
Energy-saving process route discovery method based on deep reinforcement learning
-
摘要: 由于传统基于固定加工环境的工艺路线制定规则,无法快速响应加工环境的动态变化制定节能工艺路线。因此提出了基于深度Q网络(deep Q network,DQN)的节能工艺路线发现方法。基于马尔可夫决策过程,定义状态向量、动作空间、奖励函数,建立节能工艺路线模型,并将加工环境动态变化的节能工艺路线规划问题,转化为DQN智能体决策问题,利用决策经验的可复用性和可扩展性,进行求解,同时为了提高DQN的收敛速度和解的质量,提出了基于S函数探索机制和加权经验池,并使用了双Q网络。仿真结果表明,相比较改进前,改进后的算法在动态加工环境中能够更快更好地发现节能工艺路线;与遗传算法、模拟退火算法以及粒子群算法相比,改进后的算法不仅能够以最快地速度发现节能工艺路线,而且能得到相同甚至更高精度的解。Abstract: Due to the traditional process route formulation rules based on the fixed processing environment, it is unable to quickly respond to the dynamic changes of the processing environment to formulate energy-saving process routes. Therefore, an energy-saving process route discovery method based on deep Q network (DQN) is proposed in this paper. Based on the Markov decision process, we define the state vector, action space, and reward function, establish an energy-saving process route model, and transform the energy-saving process route planning problem with dynamic changes in the processing environment into a DQN agent decision-making problem, which uses the reusable and extensible decision-making experience to solve the problem. At the same time, an exploration mechanism based on the S function, a weighted experience pool, and a double-Q network are used to improve the convergence speed and solution quality of DQN. The simulation results show that compared with that before improvement, the improved algorithm can find energy-saving process routes faster and better in the dynamic processing environment; and compared with genetic algorithm, simulated annealing algorithm, as well as particle swarm algorithm, the improved algorithm can not only discover energy-saving process routes at the fastest speed, but also obtain the same or even higher precision solutions.
-
工艺路线表述了零件在加工过程中所使用的加工资源以及特征的加工顺序等。针对某一零件,如何在满足工艺约束等条件下,寻找目标工艺路线,即是工艺路线规划所需要解决的问题。目前对工艺路线规划的研究主要分为两类:知识驱动的工艺路线规划,基于启发式算法的工艺路线规划。
基于知识驱动的工艺路线规划方法,利用知识专家系统来推理出合理的工艺路线,虽然提高了工艺路线规划的可行性,但是无法保证获得的解能逼近全局最优,于是众多专家学者将目光转向启发式算法。
启发式算法能够很好地逼近全局最优解,主要算法包括:遗传算法[1-3]、模拟退火算法[4-5]、粒子群算法[6-7]等。其中遗传算法广泛应用于工艺路线规划,Vafadar等[8]利用遗传算法来寻找机器的最优工艺参数和刀具配置,进行工艺路线规划。Wu等[9]将和谐搜索和遗传算法相结合,利用遗传算法来确定机器的分配和操作顺序,从而解决工艺路线规划问题。Ma等[10]借助模拟退火算法来解决多约束工艺路线规划问题,该算法考虑了各零件特征之间的约束关系,实验证明,模拟退火算法的全局搜索能力强于遗传算法。启发式算法的解虽然能够逼近全局最优解,但是其先前获得的解对加工环境发送变化的工艺路线搜索没有帮助,需重新规划,无法在加工环境发生变化时快速响应。因此,针对加工环境动态变化的场景,需要一种具有基于学习的、动态决策的工艺路线规划方法,能够以响应式的处理方式进行工艺路线规划。
深度强化学习(deep reinforcement learning, DRL)由强化学习和神经网络组成,已经在多个领域取得了优异的成绩。在飞行领域,DRL实现了多机协同[11-12];在交通领域,DRL提高车辆在交通路口的通过效率[13-15];在机器人领域,DRL提高准被动双足机器人斜坡步行稳定性[16],加快了机器人数据学习速率[17];在游戏领域,由DRL实现的AlphaGO[18]、AlphaStar[19]、OpenAIFive[20]分别在游戏围棋、星际争霸 II、Dota 2 中战胜了代表人类最高水平的玩家。
深度Q网络(deep Q-network, DQN)作为DRL的一员,由Q-Learning和神经网络组成[21],具有当加工环境动态变化时工艺路线动态决策的潜力,具体理由如下:1) DQN是一种基于奖励的直面对象的决策方法,在处理具有约束的工艺路线时,能够在离散可行域中获得高质量的解;2) DQN通过计算状态值或动作价值函数,以网络参数的形式存储和显示顺序决策的结构特征,能够在处理具有相同决策结构特征的工艺路线规划时,利用先前存储的策略知识,不仅提高DQN的决策速度,而且使得其具有可扩展性和可重用性;3) DQN基于马尔可夫决策过程(Markov decision process, MDP)建立模型,并不需要复杂的数学推导。
因此,针对基于知识驱动的工艺路线规划无法逼近全局最优,启发式算法无法快速响应加工环境动态变化的问题,考虑到DQN在解决加工环境动态变化时工艺路线规划的潜力,因此本文将DQN应用于工艺路线规划,提出了基于DQN的节能工艺路线规划方法。
1. 基于MDP节能工艺路线建模
本节基于MDP建立节能工艺路线模型。首先介绍了工艺路线特征、工艺路线−能耗关联模型,接着结合MDP在工艺路线规划下的含义,分别定义状态向量、动作空间以及奖励函数。
1.1 工艺路线特征描述
在制定零件的工艺路线时,需要考虑零件特征之间的工序约束,例如先面后孔。先粗后细、先基准后其他、夹具要求等。
针对零件特征间的工序约束,本文设计了特征约束矩阵
${{{\boldsymbol{P}}}_{{\text{RE}}}}$ ,来处理零件特征的约束问题。零件P的${{{\boldsymbol{P}}}_{{\text{RE}}}}$ 定义为$$ {{{\boldsymbol{P}}}_{{\text{RE}}}}(P) = {\left[ {{p_{{\text{re}}}}(p,q)} \right]_{n \times n}} $$ 式中:n表示加工零件的特征数,
${p_{{\text{re}}}}(p,q)$ 表示约束矩阵的第p行、第q列的值。${p_{{\text{re}}}}(p,q) = 1$ 表示特征Fp+1先于特征Fq+1加工,${p_{{\text{re}}}}(p,q) = 0$ 表示特征Fp+1、Fq+1没有约束关系。在解决了零件特征之间的约束后,将从现有的加工资源下,为特征选取具体的操作。操作由机床、刀具、进刀方向组成,同一操作由于机床、刀具、进刀方向的不同,可组合成多个选项,而这些选项则构成了操作集合,Ci表示为操作Oi的操作集合,定义为
$$ {C_i} = \left\{ {{c_{i1}},{c_{i2}}, \cdots ,{c_{ij}}, \cdots, {c_{ip}}} \right\} $$ 式中cij表示Opi的第j个选项。在工艺路线规划中,Oi有且仅能从Ci中选取一个c。cij定义为
$$ {c_{ij}} = \left\{ {{m_{ij}},{t_{ij}},{s_{ij}}} \right\} $$ 式中:mij、tij、sij分别表示Ci的第j个选项中的机床、刀具以及进刀方向。
1.2 工艺路线–能耗关联模型
工艺路线总能耗TEC定义为
$$ {T_{{\text{EC}}}} = {D_{{\text{EC}}}} + {T_{{\text{CEC}}}} $$ 式中:DEC表示设备能耗,TCEC表示总切换能耗。
1) 设备能耗
DEC由加工零件P时所用设备的总能耗组成,定义为
$$ {D_{{\text{EC}}}} = {M_C} + {T_C} $$ 式中:MC、TC分别表示加工零件P时,机床、刀具消耗的总能量。
MC、TC定义分别为
$$ {M_C} = \sum\limits_{i = 1}^t {M_{C_i}} $$ $$ {T_C} = \sum\limits_{i = 1}^t {{T_{C_i}}} $$ 式中:t表示零件P的操作个数;
${M_{C_i}}$ 、${T_{C_i}}$ 分别表示执行第i个操作时,机床、刀具消耗的能量。2) 总切换能耗
在执行当前操作b前,由于切换了加工资源,与上一操作a所使用的加工资源不同,进而产生了切换能耗CEC,定义为
$$ {C_{{\text{E}}{{\text{C}}_{ab}}}} = {M_{{\text{C}}{{\text{E}}_{ab}}}} + {T_{{\text{C}}{{\text{E}}_{ab}}}} + {D_{{\text{C}}{{\text{E}}_{ab}}}} $$ 式中:
${M_{{\text{C}}{{\text{E}}_{ab}}}}$ 表示机床切换能耗,${T_{{\text{C}}{{\text{E}}_{ab}}}}$ 表示刀具切换能耗,${D_{{\text{C}}{{\text{E}}_{ab}}}}$ 表示进刀方向切换能耗。机床切换能耗定义为
$$ {M_{{\text{C}}{{\text{E}}_{ab}}}} = {\varOmega _1}({m_a},{m_b}) \cdot {E^{{\text{mc}}}} $$ 式中:Emc表示切换机床时所消耗的能量,ma、mb分别表示操作a、b所选择的机床,
${\varOmega _1}(X,Y) = \left\{ \begin{gathered} 1,{\text{ }}X \ne Y \\ 0,{\text{ }}X{\text{ = }}Y \\ \end{gathered} \right.$ 。刀具切换能耗计算公式为
$$ {T_{{\text{C}}{{\text{E}}_{ab}}}} = {\varOmega _1}({t_a},{t_b}) \cdot {{{\varOmega }}_2}({m_a},{m_b}) \cdot {E^{{\text{tc}}}} $$ 式中:Etc表示切换刀具所消耗的能量,ta、tb分别表示操作a、b所选择的刀具,
${\varOmega _2}(X,Y) = \left\{ \begin{gathered} 1,{\text{ }}X{\text{ }} = {\text{ }}Y \\ 0,{\text{ }}X \ne Y \\ \end{gathered} \right.$ 。进刀方向切换能耗为
$$ {D_{{{\rm{CE}}_{ab}}}} = {\varOmega _1}({d_a},{d_b}) \cdot {\varOmega _2}({m_a},{m_b}) \cdot {E^{{\rm{dc}}}} $$ 式中:Edc表示进刀方向改变时所消耗的能量,da、db分别表示操作a、b所选择的进刀方向。
总切换能耗由每次执行操作时,而产生的切换能耗累加而成,定义为
$$ {T_{{\text{CEC}}}} = \sum\limits_{i = 1}^{t - 1} {{C_{{\text{EC}}i(i + 1)}}} $$ 式中t表示加工零件P的操作个数。
1.3 工艺路线–MDP
MDP作为DQN的数学模型,由四元组<S, A, P, R> [22]构成。结合节能工艺路线定义,给出状态向量S、动作空间A和奖励函数R的定义。
1.3.1 状态向量
为了使智能体能够从状态向量中得知零件的加工状况,本文将零件加工状况映射到MDP的状态向量,状态向量定义为
${{\boldsymbol{S}}} = [{O_1}\;{O_2}\; \cdots \;{O_i} \cdots ]$ ,状态向量中特征Oi的数量由加工零件的操作个数决定。同时考虑到零件特征之间的约束、每个操作执行且仅执行一次,因此本文状态向量中的特征Oi有3种状况:状况0 在当前状态下,该操作可以被执行;
状况1 该操作违反了零件特征间的约束,所以在当前状态下该操作无法被执行;
状况2 该操作已经执行了,不能再次选择。
1.3.2 动作空间
动作是连接MDP中状态转换的桥梁。本文将零件加工步骤映射到动作空间。动作空间定义为:
$A = \{ 1,2, \cdots \} $ 。动作空间的动作个数取决于加工零件的操作数,当选取的动作为$ i $ 时,表示执行操作Oi;当选取动作表示的操作处于1、2状况时,此动作默认无效,不会引起状态的变化。执行操作Oi时,需要从集合Ci中选取一个c,其选取原则为:机床、刀具、进刀方向应与前一个操作保持一致,如果无法保持一致,则选择加工资源中能耗最小的。
1.3.3 奖励函数
奖励作为强化学习的重要组成部分,智能体可以通过奖励来判断动作的好坏,从而进行有效的学习。本文将奖励设计为状态的函数。奖励函数定义为
$$ {R_{t + 1}} = \left\{ \begin{split} & - ({D_{{\text{E}}{{\text{C}}_t}}} + {C_{{\text{E}}{{\text{C}}_{(t - 1)t}}}}),\quad{{{\boldsymbol{s}}}_t} \ne {{{\boldsymbol{s}}}_{t + 1}} \\ & - X,\quad{{{\boldsymbol{s}}}_t} = {{{\boldsymbol{s}}}_{t + 1}} \\ \end{split} \right. $$ 式中:Rt+1表示在执行动作at后,智能体所获得的奖励;
$ {D_{{\text{E}}{{\text{C}}_t}}} $ 、$ {C_{{\text{E}}{{\text{C}}_{(t - 1)t}}}} $ 表示执行动作at时,设备能耗以及切换能耗;${{{\boldsymbol{s}}}_t} \ne {{{\boldsymbol{s}}}_{t + 1}}$ ,表示执行动作at后,智能体的状态发生变化,即此动作有效;而${{{\boldsymbol{s}}}_t} = {{{\boldsymbol{s}}}_{t + 1}}$ 则表示此动作无效,显然这样的情况应该避免发生,所以当出现这种情况时,对智能体进行惩罚;$ X $ 是惩罚系数,$X > \max {(D{}_{{\text{E}}{{\text{C}}_t}} + {C_{{\text{E}}{{\text{C}}_{(t - 1)t}}}})}$ 。2. 基于DQN的节能工艺路线问题求解
本节将节能工艺路线规划问题转化为DQN智能体决策问题,利用决策经验的可复用性和可扩展性,进行求解。同时为了提高DQN的收敛速度和解的质量,提出了基于S函数探索机制和加权经验池技术,并使用双Q网络改进DQN。
2.1 节能工艺路线规划问题求解
结合1.3节MDP的含义,本文将节能工艺路线规划问题转化为DQN智能体决策问题,利用决策经验的可复用性和可扩展性进行求解。如图1所示,智能体在加工零件状况为st下,通过决策从动作空间
$A = \{ 1,\;2, \cdots ,k\} $ 中,选取动作(操作)at,零件进入新的状态st+1,同时,零件根据动作的优劣反馈给智能体奖励Rt+1。DQN根据以上产生的决策经验<st, at, Rt+1, st+1>进行学习,使其获得的奖励最大,从而获得节能工艺路线。 图 1 DQN模型Fig. 1 DQN model
图 1 DQN模型Fig. 1 DQN model 下载:
全尺寸图片
下载:
全尺寸图片
2.2 改进DQN
2.2.1 基于S函数的探索机制
在强化学习中,“利用”表示执行当前能获得奖励最大的动作,“探索”是指牺牲眼前最大奖励,去探索可能存在更大奖励的区域。“利用”和“探索”存在博弈,如果只使用“利用”,则有可能陷入局部最优解;如果只使用“探索”,算法则可能无法收敛。
为了解决这个问题,DQN算法采用
$\varepsilon- {\rm greedy }$ 策略G,策略G定义为$$ G=\left\{\begin{split} &1,\quad \varepsilon > K\\ &0,\quad \varepsilon \leqslant K\end{split}\right. $$ (1) 式中:1表示“探索”;0表示“利用”;
$ K \in[0,1] $ ;$ \varepsilon \in[0,1] $ ,与随机值K不同的是,贪婪值ε会随着迭代次数改变而改变。常规DQN算法贪婪值ε会随着迭代次数线性减小,虽然避免了陷入局部最优解,但可能会导致智能体在迭代中后期仍出现“探索”,使经验池出现意想不到的经验,导致神经网络学习次数增加甚至出现已经收敛的神经网络发散的现象,神经网络的收敛速度变慢,从而使智能体学习时间变长。
为了加快DQN算法的收敛速度,同时避免算法陷入局部最优解,本文提出了基于S函数的探索机制,使得在算法运行前期,智能体尽可能地使用“探索”,增加经验池中样本的多样性,避免陷入局部最优解,在算法运行中后期,智能体尽可能地使用“利用”,避免样本池中出现意想不到的样本,加快算法的收敛速度,缩短学习时间。
为了达到预期目标,定义S函数:
$$ \varepsilon = - \dfrac{1}{{1 + {{\text{e}}^{ - \left(\tfrac{{15\rho }}{\nu } - s\right)}}}} + 1 $$ (2) 式中:
$\varepsilon $ 是贪婪值,v是算法迭代总次数,ρ是当前迭代次数,切换权值s用于控制智能体使用“探索”和“利用”的权重。当$v=10, s=6$ 时,ε的取值情况如图2所示,图中红点K值表示随机值K在0到1之间随机取值的情况。由式(1)可知,在某次迭代中,贪婪值大于红点K值智能体使用“探索”,否者使用“探索”,所以红点位于曲线之下则表示“探索”,位于曲线之上或在曲线上表示“利用”。从图中可以看出,在迭代前期即前3次迭代,红点均位于S型探索曲线下方,反观线性探索曲线,在迭代一开始,就有一个红点位于线性探索曲线上方,即算法执行“利用”,显然这样极其容易导致算法陷入局部最优解。在迭代中后期,即4~10次迭代,所有的红点均在S型探索曲线上方,而在线性探索曲线中,依旧出现了“探索”与“利用”交替的情况,即红点交叉位于曲线上下。在迭代前期,S型探索探索率为100%,线性探索探索率为66.7%;在迭代中后期,S型探索利于率为100%,线性探索利用率为71.43%。显然在迭代前期,S型探索的探索率大于线性探索,在迭代中后期,S型探索的利用率大于线性探索,导致这样的结果是因为在迭代前期,位于S型探索曲线以下的面积大于线性探索,即紫色区域,在迭代中后期,位于S型探索曲线以上的面积大于线性探索,即绿色区域。可以通过式(2)中的切换权值s来调整紫色区域和绿色区域的大小,从而调整“探索”与“利用”在DQN算法中的权重,提高解的确定性,加快算法收敛速度。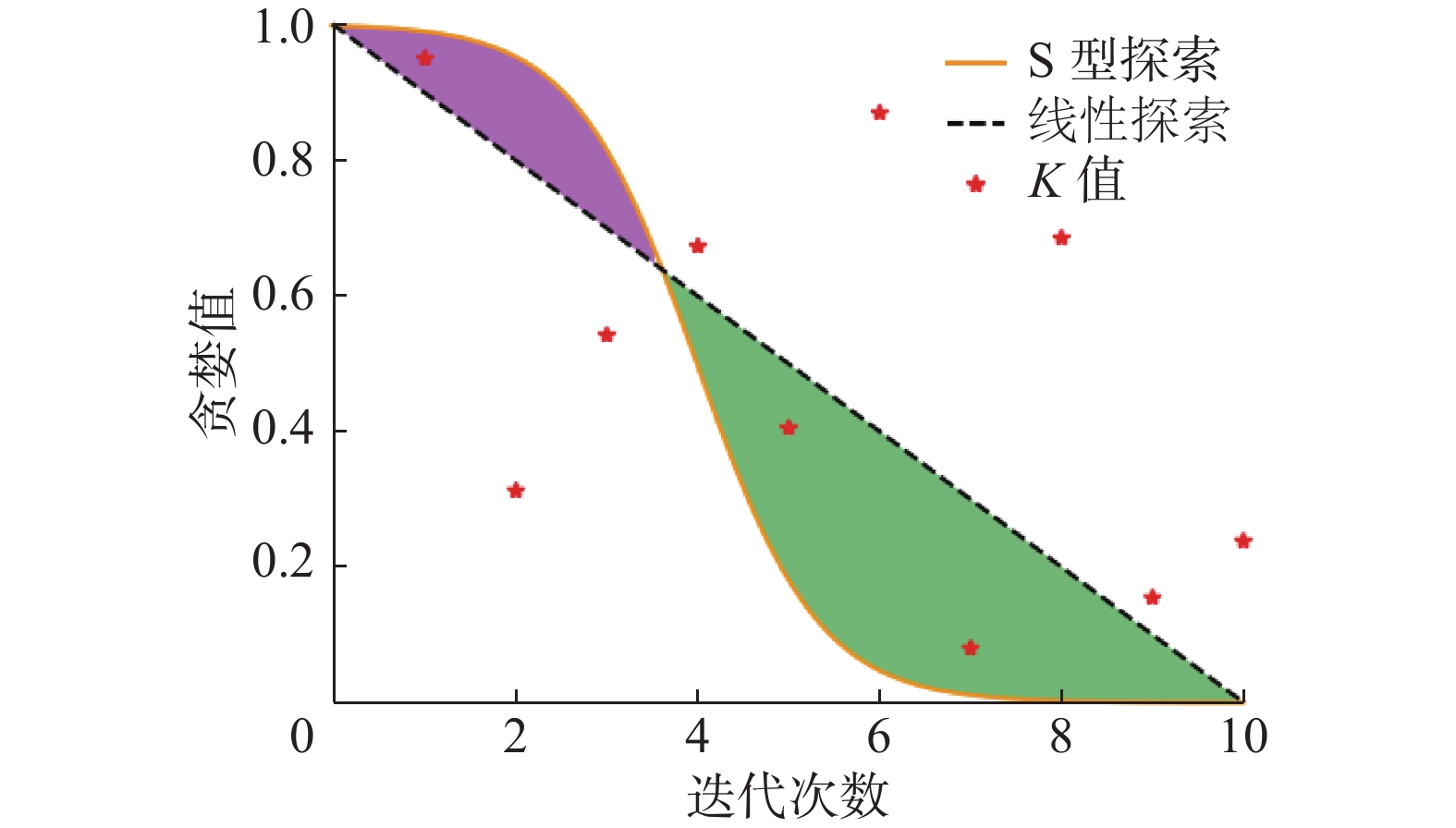 图 2 ε取值情况Fig. 2 Value ofε下载:
全尺寸图片
图 2 ε取值情况Fig. 2 Value ofε下载:
全尺寸图片
2.2.2 加权经验池
DQN算法为了保证神经网络收敛使用经验回放技术。该技术设置了容量为D的经验池,用于保存智能体与环境交互过程中生成的经验,每一个经验由四元组<st, at, Rt+1, st+1>构成。在神经网络学习的过程中,将随机从经验池中选取一定数量M的经验,从而打破经验间的高相关度。
随着零件特征数的增加,特征间的约束愈加复杂,智能体可能会花费大量时间才会获得一条合理的工艺路线,且导致经验池中存在大量违反零件加工约束的经验,这些错误的经验很容易将经验池“撑爆”,导致经验溢出,在DQN算法中,当发生经验溢出时,常将经验池中的第一条经验删除,但这种不加思考的删除,极其容易将关键经验删除,导致智能体学习速率变慢。同时在学习开始,由于经验池中仅存在少量且合理的经验,导致智能体很难获得有效经验,使得智能体将花费大量精力来获取有效经验,极大地降低了智能体的学习速率。
为了避免删除关键经验和提高智能体对少量且合理经验的利用率,本文提出加权经验池技术,对经验池中的每一条经验赋予权重。文献[23]认为神经网络预测值与真实值误差越大,越值得智能体学习,但其没有考虑到经验的合理性,如果两条经验神经网络的预测值和误差值相同,但前者违反了零件之间的特征约束,而后者没有,显然,智能体应该优先学习没有违法零件特征约束的经验,提高智能体规避零件特征约束的能力,加快智能体学习速率。因此,针对经验的合理性,定义了优势权值g,当经验中的奖励大于负的惩罚系数X时,即经验中的操作没有违反零件操作约束,智能体应该学习,增大其权值,加上优势权值g,提高智能体对该经验的利用率。
经验池中第i条经验Ei的权重为wi:
$$ {w_i} = \left\{ \begin{split} &\left| {{\text{los}}{{\text{s}}_i}} \right| + l + g,\quad {R_i > - X} \\ &\left| {{\text{los}}{{\text{s}}_i}} \right| + l,\quad {R_i}\leqslant {\text{ }} - X \end{split} \right. $$ (3) 式中:|lossi|表示神经网络的输出值与目标值差值的绝对值;
$ l \in(0,0.001] $ ,作用是防止|lossi|为0减小经验的多样性;Ri为经验Ei中奖励大小;X表示惩罚系数;g表示优势权值,$ g \in(0,1) $ 。在经验池中,经验Ei被采样选中的概率为
$$ {P_i} = \dfrac{{{w_i}^o}}{{\displaystyle\sum\limits_{j = 1}^D {{w_j}^o} }} $$ (4) 式中:wi表示经验Ei的权值;
$ D $ 表示经验池总容量;优先权值o,表示经验采样的优先情况,$o \in[0,1] $ 。当$ o=0 $ 时,优先经验采样就变为了随机经验采样。2.2.3 双Q网络
Hasselt等[24]指出DQN算法的目标值计算公式往往会使智能体过高地估计动作价值,导致智能体有时学习到不切实际的动作价值,且随着动作数的增加过估计现象愈加严重,为了解决此问题,提出了双Q网络技术。
双Q网络技术主要将DQN算法中动作的选择和Q值的评估分别使用估计网络和目标网络来完成,从而实现选择与评估的解耦,其中估计网络与目标网络结构完全相同,为了减小因策略不收敛而引起的误差。相比较DQN算法,双Q网络技术仅将目标值计算公式进行改写:
$$ y = {R_{t + 1}} + \gamma {Q_t}({{{\boldsymbol{s}}}_{t + 1}},{\text{argma}}{{\text{x}}_{a' \in A}}{Q_e}({{{\boldsymbol{s}}}_{t + 1}},a';\theta );{\theta ^ - }) $$ 式中:Rt+1表示t时刻智能体所获得的奖励;γ为衰减因子;Qt为目标网络;Qe为估计网络;θ−、θ分别为其权值;
${\text{argma}}{{\text{x}}_{a' \in A}}{Q_e}({{{\boldsymbol{s}}}_{t + 1}},a';\theta )$ 表示智能体在状态st+1下通过Qe网络估计行为价值来贪婪地选择动作${a}^{\prime}$ ,使得Qe值最大,接着使用Qt网络合理地评估动作价值。2.3 改进后的DQN——SWDDQN
综上,最终获得改进后的DQN:基于S函数和加权经验池的深度双Q网络(deep double Q network based on S-function and weighted experience pool, SWDDQN),SWDDQN算法伪代码如下所示:
输入 Qt网络权值更新周期N,迭代次数episodes,经验池容量D,经验暂存区容量M,切换权值s,惩罚系数X。
初始化 经验池容量D,容量为M的经验暂存区L,网络权值
$\theta $ 、${\theta ^ - }$ 。1) for
$i = 1:$ episodes do2) 根据零件加工状态,初始化状态向量st
3) while 零件没有加工完成 do
4) 计算
$\varepsilon = 1 - 1\bigg/\left\{1 + {{{\rm{exp}}}\left[ - \left(\dfrac{{15\rho }}{v} - s\right)\right]}\right\}$ ,根据$ \varepsilon $ 值选取随机动作at或${a_t} = \arg {\max _a}{Q_e}({{{\boldsymbol{s}}}_t},a;\theta )$ 5) 执行动作at,获取零件新状况st+1以及零件反馈的奖励Rt+1
6) 若经验池容量已满,则选取经验
${E_i}\sim P{(i)_{\min }} = w_i^o\Big/\displaystyle\sum {_jw_j^o}$ ,并删除该经验7) 经验<st,at,Rt+1,st+1>存入经验池D
8) 更新经验池中经验的权重与被采样概率
9) 更新状态向量
${{{\boldsymbol{s}}}_t} \leftarrow {{{\boldsymbol{s}}}_{t + 1}}$ 10) 从经验池中获取数量为M的经验放入L
11) 根据L中的经验计算目标值:
$$ {y_i} = {R_{t + 1}} + \gamma {Q_t}({{{\boldsymbol{s}}}_{t + 1}},\arg {\max _{a' \in A}}{Q_e}({{{\boldsymbol{s}}}_{t + 1}},a';\theta );{\theta ^ - }) $$ 12) 根据函数:
$J(\theta ) = {E_\pi }[{({y_i} - {Q_e}({{{\boldsymbol{s}}}_i},{a_i};\theta ))^2}]$ ,使用梯度下降更新权值$\theta $ 13) 每隔N步,更新Qt网络权重:
${\theta ^ - } \leftarrow \theta $ 14) end while
15) end for
将SWDDQN应用在节能工艺路线规划中,其机理如图3所示,主要分为决策模块和学习模块。在决策模块中,智能体根据加工零件初始化状态向量st,并根据S函数探索机制决定探索或者利用,从而选择动作at,加工零件根据动作的优劣反馈奖励Rt+1,同时更新自身状态进入新状态st+1,状态向量更新
${{{\boldsymbol{s}}}_t} = {{{\boldsymbol{s}}}_{t + 1}}$ ,此时,经验Ei生成,经验Ei根据式(3)获得权重wi,并存放中加权经验池中。在学习模块中,从加权经验池中,根据式(4)选取一批经验,使用双Q网络计算目标值,使用梯度下降更新估计网络Qe的权值θ,并每隔N步,将估计网络Qe权值θ赋值目标网络Qt权值θ−,更新目标网络Qt。智能体根据学习模块的估计网络Qe更新自己,接着再根据加工零件的新状态st+1结合S函数探索机制选取动作,重复以上步骤,直到零件加工完成。智能体选取的动作组成了加工零件的工艺路线。 图 3 SWDDQN算法机理图Fig. 3 SWDDQN algorithm mechanism diagram下载:
全尺寸图片
图 3 SWDDQN算法机理图Fig. 3 SWDDQN algorithm mechanism diagram下载:
全尺寸图片
3. 实验与分析
为了验证本文改进的SWDDQN在工艺路线规划中的有效性和优越性,进行计算机仿真实验。模拟复杂生产系统加工环境动态变化,将SWDDQN与DQN对比,验证算法在加工环境变动时工艺路线规划的能力,同时与遗传算法(genetic Algorithm, GA)、模拟退火算法(simulated Annealing, SA)、蚁群算法(ant colony system,ACO)进行对比实验,验证SWDDQN搜索节能工艺路线的速度和精度。本文实验均运行在CPU为Intel(R) Core(TM) i7-8700 CPU @3.20GHZ、GPU为NVIDIA GeForce GTX 960M、内存为16 GB的计算机上运行。
3.1 实验设计
在复杂生产系统中,加工环境时常动态变化,因此,在本文仿真实验中,随机选取0~1台机床、0~1个刀具,使其发生故障无法使用,来模拟复杂生产系统加工环境动态变化,使用DQN、SWDDQN算法对目标零件进行工艺路线规划,寻找节能工艺路线。算法执行流程如图4所示,DQN或SWDDQN根据加工零件的操作执行状态,选择动作at,零件加工,同时更新操作的执行状态,重复以上步骤,直到零件加工完成,选取的动作构成了零件的工艺路线。
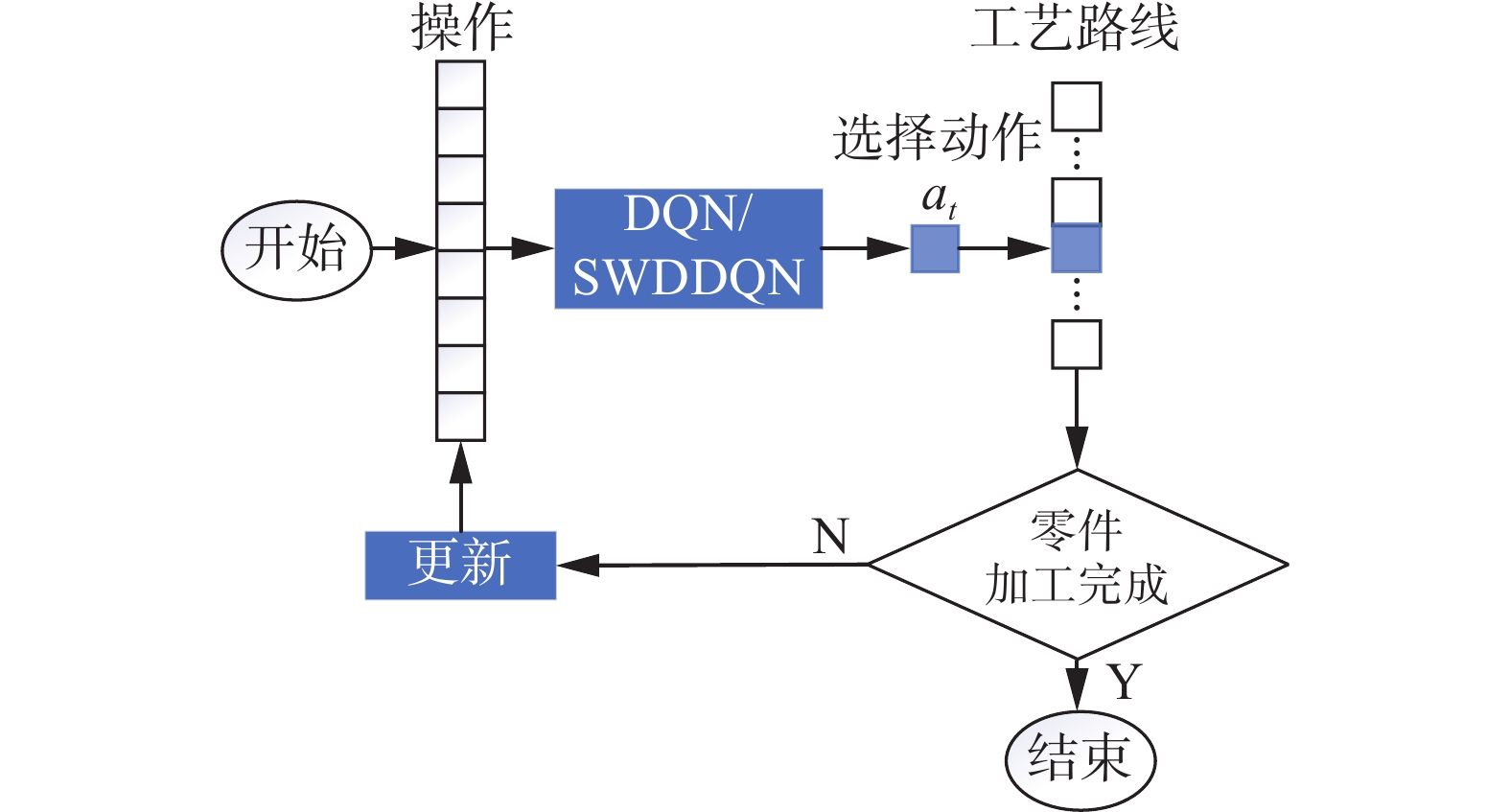 图 4 算法执行流程图Fig. 4 Algorithm execution flow chart下载:
全尺寸图片
图 4 算法执行流程图Fig. 4 Algorithm execution flow chart下载:
全尺寸图片
本文以文献[25]给出的零件P2为目标工件,P2如图5,特征详情如表1所示,P2共19个特征,其中特征F7、F9需要多个操作配合完成,P2的操作约束如表2所示,加工资源及成本如表3所示,其中
${E^{{\text{mc}}}} = 300{\text{ kJ}}$ 、${E^{{\text{tc}}}} = 10{\text{ kJ}}$ 、${E^{{\text{dc}}}} = 90{\text{ kJ}}$ 。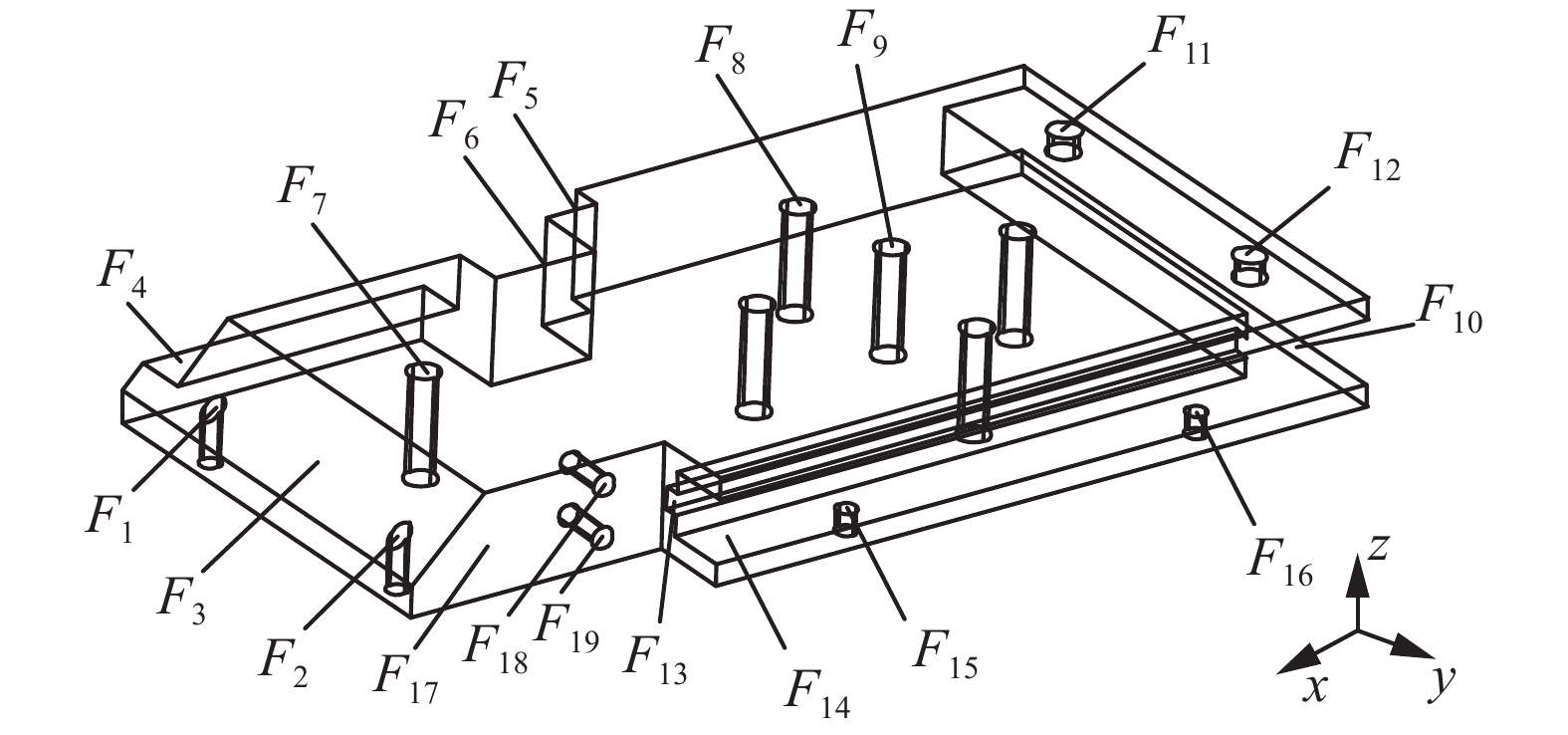 图 5 零件P2Fig. 5 Part P2下载:
全尺寸图片
表 1 零件P2特征详情Table 1 Part P2 feature details
图 5 零件P2Fig. 5 Part P2下载:
全尺寸图片
表 1 零件P2特征详情Table 1 Part P2 feature details特征 操作类型 机床编号 刀具编号 进刀方向 F1 钻孔(O1) M1、M2、M3、M7 T1、T9 +z、−z F2 钻孔(O2) M1、M2、M3、M7 T1、T9 +z、−z F3 铣削(O3) M2、M3、M6 T7 +z、−z F4 铣削(O4) M2、M3、M5、M6 T5、T6 +y、−z F5 铣削(O5) M2、M3 T5、T6 +y F6 铣削(O6) M2、M3 T5、T6 +y F7 钻孔(O7) M1、M2、M3、M7 T2、T9 +z、−z 铰孔(O8) M1、M2、M3 T3 +z、−z 钻孔(O9) M3、M4、M7 T4、T9 +z、−z F8 钻孔(O10) M1、M2、M3、M7 T1、T9 −z F9 钻孔(O11) M1、M2、M3、M7 T2、T9 +z、−z 铰孔(O12) M1、M2、M3 T3 +z、−z 钻孔(O13) M3、M4、M7 T4、T9 +z、−z F10 铣削(O14) M2、M3、M5、M6 T5、T6 +x F11 钻孔(O15) M1、M2、M3、M7 T1、T9 −z F12 钻孔(O16) M1、M2、M3、M7 T1、T9 −z F13 铣削(O17) M2、M3 T5、T8 −y、−z F14 铣削(O18) M2、M3、M5、M6 T5、T6 −y、−z F15 钻孔(O19) M1、M2、M3、M7 T1、T9 +z、−z F16 钻孔(O20) M1、M2、M3、M7 T1、T9 +z、−z F17 铣削(O21) M2、M3、M5、M6 T5、T6 −y F18 钻孔(O22) M1、M2、M3、M7 T1、T9 −y F19 钻孔(O23) M1、M2、M3、M7 T1、T9 −y 表 2 零件P2操作约束Table 2 Part P2operational constraints操作 优先于 操作 优先于 O1 O2、O3 O13 O10 O2 O3 O14 O3、O4、O17、
O18、O19、O20、
O21、O22、O23O3 无 O15 O16 O4 O3 O16 无 O5 O4、O6、O15、O16、
O17、O18、O19、O20、
O21、O22、O23O17 无 O6 O4、O15、O16、O17、O18、O19、O20、O21、O22、O23 O18 O17、O19 续表 2 操作 优先于 操作 优先于 O7 O8、O9、O10、O11、O12、O13 O19 无 O8 O9、O10、O11、O12、O13 O20 无 O9 O10、O11、O12、O13 O21 O1、O2、O3、O7、O8、O9、O10、O11、O12、O13、O17、O8、O19、O22、O23 O10 无 O22 无 O11 O10、O12、O13 O23 无 O12 O10、O13 表 3 加工资源和成本Table 3 Processing resources and costskJ 机床编号 类型 能耗 刀具编号 类型 能耗 1 钻床 40 1 钻孔 3 2 立式数控铣削 65 2 立铣 3 3 立铣 35 3 铰刀 8 4 镗床 50 4 镗刀 15 5 刨床 45 5 铣刀1 10 6 磨床 40 6 铣刀2 15 7 车床 45 7 倒角刀 10 8 起槽刀 10 9 车刀 14 3.2 实验结果与分析
3.2.1 神经网络层数敏感性实验
在进行DQN、SWDDQN算法性能对比前,为了选取合适的神经网络层数,开展神经网络层数敏感性实验。在此实验中,假设加工环境没有发生变动,使用DQN算法对零件P2进行工艺路线规划,实验全程使用“利用”。实验结果如图6所示。
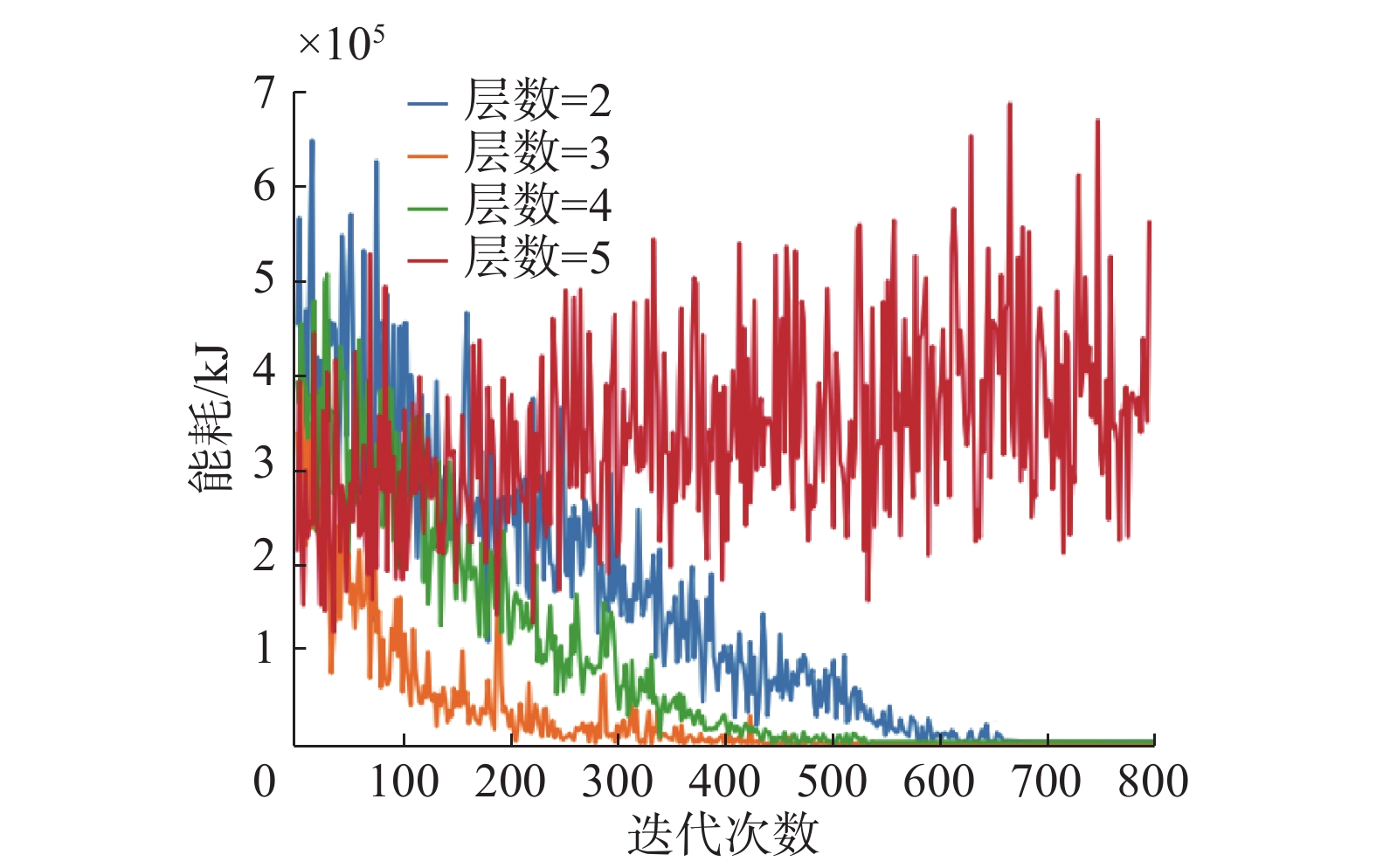 图 6 神经网络层数敏感图Fig. 6 Neural network layer sensitive map下载:
全尺寸图片
图 6 神经网络层数敏感图Fig. 6 Neural network layer sensitive map下载:
全尺寸图片
从图中可以看出,当神经网络由2层增加到3层时,算法的收敛速度加快;但随着神经网络由3层增加到4层时,由于神经网络层数的增加,使得学习难度增加,导致算法的收敛速度减缓;当神经网络层数由4层增加到5层时,因为梯度消失,所以算法不再收敛,曲线发散。因此综合考虑算法的收敛性和收敛速度,神经网络层数选择3层比较合理。所以在本文实验中,DQN、SWDDQN算法均选择3层神经网络。
3.2.2 智能体学习实验
模拟复杂生产系统加工环境变动,随机选取0~1台机床、0~1个刀具,使其故障不可用,使用DQN、SWDDQN算法对目标工件P2进行工艺路线规划,寻找节能工艺路线。DQN、SWDDQN算法模型参数相同,如表4所示。两种模型学习后,能耗对比如图7所示。
表 4 模型参数Table 4 Model parameter参数 参数含义 取值 N $ Q_t $网络权值更新周期 50 episodes 迭代次数 700 D 经验池容量 20000 M 经验暂存区容量 32 s 切换权值 2 X 惩罚系数 600  图 7 模型能耗对比Fig. 7 Model energy comparison下载:
全尺寸图片
图 7 模型能耗对比Fig. 7 Model energy comparison下载:
全尺寸图片
因为SWDDQN算法使用了基于S型函数探索机制,所以从图7中可以看出在迭代中后期,SWDDQN算法能耗突变相比较DQN算法明显减少,如在220、240等迭代次数时,DQN算法能耗发生突变,而SWDDQN算法则没有,即SWDDQN解的确定性高于DQN算法。又因为SWDDQN算法使用了双Q网络技术,智能体会避免高估动作价值,所以从图7中可以看出SWDDQN算法获得的能耗小于DQN算法。从图7的局部放大图中可以看出,由于加工环境发生变动,所以模型学习过程中,智能体在迭代后期,能耗在一定范围内震荡,但并未出现突变点,即智能体具有规避特征约束的能力。
在学习过程中,DQN、SWDDQN的智能体运行总步数对比如图8所示。因为DQN、SWDDQN算法在学习前期几乎都在“探索”,所以两者智能体的运行总步数大致相同。但随着学习的进行,SWDDQN算法因为使用了加权经验池技术,相比较DQN算法能更快速地找到关键经验进行学习,所以SWDDQN算法智能体的运行总步数远远小于DQN算法。
 图 8 模型总步数对比Fig. 8 Comparison of total steps of the model下载:
全尺寸图片
图 8 模型总步数对比Fig. 8 Comparison of total steps of the model下载:
全尺寸图片
模拟复杂生产系统加工环境变动,在DQN、SWDDQN学习过程中,神经网络损失对比如图9所示。由于DQN、SWDDQN算法学习前期几乎都在探索,模型还没有开始学习,所以损失为零。但随着学习次数的增加,模型损失开始变化。从图9中可以看出,DQN神经网络大概在迭代370次收敛,模型完成学习;SWDDQN神经网络大概在迭代330次收敛,模型完成学习。从图9中,可以看出SWDDQN神经网络收敛速度快于DQN算法。
 图 9 神经网络损失对比Fig. 9 Neural network loss comparison下载:
全尺寸图片
图 9 神经网络损失对比Fig. 9 Neural network loss comparison下载:
全尺寸图片
3.2.3 模型泛化实验
相比于启发式算法,基于深度神经网络的模型具有泛化能力,因此能够处理加工环境变动的工艺路线规划问题。为了测试模型的泛化能力,针对模型设置了两个测试案例。
案例1 加工环境正常,以零件P2为加工目标,在学习模型的基础上进行泛化,观察智能体是否可以高效地学习模型中的知识,从而加快工艺路线的规划效率。
案例2 假设复杂生产系统机床M3、刀具T5发生故障,无法正常使用,对零件P2进行工艺路线规划,来验证SWDDQN算法是否能够克服加工环境变动而导致的影响。
案例1、2模型泛化结果分别如图10、11所示。从图10、11中可以看出,在案例1中,SWDDQN算法、DQN算法分别在迭代33次、48次左右收敛,而在案例2中,SWDDQN算法、DQN算法分别在迭代61次、94次收敛。因为智能体在模型学习阶段,已经学习了零件P2的工艺路线规划模型,所以在案例1泛化阶段,智能体仅通过神经网络反向传播即可获得优化方案。而在案例2中,机床M3、刀具T5发生了故障无法使用,因此智能体需要对某些特征的加工资源进行重新分配,增加了计算量,所以案例2相比较案例1收敛速度减慢。从图10、11中还可以看出,无论是在案例1还是案例2中,SWDDQN算法收敛能耗均小于DQN算法,即SWDDQN算法所发现的最优工艺路线能耗要优于DQN算法所发现的最优工艺路线能耗,这是因为SWDDQN算法使用了双Q网络避免智能体过高地估计动作值。
 图 10 案例1模型泛化Fig. 10 Case 1 model generalization下载:
全尺寸图片
图 10 案例1模型泛化Fig. 10 Case 1 model generalization下载:
全尺寸图片
 图 11 案例2模型泛化Fig. 11 Case 2 model generalization下载:
全尺寸图片
图 11 案例2模型泛化Fig. 11 Case 2 model generalization下载:
全尺寸图片
案例1、2模型泛化后,SWDDQN、DQN算法寻找的最优工艺路线能耗详情如表5所示,具体工艺路线如表6~9所示。从表5中可以看出,在案例1中,SWDDQN算法的最优工艺路线相比较DQN算法更节能,两者设备能耗相同,而SWDDQN算法的切换能耗小于DQN算法,使得SWDDQN算法最优工艺路线总能耗由1502 kJ降至1412 kJ,能耗降低了5.99%。在案例2中,SWDDQN算法的最优工艺路线能耗同样低于DQN算法,但相比较DQN算法,SWDDQN算法能耗值却仅降低了4.24%,主要是因为案例1中的机床、刀具数量大于案例2的机床、刀具数量,案例1中的可行解的数量更多、探索空间更广,更有利于加权经验池、基于S函数探索机制的发挥。
表 5 案例最优解能耗详情Table 5 Case optimal solution energy consumption detailskJ 案例 算法 设备能耗 切换能耗 总能耗 案例1 DQN 962 540 1502 案例1 SWDDQN 962 450 1412 案例2 DQN 1552 1670 3222 案例2 SWDDQN 1577 1460 3037 表 6 案例1:SWDDQN算法最优工艺路线Table 6 Case 1: SWDDQN algorithm optimal process route序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 14 5 6 4 21 18 17 22 23 1 2 19 20 7 8 3 9 11 12 13 10 15 16 机床 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 刀具 5 5 5 5 5 5 5 1 1 1 1 1 1 2 3 7 9 2 3 9 1 1 1 进刀方向 +x +y +y +y −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z +z −z −z −z 表 7 案例1:DQN算法最优工艺路线Table 7 Case 1: DQN algorithm optimal process route序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 5 6 14 4 21 18 17 22 23 1 2 19 20 7 8 3 9 11 12 13 10 15 16 机床 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 刀具 5 5 5 5 5 5 5 1 1 1 1 1 1 2 3 7 9 2 3 9 1 1 1 进刀方向 +y +y +x +y −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z +z −z −z −z 表 8 案例2:SWDDQN算法最优工艺路线Table 8 Case 2: SWDDQN algorithm optimal process route序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 14 5 6 4 15 16 20 21 22 23 18 17 1 2 19 7 8 3 9 11 12 13 10 机床 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 7 7 1 7 7 刀具 6 6 6 6 1 1 1 6 1 1 6 8 1 1 1 2 3 7 9 2 3 9 1 进刀方向 +x +y +y +y −z −z −z −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z −z 表 9 案例2:DQN算法最优工艺路线Table 9 Case 2: DQN algorithm optimal process route序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 14 5 6 4 15 16 20 21 22 23 18 17 1 2 19 7 8 3 9 11 12 13 10 机床 6 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 7 7 1 7 7 刀具 6 6 6 6 1 1 1 6 1 1 6 8 1 1 1 2 3 7 9 2 3 9 1 进刀方向 +x +y +y +y −z −z −z −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z −z 3.3 算法性能对比
为了验证SWDDQN搜索节能工艺路线的速度和精度,与启发式算法GA、SA以及ACO算法进行对比,以案例1为例,GA、SA以及ACO算法对零件P2进行工艺路线规划,算法获得最优工艺路线如表10~12所示,能耗收敛曲线如图12所示,算法收敛时其迭代次数及能耗详情如表13所示。从图12、表13中可以看出,在4种算法中,SWDDQN算法收敛速度最快,迭代33次收敛;而在3种启发式算法中,ACO算法收敛速度最快,迭代56次收敛,GA算法收敛速度第2,迭代78次收敛,而SA算法收敛速度最慢,迭代95次收敛。在4种算法获得最优解中,SWDDQN算法能耗1412 kJ最低;在3种启发式算法中,ACO算法收敛速度虽然最快,但收敛的解能耗1542 kJ最高,而GA算法收敛速度虽然慢于ACO算法,但收敛解的能耗1502 kJ低于ACO算法,SA算法收敛速度虽然最慢,但收敛的解能耗1412 kJ最小,同时也验证了文献[10]的结论:SA算法的全局搜索能力强于GA算法。从整体看来,SWDDQN模型泛化后不仅能够以最快地速度发现节能工艺路线,而且有相同甚至更高精度的解。综上,SWDDQN不仅能够处理加工环境动态变化的节能工艺路线规划问题,而且能快速地获取与启发式算法精度相同甚至更高的节能工艺路线,体现了SWDDQN的优越性。
表 10 GA最优工艺路线Table 10 GA optimal process route序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 5 6 14 4 21 18 17 22 23 1 2 19 20 7 8 3 9 11 12 13 10 15 16 机床 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 刀具 5 5 5 5 5 5 5 1 1 1 1 1 1 2 3 7 9 2 3 9 1 1 1 进刀方向 +y +y +x +y −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z +z −z −z −z 表 11 SA最优工艺路线Table 11 SA optimal process route序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 14 5 6 4 21 18 17 22 23 1 2 19 20 7 8 3 9 11 12 13 10 15 16 机床 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 刀具 5 5 5 5 5 5 5 1 1 1 1 1 1 2 3 7 9 2 3 9 1 1 1 进刀方向 +x +y +y +y −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z +z −z −z −z 表 12 ACO算法最优工艺路线Table 12 ACO algorithm optimal process route序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 14 5 6 4 15 16 20 21 18 17 22 23 1 2 19 7 8 3 9 11 12 13 10 机床 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 刀具 6 6 6 6 1 1 1 5 5 5 1 1 1 1 1 2 3 7 9 2 3 9 1 进刀方向 +x +y +y +y −z −z −z −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z −z 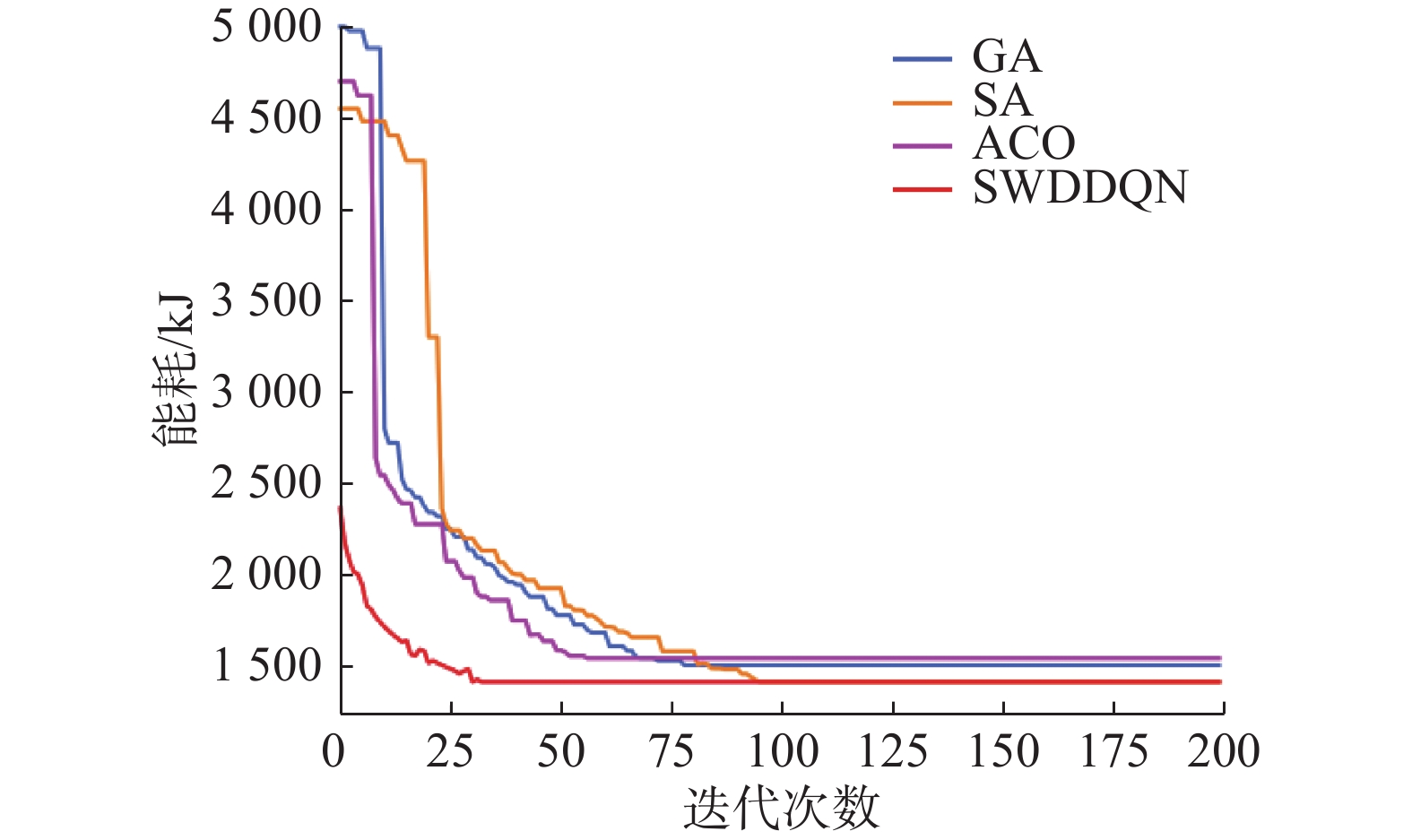 图 12 算法性能对比Fig. 12 Algorithm performance comparison下载:
全尺寸图片
表 13 算法性能对比详情Table 13 Algorithm performance comparison details
图 12 算法性能对比Fig. 12 Algorithm performance comparison下载:
全尺寸图片
表 13 算法性能对比详情Table 13 Algorithm performance comparison detailsGA SA ACO SWDDQN 迭代次数 78 95 56 33 能耗/kJ 1502 1412 1542 1412 4. 结束语
本文将DQN算法应用于工艺路线规划问题,提出了基于DQN的节能工艺路线发现方法。基于MDP建立节能工艺路线模型,将节能工艺路线规划问题转化为智能体决策问题进行求解,为了提高DQN的收敛速度和解的质量,使用基于S型函数探索机制、加权经验池、双Q网络技术来改进算法。以实际加工零件为例,模拟加工环境变动,对目标工件进行工艺路线规划,同时与多种启发式算法对比,验证所提算法的优越性。未来将关注多零件并行加工工艺路线规划问题,同时考虑加工能耗与加工时间,将强化学习与图神经网络相结合,来解决此类问题。
-
图 1 DQN模型
Fig. 1 DQN model
下载:
全尺寸图片
图 2 ε取值情况
Fig. 2 Value ofε
下载:
全尺寸图片
图 3 SWDDQN算法机理图
Fig. 3 SWDDQN algorithm mechanism diagram
下载:
全尺寸图片
图 4 算法执行流程图
Fig. 4 Algorithm execution flow chart
下载:
全尺寸图片
图 5 零件P2
Fig. 5 Part P2
下载:
全尺寸图片
图 6 神经网络层数敏感图
Fig. 6 Neural network layer sensitive map
下载:
全尺寸图片
图 7 模型能耗对比
Fig. 7 Model energy comparison
下载:
全尺寸图片
图 8 模型总步数对比
Fig. 8 Comparison of total steps of the model
下载:
全尺寸图片
图 9 神经网络损失对比
Fig. 9 Neural network loss comparison
下载:
全尺寸图片
图 10 案例1模型泛化
Fig. 10 Case 1 model generalization
下载:
全尺寸图片
图 11 案例2模型泛化
Fig. 11 Case 2 model generalization
下载:
全尺寸图片
图 12 算法性能对比
Fig. 12 Algorithm performance comparison
下载:
全尺寸图片
表 1 零件P2特征详情
Table 1 Part P2 feature details
特征 操作类型 机床编号 刀具编号 进刀方向 F1 钻孔(O1) M1、M2、M3、M7 T1、T9 +z、−z F2 钻孔(O2) M1、M2、M3、M7 T1、T9 +z、−z F3 铣削(O3) M2、M3、M6 T7 +z、−z F4 铣削(O4) M2、M3、M5、M6 T5、T6 +y、−z F5 铣削(O5) M2、M3 T5、T6 +y F6 铣削(O6) M2、M3 T5、T6 +y F7 钻孔(O7) M1、M2、M3、M7 T2、T9 +z、−z 铰孔(O8) M1、M2、M3 T3 +z、−z 钻孔(O9) M3、M4、M7 T4、T9 +z、−z F8 钻孔(O10) M1、M2、M3、M7 T1、T9 −z F9 钻孔(O11) M1、M2、M3、M7 T2、T9 +z、−z 铰孔(O12) M1、M2、M3 T3 +z、−z 钻孔(O13) M3、M4、M7 T4、T9 +z、−z F10 铣削(O14) M2、M3、M5、M6 T5、T6 +x F11 钻孔(O15) M1、M2、M3、M7 T1、T9 −z F12 钻孔(O16) M1、M2、M3、M7 T1、T9 −z F13 铣削(O17) M2、M3 T5、T8 −y、−z F14 铣削(O18) M2、M3、M5、M6 T5、T6 −y、−z F15 钻孔(O19) M1、M2、M3、M7 T1、T9 +z、−z F16 钻孔(O20) M1、M2、M3、M7 T1、T9 +z、−z F17 铣削(O21) M2、M3、M5、M6 T5、T6 −y F18 钻孔(O22) M1、M2、M3、M7 T1、T9 −y F19 钻孔(O23) M1、M2、M3、M7 T1、T9 −y 表 2 零件P2操作约束
Table 2 Part P2operational constraints
操作 优先于 操作 优先于 O1 O2、O3 O13 O10 O2 O3 O14 O3、O4、O17、
O18、O19、O20、
O21、O22、O23O3 无 O15 O16 O4 O3 O16 无 O5 O4、O6、O15、O16、
O17、O18、O19、O20、
O21、O22、O23O17 无 O6 O4、O15、O16、O17、O18、O19、O20、O21、O22、O23 O18 O17、O19 续表 2 操作 优先于 操作 优先于 O7 O8、O9、O10、O11、O12、O13 O19 无 O8 O9、O10、O11、O12、O13 O20 无 O9 O10、O11、O12、O13 O21 O1、O2、O3、O7、O8、O9、O10、O11、O12、O13、O17、O8、O19、O22、O23 O10 无 O22 无 O11 O10、O12、O13 O23 无 O12 O10、O13 表 3 加工资源和成本
Table 3 Processing resources and costs
kJ 机床编号 类型 能耗 刀具编号 类型 能耗 1 钻床 40 1 钻孔 3 2 立式数控铣削 65 2 立铣 3 3 立铣 35 3 铰刀 8 4 镗床 50 4 镗刀 15 5 刨床 45 5 铣刀1 10 6 磨床 40 6 铣刀2 15 7 车床 45 7 倒角刀 10 8 起槽刀 10 9 车刀 14 表 4 模型参数
Table 4 Model parameter
参数 参数含义 取值 N $ Q_t $网络权值更新周期 50 episodes 迭代次数 700 D 经验池容量 20000 M 经验暂存区容量 32 s 切换权值 2 X 惩罚系数 600 表 5 案例最优解能耗详情
Table 5 Case optimal solution energy consumption details
kJ 案例 算法 设备能耗 切换能耗 总能耗 案例1 DQN 962 540 1502 案例1 SWDDQN 962 450 1412 案例2 DQN 1552 1670 3222 案例2 SWDDQN 1577 1460 3037 表 6 案例1:SWDDQN算法最优工艺路线
Table 6 Case 1: SWDDQN algorithm optimal process route
序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 14 5 6 4 21 18 17 22 23 1 2 19 20 7 8 3 9 11 12 13 10 15 16 机床 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 刀具 5 5 5 5 5 5 5 1 1 1 1 1 1 2 3 7 9 2 3 9 1 1 1 进刀方向 +x +y +y +y −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z +z −z −z −z 表 7 案例1:DQN算法最优工艺路线
Table 7 Case 1: DQN algorithm optimal process route
序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 5 6 14 4 21 18 17 22 23 1 2 19 20 7 8 3 9 11 12 13 10 15 16 机床 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 刀具 5 5 5 5 5 5 5 1 1 1 1 1 1 2 3 7 9 2 3 9 1 1 1 进刀方向 +y +y +x +y −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z +z −z −z −z 表 8 案例2:SWDDQN算法最优工艺路线
Table 8 Case 2: SWDDQN algorithm optimal process route
序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 14 5 6 4 15 16 20 21 22 23 18 17 1 2 19 7 8 3 9 11 12 13 10 机床 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 7 7 1 7 7 刀具 6 6 6 6 1 1 1 6 1 1 6 8 1 1 1 2 3 7 9 2 3 9 1 进刀方向 +x +y +y +y −z −z −z −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z −z 表 9 案例2:DQN算法最优工艺路线
Table 9 Case 2: DQN algorithm optimal process route
序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 14 5 6 4 15 16 20 21 22 23 18 17 1 2 19 7 8 3 9 11 12 13 10 机床 6 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 7 7 1 7 7 刀具 6 6 6 6 1 1 1 6 1 1 6 8 1 1 1 2 3 7 9 2 3 9 1 进刀方向 +x +y +y +y −z −z −z −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z −z 表 10 GA最优工艺路线
Table 10 GA optimal process route
序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 5 6 14 4 21 18 17 22 23 1 2 19 20 7 8 3 9 11 12 13 10 15 16 机床 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 刀具 5 5 5 5 5 5 5 1 1 1 1 1 1 2 3 7 9 2 3 9 1 1 1 进刀方向 +y +y +x +y −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z +z −z −z −z 表 11 SA最优工艺路线
Table 11 SA optimal process route
序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 14 5 6 4 21 18 17 22 23 1 2 19 20 7 8 3 9 11 12 13 10 15 16 机床 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 刀具 5 5 5 5 5 5 5 1 1 1 1 1 1 2 3 7 9 2 3 9 1 1 1 进刀方向 +x +y +y +y −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z +z −z −z −z 表 12 ACO算法最优工艺路线
Table 12 ACO algorithm optimal process route
序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 操作 14 5 6 4 15 16 20 21 18 17 22 23 1 2 19 7 8 3 9 11 12 13 10 机床 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 刀具 6 6 6 6 1 1 1 5 5 5 1 1 1 1 1 2 3 7 9 2 3 9 1 进刀方向 +x +y +y +y −z −z −z −y −y −y −y −y +z +z +z +z +z +z +z +z +z +z −z 表 13 算法性能对比详情
Table 13 Algorithm performance comparison details
GA SA ACO SWDDQN 迭代次数 78 95 56 33 能耗/kJ 1502 1412 1542 1412 -
[1] HALIM A H, ISMAIL I. Combinatorial optimization: comparison of heuristic algorithms in travelling salesman problem[J]. Archives of computational methods in engineering, 2019, 26(2): 367–380. doi: 10.1007/s11831-017-9247-y [2] REZOUG A, BADER-EL-DEN M, BOUGHACI D. Guided genetic algorithm for the multidimensional knapsack problem[J]. Memetic computing, 2018, 10(1): 29–42. doi: 10.1007/s12293-017-0232-7 [3] KIEFFER E, DANOY G, BRUST M R, et al. Tackling large-scale and combinatorial bi-level problems with a genetic programming hyper-heuristic[J]. IEEE transactions on evolutionary computation, 2020, 24(1): 44–56. doi: 10.1109/TEVC.2019.2906581 [4] 陈科胜, 鲜思东, 郭鹏. 求解旅行商问题的自适应升温模拟退火算法[J]. 控制理论与应用, 2021, 38(2): 245–254. doi: 10.7641/CTA.2020.00090 CHEN Kesheng, XIAN Sidong, GUO Peng. Adaptive heating simulation annealing algorithm for solving the traveling salesman problem[J]. Control theory & applications, 2021, 38(2): 245–254. doi: 10.7641/CTA.2020.00090 [5] 何庆, 吴意乐, 徐同伟. 改进遗传模拟退火算法在TSP优化中的应用[J]. 控制与决策, 2018, 33(2): 219–225. doi: 10.13195/j.kzyjc.2016.1666 HE Qing, WU YIle, XU Tongwei. Improve the application of genetic simulation annealing algorithm in TSP optimization[J]. Control and decision, 2018, 33(2): 219–225. doi: 10.13195/j.kzyjc.2016.1666 [6] JOY J, RAJEEV S, ABRAHAM E C. Particle swarm optimization for multi resource constrained project scheduling problem with varying resource levels[J]. Materials today:proceedings, 2021, 47: 5125–5129. doi: 10.1016/j.matpr.2021.05.307 [7] PETROVIĆ M, VUKOVIĆ N, MITIĆ M, et al. Integration of process planning and scheduling using chaotic particle swarm optimization algorithm[J]. Expert systems with applications, 2016, 64: 569–588. doi: 10.1016/j.eswa.2016.08.019 [8] VAFADAR A, HAYWARD K, TOLOUEI-RAD M. Drilling reconfigurable machine tool selection and process parameters optimization as a function of product demand[J]. Journal of manufacturing systems, 2017, 45: 58–69. doi: 10.1016/j.jmsy.2017.08.004 [9] WU Xiuli, LI Jing. Two layered approaches integrating harmony search with genetic algorithm for the integrated process planning and scheduling problem[J]. Computers & industrial engineering, 2021, 155: 107194. [10] MA G H, ZHANG Y F, NEE A Y C. A simulated annealing-based optimization algorithm for process planning[J]. International journal of production research, 2000, 38(12): 2671–2687. doi: 10.1080/002075400411420 [11] 施伟, 冯旸赫, 程光权, 等. 基于深度强化学习的多机协同空战方法研究[J]. 自动化学报, 2021, 47(7): 1610–1623. doi: 10.16383/j.aas.c201059 SHI Wei, FENG Yanghe, CHENG Guangquan, et al. Research on multi-aircraft collaborative air combat method based on deep reinforcement learning[J]. Acta automatica sinica, 2021, 47(7): 1610–1623. doi: 10.16383/j.aas.c201059 [12] ZHOU Wenhong, LIU Zhihong, LI Jie, et al. Multi-target tracking for unmanned aerial vehicle swarms using deep reinforcement learning[J]. Neurocomputing, 2021, 466: 285–297. doi: 10.1016/j.neucom.2021.09.044 [13] 王云鹏, 郭戈. 基于深度强化学习的有轨电车信号优先控制[J]. 自动化学报, 2019, 45(12): 2366–2377. WANG Yunpeng, GUO Ge. Tram signal priority control based on deep reinforcement learning[J]. Acta automatica sinica, 2019, 45(12): 2366–2377. [14] GUO Ge, WANG Yunpeng. An integrated MPC and deep reinforcement learning approach to trams-priority active signal control[J]. Control engineering practice, 2021, 110(5): 104758. [15] PENG Bile, KESKIN M F, Kulcsár B, et al. Connected autonomous vehicles for improving mixed traffic efficiency in unsignalized intersections with deep reinforcement learning[J]. Communications in transportation research, 2021, 1: 100017. doi: 10.1016/j.commtr.2021.100017 [16] 吴晓光, 刘绍维, 杨磊, 等. 基于深度强化学习的双足机器人斜坡步态控制方法[J]. 自动化学报, 2021, 47(8): 1976–1987. doi: 10.16383/j.aas.c190547 WU Xiaoguang LIU Shaowei, YANG Lei, et al. A slope gait control method for bipedal robots based on deep reinforcement learning[J]. Acta automatica sinica, 2021, 47(8): 1976–1987. doi: 10.16383/j.aas.c190547 [17] JIANG Rong, WANG Zhipeng, HE Bin, et al. A data-efficient goal-directed deep reinforcement learning method for robot visuomotor skill[J]. Neurocomputing, 2021, 462: 389–401. doi: 10.1016/j.neucom.2021.08.023 [18] SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 529: 484–489. doi: 10.1038/nature16961 [19] VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning[J]. Nature, 2019, 575: 350–354. doi: 10.1038/s41586-019-1724-z [20] BERNER C, et al. Dota 2 with large scale deep reinforcement learning[EB/OL]. (2019−10−1)[2021−12−14].https://arxiv.org/abs/1912.06680. [21] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing atari with deep reinforcement learning[EB/OL]. (2013−12−19) [2021−12−14]. https://arxiv.org/abs/1312.5602. [22] LUO Shu, ZHANG Linxuan, FAN Yushun. Dynamic multi-objective scheduling for flexible job shop by deep reinforcement learning[J]. Computers & industrial engineering, 2021, 159: 107489. [23] SCHAUL T, QUAN J, ANTONOGLOU I, et al. Prioritized experience replay[EB/OL]. (2016−2−25) [2021−12−14]. https://arxiv.org/abs/1511.05952. [24] VAN HASSELT H, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[EB/OL]. (2015−12−8)[2021−12−14]. https://arxiv.org/abs/1509.06461. [25] LIU Xiaojun, YI Hong, NI Zhonghua. Application of ant colony optimization algorithm in process planning optimization[J]. Journal of intelligent manufacturing, 2013, 24(1): 1–13. doi: 10.1007/s10845-010-0407-2




































































