
Hyperspectral image classification based on hybrid convolutional neural network with triplet attention
-
摘要: 针对高光谱图像光谱维度高、现有网络无法提供深度级的多层次特征,从而影响分类精度和速度的问题。首先采用核主成分分析对高光谱图像进行降维,使降维后的数据具有最佳区分度,提出了一种基于混合卷积与三重注意力的卷积神经网络(hybrid convolutional neural network with triplet attention, HCTA-Net)模型,该模型设计了一种基于三维、二维和一维卷积的混合卷积神经网络,通过不同维度卷积神经网络的融合,提取高光谱图像精细的光谱–空间联合特征。在二维卷积中加入深度可分离卷积,减少了模型参数,同时引入三重注意力机制,使用三分支结构实现跨维度信息交互,抑制无用的特征信息。在Indian Pines、Salinas和Pavia University数据集上的实验结果表明,本文提出的模型优于其他对比方法,总体分类精度分别达到了99.16%、99.87%和99.76%。Abstract: To solve the problems of a high spectral dimension of hyperspectral images and the failure of the existing network to provide multilevel features at the depth level, which affects the classification accuracy and speed, the kernel principal component analysis is used to reduce the dimensionality of hyperspectral images to have the best data differentiation after dimensionality reduction, and a hybrid convolutional neural network with triplet attention (HCTA-Net) model is proposed to design a hybrid model based on 3D, 2D, and 1D CNN to extract the fine spectral–spatial joint features through the fusion of different dimension convolutions. The model also adds depthwise separable convolution into the 2D-CNN to reduce the model parameters and simultaneously introduces a triplet attention mechanism, which uses a three-branch structure to achieve cross-dimensional information interaction to inhibit useless feature information. Experimental results on the Indian Pines, Salinas, and Pavia University datasets show that the proposed model is superior to other comparison methods, and the overall classification accuracy reaches 99.16%, 99.87, and 99.76%, respectively.
-
高光谱图像(hyperspectral images, HSI)是由一维光谱特征和二维空间信息组成的含有上百通道且波段连续的三维图像,被广泛应用于国防安全、海洋勘探[1]及地物分类[2]等领域。但由于HSI波段多、空间分辨率低和Hughes现象[3]等现实问题,使HSI分类问题仍面临很大的挑战,因此研究一个高效提升HSI分类性能的模型具有重要的应用价值。
HSI分类需要同时考虑光谱和空间特征信息。传统的HSI分类方法主要侧重于研究连续光谱,利用可区分的光谱特征对数据进行分类,典型的分类器包括K近邻(K-nearest neighbor algorithm, KNN)[4]、支持向量机(support vector machine, SVM)[5]、字典学习[6]等,其中KNN分类器需要大量的训练样本,SVM虽能缓解Hughes现象,但分类精度不佳,因此对于高维小样本的HSI数据集,这些分类方法效果往往并不理想。研究表明,空间信息和光谱特征的互补决策融合,有助于提高分类性能[7],于是Fauvel等[8]提出集成决策树、Zhong等[9]提出深度信念网络的分类方法用于决策融合,但由于特征表达能力有限,仍不能完全表示光谱–空间信息的丰富度,难以有效提高分类水平。
近年来,深度学习凭借其优异的特征提取能力,被广泛用于HSI分类领域[10]。Hu等[11]首次将1D-CNN应用于HSI分类,分类结果略优于传统的分类方法,但会造成空间特征丢失的问题。Xu等[12]提出一种双支CNN模型,将并行的2D-CNN与1D-CNN用于提取光谱–空间特征,通过简单的融合,提高了分类性能,但未考虑光谱–空间特征间的关联性。针对这一问题,Zhang等[13]提出一种3D密集连接网络SSDANet,直接对三维数据进行光谱–空间特征提取,充分发挥了HSI“图谱合一”的特点,但随着模型深度的加深,细节特征将逐渐丢失,还带来了模型复杂、计算量大等问题。为此,Guo等[14]提出一种深度协同网络CACNN,将3D-CNN与2D-CNN用一种深度多层特征融合策略相结合用于HSI分类,得到较为满意的结果,但对光谱–空间相关特征仍不够关注。
此外,在提取特征进行分类时,研究者受人类视觉机制的启发,提出用注意力机制来抑制冗余信息,聚焦特定特征并分配相应权重,从而提高模型的分类性能。Hu等[15]提出了压缩激活网络(squeeze and excitation network, SENet),是第一个通过对通道特征进行加权建模的注意力机制。在此基础上,为了将空间与通道两个维度的特征结合起来重新进行校准,Woo等[16]提出了卷积块注意力模块(convolutional block attention module, CBAM),对输入的特征进行约束增强处理。另外,基于注意力机制的CNN模型在HSI分类领域逐渐取得了较为显著的成果。如Fang等[17]提出了单注意力网络MSDN-SA,提高了光谱波段间的相关性。为进一步加强空间信息特征,Roy等[18]在A2S2K-ResNet网络中引入基于注意力的自适应光谱–空间核模块,实现了光谱–空间信息的联合挖掘,增强了网络结构的特征表达能力。Ahmad等[19]将三分支注意力融合块引入AfNet结构,自适应地强调重要特征,显著抑制了冗余和无效信息。
针对现有高光谱分类模型较复杂、未充分考虑光谱–空间联合特征,无法提供深度级的多层次特征等问题,本文提出一种基于混合卷积与三重注意力网络模型(hybrid convolution neural network with triplet attention, HCTA-Net),主要贡献包括以下4个方面:
1)设计了一个由3D-CNN、改进的2D-CNN和1D-CNN组成的混合卷积神经网络结构,充分利用光谱–空间域与深空间域互补特征,提升整个网络分类性能。
2)在2D-CNN模块中加入深度可分离卷积(depthwise separable convolution, DSC)[20],降低了卷积的参数量和计算量。
3)引入三分支注意力融合块Triplet Attention[21],将注意力聚焦重要区域,以捕获更重要的光谱–空间特征作为后续网络的输入。
4)利用3个评价指标对Indian Pines、Salinas和Pavia University 3个公开的HSI数据集的分类结果进行综合评估,实验结果表明本文方法均优于比较方法。
1. HCTA-Net模型设计
本文提出的基于混合卷积模块与三重注意力机制的高光谱图像分类方法HCTA-Net,整体流程如图1所示,主要由三部分组成:数据降维、分类识别网络和结果预测。首先,采用核主成分分析方法(kernel principal component analysis, KPCA)[22]将维度为C×H×W(C为波段数,W、H分别为单个波段的高和宽)的原始HSI数据降维到B个波段,有效地消除数据冗余并保留主要空谱信息,减少后续图像处理的时间和空间复杂度。然后选取大小为K×K×B的三维图像块输入到分类识别网络中,其中K为窗口大小。其次,分类识别网络包括依次连接的3D-CNN、Triplet Attention、改进后的2D-CNN和1D-CNN模块构成的混合卷积网络,提取更强的频谱空间信息和重要的通道特征用于分类识别,最后使用softmax分类器得到最终的预测分类结果。
 图 1 HCTA-Net模型结构Fig. 1 HCTA-Net structure diagram
图 1 HCTA-Net模型结构Fig. 1 HCTA-Net structure diagram 下载:
全尺寸图片
下载:
全尺寸图片
1.1 混合卷积神经网络模块
1.1.1 3D-CNN模块
研究表明,3D-CNN可同时对HSI数据进行光谱特征和空间特征的联合提取,但随着网络深度的增加,会带来细节特征逐渐丢失,计算量大等问题。因此本文采用三层的3D-CNN对HSI数据进行特征信息提取,图2给出了三维卷积的示意图。
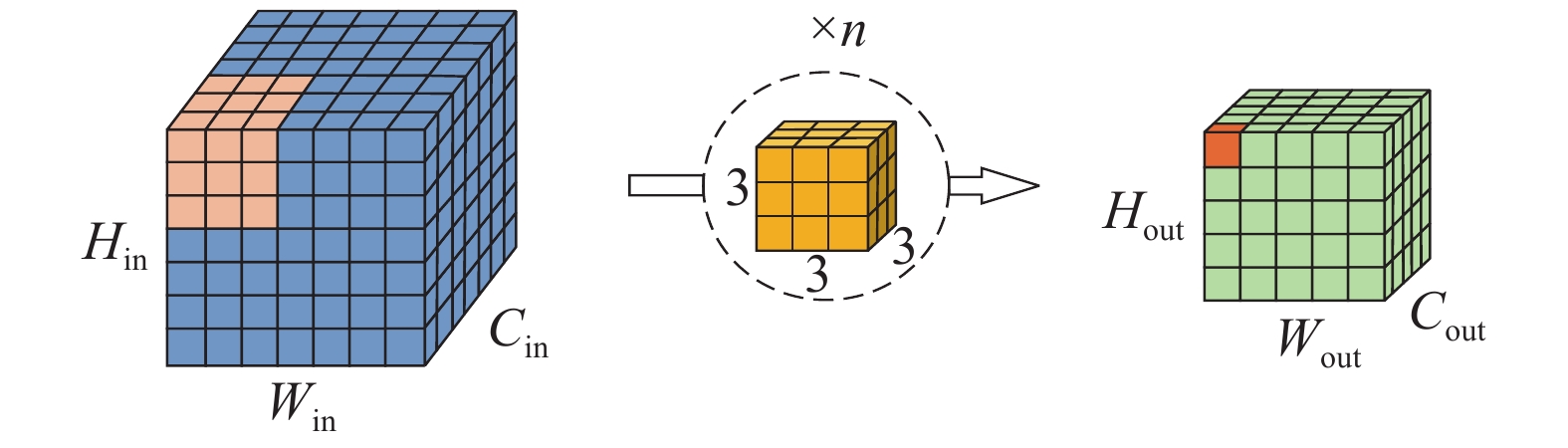 图 2 三维卷积示意Fig. 2 3D convolution diagram下载:
全尺寸图片
图 2 三维卷积示意Fig. 2 3D convolution diagram下载:
全尺寸图片
为进一步理解3D-CNN特征提取原理,将位置为(x,y,z)的神经元的激活值
$ {{v}}_{{i,j}}^{{x,y,z}} $ 公式表示为$$ {{v}}_{{i,j}}^{{x,y,}{z}}={F}\left({{b}}_{{i,j}}+\sum _{{\tau }}\sum _{{ \lambda =0}}^{{{T}}_{{i}}{-1}}\sum _{{\rho =0}}^{{{P}}_{{i}}{-1}}\sum _{{r=0}}^{{{R}}_{{i}}{-1}}{{ \omega }}_{{i,j,\tau }}^{{ \lambda ,\rho,r}}{{v}}_{{i-1,\tau }}^{{x+ \lambda ,y+\rho,z+r}}\right){}$$ (1) 式中:激活函数为
$ {F(}{\cdot}{)} $ ,$ {τ} $ 表示当前第$ i $ 层与第$ {i}{-}{1} $ 层的索引;卷积核的宽、高与光谱维度分别为$ {{T}}_{{i}} $ 、$ {{P}}_{{i}} $ 和$ {{R}}_{{i}} $ ;位置(${ \lambda ,\rho,}{r}$ )连接到第${\tau}$ 个特征值的权重用${{ \omega }}_{{i,j,\tau}}^{{ \lambda ,\rho,}{r}}$ 表示;第$ i-1 $ 层中第$ {τ} $ 个特征图位置为(${x+ \lambda ,y+\rho}{)}$ 的值可表示为${{v}}_{{i-1,\tau}}^{{x+ \lambda ,y+\rho,z+r}}$ ;$ {{b}}_{{i,j}} $ 表示偏置。1.1.2 2D-CNN模块
2D-CNN模块沿着空间维进行操作并加强HSI的局部空间特征。因此,通过上述3D-CNN模块获取到联合的光谱–空间特征后,为进一步增强HSI的局部空间特征信息,本文在3D-CNN基础上经过一层2D-CNN模块,图3给出了二维卷积的示意图。
 图 3 二维卷积示意Fig. 3 2D convolution diagram下载:
全尺寸图片
图 3 二维卷积示意Fig. 3 2D convolution diagram下载:
全尺寸图片
在第
$ {i} $ 层第$ {j} $ 个特征图上,空间位置为$ {(}{x,y)} $ 的神经元的值$ {{v}}_{{i,j}}^{{x,y}} $ ,公式表示为$$ {{v}}_{{i,j}}^{{x,y}}={F}\left({{b}}_{{i,j}}+\sum _{\tau }\sum _{\lambda {=0}}^{{{T}}_{{i}}{-1}}\sum _{\rho {=0}}^{{{P}}_{{i}}{-1}}{{ \omega }}_{{i,j,\tau}}^{{ \lambda ,\rho}}{{v}}_{{i-1,\tau}}^{{x+ \lambda ,y+\rho}}\right){}$$ (2) 式中:激活函数为
${F(}{\cdot}{)}$ ;${\tau}$ 表示当前第$ i $ 层与第$ {i}{-}{1} $ 层的索引;$ {{T}}_{{i}} $ 、$ {{P}}_{{i}} $ 分别为卷积核的宽和高;位置(${ \lambda ,\rho}$ )连接到第${\tau}$ 个特征值的权重用${{ \omega }}_{{i,j,\tau}}^{{ \lambda ,\rho}}$ 表示;第$ i $ −1层中第${\tau}$ 个特征图位置为(${x+ \lambda ,y+\rho}{)}$ 的值可表示为${{v}}_{{i-1,\tau}}^{{x+ \lambda ,y+\rho}}$ ;$ {{b}}_{{i,j}} $ 为第$ {i} $ 层第$ {j} $ 个特征图的偏置参数。1.1.3 1D-CNN模块
为进一步增强光谱特征,本文在3D-CNN与2D-CNN模块基础上,再经过一层1D-CNN模块,通过不同维度CNN的融合,充分提取了HSI精细的光谱–空间联合特征,图4给出了一维卷积示意图。
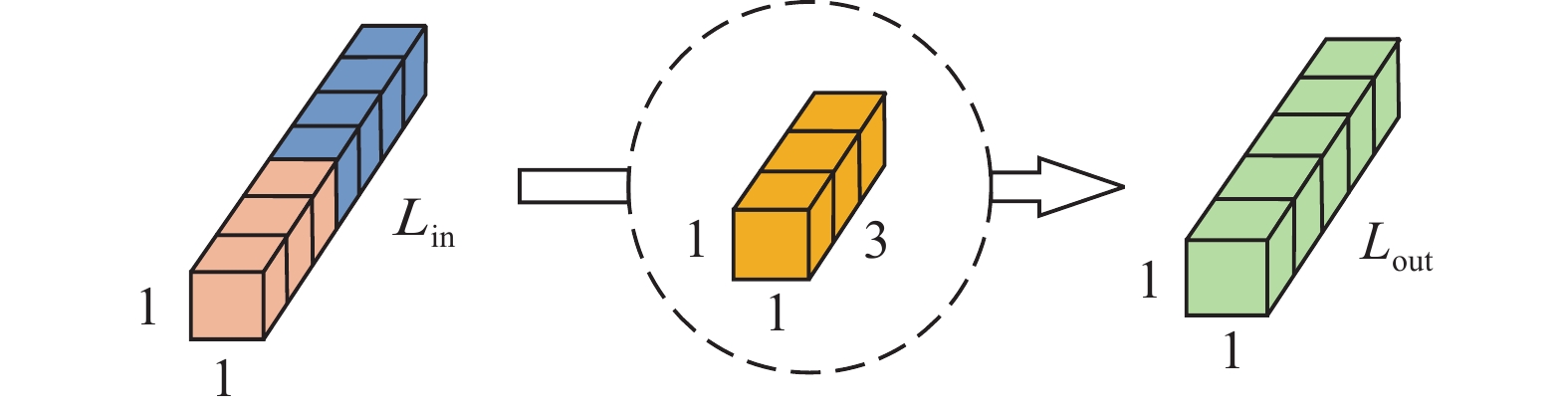 图 4 一维卷积示意Fig. 4 1D convolution diagram下载:
全尺寸图片
图 4 一维卷积示意Fig. 4 1D convolution diagram下载:
全尺寸图片
1.1.4 改进的2D-CNN模块
为了能够既充分发挥CNN网络的巨大优势,同时减少可学习参数,提高训练效率,本文在2D-CNN模块中加入深度可分离卷积,以确保模型在近似没有损失的情况下,捕获更加丰富的空间特征信息来区分不同波段的空间信息。
深度可分离卷积是传统二维卷积的一种变换形式,如图5所示,它对不同的通道采用不同的卷积核进行卷积,将传统的卷积分解为深度卷积(depthwise convolution)与逐点卷积(pointwise convolution)两部分。
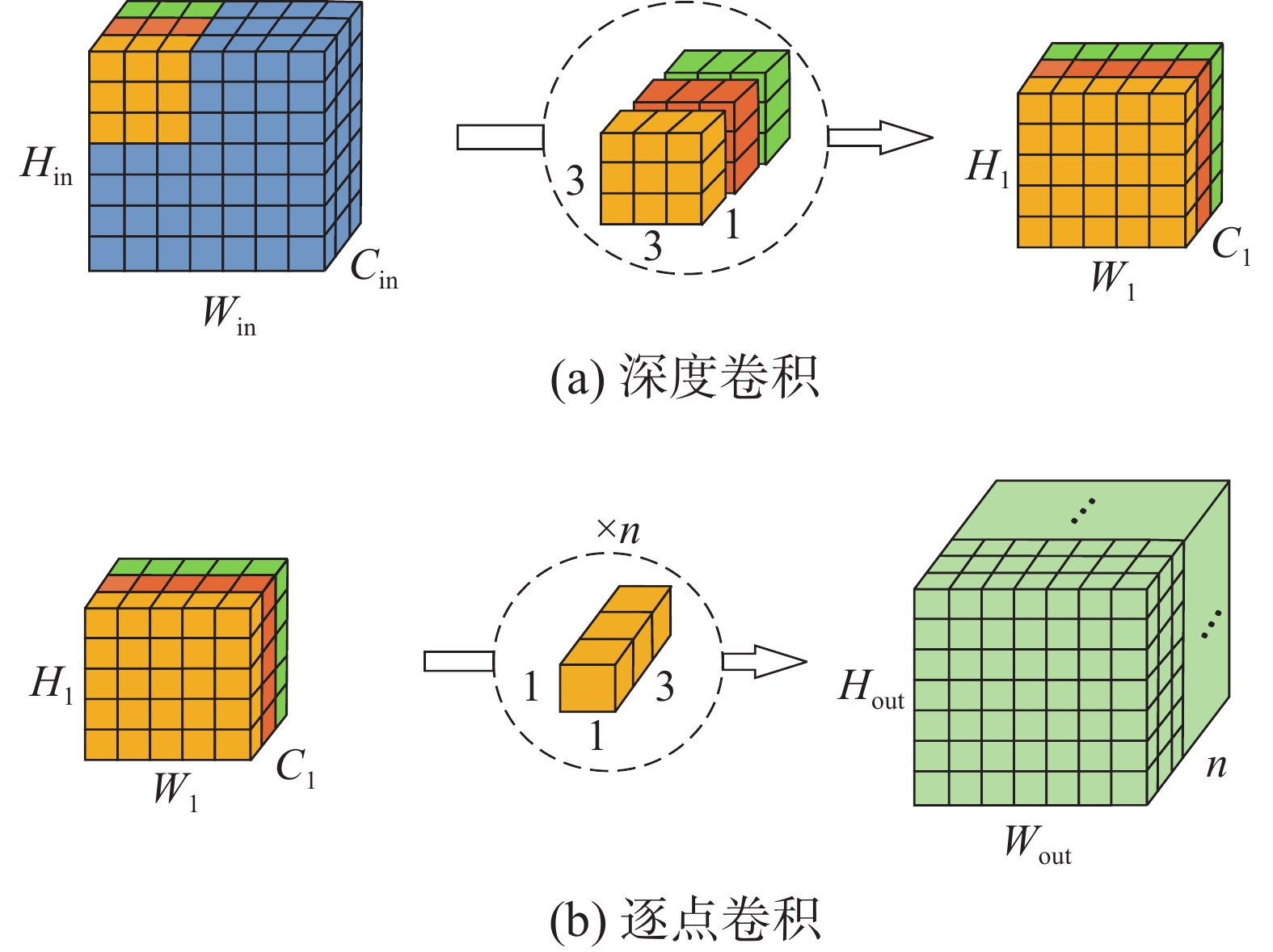 图 5 深度可分离卷积Fig. 5 Depthwise separable convolution下载:
全尺寸图片
图 5 深度可分离卷积Fig. 5 Depthwise separable convolution下载:
全尺寸图片
假设输入特征图的尺寸为
$ {S\times S\times M} $ ,卷积核的尺寸为$ {L\times L\times M} $ ,其数量为$ {N} $ 。假设对应特征图空间位置中的每一个点都会进行一次卷积操作,则对$ {N} $ 个传统的卷积,其总计算量为$$ {S\times S\times L\times L\times M\times N} $$ (3) 对深度可分离卷积而言,其计算总计算量为
$$ {S\times S\times L\times L\times M\times M\times N\times S\times S} $$ (4) 那么相对于传统卷积,深度可分离卷积的计算量与传统卷积的比值P为
$$ {P=}\frac{{1}}{{N}}+\frac{{1}}{{{L}}^{{2}}} $$ (5) 由此可得,加入深度可分离卷积不但能够实现空间与通道相关性计算的充分解耦,同时网络模型计算效率和内存开销远低于传统卷积。
1.2 Triplet Attention模块
人类视觉中的注意力会选择性地集中在部分给定的信息而忽略其余信息,这一机制有助于在保留信息上下文的同时细化感知的信息。受此启发,一些研究方法提出将注意力机制有效整合到CNN结构中,来提高视觉分类任务的性能。本文基于HSI分类问题的特点,引入轻量化的Triplet Attention注意力机制,利用三分支结构捕获跨维交互来计算注意权重,通过旋转操作和残差变换建立维度间的依存关系,如图6所示,顶部分支负责计算跨通道维度C和空间维度W的注意力权重,中间的分支负责计算通道维度C和空间维度H的注意力权重,最后一个分支用于捕获H和W的空间维度依赖关系,最后通过平均法对权重进行聚合。
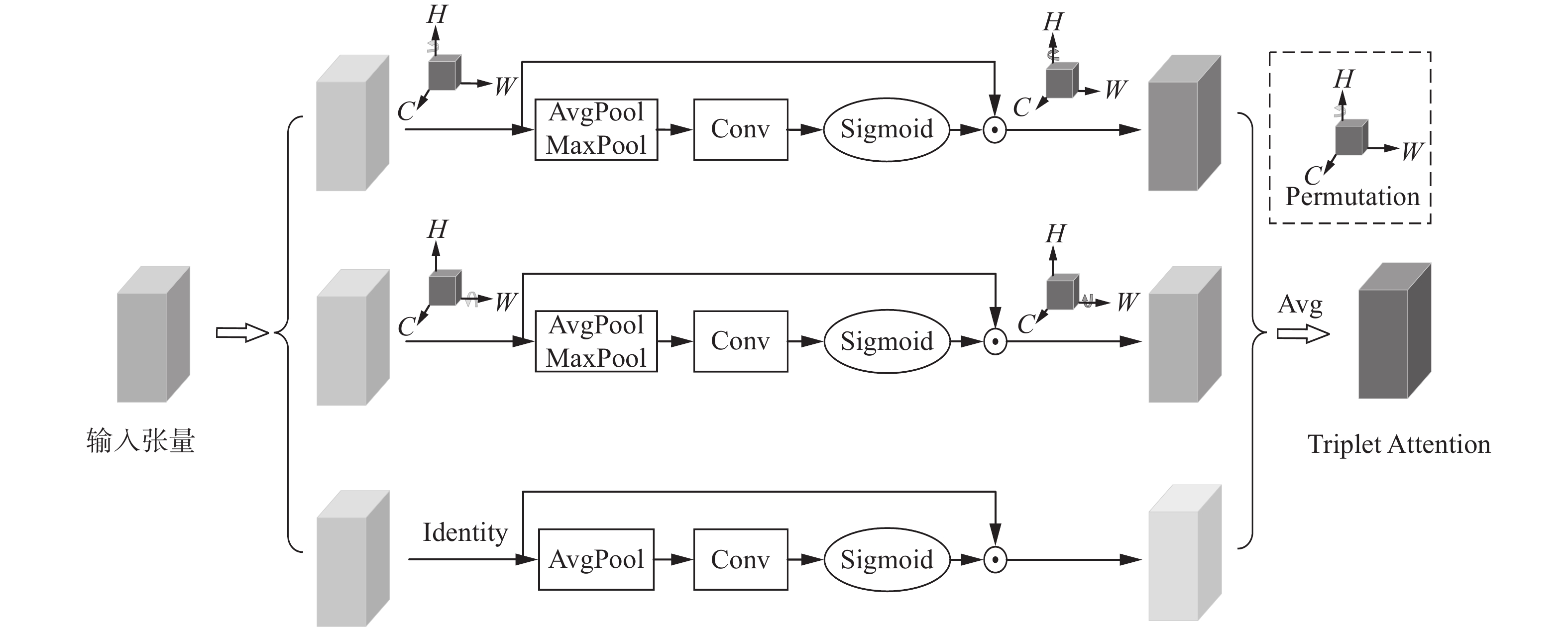 图 6 Triplet Attention原理Fig. 6 Triplet Attention schematic下载:
全尺寸图片
图 6 Triplet Attention原理Fig. 6 Triplet Attention schematic下载:
全尺寸图片
图7给出了Triplet Attention的模型结构,当给定输入为C×H×W时,输入3个分支具体实现如下:
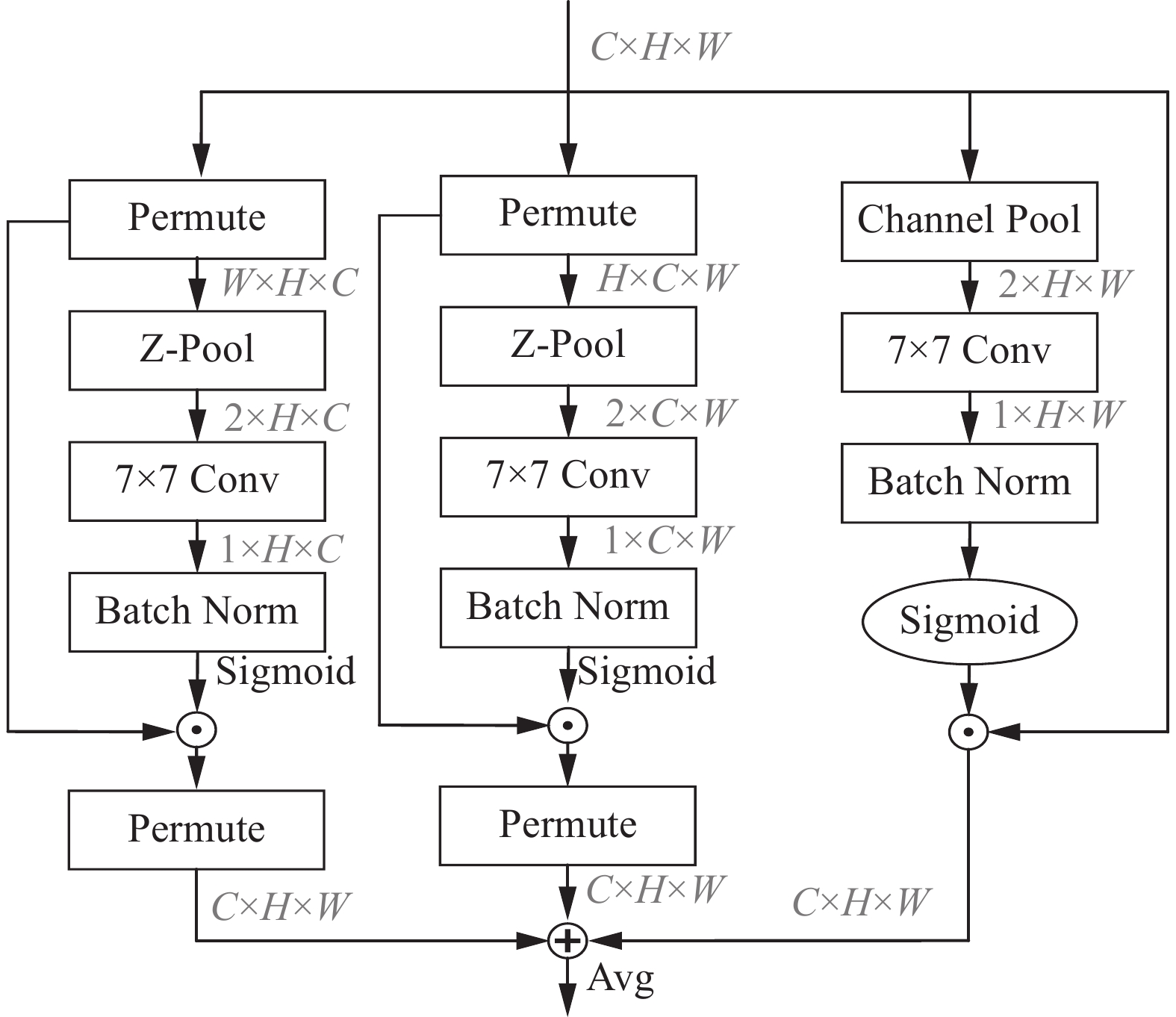 图 7 Triplet Attention结构Fig. 7 Triplet Attention architecture diagram下载:
全尺寸图片
图 7 Triplet Attention结构Fig. 7 Triplet Attention architecture diagram下载:
全尺寸图片
1)第1分支为通道维度C和空间维度H交互捕获分支,输入特征图先沿H轴逆时针旋转90°,变成形状为W×H×C的特征图,进而在W维度上进行Z-Pool,Z-Pool是对输入进行平均池化和最大池化,能够保留特征的丰富表示,同时缩小其深度,得到形状为2×H×C的特征,然后通过7×7的卷积层和BN层,经过Sigmoid激活层生成相应的注意权重。最后经过残差变换,沿H轴顺时针旋转90°,将注意力权重乘回原始特征图,得到C×H×W维度特征图。
2)第2分支为通道C和空间W维度交互捕获分支,输入特征图先沿W轴逆时针旋转90°,得到维度为H×C×W的特征图,进而在H维度上进行Z-Pool,变成形状为2×C×W的特征图。最后再通过7×7卷积和BN层,经过激活函数,再利用残差变换和旋转操作将注意力权重乘回原始特征图,变为C×H×W维度特征图。
3)第3分支为空间注意力计算分支,输入特征图经过Channel Pool,变成形状为2×H×W的特征图,进而经过7×7卷积层、BN层,经由激活函数生成空间注意力权重。最后利用残差变换和旋转操作将注意力权重乘回原始特征图,变为C×H×W维度特征图。
4)最后对3个分支输出的C×H×W维度特征进行相加取平均。
2. 实验数据获取与预处理
2.1 实验数据集
为了将HCTA-Net模型与目前的主流方法进行对比,本文选用Indian Pines、Salinas和Pavia University 3个公开的数据集进行实验,数据集参数信息如表1所示。
表 1 HSI数据集参数Table 1 HSI dataset parameter参数 Indian Pines Salinas Pavia University 采集地点 印第安纳州 加州 意大利北部 采集设备 AVIRIS AVIRIS ROSIS 谱范围/μm 0.4~2.5 0.4~2.5 0.43~0.86 大小/像素 145×145 512×217 610×340 空间分辨率/m 20 3.7 1.3 续表 1 参数 Indian Pines Salinas Pavia University 波段数 224 224 115 去噪波段数 200 204 103 样本量 10249 54129 42776 类别量 16 16 9 图8~10分别给出了Indian Pines、Salinas和Pavia University数据集相应的伪彩色图与真实参考图。
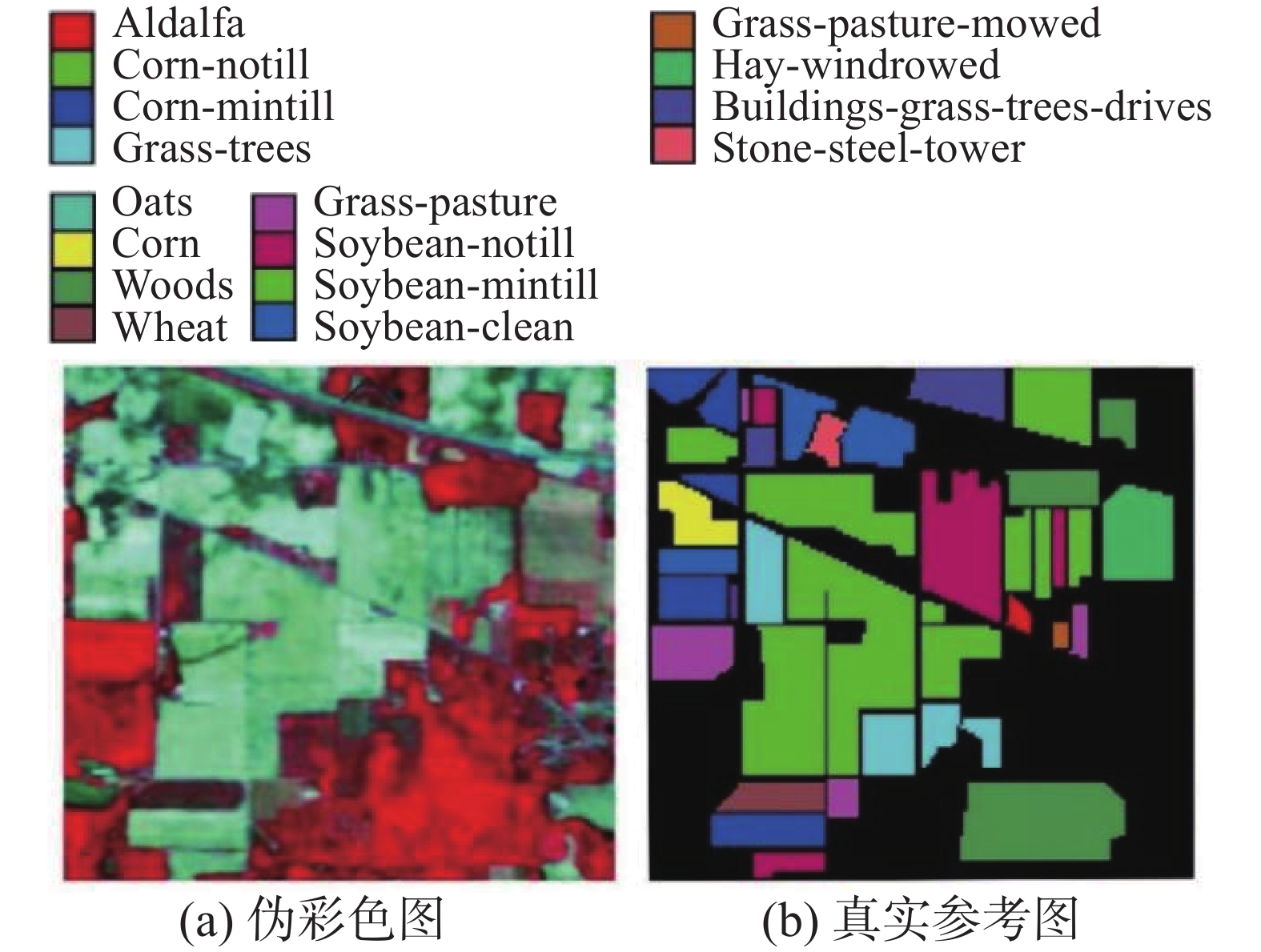 图 8 Indian Pines数据集Fig. 8 Indian Pines dataset下载:
全尺寸图片
图 8 Indian Pines数据集Fig. 8 Indian Pines dataset下载:
全尺寸图片
 图 9 Salinas数据集Fig. 9 Salinas dataset下载:
全尺寸图片
图 9 Salinas数据集Fig. 9 Salinas dataset下载:
全尺寸图片
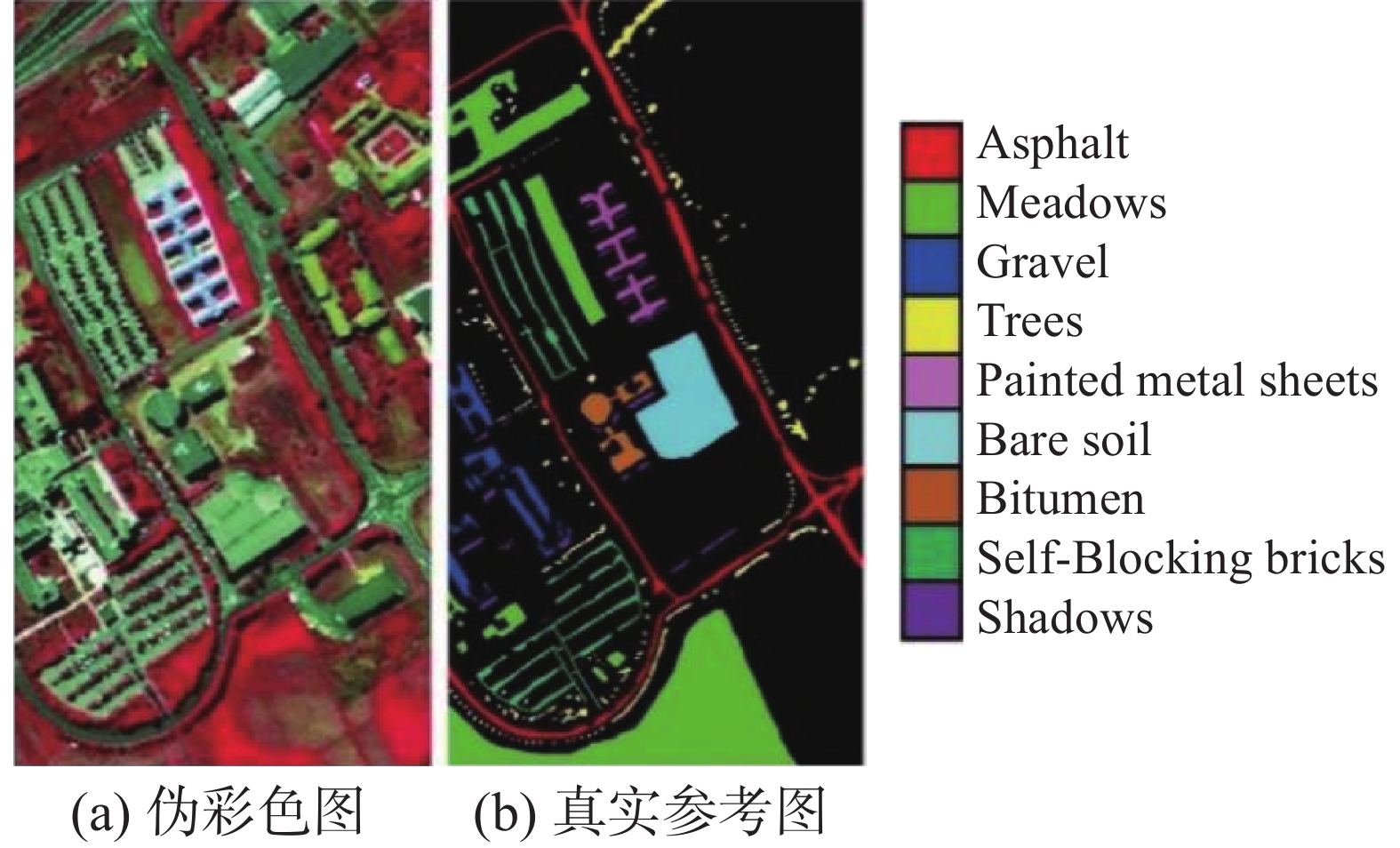 图 10 Pavia University数据集Fig. 10 Pavia University dataset下载:
全尺寸图片
图 10 Pavia University数据集Fig. 10 Pavia University dataset下载:
全尺寸图片
2.2 数据降维
HSI具有高维度和高特征冗余的特点,利用KPCA对HSI进行降维,通过引用核函数,增强对HSI数据的非线性信号处理能力,从而使用更少的特征数据,最大限度地表征原有信息。通过求解HSI数据各主成分的贡献率,本文采用Indian Pines数据集前30个主成分,贡献率为99.25%,采用Salinas数据集前15个主成分,贡献率为99.9%,采用Pavia University数据集前15个主成分,贡献率为99.9%。
2.3 实验参数设置
本文实验环境为Intel(R) Core(TM) i7-9700K CPU @3.60 GHz,内存为32.0 GB,GPU NVIDIA Geforce RTX 3070,软件环境采用开源的Tensorflow 2.0框架来搭建网络模型并进行实验。对于Indian Pines数据集,从每个类别中随机选取10%、10%和80%的样本组成训练集、验证集与测试集,对于Salinas和Pavia University数据集,从每个类别中随机选取5%、5%和90%的样本组成训练集、验证集与测试集。HCTA-Net网络模型的输入窗口大小为25×25,训练迭代次数为50次,学习率初始化设置为0.001,之后采用Adam优化器对网络进行学习训练。
在3D-CNN模块中,3个3D卷积核大小分别为(3,3,7)、(3,3,5)和(3,3,3),相对应的滤波器个数为8、16和32,在改进2D-CNN模块中,2D可分离卷积核大小为(3,3),对应的滤波器数量为64,另外,在1D-CNN模块中,采用128个卷积核大小为3的滤波器。实验利用ReLu和Dropout的组合策略来缓解训练过程中可能存在的过度拟合的问题,从而有效提高了训练模型的泛化性能。最后,本文采用总体精度(OA)、平均精度(AA)、Kappa系数(K) 3个评价指标,来评价不同模型之间的性能差异,其中,OA为分类正确数与总像元数之间的比值;AA为总体精度在各个类别中的均值;Kappa系数是用来判断一致性的程度,即分类预测结果与真实参考图之间的一致性。
3. 5种分类算法性能对比分析
为验证本文提出的HCTA-Net模型的正确性和有效性,将其与SVM[23]、2D-CNN[24]、3D-CNN[25]、HybridSN[26]、DTAResNet[27]、CNN-ASS[28]模型进行实验对比分析,为保证实验结果的公平性,实验均在相同环境中进行。不同方法在Indian Pines、Salinas和Pavia University数据集上的分类结果如图11~13所示,各类别分类精度如表2~4所示。以Indian Pines为例,由图11可以看出,仅使用SVM方法的结果图错分现象明显,3D-CNN方法通过3D卷积与残差网络思想优化了这一现象,HybridSN 通过3D与2D卷积融合明显提高了分类准确度,DTAResNet与CNN-ASS通过特征提取和引入注意力模块进一步地降低了错分程度。而本文提出的HCTA-Net方法分类效果最接近真实情况,另外,由表2可知,除Oats与Soybean-clean外,其他14类都达到了98%以上的分类精度,证明HCTA-Net模型能够聚焦融合更为丰富的光谱–空间特征信息,以达到最佳的分类效果。
表 3 不同方法下Salinas数据集各类别分类结果Table 3 Classification results of each category of Salinas dataset with different methods% 类别 SVM 2D-CNN 3D-CNN HybridSN DTAResNet CNN-ASS HCTA-Net Brocoli_green_weeds_1 97.64 100 100 100 100 100 99.67 Brocoli_green_weeds_2 99.92 99.83 99.91 100 100 99.86 99.58 Fallow 96.54 98.58 100 100 99.39 99.63 100 Fallow_rough_plow 98.94 97.91 99.92 98.54 97.89 99.03 99.21 Fallow_smooth 98.00 97.93 99.83 96.95 99.62 99.33 100 Stubble 99.76 100 100 100 100 100 100 Celery 99.21 99.85 100 100 100 100 100 Grapes_untrained 91.44 89.64 99.41 97.91 96.18 98.89 99.90 Soil_vinyard_develop 99.30 99.63 99.98 100 100 100 100 Corn_senesced_green_weeds 93.39 97.69 99.83 100 99.59 99.77 99.90  图 11 不同方法下Indian Pines分类结果Fig. 11 Classification results of Indian Pines dataset with different methods下载:
全尺寸图片
图 11 不同方法下Indian Pines分类结果Fig. 11 Classification results of Indian Pines dataset with different methods下载:
全尺寸图片
 图 12 不同方法下Salinas数据集分类结果Fig. 12 Classification results of Salinas dataset with different methods下载:
全尺寸图片
图 12 不同方法下Salinas数据集分类结果Fig. 12 Classification results of Salinas dataset with different methods下载:
全尺寸图片
 图 13 不同方法下Pavia University数据集分类结果图Fig. 13 Classification results of Pavia University dataset with different methods下载:
全尺寸图片
表 2 不同方法下Indian Pines数据集各类别分类结果Table 2 Classification results of each category of Indian Pines dataset with different methods
图 13 不同方法下Pavia University数据集分类结果图Fig. 13 Classification results of Pavia University dataset with different methods下载:
全尺寸图片
表 2 不同方法下Indian Pines数据集各类别分类结果Table 2 Classification results of each category of Indian Pines dataset with different methods% 类别 SVM 2D-CNN 3D-CNN HybridSN DTAResNet CNN-ASS HCTA-Net Alfalfa 59.52 100 100 100 100 100 100 Corn-notill 68.35 83.99 90.48 95.87 97.77 98.24 98.70 Corn-mintill 51.00 84.83 96.77 95.28 97.33 99.80 98.80 Corn 44.86 90.48 99.32 99.49 100 95.95 98.81 Grass-pasture 88.74 94.56 97.76 99.75 97.89 96.60 99.70 Grass-trees 93.46 97.56 98.67 99.83 99.10 96.90 99.03 Grass-pasture-mowed 84.62 100 100 100 37.04 100 100 Hay-windrowed 97.68 94.61 99.23 99.24 99.64 100 100 Oats 16.67 66.67 100 5.26 31.58 85.71 76.47 Soybean-notill 62.40 90.18 95.99 99.87 95.46 99.47 99.70 Soybean-mintill 84.71 88.58 99.69 99.01 97.54 99.52 99.13 Soybean-clean 47.19 78.29 99.38 98.11 98.31 98.02 97.58 Wheat 93.51 93.26 100 96.55 100 96.85k 100 Woods 96.66 98.40 98.05 99.71 99.87 98.44 100 Buildings-grass-trees-drives 56.03 89.80 100 98.13 99.55 99.57 100 Stone-steel-towers 90.48 94.67 98.31 94.52 90.63 96.43 98.39 OA 76.29 89.87 97.28 98.36 97.55 98.66 99.16 AA 70.99 78.19 85.85 91.96 90.11 96.64 98.27 K 72.62 88.42 96.89 98.13 97.21 98.44 99.05 续表 3 类别 SVM 2D-CNN 3D-CNN HybridSN DTAResNet CNN-ASS HCTA-Net Lettuce_romaine_4wk 94.29 98.81 96.81 99.81 99.28 100 100 Lettuce_romaine_5wk 99.73 99.24 99.66 99.25 99.54 99.84 100 Lettuce_romaine_6wk 98.16 99.42 100 98.23 100 99.64 99.76 Lettuce_romaine_7wk 92.23 96.41 99.89 100 100 99.32 99.90 Vinyard_untrained 52.35 88.86 95.33 99.93 99.95 99.20 99.79 Vinyard_vertical_trellis 98.95 98.88 100 100 100 100 99.81 OA 90.58 95.78 99.12 99.29 99.01 99.52 99.87 AA 94.37 97.64 99.41 99.53 99.41 99.64 99.84 K 89.48 95.30 99.02 99.21 98.90 99.47 99.86 表 4 不同方法下Pavia University数据集各类别分类结果Table 4 Classification results of each category of Pavia University dataset with different methods% 类别 SVM 2D-CNN 3D-CNN HybridSN DTAResNet CNN-ASS HCTA-Net Asphalt 94.98 96.32 99.97 99.25 99.29 98.53 99.49 Meadows 97.44 96.73 99.45 99.74 99.66 99.82 99.98 Gravel 73.08 84.42 99.75 99.29 92.55 98.47 98.82 Trees 84.44 97.21 99.85 98.01 99.38 99.13 99.63 Painted metal sheets 99.69 100 100 100 100 99.92 99.91 Bare soil 70.24 96.12 99.17 99.71 99.48 99.98 100 Bitumen 1.42 96.29 99.92 98.44 97.84 99.25 100 Self-Blocking bricks 88.14 87.13 90.76 97.36 91.58 98.35 99.29 Shadows 100 97.75 98.84 99.50 99.87 97.84 100 OA 88.08 95.30 98.73 99.27 98.46 99.34 99.76 AA 78.83 93.33 98.63 98.38 97.74 98.29 99.68 K 83.88 93.75 98.32 99.04 97.96 99.13 99.69 表2~4给出了不同方法分类结果的评价指标值,由表可知,HCTA-Net方法的OA、AA、Kappa系数均达到了最优。在Indian Pines数据集上,OA分别为99.16%,与SVM、2D-CNN、3D-CNN、HybridSN、DTAResNet 、CNN-ASS方法相比,分别提高了22.87%、9.29%、1.88%、0.8%、1.81%与0.5%,与其他方法中性能最好的CNN-ASS方法相比,AA高出了1.63%,Kappa系数高出了0.61%。在Salinas数据集上,OA达到了99.87%,比SVM、2D-CNN、3D-CNN、HybridSN、DTAResNet 、CNN-ASS方法分别提高了9.29%、4.09%、0.75%、0.58%、0.86%、0.35%,与分类效果较为理想的CNN-ASS方法相比,AA提高了0.2%,Kappa系数提高了0.39%,这是因为Salinas数据集本身样本分布较为均衡,光谱与空间维度信息有较大差异,所以有利于分类。在Pavia University数据集上,OA达到了99.76%,比SVM、2D-CNN、3D-CNN、HybridSN、DTAResNet 、CNN-ASS方法分别提高了11.68%、4.46%、1.03%、0.49%、1.3%、0.42%,与分类效果较为理想的CNN-ASS方法相比,AA提高了1.39%,Kappa系数提高了0.59%,此外,由于本文仅使用了三层3D、一层2D和一层1D卷积层,并引入深度可分离卷积,使模型更为轻量化,训练时间也得以进一步减少,实验结果如表5所示,由表可得,本文提出的HCTA-Net方法网络参数最少,所用训练时间最短,为42.5 s。
表 5 不同分类方法网络参数与训练时间Table 5 Network parameters and training time of different classification methods参数 3D-CNN HybridSN DTAResNet CNN-ASS HCTA-Net 网络参数 199153 4844793 21975725 4787507 573989 训练时间/s 124.2 76.1 441.4 63.7 42.5 在实验中,一般通过训练和验证损失率来分析判断网络模型的稳定性与拟合度。图14给出了HCTA-Net方法应用在Indian Pines数据集上的训练和验证损失率的变化曲线。由图可以看出,训练和验证的损失率在训练过程中均基本处于不断下降的状态,在迭代至20轮左右达到稳定状态,训练和验证损失基本接近0,说明HCTA-Net模型通过训练学习到了数据集的有效特征,而且模型相对稳定,收敛速度快,具有良好的学习能力和一定的泛化能力,最终总体分类精度可达到99.16%,意味着可以较为准确地区分出HSI数据集中绝大部分的地物类别。
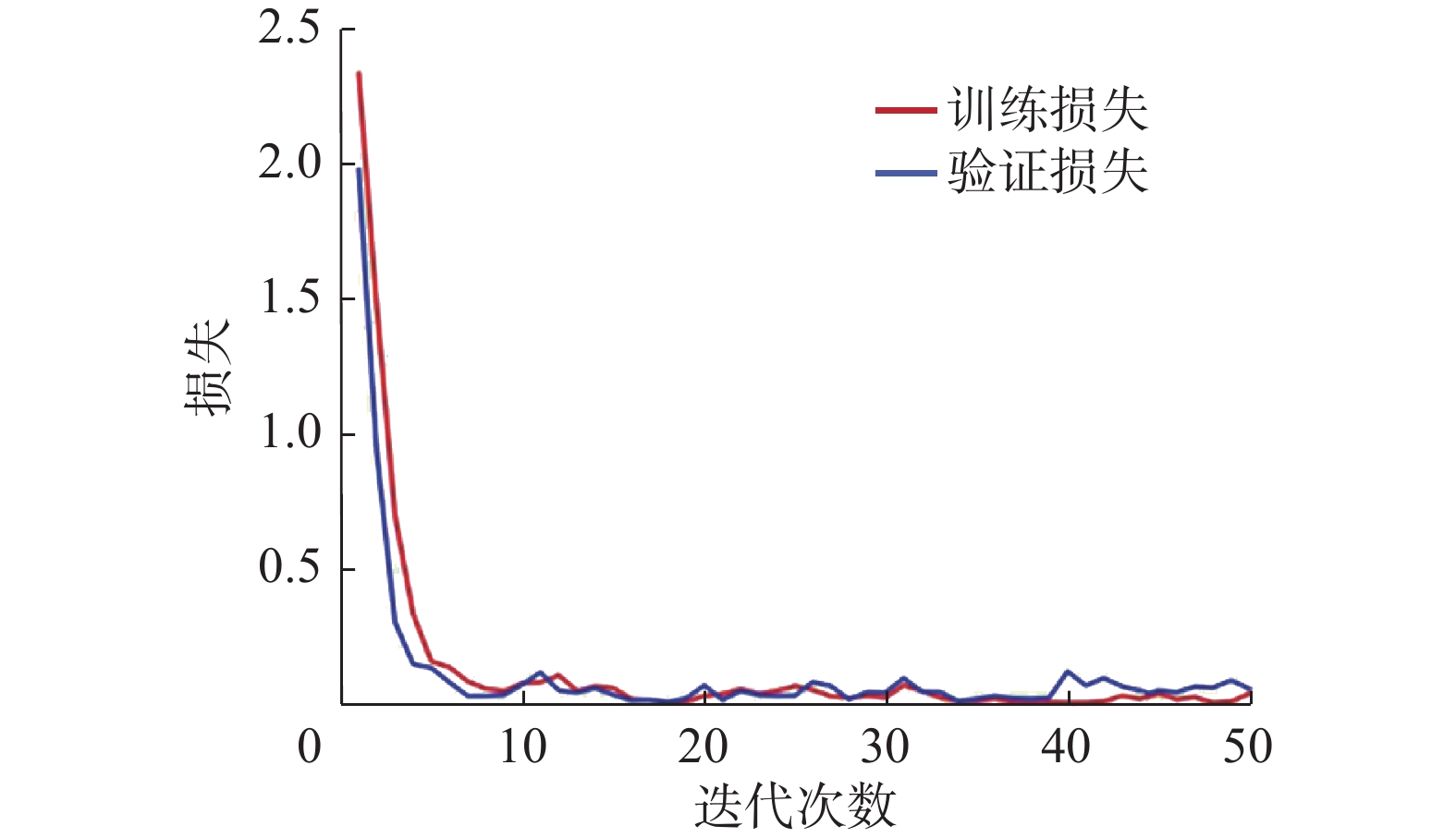 图 14 Indian Pines数据集训练和验证损失变化曲线Fig. 14 Training and validation loss rate of Indian Pines dataset下载:
全尺寸图片
图 14 Indian Pines数据集训练和验证损失变化曲线Fig. 14 Training and validation loss rate of Indian Pines dataset下载:
全尺寸图片
4. 结束语
本文针对HSI数据维度高、特征信息表征不到位及参数过多等问题,提出一种基于混合卷积与三重注意力的卷积神经网络(HCTA-Net)。该网络模型主要设计了一种由3D卷积层、2D卷积层和1D卷积层构成的混合卷积神经网络模块,有效融合不同维度的卷积层,充分利用光谱–空间域与深空间域互补特性,综合提取不同层次更加丰富的光谱–空间特征。为进一步捕获跨空间维度和通道维度间的交互信息,加入了三重注意力模块,同时通过引入深度可分离卷积,有效减少了网络参数,缩短了训练时间。该方法在Indian Pines、Salinas和Pavia University数据集上OA分别达到了99.16%、99.87%和99.76%,证明了本文方法可以有效提高HSI的分类性能。虽然本文模型具有较好的分类效果,但也存在一些不足,在后续的研究中,将进一步改进网络结构,使用更轻量级的模型达到更好的分类精度。
-
图 1 HCTA-Net模型结构
Fig. 1 HCTA-Net structure diagram
下载:
全尺寸图片
图 2 三维卷积示意
Fig. 2 3D convolution diagram
下载:
全尺寸图片
图 3 二维卷积示意
Fig. 3 2D convolution diagram
下载:
全尺寸图片
图 4 一维卷积示意
Fig. 4 1D convolution diagram
下载:
全尺寸图片
图 5 深度可分离卷积
Fig. 5 Depthwise separable convolution
下载:
全尺寸图片
图 6 Triplet Attention原理
Fig. 6 Triplet Attention schematic
下载:
全尺寸图片
图 7 Triplet Attention结构
Fig. 7 Triplet Attention architecture diagram
下载:
全尺寸图片
图 8 Indian Pines数据集
Fig. 8 Indian Pines dataset
下载:
全尺寸图片
图 9 Salinas数据集
Fig. 9 Salinas dataset
下载:
全尺寸图片
图 10 Pavia University数据集
Fig. 10 Pavia University dataset
下载:
全尺寸图片
图 11 不同方法下Indian Pines分类结果
Fig. 11 Classification results of Indian Pines dataset with different methods
下载:
全尺寸图片
图 12 不同方法下Salinas数据集分类结果
Fig. 12 Classification results of Salinas dataset with different methods
下载:
全尺寸图片
图 13 不同方法下Pavia University数据集分类结果图
Fig. 13 Classification results of Pavia University dataset with different methods
下载:
全尺寸图片
图 14 Indian Pines数据集训练和验证损失变化曲线
Fig. 14 Training and validation loss rate of Indian Pines dataset
下载:
全尺寸图片
表 1 HSI数据集参数
Table 1 HSI dataset parameter
参数 Indian Pines Salinas Pavia University 采集地点 印第安纳州 加州 意大利北部 采集设备 AVIRIS AVIRIS ROSIS 谱范围/μm 0.4~2.5 0.4~2.5 0.43~0.86 大小/像素 145×145 512×217 610×340 空间分辨率/m 20 3.7 1.3 续表 1 参数 Indian Pines Salinas Pavia University 波段数 224 224 115 去噪波段数 200 204 103 样本量 10249 54129 42776 类别量 16 16 9 表 3 不同方法下Salinas数据集各类别分类结果
Table 3 Classification results of each category of Salinas dataset with different methods
% 类别 SVM 2D-CNN 3D-CNN HybridSN DTAResNet CNN-ASS HCTA-Net Brocoli_green_weeds_1 97.64 100 100 100 100 100 99.67 Brocoli_green_weeds_2 99.92 99.83 99.91 100 100 99.86 99.58 Fallow 96.54 98.58 100 100 99.39 99.63 100 Fallow_rough_plow 98.94 97.91 99.92 98.54 97.89 99.03 99.21 Fallow_smooth 98.00 97.93 99.83 96.95 99.62 99.33 100 Stubble 99.76 100 100 100 100 100 100 Celery 99.21 99.85 100 100 100 100 100 Grapes_untrained 91.44 89.64 99.41 97.91 96.18 98.89 99.90 Soil_vinyard_develop 99.30 99.63 99.98 100 100 100 100 Corn_senesced_green_weeds 93.39 97.69 99.83 100 99.59 99.77 99.90 表 2 不同方法下Indian Pines数据集各类别分类结果
Table 2 Classification results of each category of Indian Pines dataset with different methods
% 类别 SVM 2D-CNN 3D-CNN HybridSN DTAResNet CNN-ASS HCTA-Net Alfalfa 59.52 100 100 100 100 100 100 Corn-notill 68.35 83.99 90.48 95.87 97.77 98.24 98.70 Corn-mintill 51.00 84.83 96.77 95.28 97.33 99.80 98.80 Corn 44.86 90.48 99.32 99.49 100 95.95 98.81 Grass-pasture 88.74 94.56 97.76 99.75 97.89 96.60 99.70 Grass-trees 93.46 97.56 98.67 99.83 99.10 96.90 99.03 Grass-pasture-mowed 84.62 100 100 100 37.04 100 100 Hay-windrowed 97.68 94.61 99.23 99.24 99.64 100 100 Oats 16.67 66.67 100 5.26 31.58 85.71 76.47 Soybean-notill 62.40 90.18 95.99 99.87 95.46 99.47 99.70 Soybean-mintill 84.71 88.58 99.69 99.01 97.54 99.52 99.13 Soybean-clean 47.19 78.29 99.38 98.11 98.31 98.02 97.58 Wheat 93.51 93.26 100 96.55 100 96.85k 100 Woods 96.66 98.40 98.05 99.71 99.87 98.44 100 Buildings-grass-trees-drives 56.03 89.80 100 98.13 99.55 99.57 100 Stone-steel-towers 90.48 94.67 98.31 94.52 90.63 96.43 98.39 OA 76.29 89.87 97.28 98.36 97.55 98.66 99.16 AA 70.99 78.19 85.85 91.96 90.11 96.64 98.27 K 72.62 88.42 96.89 98.13 97.21 98.44 99.05 续表 3 类别 SVM 2D-CNN 3D-CNN HybridSN DTAResNet CNN-ASS HCTA-Net Lettuce_romaine_4wk 94.29 98.81 96.81 99.81 99.28 100 100 Lettuce_romaine_5wk 99.73 99.24 99.66 99.25 99.54 99.84 100 Lettuce_romaine_6wk 98.16 99.42 100 98.23 100 99.64 99.76 Lettuce_romaine_7wk 92.23 96.41 99.89 100 100 99.32 99.90 Vinyard_untrained 52.35 88.86 95.33 99.93 99.95 99.20 99.79 Vinyard_vertical_trellis 98.95 98.88 100 100 100 100 99.81 OA 90.58 95.78 99.12 99.29 99.01 99.52 99.87 AA 94.37 97.64 99.41 99.53 99.41 99.64 99.84 K 89.48 95.30 99.02 99.21 98.90 99.47 99.86 表 4 不同方法下Pavia University数据集各类别分类结果
Table 4 Classification results of each category of Pavia University dataset with different methods
% 类别 SVM 2D-CNN 3D-CNN HybridSN DTAResNet CNN-ASS HCTA-Net Asphalt 94.98 96.32 99.97 99.25 99.29 98.53 99.49 Meadows 97.44 96.73 99.45 99.74 99.66 99.82 99.98 Gravel 73.08 84.42 99.75 99.29 92.55 98.47 98.82 Trees 84.44 97.21 99.85 98.01 99.38 99.13 99.63 Painted metal sheets 99.69 100 100 100 100 99.92 99.91 Bare soil 70.24 96.12 99.17 99.71 99.48 99.98 100 Bitumen 1.42 96.29 99.92 98.44 97.84 99.25 100 Self-Blocking bricks 88.14 87.13 90.76 97.36 91.58 98.35 99.29 Shadows 100 97.75 98.84 99.50 99.87 97.84 100 OA 88.08 95.30 98.73 99.27 98.46 99.34 99.76 AA 78.83 93.33 98.63 98.38 97.74 98.29 99.68 K 83.88 93.75 98.32 99.04 97.96 99.13 99.69 表 5 不同分类方法网络参数与训练时间
Table 5 Network parameters and training time of different classification methods
参数 3D-CNN HybridSN DTAResNet CNN-ASS HCTA-Net 网络参数 199153 4844793 21975725 4787507 573989 训练时间/s 124.2 76.1 441.4 63.7 42.5 -
[1] 王锦锦, 李真, 朱玉玲. 高光谱影像在海洋环境监测中的应用[J]. 卫星应用, 2019(8): 36–40. doi: 10.3969/j.issn.1674-9030.2019.08.009 [2] 高暖. 高光谱图像地物及目标识别[D]. 西安: 西安电子科技大学, 2019: 1−5. GAO Nuan. Terrain and target detection in hyperspectral remote sensing imagery[D]. Xi’an: Xidian University, 2019: 1−5. [3] HUGHES G. On the mean accuracy of statistical pattern recognizers[J]. IEEE transactions on information theory, 1968, 14(1): 55–63. doi: 10.1109/TIT.1968.1054102 [4] BLANZIERI E, MELGANI F. Nearest neighbor classification of remote sensing images with the maximal margin principle[J]. IEEE transactions on geoscience and remote sensing, 2008, 46(6): 1804–1811. doi: 10.1109/TGRS.2008.916090 [5] TARABALKA Y, FAUVEL M, CHANUSSOT J, et al. SVM- and MRF-based method for accurate classification of hyperspectral images[J]. IEEE geoscience and remote sensing letters, 2010, 7(4): 736–740. doi: 10.1109/LGRS.2010.2047711 [6] 陈善学, 何宇峰. 基于空谱字典的加权联合稀疏表示高光谱图像分类[J]. 光学学报, 2023, 43(1): 0110002–1−11. CHEN Shanxue, HE Yufeng. Weighted joint sparse representation hyperspectral image classification based on spatial-spectral diction[J]. Acta optica sinica, 2023, 43(1): 0110002–1−11. [7] 熊余, 单德明, 姚玉, 等. 多特征融合下的高光谱图像混合卷积分类[J]. 红外技术, 2022, 44(1): 9–20. XIONG Yu, SHAN Deming, YAO Yu, et al. Hyperspectral image hybrid convolution classification under multi-feature fusion[J]. Infrared technology, 2022, 44(1): 9–20. [8] FAUVEL M, TARABALKA Y, BENEDIKTSSON J A, et al. Advances in spectral-spatial classification of hyperspectral images[J]. Proceedings of the IEEE, 2013, 101(3): 652–675. doi: 10.1109/JPROC.2012.2197589 [9] ZHONG Ping, GONG Zhiqiang. A hybrid DBN and CRF model for spectral-spatial classification of hyperspectral images[J]. Statistics, optimization & information computing, 2017, 5(2): 75–98. [10] LIU Jinxiang, ZHANG Kefei, WU Suqin, et al. An investigation of a multidimensional CNN combined with an attention mechanism model to resolve small-sample problems in hyperspectral image classification[J]. Remote sensing, 2022, 14(3): 785. doi: 10.3390/rs14030785 [11] HU Wei, HUANG Yangyu, WEI Li, et al. Deep convolutional neural networks for hyperspectral image classification[J]. Journal of sensors, 2015, 2015: 258619. [12] XU Xiaodong, LI Wei, RAN Qiong, et al. Multisource remote sensing data classification based on convolutional neural network[J]. IEEE transactions on geoscience and remote sensing, 2018, 56(2): 937–949. doi: 10.1109/TGRS.2017.2756851 [13] ZHANG Xin, WANG Yongcheng, ZHANG Ning, et al. SSDANet: spectral-spatial three-dimensional convolutional neural network for hyperspectral image classification[J]. IEEE access, 2020, 8: 127167–127180. [14] GUO Hao, LIU Jianjun, YANG Jinlong, et al. Deep collaborative attention network for hyperspectral image classification by combining 2-D CNN and 3-D CNN[J]. IEEE journal of selected topics in applied earth observations and remote sensing, 2020, 13: 4789−4802. [15] HU Jie, SHEN Li, SUN Gang. Squeeze-and-excitation networks[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132−7141. [16] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[M]//Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 3−19. [17] FANG Bei, LI Ying, ZHANG Haokui, et al. Hyperspectral images classification based on dense convolutional networks with spectral-wise attention mechanism[J]. Remote sensing, 2019, 11(2): 159. doi: 10.3390/rs11020159 [18] ROY S K, MANNA S, SONG Tiecheng, et al. Attention-based adaptive spectral-spatial kernel ResNet for hyperspectral image classification[J]. IEEE transactions on geoscience and remote sensing, 2021, 59(9): 7831–7843. doi: 10.1109/TGRS.2020.3043267 [19] AHMAD M, KHAN A M, MAZZARA M, et al. Attention mechanism meets with hybrid dense network for hyperspectral image classification[EB/OL].(2022−01−04)[2022−12−12].https://arxiv.org/abs/2201.01001. [20] CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]//IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1800−1807. [21] CUI Ying, YU Zikun, HAN Jiacheng, et al. Dual-triple attention network for hyperspectral image classification using limited training samples[J]. IEEE geoscience and remote sensing letters, 2022, 19: 1–5. [22] 李昌元, 刘国栋, 谭博. 基于PCA和KPCA的高光谱遥感数据降维对比研究[J]. 地理空间信息, 2022, 20(7): 89–93,103. LI Changyuan, LIU Guodong, TAN Bo. Comparative study on hyperspectral remote sensing data dimensionality reduction based on PCA and KPCA[J]. Geospatial information, 2022, 20(7): 89–93,103. [23] MELGANI F, BRUZZONE L. Classification of hyperspectral remote sensing images with support vector machines[J]. IEEE transactions on geoscience and remote sensing, 2004, 42(8): 1778–1790. doi: 10.1109/TGRS.2004.831865 [24] CHEN Yushi, JIANG Hanlu, LI Chunyang, et al. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks[J]. IEEE transactions on geoscience and remote sensing, 2016, 54(10): 6232–6251. doi: 10.1109/TGRS.2016.2584107 [25] ZHONG Zilong, LI J, LUO Zhiming, et al. Spectral-spatial residual network for hyperspectral image classification: a 3-D deep learning framework[J]. IEEE transactions on geoscience and remote sensing, 2018, 56(2): 847–858. doi: 10.1109/TGRS.2017.2755542 [26] ROY S K, KRISHNA G, DUBEY S R, et al. HybridSN: exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification[J]. IEEE geoscience and remote sensing letters, 2020, 17(2): 277–281. doi: 10.1109/LGRS.2019.2918719 [27] 王爱丽, 刘美红, 薛冬, 等. 结合动态卷积和三重注意力机制的高光谱图像分类[J]. 激光与光电子学进展, 2022, 59(10): 341–351. WANG Aili, LIU Meihong, XUE Dong, et al. Hyperspectral image classification combined dynamic convolution with triplet attention mechanism[J]. Laser & optoelectronics progress, 2022, 59(10): 341–351. [28] ZHANG Yangming, YANG Kun, YUAN Lei. A hyperspectral image classification method with CNN based on attention-enhanced spectral and spatial features[J]. Journal of physics:conference series, 2021, 2006(1): 012033. doi: 10.1088/1742-6596/2006/1/012033













































