 gMission数据集组效益Fig. 9 Group benefits of gMission datasets下载:
全尺寸图片
图10给出了算法的运行时间,可以从图中看到,没有运用角色感知算法(RPA)的2个算法因为只需执行一次,运行时间较短,其值维持在0和1附近,但没有RPA划分角色的PQGM算法不能保证所产生的任务数对于当前代理集有解。PQGR算法运行时间是单调递增的且低于PQGM算法,随着任务数增多两者差距增大。PQGR算法运行时间维持在25 s以内,PQGM算法时间维持在35 s以内。
 图 10 gMission数据集运行时间Fig. 10 Running time of gMission datasets下载:
全尺寸图片
图 10 gMission数据集运行时间Fig. 10 Running time of gMission datasets下载:
全尺寸图片
经过多次实验发现,应用PQGM算法求解时,由于代理数不变,问题从无解过渡到有解时,角色数量是有一定规律的,本文称这个数量范围为过渡范围。本文实验设置中代理数为12,工人一天所能承担的角色范围为[8,15]时过渡范围约为[100, 120],因此可以根据角色数量规避掉确定无解的数据点,缩短总的任务运行时间。本文以120为边界值,形成PQGM-adjusted(PQGMA)方法,如图10所示明显缩短了运行时间。
本文分别对2个目标——地点资格值和价值进行对比。由于每个角色地点资格值取值范围为(0, 1)、价值不定,每个任务价值取值(0, 100],因此计算每个角色的地点资格值均值和每个任务的价值均值。地点资格值均值如图11所示,随着任务数增多,所有算法的均值都呈现下降趋势,PQGM算法均值最大,没有RPA划分角色的PQGR算法均值最小。由于任务完成率较高,4种算法的价值均值差距较小,当任务数较大时PQGM类算法有优势。
 图 11 gMission数据集地点资格值均值Fig. 11 Mean location qualification value of gMission datasets下载:
全尺寸图片
图 11 gMission数据集地点资格值均值Fig. 11 Mean location qualification value of gMission datasets下载:
全尺寸图片
另外,受Zhu等[22]代理分类算法中限制每个类别代理数量的启发,实验应用Zhu提出的AC_SAGRA+算法的变体(简称GAC)进行任务划分生成角色集。当任务数为100时,将利用核密度聚类算法和GAC算法进行任务划分的PQGM算法和PQGR算法进行比较,如表7所示,GAC划分后的角色所得组效益略优于核密度聚类所得组效益,但由于其模拟退火迭代次数较多,运行时间较长,整体来说不如核密度聚类效果好。
表 7 算法对比Table 7 Algorithm contract算法 角色数 时间/s PQGM PQGR 核密度 40 0.25628 5883.14 5860.88 GAC 41 578.877 5889.57 5874.15 对于正态分布任务数为500,任务价值以μ=[15, 25, 45, 64, 85],σ =3.75的正态分布生成的数据集分析,没有RPA数据处理的PQGMA算法产生的角色集不一定有解。如图12所示,随着
$ \mu $ 值的增加4种算法的组效益都在增加,差距逐渐增大,PQGMA算法的优势明显。运行时间如图13所示,当任务数为500时,4种算法的运行时间在一定范围内波动。地点资格值均值与价值均值与真实数据集相仿。如图14所示PQGMA类算法任务完成率为100%,PQGR类算法任务完成率位于98%~100%。 图 12 正态分布数据集组效益Fig. 12 Group benefits of normally distributed datasets下载:
全尺寸图片
图 12 正态分布数据集组效益Fig. 12 Group benefits of normally distributed datasets下载:
全尺寸图片
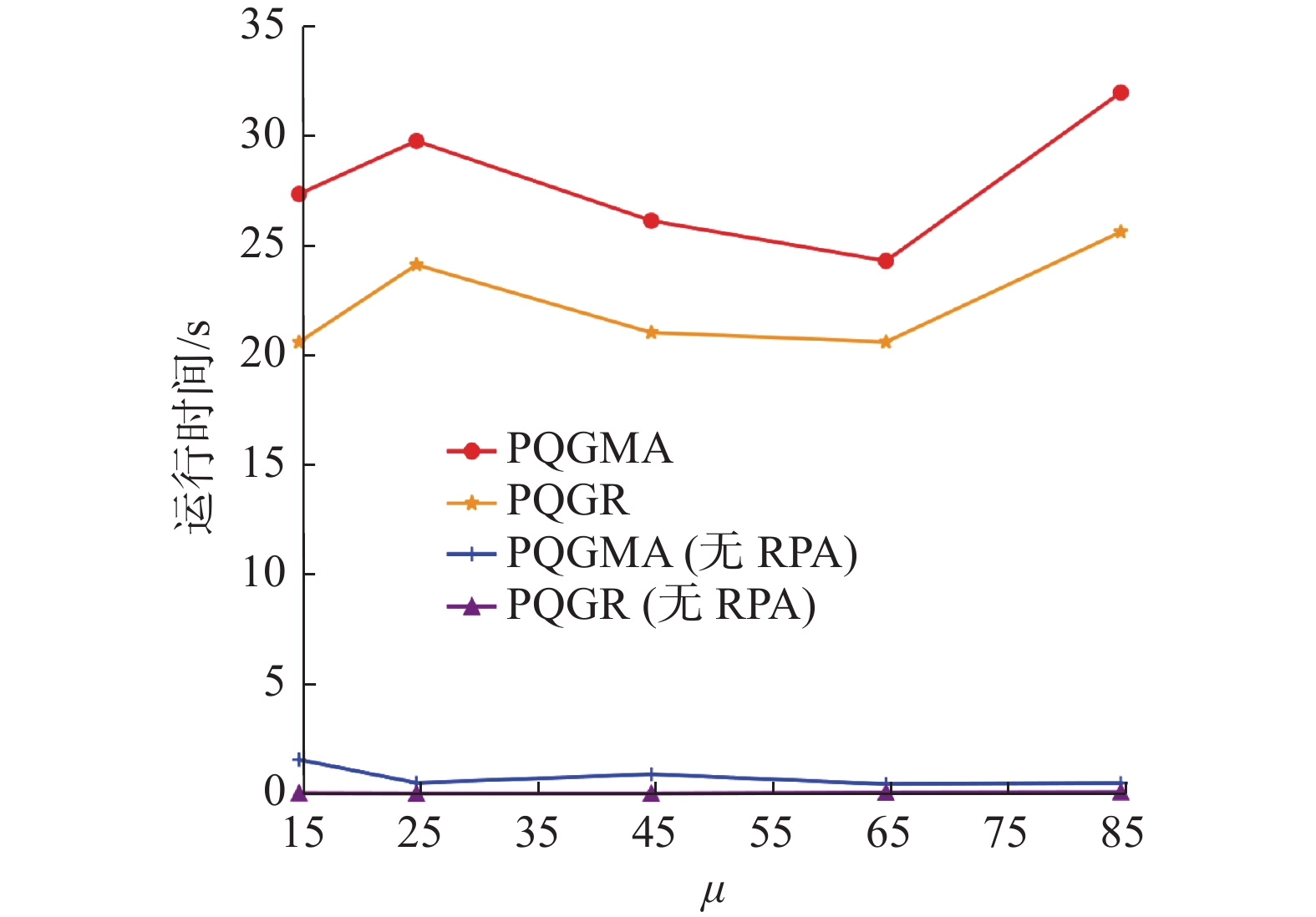 图 13 正态分布数据集运行时间Fig. 13 Running time of normally distributed datasets下载:
全尺寸图片
图 13 正态分布数据集运行时间Fig. 13 Running time of normally distributed datasets下载:
全尺寸图片
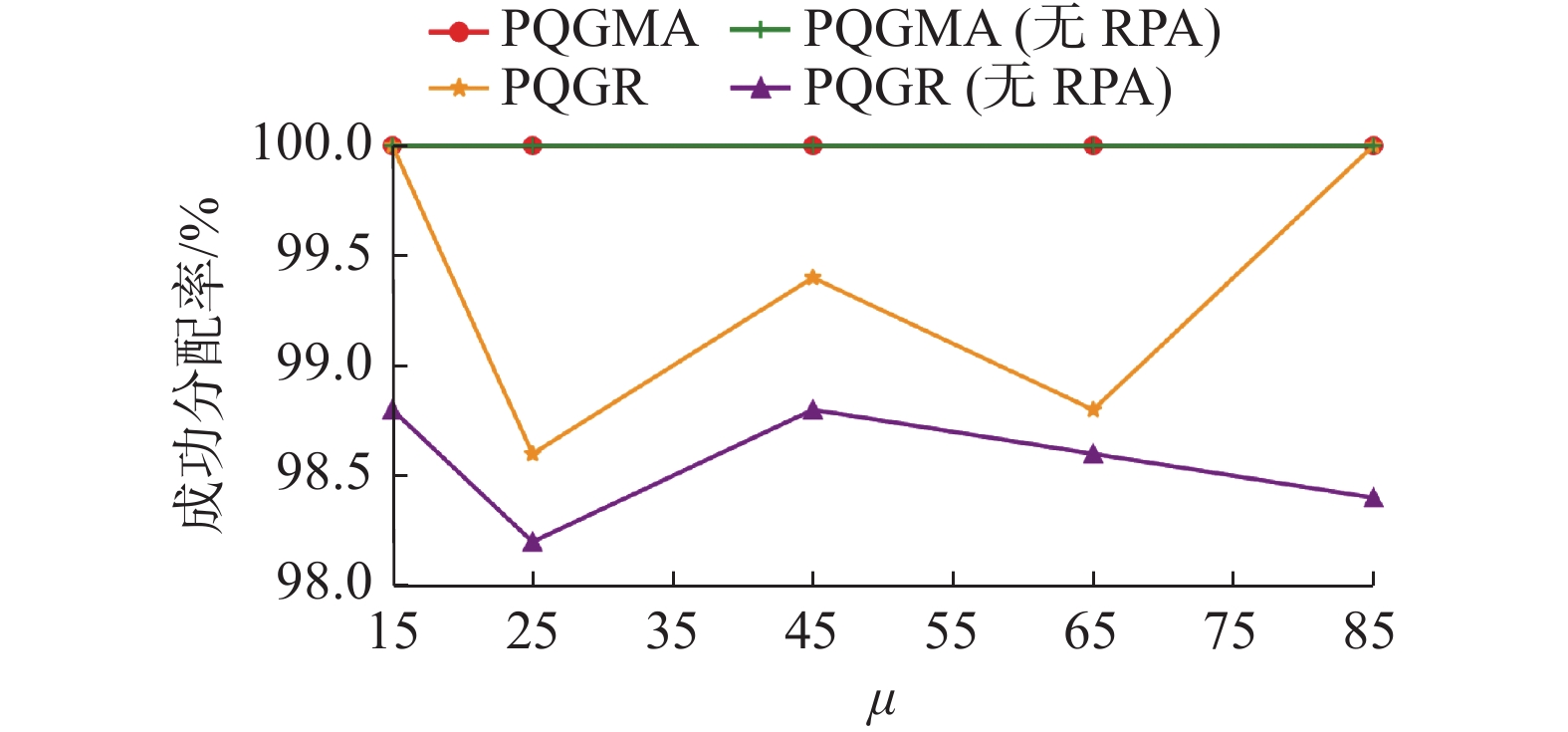 图 14 正态分布数据集任务完成率Fig. 14 Task completion rate of normally distributed datasets下载:
全尺寸图片
图 14 正态分布数据集任务完成率Fig. 14 Task completion rate of normally distributed datasets下载:
全尺寸图片
6. 结束语
本文首次提出了针对社区服务型时空众包(CSSC)模式的任务分配问题并将其通过RBC形式化表达。为实现派遣高地点资格值代理配送高价值量订单集的目标,任务分配上提出基于地点资格值的PQGR算法、PQGM算法和PQGMA算法。在数据处理和量化方面:提出基于核密度估计聚类的角色感知方法;提出代理资格值动态变化的代理地点资格值多阶段量化模型,对于资格值进行在线学习。最后在gMission数据集和合成数据集上进行了实验,验证了算法的有效性和效率。在未来的工作中,可以继续尝试其他算法去优化聚类效果,加入其他需要考虑的因素平衡角色数量和组效益的关系。
-
图 1 代理地点资格值变化过程
Fig. 1 Agent place qualification value change process
下载:
全尺寸图片
图 2 代理资格值变化情况
Fig. 2 Changes in the agent’s qualification value
下载:
全尺寸图片
图 3 PQGM算法流程图
Fig. 3 Flow chart of PQGM algorithm
下载:
全尺寸图片
图 4 订单的位置分布和角色划分
Fig. 4 Location distribution and role division of orders
下载:
全尺寸图片
图 5 gMisson数据集中任务数量随时间变化趋势
Fig. 5 Trend of the number of tasks in gMisson dataset over time
下载:
全尺寸图片
图 6 gMission数据集中不同时间段任务地点分布
Fig. 6 Tasks location distribution in different time periods in the gMission dataset
下载:
全尺寸图片
图 7 PQGM算法组效益
Fig. 7 Group benefits of PQGM algorithm
下载:
全尺寸图片
图 8 PQGR算法组效益
Fig. 8 Group benefits of PQGR algorithm
下载:
全尺寸图片
图 9 gMission数据集组效益
Fig. 9 Group benefits of gMission datasets
下载:
全尺寸图片
图 10 gMission数据集运行时间
Fig. 10 Running time of gMission datasets
下载:
全尺寸图片
图 11 gMission数据集地点资格值均值
Fig. 11 Mean location qualification value of gMission datasets
下载:
全尺寸图片
图 12 正态分布数据集组效益
Fig. 12 Group benefits of normally distributed datasets
下载:
全尺寸图片
图 13 正态分布数据集运行时间
Fig. 13 Running time of normally distributed datasets
下载:
全尺寸图片
图 14 正态分布数据集任务完成率
Fig. 14 Task completion rate of normally distributed datasets
下载:
全尺寸图片
表 1 订单的时间与位置分布
Table 1 Time and location distributions of orders
任务 时间/min 位置 价值/元 t1 0 (32,70) 41 t2 4 (21,22) 22 t3 7 (82,13) 10 t4 8 (55,85) 33 t5 8 (57,93) 65 t6 9 (65,75) 48 t7 10 (43,65) 11 t8 12 (27,45) 35 t9 15 (83,4) 19 t10 20 (99,21) 55 t11 23 (94,41) 30 t12 30 (34,59) 6 t13 32 (30,8) 23 t14 32 (28,1) 41 t15 35 (44,14) 32 表 2 收货地点的位置分布
Table 2 Location distributions of receiving places
P1 P2 P3 P4 P5 (17,72) (47,82) (81,87) (34,40) (75,17) 表 3 代理的地点资格值矩阵
Table 3 The agent's place qualification value matrix
代理/地点 P1 P2 P3 P4 P5 a1 0.66 0.12 0.65 0.98 0.21 a2 0.97 0.46 0.33 0.44 0.50 a3 0.32 0.63 0.91 0.51 0.49 a4 0.43 0.31 0.72 0.96 0.21 a5 0.17 0.55 0.56 0.59 0.79 表 4 资格值Q矩阵
Table 4 Q matrix of qualification values
代理/角色 r1 r2 r3 r4 r5 a1 27.06 55.86 23.94 18.84 99.96 a2 39.77 25.08 57.00 72.22 44.88 a3 13.12 29.07 55.86 98.91 52.02 a4 17.63 54.72 23.94 48.67 97.92 a5 6.97 33.63 90.06 86.35 60.18 表 5 PQGM算法分配矩阵T
Table 5 Assignment matrix T of PQGM
代理/角色 r1 r2 r3 r4 r5 a1 1 0 0 0 1 a2 0 1 0 0 0 a3 0 0 0 1 0 a4 0 0 0 0 1 a5 0 0 1 0 0 表 6 数据集变量设置
Table 6 Datasets variable settings
表 7 算法对比
Table 7 Algorithm contract
算法 角色数 时间/s PQGM PQGR 核密度 40 0.25628 5883.14 5860.88 GAC 41 578.877 5889.57 5874.15 -
[1] ZHU Haibin, ZHOU Mengchu. Role-based collaboration and its kernel mechanisms[J]. IEEE transactions on systems, man, and cybernetics, part C (applications and reviews), 2006, 36(4): 578–589. doi: 10.1109/TSMCC.2006.875726 [2] SHENG Yin, ZHU Haibin, ZHOU Xianzhong, et al. Effective approaches to adaptive collaboration via dynamic role assignment[J]. IEEE transactions on systems, man, and cybernetics:systems, 2016, 46(1): 76–92. doi: 10.1109/TSMC.2015.2423653 [3] ZHU Haibin. Adaptive collaboration systems: self-sustaining systems for optimal performance[J]. IEEE systems, man, and cybernetics magazine, 2015, 1(4): 8–15. doi: 10.1109/MSMC.2015.2460613 [4] ZHU Haibin, HOU Ming, ZHOU Mengchu. Adaptive collaboration based on the E-CARGO model[J]. International journal of agent technologies and systems, 2012, 4(1): 59–76. doi: 10.4018/jats.2012010104 [5] ZHU Haibin, LIU Dongning, ZHANG Siqin, et al. Solving the Many to Many assignment problem by improving the Kuhn-Munkres algorithm with backtracking[J]. Theoretical computer science, 2016, 618: 30–41. doi: 10.1016/j.tcs.2016.01.002 [6] ZHU Haibin, SHENG Yin, ZHOU Xianzhong, et al. Group role assignment with cooperation and conflict factors[J]. IEEE transactions on systems, man, and cybernetics:systems, 2018, 48(6): 851–863. doi: 10.1109/TSMC.2016.2633244 [7] ZHU Haibin, ZHOU Mengchu, ALKINS R. Group role assignment via a Kuhn-munkres algorithm-based solution[J]. IEEE transactions on systems, man, and cybernetics-part A:systems and humans, 2012, 42(3): 739–750. doi: 10.1109/TSMCA.2011.2170414 [8] ZHU Haibin, LIU Dongning, ZHANG Siqin, et al. Solving the group multirole assignment problem by improving the ILOG approach[J]. IEEE transactions on systems, man, and cybernetics:systems, 2017, 47(12): 3418–3424. doi: 10.1109/TSMC.2016.2566680 [9] ZHU Haibin. Avoiding conflicts by group role assignment[J]. IEEE transactions on systems, man, and cybernetics:systems, 2016, 46(4): 535–547. doi: 10.1109/TSMC.2015.2438690 [10] ZHU Haibin. Group multi-role assignment with conflicting roles and agents[J]. IEEE/CAA journal of automatica sinica, 2020, 7(6): 1498–1510. doi: 10.1109/JAS.2020.1003354 [11] LIU Dongning, HUANG Baoying, ZHU Haibin. Solving the tree-structured task allocation problem via group multirole assignment[J]. IEEE transactions on automation science and engineering, 2020, 17(1): 41–55. doi: 10.1109/TASE.2019.2908762 [12] JIANG Qian, ZHU Haibin, QIAO Yan, et al. Agent evaluation in deployment of multi-SUAVs for communication recovery[J]. IEEE transactions on systems, man, and cybernetics: systems, 2021, 52(11): 6968−6982. [13] ZHU Haibin. Maximizing group performance while minimizing budget[J]. IEEE transactions on systems, man, and cybernetics:systems, 2020, 50(2): 633–645. doi: 10.1109/TSMC.2017.2735300 [14] ZHU Haibin, HOU Ming, WANG Chun, et al. An efficient outpatient scheduling approach[J]. IEEE transactions on automation science and engineering, 2012, 9(4): 701–709. doi: 10.1109/TASE.2012.2207453 [15] JIANG Qian, LIU Dongning, ZHU Haibin, et al. Equilibrium means equity? an E-CARGO perspective on the golden mean principle[EB/OL]. (2022−03−05)[2022−05−01].https://ieeexplore.ieee.org/document/9732178. [16] 钱晨, 张以文, 吴其林, 等. 基于E-CARGO模型的云制造服务组合方法[J]. 小型微型计算机系统, 2020, 41(9): 2006–2011. doi: 10.3969/j.issn.1000-1220.2020.09.034 QIAN Chen, ZHANG Yiwen, WU Qilin, et al. Cloud manufacturing service composition method based on E-CARGO model[J]. Journal of Chinese computer systems, 2020, 41(9): 2006–2011. doi: 10.3969/j.issn.1000-1220.2020.09.034 [17] 李晓会, 董红斌. 基于E-CARGO模型的共乘出行匹配建模与优化方法[J]. 计算机应用, 2022, 42(3): 778–782. LI Xiaohui, DONG Hongbin. Modeling and optimization method of ride-sharing matching based on E-CARGO model[J]. Journal of computer applications, 2022, 42(3): 778–782. [18] 李炜, 吴群群, 张以文. 基于E-CARGO模型的开发者推荐方法[J]. 计算机应用, 2022, 42(2): 557–564. LI Wei, WU Qunqun, ZHANG Yiwen. Developer recommendation method based on E-CARGO model[J]. Journal of computer applications, 2022, 42(2): 557–564. [19] ZHU Haibin. Agent categorization with group role assignment with constraints and simulated annealing[J]. IEEE transactions on computational social systems, 2020, 7(5): 1234–1245. doi: 10.1109/TCSS.2020.3006381 [20] HUANG Baoying, ZHU Haibin, LIU Dongning, et al. Solving last-Mile logistics problem in spatiotemporal crowdsourcing via role awareness with adaptive clustering[J]. IEEE transactions on computational social systems, 2021, 8(3): 668–681. doi: 10.1109/TCSS.2021.3051299 [21] JIANG Qian, LIU Dongning, ZHU Haibin, et al. Quasi group role assignment with role awareness in self-service spatiotemporal crowdsourcing[J]. IEEE transactions on computational social systems, PP(99): 1-13. [22] PENG Chaoqun, ZHANG Xinglin, OU Zhaojing, et al. Task planning considering location familiarity in spatial crowdsourcing[J]. ACM transactions on sensor networks, 2021, 17(2): 16. [23] 于洪涛, 崔瑞飞, 董芹芹. 基于遗忘曲线的微博用户兴趣模型[J]. 计算机工程与设计, 2014, 35(10): 3367–3372,3379. doi: 10.3969/j.issn.1000-7024.2014.10.006 YU Hongtao, CUI Ruifei, DONG Qinqin. Micro-blog user interest model based on forgetting curve[J]. Computer engineering and design, 2014, 35(10): 3367–3372,3379. doi: 10.3969/j.issn.1000-7024.2014.10.006 [24] IBM. IBM ILOG CPLEX Optimization Package. [EB/OL]. (2021−01−01)[2022−05−01].http://www-01.ibm.com/software/integration/optimization/cplexoptimization-studio/. [25] CHEN Zhao, FU Rui, ZHAO Ziyuan, et al. gMission[J]. Proceedings of the VLDB endowment, 2014, 7(13): 1629–1632. doi: 10.14778/2733004.2733047




























































































































