
A ghost asymmetric residual attention network model for facial expression recognition
-
摘要: 针对ResNet50中的Bottleneck经过1×1卷积降维后主干分支丢失部分特征信息而导致在表情识别中准确率不高的问题,本文通过引入Ghost模块和深度可分离卷积分别替换Bottleneck中的1×1卷积和3×3卷积,保留更多原始特征信息,提升主干分支的特征提取能力;利用Mish激活函数替换Bottleneck中的ReLU激活函数,提高了表情识别的准确率;在此基础上,通过在改进的Bottleneck之间添加非对称残差注意力模块(asymmetric residual attention block, ARABlock)来提升模型对重要信息的表示能力,从而提出一种面向表情识别的重影非对称残差注意力网络(ghost asymmetric residual attention network, GARAN)模型。对比实验结果表明,本文方法在FER2013和CK+表情数据集上具有较高的识别准确率。Abstract: In this paper, a solution is proposed to address the low accuracy in facial expression recognition that results from the 1×1 convolution dimensionality reduction of the Bottleneck in ResNet50. To do so, the authors introduce the Ghost module and depth separable convolution to replace the 1×1 and 3×3 convolutions in the Bottleneck, respectively, in order to preserve more of the original feature information and improve the feature extraction ability of the trunk branch. The Mish activation function is also used to replace the ReLU activation function in the Bottleneck, further enhancing the accuracy of facial expression recognition. To further improve the ability of the model to express important information, the authors also introduce an asymmetric residual attention block (ARABlock) between the improved Bottlenecks. The proposed method, which is referred to as the ghost asymmetric residual attention network (GARAN) model, shows high recognition accuracy on the FER2013 and CK+ facial expression datasets based on comparative experimental results.
-
表情识别是通过人类的面部表情来判断情绪的一种手段。在最近的工作中,微表情识别逐渐成为该领域的研究热点。微表情持续时间短、难以捕捉,却表达了人试图压抑与隐藏的真实情感,在自动测谎、心理咨询以及临床诊断等方面有着很高的研究价值及应用前景[1]。目前,基于卷积神经网络(convolutional neural networks, CNN)的表情识别方法取得了不错的进展[2-4]。文献[5]提出一种改进LeNet-5的表情识别方法,采用跨连接的方式将低层次特征与高层次特征结合起来,使网络能够提取到更多的细节特征信息。文献[6]将VGG16中的全连接模块替换为深度卷积和全局平均池化,较好地避免了过拟合问题。深层网络更容易提取到具有丰富语义信息的深层特征,但是,随着网络的加深,梯度消失和梯度爆炸的现象越来越明显。深度残差网络(residual network, ResNet)[7]通过在残差模块间使用跳跃连接使得梯度正常回传,有效解决了这一问题。文献[8]将ResNet34与U-Net结构相结合,生成一个残差掩膜网络,通过掩膜块来细化输入特征映射,并为相应的特征映射生成权重,使网络能够聚焦关键的空间信息以做出正确的决策,提高了模型的表情识别性能。文献[9]提出的深度多尺度融合注意残差网络(deep multi-scale fusion attention residual network, DMFA-ResNet)以ResNet50为主干网络,使用3个3×3卷积代替原7×7卷积,在保证网络具有相同感受野的同时进一步提升网络深度;通过引入三支路的注意力残差模块突出重点局部区域,提高识别准确率。文献[10]受金字塔卷积(pyramidal convolution, PyConv)[11]的启发,结合通道和空间注意力以及PyConv构成一个新的模块PyConv-CSneck,以此来替换ResNet50中的Bottleneck,在提取多尺度特征的同时突出面部细节信息,强化了网络的特征提取能力。ResNet50中的Bottleneck采用1×1卷积进行先降维后升维的操作增加了网络的非线性,同时降低了模型计算量。但是,经过降维操作后再使用ReLU函数会造成激活空间坍塌,进而使得输入特征信息丢失严重,在一定程度上限制了主干网络的特征提取能力[12],而升维操作则会产生过多的相似特征图[13],导致了资源的浪费。
针对以上问题,部分学者进行了相关研究。Ghost模块[13]利用线性变化生成更多的特征图,能够以很小的代价从原始特征中挖掘更多特征信息,从而提升网络的特征提取能力。文献[14]将GhostNet作为目标跟踪的主干特征提取网络,文献[15]在YOLOv4中引入Ghost模块来提升目标识别的精度,在各自的任务中都具有良好的表现。注意力机制的作用是使网络学到更多重要的细节信息,同时忽略不重要的信息。文献[16]提出的残差注意力学习模块使用恒等映射单元来减轻信号的衰减,并且随着网络的深入其注意力感知功能会自适应变化,更好地感知特征。结合Ghost模块与残差注意力模块的思想,本文以ResNet50为主干网络,提出一种面向表情识别的重影非对称残差注意力网络模型(ghost asymmetric residual attention network, GARAN)。本文的主要贡献如下:
1)采用Ghost模块替换Bottleneck中的1×1卷积,采用Depthwise卷积替换Bottleneck中的3×3卷积,保留更丰富的特征信息,提高表情识别准确率,并且降低了模型的参数和计算量。
2)引入Mish激活函数[17]替换原Bottleneck中的ReLU激活函数,避免了网络结构加深时带来的梯度消失问题。
3)在Ghost_Bottleneck之间引入残差注意力模块来聚焦面部关键特征,有效地解决了细节信息丢失的问题;并将残差注意力模块中的3×3标准卷积分解为1×3和3×1连续两层不对称卷积,降低模型计算量的同时提升了网络的识别性能。
4)在Fer2013数据集和CK+数据集上进行训练和测试,并与ResNet50以及当前的主流方法进行了对比实验。结果表明本文所提方法在表情识别的准确率上具有明显的提升。
1. GARAN算法
1.1 Ghost模块
深度卷积神经网络中大量的卷积运算通常会导致整个网络的计算成本过大以及特征冗余问题。文献[13]提出的Ghost模块将标准卷积分为两步,第一步使用普通的1 ×1卷积生成部分原始特征,第二步对生成的部分原始特征进行低成本的线性运算(本文采用3×3的通道卷积)来增强特征和增加信道,然后将两组特征拼接在一起。Ghost模块与标准卷积相比能更好地提取特征,并且可以减少模型的参数和计算量,有效提高网络性能。Ghost模块的结构如图1所示。
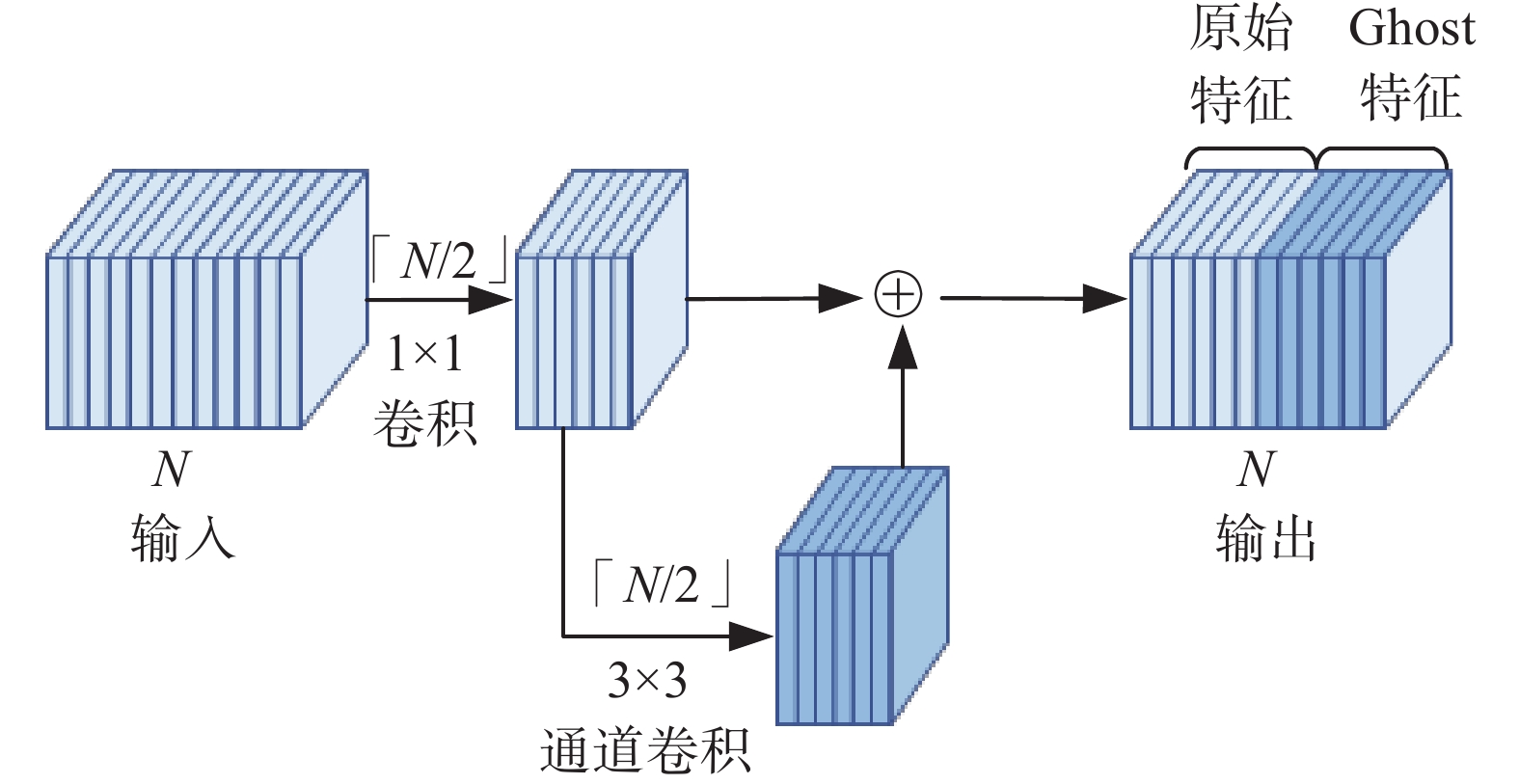 图 1 Ghost模块Fig. 1 Ghost module
图 1 Ghost模块Fig. 1 Ghost module 下载:
全尺寸图片
下载:
全尺寸图片
1.2 改进的Ghost_Bottleneck
ResNet50中的Bottleneck结构如图2(a)所示,由2个1×1卷积和1个3×3卷积构成,但是通过步长为2的1×1卷积下采样后会造成部分特征信息丢失[18]。本文使用的Ghost_Bottleneck由2个Ghost模块和1个步长为2的Depthwise卷积构成,其中第1个Ghost模块用来扩大通道数,Depthwise卷积将特征图大小降维到输入特征图的1/2,第2个Ghost模块将通道数恢复到与输入通道数一致,然后通过残差边与输入进行跳跃连接得到最终的输出,保证网络精度的同时保留更多有效特征信息。
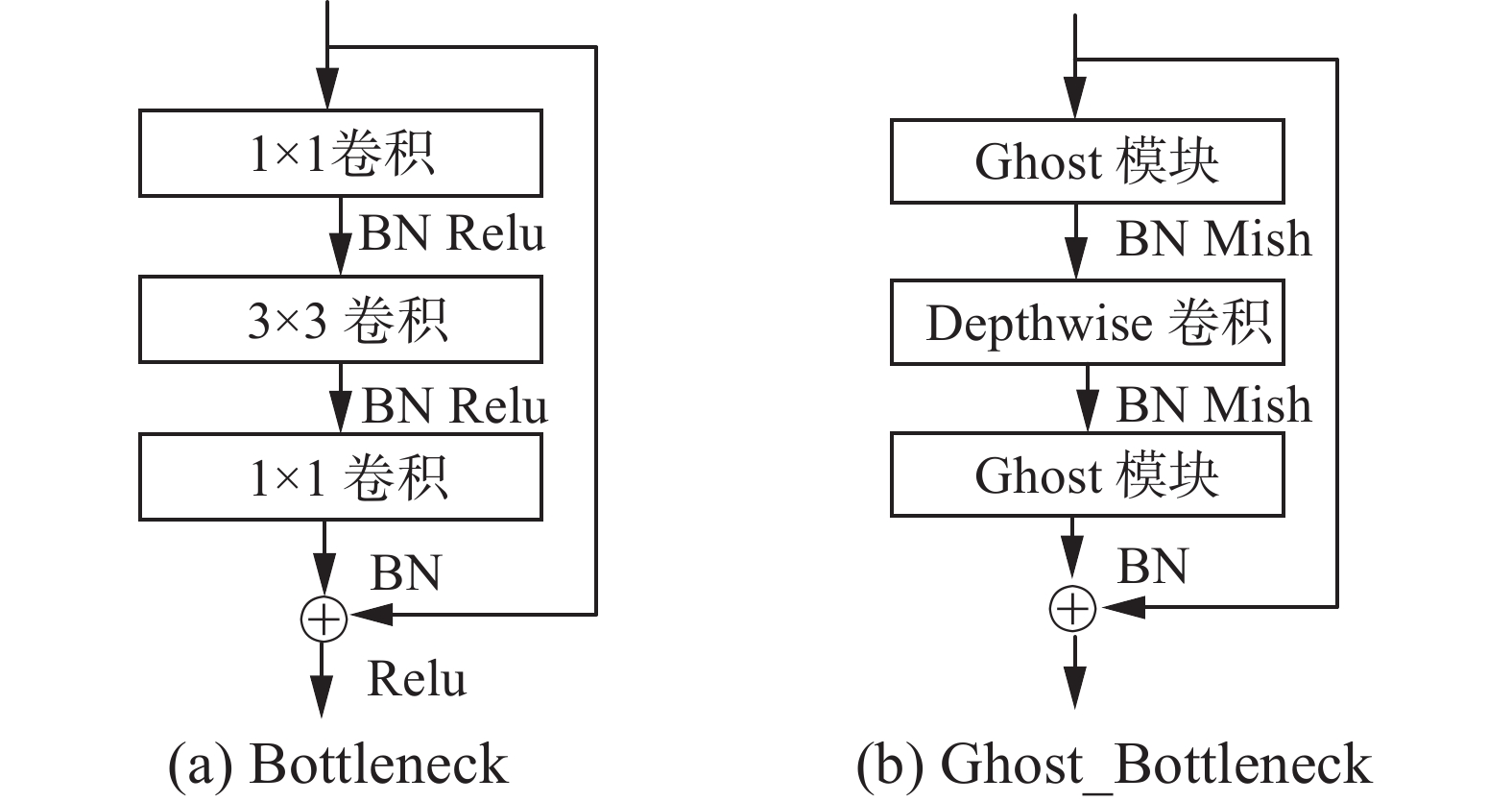 图 2 Bottleneck与Ghost_Bottleneck结构比较Fig. 2 Comparison of Bottleneck and Ghost_Bottleneck下载:
全尺寸图片
图 2 Bottleneck与Ghost_Bottleneck结构比较Fig. 2 Comparison of Bottleneck and Ghost_Bottleneck下载:
全尺寸图片
由于ReLU激活函数在输入为负时存在梯度消失的问题,而Mish函数是光滑的非单调激活函数,可以使梯度下降更加平滑,同时提高识别准确率。因此,本文使用Mish激活函数代替原Bottleneck中的ReLU激活函数。Mish激活函数的公式如下:
$$ f(x) = x \cdot {\rm{tanh}}\left( {{\rm{ln}}\left( {1 + {{\rm{e}}^x}} \right)} \right) $$ (1) 参考Mobilenetv2[12]中的线性瓶颈层,为避免激活函数对特征图造成破坏,本文在第2层Ghost模块后不使用Mish激活函数。此外,在每层之后都应用批量归一化(batch normalization, BN)进行处理,增加了网络模型的非线性,提升了网络的表达能力。改进后的Ghost_Bottleneck具体结构如图2(b)所示。
1.3 改进的非对称残差注意力模块
注意力机制通过扫描全局图像,获取需要重点关注的目标区域。但是,引入单个注意力模块可能会由于图片背景杂乱、形态多变等问题导致识别错误,而简单地堆叠注意力模块通常会导致模型的性能下降[19]。
文献[16]提出一种残差注意力网络,通过堆叠多个注意模块的方式生成注意感知特征,同时采用先自下而上后自上而下的前馈结构作为注意力模块的一部分,对输入特征添加软权重。其中每个注意模块包括两部分:主干分支(trunk branch)和掩膜分支(mask branch)。主干分支对输入特征进行处理,而掩膜分支用来增强特征,通过相关特征图学习一个权重,对主干分支的输出特征进行软加权。掩膜分支由先自下而上后自上而下的完全卷积结构组成,在残差单元之间多次使用最大池化进行下采样,增加感受野,然后使用双线性插值对输出进行上采样,确保输出大小与输入特征图相同。同时在下采样和上采样之间添加跳跃连接,捕获不同规模的信息。
为了学习到更多不同层次的图像信息,减少特征提取过程中信息的丢失,本文在网络中引入残差注意力机制。然而,网络的加深会导致整体网络性能的下降,从而影响识别准确率。为了降低残差注意力模块堆叠导致的计算量,本文在残差注意力模块中引入非对称卷积(asymmetric convolution)[20],将残差单元中标准的3×3对称卷积分解为1×3和3×1的连续两层不对称卷积,修改后的残差单元称为非对称残差单元(AResidual unit)。非对称残差注意力模块(ARABlock)的结构如图3所示。
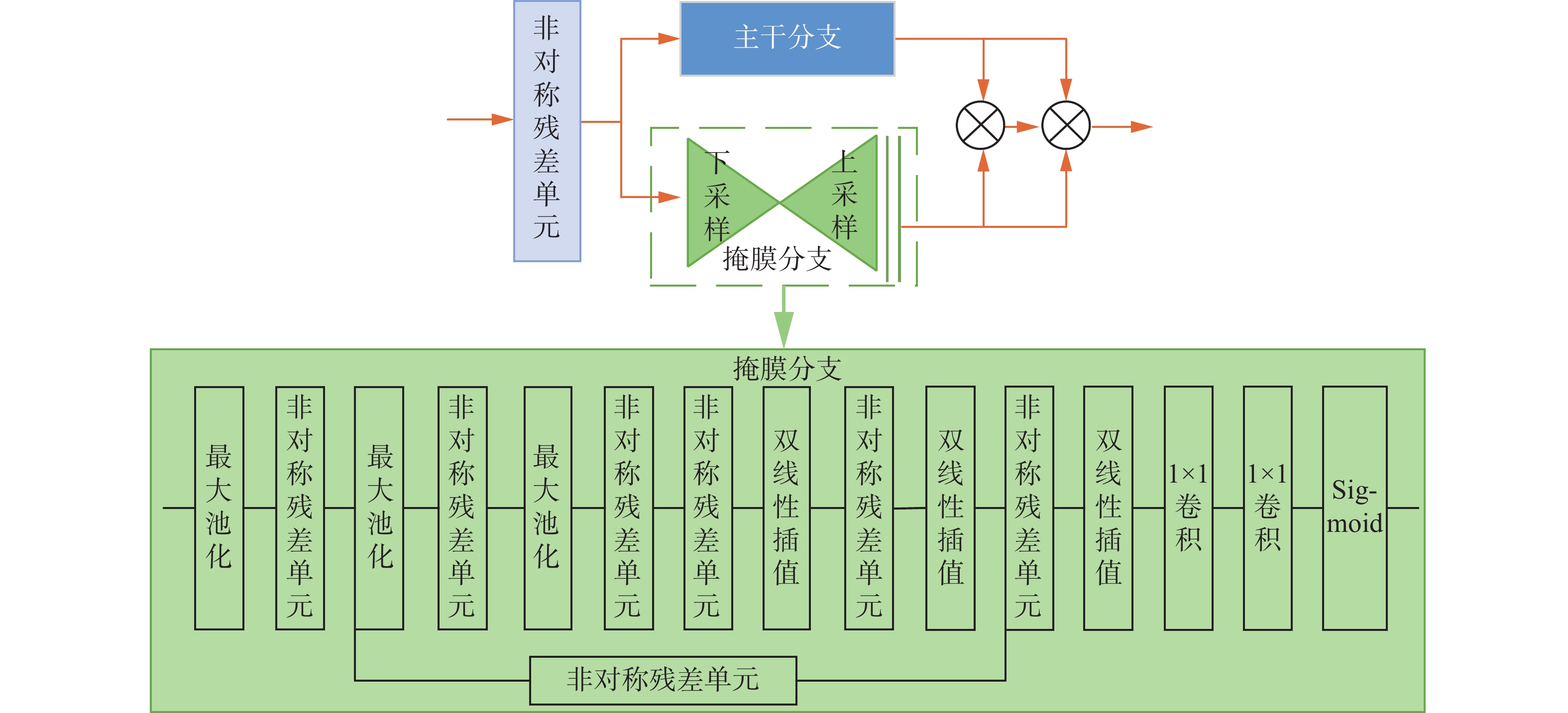 图 3 非对称残差注意力模块Fig. 3 Asymmetric residual attention block下载:
全尺寸图片
图 3 非对称残差注意力模块Fig. 3 Asymmetric residual attention block下载:
全尺寸图片
对于非对称残差注意力模块,给定输入特征图x,对其分别进行下采样和上采样,得到特征图M(x),经过sigmoid激活函数得到输出掩膜S(x):
$$ S(x) = {\rm{sigmoid}}(M(x)) = \frac{1}{{1 + {{\rm{e}}^{ - M(x)}}}}$$ (2) 输出掩膜可以在自适应学习有效特征的同时抑制噪声。假设主干分支输出特征图为F(x),则注意模块A(x)的输出为
$$ {A_{i,c}}(x) = \left( {1 + {S_{i,c}}(x)} \right) \cdot {F_{i,c}}(x) $$ (3) 式中:i代表神经元的空间位置;c代表神经元的通道位置;Si,c (x)的取值在[0, 1]区间内,当S(x)接近0时,A(x)的输出接近原始特征x。
2. 重影非对称残差注意力网络模型
本文提出的网络模型通过交叉堆叠多个Ghost_Bottleneck和多个非对称残差注意力模块ARABlock构建而成,完整的网络结构如图4所示。采用ResNet50作为主干网络结构,使用改进后的Ghost_Bottleneck替换原ResNet50中的Bottleneck,在减少计算量的同时最大程度保留原始图像细节信息;在多个Ghost_Bottleneck之间增加非对称残差注意力模块,进一步加深网络,增强局部重点区域的特征表达能力。
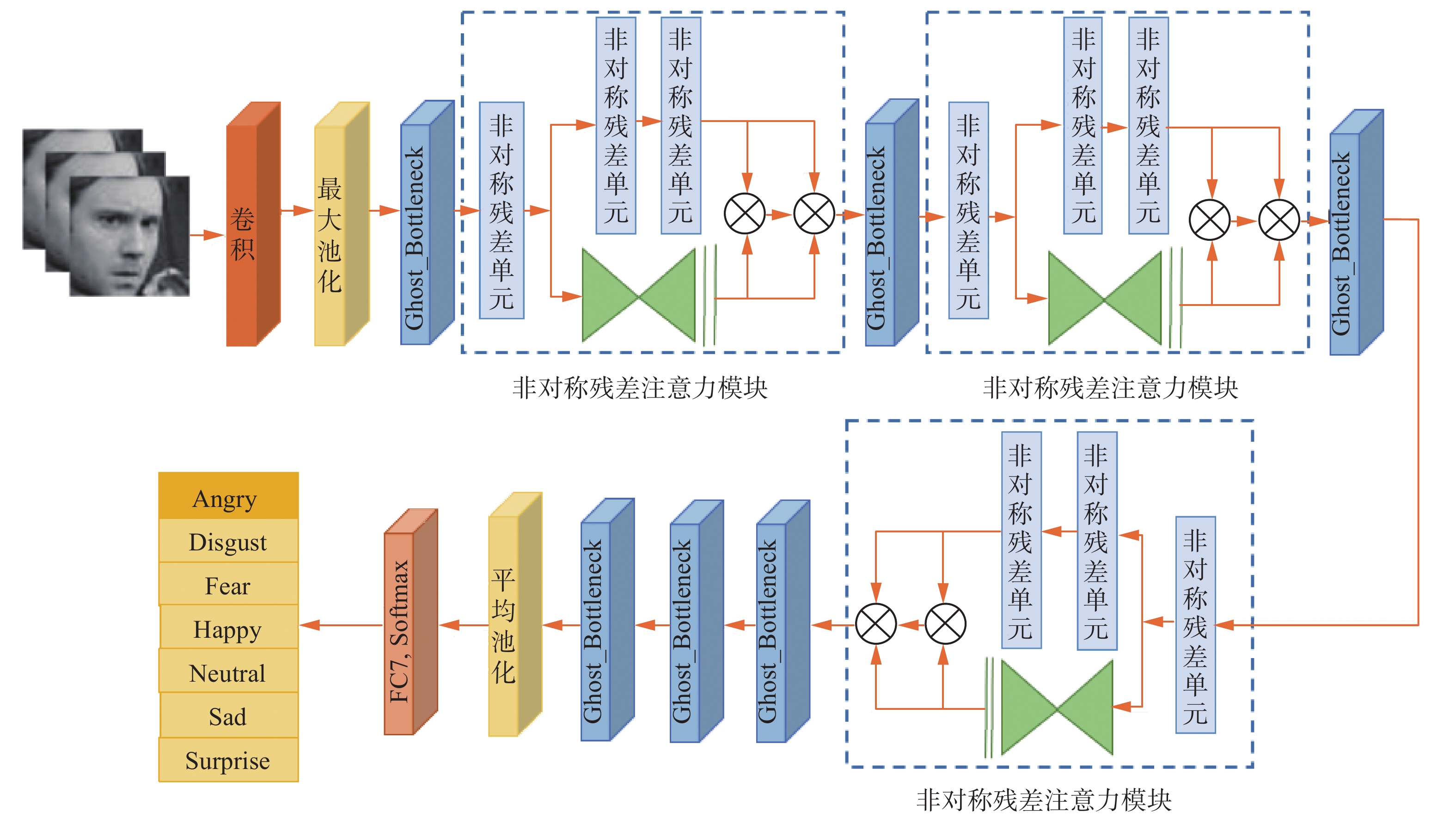 图 4 GARAN网络结构Fig. 4 GARAN network structure下载:
全尺寸图片
图 4 GARAN网络结构Fig. 4 GARAN network structure下载:
全尺寸图片
本文所提网络模型的详细信息如表1所示。首先,大小为224×224的输入图像经过一个7×7的卷积和2×2的最大池化下采样,将空间缩小到56×56。然后,经过6个Ghost_Bottleneck和3个非对称残差注意力模块堆叠,将输出的特征图空间尺寸降为7×7。再经过平均池化层使空间大小变为1×1,最后使用一个7路全连接层以及SoftMax激活函数生成对应于7种面部表情的输出。
表 1 网络模型的详细信息Table 1 Details of the network model网络层 输出 卷积核 Conv1 112×112×64 7×7, stride=2 Max Pooling 56×56×64 3×3, stride=2 Ghost_Bottleneck1 56×56×256 $\left( \begin{gathered} {\text{Ghost module} } \\ {\text{DWConv} } \\ {\text{Ghost module } }\end{gathered} \right)\times 1$ ARABlock1 56×56×256 Attention×1 续表 1 网络层 输出 卷积核 Ghost_Bottleneck2 28×28×512 $\left( \begin{gathered} {\text{Ghost module } } \\ {\text{ DWConv} } \\ {\text{Ghost module } }\end{gathered} \right)\times 1$ ARABlock2 28×28×512 Attention×1 Ghost_Bottleneck3 14×14×1024 $\left( \begin{gathered} {\text{Ghost module} } \\ {\text{ DWConv} } \\ {\text{Ghost module} } \end{gathered} \right) \times 1$ ARABlock3 14×14×1024 Attention×1 Ghost_Bottleneck4 7×7×2048 $\left( \begin{gathered} {\text{ Ghost module} } \\ {\text{ DWConv } } \\ {\text{ Ghost module} } \end{gathered} \right)\times 3$ Average Pooling 1×1×2048 7×7, stride=1 FC,SoftMax 7 / 3. 实验与分析
本文对所提方法进行了系列对比实验,实验环境如下:操作系统是64位Windows 10,编程语言使用Python3.8,深度学习框架为Pytorch1.7.0,CPU为18核心36线程3.09 GHz、96 GB,显卡为 NVDIA Quadro RTX 8000、48 GB。在训练阶段,设置batch_size为48,学习率为10−4,动量为0.9,权重衰减为10−3,优化器采用Adam。为了防止过拟合以及增强模型的泛化能力,在全连接层使用Dropout技术,设置dropout=0.5;当模型在验证集上的表现开始下降时,及时停止训练,使模型达到一个较好的拟合效果。
3.1 表情数据集
本文采用Fer2013和CK+表情数据集进行实验。Fer2013数据集由35886张人脸表情图片组成,其中,训练图片(Training)28708张,公共测试图片(PublicTest)和私有测试图片(PrivateTest)各3589张,每张图片是由大小固定为48×48的灰度图像组成,共有7种表情,具体表情对应的标签和中英文如下:0 anger 生气,1 disgust 厌恶,2 fear 恐惧,3 happy 开心,4 sad 伤心,5 surprise 惊讶,6 neutral 中性。每种表情的示例如图5。
 图 5 Fer2013数据集中7种表情示例Fig. 5 Seven emoticons from the Fer2013 dataset下载:
全尺寸图片
图 5 Fer2013数据集中7种表情示例Fig. 5 Seven emoticons from the Fer2013 dataset下载:
全尺寸图片
CK+数据集包含了123位受试者的593个视频序列,其中327个视频序列带有表情标签。本实验选取除轻蔑表情外的其他7种基本表情(愤怒、厌恶、恐惧、高兴、悲伤、惊讶和中性),每张图像的原始尺寸为640×490,将其处理为48×48大小。图6给出了经过裁剪处理后的其余7种表情示例。
 图 6 CK+数据集中7种表情示例Fig. 6 Seven emoticons from the CK+ dataset下载:
全尺寸图片
图 6 CK+数据集中7种表情示例Fig. 6 Seven emoticons from the CK+ dataset下载:
全尺寸图片
由于表情数据集的样本较少,本文在数据集预处理阶段,分别对图像进行了缩放、旋转以及水平翻转操作,增加训练样本的多样性。
3.2 评价指标
为了评估本文提出的方法在面部表情识别问题中的有效性,采用识别准确率来衡量模型的性能,将其定义为
$$ {\rm{Accuracy }}= \sum\limits_{i = 1}^7 {\frac{{{N_i}}}{{{n_T}}}} $$ (4) 式中:Accuracy表示识别准确率;Ni表示第i类识别正确的表情数量;nT表示为目标域的表情数量。
3.3 消融实验
为了验证Ghost_Bottleneck与非对称残差注意力模块在特征提取中的有效性,本文设计了如下实验。其中ResNet50是没有进行任何改进的基础网络,ARABlock表示非对称残差注意力模块,Ghost_Bottleneck表示将Bottleneck中的1×1和3×3卷积分别替换为Ghost模块和DeepWise卷积,Mish表示将Ghost_Bottleneck中的ReLU激活函数替换为Mish激活函数,将各个模块进行对比实验,实验结果如表2所示。
表 2 不同模块识别准确率对比Table 2 Comparison of recognition accuracy of different modules% 方法 Fer2013 CK+ ResNet50 69.71 95.23 ResNet50 + ARABlock 71.94 97.41 ResNet50 + Ghost_Bottleneck 71.35 96.93 ResNet50 + Ghost_Bottleneck + Mish 71.58 97.35 The Proposed 72.14 98.67 从表2中的数据可以看出,改进的Ghost_Bottleneck、非对称残差注意力模块、Mish激活函数都能够有效地提升表情识别的准确率,并且同时引入这几个模块对模型进行改进后的识别准确率提升最为显著,在Fer2013和CK+数据集上的表情识别准确率分别为72.14%和98.67%,与基础网络ResNet50相比提升了2.43%和3.44%,从而验证了本文所提方法的有效性。
图7和图8分别给出了本文所提方法在Fer2013和CK+数据集上的混淆矩阵。由图7的混淆矩阵可知,在数据集Fer2013中,本文方法在高兴(90%)、惊讶(81%)、厌恶(75%)和中性(72%)表情的识别准确率较高,这是因为这几种表情的面部动作变化明显,能够产生更多差异性的特征点,因此更容易识别。而生气(66%)、害怕(55%)和悲伤(59%)表情的识别准确率较低,且它们之间的误判率相对较高,其主要原因是这几种表情具有较高的相似性,易混淆,并且面部关键点特征变化不明显。
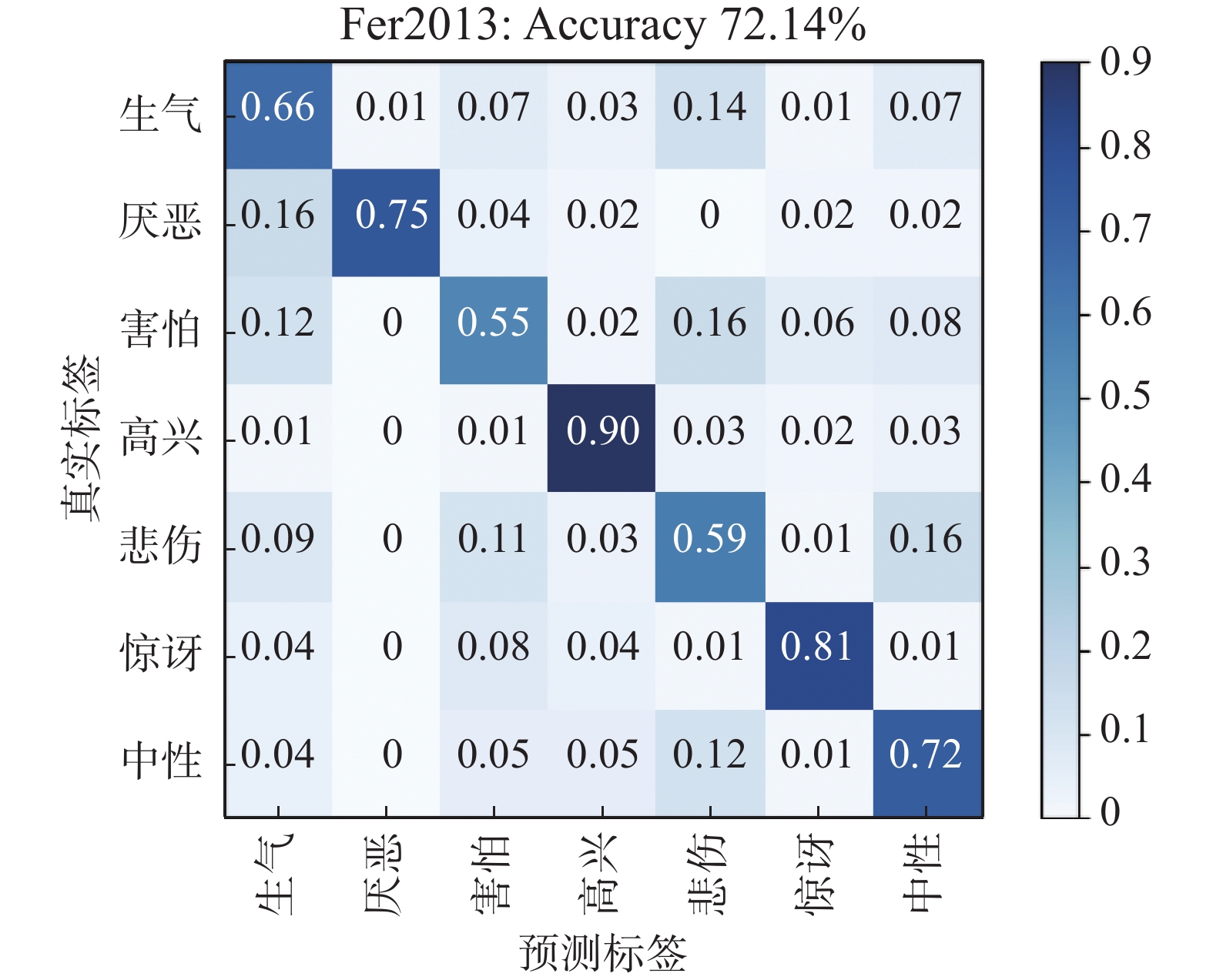 图 7 Fer2013数据集的混淆矩阵Fig. 7 Confusion matrix of Fer2013 dataset下载:
全尺寸图片
图 7 Fer2013数据集的混淆矩阵Fig. 7 Confusion matrix of Fer2013 dataset下载:
全尺寸图片
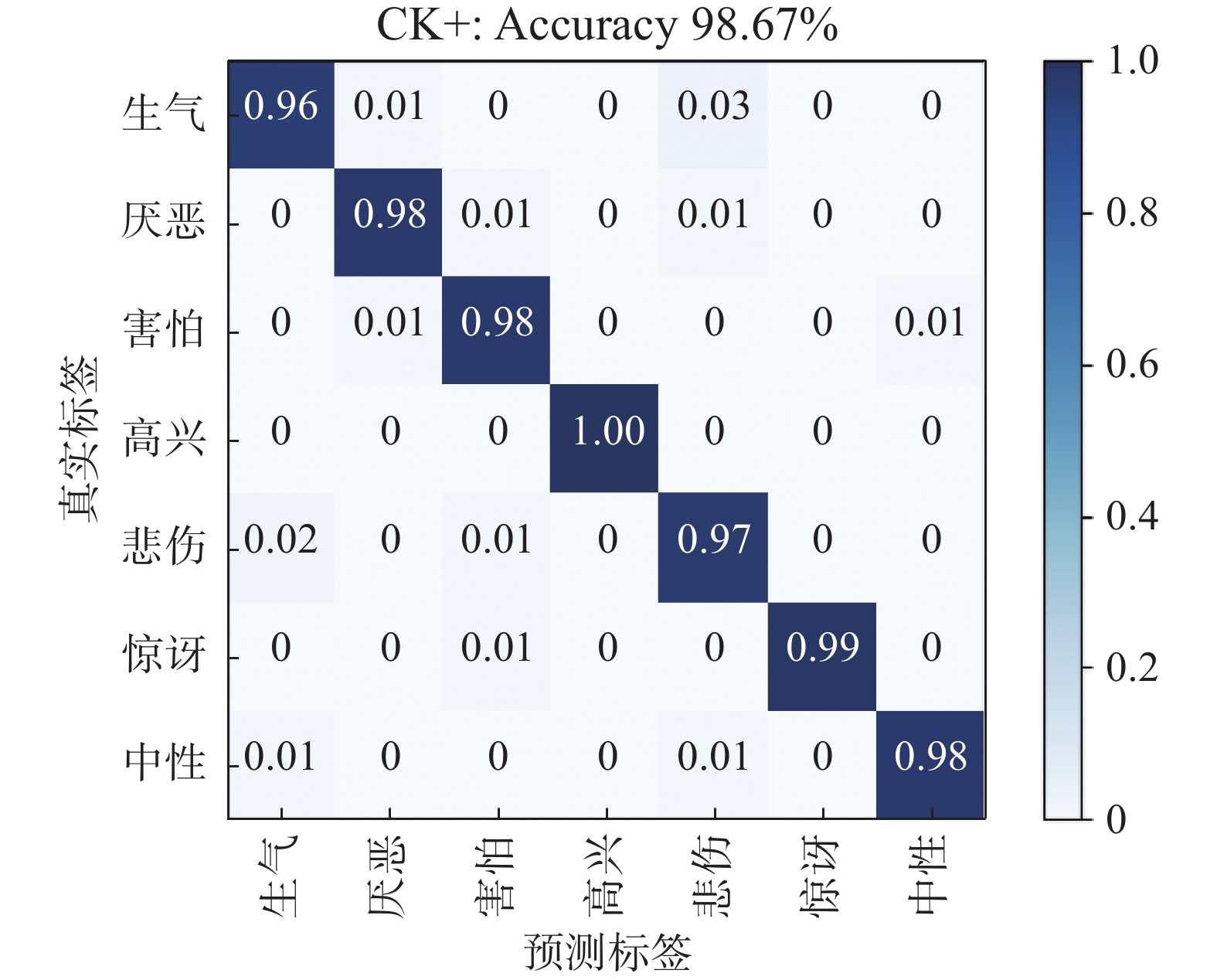 图 8 CK+数据集的混淆矩阵Fig. 8 Confusion matrix of CK+ dataset下载:
全尺寸图片
图 8 CK+数据集的混淆矩阵Fig. 8 Confusion matrix of CK+ dataset下载:
全尺寸图片
由图8的混淆矩阵可知,本文方法在CK+数据集上能取得较好的识别结果,其中高兴和惊讶的识别准确率最高,分别为99%和98%;而生气和悲伤的识别准确率较低,分别为96%和97%,且容易将生气表情错误地判断为悲伤表情,这是因为两者都属于消极情绪,类间差异小,具体表现为表情发生时都伴随着眉头紧皱、嘴角朝下的动作,因此分类相对困难。
3.4 其他主流方法对比实验
为了进一步验证所提方法的有效性,本文在Fer2013和CK+数据集上与当前比较新的几种表情识别方法分别进行了对比实验。对比结果如表3和表4所示。
分析表3和表4可知,与现有的表情识别方法相比,本文提出的方法在Fer2013和CK+两个标准数据集上均取得了不错的识别效果。在Fer2013数据集上,本文对比了5种主流的表情识别算法,其中Deep-Emotion[21]利用注意卷积网络来专注面部的重要部位,仅用一个很浅的网络就达到了较好的识别效果。MBCC-CNN[22]将残差连接、网中网以及树状多分支结构结合在一起,提高了模型的特征提取能力。本文所提方法的识别准确率相比文献[6]提高了0.3%,相比文献[8]提高了0.17%,相比文献[10]提高了1.09%,相比文献[21]提高了2.12%,相比文献[22]提高了0.62%。在CK+数据集上,本文也对比了5种主流的表情识别方法, DTAGN[23]采用两个子网络分别提取时间外观特征和时间几何特征,DeRL[24]通过cGAN生成中性表情进而学习生成模型中间层的残留表情。本文方法的识别准确率相比文献[5、8、10、23-24]分别提高了14.93%、0.21%、3.72%、1.42%以及1.37%。可见,本文所提方法能够很好地学习表情特征,具有更高的识别准确率。
4. 结束语
本文提出了一种面向表情识别的重影非对称残差注意网络(GARAN),该网络在ResNet50的基础上进行改进,将Bottleneck中的1×1卷积替换为Ghost模块,3×3卷积替换为深度可分离卷积,将ReLU激活函数替换为Mish激活函数,利用线性运算来增强特征表现,降低模型的参数量和计算量;通过引入非对称残差注意机制,增强模型对有用特征信息的响应,减少对无用特征信息的干扰。分别在Fer2013和CK+数据集上进行消融实验,验证了本文所提方法的有效性;通过与其他主流方法的对比进一步验证了本文方法的优越性。但是,由于表情的类间差异较小,生气、悲伤、害怕等表情仍具有较高的误判率,在之后的工作中将致力于解决高度相似表情间的误判问题,进一步提高表情的识别准确率。
-
图 1 Ghost模块
Fig. 1 Ghost module
下载:
全尺寸图片
图 2 Bottleneck与Ghost_Bottleneck结构比较
Fig. 2 Comparison of Bottleneck and Ghost_Bottleneck
下载:
全尺寸图片
图 3 非对称残差注意力模块
Fig. 3 Asymmetric residual attention block
下载:
全尺寸图片
图 4 GARAN网络结构
Fig. 4 GARAN network structure
下载:
全尺寸图片
图 5 Fer2013数据集中7种表情示例
Fig. 5 Seven emoticons from the Fer2013 dataset
下载:
全尺寸图片
图 6 CK+数据集中7种表情示例
Fig. 6 Seven emoticons from the CK+ dataset
下载:
全尺寸图片
图 7 Fer2013数据集的混淆矩阵
Fig. 7 Confusion matrix of Fer2013 dataset
下载:
全尺寸图片
图 8 CK+数据集的混淆矩阵
Fig. 8 Confusion matrix of CK+ dataset
下载:
全尺寸图片
表 1 网络模型的详细信息
Table 1 Details of the network model
网络层 输出 卷积核 Conv1 112×112×64 7×7, stride=2 Max Pooling 56×56×64 3×3, stride=2 Ghost_Bottleneck1 56×56×256 $\left( \begin{gathered} {\text{Ghost module} } \\ {\text{DWConv} } \\ {\text{Ghost module } }\end{gathered} \right)\times 1$ ARABlock1 56×56×256 Attention×1 续表 1 网络层 输出 卷积核 Ghost_Bottleneck2 28×28×512 $\left( \begin{gathered} {\text{Ghost module } } \\ {\text{ DWConv} } \\ {\text{Ghost module } }\end{gathered} \right)\times 1$ ARABlock2 28×28×512 Attention×1 Ghost_Bottleneck3 14×14×1024 $\left( \begin{gathered} {\text{Ghost module} } \\ {\text{ DWConv} } \\ {\text{Ghost module} } \end{gathered} \right) \times 1$ ARABlock3 14×14×1024 Attention×1 Ghost_Bottleneck4 7×7×2048 $\left( \begin{gathered} {\text{ Ghost module} } \\ {\text{ DWConv } } \\ {\text{ Ghost module} } \end{gathered} \right)\times 3$ Average Pooling 1×1×2048 7×7, stride=1 FC,SoftMax 7 / 表 2 不同模块识别准确率对比
Table 2 Comparison of recognition accuracy of different modules
% 方法 Fer2013 CK+ ResNet50 69.71 95.23 ResNet50 + ARABlock 71.94 97.41 ResNet50 + Ghost_Bottleneck 71.35 96.93 ResNet50 + Ghost_Bottleneck + Mish 71.58 97.35 The Proposed 72.14 98.67 表 3 不同方法在Fer2013数据集上的识别结果
Table 3 Recognition results of different methods on the Fer2013 dataset
-
[1] 贲晛烨, 杨明强, 张鹏, 等. 微表情自动识别综述[J]. 计算机辅助设计与图形学学报, 2014, 26(9): 1385–1395. BEN Xianye, YANG Mingqiang, ZHANG Peng, et al. Survey on automatic micro expression recognition methods[J]. Journal of computer-aided design & computer graphics, 2014, 26(9): 1385–1395. [2] LI Shan, DENG Weihong. Deep facial expression recognition: a survey[J]. IEEE transactions on affective computing, 2022, 13(3): 1195–1215. doi: 10.1109/TAFFC.2020.2981446 [3] WANG Kai, PENG Xiaojiang, YANG Jianfei, et al. Suppressing uncertainties for large-scale facial expression recognition[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 6896−6905. [4] RUAN Delian, YAN Yan, LAI Shenqi, et al. Feature decomposition and reconstruction learning for effective facial expression recognition[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 7656−7665. [5] 李勇, 林小竹, 蒋梦莹. 基于跨连接LeNet-5网络的面部表情识别[J]. 自动化学报, 2018, 44(1): 176–182. LI Yong, LIN Xiaozhu, JIANG Mengying. Facial expression recognition with cross-connect LeNet-5 network[J]. Acta automatica sinica, 2018, 44(1): 176–182. [6] 崔子越, 皮家甜, 陈勇, 等. 结合改进VGGNet和Focal Loss的人脸表情识别[J]. 计算机工程与应用, 2021, 57(19): 171–178. doi: 10.3778/j.issn.1002-8331.2007-0492 CUI Ziyue, PI Jiatian, CHEN Yong, et al. Facial expression recognition combined with improved VGGNet and focal loss[J]. Computer engineering and applications, 2021, 57(19): 171–178. doi: 10.3778/j.issn.1002-8331.2007-0492 [7] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770−778. [8] PHAM L, VU T H, TRAN T A. Facial expression recognition using residual masking network[C]//2020 25th International Conference on Pattern Recognition. Milan: IEEE, 2020: 4513−4519. [9] 高涛, 杨朝晨, 陈婷, 等. 深度多尺度融合注意力残差人脸表情识别网络[J]. 智能系统学报, 2022, 17(2): 393–401. GAO Tao, YANG Zhaochen, CHEN Ting, et al. Deep multiscale fusion attention residual network for facial expression recognition[J]. CAAI transactions on intelligent systems, 2022, 17(2): 393–401. [10] 陈加敏, 徐杨. 注意力金字塔卷积残差网络的表情识别[J]. 计算机工程与应用, 2022, 58(22): 123–131. CHEN Jiamin, XU Yang. Expression Recognition Based on Convolution Residual Network of Attention Pyramid[J]. Computer engineering and applications, 2022, 58(22): 123–131. [11] DUTA I C, LIU LI, ZHU FAN, et al. Pyramidal convolution: rethinking convolutional neural networks for visual recognition[C]//Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020. [12] SANDLER M, HOWARD A, ZHU Menglong, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4510−4520. [13] HAN Kai, WANG Yunhe, TIAN Qi, et al. GhostNet: more features from cheap operations[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 1577−1586. [14] 刘超军, 段喜萍, 谢宝文. 应用GhostNet卷积特征的ECO目标跟踪算法改进[J]. 激光技术, 2022, 46(2): 239–247. LIU Chaojun, DUAN Xiping, XIE Baowen. Improvement of eco target tracking algorithm based on GhostNet convolution feature[J]. Laser technology, 2022, 46(2): 239–247. [15] 符惠桐, 王鹏, 李晓艳, 等. 面向移动目标识别的轻量化网络模型[J]. 西安交通大学学报, 2021, 55(7): 124–131. doi: 10.7652/xjtuxb202107014 FU Huitong, WANG Peng, LI Xiaoyan, et al. Lightweight network model for moving object recognition[J]. Journal of Xi'an Jiaotong university, 2021, 55(7): 124–131. doi: 10.7652/xjtuxb202107014 [16] WANG Fei, JIANG Mengqing, QIAN Chen, et al. Residual attention network for image classification[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6450−6458. [17] MISRA D. Mish: a self regularized non-monotonic neural activation function[EB/OL]. (2020−08−13)[2021−01−01].https://arxiv.org/abs/1908.08681v1. [18] HE Tong, ZHANG Zhi, ZHANG Hang, et al. Bag of tricks for image classification with convolutional neural networks[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 558−567. [19] 崔珂璠, 熊淑华, 陈洪刚, 等. 基于非对称残差注意网络的目标跟踪算法[J]. 微电子学与计算机, 2021, 38(9): 8–16. CUI Kefan, XIONG Shuhua, CHEN Honggang, et al. An object tracking algorithm based on asymmetric residual attention network[J]. Microelectronics & computer, 2021, 38(9): 8–16. [20] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2818−2826. [21] MINAEE S, MINAEI M, ABDOLRASHIDI A. Deep-emotion: facial expression recognition using attentional convolutional network[J]. Sensors, 2021, 21(9): 3046. doi: 10.3390/s21093046 [22] SHI Cuiping, TAN Cong, WANG Liguo. A facial expression recognition method based on a multibranch cross-connection convolutional neural network[J]. IEEE access, 2021, 9: 39255–39274. [23] JUNG H, LEE S, YIM J, et al. Joint fine-tuning in deep neural networks for facial expression recognition[C]//2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 2983−2991. [24] YANG Huiyuan, CIFTCI U, YIN Lijun. Facial expression recognition by de-expression residue learning[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 2168−2177.




