Review of hazy image sharpening methods
-
摘要: 雾霾图像不仅影响视觉效果,而且模糊不清晰的图像容易为后续识别、理解等高层次任务带来困难。雾霾图像清晰化问题是一个典型的不适定问题,其成像过程难以精确建模,消除图像中的雾霾面临巨大的挑战。近年来,研究者提出大量的图像去雾算法克服雾霾引起的图像降质退化,为全面认识和理解图像清晰化算法,论文对其进行梳理和综述。首先,对雾霾图像清晰化算法进行整理,根据雾霾退化过程是否有模型支持,将清晰化算法分为基于Retinex模型、大气散射模型去雾算法和无模型图像去雾算法。大气散射模型是有模型算法中主流模型,本文详细剖析了模型成像机理,并根据其成像机制揭示大气散射模型容易受大气浓度均匀分布假设的限制,较难处理非均匀雾霾图像问题。基于深度学习的无模型图像去雾算法则不仅可以应对非均匀雾霾图像,而且去雾性能获得了极大地提升。其次,本文汇总了近年来常用去雾数据集,从数据集适应范围、规模、可扩展性等多个维度进行总结。并根据雾霾图像形成方式,对人工合成雾霾数据集和真实拍摄数据集分别从定性和定量的角度探讨了数据集对图像去雾算法的影响。Abstract: Hazy images not only induce visual effects but also easily introduce difficulties to subsequent high-level tasks, such as image recognition and understanding. Image dehazing is a typical ill-posed problem, and accurately modeling the imaging process is difficult. Therefore, eliminating the haze in the image faces enormous challenges. Researchers have proposed numerous methods to overcome the hazy image degradation caused by haze. First, this paper summarizes the image dehazing methods to understand and organize them. Whether the haze degradation process is supported by the model, the clarity algorithm is generally divided into a Retinex-based model, atmospheric scattering model defogging algorithm, and model-free image dehazing algorithm. The atmospheric scattering model is the typical model-based dehazing. The imaging mechanism of the model is comprehensively analyzed. However, addressing the non-uniform hazy image problem is difficult because the atmospheric scattering model is easily restricted to an assumption that the atmospheric concentration is distributed uniformly. The deep learning-based model-free dehazing algorithm not only deals with the non-uniform hazy image but also gains a considerable improvement in dehazing performance. Second, this paper summarizes the commonly used image dehazing data sets in recent years and compares the data sets from multiple dimensions, such as the scope of application, scale, and expandability. Moreover, the influence of a synthetic hazy data set and the data set of images shot in reality on the image dehazing algorithm is qualitatively and quantitatively discussed in accordance with the formation mode of hazy images.
-
随着人工智能技术的发展,机器视觉、计算机视觉技术在科研领域、人们日常生活都得到越来越广泛的应用,如无人驾驶[1]、安防监控[2]、行为识别[3]、目标检测[4]及跟踪[5]。计算机视觉技术通常需要以清晰的图像作为基础,模糊不清的低质图像会导致检测效果下降,甚至失败。然而,近年来,雾霾天气频发,导致由成像设备获取的图像出现模糊不清、对比度降低现象。采集的雾霾图像一方面直接影响人类视觉观察,另一方面也严重影响人工智能领域中以图像为核心处理对象的计算机视觉的发展。所以,去除雾霾对图像的影响,提高图像的清晰度受到越来越多的关注。
我们将具有代表性的去雾算法进行归类总结,分为两类:基于模型的图像去雾算法和无模型图像去雾算法。基于模型的图像去雾算法考虑雾霾图像退化机理,对图像成像时大气状况进行分析,根据图像物理退化过程的信息构建降质图像成像模型。其中两个非常有代表性的模型是Retinex模型[6]和大气散射模型[7-9]。Retinex模型依据人类视觉认知功能,认为到达眼睛的可见光信息取决于物体反射信息和环境中光照信息的乘积。其中,反射信息分量反映图像场景本质信息,光照信息反映外界环境信息,两者之间相关性较小。
Narasimhan等[7]通过分析雾霾降质图像的形成机制,将引起图像退化的大气介质散射因素和吸收因素引入成像模型,提出大气散射模型。之后,研究者在该模型基础上提出众多去雾算法也验证了模型的拟合能力。大气散射模型是目前应用最为广泛的图像去雾模型,本文详细剖析了该模型拟合雾霾降质图像形成过程,并根据模型形成机理对其局限性进行分析。基于模型的去雾算法是在多个未知变量基础上,由雾霾图像重建清晰图像,是典型不适定问题。针对不适定问题,常用的算法是通过提取先验信息对模型加以限制,转换为适定问题[10]。
无模型图像去雾算法主要包括基于图像增强技术的去雾算法和基于深度学习的图像去雾算法。图像增强技术是一种广谱类提升图像视觉效果的算法,不对图像降质过程成因进行分析。主要是通过提升图像对比度,增加图像间目标特征差异,达到改善图像质量,获得清晰图像的目的。如直方图均衡化[11-12]、同态滤波[13]等图像增强算法都可应用于图像去雾。
深度学习的出现和发展是人工智能领域的一件里程碑事件,它意味着人工智能开始拥有某种程度上“人类”的思考能力。深度学习强大的非线性映射能力也被应用于图像去雾。采用深度神经网络构建雾霾图像到清晰图像的映射,是典型的无模型图像去雾算法。该类算法无需考虑雾霾图像降质原因和成像过程,网络输入雾霾图像,经过学习后,输出即为清晰图像。
基于深度学习的图像去雾算法需要数据集支持。由于收集或创建具有真实清晰标注图像及其雾霾样本对环境、设备要求极高,面临着巨大挑战。所以,大规模真实基准数据库一直处于缺失状态。目前图像去雾算法的训练集主要是以人工合成数据集以及规模较小的真实雾霾数据集为主。如RESIDE[14]、HazeRD[15]、NYU2 Depth[16]、D-HAZ[17]和Dehazenet[18]等数据集,是通过大气散射模型将清晰图像合成为雾霾图像。这种估计机制合成的数据集非常适合处理均匀雾霾图像,与真实环境中采集到的雾霾图像差距较大。真实环境中,雾霾对图像造成的影响非常复杂,产生区域随机分布,且常常出现浓度不均匀,此时,采用人工合成雾霾图像数据集代替真实雾霾图像数据集并不合理。
近年来,随着人工智能技术的发展和落地需求,对真实环境雾霾图像清晰化研究引起了众多关注,并开始探索真实环境底层图像成像质量对高层视觉识别的影响。2019年CVPR组织者提出了主题为“Bridging the Gap between Computational Photography and Visual Recognition”的大赛。本次比赛与以往最大区别是给定图像数据集不再是清晰图像,而是真实环境拍摄的低质图像,如雾霾严重天气、光照度低等成像环境恶劣拍摄的图像。期望通过先进的算法提高真实、低质图像的高级语义信息提取和理解。真实场景雾霾图像的处理算法也被提出,同时小规模真实非均匀数据集的制作开始出现,如I-HAZE数据集[19]、O-HAZE数据集[20]以及NH-HAZE数据集[21]等。
1. 有模型图像去雾算法
基于模型的图像去雾算法主要通过分析图像退化因素,构建能够模拟这一过程的数学模型。目前应用去雾领域的2个常见模型是Retinex去雾模型和大气散射模型。
1.1 基于Retinex模型去雾算法
Retinex算法[6]依据人类视觉系统认知功能,认为到达眼睛的可见光信息
$I(x,y)$ 取决于物体的反射信息$R(x,y)$ 和环境中光照信息$B(x,y)$ 的乘积。由此理论构建的场景成像模型可表示为$$ I(x,y) = R(x,y) \cdot B(x,y) $$ (1) Retinex算法应用于图像去雾的核心思想是消除环境光照信息分量对场景的干扰,重构场景本质信息
$R(x,y)$ 部分。在光照信息$B(x,y)$ 未知情况下,由观测图像$I(x,y)$ 中获取$R(x,y)$ 是个病态问题,不存在唯一确定解。通过增加一定约束条件,估计出光照信息,进而得到场景本质图像。单尺度Retinex算法[6]和多尺度Retinex图像去雾算法[22]是Retinex模型中两类核心算法,算法通过假设环境光照信息可表示为图像与中心环绕函数
$ F(x, y) $ 的卷积运算,并通过估计环境光照信息作为先验反演清晰图像。Retinex算法具有大动态范围压缩、颜色恒常性等优点,算法提出后,各种Retinex衍生模型相继提出,使得其理论不断得到丰富和发展[23]。如基于路径Retinex算法[24]、PDE(partial differential equations)模型[25]、变分模型[26]等。1.2 基于大气散射模型去雾算法
目前,大气散射模型是描述雾霾图像成像过程的一个主要模型之一。大气散射模型由于深入分析雾霾成像时大气的状况,将图像退化机理融入成像模型,所以可以成功拟合雾霾图像成像过程。
1.2.1 大气散射模型形成机制
大气介质中悬浮颗粒的类型、大小和浓度决定了雾霾天气的状况。当光能量在大气中传播时,受雾霾介质的影响其能量会出现衰减。入射光线由观察场景到成像设备光能量的衰减过程可分为两部分:大气介质对光能量的吸收部分和散射部分。
Lambert-Beer[27]定律是光能量被吸收的基本定律,表示大气介质对光能量吸收的强弱与大气介质浓度和厚度间的关系,具体可表示为
$$ \frac{{{I_a}(x)}}{{{I_{{\rm{in}}}}(x)}} = t(x) = {{\rm{e}}^{ - Kd(x)c(x)}} $$ (2) 式中:
${I_{{\rm{in}}}}(x)$ 为入射光的强度;$ {I_a}(x) $ 为出射光的强度;$x = (m,n)$ 为图像中像素的坐标位置。$t(x)$ 为光线传播路径中大气介质透射率,主要受$d(x)$ 和$c(x)$ 两个变量的影响,其中$d(x)$ 表示入射光到成像设备的景深,$c(x)$ 为传输路径中大气介质浓度分布,$ K $ 是消光系数。散射部分指的是大气介质中的悬浮颗粒能够像光源一样散射环境中的光能量。如太阳光、散布的天空光和环境光等。从场景目标到图像采集设备,大气光散射能量可以表示为[7]
$$ {I_s}(x) = I(\infty )(1 - t(x)) $$ (3) 其中
$I(\infty )$ 表示无穷远处全局大气光值。综合考虑上述两部分组成因素,所形成的模型即为大气散射模型,具体形式如下:
$$ \begin{gathered} I(x) = {I_a}(x) + {I_s}(x) = {I_{{\rm{in}}}}(x)t(x) + I(\infty )(1 - t(x)) \end{gathered} $$ (4) 式中:
$ I(x) $ 为传感器获取的光信息,即采集到的有雾图像。$ {I_a}(x) $ 为衰减模块,用于描述入射光经过大气介质后的衰减信息。$ {I_s}(x) $ 为散射模块,表示大气光作为光源经过介质散射到达成像设备的图像信息。${I_{{\rm{in}}}}(x)$ 为被拍摄场景发出的光信息,即无雾图像,$I(\infty )$ 为全局大气光值,$t(x)$ 为透射率。若想从雾霾图像$ I(x) $ 中复原出清晰场景信息${I_{{\rm{in}}}}(x)$ ,需要先估算出$I(\infty )$ 和$t(x)$ 。1.2.2 大气散射模型的局限性
为了易于实现,Lambert-Beer定律对式(4)做了部分假设性限制:
1)大气介质颗粒均匀一致;
2)在光线传播路径上,大气介质浓度分布均匀一致。
在上述假设条件下,Lambert-Beer定律在应用于雾霾图像成像过程描述时可实现性较强。式(4)可重写为
$$ \frac{{{I_a}(x)}}{{{I_{{\rm{in}}}}(x)}} = t(x) = {{\rm{e}}^{ - \beta d(x)}} $$ (5) 在大气介质浓度分布相对均匀条件下,
$c(x)$ 被视为常数$C$ 处理。式中$\beta = K \cdot C$ 为与大气介质浓度相关的大气消光系数。式(5)是大气散射模型中透射率估计的核心算法,同时也是用于人工合成雾霾图像的依据。但是由式(5)获得的透射率或者是合成图像都适合描述大气介质分布均匀的雾霾图像,当真实环境与上述假设相差较大时,以式(5)为基础构建的模型将会与实际成像模型有较大的偏差。1.2.3 基于大气散射模型图像去雾算法
大气散射模型去雾算法的关键是模型中参数的估计,目前常用的算法有2种:基于先验信息的估计算法和基于深度学习的参数估计算法。
1)基于先验信息模型参数估计算法。
大气散射模型中,传感器获取的雾霾图像
$ I(x) $ 是已知量,而场景清晰图像${I_{{\rm{in}}}}(x)$ 、透射率$t(x)$ 、全局大气光值$I(\infty )$ 兼为未知参数。所以,大气散射模型是一个严重的不适定问题。解决不适定性的有效途径之一是在图像处理中引入降质图像的先验信息对不适定模型加以限制,转换为适定问题进行求解。目前,提取的先验信息或约束条件一般来自于雾霾图像的统计特性。a) 暗通道先验图像去雾算法
2009年He等[28]提出基于暗通道先验(dark channel prior, DCP)的图像去雾算法,暗通道先验是基于户外无雾图像的统计信息。论文提出在一些非天空图像区域中,至少在RGB之中一个颜色通道存在一些强度值非常低的像素。在雾霾图像中,这些像素的强度值主要由大气光贡献。因此,这些暗像素可以直接提供雾霾图像透射率估计。结合大气散射模型和软抠图插值算法,可以恢复一个高质量的无雾图像。
针对暗通道去雾算法在亮区域去雾效果不好,容易产生色彩失真的问题,文献[29]对图像亮暗区域进行自适应分割,分别提取暗通道值,然后根据亮区域的分布情况,自适应调整大气光值和去雾系数。文献[30]则采用多尺度窗口进行暗通道值计算,并利用原暗通道图像与引导滤波增强后的暗通道图像纹理差对亮区域透射率进行自适应修正。文献[31]针对暗通道在高亮区域透射率估计不足以及在边缘附近容易出现光晕现象提出通过修正补偿获取全局透射率算法,并采用亮度熵信息估算雾分布情况。
b) 颜色衰减先验图像去雾算法
2015年Zhu等[32]提出了基于颜色衰减先验(color attenuation prior, CAP)的图像去雾算法。该算法提取与暗通道先验相似的统计特征来辅助估计大气散射模型参数。作者通过大量观察发现雾霾会同时导致图像饱和度降低和亮度增加,全局上表现为颜色的衰减。根据颜色衰减先验,亮度和饱和度的差值被应用于估计雾霾的浓度,由此论文创建一个和有雾图像场景深度相关的线性回归模型,利用监督学习算法学习模型参数,恢复图像深度信息,再利用复原的深度信息完成图像去雾。
上述基于先验信息的去雾算法都会对图像进行深度剖析,通过不同的途径提取雾霾图像潜在的相关特征,应用于对大气散射模型限制,使病态模型易于求解。参数估计算法非常依赖先验信息的选择,当假设的先验不足以合理描述雾霾图像时,则可能会导致透射率估计不准确,算法失效。如文献[28]所提的暗通道先验算法无法解决图像中明亮区域。另外,目前多数基于先验信息的大气散射模型去雾算法几乎都是基于雾霾颗粒、浓度分布均匀的假设,即透射率函数
$t(x)$ 中的散射系数$\beta $ 被设置为常数。而在非均匀大气条件中$\beta $ 被视为常数并不合理,基于大气散射模型的去雾算法在某些情况下容易错误估计透射率函数。因此需要一种更灵活的模型。2)基于深度学习模型参数估计算法。
近年来,深度学习由于其强大的非线性映射能力和优秀的学习能力在计算机视觉领域受到广泛关注,一些学者将深度学习应用到图像复原和重建领域[33-36],并取得了良好的效果。基于深度学习的图像去雾算法以大量的训练数据作为支撑,由雾霾图像重构清晰图像。由2.1节可知,大气散射模型可以建模雾霾图像成像过程,为了由模型反演清晰图像,需要利用各种先验假设对大气散射模型加以限制,如暗通道先验、色调差异先验和颜色衰减先验等。该类算法在去雾方面取得了显著进展,但由于先验信息的使用范围具有一定的局限性,且先验信息选择的合理性和主观性也将较大程度影响模型参数的估算及最终的去雾效果。而深度神经网络不需要人工设置各种先验信息,直接在数据驱动下,可以构建雾霾图像到模型参数的映射。
a) 基于卷积神经网络去雾算法
2016年Cai等[18]认为采用先验假设提取与雾霾图像相关的特征等价于用适当的滤波器卷积输入的雾霾图像,提出了DehazeNet去雾网络算法。该网络首次采用深度卷积神经网络估计大气散射模型的中间参数,构建雾霾图像到中间参数的映射关系。论文分析了DehazeNet结构与现有多种基于先验信息去雾算法(暗通道先验、最大对比度、颜色衰减先验)等之间的联系,解释DehazeNet可以通过设置不同核函数的参数获得与基于先验信息去雾算法相同的功能。
同年,Ren等[37]提出基于多尺度卷积神经网络(multi-scale convolutional neural networks,MSCNN)的透射率估计算法。论文构建粗尺度估计网络和精细尺度估计网络,粗尺度网络选择较大的卷积核,在大感受野下预测雾霾图像的全局透射图,精细尺度网络则选择相对较小卷积核提取透射图细节信息。为了获得更丰富的细节信息,论文将粗尺度网络的输出拼接到细尺度网络。
Boyi等[38]提出AOD-Net去雾网络,认为分别单独估计透射率和大气光,会产生累积误差,不利于重建清晰图像,是一种次优化解决算法。所以论文重新改写大气散射模型式(4),使其只取决于一个参数
$ K(x) $ ,具体如下:$$ J(x) = K(x)I(x) - K(x) + b $$ (6) $$ K(x) = \dfrac{{\dfrac{1}{{t(x)}}(I(x) - A) + (A - b)}}{{I(x) - 1}} $$ (7) AOD-Net包括两个模块:
$K(x)$ 估计模块和图像重建模块,参见图1。$K(x)$ 估计模块用于估计式(7)中的参数$K(x)$ ,其综合了大气散射模型中的两个参数透射率和大气光。图像重建模块用于实现式(4),与输入图像进行相乘获取清晰图像。该文献将大气散射模型进行转换并将其嵌入到去雾网络中从而使网络模型参数估计由2个减少为1个。论文首次定量研究去雾算法对后续高级视觉任务影响,将AOD-Net与Faster R-CNN[39]相结合应用于雾霾环境中目标检测,通过实验证明联合调优模型在有雾情况下能够有效提高检测效果,优于单一Faster R-CNN检测算法。AOD-Net也可以与其他深度模型无缝嵌入,构成统一模型在模糊图像上执行目标检测、识别、跟踪等,其过程具有隐式去雾能力。
b) 基于对抗神经网络参数估计算法
生成式对抗网络(generative adversarial nets,GAN)是一种深度学习模型,常见结构包括生成器和判别器,采用博弈方式进行学习,具有强大的生成建模能力和样本空间分布学习能力。受对抗神经网络在像素级视觉任务(如图像生成[40-41]、图像修复[42-43]和图像超分辨率[44-45])上成功应用的启发,GAN也被用于雾霾图像的清晰化。
文献[46]在大气散射模型基础上设计了DehazeGAN去雾网络结构。首先,重新书写大气散射模型公式为
$$ J(x) = \frac{{I(x) - A}}{{t(x)}} + A $$ (8) 然后,构造成生成式对抗网络结构,其生成器拟合上述模型产生去雾后的图像。判别器用于鉴定重建图像效果,并指导对抗网络参数优化。文献为了消除分别估计参数带来累积误差的问题,构建密集连接特征提取单元,然后构建不同网络结构分别估计透射率和大气光值,根据式(8)复原清晰图像。
2018年Zhang等[47]提出了基于GAN结构的密集连接金字塔式去雾算法 (densely connected pyramid dehazing network,DCPDN)。网络结构共包括4个模块:1)基于金字塔密集连接的透射率估计模块;2)U-Net大气光估计模块;3)基于大气散射模型的清晰图像反演模块;4)透射率与重建图像联合判别器。
该文与文献[46]创新思路相似,将透射率、大气光和清晰图像统一集中到一个深度网络结构进行优化,从而使网络能够联合透射率、大气光和复原图像进行全局统一训练学习。论文采用新的保持边缘损失函数进行优化。
2. 无模型图像去雾算法
基于模型的图像去雾算法一方面要求模型能够准确建模雾霾图像形成过程,另一方面需要准确无误估计模型参数。但是,在实际应用时上述2个要求面临巨大的挑战。
1) 模型表达局限性。
雾霾图像降质成像过程非常复杂,为了拟合这一退化过程,构建的模型具有高度非线性特性,包含大量的未知变量,易生成不适定求解模式。为便于模型可实现,常常利用雾霾图像先验信息对模型进行限制或者做简化假设,而其中一些假设并不适用于所有可能的情况。如,大气散射模型假设在光线传播路径上,大气介质颗粒均匀一致,介质浓度分布均匀一致。这些假设在一定条件下是无法满足现实需求,实际环境存在大量雾霾颗粒、浓度分布不均匀的情况。此时,继续以大气散射模型建模雾霾图像,常常出现去雾残留严重情况,并不利于图像清晰化处理。
2) 参数估计的误差。
有模型的图像去雾算法首要任务是参数估计,不精确的参数估计会导致误差累积,无法达到雾霾图像到清晰图像全局最优去雾效果。
无模型图像去雾算法可以有效解决上述问题。无模型图像去雾算法可以直接学习有雾图像与无雾图像之间的映射关系,基于增强技术图像去雾算法和基于深度学习端到端图像去雾算法都不需要模型支持。
2.1 基于图像增强技术去雾算法
大气介质中的雾霾颗粒会吸收或散射场景入射光线,导致图像采集设备获取的图像边缘轮廓模糊、颜色对比度低。采用图像增强手段来改善图像的清晰度是非常直观的无模型去雾方法,是早期图像去雾常采用的处理方法。
2.2 基于深度学习无模型去雾算法
上述对大气散射模型的简化假设增加了模型的可实现性,但是也使模型的表达受到限制,适合描述雾霾浓度分布均匀的图像。所以,相较于基于深度学习大气散射模型参数估计算法,基于深度学习端到端去雾算法由于不受模型的限制,既可以去除雾霾浓度分布均匀图像,也可以处理非均匀雾霾图像,能够处理的图像范围更大,更加灵活。
2.2.1 基于CNN无模型图像去雾算法
2020年Sourya等[48]提出了端到端的非均匀雾霾图像去雾算法。论文分别提出深度多区域和多尺度分层网络结构去除图像中的非均匀雾霾。深度多区域分层网络框架采用图像去模糊算法[49]中提出的(1-2-4)结构。网络结构主体包括3个编码器和3个解码器。其中,(1-2-4)主要体现在3个编码器的输入图像上。第1个编码器的输入为完整图像,第2个编码器的输入是原始图像纵向划分的2个区域。最后,将图像纵向、横向分割为4个区域作为第3个编码器网络输入。为了获取多尺度深度特征,网络将第2、3个编码器特征逐级传递给上级区域,并且各编码器–解码器输出拼接到上级输入部分。论文还探索了多尺度分层网络结构去雾性能。其结构与深度多区域分层网络框架主体结构相近,区别是3个编码器的输入分别为原始雾霾图像和2倍、4倍下采样图像。由于深度多区域分层结构能够从更细的层次到更粗的层次聚合生成的局部特征,且算法速度较快,所以可以更加有效去除视频序列中的雾霾图像。
2020年Wang等[50]针对真实非均匀雾霾图像提出并联异构双胞胎端到端无模型去雾算法。网络结构主体设计为U型编码–解码式结构,用于完成雾霾图像的特征提取和重构工作,为了提高非均匀雾霾区域复原后细节信息丢失问题,论文构建一个轻量级细节特征增强子网络,与主干网络相并联,最后采用自适应加权融合的形式获取增强去雾图像。具体结构图参见图2。
文献[50]的另一个贡献之处在于创建了一个较大型的非均匀雾霾图像数据库。该数据库共拍摄190个场景图像,在每个场景下分别获取清晰样本和80~200张雾霾样本。在拍摄过程中,为防止对齐样本出现像素移位,拍摄同一个场景时,保持摄像机位置不变。同一场景不同图像采集的时间间隔非常短以此避免光照条件变化影响。相比非均匀雾霾数据集NH-HAZE,该数据集包含的场景样本多,非常适合深度神经网络训练。
2.2.2 基于GAN无模型图像去雾算法
2018年,基于条件对抗网络去雾算法被提出[51]。算法中生成器采用编–解码式结构。为了消除普通GAN算法易出现雾霾残留、伪影和颜色失真等问题,论文对损失函数进行修正,将VGG特征损失和L1正则化梯度先验损失与基于内容的像素级损失相结合,共同用于生成器的指导。
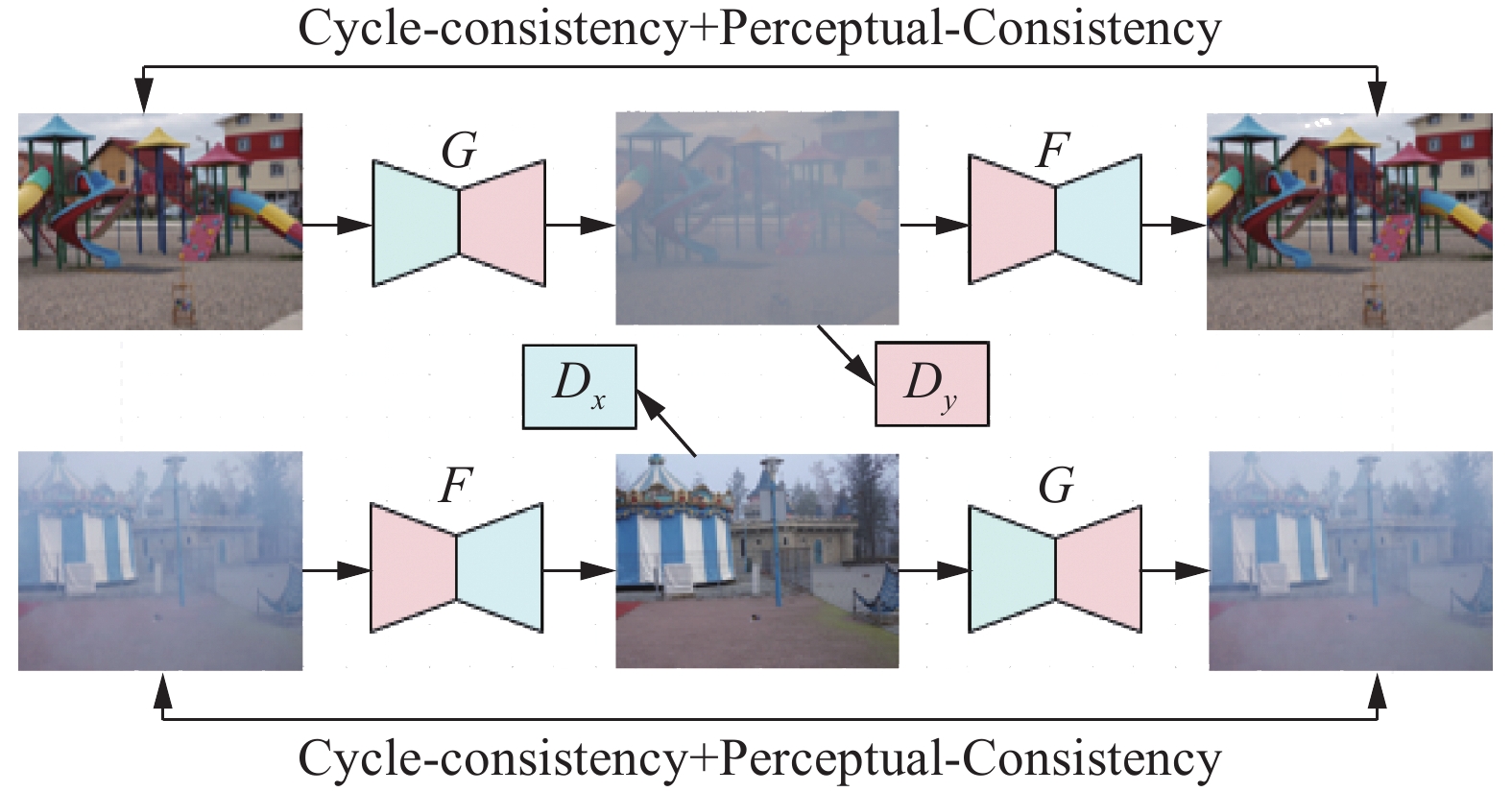
2018年Engin等[52]受文献[53]的启发,提出了基于非对齐训练集图像去雾网络Cycle-Dehaze。该网络框架由2个生成器和2个判别器组成,框架如图3所示。生成器G和F分别用于拟合雾霾图像反演清晰图像过程和清晰图像生成雾霾图像过程。判别器Dx和Dy则分别用于鉴别生成器G和F的拟合能力。算法通过结合循环一致性和感知损失来增强循环公式,以提高纹理信息恢复的质量,并生成视觉上更好的无雾图像。
不需要对齐训练样本集是该论文的一大特色。另外,论文构建了一个真正端到端图像去雾框架,无需估计大气散射模型中的各种参数。另外,论文在循环一致性损失的基础上增加循环感知一致性损失,增强CycleGAN[53]架构用于单幅图像去雾性能。
2020年,基于改进条件GAN被应用于图像去雾[54],文献采用具有较高参数学习效率的Tiramisu模型[55]代替经典的U-Net模型作为生成器,采用一种基于patch的判别器来减少输出中的伪影。最后,为了进一步提高输出的感知质量,设计一种混合加权损失函数对模型进行训练。
2.2.3 引入视觉注意力机制无模型图像去雾算法
近年来,视觉注意机制[56-58]在深度神经网络设计中得到了广泛的应用,它可以动态聚焦局部信息的变化,对网络的性能起到重要信息重点关注的作用。受文献[59]的启发,2020年Qin等[60]提出了一种端到端特征融合注意力网络(feature fusion attention network,FFA-Net),用于非均匀雾霾图像的处理。
普通的基于深度学习图像去雾网络对通道特征和像素特征的处理是一样的,每个特征给予同等的权值。但是针对非均匀雾霾图像,薄的雾霾的权重应该与厚的雾霾区域像素的权重有明显的不同。此外,根据文献DCP可知,某些像素至少在一个RGB通道中具有非常低的强度是很常见的,这进一步说明不同的通道特征应具有完全不同的加权信息。采用同等权值可能导致资源浪费,限制网络的表示能力。FFA-Net设计了一个特征注意力模块,通过将通道注意力和像素注意力分别结合在通道和像素特征上,对不同的特征和像素进行加权处理,使网络集中更多注意力在厚雾像素和更重要的通道信息上。另外,网络采用局部残差、全局残差和跳接相结合的结构,使多尺度、多样化特征进行融合,提高网络学习能力和表示能力。该文正式提出雾霾在图像上的分布是不均匀的,并通过通道注意力模块和像素注意力模块分别为通道特征和像素特征分配不同权值,将更多处理资源集中在雾度高的像素和更重要的通道信息上,使处理不同类型的信息具有更大灵活性。
3. 基于深度学习去雾算法比较
深度学习既可以应用于有模型图像去雾算法也可以不需要任何模型对图像进行处理。相较于其他清晰化算法,基于深度学习的去雾算法在大规模数据集的支持下,其去雾效果可以得到极大提升。为了对基于深度学习的去雾算法进行分析总结,我们绘制了表1,分别从算法采用的网络结构、选取的去雾模型以及论文的主要贡献、优点、缺点等角度对深度学习去雾算法进行了比较。
表 1 基于深度学习的图像去雾算法比较Table 1 Comparison of image dehazing algorithms based on deep learning分类依据 算法 网络结构 去雾模型 主要贡献 缺点 数据集 基于深度学习模型参数估计算法 DehazeNet去雾算法[18] CNN 大气散射模型 首次采用深度网络直接学习透射率与雾图关系。 1)认为大气光是一个全局一致的常数;2)并非端到端学习
算法。10000张网络清晰
图像,以大气散射
模型为基础自制成
雾霾图像。MSCNN去雾算法[37] CNN 大气散射模型 论文提出的多特征学习算法即可以直接计算大气散射模型参数,又易于实现和再现。 采用景深无穷远透射率为零估计大气光值,不利于室内雾霾图像处理。 6000张图像来自NYU2-Depth数
据集。AOD-Net去雾算法[38] CNN 大气散射模型 论文首次定量研究去雾算法对后续高级视觉任务影响。 论文通过人工选择参数形式合成雾霾数据集,与真实雾霾图像
相差较大。27256张图像来自NYU2-Depth数
据集。DCPDN去雾算法[47] CNN 大气散射模型 将大气散射模型直接嵌入网络结构中进行优化。 论文以合成雾霾图像为数据集,所以处理真实雾图效果较差。 4000张图像来自NYU2-Depth数
据集。Dehaze-GAN[46] GAN 大气散射模型 论文重新改写大气散射模型,采用不同网络结构估计透射率和大气光值。 论文以合成雾霾图像
为数据集,所以处理
真实雾图效果较差。7000张合成图像
来自Haze- COCO
数据集。续表 1 分类依据 算法 网络结构 去雾模型 主要贡献 缺点 数据集 基于深度学习无模型图像去雾算法 多区域分层网
络去雾算法[48]CNN 无模型 针对非均匀雾霾图像,提出(1-2-4)深度多区域分层网络结构。 固定多区域划分方
式不利于随机非均
匀雾霾图像处理。55张图像来自NH-HAZE数据集。 异构双胞胎网络非均匀雾霾图像去雾算法[50] CNN 无模型 针对非均匀雾霾图
像,构建轻量级细
节特征增强子网络
实现图像去雾。雾霾的非均匀性
较强时,容易出
现雾霾残留。190个场景来自自己拍摄真实雾霾数据集。 FFA-Net图像
去雾算法[60]CNN 无模型 针对非均匀雾霾图
像,利用注意力机
制为不同特征分配
不同权值。论文实验所选数据
集主要是人工合成
均匀雾霾图像,缺
少在雾霾分布不均
匀的验证。13990张图像来自RESIDE数据集。 Cycle-Dehaze
去雾算法[52]GAN 无模型 论文在循环一致性损失的基础上增加循环感知一致性损失。 文中采用非对齐数据不利于像素级图像重建。 1449张来自NYU2-Depth;25张来自
I-HAZE和35张来自
O-HAZE。从对比结果可以看出,在有模型图像去雾算法中,深度学习主要用于对大气散射模型中两个参数的估计。由于大气散射模型可以通过改变参数合成不同程度的雾霾图像,所以这类算法有大规模数据集的支持,容易获得较高的去雾评价指标。其缺点是受大气散射模型描述能力的局限,适合处理雾霾分布均匀图像。
深度学习在无模型去雾算法中,一般采用端到端方式,直接构建雾霾图像到清晰图像的映射。优点是无需考虑模型的局限性,可以处理任意雾霾浓度图像。但是,易受数据集规模小的限制。
4. 图像去雾数据集
在图像语义分割、图像理解、目标检测及跟踪、无人驾驶等计算机视觉任务中,图像作为基本处理对象,通常被假设为清晰无噪声。但在真实环境中,获取的图像因受天气、外界环境等各种因素影响,容易出现严重的退化现象。在降质严重的雾霾图像上直接进行计算机视觉任务处理会降低算法的性能,尤其是获取的图像中雾霾呈现非均匀分布。虽然深度学习可以有效构建雾霾图像到清晰图像的映射关系,但是,深度学习需要大规模带标注对齐数据集的支持。由于收集或创建具有真实清晰标注图像及其雾霾样本对环境、设备要求极高,面临着巨大挑战,所以,大规模真实基准数据库一直处于缺失状态。目前图像去雾算法的训练集主要是以人工合成数据集以及规模较小的真实雾霾数据集为主。
4.1 人工合成雾霾数据集
人工合成数据集主要是通过大气散射模型将清晰图像合成为雾霾图像,在合成过程中,随机采样散射系数β,根据式(5)生成透射图。目前常用的数据集包括如NYU2-Depth数据集[16]、D-hazy数据集[17]、HazeRD数据集[15] 和RESIDE数据集[14]。
1) NYU2-Depth数据集。
NYU2-Depth数据集[16]是由来自于美国3个不同城市的商业和住宅建筑等464个不同室内场景的视频序列组成。这些视频序列是由微软Kinect的RGB和Depth摄像头记录的。数据集共有1449幅带深度信息的图像,每幅图像附有详细的标注图。该数据集初始创建主要应用于图像目标识别以及图像中目标间关系的确定。由于数据集中包含深度信息,后来常被应用于雾霾图像的合成。研究者通过设置不同的大气光参数和透射率参数,由大气散射模型合成雾霾图像集。如文献[37, 38, 61]等都是采用NYU2-Depth数据集中清晰图像和深度图合成雾霾图像进行算法验证。
2) D-hazy数据集。
D-hazy数据集[17]是最早提出的一个专门用于定量评估图像去雾的数据集。数据集中包含1400多对无雾图像和对应的深度图。这些数据来自于之前建立的Middelbury数据集[62]和NYU2-Depth数据集。D-hazy雾霾数据集采用大气散射模型合成,其中深度信息已知,透射率中参数
$ \beta $ 设置为1,大气光值也被设置为1。3) HazeRD数据集。
HazeRD数据集[15]是在15个室外环境拍摄的清晰图像上合成数据集。标注样本包括一幅无雾RGB图像和一个对应深度图。为测试除雾算法的鲁棒性,每个场景通过设置不同透射率参数
$ \beta $ 合成5种从轻雾到浓雾图像,模拟不同天气条件的雾霾。其中,大气光值设置为0.76,以确保在阴天物体清晰度。4) RESIDE数据集。
RESIDE数据集全称REalistic Single Image Dehazing,是一个大规模人工合成数据集,共包括13990幅合成模糊图像,使用来自现有室内深度数据集Middelbury数据集和NYU2-Depth数据集[16]的1399幅清晰图像生成。由每个清晰图像生成10幅模糊图像。大气光值取值范围为[0.7,1.0],透射率中
$ t(x) = {{\rm{e}}^{ - \beta d(x)}} $ 参数$ \beta $ 取值为[0.6,1.8]。RESIDE-
$ \beta $ 为RESIDE数据集的扩充,增加了2061幅在北京室外环境拍摄的场景,通过设定$ \beta \in\{0.04, 0.06,0.08,0.1,0.12,0.16,0.2\} $ 等7个值,和大气光$ A \in \{0.8,0.85,0.9,0.95,1\} $ 5个值,共合成图72135张室外合成雾霾图像——OTS (outdoor training set )。数据集中还包括4322张室外真实雾霾图像。4.2 真实雾霾数据集
这种估计机制使合成的数据集非常适合处理均匀雾霾图像去雾算法的验证。但是实际大气介质中的雾霾受粉尘、烟和各种悬浮颗粒的影响,给图像带来的随机噪声很难令其分布均匀一致。另外,由于自然界中雾霾产生因素较多,当产生雾霾的位置比较随机时,很多由实际环境获取的雾霾图像表现出典型的非均匀分布特性,如煤矿井下采集到的降质图像、火灾现场采集到的烟雾图像等。近年来,随着对真实雾霾场景清晰化关注的加重,真实小规模雾霾数据集开始建立。
O-HAZE数据集[20]是第一个创建的包含雾霾/清晰图像对的真实雾霾数据集。它由45个不同的户外场景组成,其雾霾图像使用专业的雾霾发生器在可控照明下获取。
I-HAZE数据集[19]与O-HAZE相似,但采集的是室内环境35对雾霾/清晰样本。2018年IEEE CVPR NTIRE(new trends in image restoration and enhancement)研讨会举办针对真实雾霾场景的目标检测挑战赛。I-HAZE和 O-HAZE被选为挑战赛数据集。
DENSE-HAZE[63]是另一个真实图像数据集,雾霾分布非常密集,数据集中包含33对雾霾/清晰样本。在2019年IEEE CVPR NTIRE研讨会上,DENSE-HAZE被选为图像去雾挑战赛标准数据集。
在上述工作的基础上,2020年Ancuti等[21]提出真实非均匀带标注数据集——NH-HAZE数据集,这是第一个明确提出的具有非均匀雾霾/清晰样本图像的对齐数据集,包含55个户外场景。作者采用专业雾霾发生器将非均匀雾霾引入场景,获取真实雾霾图像。
4.3 人工合成数据集与真实数据集比较
4.3.1 人工合成数据集与真实数据集定量比较
表2对上述数据集在多个维度上进行了比较,并分析了各个数据集适合应用的范围。从数据集的数据规模可以看出,人工合成数据集通过改变透射率参数和大气光值在少量场景下即可以获得大规模雾霾图像数据。而真实拍摄的图像则目前仍然是小规模形式。人工合成数据集,由于参数选择固定,更适合描述均匀雾霾图像,图像局限性较大。
表 2 不同数据集多维度对比Table 2 Multi-dimensional comparison of different datasets数据集 室内/室外 清晰场景 真实/合成 深度信息 数据集规模 是否可扩展 雾霾浓度分布情况 NYU2-Depth 室内 464个场景 合成 有深度图 1449对图像 改变参数可以扩展 均匀 D-hazy 室内 487个场景 合成 有深度图 1400+对图像 改变参数可以扩展 均匀 HazeRD 室外 15个场景 合成 有深度图 / 改变参数可以扩展 均匀 RESIDE 室内室外 1399室内场景和
2061室外场景合成 有深度图 13990幅室内雾霾
图像和72135幅室
外雾霾图像改变参数可以扩展 均匀 O-HAZE 室外 45个场景 真实拍摄 无深度图 45对图像 不可以 非均匀 I-HAZE 室内 35个场景 真实拍摄 无深度图 35对图像 不可以 非均匀 DENSE-HAZE 室外 33个场景 真实拍摄 无深度图 33对图像 不可以 非均匀 NH-HAZE 室外 55个场景 真实拍摄 无深度图 55对图像 不可以 非均匀 下面继续从定量角度分析不同数据集对算法性能的影响。我们选用7种非常有竞争力的图像去雾算法分别在人工合成数据集RESIDE、真实雾霾数据集O-HAZE和非均匀雾霾数据集NH-HAZE上进行算法验证,算法包括He[28]、Cai[18]、Berman[64]、Galdran[65]、Zhang[66]、Liu[67]和Ancuti[68]。多种算法在不同数据上的对比如表3所示。
表 3 多种算法在人工合成数据集、真实雾霾数据集和真实非均匀雾霾数据上的效果对比Table 3 Comparison of various algorithms on synthetic dataset, real hazy dataset and real uneven hazy dataset算法 人工合成数
据集RESIDE真实雾霾图
像数据集
O-HAZE非均匀雾霾
图像数据集
NH-HAZEPSNR SSIM PSNR SSIM PSNR SSIM He[28] 17.04 0.81 16.59 0.74 12.91 0.47 Cai[18] 20.55 0.84 16.21 0.67 12.38 0.46 Berman[64] 17.45 0.75 16.61 0.75 12.46 0.53 Galdran[65] 16.53 0.78 17.55 0.65 13.32 0.48 Zhang[66] 21.56 0.86 24.24 0.73 17.08 0.59 Liu[67] 30.86 0.98 17.53 0.48 13.09 0.50 Ancuti[68] / / 20.16 0.80 14.30 0.60 这些算法在评价指标PSNR和SSIM的值相差较大,由人工合成数据集、真实雾霾数据集到非均匀数据集指标值呈明显下降趋势。人工合成数据集上的去雾评价指标结果优于真实雾霾数据集,与非均匀雾霾数据集的对比优势更加明显。文献[67]在RESIDE上的PSNR和SSIM值分别为30.86和0.98,而在NH-HAZE上的PSNR和SSIM值分别为13.09和0.50,提高了17.77和0.48。实验数据说明上述算法针对均匀雾霾分布图像有较好的处理效果,但是,当图像数据集来自于真实数据集时,算法性能受到限制,评价指标PSNR和SSIM都在减小,尤其是非均匀雾霾数据集,效果远远小于人工合成数据集。所以,对于非均匀雾霾图像需要考虑更加合适的算法进行处理。
4.3.2 人工合成数据集与真实数据集定性视觉比较
为分析合成雾霾数据集、真实雾霾数据集的异同之处,我们选用常用去雾图像样本做对比,如图4,从视觉的角度定性说明合成雾霾数据集与真实雾霾数据集之间的差别。
 图 4 人工合成雾霾图像、真实雾霾图像和真实非均匀雾霾图像对比Fig. 4 Image samples of synthetic dataset, real dataset and uneven real dataset
图 4 人工合成雾霾图像、真实雾霾图像和真实非均匀雾霾图像对比Fig. 4 Image samples of synthetic dataset, real dataset and uneven real dataset 下载:
全尺寸图片
下载:
全尺寸图片
图4(a)为人工合成数据集中室内雾霾/清晰样本对,图4(b)为人工合成数据集中室外雾霾/清晰样本对,图4(c)为真实数据集室内雾霾/清晰样本对,图4(d)为真实数据集室外雾霾/清晰样本对,图4(e)为真实非均匀雾霾数据集样本,来自于文献[21] NH-HAZE数据集。从图中可以看出人工合成数据集中雾霾分布非常均匀,图4(c)和图4(d)的真实数据集中雾霾分布相比人工合成数据集要随机性强一些,很难直接定性断定其呈均匀分布。而最后一行图像中雾霾分布的非均匀性非常明显,雾霾浓度、位置随机,对整幅图像的影响也不一致。
5. 结论
雾霾图像清晰化是人工智能领域中以图像为主要处理对象的计算机视觉任务的基础工作,研究雾霾图像的降质原理,提高其清晰化程度具有重要的研究意义和应用前景。文章对图像去雾领域代表性算法进行了详细的梳理和总结,分别从雾霾图像有模型的角度和无模型的角度,对各类算法进行分析、比较。并将目前给去雾性能带来极大提升的深度学习算法的优点、缺点进行分析和对比。另外,文章对主流的雾霾图像数据集进行了梳理,并从数据集适应范围、规模、可扩展性等多个维度对各个数据集进行总结,期望能对本领域的从业人员提供有价值的参考。未来研究方向展望:
1) 模型化方法的问题是:能准确建立雾霾成像模型是清晰化问题的一个关键内容,但目前所建模型本身还比较粗糙,建模本身的科学依据和参数赋值的统计基础都还显得不足。因此,通过足量的测试调试和理论分析,努力改进建模的质量,是这一类研究方法需要改进的地方。
2) 对于无模型的去雾方法中,深度学习最值得关注。但是,深度学习方法本身也需要有大的改进。它的最大不足是未能充分利用先验知识,仅靠现场的测试样本来解决问题。利用先验知识的方法有很多,最重要的途径是给深层神经网络增加相应的知识库(先验知识库),使相关先验信息和大量数据共同指导神经网络学习过程。目前的神经网络都没有知识库,主要是靠各个领域海量数据获得的“知识”实现映射,因此,质量受限,而且结果不可解释。如果与相应的先验知识库结合起来,就可以充分利用历史知识来提高工作质量,而且使结果可以解释。所以将先验信息有机地融合到深度学习中,是非常值得深入研究的课题。
3) 目前,不论是有模型图像去雾算法还是无模型去雾算法,多数假设雾霾浓度分布是均匀的。基于大气散射模型去雾算法,模型本身就强制假设雾霾分布均匀,而无模型算法则在选择训练数据集时,多以人工合成雾霾图像数据集为主,该类数据集的生成过程就暗含雾霾分布均匀。但是,真实场景雾霾分布的随机性较强,更可能给图像带来非均匀随机噪声。所以,去掉均匀分布假设,实现图像去雾具有更实际的意义。
4) 很多计算机视觉处理任务得益于大规模标准化数据库的支持。例如,ImageNet对图像目标识别、分类的影响和OTB2013、OTB100对目标跟踪的支持。相比之下,具有真实清晰标注图像及其雾霾样本的大规模基准数据库一直处于缺失状态。虽然,在图像去雾方面,存在大规模合成数据集,但这类数据适合建模均匀雾霾图像,而实际高级视觉信息处理中,不论是智能交通还是自动驾驶,需要处理真实图像数据都可能是非均匀雾霾图像,所以构建更多真实雾霾数据集以及提出更多针对真实雾霾图像处理算法具有重要的研究价值。
5) 目前应对各种真实雾霾图像的带标注训练集规模较小,如I-HAZE和O-HAZE分别只有35对、45对训练数据。在没有更大数据集的支持下,这类问题可以视为小样本问题。如何从小样本的角度考虑解决图像去雾问题是一个很值得的研究内容,也是我们下一步的重点工作方向。
-
图 4 人工合成雾霾图像、真实雾霾图像和真实非均匀雾霾图像对比
Fig. 4 Image samples of synthetic dataset, real dataset and uneven real dataset
下载:
全尺寸图片
表 1 基于深度学习的图像去雾算法比较
Table 1 Comparison of image dehazing algorithms based on deep learning
分类依据 算法 网络结构 去雾模型 主要贡献 缺点 数据集 基于深度学习模型参数估计算法 DehazeNet去雾算法[18] CNN 大气散射模型 首次采用深度网络直接学习透射率与雾图关系。 1)认为大气光是一个全局一致的常数;2)并非端到端学习
算法。10000张网络清晰
图像,以大气散射
模型为基础自制成
雾霾图像。MSCNN去雾算法[37] CNN 大气散射模型 论文提出的多特征学习算法即可以直接计算大气散射模型参数,又易于实现和再现。 采用景深无穷远透射率为零估计大气光值,不利于室内雾霾图像处理。 6000张图像来自NYU2-Depth数
据集。AOD-Net去雾算法[38] CNN 大气散射模型 论文首次定量研究去雾算法对后续高级视觉任务影响。 论文通过人工选择参数形式合成雾霾数据集,与真实雾霾图像
相差较大。27256张图像来自NYU2-Depth数
据集。DCPDN去雾算法[47] CNN 大气散射模型 将大气散射模型直接嵌入网络结构中进行优化。 论文以合成雾霾图像为数据集,所以处理真实雾图效果较差。 4000张图像来自NYU2-Depth数
据集。Dehaze-GAN[46] GAN 大气散射模型 论文重新改写大气散射模型,采用不同网络结构估计透射率和大气光值。 论文以合成雾霾图像
为数据集,所以处理
真实雾图效果较差。7000张合成图像
来自Haze- COCO
数据集。续表 1 分类依据 算法 网络结构 去雾模型 主要贡献 缺点 数据集 基于深度学习无模型图像去雾算法 多区域分层网
络去雾算法[48]CNN 无模型 针对非均匀雾霾图像,提出(1-2-4)深度多区域分层网络结构。 固定多区域划分方
式不利于随机非均
匀雾霾图像处理。55张图像来自NH-HAZE数据集。 异构双胞胎网络非均匀雾霾图像去雾算法[50] CNN 无模型 针对非均匀雾霾图
像,构建轻量级细
节特征增强子网络
实现图像去雾。雾霾的非均匀性
较强时,容易出
现雾霾残留。190个场景来自自己拍摄真实雾霾数据集。 FFA-Net图像
去雾算法[60]CNN 无模型 针对非均匀雾霾图
像,利用注意力机
制为不同特征分配
不同权值。论文实验所选数据
集主要是人工合成
均匀雾霾图像,缺
少在雾霾分布不均
匀的验证。13990张图像来自RESIDE数据集。 Cycle-Dehaze
去雾算法[52]GAN 无模型 论文在循环一致性损失的基础上增加循环感知一致性损失。 文中采用非对齐数据不利于像素级图像重建。 1449张来自NYU2-Depth;25张来自
I-HAZE和35张来自
O-HAZE。表 2 不同数据集多维度对比
Table 2 Multi-dimensional comparison of different datasets
数据集 室内/室外 清晰场景 真实/合成 深度信息 数据集规模 是否可扩展 雾霾浓度分布情况 NYU2-Depth 室内 464个场景 合成 有深度图 1449对图像 改变参数可以扩展 均匀 D-hazy 室内 487个场景 合成 有深度图 1400+对图像 改变参数可以扩展 均匀 HazeRD 室外 15个场景 合成 有深度图 / 改变参数可以扩展 均匀 RESIDE 室内室外 1399室内场景和
2061室外场景合成 有深度图 13990幅室内雾霾
图像和72135幅室
外雾霾图像改变参数可以扩展 均匀 O-HAZE 室外 45个场景 真实拍摄 无深度图 45对图像 不可以 非均匀 I-HAZE 室内 35个场景 真实拍摄 无深度图 35对图像 不可以 非均匀 DENSE-HAZE 室外 33个场景 真实拍摄 无深度图 33对图像 不可以 非均匀 NH-HAZE 室外 55个场景 真实拍摄 无深度图 55对图像 不可以 非均匀 表 3 多种算法在人工合成数据集、真实雾霾数据集和真实非均匀雾霾数据上的效果对比
Table 3 Comparison of various algorithms on synthetic dataset, real hazy dataset and real uneven hazy dataset
算法 人工合成数
据集RESIDE真实雾霾图
像数据集
O-HAZE非均匀雾霾
图像数据集
NH-HAZEPSNR SSIM PSNR SSIM PSNR SSIM He[28] 17.04 0.81 16.59 0.74 12.91 0.47 Cai[18] 20.55 0.84 16.21 0.67 12.38 0.46 Berman[64] 17.45 0.75 16.61 0.75 12.46 0.53 Galdran[65] 16.53 0.78 17.55 0.65 13.32 0.48 Zhang[66] 21.56 0.86 24.24 0.73 17.08 0.59 Liu[67] 30.86 0.98 17.53 0.48 13.09 0.50 Ancuti[68] / / 20.16 0.80 14.30 0.60 -
[1] SHEKAR A K, GOU Liang, REN Liu, et al. Label-free robustness estimation of object detection CNNs for autonomous driving applications[J]. International journal of computer vision, 2021, 129(4): 1185–1201. doi: 10.1007/s11263-020-01423-x [2] XIAO H, MOSHREFI A, TURNER A, et al. Methods and systems for automobile security monitoring[P]. US, 20120162423A1, 2012. [3] LI Yanshan, XIA Rongjie, LIU Xing. Learning shape and motion representations for view invariant skeleton-based action recognition[J]. Pattern recognition, 2020, 103: 107293. doi: 10.1016/j.patcog.2020.107293 [4] ZHAO Zhongqiu, ZHENG Peng, XU Shoutao, et al. Object detection with deep learning: a review[J]. IEEE transactions on neural networks and learning systems, 2019, 30(11): 3212–3232. doi: 10.1109/TNNLS.2018.2876865 [5] WANG Guangting, LUO Chong, XIONG Zhiwei, et al. SPM-tracker: series-parallel matching for real-time visual object tracking[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 3638−3647. [6] LAND E H. The retinex[J]. American scientist, 1964, 52(2): 247–264. [7] NAYAR S K, NARASIMHAN S G. Vision in bad weather[C]//Proceedings of the seventh IEEE International Conference on Computer Vision. Kerkyra: IEEE, 1999: 820-827. [8] NARASIMHAN S G, NAYAR S K. Vision and the atmosphere[J]. International journal of computer vision, 2002, 48(3): 233–254. doi: 10.1023/A:1016328200723 [9] NARASIMHAN S G, NAYAR S K. Contrast restoration of weather degraded images[J]. IEEE transactions on pattern analysis and machine intelligence, 2003, 25(6): 713–724. doi: 10.1109/TPAMI.2003.1201821 [10] 杨艳飞. 一般形式正则化的大规模离散线性不适定问题算法的研究[D]. 北京: 清华大学, 2018. YANG Yanfei. Algorithms for large scale discrete linear ill-posed problems with general-form regularization[D]. Beijing: Tsinghua University, 2018. [11] XU Zhiyuan, LIU Xiaoming, JI Na. Fog removal from color images using contrast limited adaptive histogram equalization[C]//2009 2nd International Congress on Image and Signal Processing. Tianjin: IEEE, 2009: 1−5. [12] 牛宏侠, 王春智. 基于HSI空间的沙尘图像增强算法[J]. 北京交通大学学报, 2022, 46(5): 1–8. NIU Hongxia, WANG Chunzhi. Sand-dust image enhancement algorithm based on HSI space[J]. Journal of Beijing Jiaotong University, 2022, 46(5): 1–8. [13] 程新. 基于同态滤波的图像增强算法研究[D]. 西安: 西安邮电大学, 2016. [14] LI Boyi, REN Wenqi, FU Dengpan, et al. Benchmarking single-image dehazing and beyond[J]. IEEE transactions on image processing, 2019, 28(1): 492–505. doi: 10.1109/TIP.2018.2867951 [15] ZHANG Yanfu, DING Li, SHARMA G. HazeRD: an outdoor scene dataset and benchmark for single image dehazing[C]//2017 IEEE International Conference on Image Processing. Beijing: IEEE, 2017: 3205−3209. [16] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor Segmentation and Support Inference from RGBD Images[C]//European Conference on Computer Vision. Berlin: Springer, 2012: 746−760. [17] ANCUTI C, ANCUTI C O, DE VLEESCHOUWER C. D-HAZY: a dataset to evaluate quantitatively dehazing algorithms[C]//2016 IEEE International Conference on Image Processing. Phoenix: IEEE, 2016: 2226−2230. [18] CAI Bolun, XU Xiangmin, JIA Kui, et al. DehazeNet: an end-to-end system for single image haze removal[J]. IEEE transactions on image processing: a publication of the IEEE Signal Processing Society, 2016, 25(11): 5187–5198. doi: 10.1109/TIP.2016.2598681 [19] ANCUTI C, ANCUTI C O, TIMOFTE R, et al. I-HAZE: a dehazing benchmark with real hazy and haze-free indoor images[M]//Advanced Concepts for Intelligent Vision Systems. Cham: Springer International Publishing, 2018: 620−631. [20] ANCUTI C O, ANCUTI C, TIMOFTE R, et al. O-HAZE: a dehazing benchmark with real hazy and haze-free outdoor images[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City: IEEE, 2018: 867−8678. [21] ANCUTI C O, ANCUTI C, TIMOFTE R. NH-HAZE: an image dehazing benchmark with non-homogeneous hazy and haze-free images[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: IEEE, 2020: 1798−1805. [22] PETRO A B, SBERT C, MOREL J M. Multiscale retinex[J]. Image processing on line, 2014, 4: 71–88. doi: 10.5201/ipol.2014.107 [23] XIE F, TANG M, ZHANG R. Review of image enhancement algorithms based on Retinex[J]. Journal of data acquisition and processing, 2019, 34(1): 1–11. [24] LAND E H, MCCANN J J. Lightness and retinex theory[J]. Journal of the optical society of America, 1971, 61(1): 1. doi: 10.1364/JOSA.61.000001 [25] 顾振飞, 张登银. 基于变分Retinex模型的雾天图像增强方法[J]. 中国矿业大学学报, 2018, 47(6): 1386–1394. doi: 10.13247/j.cnki.jcumt.000950 GU Zhenfei, ZHANG Dengyin. A hazy image enhancement method based on the variational Retinex model[J]. Journal of China University of Mining & Technology, 2018, 47(6): 1386–1394. doi: 10.13247/j.cnki.jcumt.000950 [26] WANG Wei, HE Chuanjiang. A variational model with barrier functionals for retinex[J]. SIAM journal on imaging sciences, 2015, 8(3): 1955–1980. doi: 10.1137/15M1006908 [27] SWINEHART D F. The beer-lambert law[J]. Journal of chemical education, 1962, 39(7): 333. doi: 10.1021/ed039p333 [28] HE Kaiming, SUN Jian, TANG Xiaoou. Single image haze removal using dark channel prior[J]. IEEE transactions on pattern analysis and machine intelligence, 2011, 33(12): 2341–2353. doi: 10.1109/TPAMI.2010.168 [29] 黄富瑜, 李刚, 邹昌帆, 等. 暗原色先验自适应图像去雾方法[J]. 光电子·激光, 2019, 30(12): 1323–1330. doi: 10.16136/j.joel.2019.12.0271 HUANG Fuyu, LI Gang, ZOU Changfan, et al. Adaptive image dehazing based on dark channel prior[J]. Journal of optoelectronics·laser, 2019, 30(12): 1323–1330. doi: 10.16136/j.joel.2019.12.0271 [30] 黄鹤, 李昕芮, 宋京, 等. 多尺度窗口的自适应透射率修复交通图像去雾方法[J]. 中国光学, 2019, 12(6): 1311–1320. doi: 10.3788/co.20191206.1311 HUANG He, LI Xinrui, SONG Jing, et al. A traffic image dehaze method based on adaptive transmittance estimation with multi-scale window[J]. Chinese optics, 2019, 12(6): 1311–1320. doi: 10.3788/co.20191206.1311 [31] 杨燕, 王志伟. 基于补偿透射率和自适应雾浓度系数的图像复原算法[J]. 通信学报, 2020, 41(1): 66–75. doi: 10.11959/j.issn.1000-436x.2020009 YANG Yan, WANG Zhiwei. Image restoration algorithm based on compensated transmission and adaptive haze concentration coefficient[J]. Journal on communications, 2020, 41(1): 66–75. doi: 10.11959/j.issn.1000-436x.2020009 [32] ZHU Qingsong, MAI Jiaming, SHAO Ling. A fast single image haze removal algorithm using color attenuation prior[J]. IEEE transactions on image processing, 2015, 24(11): 3522–3533. doi: 10.1109/TIP.2015.2446191 [33] 赵小强, 宋昭漾. 多级跳线连接的深度残差网络超分辨率重建[J]. 电子与信息学报, 2019, 41(10): 2501–2508. doi: 10.11999/JEIT190036 ZHAO Xiaoqiang, SONG Zhaoyang. Super-resolution reconstruction of deep residual network with multi-level skip connections[J]. Journal of electronics & information technology, 2019, 41(10): 2501–2508. doi: 10.11999/JEIT190036 [34] KAWULOK M, BENECKI P, PIECHACZEK S, et al. Deep learning for multiple-image super-resolution[J]. IEEE geoscience and remote sensing letters, 2020, 17(6): 1062–1066. doi: 10.1109/LGRS.2019.2940483 [35] MAEDA S. Unpaired image super-resolution using pseudo-supervision[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 288−297. [36] LIU Hongyu, JIANG Bin, XIAO Yi, et al. Coherent semantic attention for image inpainting[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 4169−4178. [37] REN Wenqi, LIU Si, ZHANG Hua, et al. Single image dehazing via multi-scale convolutional neural networks[M]//Computer Vision-ECCV 2016. Cham: Springer International Publishing, 2016: 154−169. [38] LI Boyi, PENG Xiulian, WANG Zhangyang, et al. AOD-net: all-in-one dehazing network[C]//2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 4780−4788. [39] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 [40] AMODIO M, ASSOUEL R, SCHMIDT V, et al. Image-to-image Mapping with Many Domains by Sparse Attribute Transfer[EB/OL].(2020−01−23)[2021−09−12].https://arxiv.org/abs/2006.13291. [41] 张惊雷, 厚雅伟. 基于改进循环生成式对抗网络的图像风格迁移[J]. 电子与信息学报, 2020, 42(5): 1216–1222. doi: 10.11999/JEIT190407 ZHANG Jinglei, HOU Yawei. Image-to-image translation based on improved cycle-consistent generative adversarial network[J]. Journal of electronics & information technology, 2020, 42(5): 1216–1222. doi: 10.11999/JEIT190407 [42] PATHAK D, KRÄHENBÜHL P, DONAHUE J, et al. Context encoders: feature learning by inpainting[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2536−2544. [43] ZHAO Lei, MO Qihang, LIN Sihuan, et al. UCTGAN: diverse image inpainting based on unsupervised cross-space translation[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 5740−5749. [44] LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[EB/OL].(2016−09−15)[2021−09−12].https://arxiv.org/abs/1609.04802v1. [45] HYUN S, HEO J P. VarSR: variational super-resolution network for very low resolution images[C]//European Conference on Computer Vision. Cham: Springer, 2020: 431−447. [46] ZHU H, PENG X, CHANDRASEKHAR V, et al. DehazeGAN: when image dehazing meets differential programming[C]// Twenty-Seventh International Joint Conference on Artificial Intelligence IJCAI-18. Stockholm: International Joint Conferences on Artificial Intelligence, 2018:1234−1240. [47] ZHANG He, PATEL V M. Densely connected pyramid dehazing network[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 3194−3203. [48] DAS S D, DUTTA S. Fast deep multi-patch hierarchical network for nonhomogeneous image dehazing[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: IEEE, 2020: 1994−2001. [49] ZHANG Hongguang, DAI Yuchao, LI Hongdong, et al. Deep stacked hierarchical multi-patch network for image deblurring[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 5971−5979. [50] WANG Keping, YANG Yi, LI Bingfeng, et al. Uneven image dehazing by heterogeneous twin network[J]. IEEE access, 2020, 8: 118485–118496. [51] LI Runde, PAN Jinshan, LI Zechao, et al. Single image dehazing via conditional generative adversarial network[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 8202−8211. [52] ENGIN D, GENC A, EKENEL H K. Cycle-dehaze: enhanced CycleGAN for single image dehazing[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City: IEEE, 2018: 938−9388. [53] ZHU Junyan, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2242−2251. [54] BHARATH RAJ N, VENKETESWARAN N. Single image haze removal using a generative adversarial network[C]//2020 International Conference on Wireless Communications Signal Processing and Networking. Chennai: IEEE, 2020: 37−42. [55] JÉGOU S, DROZDZAL M, VAZQUEZ D, et al. The one hundred layers tiramisu: fully convolutional DenseNets for semantic segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu: IEEE, 2017: 1175−1183. [56] XU K, BA J, KIROS R, et. al. Show, attend and tell: Neural image caption generation with visual attention[EB/OL].(2015−02−10)[2021−09−12].https://arxiv.org/abs/1502.03044. [57] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all You need[EB/OL].(2017−06−12)[2021−09−12].https://arxiv.org/abs/1706.03762. [58] WANG Xiaolong, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7794−7803. [59] ZHANG Yulun, LI Kunpeng, LI Kai, et al. Image super-resolution using very deep residual channel attention networks[C]//European Conference on Computer Vision. Cham: Springer, 2018: 294−310. [60] QIN Xu, WANG Zhilin, BAI Yuanchao, et al. FFA-net: feature fusion attention network for single image dehazing[J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(7): 11908–11915. doi: 10.1609/aaai.v34i07.6865 [61] ANVARI Z, ATHITSOS V. Dehaze-GLCGAN: unpaired single image de-hazing via adversarial training[EB/OL].(2020−08−15)[2021−09−12].https://arxiv.org/abs/2008.06632. [62] SCHARSTEIN D, HIRSCHMÜLLER H, KITAJIMA Y, et al. High-resolution stereo datasets with subpixel-accurate ground truth[M]//Lecture Notes in Computer Science. Cham: Springer International Publishing, 2014: 31−42. [63] ANCUTI C O, ANCUTI C, SBERT M, et al. Dense-haze: a benchmark for image dehazing with dense-haze and haze-free images[C]//2019 IEEE International Conference on Image Processing. Taipei: IEEE, 2019: 1014−1018. [64] BERMAN D, TREIBITZ T, AVIDAN S. Non-local image dehazing[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1674−1682. [65] GALDRAN A, BRIA A, ALVAREZ-GILA A, et al. On the duality between retinex and image dehazing[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 8212−8221. [66] ZHANG He, SINDAGI V, PATEL V M. Multi-scale single image dehazing using perceptual pyramid deep network[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City: IEEE, 2018: 1015−101509. [67] LIU Xiaohong, MA Yongrui, SHI Zhihao, et al. GridDehazeNet: attention-based multi-scale network for image dehazing[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 7313−7322. [68] ANCUTI C, ANCUTI C O, DE VLEESCHOUWER C, et al. Day and night-time dehazing by local airlight estimation[J]. IEEE transactions on image processing:a publication of the IEEE Signal Processing Society, 2020, 29: 6264–6275.