
Keypoint-based graph contrastive neural network for image classification
-
摘要: 深度学习是目前图像分类的主流方法之一,其重视感受野内的局部信息,却忽略了类别的先验拓扑结构信息。本文提出了一种新的图像分类方法,即Key-D-Graph,这是基于关键点的图对比网络方法,在识别图像类别时可以显式地考虑拓扑先验结构。具体地,图像分类需要2个步骤,第一步是基于关键点构建图像的图表达,即采用深度学习方法识别图像中目标类别的可能关键点,并采用关键点坐标生成图像的拓扑图表达;第二步基于关键点的图像图表达建立图对比网络,以估计待识别图与目标类别之间的结构差异,实现类别判断,该步骤利用了物体的拓扑先验结构信息,实现了基于图像全局结构信息的物体识别。特别的,Key-D-Graph的中间输出结果为类别关键点,具有语义可解释性,便于在实际应用中对算法逐步分析调试。实验结果表明,提出的方法可在效率和精度上超过主流方法,且通过消融实验分析验证了拓扑结构在分类中的作用机制和有效性。Abstract: At present, deep learning is one of the mainstream methods for image classification. It focuses more on local features in the receptive field than the prior information of topological structure of the category. In this paper, We propose a Keypoint-based Discriminator Graph neural network (Key-D-Graph) for image binary classification method, which is a graph comparison network method based on key points. It explicitly introduces the topology prior structure when identifying image categories. The method contains two main steps. The first step is to build the graph representation of an image with the keypoints, that is, identifying possible key points of the target category in the image by a deep learning method, and then using the coordinates of the key points to generate the topological representation of the image. The second step is to build a graph contrastive network based on the image representation of key points, so as to estimate the structural difference between the graph to be identified and the object graph, realizing object discrimination. In this step, the topological prior structure information of the object is used to realize object recognition based on the global structure information of the image. Especially, the intermediate output results of Key-D-Graph are the key points of categories containing explicit semantic information, which facilitates analysis and debugging of the algorithm step by step in practical application. Contrast experiments show that the proposed method outperforms the mainstream methods both in efficiency and precision. And the mechanism and effectiveness of topological structure in classification are verified by the ablation experiments.
-
图像分类是计算机视觉的关键问题之一,由于图像的复杂背景带来了大量数据噪声,在几十万维的数据中获取高效的图像特征表达是解决该问题的难点之一。传统的图像分类方法主要利用人工设计的特征,例如方向梯度直方图、尺度不变特征,从图像的纹理、形状、颜色角度提取图像特征,达到图像降维目的后,再采用贝叶斯、支持向量机、随机森林、KNN 等分类器实现分类[1-2]。传统方法的优势在于人工设计的特征表达往往具有语义解释,因此分类结果具有可解释性,但是由于真实环境获取的图像背景复杂,导致提取的特征不能适用于真实环境图片分类任务。随着深度学习方法的发展,特别是深度卷积神经网络(deep neural convolutional networks, DCNN) 的出现[3-4],例如Alexnet[5]、VGG[6]、Googlenet[7],图像特征提取能力进一步提升,分类精度大幅提高。2016年,He等[8]提出了残差网络,进一步加深网络提高了DCNN 提取图像高层特征能力。随后 DenseNet[9]、Inception系列网络[10]等各种深度卷积网络变体陆续提出,网络加深的同时开始变得更宽,以便于融合多尺度特征,从而进一步提升分类精度[11]。伴随着网络规模快速增长的同时,降低网络参数量、提高运算效率逐步成为研究者关注的目标。自动机器方法被引入进该领域,目的是通过算法优化网络结构[12-14],EfficientNet[15]系列网络就是由此提出的兼顾效率和性能的一类网络。虽然 DCNN 方法的效率得以提升,但网络学习的图像的分类特征仍然难以解释,端到端网络内部的机制仍不明确。研究人员通过可视化中间层特征,以分析网络内部工作原理,发现浅层网络的前几层是一些抽象的图像局部纹理和颜色特征[16]。2018 年Gerihos等[17]对DCNN 的工作机制进行了研究,该研究通过重新组合图像的纹理和轮廓生成新图像,比较新生成图像与原图像分类结果,发现 DCNN决策更偏好于局部纹理信息。
因此本文显式地引入图像中物体拓扑结构并将其与深度学习方法结合,提出了基于关键点的图对比图像分类方法 (Key-D-Graph),该方法在有效利用图像局部特征的同时,结合物体整体拓扑结构进行图像分类。Key-D-Graph从图像局部特征和全局拓扑特征的利用上进行解耦,将图像分类任务分解为一个关键点识别问题和一个基于图表征的组合优化问题。通过这种解耦,可以利用物体结构先验实现图像的高效图表示,降低了将问题作为一个整体求解的难度。
首先,关键点识别任务通过识别图像特定的局部特征确定关键点位置。独立的关键点识别研究主要集中在特定的类别,例如斑点、角点检测,采用尺度不变特征变换 (scale-invariant feature transform, SIFT) 等局部特征描述符描述图像局部特征并确定关键点位置[18]。基于深度学习的关键点检测方法常见于特定物体类别的识别任务中,例如人脸识别、人体位姿估计等。因为关键点识别无需全局感受野,常用全卷积网络框架进行稠密估计,输出整个图像范围的关键点位置响应[19]。2020 Wang 等[20]提出的HRnet (high-resolution representation network) 采用全连接网络融合不同尺度的层级特征,在图像稠密预测问题中表现出众,在图像语义分割以及关键点识别等任务中均实现了性能提升。考虑到关键点识别与图像分类相比,判别对象涉及的图像区域大大减少,在较小的图像感受野中提取的特征即可实现关键点识别。因此,本文引入HRnet网络实现关键点识别。
其次,关键点特征特异性差,容易出现误检,因此Key-D-Graph 在关键点识别的基础上结合图像的拓扑信息进行物体类别判断。近几年,图神经网络是处理图结构信息数据最出色的方法之一,图卷积网络、图注意力网络、Graph SAGE 网络为代表的各种图网络变体相继被提出,该方法在分子性质预测、社交网络分析等图结构数据分析任务上取得了令人瞩目的成绩[21-23]。该类网络通过图节点之间的信息传播、聚合以及节点信息的更新迭代来获取图上的特征。并且图神经网络的出色表现得益于它的拓扑表征能力,2019 年Xu等[24]提出了图同构网络,对图神经网络的拓扑结构信息的图表示性能进行了分析,证明了在单射形式的聚合函数下,图神经网络可以达到 1-WL (weisfeiler-leman) 测试效果。因此本文建立了基于类别结构先验的图神经网络分类图像结构特征,最终实现图像分类。
具体地,通过确定的图像关键点位置,利用三角剖分构建拓扑结构,生成基于关键点的图表达,在该图表达的基础上,采用暹罗图网络框架对比学习实现类别分类。
暹罗网络最早于2005年由Chopra等提出,该框架后来成为对比学习的基本框架之一。对比学习一般通过二元或三元损失以及多元损失,通过对比相同类别或不同类别之间的相似或不同特征,实现类别学习[25-26]。在图像处理领域,对比学习方法最初主要集中在简单背景下的人脸识别[27]和手写字体识别任务[28]中。其主要原因是图像在背景复杂、噪声较多的情况下,相同类别图像差异过大,导致网络难以收敛。为实现网络的快速收敛,许多方法通过人工设计的数据增广规则,生成正负样本,在暹罗网络框架下通过自监督学习获得图像类别内的不变特征[29]。近几年 Hinton 以及何恺明等研究人员陆续提出了SimCLR[30]、MOCO (momentum contrast)[31]等一系列对比学习方法,方法从正负样本数据增广、批次训练等角度针对对比学习方法进行优化,有效提升了对比学习的分类性能。但是现有用于图像领域的对比方法主干网络仍为 DCNN,训练中仍然受限于精心设计的正负样本对,训练崩溃问题仍然存在[32]。而基于图神经网络的对比学习框架多用于一些引文、蛋白质、程序图等图结构数据特征提取问题[33],在图像分类领域研究较少[34]。
特别地,Key-D-Graph与已往图像对比学习方法不同在于,本文的暹罗框架输入是图像的图表达而并非原始图片,该图表达包含明确对应的图像关键点位置以及拓扑结构,不包含图像颜色纹理等信息,实现了图像局部信息与结构信息的解耦。网络输入两个图像的图表达:一个为已知类别的对照图,另一个为待分类图。对照图的结构作为类别先验引入到了分类中,通过图神经网络单图以及跨图的信息传播,在利用全局的拓扑信息的同时实现类别的区分。本文的主要工作及创新点如下:
1)针对图像建立了基于关键点的图模型,将图像分类任务转化为图分类任务。
2)针对图像分类将局部特征和全局特征进行分解,两部分特征识别耦合为类别关键点识别和基于拓扑结构先验的图对比分类两个步骤。
3)在二分类实验中,本文的实验结果验证该方法可以在计算效率和分类精度的双提升,验证了该方法的有效性。超参数分析实验通过调整关键点的阈值分析了中间结果对分类结果的影响。图对比网络消融实验分析验证了基于关键点的图对比网络在学习图片距离的有效性。仿真数据集上的拓扑结构消融实验则验证了拓扑结构信息在识别结构差别的有效性。
1. Key-D-Graph图像分类方法
基于关键点的图对比图像分类 Key-D-Graph方法,如图1 所示。首先,生成基于关键点的图表达,主要步骤包含图节点生成和图结构的确定,图节点生成采用监督学习,采用一个 HRnet 网络识别图片关键点位置,然后利用关键点在图像中的位置,三角化生成图结构,由此获得图像的图表达;其次,通过图对比方法实现图像类别分类,采用图神经网络结合先验图结构进行类别推理,从而实现基于全局图像拓扑结构的图像分类。
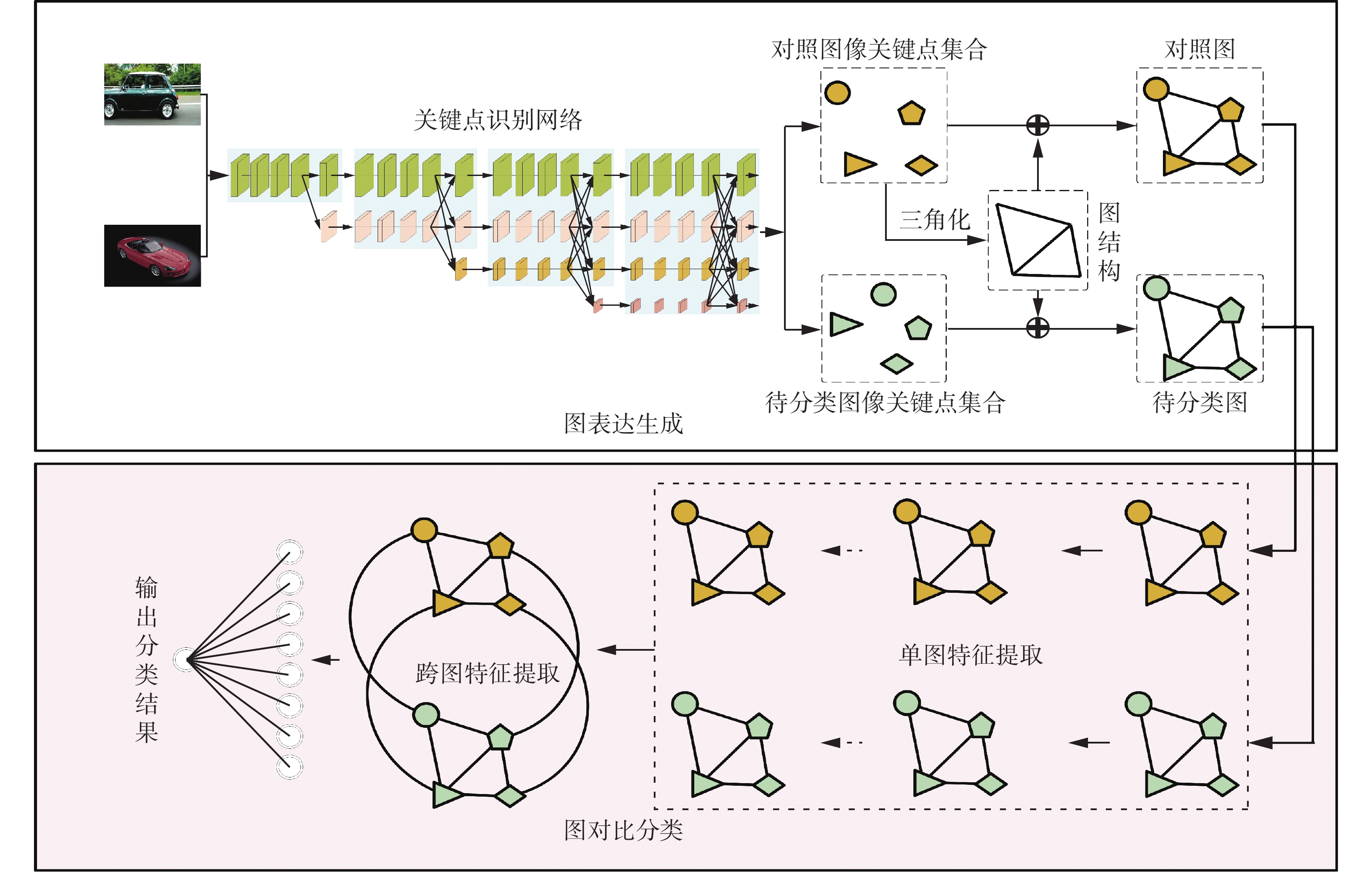 图 1 Key-D-Graph 方法流程Fig. 1 Flow of the Key-D-Graph
图 1 Key-D-Graph 方法流程Fig. 1 Flow of the Key-D-Graph 下载:
全尺寸图片
下载:
全尺寸图片
1.1 生成基于关键点的图表达
根据类别的图像的特征,首先确定一组感兴趣的类别关键点记为
$P = ({p_1},{p_2}, \cdots ,{p_l})$ , 一般认为该组特征是对应类别具有语义的一组特征,其中$l$ 为类别关键点数量,可以认为关键点集合是类别的属性集合。1.1.1 图像的关键点识别
首先依据类别知识,确定类别的关键点集合
$P$ ,关键点集合$P$ 的定义和识别体现了该类别的局部特征,包含了该类别在局部图像中与其他类别的不同。考虑到关键点特征可由一个相对较小的图像范围提取获得,深度卷积神经网络的受限的感受野也能很好的适应该问题,本文采用了 HRnet 来识别图像中的关键点,通过监督学习获取关键点位置。HRnet 网络并行地提取多尺度的特征图,并将特征图用全连接进行融合,输出高分辨率的特征。该方法在高分辨率的任务中,如分割特征点识别等任务中,用较少的参数获取更好的性能。在识别过程中,网络的输入是一张图像,输出的是关键的位置。在监督训练过程中,监督信号是图像中所有关键点的图像坐标,实际计算中先将图像的关键点坐标处理成一张热图,热图的每个红色区域对应一个关键点,由这张热图作为网络的监督信号,因此该任务是一个稠密估计任务。
具体地,网络最后一层输出为
$l \times w \times h$ ,其中$l$ 为最后一层特征的通道数,与要识别关键点数量相对应;$w,h$ 分别为输出的特征图的宽和高,这与关键点生成的热图大小一致。生成热图时,依次在关键点坐标中心位置周围确定一个正方形的网格,大小为$s \times s$ ,利用二维高斯函数以关键点坐标为重心计算网格概率,填充到热力图中,遍历所有关键点即获得一个以关键点坐标为中心的热图。该热图作为网络训练的标签,每个样本图片$i$ 标签记为$ {y^{{\text{label}}}} $ ,网络输出记为$ {y^{{\text{pred}}}} $ 。在训练中采用的是均方误差:$$ {l_{{\text{MSE}}}} = \dfrac{1}{n}\sum\limits_{i = 1}^n {{{\left(y_i^{{\text{pred}}} - y_i^{{\text{label}}}\right)}^2}} $$ 预测过程中,网络的输出
$y_i^{{\text{pred}}} \in {{\rm{R}}^{l \times w \times h}}$ ,每个通道包含一张特征图,对应一个关键点的输出结果,特征图的每一个像素值对应了该位置包含关键点的概率,在大于阈值$\theta $ 的前提下,一张特征图上最大概率对应的特征图像素位置坐标为对应的关键点位置。HRnet 获取图像关键点坐标的过程,记为$ {\boldsymbol{N}} = {\text{HRnet}}({\boldsymbol{X}}) $ ,其中${\boldsymbol{X}} \in {{\rm{R}}^{3 \times p \times q}}$ 表示图像输入,其中$p$ 和$q$ 分别为图像的宽和高,输出${\boldsymbol{N}} = [{{\boldsymbol{p}}_1},{{\boldsymbol{p}}_2}, \cdots ,{{\boldsymbol{p}}_n}],{\boldsymbol{N}} \in {{\rm{R}}^{n \times 2}}$ 表示的是识别出的节点构成的节点特征矩阵,为了便于表示,本文仍旧用${{\boldsymbol{p}}_i}$ 表示对应关键点$i$ 的特征向量,$n$ 为识别出的关键点个数。1.1.2 图结构的获取
根据获取的关键点坐标,利用三角化确定关键点之间的连接关系,本文选择德洛内三角网。该结构为 1934年德洛内提出的一种具有良好性质的三角剖分结构,该三角剖分包含一系列相连的但不重叠的三角形的集合, 其中任意两个共边三角形的外接圆不包含另一三角形顶点,被称为德洛内三角网[35]。德洛内三角网具有一系列良好的性质,例如存在唯一性,且满足最大最小角性质,德洛内三角网的边都不相交,新增删除或移动某个顶点只会影响邻近三角形等,因此被广泛应用于计算机几何计算中。
考虑到德洛内三角网为沃罗诺伊 (Voronoi) 图的对偶图,因此本文在生成德洛内三角网时,采用基于Voronoi图最小邻近点集的德洛内三角化方法[35-36]获得边结构。根据获取的关键点,生成关键点集合的德洛内三角网结构,同时对应关键点排列顺序,唯一确定图的邻接矩阵
${\boldsymbol{A}}$ 。至此本文采用深度卷积网络识别类别关键点,针对待识别关键点集合
$P$ ,输出获得关键点的位置${\boldsymbol{N}}$ 。通过关键点的图像坐标生成图结构,该图结构对应节点特征矩阵${\boldsymbol{N}}$ 的邻接矩阵记为${\boldsymbol{A}}$ ,由此得到了一个具有语义含义的图像图表达$G({\boldsymbol{N}},{\boldsymbol{A}})$ ,详见图2。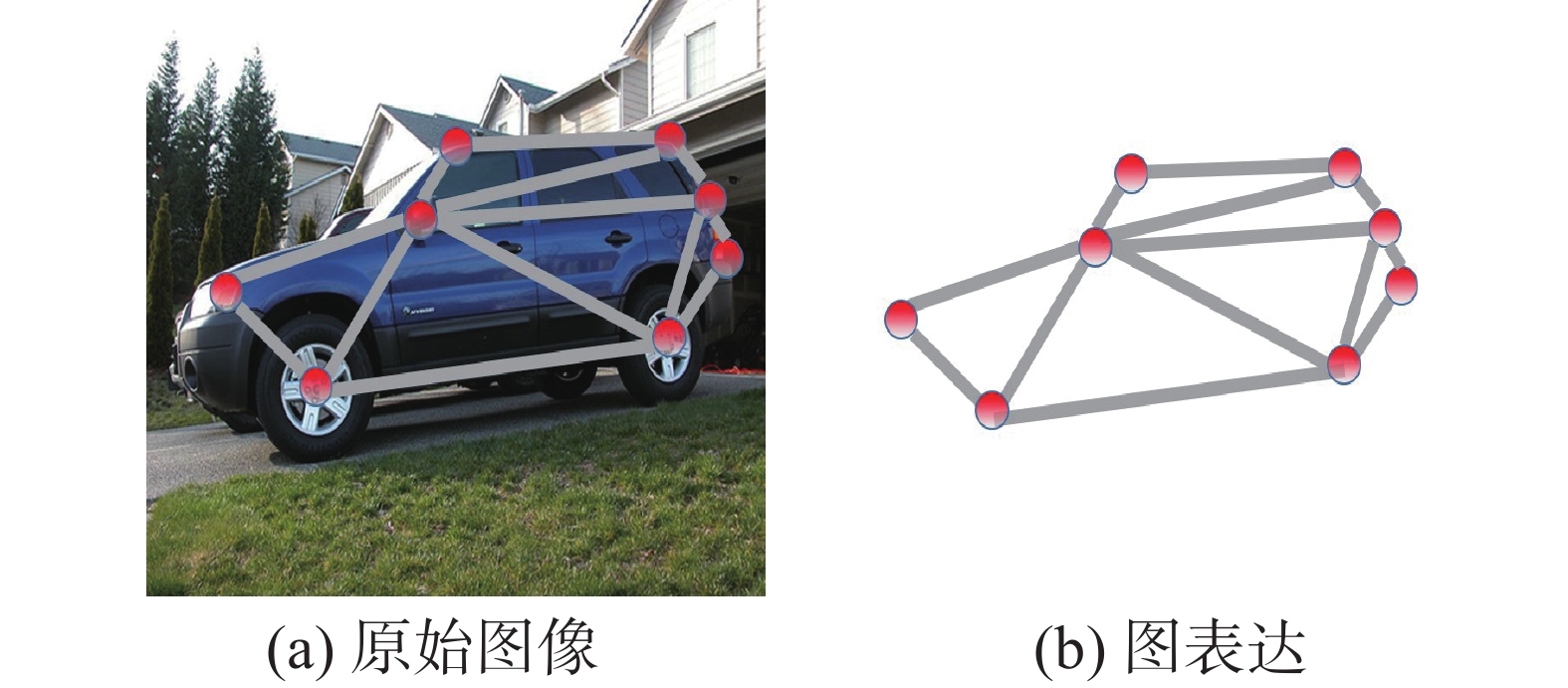 图 2 图像图表征示例Fig. 2 Graph representation example of an image下载:
全尺寸图片
图 2 图像图表征示例Fig. 2 Graph representation example of an image下载:
全尺寸图片
1.2 图对比分类
基于上一节生成的图像图表达,已经将图像分类转化为图分类问题,特别地,1.1.2节获得图表达已经剥离了原图像的纹理颜色等特征,仅包含关键点位置以及对应的拓扑图结构,实际上由图2 可以看出该图表达实际对应了图像物体的拓扑图结构。
考虑到输入图像中物体的位置、大小一般并不相同, 即使是相同的物体在不同尺度、角度下关键点位置之间的距离也会较大。因此图的分类中要考虑不同尺度、位姿差别下的拓扑图结构的一致性特征。而考虑跨图的关键点属性对应,以及图上的信息传播步骤可以自适应地调整两张图的隐变量并学习到两者基于类别形状的图距离。
图数据分析问题已经被广泛地研究,特别是图神经网络方法在多个图分类任务获得了令人瞩目的成绩。因此本文采用图神经网络方法提取类别的拓扑特征,同时考虑通过对比学习获取同类比特征,具体地,通过待分类图与对照图的对比区别类别间距离以实现图分类,本节采用对比学习常用的暹罗网络框架,如图1 的图对比分类部分所示,一共包含2个步骤:1)单张图的隐变量获取,该部分通过图网络分别获取对照图和待分类图的隐变量;2)是跨图特征提取,两张图的节点实际对应的是具有实际语义的关键点,在对照图和待分类图的节点之间存在对应关系,跨图特征提取部分在对应关系之间进行图上的信息传播,以获取表达两张图相对关系的隐变量。本文采用图对比网络计算对照图与待分类图的距离,最终实现类别判断。
1.2.1 网络输入
输入的对照图和待分类图分别记为
${G^{\text{T}}} = G({{\boldsymbol{A}}^{{\text{T}}}}, {{\boldsymbol{N}}^{{\text{T}}}})$ ,${G^{{\text{E}}}} = G({{\boldsymbol{A}}^{{\text{E}}}},{{\boldsymbol{N}}^{{\text{E}}}})$ ,其中T标记对照图信息,E标记待分类图的信息;输入的图信息仅包含图像的关键点位置和关键点生成的全局拓扑结构,不再包含图像局部特征如颜色、纹理等,实现了局部特征与全局特征的解耦。在计算中,待分类图和对照图的结构一致,采用的都是对照图结构,记为
$$ {\boldsymbol{A}} = {{\boldsymbol{A}}^{{\text{E}}}} = {{\boldsymbol{A}}^{{\text{T}}}} $$ 对照图的结构相当于类别结构先验,采用相同图结构目的是使分类图在先验图结构下获得与对照图相似的隐变量。
1.2.2 单图特征提取
图中的节点特征为关键点的图像坐标位置,节点特征会依照物体的拓扑结构移动等产生相应的变动,本文目的是通过单图的特征提取,消除物体结构在单图物体的相对移动对节点特征产生的影响。具体地,采用图卷积层提取新的图节点特征:
$$ \begin{array}{*{20}{l}} {{\boldsymbol{N'}}} = {{\text{GN}}{{\text{N}}_1}({\boldsymbol{A,N}})} ={{f_{{\text{softmax}}}}({\boldsymbol{AN}}{{\boldsymbol{W}}_1})} \end{array} $$ (1) 式中:
${\text{GN}}{{\text{N}}_1}$ 表示单图特征提取的图神经网络,${f_{{\text{softmax}}}}$ 为激活函数,${{\boldsymbol{W}}_{{1}}}$ 是待学习的参数。在单张图节点特征的提取过程中采用的是共享参数的图神经网络,两张图同时输入,各自输出单图的节点隐变量作为跨图特征提取步骤的输入。1.2.3 跨图特征提取
获知的单张图特征后,通过两张图 (
${G^{\text{T}}}$ 和${G^{\text{E}}}$ ) 对应节点关系组合而成的图神经网络层学习两图相对关系隐变量。图中的每个节点属于某类关键点,根据关键点的属性可以得到两张图节点的匹配关系,匹配关系矩阵记为${{\boldsymbol{A}}^{({\text{T}},{\text{E}})}}$ ,两张图像中识别出的关键点的数量分别为$m$ 和$n$ 。如果待分类图中的关键点$p_i^{\text{T}}$ 与对照图中关键点$p_j^{\text{E}}$ 同属一个类别,则匹配矩阵中元素$a_{ij}^{({\text{T}},{\text{E}})} = a_{ji}^{({\text{T,E}})} = 1$ ,否则值为0。通过这些匹配连接的边对照图和待分类图可以构成一张大图,这张大图的节点,记为${{\boldsymbol{N}}_{{\rm{match}}}} = [{{\boldsymbol{N}}^{\text{T}}},{{\boldsymbol{N}}^{\text{E}}}]$ ,邻接矩阵则记为$$ {{\boldsymbol{A}}_{{\text{match}}}} = \left[ {\begin{array}{*{20}{c}} {{{\boldsymbol{I}}_m}}&{ - {{\boldsymbol{A}}^{({\text{T,E}})}}} \\ { - {{\boldsymbol{A}}^{({\text{T,E}})}}}&{{{\boldsymbol{I}}_n}} \end{array}} \right] $$ 在对照图和待分类图(
${G^{\text{T}}}$ 和${G^{\text{E}}}$ )以及它们节点匹配关系构造生成的大图$G({{\boldsymbol{N}}_{{\text{match}}}},{{\boldsymbol{A}}_{{\text{match}}}})$ 上,通过图上信息传播操作更新全部节点隐变量:$$ \begin{array}{*{20}{c}} {}{{{{\boldsymbol{N'}}}_{{\text{match}}}}} = {{\text{GN}}{{\text{N}}_{{\text{match}}}}({{\boldsymbol{A}}_{{\text{match}}}},{{\boldsymbol{N}}_{{\text{match}}}})} =\\ {{f_{{\text{softmax}}}}({{\boldsymbol{A}}_{{\text{match}}}}{{\boldsymbol{N}}_{{\text{match}}}}{{\boldsymbol{W}}_2})} =\\ {\left(\left[ {\begin{array}{*{20}{c}} {{{\boldsymbol{I}}_m}}&{ - {{\boldsymbol{A}}^{{\text{(T,E)}}}}} \\ { - {{\boldsymbol{A}}^{{\text{(T,E)}}}}}&{{{\boldsymbol{I}}_n}} \end{array}} \right]\left[ {{{\boldsymbol{N}}^{\text{T}}}}\quad{{{\boldsymbol{N}}^{\text{E}}}} \right]{{\boldsymbol{W}}_2}\right)} \end{array} $$ (2) 式中:
${{\boldsymbol{W}}_{{2}}}$ 为该部分待学习参数,在聚合图上所有点的距离特征后,通过一个多层感知机(multilayer perceptron,MLP),输出两张图的预测距离,${{\boldsymbol{W}}_3}$ 为该部分参数:$$ {g^{{\text{pred}}}} = {\text{ML}}{{\text{P}}_{{{\boldsymbol{W}}_3}}}({\boldsymbol{N}}_{{\text{match}}}') $$ (3) 最后输出
${g^{{\text{pred}}}}$ 表示的是待分类图与对照图的距离,输入相同类别与不同类别的${G^{\text{T}}}$ 和${G^{\text{E}}}$ 对应不同的${g^{{\text{pred}}}}$ 。1.3 训练与预测过程
图对比方法中的网络参数与关键点识别部分的网络参数是分开训练。图对比网络的训练过程中,训练中任意选取两张图像,类别一致为正样本对标签值为1,类别不一致为负样本对标签值为−1。采用对比学习中常用的软间隔损失函数(soft margin loss)作为损失函数:
$$ {l_{}} = \sum\limits_i {\frac{{\ln (1 + {\text{exp}}( - {g_i} \times g_i^{{\text{pred}}}))}}{{|{g^{{\text{pred}}}}|}}} $$ 式中:
$g_i^{{\text{pred}}}$ 为预测值,${g_i}$ 为标签值,$|{g^{{\text{pred}}}}|$ 表示的输出向量的个数。在预测过程中,对照图为该类别训练集中的一个图表示,待分类图为测试图像由1.1节获取的图表示,根据输出的${g_i}$ 判断两张图是否来自同类别,实现图像的类别判断。2. 实验结果及分析
为了验证提出方法的有效性,本文在真实环境图片以及仿真数据中分别进行了实验。其中在真实环境图片中分别进行对比实验和消融实验,以及关键超参数的分析实验:在对比实验中,将 Key-D- Graph 与主流图像分类深度卷积神经网络对比,方法的分类性能和效率进行评估;在消融实验,去掉中间的图神经网络层,与直接利用关键点分类结果进行对比,以分析图对比网络的作用;超参数分析实验中设置了多个关键点识别阈值,以分析第一步关键点识别与图对比分类之间的关系。在仿真数据中设计了拓扑结构信息消融实验,分析拓扑图结构体现的拓扑信息在距离学习中的作用。
2.1 真实环境数据集上的实验
2.1.1 数据集
针对二分类任务,本文选择Pascal VOC2012数据集[37]中的多个类别数据作为训练数据集。该数据集是 Pascal VOC2012图像分类挑战赛的公开数据集,共包含20类物体,包含分类、检测、分割等任务标签。例如汽车与非汽车的类别分类,测试集为原测试集中的全部 153 张汽车图像,另随机挑选了153 张非汽车类别的测试集中的图像构成类别评价测试集。伯克利大学发布了Pascal VOC2012数据集中8702张图像中的20类物体关键点位置,共标注了161种关键点,其中7020张训练图像,1682张测试图像。该数据同时具有图像类别和关键点标注标签,因此本文选择在该数据集上进行训练测试。
2.1.2 实验设置
在关键点识别网络学习过程中,首先对输入图像进行预处理,依据物体所在的检测框进行随机尺度缩放然后进行中心裁切,然后将裁切后的图像统一缩放为分辨率256×256作为网络的输入。在修改尺寸的过程中,如果随机裁切后的图像分辨率小于64×64,则将图像进行尺度缩放后补齐。选取HRnetv2-18作为关键点识别网络,针对实验数据集网络识别161类关键点,输出关键点的坐标作为图对比分类中图节点特征,如果图中没有此类关键点,则该关键特征设置为(−1,−1)。该关键点的位置为训练过程采用ADAM优化器。关键点训练过程的超参数设置详见表1。
表 1 训练超参数Table 1 Parameters of training in keypoints detection参数 数值 关键点覆盖网格大小 s/像素 7 标签热图分辨率 64×64 关键点识别阈值 θ 0.01 关键点识别网络初始学习率 0.00001 图对比网络学习率衰减率 0.1 图对比网络训练批次数 300 在图对比分类网络中,共包含4层图结构,其中暹罗结构下的单图特征提取有3层单图信息交换的图卷积层和1层跨图的图卷积层。隐变量维度为20,对提取的图特征进行距离预测的MLP(详见式 (1)) 的隐含层数为1,隐层节点数与两张图的节点总数相同。训练以及测试过程的对照图都来自于已知类别的训练集,在训练过程中待分类图也来自于训练集,测试时待分类图为测试集中的样本。输入过程中通过增加随机生成的关键点进行数据增广,训练采用SGD优化器。
2.1.3 对比指标
实验对比采用分类主要指标准确率
${V_{{\text{accuracy}}}}$ 、召回率${V_{{\text{recall}}}}$ 、精确率${V_{{\text{precision}}}}$ 、$ {F_1} $ 指标${V_{{{{F}}_{\text{1}}}}}$ ,其中准确率计算方式为$$ {V_{{\text{accuracy}}}} = \frac{{N_{{\rm{TP}}} + N_{{\rm{TN}}}}}{{N_{{\rm{TP}}} + N_{{\rm{TN}}} + N_{{\rm{FP}}} + N_{{\rm{FN}}}}} $$ 式中:
$N_{{\rm{TP}}} $ 正样本中检测正确的样本数,$N_{{\rm{TN}}} $ 为负样本中检测正确的样本数,$N_{{\rm{FP}}} $ 为正样本中检测错误的样本数,$N_{{\rm{FN}}} $ 为负样本中检测错误的样本数。召回率为正样本中识别正确的样本占所有正样本的比例,计算公式为$$ {V_{{\text{recall}}}} = \frac{{N_{{\rm{TP}}}}}{{N_{{\rm{TP}}} + N_{\rm{FN}}}}$$ 精确率为预测正确的正样本占所有正确识别样本的比例,计算公式为
$$ {V_{{\text{precision}}}} = \frac{{N_{\rm{TP}}}}{{N_{\rm{TP}} + N_{\rm{FP}}}} $$ 精确率与召回率是一组相互矛盾的分类评价指标, 当召回率过高时,将导致负样本误检为正样本,分类精确率下降;F1指标是一个综合指标,可以折中评价网络的性能,计算公式为
$$ {V_{{F_1}}} = \frac{{2 \times {V_{{\text{precision}}}} \times {V_{{\text{recall}}}}}}{{{V_{{\text{precision}}}} + {V_{{\text{recall}}}}}} $$ 2.1.4 对比实验
为了验证方法的分类性能以及计算效率,在标有关键点的VOC数据集中车与其他物体分类任务上将 Key-D-Graph 方法与多个深度学习端到端的分类基准网络进行了对比。
Key-D-Graph方法的参数为所有待学习参数,包含了关键点识别和图对比分类网络的参数,其中HRnet网络参数量为9.64 MB,图对比分类网络参数量为1.04 MB。本文通过实验发现调整关键点识别的阈值,网络性能会发生变化,在对比实验中给出了关键点筛选阈值为 0.1 时以及设置为 0.01 的分类性能。对比实验中选取了ResNet和EfficientNet两个系列基准网络,其中ResNet是深度卷积神经网络领域最常用方法之一,对比试验选取了参数量较少的ResNet18和ResNet34进行对比;EfficientNet由谷歌Tan等提出,被认为是分类性能最好的分类器之一[15],可以在相同的参数量取得更好的分类效果,EfficientNet-B0是经过搜索算法获得的分类基线模型,研究人员在此基础上提出了一系列的EfficientNet,在许多数据集上表现出色,因此除EfficientNet-B0 外,本文选择了本系列中与Key-D-Graph参数量类似的 EfficientNet-B2和 EfficientNet-B3的分类结果进行对比。
实验结果详见表2,对比指标为准确率
${V_{{\text{accuracy}}}}$ 、参数量${V_{{\text{Params}}}}$ 和乘积累加运算量(multiply–accumulate operations,MACs)${V_{{\text{MACs}}}}$ ,准确率可以衡量网络分类效果,网络的参数量和MACs来对比算法的复杂度。表 2 对比实验结果Table 2 Results of contrast experiments方法 参数量/MB MACs/GB 准确率/% EfficientNet-B0 4.01 0.4 96.43 EfficientNet-B2 7.70 1.0 98.21 Resnet18 11.18 2.4 96.18 Resnet34 21.29 4.8 97.45 EfficientNet-B3 10.69 1.8 96.94 Key-D-Graph(0.1) 10.68 4.7 92.48 Key-D-Graph(0.01) 10.68 4.7 98.37 由表2可以看出,与Resnet方法相比,本文方法在相似参数量甚至更少参数量的情况下取得了分类精度的提升,阈值为0.1的 Key-D-Graph比21.53 MB参数的Resnet34提高了1.96%,阈值为0.01时Key-D-Graph 比21.53 MB参数的Resnet34提高了7.85%。同时MACs上,HRNet 为4.659 GB,而图对比分类部分仅为1.72 MB,与深度卷积获取关键点部分相比可以忽略不计。主要是因为在图对比分类中的数据采用基于关键点的图表示,与图像RGB表示相比,维度大大减少。
当阈值为0.1时,Key-D-Graph超过了EfficientNet-B0,EfficientNet-B2,仅次于EfficientNet-B3的分类结果,但是EfficientNet-B3的参数量比Key-D-Graph多1.55 MB。阈值为0.01时 Key-D-Graph则超过了EfficientNet-B3方法4.91%,与EfficientNet方法相比也能在参数量更少的情况下获得更好的分类结果。同时,针对对比实验中的关键点阈值对分类结果的影响,也设计了相关实验以分析该参数的作用.
2.1.5 消融实验
本文设计了消融实验以分析图对比分类网络部分对分类结果的影响。消融实验将本文的分类结果与擦除图分类网络直接对关键点分类的方法进行了对比,以分析图对比分类网络的分类作用. 消融实验将提取的关键点直连一个MLP网络进行分类,该MLP网络的设置与公式(3)中的设置相同,记为HRnet+MLP。HRnet+MLP与Key-D-Graph相比擦除了图对比分类网络,即图1 中的图对比分类部分全部采用MLP进行替代,该实验可以分析本文提出的图对比分类网络基于图结构的特征提取能力。两组实验的关键点阈值均为0.1。除了汽车类别外,还在行人/其他类别,牛/其他类别数据上进行了实验对比,实验结果详见表3。
表 3 多组消融实验结果Table 3 Results of ablation experiments% 方法
指标HRnet+MLP Key-D-Graph 准确率 召回率 精确率 F1 准确率 召回率 精确率 F1 汽车 89.14 86.45 92.41 89.33 92.48 87.74 97.14 92.20 行人 83.65 74.68 91.47 82.23 84.62 73.42 95.08 82.86 牛 87.04 92.59 83.33 87.72 83.96 92.59 84.74 88.50 该消融实验包含了3个分类任务上的对比实验,分别对比了准确率、召回率、精确率以及F1值。如表3 所示,增加图对比神经网络部分后,3个分类实验的识别准确率、精确率以及F1指标在均有提升,该结果验证了图对比学习网络提取分类特征的有效性,也体现结构特征对分类任务的价值。
2.1.6 超参数分析实验
超参数分析实验主要是针对关键点识别阈值这一关键超参数进行对比,在汽车/非汽车训练及测试集上进行了多次实验,以分析该超参数对实验结果的影响。实验中,在多个阈值的关键点数据上比较图对比分类网络效果,结果详见表4。从表4 可以看出当阈值减少时,方法的分类性能有所增加。当阈值减少时,图像中会识别出更多的关键点,无论是正确还是错误的关键点都为图分类网络提供更多了关键点以及结构信息。误检的关键点位置并不能与对照图关键点之间的相对关系保持一致,增加了与对照图之间的距离,从而提高了分类性能。
表 4 超参数分析实验结果Table 4 Results of hyperparameter analysis experiments% 阈值 准确率 召回率 精确率 F1 0.1 92.48 87.74 97.14 92.20 0.05 96.08 93.55 98.63 96.03 0.01 98.37 98.06 98.70 98.38 2.2 仿真数据集上的拓扑结构消融实验
除真实环境图像上的分类任务实验外本文仿真数据集上设计了分析测试实验,以分析Key- D-Graph 图对比网络中拓扑结构信息度量物体位姿距离的能力,通过该消融实验的实验结果对比,可通过分析包含拓扑结构和擦除拓扑结构对位姿距离估计的影响,以解析图对比网络中的拓扑结构信息在分类中的作用。
仿真数据集为由一个3D骨骼数据生成的2D图像数据集,不同的位姿下可以生成不同角度的2D图像,生成图片如图3所示,图中展示了生成的两种图像,一种是3D模型视角图像,另一种是由3D模型投影生成的图像,两种图片关键点绝对位置不同,以仿真不同模态的2D图像。本测试目的是输入单张图像可以估计当前骨骼的位姿,即在已知的3D位姿的多张2D图片中确定最相近的2D图像,该2D图像的对应位姿即为估计的3D位姿。
 图 3 仿真数据集中的 2D 图片Fig. 3 2D images in the simulation dataset下载:
全尺寸图片
图 3 仿真数据集中的 2D 图片Fig. 3 2D images in the simulation dataset下载:
全尺寸图片
数据集将80对2D图像作为训练集,3组位姿估计作为测试集。该消融实验将Key-D-Graph和Key-D-MLP进行对比,Key-D-MLP即为擦除了关键点的拓扑图结构,即图神经网络中基于结构信息传播步骤采用MLP 替代,相当于输入无结构的关键点向量,与Key-D-Graph的不同在于没有图结构以及跨图结构的信息传播,即式(1)及式(2)中的GNN层均替换为MLP, 与3.3节图对比网络消融实验中的HRnet+MLP相比,保留了暹罗对比学习框架。Key-D-Graph和Key-D-MLP仍通过对比学习不同2D图像之间的位姿差异,监督损失采用的是仿真图像已知对应的3D模型位姿距离,具体的采用L2范数作为要估计的3D位姿距离。在训练过程中,通过对比两张图中对应节点之间的相对位置关系,获得两张图的位姿差异,这种差异相当于图与图之间的位姿距离。
如表5及图4实验结果所示,与擦除掉结构信息的 Key-D-MLP方法相比,具有拓扑结构的 Key- D-Graph可以在测试集的3组图像中估计的最小距离均为最佳的位姿匹配图像,说明Key-D-Graph对图像间的3D位姿距离估计的更为准确,该方法与Key-D-MLP相比更能有效学习不同图像位姿之间的距离。两个对比方法的差别则在于一个包含先验图结构,另一个擦除了先验图结构,实验结果的不同说明了Key-D-Graph 方法引入的对照图拓扑结构先验能够帮助网络更好地在图像平移变化中获取结构不变量,可以有效提取物体的结构特征。
表 5 拓扑结构信息消融实验结果Table 5 Results of topological information ablation experiments方法 实验结果 Key-D-Graph 3组均成功获取最佳匹配 Key-D-MLP 成功匹配1组 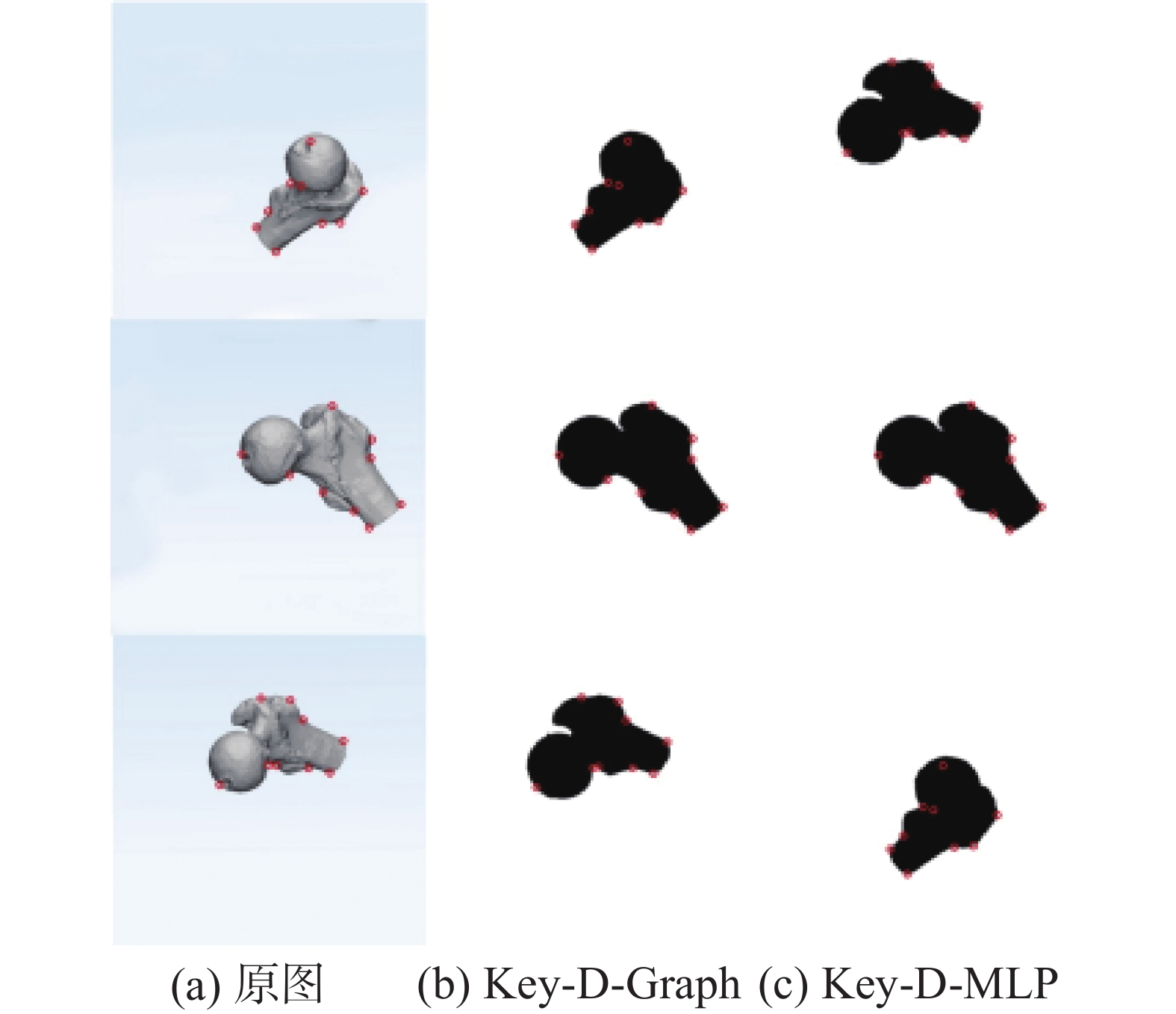 图 4 最佳结果对Fig. 4 Best image pairs in the results下载:
全尺寸图片
图 4 最佳结果对Fig. 4 Best image pairs in the results下载:
全尺寸图片
3. 分析讨论
通过以上实验结果说明,本文提出的 Key-D- MLP 分类精度以及计算效率均超过了现有的主流方法且具有如下特点:
1) Key-D-Graph 是中间结果,可解释的两阶段方法。方法的第一阶段输出目标类别关键点,可视化结果见图5,关键点具有明确语义信息且依据超参数分析实验结果,该阈值与网络识别关键点结果以及识别网络训练相关,该阈值为关键点识别的输出概率,说明可根据阈值调整识别出的关键点数量,从而影响最终的分类结果。而端到端的深度学习方法一般被认为是黑箱结构,难以对网络中间层结果明确地进行语义解释,且难以利用中间输出结果对方法进行有针对性地调整。因此本文提出的Key-D-Graph方法依据中间输出的具有可解释性的语义信息且可以对结果进行调控,与端到端的深度学习方法相比更适用于需要部分中间结果分析的应用场景。
 图 5 汽车关键点识别可视化Fig. 5 Detected keypoints visualization of the cars下载:
全尺寸图片
图 5 汽车关键点识别可视化Fig. 5 Detected keypoints visualization of the cars下载:
全尺寸图片
但是如何确定最优阈值仍是一个困难的问题。阈值为关键点识别的输出概率,每个阈值可得到一个图分类数据集,而且最优阈值随不同数据集上关键点识别网络的输出范围和图分类网络的训练结果变化。事实上,关键点网络的输出与训练的过程有关,输出结果会因训练不同,导致网络可能在识别相同关键点时对应不同的阈值。因此寻找最优阈值需要在不同数据集和大量关键点识别网络上进行大量训练以归纳总结最优阈值的范围。
2)由对比实验结果可以看出,两阶段的网络将局部信息与全局信息识别进行了解耦操作,与现有的基准模型相比更加简洁、有效。在局部识别过程中,即第一步的关键点的识别过程中,任务所需的感受野小,相比图像分类难度大大降低,同时关键点识别步骤去除了原图像中与分类无关的大量冗余信息,关键点与原图像相比维度大大降低,也为图表达分类降低了难度,因此在对比实验中可以实现在降低计算复杂度的同时提升分类效率。
3) Key-D-Graph 将图像识别解耦为局部信息与全局信息识别过程,这个步骤充分利用了类别先验信息,同时验证了图表达拓扑结构的有效性。首先,通过对类别的认知定义了图像的关键点集合,这部分一是考虑类别特异性,二是在实际应用中,可以依据识别环境对关键点进行选择。其次,在图对比分类步骤中将已知样本结构作为先验知识引入测试样本中,建立了基于全局图像图表达,采用图对比网络实现了全局特征的利用,该步骤基于暹罗结构的图对比方法实现了基于先验图结构的推理。依据拓扑结构消融实验的结果,可以看出先验图拓扑结构在距离学习任务的有效性。已有的深度卷积网络方法完全是通过大量的样本学习提取特征,缺乏先验语义结构的利用,而拓扑结构消融实验说明 Key-D-Graph 引入的对照图结构可以更好地提取图像结构特征,从而弥补了类别先验语义结构利用的不足。
4. 结束语
本文提出了一种图像分类方法 Key-D-Graph, 通过深度卷积网络获得图像关键点,然后建立基于关键点的图像图表达,结合先验图结构信息利用图对比学习网络实现图像分类。该方法分阶段实现了图像局部特征和全局结构特征识别,在应用中可依据中间输出的关键点结果调试分类结果。对比实验结果表明该方法与已有的深度学习相比,在效率和性能上均有提升,同时验证了图拓扑结构信息在分类任务中的重要作用,弥补了现有主流深度学习方法在图像类别先验结构利用上的不足。
消融实验结果说明拓扑图结构在3D位姿距离估计中的有效性,因此未来将考虑将不同类别图像的差异转化为不同角度投影图的距离学习,以实现多类别图像分类。确定最优阈值可以更清晰揭示阈值对结果的影响机制,也是未来待研究的工作之一。
-
图 1 Key-D-Graph 方法流程
Fig. 1 Flow of the Key-D-Graph
下载:
全尺寸图片
图 2 图像图表征示例
Fig. 2 Graph representation example of an image
下载:
全尺寸图片
图 3 仿真数据集中的 2D 图片
Fig. 3 2D images in the simulation dataset
下载:
全尺寸图片
图 4 最佳结果对
Fig. 4 Best image pairs in the results
下载:
全尺寸图片
图 5 汽车关键点识别可视化
Fig. 5 Detected keypoints visualization of the cars
下载:
全尺寸图片
表 1 训练超参数
Table 1 Parameters of training in keypoints detection
参数 数值 关键点覆盖网格大小 s/像素 7 标签热图分辨率 64×64 关键点识别阈值 θ 0.01 关键点识别网络初始学习率 0.00001 图对比网络学习率衰减率 0.1 图对比网络训练批次数 300 表 2 对比实验结果
Table 2 Results of contrast experiments
方法 参数量/MB MACs/GB 准确率/% EfficientNet-B0 4.01 0.4 96.43 EfficientNet-B2 7.70 1.0 98.21 Resnet18 11.18 2.4 96.18 Resnet34 21.29 4.8 97.45 EfficientNet-B3 10.69 1.8 96.94 Key-D-Graph(0.1) 10.68 4.7 92.48 Key-D-Graph(0.01) 10.68 4.7 98.37 表 3 多组消融实验结果
Table 3 Results of ablation experiments
% 方法
指标HRnet+MLP Key-D-Graph 准确率 召回率 精确率 F1 准确率 召回率 精确率 F1 汽车 89.14 86.45 92.41 89.33 92.48 87.74 97.14 92.20 行人 83.65 74.68 91.47 82.23 84.62 73.42 95.08 82.86 牛 87.04 92.59 83.33 87.72 83.96 92.59 84.74 88.50 表 4 超参数分析实验结果
Table 4 Results of hyperparameter analysis experiments
% 阈值 准确率 召回率 精确率 F1 0.1 92.48 87.74 97.14 92.20 0.05 96.08 93.55 98.63 96.03 0.01 98.37 98.06 98.70 98.38 表 5 拓扑结构信息消融实验结果
Table 5 Results of topological information ablation experiments
方法 实验结果 Key-D-Graph 3组均成功获取最佳匹配 Key-D-MLP 成功匹配1组 -
[1] 黄凯奇, 任伟强, 谭铁牛. 图像物体分类与检测算法综述[J]. 计算机学报, 2014, 37(6): 1225–1240. HUANG Kaiqi, REN Weiqiang, TAN Tieniu. A review on image object classification and detection[J]. Chinese journal of computers, 2014, 37(6): 1225–1240. [2] 王亮申, 欧宗瑛, 朱玉才, 等. 基于SVM的图像分类[J]. 计算机应用与软件, 2005, 22(5): 98–99,126. doi: 10.3969/j.issn.1000-386X.2005.05.036 WANG Liangshen, OU Zongying, ZHU Yucai, et al. Classifying images with SVM method[J]. Computer applications and software, 2005, 22(5): 98–99,126. doi: 10.3969/j.issn.1000-386X.2005.05.036 [3] 任越美, 张艳宁, 李映. 压缩感知及其图像处理应用研究进展与展望[J]. 自动化学报, 2014, 40(8): 1563–1574. REN Yuemei, ZHANG Yanning, LI Ying. LI Ying. Advances and perspective on compressed sensing an application on image processing[J]. Acta automaica sinica, 2014, 40(8): 1563–1574. [4] 马忠丽, 刘权勇, 武凌羽, 等. 一种基于联合表示的图像分类方法[J]. 智能系统学报, 2018, 13(2): 220–226. doi: 10.11992/tis.201611036 MA Zhongli, LIU Quanyong, WU Lingyu, et al. Syncretic representation method for image classification[J]. CAAI transactions on intelligent systems, 2018, 13(2): 220–226. doi: 10.11992/tis.201611036 [5] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the acm, 2012, 60: 84–90. [6] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2014−09−04)[ 2021−12−01].https://arxiv.org/abs/1409.1556. [7] SZEGEDY C, LIU Wei, JIA Yangqing, et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1−9. [8] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770−778. [9] HUANG Gao, LIU Zhuang, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2261−2269. [10] BALDASSARRE F, MORÍN D G, RODÉS-GUIRAO L. Deep koalarization: image colorization using CNNs and inception-ResNet-v2[EB/OL]. (2017−12−09) [ 2021−12−01].https://arxiv.org/abs/1712.03400. [11] CHEN Yaran, LI Haoran, GAO Ruiyuan, et al. Boost 3-D object detection via point clouds segmentation and fused 3-D GIoU-L1 loss[J]. IEEE transactions on neural networks and learning systems, 2022, 33(2): 762–773. doi: 10.1109/TNNLS.2020.3028964 [12] CHEN Y, GAO R, LIU F, et al. ModuleNet: knowledge-inherited neural architecture search[J]. IEEE transactions on cybernetics, 2022, 52(11): 11661–11671. doi: 10.1109/TCYB.2021.3078573 [13] DING Zixiang, CHEN Yaran, LI Nannan, et al. BNAS: efficient neural architecture search using broad scalable architecture[J]. IEEE transactions on neural networks and learning systems, 2022, 33(9): 5004–5018. doi: 10.1109/TNNLS.2021.3067028 [14] LI Nannan, PAN Yu, CHEN Yaran, et al. Heuristic rank selection with progressively searching tensor ring network[J]. Complex & intelligent systems, 2022, 8(2): 771–785. [15] TAN Mingxing, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks[EB/OL]. (2019−05−28)[2021−12−01].https://arxiv.org/abs/1905.11946. [16] ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks[C]//European Conference on Computer Vision. Cham: Springer, 2014: 818−833. [17] GEIRHOS R, RUBISCH P, MICHAELIS C, et al. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness[EB/OL]. (2018−11−29)[2021−12−01].https://arxiv.org/abs/1811.12231. [18] LOWE D G. Object recognition from local scale-invariant features[C]//Proceedings of the Seventh IEEE International Conference on Computer Vision. Kerkyra: IEEE, 1999: 1150−1157. [19] WEI Shihen, RAMAKRISHNA V, KANADE T, et al. Convolutional pose machines[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 4724−4732. [20] WANG Jingdong, SUN Ke, CHENG Tianheng, et al. Deep high-resolution representation learning for visual recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2021, 43(10): 3349–3364. doi: 10.1109/TPAMI.2020.2983686 [21] LU Yi, CHEN Yaran, ZHAO Dongbin, et al. CNN-G: convolutional neural network combined with graph for image segmentation with theoretical analysis[J]. IEEE transactions on cognitive and developmental systems, 2021, 13(3): 631–644. doi: 10.1109/TCDS.2020.2998497 [22] LU Yi, CHEN Yaran, ZHAO Dongbin, et al. Graph-FCN for image semantic segmentation[C]//International Symposium on Neural Networks. Cham: Springer, 2019: 97−105. [23] 张勇, 高大林, 巩敦卫, 等. 用于关系抽取的注意力图长短时记忆神经网络[J]. 智能系统学报, 2021, 16(3): 518–527. doi: 10.11992/tis.202008036 ZHANG Yong, GAO Dalin, GONG Dunwei, et al. Attention graph long short-term memory neural network for relation extraction[J]. CAAI transactions on intelligent systems, 2021, 16(3): 518–527. doi: 10.11992/tis.202008036 [24] XU K, HU Weihua, LESKOVEC J, et al. How powerful are graph neural networks? [EB/OL]. (2018−10−01)[2021−12−01].https://arxiv.org/abs/1810.00826. [25] CHOPRA S, HADSELL R, LECUN Y. Learning a similarity metric discriminatively, with application to face verification[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego: IEEE, 2005: 539−546. [26] SOHN K. Improved deep metric learning with multi-class N-pair loss objective[C]//NIPS’16: Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: ACM, 2016: 1857−1865. [27] TAIGMAN Y, YANG Ming, RANZATO M, et al. DeepFace: closing the gap to human-level performance in face verification[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 1701−1708. [28] CARON M, MISRA I, MAIRAL J, et al. Unsupervised learning of visual features by contrasting cluster assignments[EB/OL]. (2020−06−17)[2021−12−01].https://arxiv.org/abs/2006.09882. [29] OORD A V D, LI YAZHE, VINYALS O. Representation learning with contrastive predictive coding[EB/OL]. (2018−07−10)[2021−12−01].https://arxiv.org/abs/1807.03748. [30] CHEN Ting, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[EB/OL]. (2020−02−13)[2021−12−01].https://www.semanticscholar.org/paper/A-Simple-Framework-for-Contrastive-Learning-of-Chen-Kornblith/34733eaf66007516347a40ad5d9bbe1cc9dacb6b. [31] HE Kaiming, FAN Haoqi, WU Yuxin, et al. Momentum contrast for unsupervised visual representation learning[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 9726−9735. [32] CHEN Xinlei, HE Kaiming. Exploring simple Siamese representation learning[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 15745−15753. [33] ZHU Yanqiao, XU Yichen, YU Feng, et al. Graph contrastive learning with adaptive augmentation[C]//WWW ’21: Proceedings of the Web Conference 2021. New York: ACM, 2021: 2069−2080. [34] WANG Runzhong, YAN Junchi, YANG Xiaokang. Learning combinatorial embedding networks for deep graph matching[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 3056−3065. [35] 张俊, 田慧敏. 一种基于边指针搜索及区域划分的三角剖分算法[J]. 自动化学报, 2021, 47(1): 100–107. doi: 10.16383/j.aas.c190155 ZHANG Jun, TIAN Huimin. A triangulation algorithm based on edge-pointer search and region-division[J]. Acta automatica sinica, 2021, 47(1): 100–107. doi: 10.16383/j.aas.c190155 [36] GUIBAS L J, KNUTH D E, SHARIR M. Randomized incremental construction of delaunay and Voronoi diagrams[M]//Automata, Languages and Programming. Berlin/Heidelberg: Springer-Verlag, 2005: 414−431. [37] EVERINGHAM M, ESLAMI S, GOOL L, et al. The pascal visual object classes challenge: a retrospective[J]. International journal of computer vision, 2014, 111: 98–136.













































































