
Multi-layer attention knowledge representation learning by integrating entity structure with semantics
-
摘要: 基于知识图谱的知识表示学习虽然可以获得实体的结构和关系嵌入,但是缺少对实体描述文本的语义信息利用。此外,随着知识图谱规模的增长,实体和关系的类别与数量,以及实体描述的内容和来源随之增加,实体的文本描述与三元组结构信息之间的对应关系更加难以获得。基于此,本文提出一种实体结构与语义融合的多层注意力知识表示学习方法,通过构建多层注意力机制,将实体的结构嵌入用于增强实体描述中的语义表达,再通过Transformer模型获取实体描述的语义关系,并采用关系的结构嵌入对其增强和整合,最后利用整合后的语义关系对关系嵌入集合加以丰富和整合。特别是,构建了面向实体结构与语义融合多层注意力机制的损失函数。实验结果表明,本文所提方法能有效推理包含复杂实体描述的实体之间隐藏链路关系,在三元组分类任务中具有比同类方法更准确的分类精度。Abstract: Though the structure and relationship embedding of entities can be obtained by knowledge representation learning based on the knowledge graph, there lacks of the semantic information utilization of entity description texts. In addition, with the increase of the scale of knowledge graph, the categories and quantities of entities and their relationships, as well as the contents and sources of entity descriptions increase accordingly. It is more difficult to obtain the corresponding relationship between entity text descriptions and triple structure information. Therefore, this paper presents a multi-layer attention knowledge representation learning method, which integrates entity structure with semantics. By constructing a multi-layer attention mechanism, the structural embedding of entities is used to enhance the semantic expression in entity description, and then the semantic relationship of entity description is obtained by Transformer model, and it is enhanced and integrated by structural embedding of relationships. Finally, the integrated semantic relationship is used to enrich and integrate the relationship embedding set. Specifically, a loss function is constructed for a multi-layer attention mechanism, which integrates entity structure with semantic information. The experimental results show that the method proposed in this paper can effectively infer the hidden link relationship between entities containing complex entity descriptions, and has more accurate classification accuracy than the other similar methods in triple classification tasks.
-
随着互联网技术的迅猛发展,各类数据呈现爆炸式增长。为更加有效地描述数据中隐含的有价值知识,知识图谱应运而生,具有代表性的有Freebase [1]、WordNet[2]和YAGO[3]等。知识图谱旨在描述真实世界中存在的各种实体或概念及其关系,本质上是一种大型语义网络,由诸多相互连接的节点构成[4]。每个节点代表一个实体,节点之间的边表示实体之间的关系[5]。实体及其关系采用三元组表示,用于描述知识图谱中包含的信息[6],例如,(中国,首都,北京)这个三元组表示的信息是:“中国的首都是北京”。由于知识图谱采用符号化的表示方法,在因果推理[7]、用户推荐[8]和智能问答[9]等知识服务应用中,随着其规模的增加,会出现数据稀疏等问题,导致知识服务的完成质量降低。针对该问题,知识表示学习方法被提出。知识表示学习方法用于得到三元组内实体和关系的分布式描述,将三元组由离散的符号化描述转化为低维向量表示[10],有效地解决了知识图谱的数据稀疏问题,并且提高了知识服务的计算效率。
在知识表示学习中,除了三元组的结构信息,与三元组内实体对应的文本描述也可以被利用,其包含的丰富语义信息可以提高三元组的知识内涵。但是,随着知识图谱规模的增长,实体和关系的类别与数量以及实体描述的内容和来源随之增加,实体的文本描述与三元组结构信息之间的对应关系更加难以获得,而现有结合实体描述的知识表示学习方法并未解决这个问题。
针对上述问题,本文提出一种实体结构与语义融合的多层注意力知识表示学习模型(entity structure and semantic fusion knowledge representation learning model based on multi-layer attention mechanism,ESKMA)。该模型构建多层注意力机制,将知识图谱中实体所对应文本描述包含的语义关系与三元组的结构嵌入相结合,丰富三元组的知识内涵;面对复杂且多源的实体文本描述,采用多层注意力机制,通过实体的结构嵌入增强实体描述中的语义表达,再通过Transformer模型整合复杂实体描述的语义关系,并利用语义关系对关系嵌入加以增强。针对链路预测和三元组分类任务,本文所提模型在4个数据集上的表现均优于其他模型。特别是,本模型面向具有复杂实体描述的数据集性能更佳。
1. 相关工作
研究人员已开展了丰富的知识表示学习工作,结合本文所提算法,详细阐述相关的两类知识表示学习方法。
1.1 基于翻译思想的知识表示学习
早期的知识表示学习专注于三元组的结构嵌入,其最具代表性的是TransE[11-12]。它将实体之间的关系看作是从头部实体到尾部实体的映射。虽然采用TransE描述三元组的实体和关系简单有效,但是难以准确地描述复杂的实体对应关系,比如:某一实体存在于多种关系中(记为
$1 - N$ );多种实体存在于同一种关系中(记为$N - 1$ );或多个实体之间存在多种关系(记为$N - M$ )。为解决上述问题,研究人员提出TransE的多种衍生模型。其中,TransH[13] 假设实体向量和关系向量位于不同的超平面中,并将头部实体向量和尾部实体向量分别映射到关系向量所在的超平面。TransR[14]则通过矩阵变换,将头部实体和尾部实体向量投影到特定关系空间。与TransR不同,TransD[15]针对实体和关系之间存在的$ N-M $ 映射,动态获取从实体向量到关系向量的变换矩阵。TranSparse[16]在TransR模型基础上,采用稀疏矩阵代替稠密矩阵描述异构关系,并通过不同的稀疏投影矩阵,实现头实体到尾实体的映射,解决关系不平衡问题。TransA [17]根据自适应策略对三元组嵌入的损失函数进行了改进。KG2E[18]将实体和关系表示为从多维高斯分布中抽取的随机向量,有效反映了知识图谱中实体和关系的不确定性。TransG[19]则利用高斯分布建模实体和关系,认为一个关系可以有多个语义。TransE-SNS[20]基于实体相似性生成负例三元组,提高知识图谱嵌入的质量。上述改进模型在一定程度上为复杂关系表示提供了有效解决途径,但是仍采用三元组结构嵌入,并没有充分利用实体文本描述中的丰富语义信息。
1.2 结合实体描述的知识表示学习方法
为了更加合理地描述实体和关系之间的复杂映射,研究人员尝试将三元组的结构嵌入和文本描述的语义信息相结合。Soche等[21]提出NTN(neural tensor network)模型,将实体描述与三元组分别嵌入,但并未对它们之间的交互方式进行建模。Santos等[22]考虑到知识图谱中数据的不完备性,采用自然语言处理技术,直接从纯文本中提取关系知识。Chen等[23]将深度神经网络应用于文本关系向量的提取。Zhang等[24]借鉴Paragraph Vector[25]模型,采用实体描述辅助三元组内的实体进行向量表达,但没有区分实体描述所对应的文本词序。Xu等[26]构建了3种神经网络模型,实现实体描述中的语义信息提取,并设计了一种门控机制,将结构信息和语义信息映射到同一向量空间。Xie等[27]提出DKRL(description-embodied knowledge representation learning)模型,采用CBOW(continuous bag of words)[28]模型对实体描述加以编码。Wang等[29]提出TEKE (text-enhanced knowledge embedding)模型,采用word2vec和TransH分别获得实体对应的文本描述和三元组结构信息的向量表达。Wang等[30]提出TransET模型,学习实体对应的类别内包含的语义信息。Hu等[31]引入图卷积神经网络(graph convolutional network, GCN)学习实体对应节点与邻居节点之间的语义信息,将其应用到实体嵌入中,再与实体描述相结合。Ji等[32]提出一种基于参考句的模型,通过注意力机制选择高质量的参考句,再利用参考句整合结构嵌入和实体描述包含的语义信息。Wen等[33]通过长短期记忆网络(long short-term memory, LSTM),融合实体描述中的语序特征和三元组的结构信息,丰富了三元组的语义表达。Zhao等[34]采用卷积神经网络(convolutional neural networks, CNN)从实体对应的文本描述中提取语义关系,并利用注意力机制区分不同语义关系的可信度,但文本描述获取的语义关系不够准确。Wu等[35]利用实体描述中的语义信息将实体和关系共同嵌入到双曲空间加以训练。Do等[36]则通过元路径(meta-path)来评估实体之间关系与文本信息的相似性,从而提升模型的准确性。Zheng等[37]根据特定医学数据集,将医学成像信息、文本信息与三元组结构信息相融合,显著提高了模型性能。Jiang等[38]提出了一种自适应采样算法,实现邻居节点特征的聚合,进一步与实体描述相结合。Chen等[39]提出了DAC(dimensional attention composition)方法,对融合结构和实体描述信息的模型参数进行调节,有效解决了知识图谱的稀疏性。Cheng等[40]提出了MCapsEED(multi-scale capsule-based embedding model incorporating entity descriptions)模型,采用胶囊网络和注意力机制获取实体描述中的语义信息。
上述这些方法将知识表示学习与实体的语义描述相结合,给出三元组的融合表示。但是,上述方法仅仅提出了单一来源实体描述的语义信息获取方法,而知识图谱规模的扩大必然会导致复杂多源实体描述的出现。因此,更好地获取复杂多源实体描述的语义信息,并与三元组结构信息相结合具有重要意义。
2. 实体的结构嵌入与语义信息表示
定义知识图谱为
$ G = \{ E,R,T\} $ ,其中,$ E $ 为实体的集合,$ R $ 表示实体之间关系的集合,$T$ 为知识图谱中三元组的集合。一个三元组记为$ (h,r,t) \in T $ ,其中,$ h,t \in E $ 分别表示头实体和尾实体,$ r \in R $ 表示头实体h和尾实体t之间的关系。2.1 三元组的结构嵌入
三元组结构嵌入借用TransE[11-12]的建模过程来描述。对于知识图谱三元组内的头实体h和尾实体t,通过结构嵌入获得其向量表达,记为hG和tG。基于此,定义从头实体向量hG到尾实体向量tG的映射关系为
${{\boldsymbol{r}}_{h,t}}$ :$$ {{\boldsymbol{r}}_{h,t}} = {{\boldsymbol{t}}_{{G}}} - {{\boldsymbol{h}}_{{G}}} $$ (1) 每个三元组
$ (h,r,t) $ 通过知识表示学习得到关系嵌入向量,记为${{\boldsymbol{r}}_{{G}}}$ 。知识表示学习的目的是使${{\boldsymbol{t}}_{{G}}} - {{\boldsymbol{h}}_{{G}}} \approx {{\boldsymbol{r}}_{{G}}}$ ,则每个三元组$ (h, r, t) $ 的距离函数有:$$ \varphi (h,t) = \parallel {{\boldsymbol{r}}_{h,t}} - {{\boldsymbol{r}}_{{G}}}\parallel = \parallel \left( {{{\boldsymbol{t}}_{{G}}} - {{\boldsymbol{h}}_{{G}}}} \right) - {{\boldsymbol{r}}_{{G}}}\parallel $$ (2) 进而,获得三元组的实体嵌入损失函数如下:
$$ {L_G}(G) = \mathop \sum \limits_{(h,r,t) \in T} \mathop \sum \limits_{\left( {h',r,t'} \right) \in T'} {\left[ {\mu + \varphi (h,t) - \varphi \left( {h',t'} \right)} \right]_ + } $$ (3) 式中:
$[{x_ + }] = \left\{ \begin{gathered} x\;\;\;\;x > 0 \\ 0\;\;\;\;x \leqslant 0 \\ \end{gathered} \right.$ ,$ \mu > 0 $ 为超参数,衡量正确三元组和错误三元组的边界。$ \varphi (h,t) $ 表示$T$ 已有三元组的距离函数,$ \varphi (h',t') $ 表示随机选取知识图谱中任一实体,替换头实体h和尾实体t组成的负三元组距离函数[41],负三元组的集合记为$T'$ ,$T'$ 中的三元组在实际知识图谱中不存在。2.2 实体描述文本语义信息
记D是实体的文本描述语料库,与三元组
$(h,r,t)$ 中头实体h和尾实体t相对应的句子集合记为$\{ {s_1},{s_2}, \cdots ,{s_n}\}$ ,句子集合的嵌入向量记为$[{p_1}\;{p_2}\;\cdots \;{p_n}]$ ,n表示句子的数量,其中每个句子都包含h和t。第i个句子为${s_i} = \{ {w_{i1}}, {w_{i2}}, \cdots {w_{ij}} \cdots {w_{im}}\}$ ,${w_{ij}}$ 表示句子中包含的词,m表示该句子中词的数量。${s_i}$ 中第$j$ 个词${w_{ij}}$ 的初始嵌入向量记为${{\boldsymbol{g}}_{ij}} = [{{\boldsymbol{v}}_{ij}}\;f_{ij}^h\;f_{ij}^t]$ ,其中,${{\boldsymbol{v}}_{ij}}$ 表示采用词嵌入模型获得的词向量,$ f_{ij}^h $ 和$f_{ij}^t$ 分别表示${w_{ij}}$ 与相应的h和t之间距离。与${s_i}$ 相应的嵌入向量记为${{\boldsymbol{p}}_i} = [{{\boldsymbol{z}}_{i1}}\;{{\boldsymbol{z}}_{i2}} \cdots{{\boldsymbol{z}}_{ij}} \cdots {{\boldsymbol{z}}_{im}}]$ ,${{\boldsymbol{z}}_{ij}}$ 表示每个词的嵌入向量。3. 多层注意力知识表示学习
本文提出的多层注意力知识表示学习模型设计思路如图1所示,通过多层注意力机制,实体结构嵌入对句子中实体的语义信息加以增强;实体之间的关系嵌入对其语义关系进行整合;整合后的语义关系进一步丰富其关系嵌入,增加三元组的知识内涵。
 图 1 ESKMA模型设计思路Fig. 1 Design idea of ESKMA
图 1 ESKMA模型设计思路Fig. 1 Design idea of ESKMA 下载:
全尺寸图片
下载:
全尺寸图片
3.1 基于注意力机制的语义信息增强
句子
${s_i}$ 中,除了包含h和t构成的实体对,还存在蕴含多种关系的实体对,并且其他实体与h和t之间存在不同的关联。为准确地获取与h和t相关的语义信息,本文构建了从实体结构嵌入到句子中实体语义信息的注意力机制,记为“$E \to C$ ”,如图2所示。根据h和t的实体结构嵌入,计算句子中每个词相对于h和t的权重,优化句子内实体的语义信息,调整初始嵌入向量${{\boldsymbol{g}}_{ij}}$ ,获得与${w_{ij}}$ 相对应的嵌入向量${{\boldsymbol{z}}_{ij}}$ 。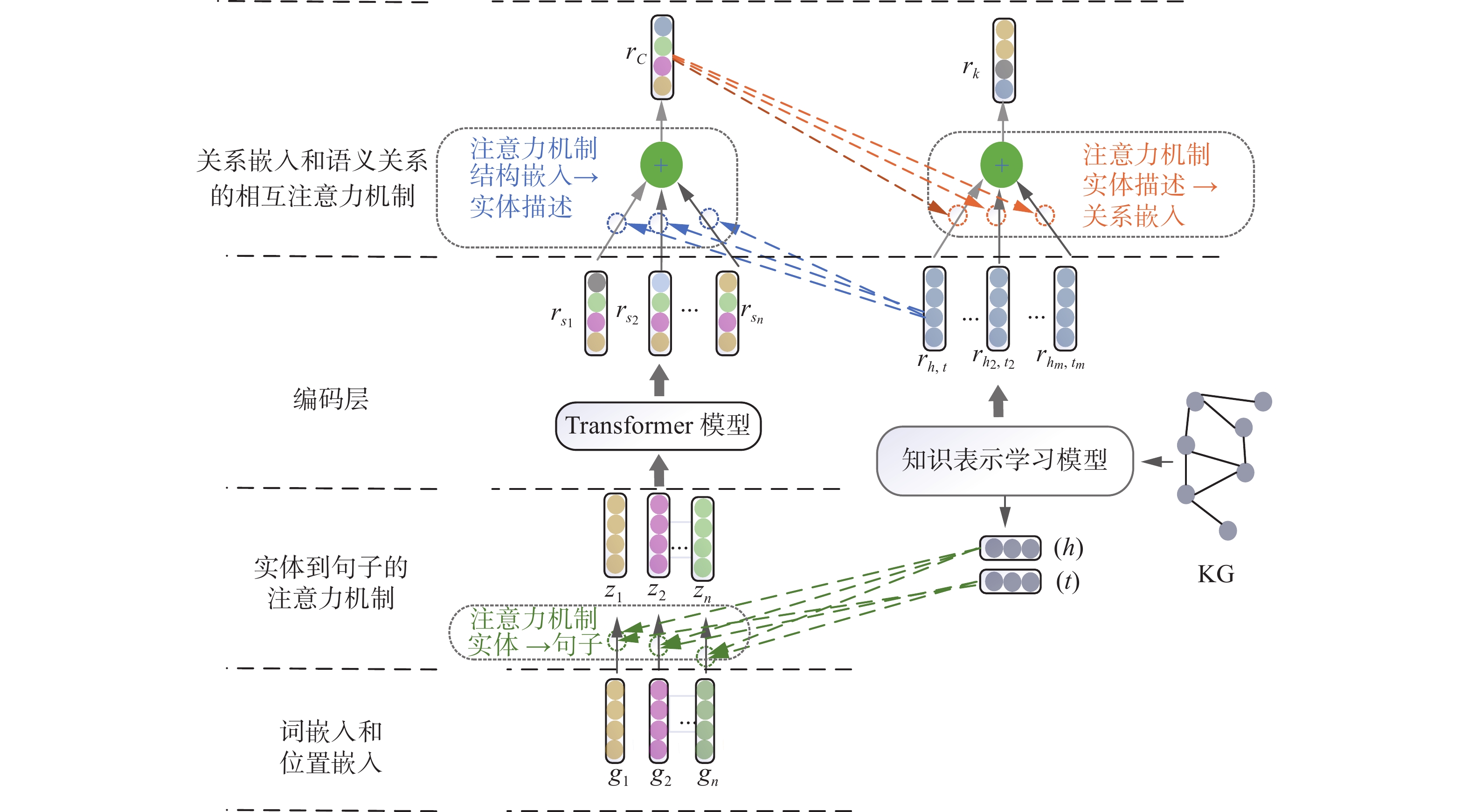 图 2 ESKMA方法流程图Fig. 2 Flow chart of ESKMA method下载:
全尺寸图片
图 2 ESKMA方法流程图Fig. 2 Flow chart of ESKMA method下载:
全尺寸图片
记
${{\boldsymbol{M}}_{{\text{E}} \to {\text{C}}}}$ 为权重矩阵,${{\boldsymbol{b}}_{E \to C}}$ 为偏差向量,则第$j$ 个词对应头实体h和尾实体t的权重${\boldsymbol{a}}_{ij}^h$ 和${\boldsymbol{a}}_{ij}^t$ 有:$$ {\boldsymbol{a}}_{ij}^h = {\text{Softmax[}}{h_G} \cdot \tanh ({{\boldsymbol{M}}_{E \to C}}{w_{ij}} + {{\boldsymbol{b}}_{E \to C}})] $$ $$ {\boldsymbol{a}}_{ij}^t = {\text{Softmax[}}{h_G} \cdot \tanh ({{\boldsymbol{M}}_{E \to C}}{w_{ij}} + {{\boldsymbol{b}}_{E \to C}})] $$ 由此,获得第
$j$ 个词${w_{ij}}$ 的嵌入${z_{ij}}$ 和最终权重${a_{ij}}$ 为$$ {a_{ij}} = \frac{{a_{ij}^h + a_{ij}^t}}{2} $$ $$ {{\boldsymbol{z}}_{ij}} = {a_{ij}} \cdot {{\boldsymbol{g}}_{ij}} $$ 进而,根据每个词的最终嵌入向量
${{\boldsymbol{z}}_{ij}}$ ,获得句子${s_i}$ 的嵌入向量${{\boldsymbol{p}}_i}$ 。3.2 基于注意力机制的语义关系整合
由于
$\{ {s_1},{s_2}, \cdots ,{s_n}\}$ 中每个句子之间的语义信息可能存在差异,所以选用Transformer模型[42]学习句子之间的语义关系。在模型输入层,每个句子的嵌入向量${{\boldsymbol{p}}_i}$ 与词${w_{ij}}$ 在本句中的位置相叠加;通过Transformer模型,获得h和t在$\{ {s_1},{s_2}, \cdots ,{s_n}\}$ 中的语义关系,记为$[{r_{{s_1}}}{r_{{s_2}}} \cdots {r_{{s_n}}}]$ ,其中每个${r_{{s_j}}}$ 代表h和t之间的一种语义关系。基于关系嵌入
${r_{h,t}}$ 包含的结构信息,通过注意力机制“$G \to C$ ”,对上述语义关系加以增强。记${{\boldsymbol{M}}_{G \to C}}$ 为权重矩阵,${{\boldsymbol{b}}_{G \to C}}$ 为偏差向量,获得第$j$ 个句子对应语义${r_{{s_j}}}$ 的权重${{\boldsymbol{a}}_j}$ 为$$ {{\boldsymbol{a}}_j} ={\rm{Softmax}} [{r_{{s_j}}} \cdot \tanh ({{\boldsymbol{M}}_{G \to C}}{r_{{s_j}}} + {{\boldsymbol{b}}_{G \to C}})] $$ 进而,获得增强后的语义关系
${r_C}$ 为$$ {r_C} = \mathop \sum \limits_{j = 1}^n {a_j} \cdot {r_{{s_j}}} $$ 为便于模型训练,本文面向语义关系,构建了语义关系损失函数
$L_{G \rightarrow C}(s) $ ,记为$$ {L_{G \to C}}(s) = \sum\limits_{s \in \{ {s_1},{s_2}, \cdots ,{s_n}\} } {\sum\limits_{r' \ne r} {{{[\mu + {\psi _r}(s) - {\psi _{r'}}(s)]}_ + }} } $$ 式中:
$\mu $ 和${[x]_ + }$ 的定义与式(3)相同;${\psi _r}(s)$ 表示语义关系${r_C}$ 在向量空间与${r_G}$ 的距离函数。$$ {\psi _{r'}}(s) = \parallel {r_C} - {r_G}{\parallel _l} $$ 基于此,
${\psi _{r'}}(s)$ 表示随机选取知识图谱中任一关系,替换h和t对应关系r组成的负三元组在向量空间的距离函数。3.3 基于注意力机制的关系嵌入增强
为了丰富三元组中头实体h和尾实体t的关系嵌入
${r_{h,t}}$ 所包含的语义信息,构建从语义关系到关系嵌入的注意力机制,记为“$C \to G$ ”。假设三元组中存在m个实体对符合关系r,记为$\{ ({h_1},{t_1}), ({h_2},{t_2}), \cdots , ({h_m},{t_m})\}$ ,与这些实体对相应的关系嵌入记为$\{ {r_{{h_1},{t_1}}},{r_{{h_2},{t_2}}}, \cdots ,{r_{{h_m},{t_m}}}\}$ 。考虑到$\left\{r_{h_{1}, t_{1}},r_{h_{2}, t_{2}}, \cdots, r_{h_{m}, t_{m}}\right\}$ 与语义关系${r_C}$ 的关联程度可能不一致,采用注意力机制“$C \to G$ ”,引入语义关系$ r_{C} $ 丰富关系嵌入。记${{\boldsymbol{M}}_{C \to G}}$ 为权重矩阵,${{\boldsymbol{b}}_{C \to G}}$ 为偏差向量,获得$\{r_{h_{1}, t_{1}}, r_{h_{2}, t_{2}}, \cdots, r_{h_{m}, t_{m}}\}$ 中第j个关系嵌入${r_{{h_j},{t_j}}}$ 的权重bj为$$ {{\boldsymbol{b}}_j} = {\text{Softmax[}}{r_{{h_j}{t_j}}} + \tanh ({{\boldsymbol{M}}_{C \to G}}{r_C} + {{\boldsymbol{b}}_{C \to G}}){\text{]}} $$ 进而,获得增强后的关系嵌入记为
$ r_{k} $ 为$$ {r_k} = \mathop \sum \limits_{j = 1}^m {b_j} \cdot {r_{{h_j},{t_j}}} $$ 为便于模型训练,本文面向关系嵌入,构建了关系嵌入损失函数
${L_{C \to G}}(h,r,t)$ ,记为$$ \begin{gathered} {L_{C \to G}}(h,r,t) = \\ \mathop \sum\limits_{\scriptstyle{(h,r,t) \in \{ (h,r,t), \cdots ,({h_m},r,{t_m})\}}\atop \scriptstyle{{ (h',r,t') \notin \{ (h,r,t), \cdots ,({h_m},r,{t_m})\} }}} {[\mu + {\varphi _r}(h,t) - {\varphi _r}(h',t')]_ + } \end{gathered} $$ 式中:
$ \mu $ 和$ [x]_{+} $ 的定义与式(3)相同,$ \varphi_{r}(h, t) $ 表示关系嵌入$ r_{k} $ 在向量空间与$ r_{G} $ 的距离函数。$$ {\varphi _r}(h,t) = {\left\| {{r_k} - {r_G}} \right\|_l} $$ 基于此,
${\varphi _r}(h',t')$ 表示随机选取知识图谱中除$\left\{ {\left( {{h_1},{t_1}} \right),\left( {{h_2},{t_2}} \right), \cdots ,\left( {{h_m},{t_m}} \right)} \right\}$ 外的任一实体,替换头实体h或尾实体t组成的负三元组所对应的距离函数。基于语义关系
${r_C}$ 和三元组关系嵌入${r_k}$ 的损失函数${L_{G \to C}}(s)$ 和${L_{C \to G}}(h,r,t)$ ,借鉴门控机制[26]定义模型的损失函数如下:$$ L = {\text{argmin(}}\alpha {L_{G \to C}}(s) + (1 - \alpha ){L_{C \to G}}(h,r,t){\text{)}} $$ 式中
$\alpha \in [0,1]$ 用于调节两类损失函数的比重。4. 实验分析与比较
为验证所提方法的有效性,本文面向4个数据集,针对链路预测和三元组分类两类任务进行实验分析。所有实验基于TensorFlow框架,基于NVIDIA RTX 2060的GPU和Intel(R) i5-9400F的CPU环境下完成。
本文采用了FB15k[11]、FB15K-237[43]和WN11[21],以及MCMK数据集等4个数据集。其中,MCMK数据集融合了OpenKG中的“中文症状库”“医疗问答知识图谱”和其他中医典籍与中西医药典,其中的句子最多包括1458个词,平均词数为728,具有复杂和多源的特点,实体描述的语义差异显著。FB15k中的句子最多包含343个词、平均词数为69。FB15K-237是FB15k 的子集,它减少了部分重复关系,融合了部分实体。4个数据集的核心参数如表1所示。
表 1 数据集参数Table 1 Parameters of the datasets数据集 实体 关系 训练集 验证集 测试集 FB15k 14952 1346 483143 50001 59072 FB15K-237 14541 237 272116 17536 20467 WN11 38696 11 112581 2609 10544 MCMK 32187 24 12692 2716 4729 为充分对比本文所提方法性能,选取TEKE模型、Text-Graph模型、TransE模型、TransH模型、TransR模型、TransD模型和TransA 模型作为对比算法。本文所提ESKMA方法中,采用Word2Vec获得词嵌入
$ v_{ij} $ ;在模型训练中,采用随机梯度下降法[44]优化损失函数;为防止模型的过拟合,采用L2正则化。实验参数设置如表2所示。表 2 实验参数Table 2 Experimental parameters实验参数 取值 学习率 $\lambda $ {0.0001,0.001,0.01,0.1} Transformer模型层数 6 Transformer自注意力机制头数 12 边界参数 $\mu $ {0.5,1.0,1.5,2.0} Batch Size {64,128,256,512} Dropout系数 0.6 实体和关系的向量维度 $d$ {50,100,200} 损失函数权重 $\alpha $ {0.2,0.4,0.6,0.8} 4.1 参数敏感性分析
在ESKMA模型训练中,学习率
$\lambda $ 、边界参数$\mu $ 、向量维度$d$ 、损失函数权重$\alpha $ 和Batch Size对模型性能存在直接影响。因此,本节根据三元组分类的准确率对上述参数进行敏感性分析。面向FB15K、WN11和MCMK 3个数据集,学习率$\lambda $ 、边界参数$ \mu $ 、向量维度$ d $ 、损失函数权重$\alpha $ 和Batch Size分别采用表2所列参数取值范围,获得的算法分类效果如图3~7所示。 图 3 边界参数对算法性能的影响Fig. 3 The influence of margin to algorithm performance下载:
全尺寸图片
图 3 边界参数对算法性能的影响Fig. 3 The influence of margin to algorithm performance下载:
全尺寸图片
 图 4 学习率对算法性能的影响Fig. 4 The influence of learning rate to algorithm performance下载:
全尺寸图片
图 4 学习率对算法性能的影响Fig. 4 The influence of learning rate to algorithm performance下载:
全尺寸图片
 图 5 向量维度对算法性能的影响Fig. 5 The influence of embedding dimensions to algorithm performance下载:
全尺寸图片
图 5 向量维度对算法性能的影响Fig. 5 The influence of embedding dimensions to algorithm performance下载:
全尺寸图片
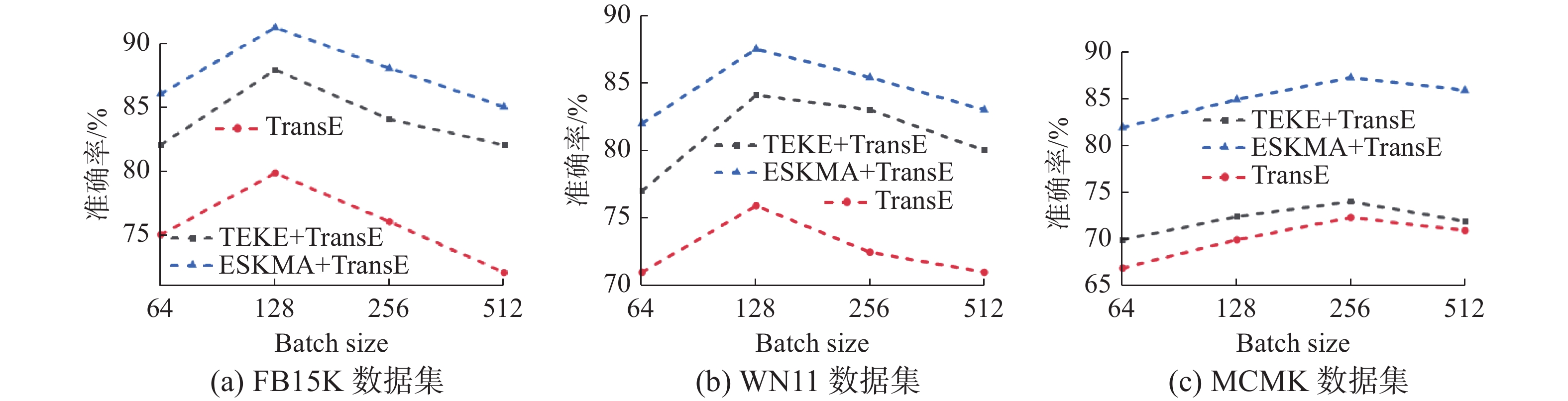 图 6 Batch Size对算法性能的影响Fig. 6 The influence of Batch Size to algorithm performance下载:
全尺寸图片
图 6 Batch Size对算法性能的影响Fig. 6 The influence of Batch Size to algorithm performance下载:
全尺寸图片
由实验结果可见,边界参数
$\mu $ 对数据集不敏感,均在$\mu = 1.0$ 时获得最佳三元组分类精度。面向不同数据集,取得最佳分类性能时的参数和相应的训练时间如下所示:FB15K和FB15K-237数据集:
$\lambda = 0.001$ 、$d = 100$ 、$\alpha = 0.4$ 、${\text{Batch Size = 128}}$ ;训练时间为138 min 和102 min。WN11数据集:$\lambda = 0.001$ 、$d = 200$ 、$\alpha = 0.6$ 、Batch Size = 128;训练时间为192 min。MCMK数据集:$\lambda = 0.01$ 、$ d=200 $ 、$\alpha = 0.6$ 、Batch Size = 256;训练时间为275 min。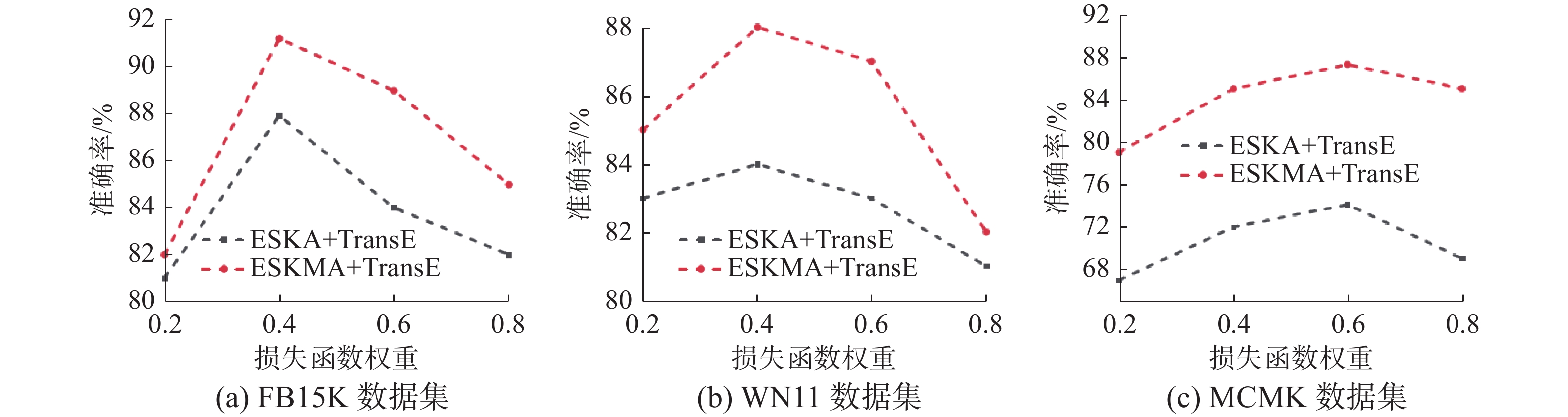 图 7 损失函数权重对算法性能的影响Fig. 7 The influence of loss function weight to algorithm performance下载:
全尺寸图片
图 7 损失函数权重对算法性能的影响Fig. 7 The influence of loss function weight to algorithm performance下载:
全尺寸图片
4.2 链路预测
链路预测用于预测两个实体之间缺失的关系,即预测三元组
$(h,r,t)$ 。本文采用平均排序 (mean rank, MR)和Hits@10两个评价指标用于评价链路预测准确性。较低的MR值或较高的Hits@10意味着模型的链路预测性能更好。平均排序表示获得正确关系的三元组排名平均值。记T为三元组集合,|T|为三元组集合规模,ki表示第i个三元组的链路预测排名,则有:
$$ {\text{MR}} = \frac{1}{{|T|}}\mathop \sum \limits_{i = 1}^{\left| T \right|} {k_i} $$ Hits@10表示前10个预测结果中获得正确关系的三元组比例。定义
${\rm I}{\rm I}(\cdot) $ 为indicator函数,则有:$$ {\text{Hits}}@10 = \frac{1}{{|T|}}\mathop \sum \limits_{i = 1}^{\left| T \right|} {\rm I}{\rm I}({k_i} \leqslant 10) $$ 表3给出了所有对比算法的链路预测结果,最优预测结果加粗表示。其中,ESKMA+TransE、ESKMA+TransH和ESKMA+ TransR分别代表将本文所提多层注意力机制与相应的结构嵌入模型相结合;ESKA+ TransE、ESKA+ TransH和ESKA+ TransR在上述方法的基础上,删除了多层注意力机制。此外,为了更加直观地对所提模型和对比模型的实验结果加以对比,基于TransE、TransH和TransR 3个基础模型,所有对比方法的Hits@10和MR指数如图8和图9所示。
表 3 链路预测实验结果Table 3 The prediction results of relationships模型 FB15k FB15K-237 MCMK MR Hits@10 MR Hits@10 MR Hits@10 TransD 91 77.3 244 48.0 462 35.0 TransH 84 58.5 348 45.2 451 42.7 TransA 74 80.4 451 49.1 437 38.0 TransR 78 65.5 252 47.8 467 43.6 TransE 125 47.1 347 46.5 412 38.6 TEKE+ TransE 79 67.6 171 48.9 367 45.0 Text-Graph+ TransE 72 76.3 169 48.3 287 46.5 ESKA+ TransE 75 70.8 174 48.5 374 42.8 ESKMA+ TransE 69 82.5 151 51.6 214 56.3 TEKE+ TransH 75 70.4 259 48.8 386 62.0 ESKA+ TransH 77 76.0 312 43.7 423 54 ESKMA+ TransH 70 82.5 260 52.7 274 85.0 TEKE+ TransR 79 68.5 233 48.1 365 59.8 续表 3 模型 FB15k FB15K-237 MCMK MR Hits@10 MR Hits@10 MR Hits@10 ESKA+ TransR 74 73.4 217 45.7 437 40.5 ESKMA+ TransR 68 81.0 187 54.5 292 65.4  图 8 面向不同基础模型的Hits@10值Fig. 8 Hits@10 values for different base models下载:
全尺寸图片
图 8 面向不同基础模型的Hits@10值Fig. 8 Hits@10 values for different base models下载:
全尺寸图片
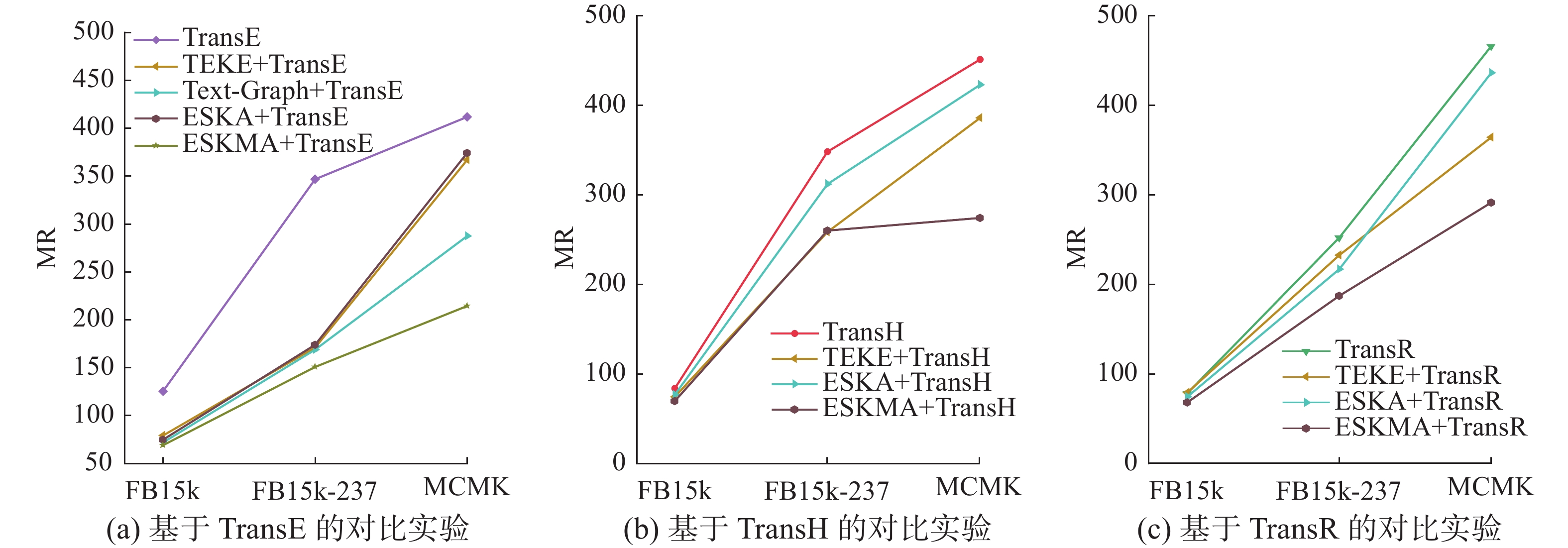 图 9 面向不同基础模型的MR值Fig. 9 MR values for different base models下载:
全尺寸图片
图 9 面向不同基础模型的MR值Fig. 9 MR values for different base models下载:
全尺寸图片
由ESKMA模型的链路预测实验结果可见,所提模型在3个数据集上都具有最小的MR指数和最大的Hits@10。特别是,面向FB15K数据集,ESKMA+ TransE模型的预测结果比TransE模型更准确,评价指标MR降低了45%,Hits@10增加了42%,说明实体描述内的语义信息可以有效提高知识表示学习的质量。此外,ESKMA+TransE模型的预测结果比TEKE+TransE模型更准确,评价指标MR降低了13%,Hits@10增加了18%,说明ESKMA模型比同样结合实体描述的知识表示学习模型具有更优性能。面向FB15K-237和MCMK数据集,ESKMA+TransR模型的Hits@10相比于TEKE+TransR模型分别提升了8%和37%。可见,ESKMA模型更适合处理包含复杂实体描述的数据集。
对比分析ESKA模型的链路预测实验结果,可知ESKA+TransH模型在3个数据集上均比ESKMA+TransH模型取得的预测精度差,表明多层注意力机制可以更好地获取实体描述包含的语义信息,并与结构嵌入相结合。特别是,面向FB15k-237、ESKA+TransE模型的HITS@10相比TransR提升了12%;而面向MCMK数据集,其HITS@10比TransR模型下降了7%,这表明多层注意力机制的缺失,会降低知识表示学习的质量。
4.3 三元组分类
三元组分类是一个典型的二分类任务,旨在判断给定的一个三元组
$ (h, r, t) $ 是否正确。针对该分类任务,本文设置了特定的关系阈值$ \sigma $ 。如果三元组$ (h, r, t) $ 的距离得分小于阈值$ \sigma $ ,则认为该三元组是正确的;否则,是错误的。实验中,选取在验证集上取得最大化分类准确率的阈值$ \sigma $ ,其余参数选取与链路预测任务相同的取值,通过获得正确关系的三元组比例评价三元组分类的准确性。图10和表4给出了所有对比算法的三元组分类结果,最优分类结果加粗表示。显然,ESKMA模型在3个数据集上都具有最高的三元组分类准确率。特别是,面向WN11数据集,ESKMA+ TransH模型的准确率比TransH模型提高了9.7%,比TEKE+ TransH模型提高了2.9%。此外,ESKMA模型的准确率比ESKA模型也有所提高。比如,ESKMA+TransR模型在FB15k数据集上的三元组分类精度比ESKA+TransE模型提高了3.8%,表明多层注意力机制在知识表示学习中具有重要作用。此外,结合实体描述的TEKE、ESKA和ESKMA方法在3个数据集上普遍比只采用结构信息的TransE等模型具有更高的三元组分类准确率,并且在MCMK数据集上提升最为明显,证明了实体描述可以有效提高知识表示学习的质量。
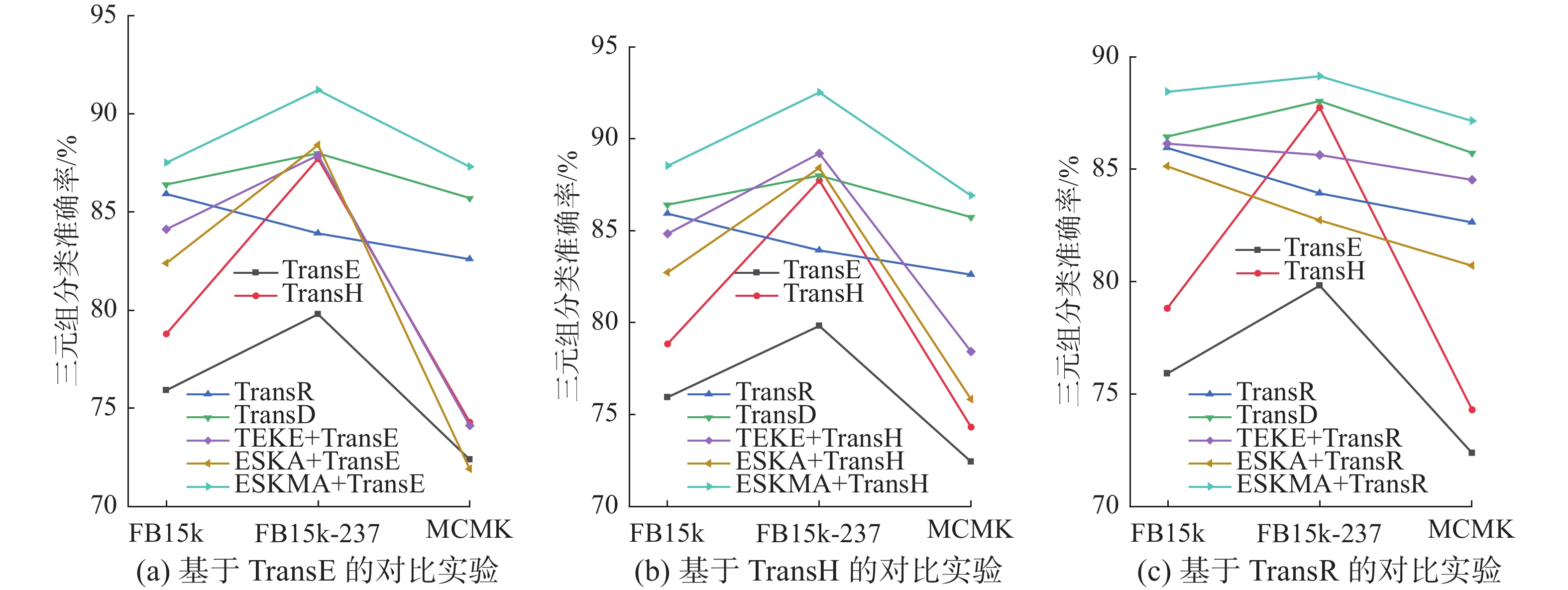 图 10 三元组分类实验结果Fig. 10 Three-tuple classification experimental result下载:
全尺寸图片
表 4 三元组分类实验结果Table 4 The results of triad classification experiment
图 10 三元组分类实验结果Fig. 10 Three-tuple classification experimental result下载:
全尺寸图片
表 4 三元组分类实验结果Table 4 The results of triad classification experiment% 模型 WN11 FB15K MCMK TransE 75.9 79.8 72.4 TransH 78.8 87.7 74.3 TransR 85.9 83.9 82.6 TransD 86.4 88.0 85.7 TEKE+ TransE 84.1 87.9 74.1 ESKA+ TransE 82.4 88.4 71.9 ESKMA+ TransE 87.5 91.2 87.3 TEKE+ TransH 84.8 89.2 78.4 ESKA+ TransH 82.7 88.4 75.8 ESKMA+ TransH 88.5 92.5 86.9 TEKE+ TransR 86.1 85.6 84.5 ESKA+ TransR 85.1 82.7 80.7 ESKMA+ TransR 88.4 89.1 87.1 5. 结束语
知识图谱包含的实体来源广泛,对应的实体描述包含丰富的语义信息,可以用来提升知识表示学习的质量。但是,这些语义信息难以准确获取并与知识表示学习相结合。因此,本文提出ESKMA方法,采用多层注意力机制,使用实体的结构嵌入增强实体描述中的语义表达,再通过Transformer模型整合复杂实体描述的语义关系,并利用语义关系对关系嵌入加以增强。面对4个数据集,ESKMA模型在链路预测和三元组分类任务上比只考虑结构信息的知识表示学习模型TransE、TransH、TransR、TransD和TransA以及同样结合实体描述的最新知识表示学习模型TEKE和Text-Graph都具有更佳的性能。此外,面向MCMK数据集,所提模型对未利用实体描述的知识表示学习质量的提高比TEKE和Text-Graph模型更为明显。可见,ESKMA模型在处理常规数据集时较主流模型更为优秀,而在处理具有复杂实体描述信息的知识图谱数据集时具有更大优势。
-
图 1 ESKMA模型设计思路
Fig. 1 Design idea of ESKMA
下载:
全尺寸图片
图 2 ESKMA方法流程图
Fig. 2 Flow chart of ESKMA method
下载:
全尺寸图片
图 3 边界参数对算法性能的影响
Fig. 3 The influence of margin to algorithm performance
下载:
全尺寸图片
图 4 学习率对算法性能的影响
Fig. 4 The influence of learning rate to algorithm performance
下载:
全尺寸图片
图 5 向量维度对算法性能的影响
Fig. 5 The influence of embedding dimensions to algorithm performance
下载:
全尺寸图片
图 6 Batch Size对算法性能的影响
Fig. 6 The influence of Batch Size to algorithm performance
下载:
全尺寸图片
图 7 损失函数权重对算法性能的影响
Fig. 7 The influence of loss function weight to algorithm performance
下载:
全尺寸图片
图 8 面向不同基础模型的Hits@10值
Fig. 8 Hits@10 values for different base models
下载:
全尺寸图片
图 9 面向不同基础模型的MR值
Fig. 9 MR values for different base models
下载:
全尺寸图片
图 10 三元组分类实验结果
Fig. 10 Three-tuple classification experimental result
下载:
全尺寸图片
表 1 数据集参数
Table 1 Parameters of the datasets
数据集 实体 关系 训练集 验证集 测试集 FB15k 14952 1346 483143 50001 59072 FB15K-237 14541 237 272116 17536 20467 WN11 38696 11 112581 2609 10544 MCMK 32187 24 12692 2716 4729 表 2 实验参数
Table 2 Experimental parameters
实验参数 取值 学习率 $\lambda $ {0.0001,0.001,0.01,0.1} Transformer模型层数 6 Transformer自注意力机制头数 12 边界参数 $\mu $ {0.5,1.0,1.5,2.0} Batch Size {64,128,256,512} Dropout系数 0.6 实体和关系的向量维度 $d$ {50,100,200} 损失函数权重 $\alpha $ {0.2,0.4,0.6,0.8} 表 3 链路预测实验结果
Table 3 The prediction results of relationships
模型 FB15k FB15K-237 MCMK MR Hits@10 MR Hits@10 MR Hits@10 TransD 91 77.3 244 48.0 462 35.0 TransH 84 58.5 348 45.2 451 42.7 TransA 74 80.4 451 49.1 437 38.0 TransR 78 65.5 252 47.8 467 43.6 TransE 125 47.1 347 46.5 412 38.6 TEKE+ TransE 79 67.6 171 48.9 367 45.0 Text-Graph+ TransE 72 76.3 169 48.3 287 46.5 ESKA+ TransE 75 70.8 174 48.5 374 42.8 ESKMA+ TransE 69 82.5 151 51.6 214 56.3 TEKE+ TransH 75 70.4 259 48.8 386 62.0 ESKA+ TransH 77 76.0 312 43.7 423 54 ESKMA+ TransH 70 82.5 260 52.7 274 85.0 TEKE+ TransR 79 68.5 233 48.1 365 59.8 续表 3 模型 FB15k FB15K-237 MCMK MR Hits@10 MR Hits@10 MR Hits@10 ESKA+ TransR 74 73.4 217 45.7 437 40.5 ESKMA+ TransR 68 81.0 187 54.5 292 65.4 表 4 三元组分类实验结果
Table 4 The results of triad classification experiment
% 模型 WN11 FB15K MCMK TransE 75.9 79.8 72.4 TransH 78.8 87.7 74.3 TransR 85.9 83.9 82.6 TransD 86.4 88.0 85.7 TEKE+ TransE 84.1 87.9 74.1 ESKA+ TransE 82.4 88.4 71.9 ESKMA+ TransE 87.5 91.2 87.3 TEKE+ TransH 84.8 89.2 78.4 ESKA+ TransH 82.7 88.4 75.8 ESKMA+ TransH 88.5 92.5 86.9 TEKE+ TransR 86.1 85.6 84.5 ESKA+ TransR 85.1 82.7 80.7 ESKMA+ TransR 88.4 89.1 87.1 -
[1] BOLLACKER K, EVANS C, PARITOSH P, et al. Freebase: a collaboratively created graph database for structuring human knowledge[C]//Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data. Vancouver: ACM, 2008: 1247–1250. [2] MILLER G A. WordNet[J]. Communications of the ACM, 1995, 38(11): 39–41. doi: 10.1145/219717.219748 [3] SUCHANEK F M, KASNECI G, WEIKUM G. Yago: a core of semantic knowledge[C]//Proceedings of the 16th International Conference on World Wide Web. Banff: ACM, 2007: 697–706. [4] 徐有为, 张宏军, 程恺, 等. 知识图谱嵌入研究综述[J]. 计算机工程与应用, 2022, 58(9): 30–50. doi: 10.3778/j.issn.1002-8331.2111-0248 XU Youwei, ZHANG Hongjun, CHENG Kai, et al. Comprehensive survey on knowledge graph embedding[J]. Computer engineering and applications, 2022, 58(9): 30–50. doi: 10.3778/j.issn.1002-8331.2111-0248 [5] 张晓林. 机构知识库的发展趋势与挑战[J]. 现代图书情报技术, 2014(2): 1–7. ZHANG Xiaolin. Trends and challenges for institutional repositories[J]. New technology of library and information service, 2014(2): 1–7. [6] LEHMANN J, ISELE R, JAKOB M, et al. DBpedia–A large-scale, multilingual knowledge base extracted from Wikipedia[J]. Semantic web, 2015, 6(2): 167–195. doi: 10.3233/SW-140134 [7] HACHEY B, RADFORD W, NOTHMAN J, et al. Evaluating entity linking with wikipedia[J]. Artificial intelligence, 2013, 194: 130–150. doi: 10.1016/j.artint.2012.04.005 [8] 张明星, 张骁雄, 刘姗姗, 等. 利用知识图谱的推荐系统研究综述[J]. 计算机工程与应用, 2023, 59(4): 30–42. doi: 10.3778/j.issn.1002-8331.2209-0033 ZHANG Mingxing, ZHANG Xiaoxiong, LIU Shanshan, et al. Review of recommendation systems using knowledge graph[J]. Computer engineering and applications, 2023, 59(4): 30–42. doi: 10.3778/j.issn.1002-8331.2209-0033 [9] 王智悦, 于清, 王楠, 等. 基于知识图谱的智能问答研究综述[J]. 计算机工程与应用, 2020, 56(23): 1–11. doi: 10.3778/j.issn.1002-8331.2004-0370 WANG Zhiyue, YU Qing, WANG Nan, et al. Survey of intelligent question answering research based on knowledge graph[J]. Computer engineering and applications, 2020, 56(23): 1–11. doi: 10.3778/j.issn.1002-8331.2004-0370 [10] LIU Zhiyuan, SUN Maosong, LIN Yankai, et al. Knowledge representation learning: a review[J]. Journal of computer research and development, 2016, 53(2): 247–261. [11] BORDES A, USUNIER N, GARCIA-DURÁN A, et al. Translating embeddings for modeling multi-relational data[C]//Proceedings of the 26th International Conference on Neural Information Processing Systems-Volume 2. Lake Tahoe: ACM, 2013: 2787–2795. [12] MIKOLOV T, SUTSKEVER I, CHEN Kai, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2. Lake Tahoe: ACM, 2013: 3111–3119. [13] WANG Zhen, ZHANG Jianwen, FENG Jianlin, et al. Knowledge graph embedding by translating on hyperplanes[C]//Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence. Québec City: ACM, 2014: 1112–1119. [14] LIN Yankai, LIU Zhiyuan, SUN Maosong, et al. Learning entity and relation embeddings for knowledge graph completion[C]//Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence. Austin: ACM, 2015: 2181–2187. [15] JI Guoliang, HE Shizhu, XU Liheng, et al. Knowledge graph embedding via dynamic mapping matrix[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing: Association for Computational Linguistics, 2015: 687−696. [16] JI Guoliang, LIU Kang, HE Shizhu, et al. Knowledge graph completion with adaptive sparse transfer matrix[C]//Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. Phoenix: ACM, 2016: 985–991. [17] XIAO Han, HUANG Minlie, HAO Yu, et al. TransA: an adaptive approach for knowledge graph embedding[EB/OL]. (2015−09−18)[2022−04−22].https://arxiv.org/abs/1509.05490. [18] HE Shizhu, LIU Kang, JI Guoliang, et al. Learning to represent knowledge graphs with Gaussian embedding[C]//Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. Melbourne: ACM, 2015: 623–632. [19] XIAO Han, HUANG Minlie, ZHU Xiaoyan. TransG: a generative model for knowledge graph embedding[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: Association for Computational Linguistics, 2016: 2316−2325. [20] 饶官军, 古天龙, 常亮, 等. 基于相似性负采样的知识图谱嵌入[J]. 智能系统学报, 2020, 15(2): 218–226. doi: 10.11992/tis.201811022 RAO Guanjun, GU Tianlong, CHANG Liang, et al. Knowledge graph embedding based on similarity negative sampling[J]. CAAI transactions on intelligent systems, 2020, 15(2): 218–226. doi: 10.11992/tis.201811022 [21] SOCHER R, CHEN Danqi, MANNING C D, et al. Reasoning with neural tensor networks for knowledge base completion[C]//Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 1. New York: ACM, 2013: 926–934. [22] SANTOS C N D, XIANG Bing, ZHOU Bowen. Classifying relations by ranking with convolutional neural networks[EB/OL]. (2015−04−24)[2022−04−22].https://arxiv.org/abs/1504.06580. [23] CHEN Yahui. Convolutional neural network for sentence classification[D]. Master's thesis: University of Waterloo, 2015. [24] ZHANG Dongxu, YUAN Bin, WANG Dong, et al. Joint semantic relevance learning with text data and graph knowledge[C]//Proceedings of the 3rd Workshop on Continuous Vector Space Models and their Compositionality. Beijing: Association for Computational Linguistics, 2015: 32−40. [25] LE Q V, MIKOLOV T. Distributed representations of sentences and documents[EB/OL]. (2014−05−16)[2022−04−22].https://arxiv.org/abs/1405.4053. [26] XU JIACHENG, CHEN KAN, QIU XIPENG, et al. Knowledge graph representation with jointly structural and textual encoding[EB/OL]. (2016−11−26)[2022−04−22].https://arxiv.org/abs/1611.08661. [27] XIE Ruobing, LIU Zhiyuan, JIA Jia, et al. Representation learning of knowledge graphs with entity descriptions[C]//Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. Phoenix: ACM, 2016: 2659–2665. [28] MIKOLOV T, CHEN KAI, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013−01−16)[2022−04−22].https://arxiv.org/abs/1301.3781. [29] WANG Zhigang, LI Juanzi. Text-enhanced representation learning for knowledge graph[C]//Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence. New York: ACM, 2016: 1293–1299. [30] WANG Peng, ZHOU Jing, LIU Yuzhang, et al. TransET: knowledge graph embedding with entity types[J]. Electronics, 2021, 10(12): 1407. doi: 10.3390/electronics10121407 [31] HU Linmei, ZHANG Mengmei, LI Shaohua, et al. Text-graph enhanced knowledge graph representation learning[J]. Frontiers in artificial intelligence, 2021, 4: 697856. doi: 10.3389/frai.2021.697856 [32] JI Zizheng, LEI Zhengchao, SHEN Tingting, et al. Joint representations of knowledge graphs and textual information via reference sentences[J]. IEICE transactions on information and systems, 2020, E103.D(6): 1362–1370. doi: 10.1587/transinf.2019EDP7229 [33] CHEN Wenrui, HONG Dongpao, ZHENG Chao. Learning knowledge graph embedding with entity descriptions based on LSTM networks[C]//2020 IEEE International Symposium on Product Compliance Engineering-Asia. Chongqing: IEEE, 2021: 1−7. [34] ZHAO Feng, XU Tao, JIN L, et al. Convolutional network embedding of text-enhanced representation for knowledge graph completion[J]. IEEE Internet of Things journal, 2021, 8(23): 16758–16769. doi: 10.1109/JIOT.2020.3039750 [35] WU Jiajun, LI Bohan, JI Ye, et al. Text-enhanced knowledge graph representation model in hyperbolic space[C]//International Conference on Advanced Data Mining and Applications. Cham: Springer, 2022: 137−149. [36] DO P, PHAM P. W-KG2Vec: a weighted text-enhanced meta-path-based knowledge graph embedding for similarity search[J]. Neural computing and applications, 2021, 33(23): 16533–16555. doi: 10.1007/s00521-021-06252-8 [37] ZHENG Wenbo, YAN Lan, GOU Chao, et al. Pay attention to doctor-patient dialogues: multi-modal knowledge graph attention image-text embedding for COVID-19 diagnosis[J]. Information fusion, 2021, 75: 168–185. doi: 10.1016/j.inffus.2021.05.015 [38] JIANG Tingting, WANG Hao, LUO Xiangfeng, et al. MIFAS: Multi-sourceheterogeneous information fusion with adaptive importance sampling for link prediction[J]. Expert systems, 2022, 39(4): e12888. [39] CHEN Junfan, XU Jie, BO Manhui, et al. Augmenting embedding projection with entity descriptions for knowledge graph completion[J]. IEEE access, 2021, 9: 159955–159964. doi: 10.1109/ACCESS.2021.3132071 [40] CHENG Jingwei, ZHANG Fu, YANG Zhi. Knowledge graph representation learning with multi-scale capsule-based embedding model incorporating entity descriptions[J]. IEEE acscess, 2020, 8: 203028–203038. doi: 10.1109/ACCESS.2020.3035636 [41] WANG Yashen, ZHANG Huanhuan, LI Yifeng, et al. Simplified representation learning model based on parameter-sharing for knowledge graph completion[C]// China Conference on Information Retrieval. Cham: Springer, 2019: 67−78. [42] DEVLIN J, CHANG MING-WEI, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2018−10−11)[2022−04−22]. https://arxiv.org/abs/1810.04805. [43] TOUTANOVA K, CHEN Danqi. Observed versus latent features for knowledge base and text inference[C]//Proceedings of the 3rd Workshop on Continuous Vector Space Models and their Compositionality. Beijing: Association for Computational Linguistics, 2015: 57−66. [44] BOTTOU L. Large-scale machine learning with stochastic gradient descent[C]//Proceedings of COMPSTAT’2010. Paris: SpringerLink, 2010: 177−186.





















































































































































