
Dual BERT directed sentiment text classification based on attention mechanism
-
摘要: 在计算社会科学中,理解政治新闻文本中不同政治实体间的情感关系是文本分类领域一项新的研究内容。传统的情感分析方法没有考虑实体之间情感表达的方向,不适用于政治新闻文本领域。针对这一问题,本文提出了一种基于注意力机制的双变换神经网络的双向编码表示(bi-directional encoder representations from transformers, BERT)有向情感文本分类模型。该模型由输入模块、情感分析模块、政治实体方向模块和分类模块四部分组成。情感分析模块和政治实体方向模块具有相同结构,都先采用BERT预训练模型对输入信息进行词嵌入,再采用三层神经网络分别提取实体之间的情感信息和情感方向信息,最后使用注意力机制将两种信息融合,实现对政治新闻文本的分类。在相关数据集上进行实验,结果表明该模型优于现有模型。Abstract: Understanding the emotional relationships between different political entities in political news texts is a new research topic in the text classification field in computational social science. Traditional methods of sentiment analysis cannot be applied to political news texts because they do not consider the direction of emotional expression between entities. This study proposes a dual BERT-directed sentiment text classification model based on the attention mechanism, which consists of four modules: input module, sentiment analysis module, political entity direction module, and classification module. The structure of the sentiment analysis module and the political entity direction module are identical. Both employ the BERT pretraining model to embed the input information, a three-layer neural network to extract the emotional information or emotional direction information between entities, and an attention mechanism to combine these two kinds of information to classify political news texts. Experiments on comparable data sets show that the model outperforms existing models.
-
情感分析是自然语言处理中文本分类领域的一项基本任务,其研究目的是对带有情感色彩的主观性文本进行分析并提取其主要情感。社交媒体上的用户情感分析是情感分析领域的重要组成部分。社交媒体上的用户情感对整个社交媒体舆论风向具有重要的影响,进而会影响整个社会的政治风向。而以前的研究主要应用训练好的模型推断嵌入在各种社交网络和媒体上的文本数据是否包含正面或负面情感[1-3]。同时,衡量新闻媒体中政治文本的情绪或语气是计算社会科学中广泛使用的方法[4]。文献[5-7]使用社交媒体帖子来评估公众对政治行为者的看法,并通过大规模情感分析预测未来事件的结果,而文献[8-10]进一步延伸到非语言或多模态维度。然而目前已有的大多数工作集中在句子级分类[11-14],或旨在检测对特定目标的情感极性[15-16]。而以往的这些方法通常不区分情感的来源和目标。这些方法使用的数据主要使用来自用户生成的内容,如推特评论或来自Yelp的餐厅评论,同时这些方法假设每个用户(账号持有人)都是情绪的来源,并且目标也是明确定义或容易识别(如餐厅评论)的。但是这一假设在政治新闻分析中并不适用,因为很多政治人物在新闻报道中相互指责或相互支持。政治情感分析的关键是识别政治人物责备“谁”或支持“谁”[17],而不是简单地将全局的情感极性分配给指定文件或句子。例如:从“X支持Y批评Z”这句话中,我们可以推断X对Y是积极的,而X和Y都对Z是消极的。但是,现有的情感分析方法并不适合检测实体之间的这种情感关系。针对上述问题,本文提出基于注意力机制的双BERT有向情感文本分类模型,可以有效解决上述问题,提高情感分析的准确性。本研究不仅为自然语言学界的有向情感分析问题提出了解决方法,而且为社会科学界增加了对政治新闻中媒体偏见的实证理解。
1. 理论基础
1.1 BERT预训练模型
变换神经网络的双向编码表示(bi-directional encoder representations from transformers,BERT)模型是由谷歌公司在2018[18]提出的开源模型,它在当时11项自然语言处理任务中夺得最优结果,再一次将自然语言处理推向了浪潮之巅。
BERT相较于原来的循环神经网络(recurrent neural network,RNN)、长短时记忆网络 (long short-term memory,LSTM)可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。相较于之前的预训练模型,BERT能根据句子上下文获取词义信息,从而避免歧义产生。同时BERT能够双向提取词义信息,从而得到更丰富、更隐蔽的特征。BERT模型框架如图1所示。
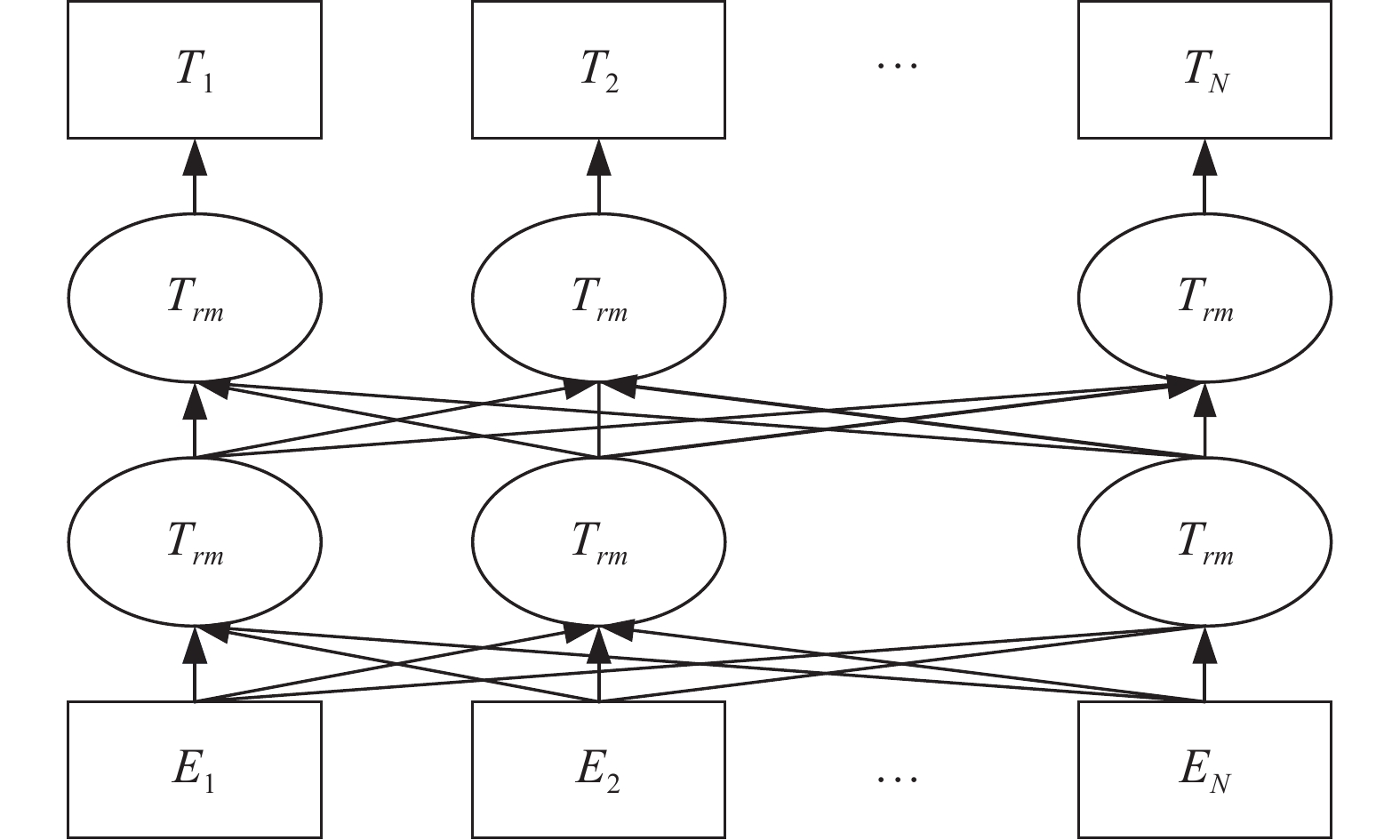 图 1 BERT框架Fig. 1 BERT framework
图 1 BERT框架Fig. 1 BERT framework 下载:
全尺寸图片
下载:
全尺寸图片
BERT先将输入文本中的各个字表示为语义向量,再输入至多个变换神经网络(Transformer)编码器中进行训练,最后得到训练后的词向量。BERT中最重要的结构是 Transformer 编码器,其包含了多头注意力机制、自注意力机制、残差连接、层归一化、线性转换等关键操作,通过这些操作,Transformer编码器能将输入文本中的各个字的语义向量转换为相同长度的增强语义向量,通过多层Transformer 编码器,BERT实现了对文本中的各个字的语义向量的训练。
BERT是一个语言理解模型。BERT采用大规模、与特定自然语言处理(natural language processing, NLP)任务无关的文本语料进行训练,其目标是学习语言本身应该是什么样的,以便理解语言的本质特征。BERT模型的训练过程就是逐渐调整模型参数,使得模型输出的文本语义表示能够刻画语言的本质,便于后续针对具体NLP任务作微调。
1.2 文本情感分析
目前的文本情感分析方法主要包括基于情感词典的方法、基于机器学习的方法和基于深度学习的方法。基于情感词典的方法是文本情感分析的基础,利用文本情感词典,可以对情感词典进行极性和强度标注,进而进行文本情感分类。而构建情感词典有人工构建和自动构建两种方式。但基于词典的文本情感分析技术由于构建的词典往往只针对某个领域,对于跨领域文本分析的效果不够好。基于机器学习的方法首先将文本信息进行特征处理,然后对模型进行有监督学习训练,训练好的模型用于预测新的文本信息的情感极性。根据分类算法不同,基于机器学习的方法可分为朴素贝叶斯、最大熵和支持向量机3种方法。而随着深度学习研究的不断发展,深度学习技术也开始应用于文本情感分析领域。例如,Ma等[19]提出的融合了高维注意力机制的深度学习方法;翟学明等[20]提出的和条件随机场相结合的深度学习方法,在情感分析上都取得了不错的效果。基于深度学习的文本情感分析的过程如图2所示。首先对文本进行预处理,接着将文本词嵌入后得到文本的向量表示。然后通过深度学习模型对文本向量进行计算,最后得到情感分析结果。
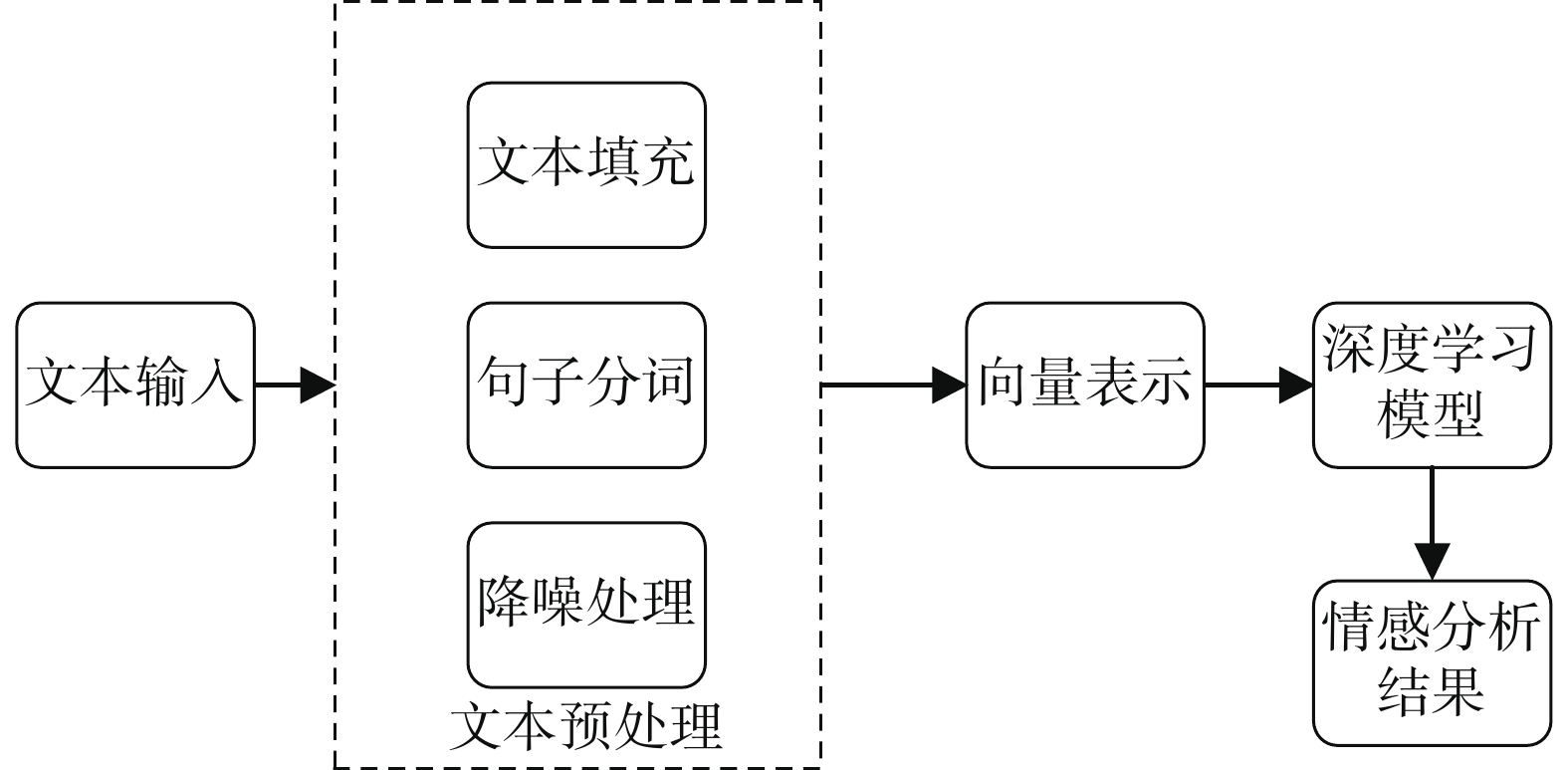 图 2 情感分析过程Fig. 2 Sentiment analysis process diagram下载:
全尺寸图片
图 2 情感分析过程Fig. 2 Sentiment analysis process diagram下载:
全尺寸图片
2. 基于注意力机制的双BERT有向情感文本分类模型
本文提出的基于注意力机制的双BERT有向情感分类模型结构如图3所示。其主要由输入模块、情感分析模块、政治实体方向模块和分类模块组成。输入政治新闻文本到输入模块后,在情感分析模块获得文本中政治实体的情感特征,在政治实体方向模块提取文本中政治实体的方向特征,然后,两种特征输入至分类模块中,最后通过政治实体间有向情感预测文本类别。本文提出的模型中的政治实体方向模块和情感分析模块采用相同的结构,提取不同的特征,两个模块都包含基于BERT的词嵌入层和编码层。分类模块则包含转换层、融合层以及分类层。
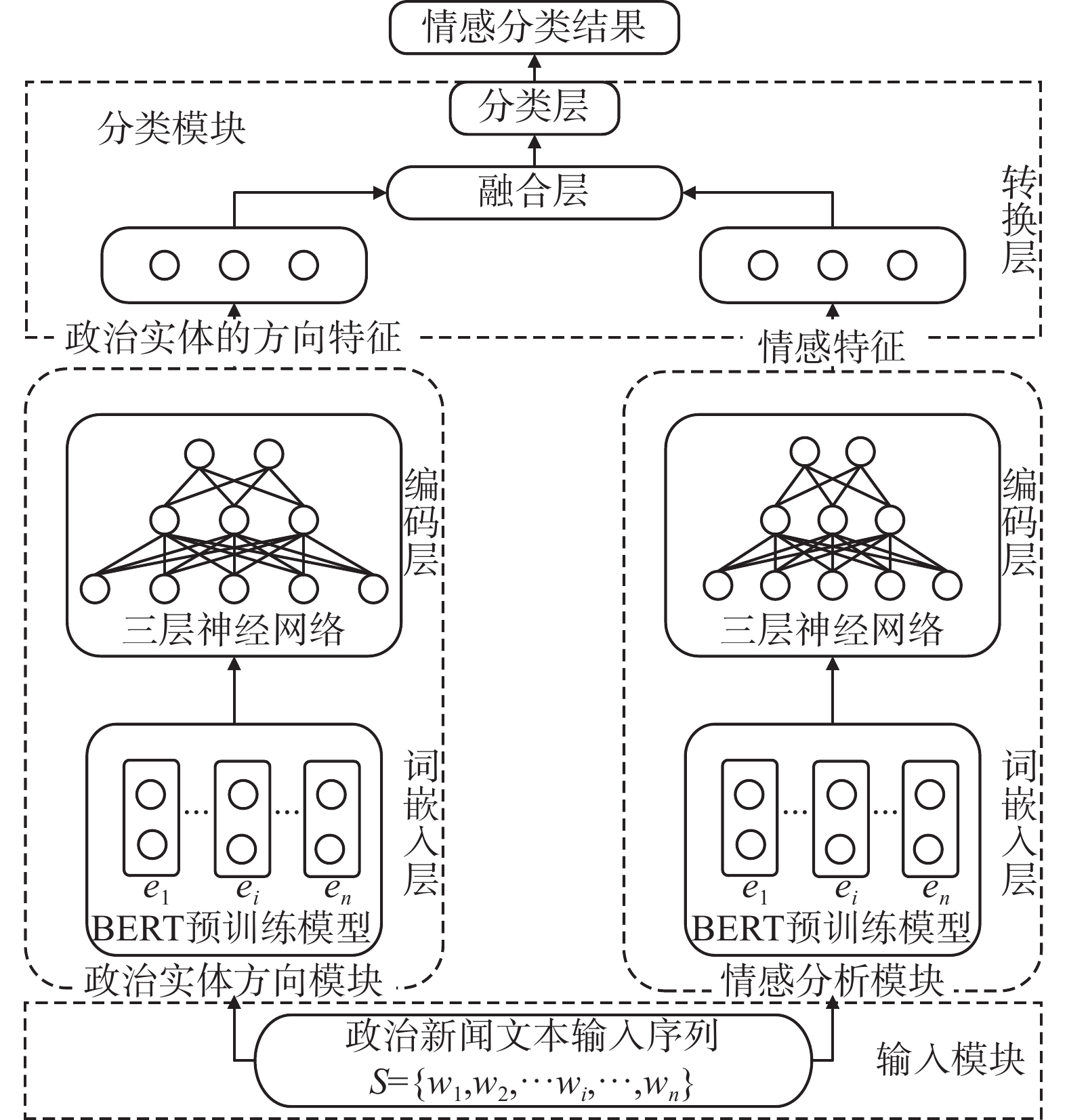 图 3 基于注意力机制的双BERT有向情感分类模型Fig. 3 Analysis model of a dual BERT directed sentiment based on attention mechanism下载:
全尺寸图片
图 3 基于注意力机制的双BERT有向情感分类模型Fig. 3 Analysis model of a dual BERT directed sentiment based on attention mechanism下载:
全尺寸图片
2.1 输入模块
对政治实体方向模块和情感分析模块,输入模块输入的输入序列都为数据集中的一批句子序列,表示为
$S^N $ , N表示批处理大小。其中一个句子可以表示为$S_j^N = \{ {w_{j1}},{w_{j2}}, \cdots ,{w_{ji}}, \cdots ,{w_{jn}}\} $ ,j表示这批政治新闻文本句子中的第j个句子,${w_{ji}}$ 表示第j个句子中的第i个词汇, n为句子长度。2.2 词嵌入层
BERT模型在多个自然语言处理任务中取得了巨大成功,并被应用于文本情感分析。为了获取文本中政治实体间的情感特征和方向特征,本文使用BERT预训练模型将文本中的单词从低维空间一一映射到多维空间中,与之前的Glove预训练模型提供的词嵌入矩阵相比,BERT预训练模型提供了一个更大的语言理解模型,能获得更好的语义信息。
在BERT预训练模型之前的大多数预训练模型都是提供一个转换矩阵M,
${\boldsymbol{M}} \in {{\bf{R}}^{Vd}}$ ,其中V是词汇表中单词的总数,d是单词转换后的维度,通过转换矩阵M,可将文本序列中的任一单词wi转换为维数为d的数字向量,方便之后的数学计算。相较于Glove模型的转换矩阵参数不变,BERT预训练模型旨在通过联合调节所有层中的上下文,来预先训练单词的深度双向表示。本模型使用2个互相独立的BERT预训练模型分别获取文本序列的政治实体方向词嵌入和情感词嵌入,再分别输入至政治实体方向模块和情感分析模块中的编码层中,以此提高此模型对政治新闻文本的有向情感分析能力。本文分别使用政治实体方向数据和情感数据训练这两个BERT预训练模型,让本模型更好地获得文本序列的政治实体方向词嵌入和情感词嵌入。而本模型中BERT预训练模型的输入为经过随机初始化和分词处理后的文本序列$S^N $ 的各个词的原始词向量。2.3 编码层
编码层的任务是将经过词嵌入层转换后的嵌入向量编码成含有丰富上下文语义信息的序列向量。词嵌入本身包含基础语言信息,通过多层神经网络对词嵌入信息进行恰当缩放与聚合,有效聚合了上下文信息,即减少了计算消耗所需的资源,又能够有效提高计算的效率。
编码层采用三层神经网络对词嵌入向量进行编码。输入层输入维度为词嵌入层嵌入维度,隐藏层维度为512,输出层输出维度为3。政治实体方向模块和情感分析模块的训练目标不同,其他基本相同。政治实体方向模块训练目标为0,1(p→q),2(p←q),p、q为政治新闻文本中的两个实体对象, 情感分析模块训练目标为0(中性)、1(积极)、2(消极)。
三层神经网络在隐藏层与输出层之间使用ReLU激活函数,增强神经网络模型的非线性,相比其他激活函数,ReLU激活函数可以加快训练速度。
2.4 转换层
转换层主要利用线性转换的方法对情感特征和政治实体的方向特征进行变长计算。转换层的结构如图4所示。
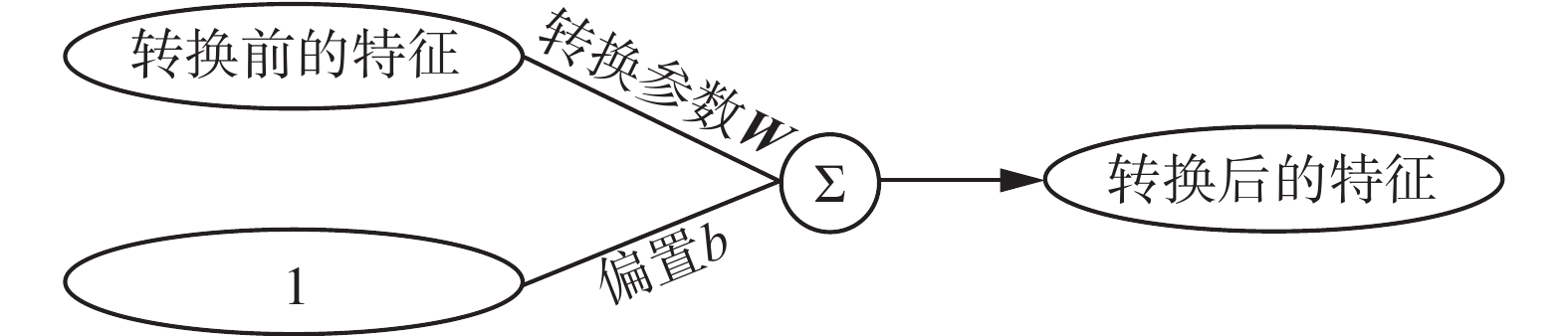 图 4 转换层结构Fig. 4 Transfer layer structure下载:
全尺寸图片
图 4 转换层结构Fig. 4 Transfer layer structure下载:
全尺寸图片
如果用ht-1和bt-1代表进入转换层之前的情感特征和政治实体的方向特征,用W1和W2代表转换参数,b1和b2代表偏置,ht和bt代表转换之后的情感特征和政治实体的方向特征,则转换层计算公式为
$$ {{h_t = }}{\boldsymbol{W}}_1{h_{t-1}}{{ + b}}_1 $$ $$ b_t = {\boldsymbol{W}}_2{b_{t - 1}} + b_2 $$ 2.5 融合层
本层的任务是将转换层得到的相同长度的情感特征和政治实体的方向特征融合在一起,为分类层的分类做准备。
本模型主要利用注意力机制[21]融合文本的情感特征向量h和政治实体的方向特征向量b,并计算两者的注意力分数a。注意力机制源于人类会选择性地关注所有信息的关键部分,同时忽略其他可见的信息。本文使用的注意力机制为改进的缩放点积注意力机制。改进的缩放点积注意力机制结构图如图5所示。
 图 5 改进的缩放点积注意力机制Fig. 5 Improved scaled dot-product attention下载:
全尺寸图片
图 5 改进的缩放点积注意力机制Fig. 5 Improved scaled dot-product attention下载:
全尺寸图片
该注意力机制计算时首先将情感特征h和政治实体的方向特征b相乘,接着进行缩放操作即除以情感特征h和政治实体的方向特征b的长度,得到的结果可以选择是否进行mask操作,然后进行softmax计算。最后将该结果与政治实体的方向特征b再次进行点乘计算后得到情感特征h和政治实体的方向特征b的注意力分数a。此过程计算公式为
$$ a({\boldsymbol{h}},{\boldsymbol{b}}) = {\rm softmax}\left(\frac{{{\boldsymbol{hb}}}}{{\sqrt d }}\right){\boldsymbol{b}} $$ 式中d为情感特征h和政治实体的方向特征b的长度。
2.6 分类层
本模型将注意力分数a视为政治文本领域识别政治实体之间的有向情感所依据的最终特征,通过一个线性网络将其映射到任务所要求的结果空间,并使用softmax来计算政治实体之间的有向情感态度为y的可能性:
$$ y = {\rm softmax} \left( {{\boldsymbol{W}}a\left( {{\boldsymbol{h}},{\boldsymbol{b}}} \right) + l} \right) $$ 式中:W是将向量映射到输出真空的矩阵;l是偏差。模型训练的目的是使真实值与预测值之间的交叉熵损失最小,交叉熵损失函数为
$$ {\text{Loss}} = - ({{\boldsymbol{g}}_i}\ln y + (1 - {{\boldsymbol{g}}_i})\ln (1 - y)) $$ 式中:
${{\boldsymbol{g}}_i}$ 是标签的向量表示;$ y $ 为真实样本标签。3. 实验结果与分析
3.1 实验数据集
本文在Park等[22]提供的数据集上进行了实验验证。数据集中的单一数据包含一个有两个实体p和q的句子S,以及一项情感关系分类标签,目的是检测从p到q之间的不同方向情感关系。数据集详情如表1所示。训练集与测试集之比为9∶1。
表 1 数据集参数Table 1 Parameters to the data set模型 数据量 中性 10604 积极(p→q) 1656 积极(p←q) 327 消极(p→q) 3163 消极(p←q) 478 总数 16228 为验证提出模型的有效性,本文与下述模型进行了对比。
1) FastText[23]是Facebook2016年提出的文本分类模型,是一种高效的浅层网络。
2)卷积神经网络[24](convolutional neural networks,CNN),是深度学习的代表算法之一。
3)循环神经网络[25](recurrent neural network, RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络。
4)融合注意力机制的循环神经网络(RNN_Att),它根据注意力机制构建注意力权重,取得了不错的效果。
5) Transformer[21]模型,其主要由注意力机制构成。
6) LNZ模型,是由Liang等[26]提出的当前最先进的方向过错检测方法。
7) RoBERTa是由Facebook[27]提出的对BERT模型的改进模型。
8) DSE2QA是由Park等[22]提出的最新模型。
3.2 模型设置
本文输入序列文本长度设置为125,如果文本长度超过125,那么截断;反之,则补零。本文中所有BERT模型选用uncased-BERT-base,词嵌入的维度为 768。转换层输出维度为125×768。
在训练过程中,本文利用Adam作为目标函数的优化器,分层设置学习率,BERT词嵌入层学习率设为0.00002,其他层学习率设为0.000001,同时对学习率进行预热操作。损失函数为交叉熵损失函数,训练批次大小为40,dropout在注意力机制中设为0.2,在情感分析模型、政治实体方向模型中设为0.5。
本文使用装有NVIDIA RTX 3090显卡的服务器运行实验程序,文中的所有的实验模型使用pytorch框架和Jutyper Notebook编写。
3.3 实验结果
本文使用3种指标对实验结果进行评价:Micro-F1、Macro-F1和平均精度(mAP)。
对于多分类数据预测结果有4种情况:
真阳性TP:预测为正,实际为正。
假阳性FP:预测为正,实际为负。
假阴性FN:预测为负,实际为正。
真阴性TN:预测为负,实际为负。
准确率P计算公式为
$$ P = {\text{TP}}/({\text{TP + FP}}) $$ 召回率R计算公式为
$$ R = {\text{TP(TP + FN)}} $$ F1-score计算公式为
$$ {{{F}}_{\text{1}}}{\text{-score}} = 2PR/(P + R) $$ Micro-F1先计算总体的TP、FP、FN和FP,再计算F1-score。Macro-F1分别计算每个类别的F1-score,然后做平均。因此,Macro-F1是对倾斜类分布(如本文使用的数据)的更健壮的度量方法。同时,mAP测量每个类别的平均精度(AP)的未加权平均值,AP为各个类别准确率-召回率曲线下的面积。对比实验结果如表2、3所示,部分实验结果来自文献[22],实验的最优结果加粗表示。
表 2 实验结果对比Table 2 Comparison of experimental results模型 Micro-F1 Macro-F1 mAP FastText 0.2148 0.2041 0.2720 CNN 0.3258 0.1570 0.4509 RNN 0.1360 0.1580 0.2047 RNN_Att 0.2109 0.2085 0.2796 Transformer 0.6177 0.3277 0.3822 LNZ(EntityPrior) 0.5833 0.4063 0.4140 LNZ(Context) 0.6371 0.4665 0.4291 LNZ(Combined) 0.7055 0.5358 0.5295 RoBERTa 0.7486 0.6409 0.7319 DSE2QA(Complete) 0.7726 0.6617 0.7387 DSE2QA(Pseudo) 0.7973 0.6766 0.7488 本文模型 0.8030 0.6845 0.7466 表2给出了每个模型的Micro-F1、Macro-F1、mAP,对比发现,本文提出的模型的Micro-F1比传统Transformer提高了18.53%,比DSE2QA (Pseudo)提高了0.57%。同时,本文提出的模型的Macro-F1比传统Transformer提高了35.68%,比DSE2QA (Pseudo)提高了0.79%。说明本文模型与经典神经网络模型以及最新模型相比,在政治新闻文本的有向情感分析任务上确实具有更好的效果。而在mAP指标上,本文提出模型的mAP与DSE2QA (Pseudo)大致相当。
在表3中,0、1、2、3、4分别代表了两个实体p和q之间不同的有向情感类别。具体为:0表示中性;1表示积极(p→q);2表示积极(p←q);3表示消极(p→q);4表示消极(p←q)。同时,表3给出了不同模型的每个类别的F1-score评分。本文模型与其他模型相比在各个类别上的F1-score均表现出了优秀的性能。相比于性能较好的DSE2QA (Pseudo)模型,本文模型在类别0上提高了2.49%,在类别1上提高了0.184%,在类别3上提高了0.12%,在类别4上提高了1.11%,只在类别2上降低了3.66%。实验说明,本文模型与其他模型相比,对政治新闻文本的各项有向情感都具有更好的识别能力。
表 3 各个类别F1-scoreTable 3 F1-score for each category模型 0 1 2 3 4 FastText 0.7906 0 0 0.2297 0 CNN 0.0497 0.3871 0 0.3484 0 RNN 0.7902 0 0 0 0 RNN_Att 0.6380 0 0 0.4046 0 Transformer 0.6404 0.3030 0.1143 0.3993 0.1818 LNZ(EntityPrior) 0.7133 0.2629 0.2353 0.4533 0.3667 LNZ(Context) 0.7469 0.4069 0.2817 0.5007 0.3964 LNZ(Combined) 0.7981 0.443 0.3333 0.5827 0.5217 RoBERTa 0.8054 0.6373 0.5079 0.7184 0.5354 DSE2QA(Complete) 0.8293 0.6421 0.5672 0.7416 0.5283 DSE2QA(Pseudo) 0.8550 0.6519 0.5672 0.7402 0.5686 本文模型 0.8799 0.6531 0.5306 0.7513 0.6076 3.4 消融实验
为验证模型中主要模块设计的合理性和有效性,本文进行了消融实验:
1)直接将模型中的政治间实体的方向特征和情感特征拼接融合,而不使用注意力机制,此设置为模型1;
2)去掉模型中的情感分析模块,使用政治实体的方向特征代替情感特征,此设置为模型2;
3)去掉模型中的政治实体方向模块,使用政治实体的情感特征代替方向特征,此设置为模型3。
实验结果如表4所示,实验的最优结果加粗表示。
表 4 消融实验Table 4 Ablation experiment模型 Micro-F1 Macro-F1 mAP 模型1 0.7742 0.6786 0.6887 模型2 0.4269 0.4294 0.4009 模型3 0.4279 0.3844 0.3905 本文模型 0.8030 0.6845 0.7466 从表4中可以看到,缺少任一功能模块,尤其是去掉情感分析模块或政治实体方向模块后,模型的效果都将有着明显的下降。其原因是:这两种模块在整个模型中相辅相成,情感分析模块能够获取政治实体间的情感特征却缺乏对方向信息的提取,政治实体方向模块则相反,可以获取政治实体间的情感方向却难以获得情感信息。两个模块对整个模型十分关键,缺一不可。而注意力机制则实现了对政治实体的方向特征和情感特征的有效融合,提升了模型识别政治新闻有向情感的能力。
通过上述消融实验,说明本模型中的各个模块可以实现对政治文本的准确分类,缺一不可。
4. 结束语
在本文中,针对当前政治新闻文本分类研究中存在的不足,设计了基于注意力机制的双BERT有向情感文本分类模型,该模型通过情感分析模块、政治实体方向模块,既能捕捉到政治实体间的情感信息,还能有目的性地识别出情感间的方向信息。该模型将BERT 预训练语言模型与改进的缩放点积注意力机制相结合,能够有效提取政治新闻文本中的有向情感特征。实验证明,本文提出的模型在相应的数据集上取得了最优的效果,并通过消融实验验证了模型的合理性和有效性。
尽管本文提出的模型在数据集上取得了不错的表现,但它仍存在一定的提升空间,可以进一步优化模型结构,让模型适应没有标签或小样本的数据集。下一步工作是,改变模型中编码层的结构,优化模型计算方法,降低模型中的参数量,提高模型计算效率,减少模型计算时消耗的资源,并有效提升模型对政治新闻文本中不同政治实体间有向情感的识别能力。
-
图 1 BERT框架
Fig. 1 BERT framework
下载:
全尺寸图片
图 2 情感分析过程
Fig. 2 Sentiment analysis process diagram
下载:
全尺寸图片
图 3 基于注意力机制的双BERT有向情感分类模型
Fig. 3 Analysis model of a dual BERT directed sentiment based on attention mechanism
下载:
全尺寸图片
图 4 转换层结构
Fig. 4 Transfer layer structure
下载:
全尺寸图片
图 5 改进的缩放点积注意力机制
Fig. 5 Improved scaled dot-product attention
下载:
全尺寸图片
表 1 数据集参数
Table 1 Parameters to the data set
模型 数据量 中性 10604 积极(p→q) 1656 积极(p←q) 327 消极(p→q) 3163 消极(p←q) 478 总数 16228 表 2 实验结果对比
Table 2 Comparison of experimental results
模型 Micro-F1 Macro-F1 mAP FastText 0.2148 0.2041 0.2720 CNN 0.3258 0.1570 0.4509 RNN 0.1360 0.1580 0.2047 RNN_Att 0.2109 0.2085 0.2796 Transformer 0.6177 0.3277 0.3822 LNZ(EntityPrior) 0.5833 0.4063 0.4140 LNZ(Context) 0.6371 0.4665 0.4291 LNZ(Combined) 0.7055 0.5358 0.5295 RoBERTa 0.7486 0.6409 0.7319 DSE2QA(Complete) 0.7726 0.6617 0.7387 DSE2QA(Pseudo) 0.7973 0.6766 0.7488 本文模型 0.8030 0.6845 0.7466 表 3 各个类别F1-score
Table 3 F1-score for each category
模型 0 1 2 3 4 FastText 0.7906 0 0 0.2297 0 CNN 0.0497 0.3871 0 0.3484 0 RNN 0.7902 0 0 0 0 RNN_Att 0.6380 0 0 0.4046 0 Transformer 0.6404 0.3030 0.1143 0.3993 0.1818 LNZ(EntityPrior) 0.7133 0.2629 0.2353 0.4533 0.3667 LNZ(Context) 0.7469 0.4069 0.2817 0.5007 0.3964 LNZ(Combined) 0.7981 0.443 0.3333 0.5827 0.5217 RoBERTa 0.8054 0.6373 0.5079 0.7184 0.5354 DSE2QA(Complete) 0.8293 0.6421 0.5672 0.7416 0.5283 DSE2QA(Pseudo) 0.8550 0.6519 0.5672 0.7402 0.5686 本文模型 0.8799 0.6531 0.5306 0.7513 0.6076 表 4 消融实验
Table 4 Ablation experiment
模型 Micro-F1 Macro-F1 mAP 模型1 0.7742 0.6786 0.6887 模型2 0.4269 0.4294 0.4009 模型3 0.4279 0.3844 0.3905 本文模型 0.8030 0.6845 0.7466 -
[1] BING Liu. Sentiment analysis and opinion mining[M]. Switzerland: Springer Cham, 2012. [2] HUTTO C, GILBERT E. Vader: a parsimonious rule-based model for sentiment analysis of social media text[C]//Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media. Michigan: AAAI, 2014: 216−225. [3] PARK K, CHA M, RHIM E. Positivity bias in customer satisfaction ratings[C]//WWW’18: Companion Proceedings of the The Web Conference 2018. New York: ACM, 2018: 631−638. [4] YOUNG L, SOROKA S. Affective news: the automated coding of sentiment in political texts[J]. Political communication, 2012, 29(2): 205–231. doi: 10.1080/10584609.2012.671234 [5] O’CONNOR B, BALASUBRAMANYAN R, ROUTLEDGE B R, et al. From tweets to polls: linking text sentiment to public opinion time series[C]//Fourth International AAAI Conference on Weblogs and Social Media. Washington: AAAI, 2010: 122−129. [6] CERON A, CURINI L, IACUS S M, et al. Every tweet counts? How sentiment analysis of social media can improve our knowledge of citizens’ political preferences with an application to Italy and France[J]. New media & society, 2014, 16(2): 340–358. [7] UNANKARD S, LI Xue, SHARAF M, et al. Predicting elections from social networks based on sub-event detection and sentiment analysis[M]//Web Information Systems Engineering-WISE 2014. Cham: Springer International Publishing, 2014: 1−16. [8] JOO J, LI Weixin, STEEN F F, et al. Visual persuasion: inferring communicative intents of images[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 216−223. [9] XUE Di, HONG Zheng, GUO Shize, et al. Personality recognition on social media with label distribution learning[J]. IEEE access, 2017, 5: 13478–13488. doi: 10.1109/ACCESS.2017.2719018 [10] CHEN Danni, PARK K, JOO J. Understanding gender stereotypes and electoral success from visual self-presentations of politicians in social media[C]// Joint Workshop on Aesthetic and Technical Quality Assessment of Multimedia and Media Analytics for Societal Trends. New York: ACM, 2020: 21−25. [11] 蔡庆平, 马海群. 基于Word2Vec和CNN的产品评论细粒度情感分析模型[J]. 图书情报工作, 2020, 64(6): 49–58. CAI Qingping, MA Haiqun. A fine-grained sentiment analysis model for product reviews based on Word2Vec and CNN[J]. Library and information service, 2020, 64(6): 49–58. [12] 张宜浩, 朱小飞, 徐传运, 等. 基于用户评论的深度情感分析和多视图协同融合的混合推荐方法[J]. 计算机学报, 2019, 42(6): 1316–1333. doi: 10.11897/SP.J.1016.2019.01316 ZHANG Yihao, ZHU Xiaofei, XU Chuanyun, et al. Hybrid recommendation approach based on deep sentiment analysis of user reviews and multi-view collaborative fusion[J]. Chinese journal of computers, 2019, 42(6): 1316–1333. doi: 10.11897/SP.J.1016.2019.01316 [13] VAN HEE C, LEFEVER E, HOSTE V. SemEval-2018 task 3: irony detection in English tweets[C]//Proceedings of The 12th International Workshop on Semantic Evaluation. New Orleans: ACM, 2018: 39−50. [14] ZAMPIERI M, MALMASI S, NAKOV P, et al. Predicting the type and target of offensive posts in social media[C]//Proceedings of the 2019 Conference of the North. Minneapolis: ACL, 2019: 1415–1420. [15] CHE Wanxiang, ZHAO Yanyan, GUO Honglei, et al. Sentence compression for aspect-based sentiment analysis[J]. IEEE-ACM transactions on audio speech and language processing, 2015, 23(12): 2111–2124. doi: 10.1109/TASLP.2015.2443982 [16] CORTIS K, FREITAS A, DAUDERT T, et al. Semeval-2017 task 5: fine-grained sentiment analysis on financial microblogs and news[C]//Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). Vancouver: ACL, 2017: 519−535. [17] BALAHUR A, STEINBERGER R, KABADJOV M, et al. Sentiment analysis in the news[EB/OL]. (2013−09−24)[ 2021−12−18].https://arxiv.org/abs/1309.6202. [18] DEVLIN J, CHANG MING-WEI, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2018−10−11)[ 2021−12−18].https://arxiv.org/abs/1810.04805. [19] MA Dehong, LI Sujian, ZHANG Xiaodong, et al. Interactive attention networks for aspect-level sentiment classification[EB/OL]. (2017−09−04)[ 2021−12−18].https://arxiv.org/abs/1709.00893. [20] 翟学明, 魏巍. 混合神经网络和条件随机场相结合的文本情感分析[J]. 智能系统学报, 2021, 16(2): 202–209. ZHAI Xueming, WEI Wei. Text sentiment analysis combining hybrid neural network and conditional random field[J]. CAAI transactions on intelligent systems, 2021, 16(2): 202–209. [21] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Conference and Workshop on Neural Information Processing Systems. Long Beach: MIT, 2017: 5998−6008. [22] PARK K, PAN ZHUFENG, JOO J. Who blames or endorses whom? entity-to-entity directed sentiment extraction in news text[EB/OL]. (2021−06−02)[2021−12−18].https://arxiv.org/abs/2106.01033. [23] JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of tricks for efficient text classification[EB/OL]. (2016−07−06)[2021−12−18].https://arxiv.org/abs/1607.01759. [24] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]//NIPS’12: Proceedings of the 25th International Conference on Neural Information Processing Systems-Volume 1. New York: ACM, 2012: 1097−1105. [25] ZAREMBA W, SUTSKEVER I, VINYALS O. Recurrent neural network regularization[EB/OL]. (2014−09−08)[2021−12−18].https://arxiv.org/abs/1409.2329. [26] LIANG Shuailong, NICOL O, ZHANG Yue. Who blames whom in a crisis? detecting blame ties from news articles using neural networks[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu: AAAI, 2019: 655−662. [27] LIU Yinhan, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. (2019−07−26)[2021−12−18].https://arxiv.org/abs/1907.11692.















