
Dongba pictographs recognition based on improved residual learning
-
摘要: 基于深度学习模型的东巴象形文字识别效果明显优于传统算法,但目前仍存在识别字数少、识别准确率低等问题。为此本文建立了包含1387个东巴象形文字、图片总量达到22万余张的数据集,大幅度增加了可识别字数,并辅助提高了东巴象形文字的识别准确率。同时,本文根据东巴象形文字相似度高、手写随意性大的特点,选择ResNet模型作为改进的网络结构,设计了残差跳跃连接方式和卷积层的数量,并通过加入最大池化层实现了下采样的改进。实验结果表明,在本文建立的东巴象形文字数据集上,改进的ResNet模型实现了东巴象形文字识别字数多且识别准确率高的最好效果,识别准确率可达到98.65%。Abstract: Dongba pictographs recognition based on deep learning model has better recognition effect than that of traditional algorithms. However, these methods have disadvantages such as small number of recognizable Dongba pictographs and low recognition accuracy. Aiming at these problems, in this study, we build a novel dataset of Dongba pictographs that contains 1387 Dongba pictographs and more than 220 thousand images. Therefore, the number of recognizable Dongba pictographs is greatly increased and the Dongba pictographs recognition accuracy is improved. Since Dongba pictographs are characterized by high similarity and random writing, ResNet is adopted as an improved network structure. Moreover, we design a residual shortcut connection and the number of convolutional layers and introduce the max-pooling into the ResNet to improve down-sampling. The experimental results demonstrate that the improved ResNet model can recognize more Dongba characters, and has achieved the highest recognition accuracy 98.65% in our dataset.
-
东巴象形文字由纳西族祖先创造,至今已有两千多年的历史。2003年,东巴古籍文献被联合国教科文组织列为“世界记忆遗产”名录,成为人类共同拥有的宝贵财富。东巴象形文字的识别一直是研究的热点和重点。早期的东巴象形文字识别研究一般采用传统算法提取东巴象形文字特征进行识别,关键步骤一般包括图像去噪、特征提取和分类器识别3个步骤。常用的图像去噪方法有中值去噪、自适应去噪和小波去噪[1];在特征提取方面,方向元素、粗网格[2-3]等统计特征比分析东巴象形文字的结构、笔画等结构特征取得的效果更好;常用的分类器模型包括支持向量机[4]、随机森林[5]等。代表性的研究有2017年徐小力等采用拓扑特征法和投影法相结合的特征提取方法,取得了84.4%的识别准确率[6]。2019年杨玉婷等通过结合东巴象形文字的结构和形态,提出了基于网格分辨率的东巴象形文字相似度测量算法,能够检索和识别不同形状的东巴象形文字[7]。上述研究虽然取得了一定的成果,但实现过程复杂且效率较低,算法的识别准确率有待提高。直到2019年,随着人工智能技术的发展,国内外开始出现基于深度学习的东巴文识别文章,2019年张泽晖建立了包含30592张图片的东巴象形文字数据集,设计了孪生网络并协同进行文字语义识别,对956个东巴象形文字测试,取得了85.6%识别准确率[8];同年,Wu[9]在训练集图像3800张,测试集图像200张的条件下,使用VGGNet取得了95.8%的识别准确率;2021年谢裕睿等提出了基于ResNet网络的东巴象形文字识别方法,建立了包含536个东巴象形文字的数据集,并对94个东巴象形文字测试,取得了93.58%的识别准确率[10]。
以上研究对东巴象形文字识别做出较大的贡献,但目前还存在一些问题:1)东巴象形文字大多包含多个异体字,且在东巴经典中广泛存在;但现有的数据集都没有涉及异体字,导致东巴经典中的大量文字不能识别;2)现有的东巴象形文字数据集规模较小,影响了算法识别的准确率;3)所采用的深度学习模型较为初级,无法适应东巴象形文字的随机性和手写不确定性,识别准确率有待进一步提高。
为了解决上述问题,本文主要做了以下两个方面的工作:
1)根据东巴象形文字字典[11-12],采用人工仿写的方法建立了1387个东巴象形文字(包括异体字)、图像规模达22万余张的东巴象形文字数据集,有效解决了异体字问题,大幅增加了可识别东巴象形文字的数量,并有效扩充了数据集的规模。2)根据东巴象形文字的图像特点,选择应用效果最好的ResNet模型作为改进的网络结构,设计了残差跳跃连接方式和卷积层的数量,并通过加入最大池化层实现了下采样的改进,有效提高了算法识别的准确率。
1. 东巴象形文字数据集建立
1.1 东巴象形文字图像获取
深度学习模型能够取得较好的识别效果,其前提是需要大量带标注的训练数据。为此本文首先研究如何建立大规模的东巴象形文字数据集,来保证识别的东巴象形文字更多,并可辅助提高算法识别的准确率。
东巴象形文字的特点可总结如下。1)内容广泛、字数多。按照属性可分为天文、地理、建筑等十八大类,共有2000余字(包括异体字)[11]。2)相似度高。结构相似的东巴象形文字因其细节部分不同,其字义亦不同。3)书写随意性较大。不同人书写的东巴象形文字都会有不规则的形变。4)异体字多。大多数东巴象形文字都有多个异体字。
上述特点增加了东巴象形文字的识别难度,因此为了获得更好的识别效果,数据集中每个东巴象形文字大约需要150张图像,才能满足训练的要求。但是仅通过东巴古籍来获取远远不能达到数量的要求,常用的数据增强方法主要是几何变换[13-15],但由于东巴文本身象形字的图画特点,相近的形状可表达不同的含义,通过几何变换可能变成其他文字,所以这种数据增强的方法难以适用东巴象形文字。
为此本文根据东巴象形文字手写或刀刻的书写习惯,提出采用人工仿写东巴象形文字字典的方法建立大规模数据集,再通过图像预处理方法提高数据集的图片质量,这样可以保证数据集中东巴象形文字的数量足够多,既可以最大幅度地增加算法可识别的东巴象形文字字数,又可以辅助提高算法识别的准确率。本文建立的东巴象形文字数据集示例如图1所示,其中每一行的5幅图片同属异体字,共有相同的释义,第一列为统一的文字释义,从中可以看出异体字之间的差别较大。
 图 1 东巴象形文字数据集示例Fig. 1 Samples of Dongba pictographs datasets
图 1 东巴象形文字数据集示例Fig. 1 Samples of Dongba pictographs datasets 下载:
全尺寸图片
下载:
全尺寸图片
1.2 东巴象形文字图像预处理
人工仿写的东巴象形文字受光照以及拍照设备等的影响,往往会产生极大的噪声,影响东巴象形文字数据集的质量,因此必须对其进行一系列的图像预处理。图2给出了本文建立东巴象形文字数据集的技术路线,具体步骤如下。
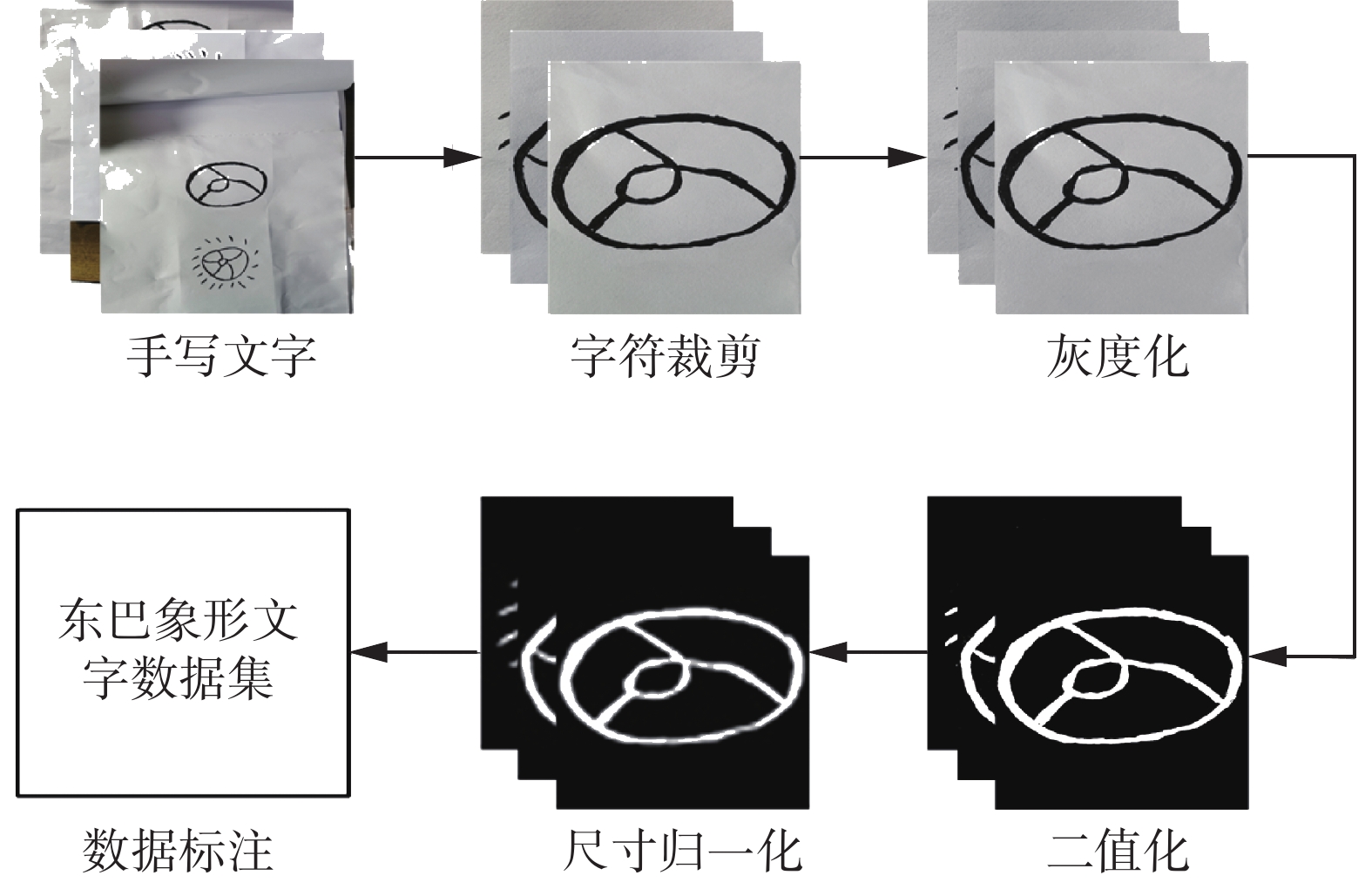 图 2 东巴象形文字数据集建立技术路线Fig. 2 Technical route for Dongba pictographs dataset establishment下载:
全尺寸图片
图 2 东巴象形文字数据集建立技术路线Fig. 2 Technical route for Dongba pictographs dataset establishment下载:
全尺寸图片
1)字符裁剪。对人工仿写的原始图像进行字符裁剪,使得每张图像中仅包含一个东巴象形文字。具体过程如算法1所示。
算法1 符裁剪算法
输入 未裁剪的手写东巴象形文字图像X;
输出 仅包含一个东巴象形文字的图像Y。
①
${{\boldsymbol{X}}_h} \leftarrow$ 图像X的高度;②
${{\boldsymbol{X}}_w} \leftarrow$ 图像X的宽度;③
${{\boldsymbol{Y}}_h} \leftarrow {1 \mathord{\left/ {\vphantom {1 3}} \right. } 3}{{\boldsymbol{X}}_h} - {2 \mathord{\left/ {\vphantom {2 3}} \right. } 3}{{\boldsymbol{X}}_h}$ ;④
${{\boldsymbol{Y}}_w} \leftarrow {1 \mathord{\left/ {\vphantom {1 3}} \right. } 3}{{\boldsymbol{X}}_w} - {2 \mathord{\left/ {\vphantom {2 3}} \right. } 3}{{\boldsymbol{X}}_w}$ ;⑤
${\boldsymbol{Y}} \leftarrow {{\boldsymbol{Y}}_h} - {{\boldsymbol{Y}}_w}$ 。2)灰度化。黑白两种颜色反差较大,可提高东巴象形文字识别的效果。为此,使用加权平均值法进行图像灰度化,去除图像的颜色信息,将三通道的彩色图像转换成单通道的灰度图像。灰度化公式如式(1)所示:
$${ {\rm{Gray}}_{i,j}} = 0.299{R_{i,j}} + 0.587{G_{i,j}} + 0.114{B_{i,j}} $$ (1) 式中:
${R_{i,j}}$ 、${G_{i,j}}$ 、${B_{i,j}}$ 分别代表图像在$ (i,j) $ 处的红、绿、蓝3种颜色分量像素值;${{\rm{Gray}}_{i,j}}$ 代表图像在$ (i,j) $ 处的灰度值。3)二值化。为了极大程度减少图像数据量,通过全局阈值二值化减少图像无关像素信息,并使整个图像呈现出明显的黑白效果,凸显东巴象形文字轮廓,图像二值化公式如式(2)所示:
$$ {b_{i,j}} = \left\{ \begin{aligned} &0,\quad{{\rm Gray}}_{i,j}\geqslant125\\ &255,\quad{{\rm Gray}}_{i,j}< 125 \end{aligned} \right. $$ (2) 式中
${b_{i,j}}$ 表示图像二值化后图像在$ (i,j) $ 处的像素值。4)尺寸归一化。常用的图像尺寸归一化方法是双线性插值法,但是当原图像与尺寸归一化图像尺寸相差过大时,尺寸归一化后的图像纹理特征易损坏,不利于深度学习模型识别。而像素区域关系重采样法能够保留完整图像信息的条件下,将输入图像尺寸最大程度减小,大幅度减少图像像素数以及数据量,在保证深度学习模型识别准确率不变的前提下,加快模型的训练速度。根据其他数据集图像尺寸大小设置的经验以及多次对比实验验证,我们发现当图像尺寸归一化为
$ 64 \times 64 $ 时,可以取得最好的识别效果,并且模型训练速度快。本文对像素区域关系重采样法和双线性插值法在东巴文字图像上的效果进行了简单的实验对比,分别将图像尺寸归一化为$ 64 \times 64 $ 。图3给出了实验结果。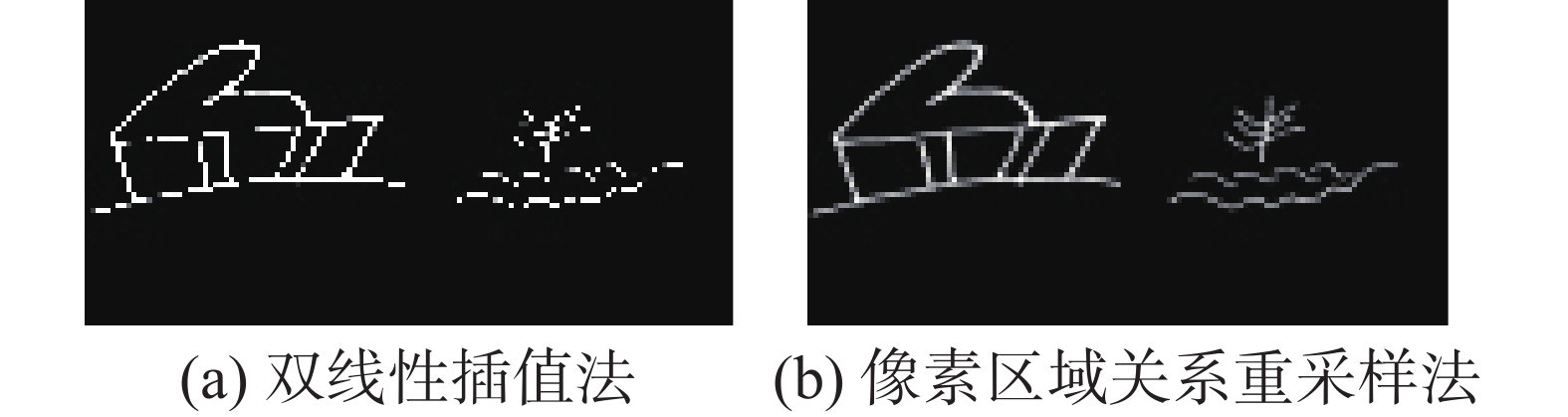 图 3 两种尺寸归一化方法示例Fig. 3 Samples of two size normalization methods下载:
全尺寸图片
图 3 两种尺寸归一化方法示例Fig. 3 Samples of two size normalization methods下载:
全尺寸图片
从图3中可以看出,双线性插值法后的东巴象形文字纹理特征有残缺,而像素区域关系重采样可获得更好的尺寸归一化效果。
因此本文选择像素区域关系重采样法进行尺寸归一化操作,其公式如式(3)所示:
$$ \begin{gathered} {\boldsymbol{A}}{\text{ = }}{\boldsymbol{B}} \odot {\boldsymbol{\alpha}} \hfill \\ {f_{i,j}} = \frac{{\displaystyle\sum\limits_{i,j} {{a_{i,j}}} }}{{\displaystyle\sum\limits_{i,j} {{\alpha _{i,j}}} }} \hfill \\ \end{gathered} $$ (3) 式中:B表示图像某区域内像素值矩阵;
$\boldsymbol {\alpha}$ 是与B相对应的像素值系数矩阵,其取值取决于原图像与尺寸归一化图像的尺寸大小关系;$ \odot $ 表示Hadamard积;${f_{i,j}}$ 表示图像B区域通过尺寸归一化后的像素值。5)数据标注。通过数据编码标注,将第i个东巴象形文字的所有图像I统一编码为i,使计算机将图像和编码相互对应,如式(4)所示:
$$ F({\boldsymbol{I}}) = i $$ (4) 式中
$ F(·) $ 表示编码标注算法,具体过程如算法2所示。算法2 编码标注算法
输入 train,test (其中有命名为i(包含图像I)的文件夹)
输出 图像I与其编码i相互对应的txt文档
① for i
$ \in $ train,test;②for I
$ \in i $ ;③将I的绝对地址和i写入txt文档;
④换行;
⑤重复迭代2)~4);
⑥返回图像I与其编码i相互对应的txt文档
通过上述一系列的图像预处理,本文建立了东巴象形文字数据集,该数据集包含1387个东巴象形文字(包括异体字),每个东巴象形文字对应160余张书写各异的图片,数据集图片总量为223050张。
2. 改进残差学习神经网络
近年来,深度学习成功应用于图像识别[16-19]领域,提出了一系列性能优异的网络模型,其中ResNet模型首次提出残差跳跃连接(residual shortcut connection)结构[20],解决了网络加深带来的梯度消失问题以及神经网络深度与识别准确度之间的矛盾,可有效提取更多的图像细节特征,目前已成为图像识别的主流深度学习模型。
考虑到东巴象形文字识别的具体问题,不仅字数多、书写随意性较大,而且有些字形较为相似,因此需要提取细节特征能力强的网络结构,为此本文选择ResNet模型作为本文改进的网络结构,设计了残差跳跃连接方式和卷积层的数量,并通过加入最大池化层实现了对下采样的改进,更好地提取了东巴象形文字的纹理分布特征。本文设计的网络主要框架如图4所示。下面将详细介绍设计思路和改进方法。
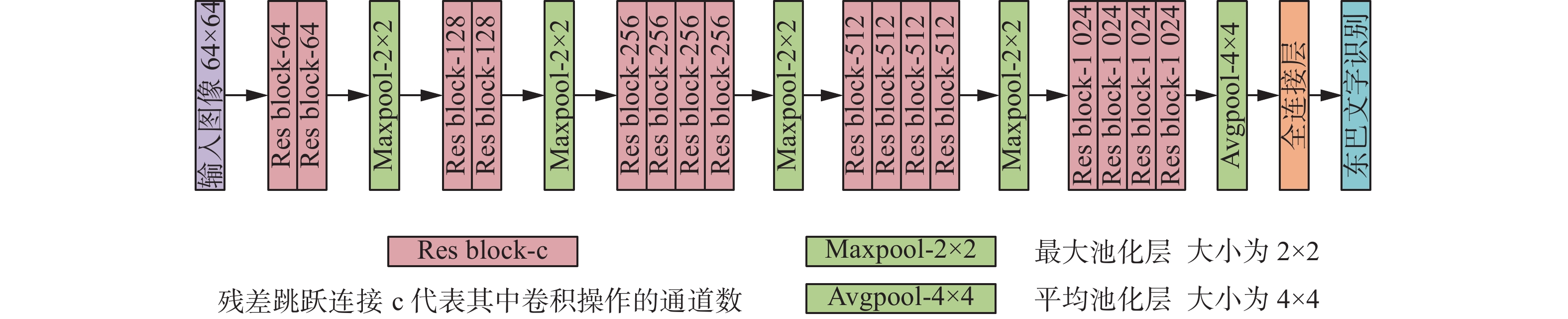 图 4 东巴象形文字识别网络结构Fig. 4 Network structure of Dongba pictographs recognition下载:
全尺寸图片
图 4 东巴象形文字识别网络结构Fig. 4 Network structure of Dongba pictographs recognition下载:
全尺寸图片
2.1 残差跳跃连接
残差跳跃连接可以解决神经网络随着深度增加出现性能退化的问题。深层神经网络难以拟合的原因是恒等映射
$ H(x) = x $ 的学习比较困难,但当把网络设计为$ H(x) = F(x) + x $ 时,可以把学习恒等映射转化为更加容易学习的残差映射$ F(x) = H(x) - x $ ,并且$ F(x) $ 对输出变化更加敏感,参数的调整幅度更大,从而可以加快学习速度,提高网络的优化性能。残差跳跃连接的一般定义如式(5)所示:$$ {{y}} = F(x,\{ {W_i}\} ) + {W_s}{{x}} $$ (5) 其中
$ {W_s} $ 主要是用$ 1 \times 1 $ 卷积[21]来匹配残差跳跃连接输入x和输出y的通道维度。$ F(x,\{ {W_i}\} ) $ 为网络需要学习的残差映射。而当残差跳跃连接输入和输出维度相同时,可将其定义如式(6)所示:$$ {{y}} = F(x,\{ {W_i}\} ) + {{x}} $$ (6) 文献[22]证明了越是接近当前卷积层的前层输出对当前层的特征提取效果影响越大,可以使网络更容易训练。为此本文仅将相邻堆叠的卷积层组成残差跳跃连接结构,在有效重复利用特征图的同时,降低网络参数量和复杂度。本文残差跳跃连接结构如图5所示。图5中残差映射
$ F({{x}}) $ 如式(7)所示,输出y和输入x的关系式如式(8)所示:$$ F({{x}}) = {W_2}\sigma ({W_1}{{x}}) $$ (7) $$ {{y}} = \sigma ({W_2}\sigma ({W_1}x) + x) $$ (8) 式中:
$ \sigma $ 均表示ReLU激活函数,$ {W_1} $ 和$ {W_2} $ 分别表示卷积层学习的参数。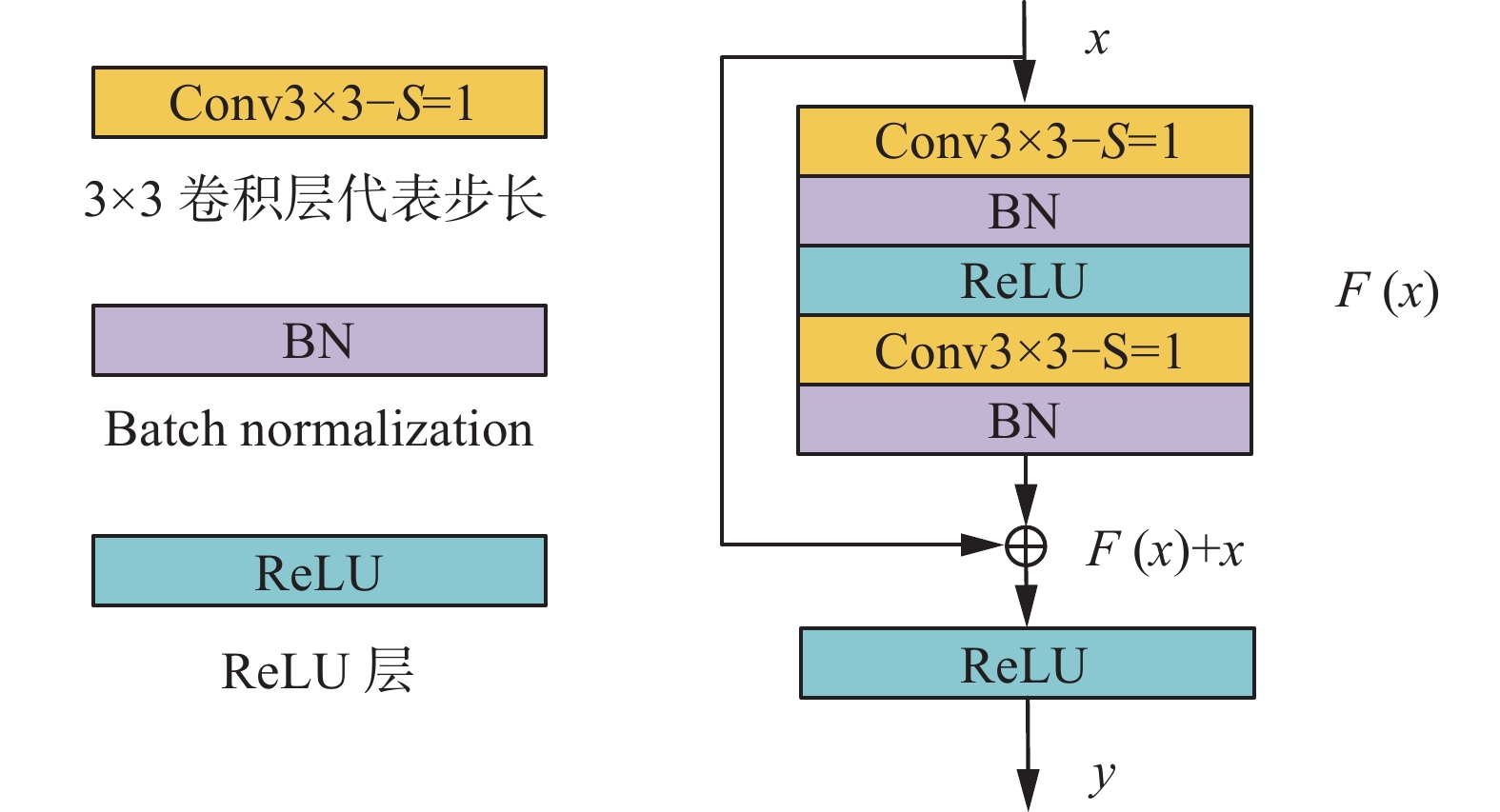 图 5 本文残差跳跃连接模块Fig. 5 Residual skip connection module of this paper下载:
全尺寸图片
图 5 本文残差跳跃连接模块Fig. 5 Residual skip connection module of this paper下载:
全尺寸图片
2.2 卷积层的选择
网络模型卷积核的选择与网络计算量大小密切相关。尽管大的卷积核可以直接增大感受野,但是会带来网络计算量的暴增,而多个
$ 3 \times 3 $ 卷积核可以在降低计算量的前提下实现$ 5 \times 5 $ 或$ 7 \times 7 $ 乃至更大卷积核的效果。由式(9)可以发现,3个$ 3 \times 3 $ 卷积核实现$ 7 \times 7 $ 卷积核效果时,其参数量可以减少到55%。$$ \eta = \frac{{3 \times 3 \times 3 \times {C^2}}}{{7 \times 7 \times {C^2}}} \times 100{\text{%}} \approx 55{\text{%}} $$ (9) 其中C指输入和输出的通道数。
除了能够降低网络模型的计算量,单个
$ 3 \times 3 $ 卷积核还可以捕获特征图像素四周的信息,多个$ 3 \times 3 $ 卷积核的叠加还可以直接增加网络深度[23],使网络模型的特征提取能力更强,从而取得更好的识别效果。东巴象形文字具有字数多、字形相似等特点,因此需要提取特征能力强的网络结构,而多个
 卷积层的叠加能够在参数量最少的前提下实现最好的特征提取能力。因此本文设计了32层
卷积层的叠加能够在参数量最少的前提下实现最好的特征提取能力。因此本文设计了32层
$ 3 \times 3 $ 的卷积层,再加1层全连接层,构成33层网络模型,用以获得东巴象形文字最好的识别效果。同时,为了防止网络过拟合,加快网络训练速度,本文对每一个卷积层执行批量归一化(batch normalization)[24]操作。然后再使用修正线性单元ReLU[25](rectified linear units)
$ f(x) = \max (0,x) $ 作为激活函数,增强网络的非线性表达能力,在$ x > 0 $ 时保持梯度不衰减,从而缓解网络出现的梯度消失问题。2.3 下采样改进
下采样可以降低特征图维度,保留图像主要特征的同时减少网络模型的参数量,防止过拟合现象的发生。在ResNet模型中通常采用令卷积步长
$ {\rm{Stride}} = 2 $ 来实现下采样的效果,但是由于本文建立的东巴象形文字数据集经过灰度归一化后,其前景像素值远远大于背景像素值,用这种方法实现下采样获得的东巴象形文字纹理特征不够丰富,影响了识别效果,因此有必要对下采样进行改进。最大池化层通过提取特征图局部区域内的像素最大值,可以最大程度降低特征图背景的无关信息,使网络模型提取更多有用的前景特征,降低背景特征干扰。因此,本文对ResNet模型中的下采样方式进行了改进,通过采用最大池化层来获得丰富的纹理特征。最大池化层的公式如式(10)所示:
$$ {\rm{poolin{g}}}_{\rm{max}}={\rm{max}}{a}_{i},\quad i\in {r}_{k} $$ (10) 其中:
$ {r_k}(k = 1,2, \cdots ,K) $ 为特征图所划分的多个区域,$ {a_i} $ 表示第i区域内的像素值。而网络深层的平均池化层通过提取特征图的像素加权值,可以保留更加完整的特征图信息。并且通过平均池化将特征图下采样为
$ 1 \times 1 $ 后再与全连接层相连接,可以减少网络参数。池化层的池化区域为特征图中的连续区域,对小的形态改变具有不变性,不仅能够逐步减少特征图的空间大小、参数数量、内存占用和计算量,而且拥有更大的感受野,可有效控制过拟合现象的发生。3. 实验结果及分析
为验证本文创新工作的有效性与先进性,实验部分主要做了3个方面的工作:1)本文建立的东巴象形文字数据集对比实验及分析;2)本文提出的东巴象形文字识别方法对比实验及分析,包括网络改进前后的对比实验;3)结合实验结果,分析归纳了目前仍存在的问题。
3.1 实验条件
实验中所有对比实验均在表1所示的实验平台上运行。
表 1 实验环境配置Table 1 Experimental environment configurations配件 参数 操作系统 Ubuntu 16.04 处理器 IntelRCoreTMi7-7700CPU@3.60 GHz 显卡 GeForce GTX 1070 Ti 内存 16 GB 开发工具 Pytorch1.0.0 Python3.6.2 实验epoch设置为80,初始学习率设置为0.001,每50个epoch将学习率降低为原来的三分之一,直到运行结束所有epoch。
本文梯度优化函数选择Adam函数,损失函数使用交叉熵函数,交叉熵函数定义如式(11)所示:
$$ L = - {\rm{log}}\left( {\frac{{{\rm{exp}} ({x_j})}}{{\displaystyle\sum\limits_i {{\rm{exp}} ({x_i})} }}} \right) = - {x_j} + {\rm{log}} \displaystyle\sum\limits_i {\exp ({x_i})} $$ (11) 其中
$ {x_j} $ 代表全连接层第j个网络节点输出值。本文改进的ResNet模型具体参数如表2所示。
3.2 本文建立的数据集验证
目前关于东巴象形文字的数据集较少,文献[8-10]是目前已知的3个东巴象形文字数据集,因此将本文的数据集与上述3种数据集都进行了对比实验。
3.2.1 数据集有效性验证
这里选取在图像识别领域表现优异的ResNet18、ResNet34、VGGNet以及本文的改进网络模型在本文建立的东巴象形文字数据集上进行识别效果对比。在数据集中随机选取5000张图像计算其均值和方差,然后将图像归一化处理后输入网络。随机选取数据集图片总数的80%作为训练集,即178223张图片,其余44827张图片作为测试集。在训练集上训练网络模型后,在测试集上对1387个东巴象形文字(包括异体字)进行识别准确率测试。其实验结果如表3所示。
表 2 本文网络参数设计Table 2 Network configurations of this paper网络层 卷积核 输出图像
尺寸大小/
像素×像素输出通道数 输入层 / $ 64 \times 64 $ 1 卷积层 $ \left[\begin{array}{c}3\times 3步长\text{=}1\\ 3\times 3步长\text{=}1\end{array}\right]\times 2 $ $ 64 \times 64 $ 64 最大池化 $ 2 \times 2 $步长=2 $ 32 \times 32 $ 64 卷积层 $ \left[\begin{array}{c}3\times 3步长\text{=}1\\ 3\times 3步长\text{=}1\end{array}\right]\times 2 $ $ 32 \times 32 $ 128 最大池化 $ 2 \times 2 $步长=2 $ 16 \times 16 $ 128 卷积层 $ \left[\begin{array}{c}3\times 3步长\text{=}1\\ 3\times 3步长\text{=}1\end{array}\right]\times 4 $ $ 16 \times 16 $ 256 最大池化 $ 2 \times 2 $步长=2 $ 8 \times 8 $ 256 卷积层 $ \left[\begin{array}{c}3\times 3步长\text{=}1\\ 3\times 3步长\text{=}1\end{array}\right]\times 4 $ $ 8 \times 8 $ 512 最大池化 $ 2 \times 2 $步长=2 $ 4 \times 4 $ 512 卷积层 $ \left[\begin{array}{c}3\times 3步长\text{=}1\\ 3\times 3步长\text{=}1\end{array}\right]\times 4 $ $ 4 \times 4 $ 1024 平均池化 $ 4 \times 4 $ $ 1 \times 1 $ 1024 全连接层 softmax 表 3 数据集有效性验证实验Table 3 Experiment of dataset validity verification测试模型 识别准确率/% ResNet18 98.22 ResNet34 98.01 VGGNet 98.34 本文算法 98.65 从表3中可以看出,对于不同的网络模型,本文建立的东巴象形文字数据集都获得了高于98%的识别准确率,最高可达98.65%,这说明本文建立的东巴象形文字数据集是有效的,每个东巴象形文字多达160多张书写各异的图片,其数据规模完全满足具体识别的要求。
3.2.2 数据集先进性验证
文献[8-10]分别给出了3种东巴象形文字识别方法和与之对应的3个东巴象形文字数据集,这里采用这3种识别方法在本文提出的数据集上分别进行了识别准确率方面的对比实验。表4给出了各个数据集能够识别的字数和不同模型在数据集上进行识别的准确率。
从表4中可以看出,首先本文建立的数据集能够识别的东巴象形文字最多;其次,相同的网络模型在不同的东巴象形文字数据集上取得的识别效果不同,相较于其他3个文献所建立的数据集,本文建立的数据集采用3种相对应的网络模型都取得了最高的识别准确率,说明本文建立的数据集在数据规模和数据质量上都是目前最好的,也说明优秀的数据集可辅助提高深度学习模型的性能。
3.3 本文识别算法的实验验证
根据东巴象形文字识别的特点,本文对ResNet模型进行了改进,提高了东巴象形文字的识别准确率。这里将验证本文网络模型改进的有效性。通过将其与采用残差跳跃连接加传统池化方式以及无残差跳跃连接加最大池化方式的网络模型进行消融实验。同时,将本文改进的网络模型与文献[8-10]中取得识别准确率最高的网络模型以及ResNet34进行对比实验,以验证其先进性。所有实验在本文建立的数据集上进行。
3.3.1 算法的有效性验证
为了验证本文改进ResNet模型的有效性,这里进行了改进前后的对比实验。将本文改进的网络模型(残差+最大池化)与残差加传统池化、无残差加最大池化3种网络模型进行识别效果对比,实验结果如表5所示。
表 5 算法有效性验证实验Table 5 Experiment of algorithm validity verification测试模型 识别准确率/% 残差+传统池化 98.11 无残差+最大池化 97.64 残差+最大池化 98.65 由表5可以看出,本文改进的残差跳跃连接加最大池化下采样网络模型取得了最高的识别准确率,相较于残差跳跃连接加传统池化的网络模型提高了0.54%;相较于无残差跳跃连接加最大池化下采样的网络模型提高了1.01%,从而验证了本文改进残差跳跃连接加最大池化网络模型的有效性。
3.3.2 算法的先进性验证
为了验证本文改进网络模型的先进性,在相同的实验环境下,本文分别与文献[8]采用的ResNet18网络模型、文献[9]采用的VGGNet网络模型以及文献[10]采用的20层ResNet网络模型进行了对比实验,实验结果如表6所示。
从表6中可以看出,本文改进的网络模型识别准确率最高,相较于文献[8]的方法提高了0.43%;相较于文献[9]的方法提高了0.31%;相较于文献[10]的方法提高了0.95%。充分验证了本文改进网络模型的先进性。
同时,本文又与层数有所增加的ResNet34网络进行了对比性实验。从表6中可以看出,34层网络模型的识别准确率不仅低于本文的33层网络模型,而且也低于18层的网络模型,这说明网络层数的简单叠加在具体的东巴象形文字识别中不一定获得更好的识别效果。
3.4 存在的问题
虽然本文取得了98.65%的识别准确率,但对于误识别问题我们又进行了深入分析,通过观察多次实验结果,发现错误识别的东巴象形文字都有一个共同的特点,那就是都有与之非常相似的东巴象形文字,图6给出了部分相似文字的示例。
 图 6 相似东巴象形文字示例Fig. 6 Samples of similar Dongba pictographs下载:
全尺寸图片
图 6 相似东巴象形文字示例Fig. 6 Samples of similar Dongba pictographs下载:
全尺寸图片
从图6可以看出,“水槽”和“水涧”,“侧视之人”和“左”或“爬”等字的区别仅仅体现在线条的弯曲程度不同;“腰”和“爬”更多体现在它们之间大小有所差异;“神山山脚”和“神山山腰”,“中”和“矛”主要体现在图像上部分所画的高度不同;“尾巴”和“树倒”的差异体现在右下角线条的长度和弯曲程度;“臂膀”和“手”则几乎相同。
可见,东巴象形文字中有很多相似乃至接近“相同”的文字,又因为东巴象形文字的手工书写形式,随意性较大,这些相似的东巴象形文字在书写过程中极容易导致差异性变小、辨识度下降,这是影响东巴象形文字识别准确率的主要原因。
4. 结束语
针对现有东巴象形文字识别方法存在的识别文字数量少、识别准确率较低等问题,本文首先建立了包含1387个东巴象形文字(包括异体字)、图片总量达到22万余张的东巴象形文字数据集,可识别的东巴象形文字大幅增加。通过扩大数据集的规模,辅助提高了算法识别的准确率;更为重要的是本文选择ResNet模型作为改进的网络结构,设计了残差跳跃连接方式和卷积层的数量,并通过加入最大池化层实现了对下采样的改进,更好地提取了东巴象形文字的纹理分布特征。通过对1387个东巴象形文字(包括异体字)分别进行测试,实验结果表明,本文提出的改进ResNet模型识别准确率平均达到98.65%,取得了当前识别字数最多、识别准确率最高的效果。
未来将继续扩大东巴象形文字数据集的文字数量,力争包含现存的所有东巴象形文字。针对其中相似度极高的文字,将研究设计专门的网络模型来有效将它们区别开来,从而进一步提高东巴象形文字识别的准确率。
-
图 1 东巴象形文字数据集示例
Fig. 1 Samples of Dongba pictographs datasets
下载:
全尺寸图片
图 2 东巴象形文字数据集建立技术路线
Fig. 2 Technical route for Dongba pictographs dataset establishment
下载:
全尺寸图片
图 3 两种尺寸归一化方法示例
Fig. 3 Samples of two size normalization methods
下载:
全尺寸图片
图 4 东巴象形文字识别网络结构
Fig. 4 Network structure of Dongba pictographs recognition
下载:
全尺寸图片
图 5 本文残差跳跃连接模块
Fig. 5 Residual skip connection module of this paper
下载:
全尺寸图片
图 6 相似东巴象形文字示例
Fig. 6 Samples of similar Dongba pictographs
下载:
全尺寸图片
表 1 实验环境配置
Table 1 Experimental environment configurations
配件 参数 操作系统 Ubuntu 16.04 处理器 IntelRCoreTMi7-7700CPU@3.60 GHz 显卡 GeForce GTX 1070 Ti 内存 16 GB 开发工具 Pytorch1.0.0 Python3.6.2 表 2 本文网络参数设计
Table 2 Network configurations of this paper
网络层 卷积核 输出图像
尺寸大小/
像素×像素输出通道数 输入层 / $ 64 \times 64 $ 1 卷积层 $ \left[\begin{array}{c}3\times 3步长\text{=}1\\ 3\times 3步长\text{=}1\end{array}\right]\times 2 $ $ 64 \times 64 $ 64 最大池化 $ 2 \times 2 $步长=2 $ 32 \times 32 $ 64 卷积层 $ \left[\begin{array}{c}3\times 3步长\text{=}1\\ 3\times 3步长\text{=}1\end{array}\right]\times 2 $ $ 32 \times 32 $ 128 最大池化 $ 2 \times 2 $步长=2 $ 16 \times 16 $ 128 卷积层 $ \left[\begin{array}{c}3\times 3步长\text{=}1\\ 3\times 3步长\text{=}1\end{array}\right]\times 4 $ $ 16 \times 16 $ 256 最大池化 $ 2 \times 2 $步长=2 $ 8 \times 8 $ 256 卷积层 $ \left[\begin{array}{c}3\times 3步长\text{=}1\\ 3\times 3步长\text{=}1\end{array}\right]\times 4 $ $ 8 \times 8 $ 512 最大池化 $ 2 \times 2 $步长=2 $ 4 \times 4 $ 512 卷积层 $ \left[\begin{array}{c}3\times 3步长\text{=}1\\ 3\times 3步长\text{=}1\end{array}\right]\times 4 $ $ 4 \times 4 $ 1024 平均池化 $ 4 \times 4 $ $ 1 \times 1 $ 1024 全连接层 softmax 表 3 数据集有效性验证实验
Table 3 Experiment of dataset validity verification
测试模型 识别准确率/% ResNet18 98.22 ResNet34 98.01 VGGNet 98.34 本文算法 98.65 表 4 数据集先进性验证实验
Table 4 Experiment of dataset advancement verification
表 5 算法有效性验证实验
Table 5 Experiment of algorithm validity verification
测试模型 识别准确率/% 残差+传统池化 98.11 无残差+最大池化 97.64 残差+最大池化 98.65 -
[1] GUO Hai, ZHAO Jingying, LI Xiaoniu. Preprocessing method for NaXi pictographs character recognition using wavelet transform[J]. International journal of digital content technology and its applications, 2010, 4(3): 117–131. doi: 10.4156/jdcta.vol4.issue3.12 [2] GUO Hai, ZHAO Jingying. Research on feature extraction for character recognition of NaXi pictograph[J]. Journal of computers, 2011, 6(5): 947–954. [3] DA Mingjun, ZHAO Jingying, SUO Guojie, et al. Online handwritten Naxi pictograph digits recognition system using coarse grid[C]//Computer science for environmental engineering and EcoInformatics. Berlin, German: Springer, 2011: 390−396. [4] HSU C W, LIN C J. A comparison of methods for multiclass support vector machines[J]. IEEE transactions on neural networks, 2002, 13(2): 415–425. doi: 10.1109/72.991427 [5] BREIMAN L. Random forests[J]. Machine learning, 2001, 45(1): 5–32. doi: 10.1023/A:1010933404324 [6] 徐小力, 蒋章雷, 吴国新, 等. 基于拓扑特征和投影法的东巴象形文识别方法研究[J]. 电子测量与仪器学报, 2017, 31(1): 150–154. https://www.cnki.com.cn/Article/CJFDTOTAL-DZIY201701024.htm XU Xiaoli, JIANG Zhanglei, WU Guoxin, et al. Identification method of Dongba pictograph based on topological characteristic and projection method[J]. Journal of electronic measurement and instrumentation, 2017, 31(1): 150–154. https://www.cnki.com.cn/Article/CJFDTOTAL-DZIY201701024.htm [7] 杨玉婷, 康厚良. 东巴象形文字特征曲线提取算法研究[J]. 图学学报, 2019, 40(3): 591–599. https://www.cnki.com.cn/Article/CJFDTOTAL-GCTX201903025.htm YANG Yuting, KANG Houliang. Research on the extracting algorithm of dongba hieroglyphic feature curves[J]. Journal of graphics, 2019, 40(3): 591–599. https://www.cnki.com.cn/Article/CJFDTOTAL-GCTX201903025.htm [8] 张泽晖. 基于卷积神经网络的东巴文字分类与识别[D]. 昆明: 云南大学, 2019. ZHANG Zehui. Classification and recognition of dongba characters based on convolutional neural network[D]. Kunming: Yunnan University, 2019. [9] WU Guoxin, LIU Xiuli, JIANG Zhanglei, et al. Dongba classical ancient books image classification method based on ReN-Softplus convolution residual neural network[C]//2019 14th IEEE International Conference on Electronic Measurement & Instruments. New York, USA: IEEE, 2019: 398−404. [10] 谢裕睿, 董建娥. 基于ResNet网络的东巴象形文字识别研究[J]. 计算机时代, 2021(1): 6–10. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJS202101002.htm XIE Yurui, DONG Jian'e. Research on Dongba hieroglyph recognition using ResNet network[J]. Computer era, 2021(1): 6–10. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJS202101002.htm [11] 李霖灿. 纳西族象形标音文字字典[M]. 昆明: 云南民族出版社, 2001. LI Lincan. Naxi Pictographs and Transcription Characters Dictionary[M]. Kunming: Yunnan Nationalities Publishing House, 2001. [12] 方国瑜, 和志武. 纳西象形文字谱[M]. 昆明: 云南人民出版社, 1981. FANG Guoyu, HE Zhiwu. Naxi pictograph character chart[M]. Kunming: Yunnan People’s Publishing House, 1981. [13] BUSLAEV A, PARINOV A, KHVEDCHENYA E, et al. Albumentations: fast and flexible image augmentations[EB/OL]. (2018-09-18) [2021-11-30].https://arxiv.org/abs/1809.06839. [14] ZHANG Hongyi, MOUSTAPHA Cisseet, YANN N Dauphin, et al. Mixup: beyond empirical risk minimization[EB/OL]. (2017-10-25) [2021-11-30].https://arxiv.org/abs/1710.09412. [15] DAN Hendrycks, NORMAN Mu, EKIN D Cubuk, et al. AugMix: A simple data processing method to improve robustness and uncertainty[EB/OL]. (2019-12-05) [2021-11-30].https://arxiv.org/abs/1912.02781. [16] HE Tong, ZHANG Zhi, ZHANG Hang, et al. Bag of tricks for image classification with convolutional neural networks[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2019: 558−567. [17] KHAN A, SOHAIL A, ZAHOORA U, et al. A survey of the recent architectures of deep convolutional neural networks[J]. Artificial intelligence review, 2020, 53(8): 5455–5516. doi: 10.1007/s10462-020-09825-6 [18] XIE Saining, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2017: 5987−5995. [19] TAN Mingxing, LE Quoc V. EfficientNet: rethinking model scaling for convolutional neural networks[EB/OL]. (2019-05-28) [2021-11-30].https://arxiv.org/abs/1905.11946. [20] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2016: 770−778. [21] LIN Min, CHEN Qiang, YAN Shuicheng. Network in network[EB/OL]. (2013-12-16) [2021-11-30].https://arxiv.org/abs/1312.4400. [22] HUANG Gao, LIU Shichen, MAATEN L V D, et al. CondenseNet: an efficient DenseNet using learned group convolutions[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2018: 2752−2761. [23] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2014-09-04) [2021-11-30].https://arxiv.org/abs/1409.1556v3. [24] IOFFE Sergey, SZEGEDY Christian. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]//2015 International Conference on Machine Learning. New York, USA: ACM, 2015: 448−456. [25] VINOD Nair, GEOFFREY E Hinton. Rectified Linear Units Improve Restricted Boltzmann Machines[C]//2010 International Conference on Machine Learning. New York, USA: ACM, 2010: 807−814.



























































