
High-precision real-time detection algorithm for foreign object debris on complex airport pavements
-
摘要: 机场道面外来物(foreign object debris, FOD)具有类型多样、形状各异、背景复杂、目标弱小等特点,并且严重影响飞行器安全,故其高精度实时检测具有重要意义。针对以上问题,提出基于超分辨率特征金字塔并带有纹理信息提取模块的FOD实时检测网络(FOD real-time detection network, FOD-RDN)。该网络采用Darknet-53作为主干网提取特征,通过超分辨率特征金字塔对形状各异的小目标进行检测,并设计了纹理信息提取模块降低复杂背景的干扰。同时采用双通道YOLO检测器和基于CIoU的损失函数,进一步提升网络对FOD的检测精度和速度。实验结果表明,本文算法在满足实时性要求的情况下,在FOD数据集上整体检测精度达到了91.8%,相比于主流目标检测网络在FOD目标检测方面具有更好的检测效果。Abstract: Foreign object debris (FOD) on the airport pavement has the characteristics of diverse types, different shapes, complex backgrounds, and weak targets, which seriously affect safety of aircrafts. Therefore, high-precision real-time detection of FOD on the airport pavement is of great significance. To solve the above problems, we propose a FOD real-time detection network (FOD-RDN) based on super-resolution feature pyramid with texture information extraction module. The network uses Darknet-53 as the backbone network to extract features, and detects small targets with different shapes through super-resolution feature pyramid. Then the texture information extraction module is designed to reduce the interference of complex background. At the same time, a dual-channel YOLO detector and a CIoU-based loss function are used to further improve the accuracy and speed of the network detecting FOD. The experimental results show that the algorithm in this paper can achieve an overall detection accuracy of 91.8% on the FOD dataset under the condition of meeting the real-time requirements, which is better than the mainstream object detection network in terms of FOD detection.
-
机场跑道外来异物(foreign object debris, FOD)指的是任何不属于机场道面,却因各种原因被遗留在机场运行区域的外来物体[1],典型的有金属器件、机械工具、碎石块、杂物等。FOD会对航空器的安全造成巨大危害,许多航空事故都是由于跑道异物引起的。因此,为了保证航空器的安全起降,有必要对FOD进行及时准确的检测并清理。但是FOD存在不确定度高、目标较小、难以检测的问题,因此FOD的高精度检测具有重要的研究价值。
目前很多大型机场已经部署了自动化FOD检测系统。主要包括:以色列的FODetect系统,该系统由120套子探测器覆盖整个机场跑道,可有效地避免跑道边灯对探测系统的影响;新加坡的iFerret智能检测系统,该系统使用了星光级摄像设备,可以全天候对机场跑道进行高精度拍摄;英国的Tarsier Radar系统,使用了毫米波雷达与可见光及红外灯光学摄像设备,可有效地对FOD进行检测[2];中国民航局第二研究所自主研发生产的FOD探测系统[3],可利用塔架式和边灯式光电系统进行复合探测。但是以上这些系统造价昂贵,中小机场难以负担。因此目前中小机场大多采用人工巡检车的方式进行FOD检测,在机坪上通过肉眼来巡检跑道是否存在FOD,这种检测方式具有主观性强、检测效率低、易漏检等缺点。因此,研究基于图像的移动式的FOD自动检测方法具有重要的应用价值。
机场道面FOD的检测,本质是在复杂道面背景下的小目标检测问题。目前的检测算法主要分为基于传统图像处理的算法和基于深度学习的算法两种。传统算法方面,刘天畅等[4]提出采用图像分割和水雾模型法对试飞跑道上的FOD进行识别,Liang等[5]提出利用Gabor滤波器对机场跑道图像的纹理进行分析并通过仿真实验证明该算法的有效性和实用性,张怡等[6]提出了基于差分GPS定位的图像差分异物检测方法检测道面FOD。这些基于传统算法的FOD检测方法主要采用大量的先验知识和技巧来设计有效的特征提取器,一旦外部条件、异物类型出现变化,这些算法就会失去效果。
随着深度学习的发展,基于卷积神经网络的算法被广泛应用到目标检测中。深度学习可以通过数据来自动学习目标的特征,相对于传统会有更好的检测效果,能够适应多样化的背景和目标类型。Xu等[7]提出了一种基于转移学习和主流深度卷积神经网络(D-CNN)模型的FOD识别方法。鞠默然等[8]提出了一种YOLO-V3的改进方法对多尺度特征图进行拼接融合获取更多的小目标特征信息。吴天舒等[9]在SSD算法中引入转置卷积结构,增加低层特征提取能力,提高算法的检测精度。但是上述方法中,较高的检测精度的算法速度较慢,无法满足实时性要求,而可以达到实时性要求的单阶段的检测网络,由于对浅层特征提取不够充分,在机场复杂背景下对FOD小目标的检测精度较差。
针对以上问题,提出一种FOD高精度实时检测网络FOD-RDN,可以实时地对机场复杂道面上存在的FOD进行有效检测。本文主要方向是对多尺度特征金字塔在小目标检测方向上的优化和增强。首先,提出了超分辨率特征金字塔(super-resolution feature pyramid network, SFPN),增强对小目标特征的提取能力;然后提出了名为纹理信息提取模块(texture information extraction module, TIEM),降低复杂背景对于小目标检测的干扰;最后,通过双通道YOLO检测器和基于CIoU的损失函数,进一步提升精度和速度。
1. 机场复杂道面FOD检测算法
本文提出的FOD-RDN网络由3部分构成,包括主干特征提取网络、带有纹理特征提取模块的超分辨率特征金字塔和双通道YOLO[10]检测器。图1所示为网络流程图,在获取图像后,送入主干网络提取特征,主干网络由Darknet-53[11]实现;接着将Darknet-53部分深层特征送入超分辨率特征金字塔,并且通过纹理特征提取模块降低复杂背景干扰,进一步提取小目标有效特征,超分辨率特征金字塔由多尺度金字塔和基于亚像素卷积的图像超分辨率上采样模块构成;最后送入双通道YOLO检测器,这部分由中尺度检测器和小尺度检测器组成,并输出FOD的检测结果。
 图 1 网络流程图Fig. 1 Network flow chart
图 1 网络流程图Fig. 1 Network flow chart 下载:
全尺寸图片
下载:
全尺寸图片
完整网络结构如图2所示,输入图像的分辨率为640×640,主干网络采用Darknet-53提取特征,Darknet-53包含52个卷积层,去掉了最后的全连接层,大量使用残差结构,可以有效提取目标的深层次特征并避免深层网络的退化问题[12];然后输入带有纹理特征提取能力的超分辨率特征金字塔,通过多个尺度融合与基于亚像素卷积的图像超分辨率(super resolution, SR)模块获得目标更可信的浅层特征,并在小尺度特征提取部分加入纹理特征提取模块,进一步提取小目标的浅层纹理信息;最后将融合后的特征输入双通道YOLO检测器,进行类别预测和边界框回归,获得最终的FOD检测结果,下面对每个模块进行具体说明。
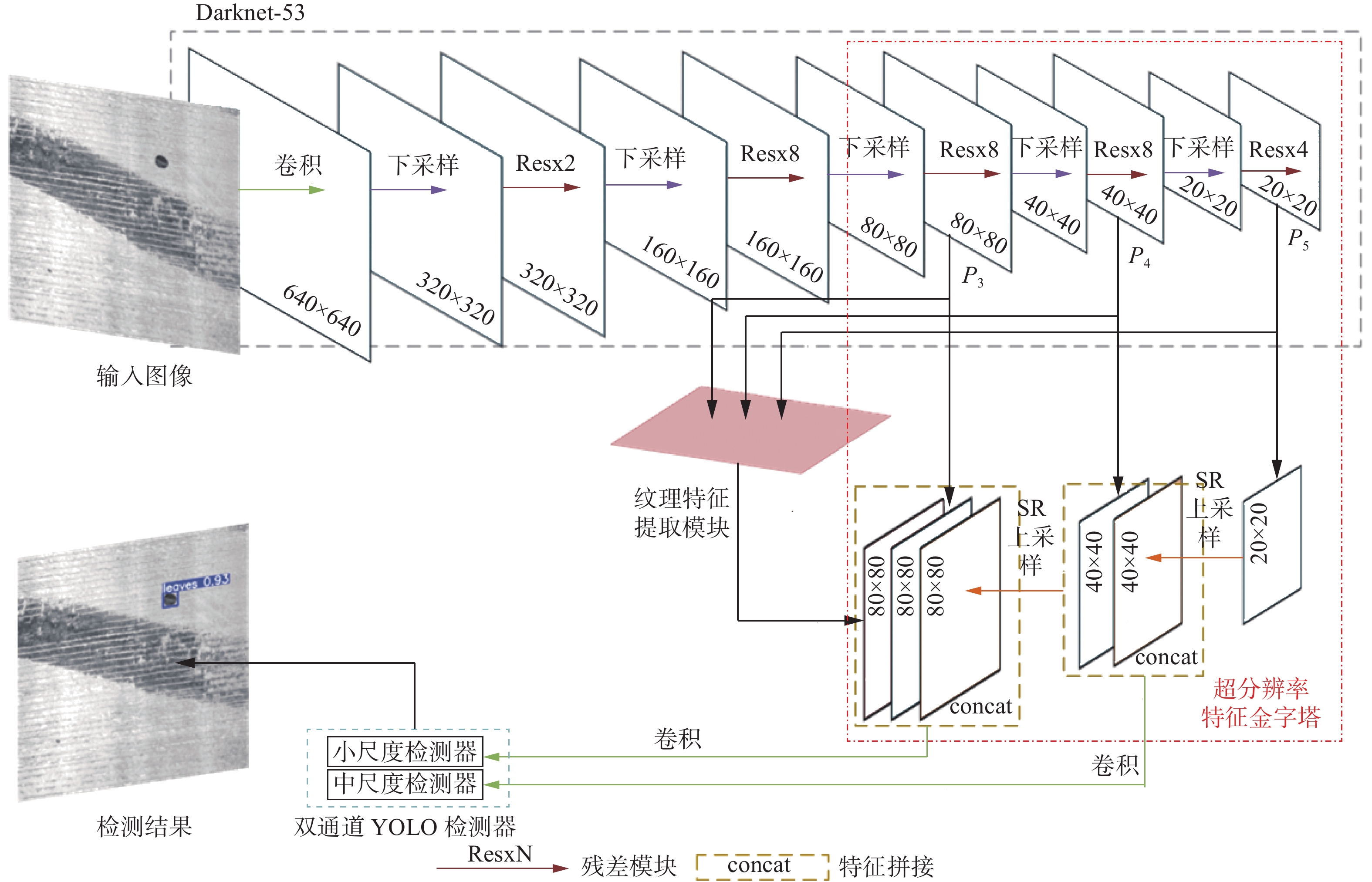 图 2 FOD-RDN 网络结构Fig. 2 FOD-RDN network structure下载:
全尺寸图片
图 2 FOD-RDN 网络结构Fig. 2 FOD-RDN network structure下载:
全尺寸图片
1.1 超分辨率特征金字塔
为有效检测机场道面小目标,可以通过特征金字塔[13](feature pyramid network, FPN)模块提取融合更多小目标的特征。FPN是通过融合不同层次的特征并构造特征金字塔来增强目标的有效特征,网络深层特征图映射了较大的目标,浅层特征映射较小的目标,并且融合深层和浅层特征[14]。
但融合时,深层特征需要提高分辨率才能与浅层特征正常融合,FPN中通过双线性插值的方法进行对深层特征进行上采样提高了2倍分辨率,这会使低层特征图的细节丢失[15],从而在高层特征处引入很多的噪声信息,最终会损害小目标的有效信息。因此,为了获得机场道面上FOD的有效信息,本文提出了超分辨率特征金字塔,如图3所示。在SFPN中,高分辨率特征图的生成取决于网络提取到的原始真实特征,提高模型对小目标的性能检测。SR模块[16]使用多通道的深度特征,通过压缩通道数量提高特征图像的分辨率,可以有效避免上采样过程中补零方式带来的噪声。因此,在多个尺度融合阶段,使用SR模块替换通常使用的上采样,可以在提高特征图像分辨率的同时避免加入无用噪声。
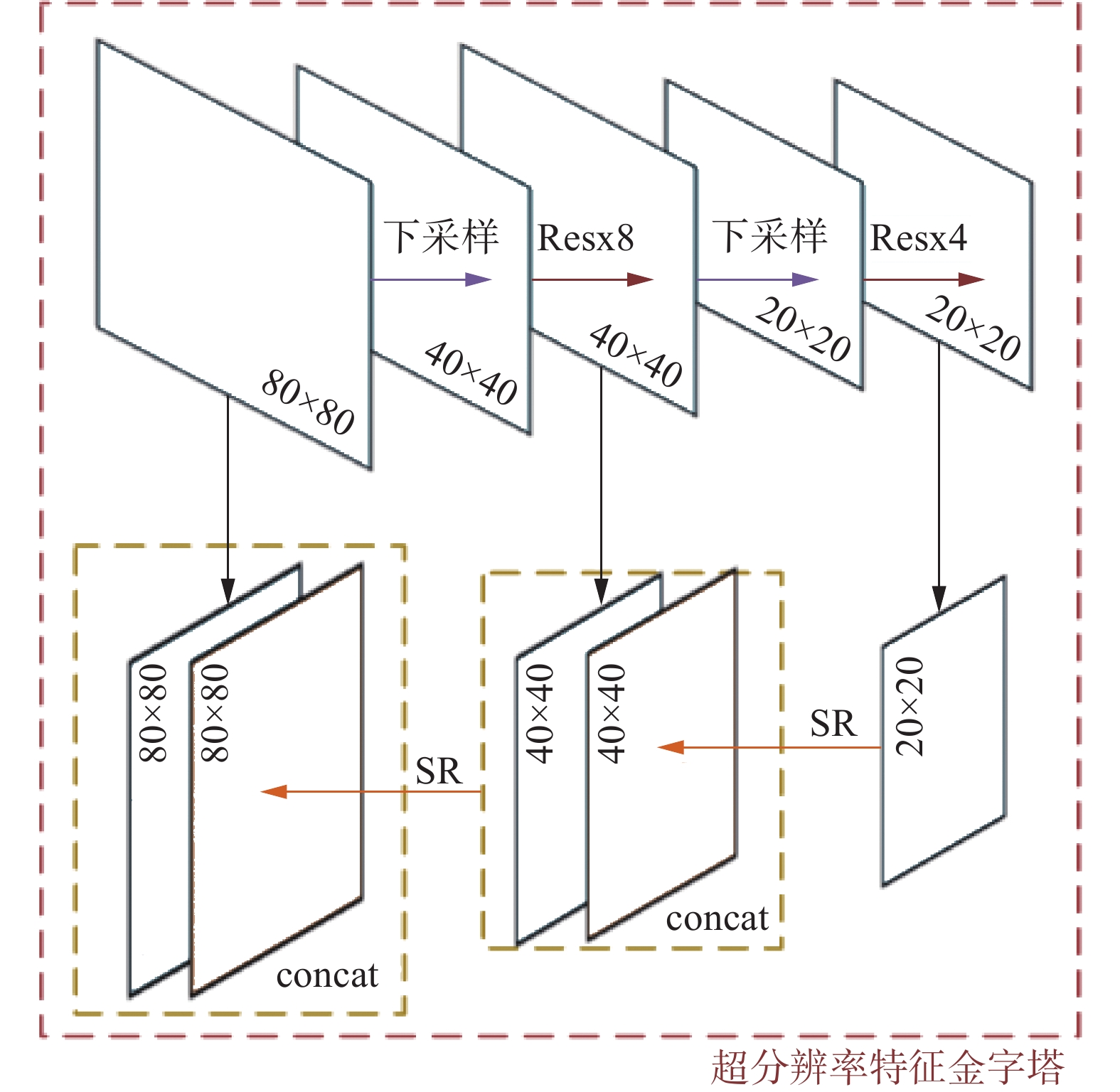 图 3 超分辨率特征金字塔Fig. 3 Super-resolution feature pyramid net下载:
全尺寸图片
图 3 超分辨率特征金字塔Fig. 3 Super-resolution feature pyramid net下载:
全尺寸图片
图3所示为超分辨率特征金字塔结构,设
$ {P}_{i} $ 为自下而上的超分辨率特征金字塔的第i级输出,经过$ 1\times 1 $ 的卷积压缩通道后,与经过SR上采用的特征图融合,从而获得还原度更高的纹理信息。SFPN的输入和输出的关系可分别表示为$$ {F}_{i}={\mathrm{c}\mathrm{o}\mathrm{n}\mathrm{c}\mathrm{a}\mathrm{t}}_{}(\mathrm{S}\mathrm{R}\left({F}_{i}\right),{P}_{i})$$ $$ {P}_{i}={\mathrm{c}\mathrm{o}\mathrm{n}\mathrm{v}}_{1\times 1}\left({P}_{i-1}\right)$$ 式中:
$ \mathrm{S}\mathrm{R}\left({F}_{i}\right) $ 为SFPN使用的基于亚像素卷积的图像超分辨率上采样;$ {\mathrm{c}\mathrm{o}\mathrm{n}\mathrm{c}\mathrm{a}\mathrm{t}}_{} $ 表示多个特征图融合;$ {\mathrm{c}\mathrm{o}\mathrm{n}\mathrm{v}}_{1\times 1} $ 表示$ 1\times 1 $ 的卷积。1.2 纹理信息提取模块
机场道面复杂多变,并有很多的油污水渍对目标检测造成干扰[17]。为了减少复杂背景的干扰,提取FOD的有效信息,本文提出了纹理信息提取模块TIEM。该模块将图像超分辨率模块作为关键参考要素,上采样时得到更加真实可信的浅层特征[18],并结合来自高层的深度语义信息和低层的区域纹理信息,最终降低复杂背景干扰并突出小目标的纹理特征。
模块的具体设计如图4所示:对特征层
$ {P}_{5} $ 通过残差模块[19]提取内容信息,通过亚像素卷积提高分辨率。再与特征$ {P}_{4} $ 和融合,采用残差结构提取纹理特征。接着,再次经过SR模块提高分辨率并与特征$ {P}_{3} $ 融合。由于特征$ {P}_{3} $ 包含深层特征和跨层连接的浅层特征,含有很多没有经过卷积层处理的噪声,需要通过残差模块提取有效纹理信息并过滤背景噪声干扰,用于后续网络的小目标检测。公式为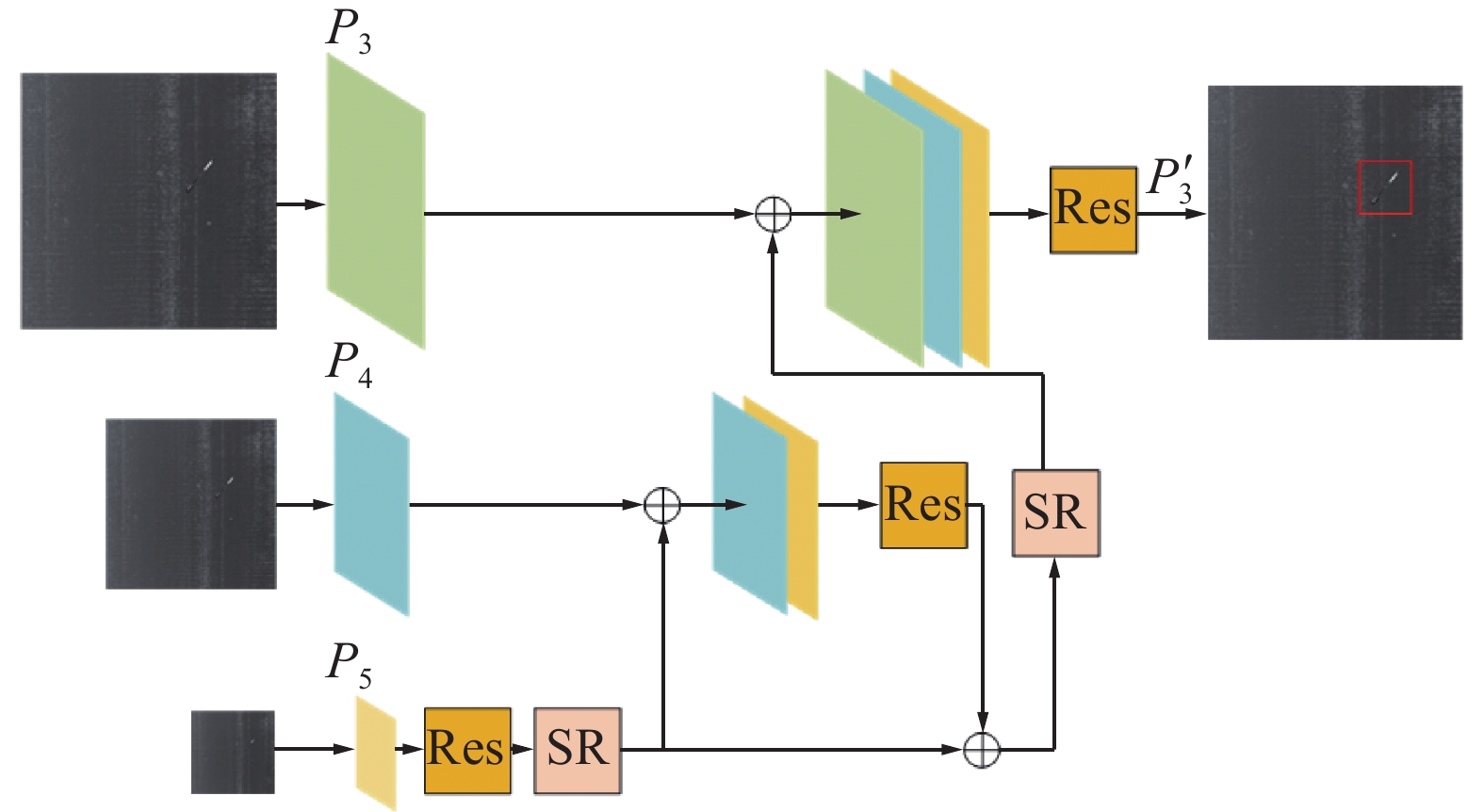 图 4 纹理信息提取模块Fig. 4 Texture information extraction module下载:
全尺寸图片
图 4 纹理信息提取模块Fig. 4 Texture information extraction module下载:
全尺寸图片
$$ {P}_{3}'={R}_{t}\left({P}_{3}\right|\left|\right({R}_{t}\left({P}_{4}\right|\left|{R}_{3}\right({P}_{5})\uparrow 2\times )+{R}_{c}\left({P}_{4}\right)\uparrow 2\times \left)\right) $$ 式中:
$ {R}_{t} $ 表示残差结构提取纹理特征,$ {R}_{c} $ 表示残差结构提取上下文信息,$ \uparrow 2\times $ 表示通过基于亚像素卷积的图像超分辨率上采样模块提升2倍分辨率,$ \left|\right| $ 表示特征拼接。如图5所示,为机场道面FOD检测,加入纹理信息提取模块前后的热力图对比效果,分别为原图、单纯SFPN和带有TIEM的SFPN结构。热力图[20]可以直观地展示出对最终的检测结果影响最大的部分,并且通过红、蓝、绿依次表示影响度由高到低。由图5可见,加入TIEM模块后,FOD小目标的特征变得更加明显。
 图 5 FOD在加入纹理信息提取模块前后热力图对比Fig. 5 Comparison of heat map of FOD before and after adding texture information extraction module下载:
全尺寸图片
图 5 FOD在加入纹理信息提取模块前后热力图对比Fig. 5 Comparison of heat map of FOD before and after adding texture information extraction module下载:
全尺寸图片
1.3 双通道YOLO检测器
在超分辨率特征金字塔中,输出特征图的特征层越高,提取的语义信息等级越高。特征层由低到高,分辨率逐渐减小,感受野逐渐增大[21]。本文算法的金字塔输出特征层分别经过了4、16、32倍下采样,其感受野逐渐提高。机场FOD数据集中采集到的图像的分辨率为640像素×640像素,对应着特征层的分辨率为80像素×80像素、40像素×40像素、20像素×20像素,分别是小尺度、中尺度和大尺度的目标。YOLO算法使用了3通道检测器,其中大尺度检测器负责检测32倍下采样的20×20像素的特征图,但是在FOD数据集中,FOD小目标长或宽最小长度所占像素在7~40个,经过32倍下采样,一些较小的FOD目标的长或宽已经无法用一个像素表示。这时检测器根本无法寻找到有效目标,却会产生无效的检测结果,这些结果会降低后续非极大值抑制[22](non max suppression, NMS)阶段边界框回归的效率和精度。因此本文取消在32倍下采样特征层的YOLO检测器,仅在16和4倍下采样特征层进行检测。这样的优点:第1可以减少NMS的运算量,提高速度;第2保证了检测器寻找的FOD小目标可以用1个以上的像素表示,使寻找到的FOD小目标更加精准。本文使用K-means[23]算法对数据集的锚定框重新聚类,聚类结果如表1所示。
表 1 K-means重聚类锚定框大小Table 1 K-means re-clustering anchor box size特征图 锚定框大小 中尺度 (4,4);(5,4);(5,7) 小尺度 (2,2);(3,2);(4,3) 1.4 损失函数
YOLO-v3将输入模型的图像划分为n×n的网格,并通过每个小网格进行物体预测,并且只有预测框和标注框的重合度高于设定阈值时,才会取1,因此有效地判定预测框和标注框的重合度对损失函数的梯度优化极为重要。YOLO-v3 采用交并比(intersection over union, IoU)
$ {I}_{\mathrm{I}\mathrm{o}\mathrm{U}} $ 判定预测框和标注框的重合度,IoU是指目标预测边界框和真实边界框的交集和并集的比值,公式为$$ {I}_{\mathrm{I}\mathrm{o}\mathrm{U}}=\frac{A\cap B}{A\cup B} $$ 式中:A代表预测边界框,B代表标注边界框。机场道面FOD多为小目标,然而IoU在小目标检测方面会有2个问题。1)由于FOD目标较小,在初始训练阶段模型产生的预测框与真实标签会有较大的偏离导致重合度较低、IoU接近0。意味着即便2个框的距离很近,通过IoU也无法有效反馈,这样会使损失函数无法优化。2)FOD具有大小、方向随机性的特点,但是通过
$ \mathrm{I}\mathrm{o}\mathrm{U} $ 无法体现出不同方向;并且当预测框和真实标签的交并比数值相同就被判定为完全一样,无法反映预测框和标签框的相交状态。如图6所示,为预测框与真实标签很接近却不重合的情况。其中黄色框为预测框,绿色框为真实标签,d表示两个框中心点的距离,c表示两个框最小闭包区域的对角线距离。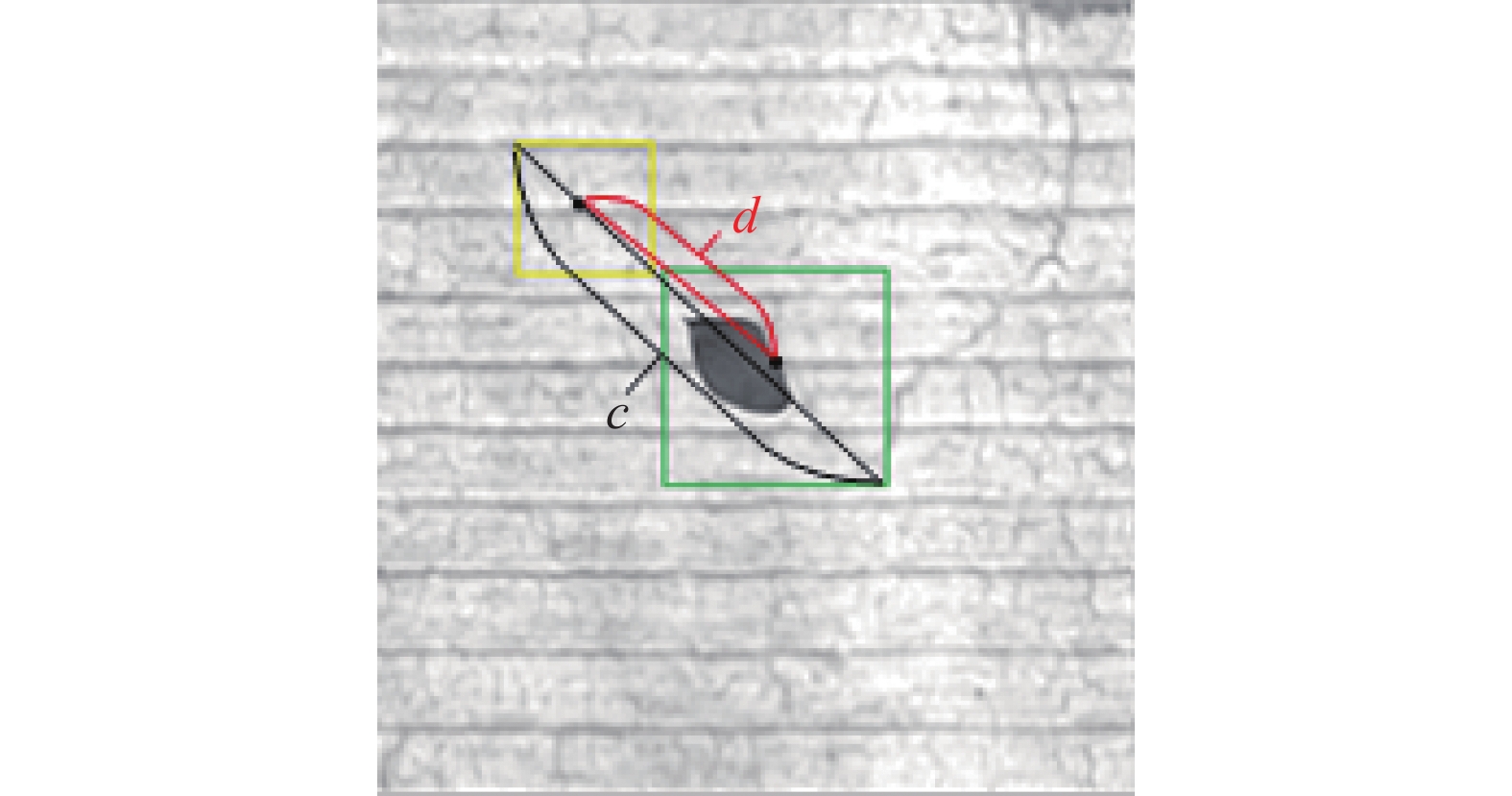 图 6 预测框与真实标注框Fig. 6 Prediction box and real annotation box下载:
全尺寸图片
图 6 预测框与真实标注框Fig. 6 Prediction box and real annotation box下载:
全尺寸图片
针对以上问题,本文采用CIoU函数进行优化YOLO-v3的损失函数。CIoU采用的是预测框和真实框的中心点的欧氏距离与包含预测框和真实框的最小闭包区域的对角线距离的平方之比来衡量中心点的误差[24]。在采用CIoU后,当FOD的预测框与真实框不重叠时,网络仍然得到预测框的移动方向和接近程度。CIoU的公式为
$$ {I}_{\mathrm{C}\mathrm{I}\mathrm{o}\mathrm{U}}=1-{I}_{\mathrm{I}\mathrm{o}\mathrm{U}}+\frac{{\rho }^{2}(b,{b}^{{\rm{gt}}})}{{c}^{2}}+\alpha v $$ $$ \alpha =\frac{v}{1-{I}_{\mathrm{I}\mathrm{o}\mathrm{U}}+v},v=\frac{4}{\text{π }}{\left(\mathrm{a}\mathrm{r}\mathrm{c}\mathrm{t}\mathrm{a}\mathrm{n}\frac{{w}^{\mathrm{g}\mathrm{t}}}{{h}^{\mathrm{g}\mathrm{t}}}-\mathrm{a}\mathrm{r}\mathrm{c}\mathrm{t}\mathrm{a}\mathrm{n}\frac{w}{h}\right)}^{2} $$ 式中:
$ \left(b,{b}^{\mathrm{g}\mathrm{t}}\right) $ 分别代表了预测框和真实框的中心点;$ {\rho }^{2}\left(b,{b}^{\mathrm{g}\mathrm{t}}\right) $ 为预测框和真实框的中心点的欧氏距离;$ c $ 是能够同时包含预测框和真实框的最小闭包区域的对角线距离;$ {w}^{\mathrm{g}\mathrm{t}} $ 和$ {h}^{\mathrm{g}\mathrm{t}} $ 是真实框的宽和长;$\mathrm{a}\mathrm{r}\mathrm{c}\mathrm{t}\mathrm{a}\mathrm{n}\dfrac{w}{h}$ 用于计算长宽比,v表示了预测框和真实框长宽比的相似性。优化后的损失函数L由坐标回归损失函数$ {L}_{\mathrm{b}\mathrm{o}\mathrm{x}} $ 、置信度损失函数$ {L}_{\mathrm{c}\mathrm{o}\mathrm{n}\mathrm{f}} $ 和分类损失函数$ {L}_{\mathrm{c}\mathrm{l}\mathrm{s}} $ 组成。前项计算因子$ {\lambda }_{\mathrm{C}\mathrm{I}\mathrm{o}\mathrm{U}-\mathrm{n}\mathrm{o}\mathrm{o}\mathrm{b}\mathrm{j}} $ 和$ {I}_{ij}^{\mathrm{C}\mathrm{I}\mathrm{o}\mathrm{U}-\mathrm{o}\mathrm{b}\mathrm{j}} $ 会对预测框和标注框的移动方向和接近程度更好地判定,公式为$$ L = {L_{{\text{box}}}} + {L_{{\text{conf}}}} + {L_{{\text{cls}}}} $$ $$ \begin{gathered} {L_{{\rm{box}}}} = {\lambda _{{\rm{CIoU - coord}}}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {I_{ij}^{{\rm{CIoU - obj}}}} } (2 - {w_i} \times {h_i})[{({x_i} - \hat {{x_i}})^2} +\\ {({y_i} - \hat {{y_i}})^2}] + {\lambda _{{\rm{CIoU - coord}}}}\sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {I_{ij}^{{\rm{CIoU - obj}}}} } (2 - {w_i} \times {h_i})\cdot\\ [{({w_i} - \hat {{w_i}})^2} + {({h_i} - \hat {{h_i}})^2}] \\ \end{gathered}$$ $$ \begin{gathered} {L_{{\rm{conf}}}} = - \sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {I_{ij}^{{\rm{CIoU - obj}}}} } [\hat {{C_i}}{\log _2}({C_i}) + \\ (1 - \hat {{C_i}}){\log _2}(1 - \hat {{C_i}})] - {\lambda _{{\rm{CIoU - noobj}}}} \cdot\\ \sum\limits_{i = 0}^{{S^2}} {\sum\limits_{j = 0}^B {I_{ij}^{{\rm{CIoU - obj}}}} } \left[\hat {{C_i}}{\log _2}({C_i}) + (1 - \hat {{C_i}}){\log _2}(1 - \hat {{C_i}})\right] \\ \end{gathered} $$ $$ \begin{gathered} {L_{{\rm{cls}}}} = - \sum\limits_{i,j = 0}^{{S^2}} {I_{ij}^{{\rm{CIoU - obj}}}} \sum\limits_{c \in {\rm{class}}} {} \left[ {{\hat p}_i^j}{\log _2}(p_i^j) +\right.\\ \left. (1 - {{\hat p}_i^j}){\log _2}(1 - p_i^j)\right] \\ \end{gathered}$$ 式中:
${{(\hat x}}_{i},{\hat{y}}_{i},{\hat{w}}_{i},{\hat{h}}_{i})$ 和$ {(x}_{i},{y}_{i},{w}_{i},{h}_{i}) $ 分别表示预测边界框和标注边界框的中心坐标和长宽;${\hat{C}}_{i}$ 和$ {C}_{i} $ 分别表示预测边界框和标注边界框的置信度;${\hat{p}}_{i}^{j}$ 、$ {p}_{i}^{j} $ 分别表示预测目标边界框和标注目标边界框的类别概率;$ {\mathrm{log}}_{2}\left(p\right) $ 代表交叉熵损失函数。2. 实验与分析
本文利用深度学习框架 Pytorch实现和训练所设计神经网络模型。实验硬件环境是主频为 3.2 GHz的i7-8700 CPU,64 GB内存,11 GB显存的GeForce GTX 2080ti显卡。操作系统为Ubuntu 18.04。
2.1 数据集
在机场FOD检测领域,目前没有公开的图像数据集。为此,本文参考民航行业标准对于FOD的定义规范和FOD判别手册,总结归纳选取21个种类常见物体作为FOD,通过真实机场跑道图像数据构建了实验数据集。
部分图像样例如图7所示,选用FOD包括螺帽、螺钉、金属垫圈、笔、钥匙、U盘、树枝、树叶、石子、螺丝刀头、六角扳手、开口扳手、耳机、铁丝、塑料瓶盖、金属圆环、手机充电插头、拉链、小夹子、螺丝刀、行李箱锁等。最终生成1800张机场道面FOD图像数据,其中如U盘、螺丝刀等,由于形状较为规则,来自标准工业产品,每种50张,而形状不规则的自然物体,如石子、树枝等每种100张,并按照7∶3构建了训练集和测试集。
 图 7 机场复杂道面FOD图像数据集Fig. 7 FOD data set collected from complex airport pavement下载:
全尺寸图片
图 7 机场复杂道面FOD图像数据集Fig. 7 FOD data set collected from complex airport pavement下载:
全尺寸图片
2.2 评价指标
本文使用随机梯度下降对网络参数进行学习,权重衰减系数设置0.0001,学习率为0.001,由于受到实验平台硬件约束,将batch-size设置为16,共训练300个epochs。为了量化检结果,采用
$ {A}_{\mathrm{A}\mathrm{P}} $ (平均精确度)、$ {M}_{\mathrm{m}\mathrm{A}\mathrm{P}} $ (平均精确度的均值)进行性能评估,其中$ {A}_{\mathrm{A}\mathrm{P}} $ 衡量模型在检测每个类别上的表现程度,$ {M}_{\mathrm{m}\mathrm{A}\mathrm{P}} $ 衡量模型在检测所有类别上的表现程度,通过将每个类别对应的$ {A}_{\mathrm{A}\mathrm{P}} $ 值算术平均后得到。这2个值的计算依赖于精确率$ P $ 和召回率$ R $ ,精确率$ P $ 是指在所有预测为正确的目标中,真正正确目标所占的比例;召回率$ R $ 是指在所有真正目标中,被正确检测出来的目标所占的比例。其公式分别为$$ P=\frac{{X}_{\mathrm{T}\mathrm{P}}}{{X}_{\mathrm{T}\mathrm{P}}+{X}_{\mathrm{F}\mathrm{P}}} $$ $$ R=\frac{{X}_{\mathrm{T}\mathrm{P}}}{{X}_{\mathrm{T}\mathrm{P}}+{X}_{\mathrm{F}\mathrm{N}}}$$ $$ {A}_{\mathrm{A}\mathrm{P}}={\int }_{0}^{1}P\left(R\right)\mathrm{d}R $$ $$ {M}_{\mathrm{m}\mathrm{A}\mathrm{P}}=\dfrac{\displaystyle\sum _{i=1}^{k}A_{{{\rm{AP}}}_{i}}}{k}$$ 式中:
$ {X}_{\mathrm{T}\mathrm{P}} $ 表示被正确检出的目标数,$ {X}_{\mathrm{F}\mathrm{P}} $ 表示被错误检出的目标数,$ {X}_{\mathrm{T}\mathrm{N}} $ 表示没有被正确检出的目标数,$ k $ 表示检测中所有类别的个数。2.3 网络检测性能对比
为验证本文算法的有效性,与目前流行算法进行对比。这里采用 Faster R-CNN(FRC)[25]、YOLO-v3、YOLO-v5、SSD[26]作为对比算法。FRC是目前使用最广泛的基于候选区域的双阶段目标检测算法。SSD和YOLO-v3是目前比较经典的单阶段检测算法。YOLO-v5是目前公开的YOLO系列的最新算法。
根据以上网络参数设置,完成了在FOD数据集上的对比实验,测试结果在表2给出。可以看出,本文在整体FOD数据集上,达到了91.8%的检测精度,高于其他经典算法,说明本文算法可以有效检测到机场复杂道面背景下FOD小目标。在速度方面,本文算法的单张处理时间为50 ms,可以满足机场道面FOD检测的实时性要求。
表 2 本文与其他模型数据集检测精度和时间对比Table 2 Comparison of detection accuracy and time between this paper and other model data sets模型 P/% R/% 0.5mAP/% 0.95mAP/% 时间/ms FRC 26.1 84.1 58.6 44.6 900 SSD 73.9 24.7 48.8 38.4 143 YOLO-v3 71.4 85.8 85.8 69.2 49 YOLO-v5 84.7 71.8 77.0 59.1 47 本文算法 80.3 90.3 91.8 74.6 50 表3给出了本文和其他算法在FOD数据集上的各种类别的检测效果,可以看出本文算法在大多数螺丝钉、螺母等尺寸较小的物体上,本文的检测精度均高于其他对比算法。这说明对于尺寸较小的物体本文提出的超分辨率特征金字塔通过亚像素卷积进行上采样,有效避免了原始特征金字塔使用的双线性插值法产生的干扰问题,所得到的特征图尽可能地保留了真实小目标的浅层形状纹理特征和深层语义特征。同时,因为加入了纹理信息特征提取模块,本文网络可以通过基于亚像素卷积的图像超分辨率模块,构建残差类似结构,抑制了机场复杂背景的干扰,生成具有更清晰小目标纹理特征的特征图,并传递给后续的超分辨率特征金字塔使用。再者双通道YOLO检测器通过舍弃干扰较多的大小为80×80的特征图检测器,有效地加快了检测速度。而且文本所使用基于CIoU的损失函数,也在一定程度上提高了检测速度和检测精度。
表 3 本文与其他模型各种类别检测精度对比Table 3 Comparison of detection accuracy of various categories between this paper and other models% 类别 本文 SSD FRC YOLO-v3 YOLO-v5 六角扳手 92.7 50.5 72.9 92.2 77.0 瓶盖 99.1 91.8 72.1 98.9 75.8 树枝 67.5 4.8 56.5 40.7 93.0 续表 3 类别 本文 SSD FRC YOLO-v3 YOLO-v5 圆环 89.7 65.8 61.1 89.6 17.1 夹子 99.6 35.2 71.2 99.4 90.0 刀头 99.7 8.1 40.3 95.7 94.3 耳机 85.3 48.2 48.6 83.2 93.2 垫片 89.2 39.3 23.1 81.3 78.3 钥匙 99.1 34.9 45.8 97.5 63.2 树叶 91.1 55.5 68.3 82.1 88.0 铁丝 65.4 11.9 48.7 64.7 70.5 行李锁 99.7 91.3 94.0 99.8 49.0 螺母 99.8 7.9 11.0 99.5 97.2 钢笔 96.4 86.7 80.1 96.7 92.9 插头 99.7 99.1 99.7 99.5 99.7 螺丝 99.4 22.3 27.9 94.0 76.3 螺丝刀 88.4 67.9 79.4 72.1 76.5 扳手 74.5 50.0 44.9 22.1 10.2 石头 95.2 40.1 36.8 96.4 88.5 U盘 99.1 67.8 73.3 97.1 98.7 拉链 99.5 44.1 69.8 97.9 93.8 2.4 网络检测性能分析
为了验证SFPN和TIEM模块的有效性,进行消融实验。对于SFPN,分别将SFPN和FPN加入到 FOD-RDN中,其他条件不变;对于TIEM,分别在FOD-RDN中去除TIEM和保留TIEM,其他条件不变,实验结果见表4。
表 4 超分辨率特征金字塔和纹理信息特征提取模块的有效性Table 4 Effectiveness of multi-scale super-resolution feature pyramid and texture information feature extraction module模型 P/% R/% 0.5mAP/% 0.95mAP/% 时间/ms FOD-RDN 80.3 90.3 91.8 74.6 50 采用SFPN 75.1 87.9 88.2 71.6 52 去除TIEM 74.2 85.6 87.1 70.2 47 表4中可见,相对于FPN,使用SFPN的检测精度从88.00%上升到88.20%,这说明SFPN有效地提取到了小目标的浅层特征信息,提高模型对FOD小目标的检测能力。对于TIEM,去除TIEM模块的模型检测精度为87.10%,下降了4.6%,这说明本文构造的纹理特征提取模块是可以有效提取到小目标的可靠纹理特征并阻止无用的背景噪声干扰。
为验证本文采用的双通道YOLO检测器的有效性,与三通道YOLO检测器进行对比实验,在训练阶段边框损失函数的回归曲线,从图8中可以看出,双通道YOLO检测器在训练阶段有着更快的收敛速度并经过实验验证,如图8所示,为双通道的16 和 8 倍下采样与原始的32倍、16倍、8倍下采样在训练阶段边框损失函数的回归曲线,双通道检测器在训练阶段有着更快的收敛速度。表5给出了本文采用的双通道的检测器相比三通道检测器有更好的检测精度。
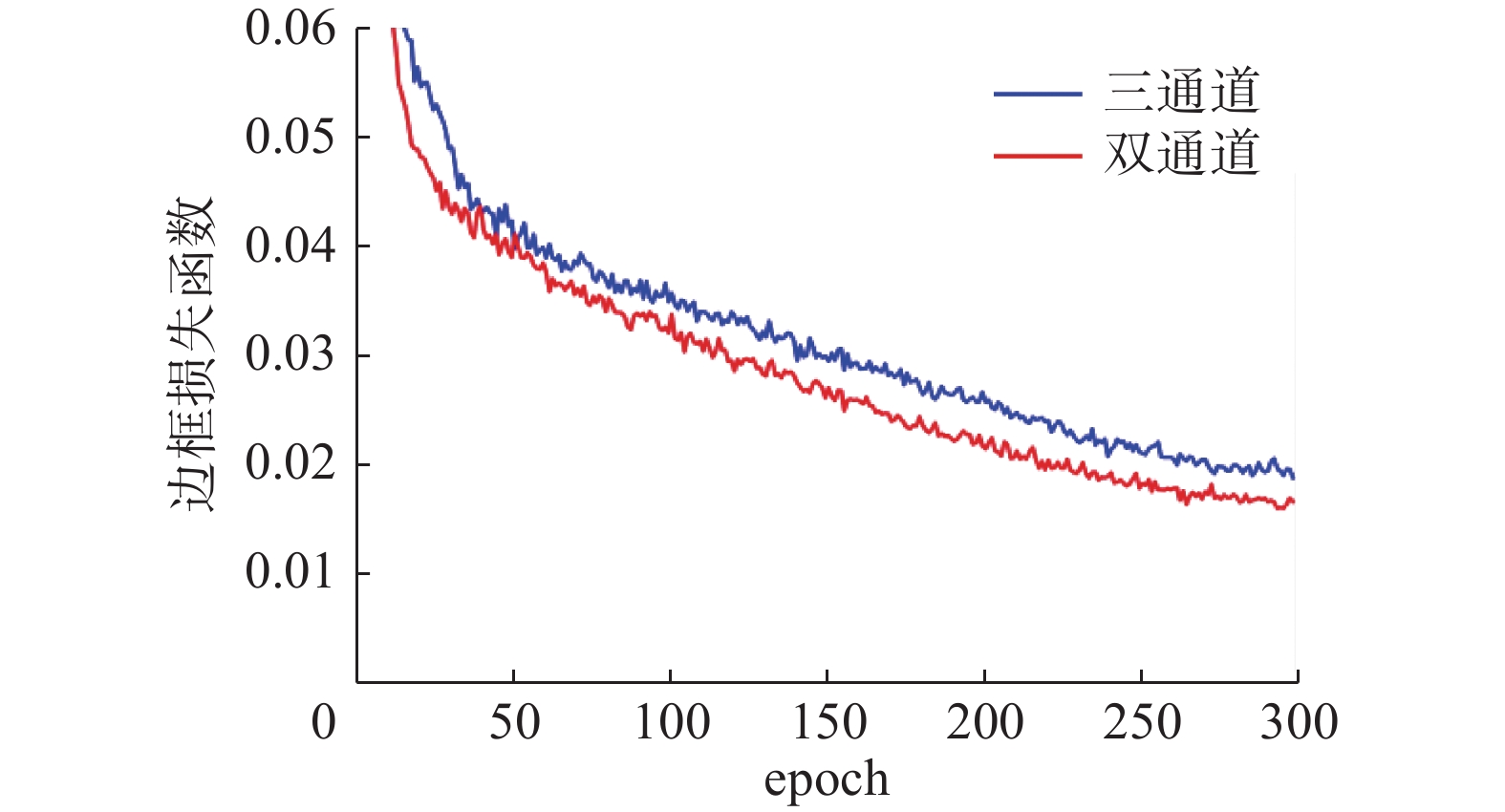 图 8 双通道与三通道边框损失函数回归曲线Fig. 8 Two-channel and three-channel frame loss function regression curves下载:
全尺寸图片
表 5 双通道检测器的有效性Table 5 Effectiveness of the dual-channel detector
图 8 双通道与三通道边框损失函数回归曲线Fig. 8 Two-channel and three-channel frame loss function regression curves下载:
全尺寸图片
表 5 双通道检测器的有效性Table 5 Effectiveness of the dual-channel detector模型 P/% R/% 0.5 mAP /% 0.95 mAP /% 时间/ms 双通道 80.3 90.3 91.8 74.6 50ms 三通道 72.4 86.9 88.2 70.3 53ms 为验证本文采用的CIoU的损失函数有效性,与采用IoU的损失函数进行对比实验。如图9所示,CIoU的红色实线比IoU的蓝色虚线有更高的检测精度。
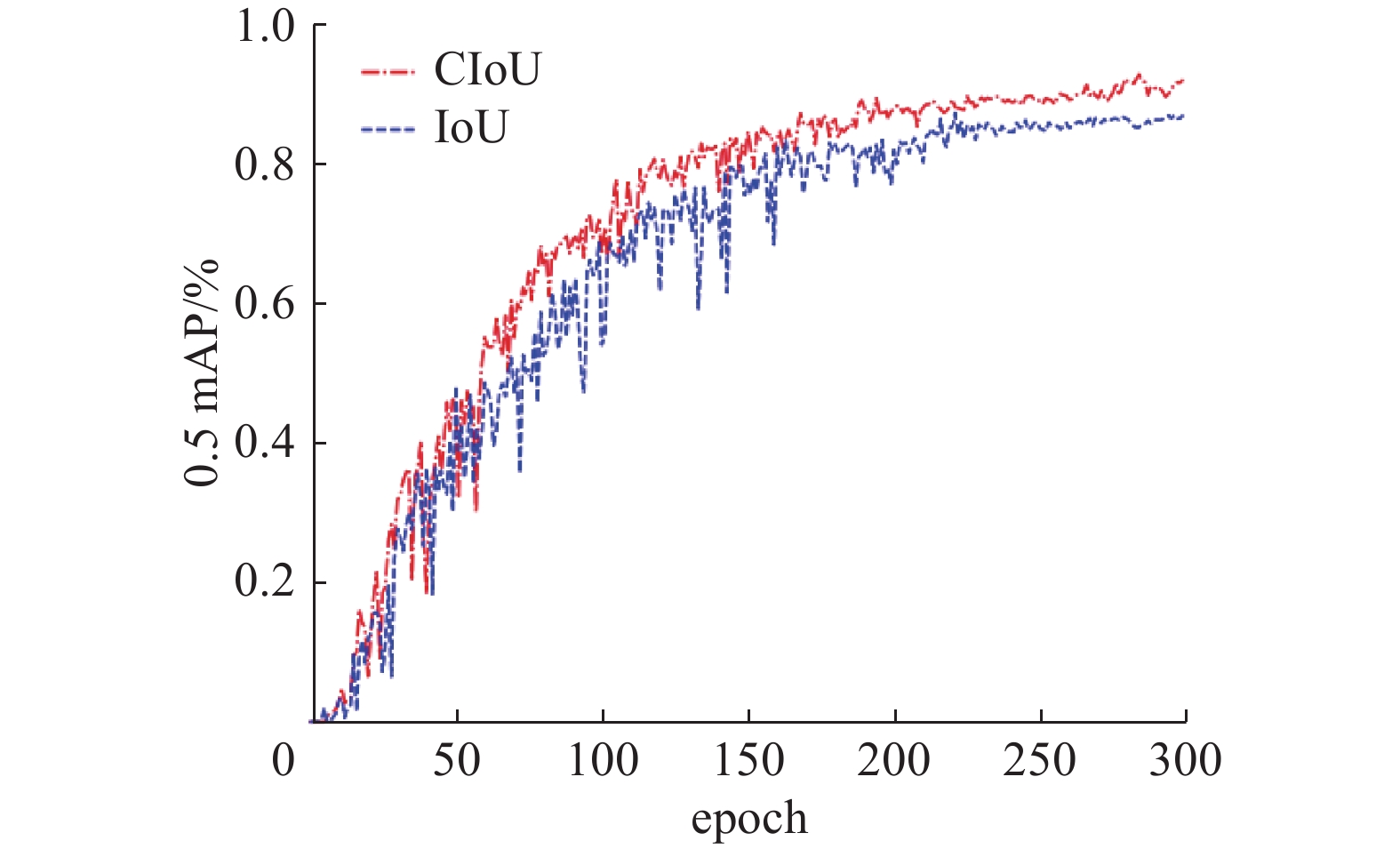 图 9 CIoU和IoU检测精度对比Fig. 9 Comparison of detection accuracy between CIoU and IoU下载:
全尺寸图片
图 9 CIoU和IoU检测精度对比Fig. 9 Comparison of detection accuracy between CIoU and IoU下载:
全尺寸图片
图10为本文算法在FOD数据集上的检测结果。可以看出,在机场复杂道面背景下,本文对于小目标FOD有着较高的检测精度。
 图 10 FOD数据集检测结果Fig. 10 FOD data set detection results下载:
全尺寸图片
图 10 FOD数据集检测结果Fig. 10 FOD data set detection results下载:
全尺寸图片
3. 结束语
本文针对机场道面FOD检测中遇到的目标尺寸小、图像中像素占比少的问题,提出了一种FOD-RDN检测算法。该算法通过纹理特征提取模块和超分辨率特征金字塔提升了检测精度。其主要思想是,在保证检测算法实时性的前提下,通过亚像素卷积对多尺度特征金字塔进行优化提升对尺寸较小目标的特征提取能力,同时引入纹理特征提取模块对影响目标检测的复杂机场道面背景进行抑制。同时本文提出了双通道YOLO检测器,并使用CIoU优化了原有的损失函数。本文算法在机场FOD数据集上验证了有效性。与目前经典算法进行对比实验,结果表明,本文算法具有更高的检测精度,并可以达到实时性的检测要求。
-
图 1 网络流程图
Fig. 1 Network flow chart
下载:
全尺寸图片
图 2 FOD-RDN 网络结构
Fig. 2 FOD-RDN network structure
下载:
全尺寸图片
图 3 超分辨率特征金字塔
Fig. 3 Super-resolution feature pyramid net
下载:
全尺寸图片
图 4 纹理信息提取模块
Fig. 4 Texture information extraction module
下载:
全尺寸图片
图 5 FOD在加入纹理信息提取模块前后热力图对比
Fig. 5 Comparison of heat map of FOD before and after adding texture information extraction module
下载:
全尺寸图片
图 6 预测框与真实标注框
Fig. 6 Prediction box and real annotation box
下载:
全尺寸图片
图 7 机场复杂道面FOD图像数据集
Fig. 7 FOD data set collected from complex airport pavement
下载:
全尺寸图片
图 8 双通道与三通道边框损失函数回归曲线
Fig. 8 Two-channel and three-channel frame loss function regression curves
下载:
全尺寸图片
图 9 CIoU和IoU检测精度对比
Fig. 9 Comparison of detection accuracy between CIoU and IoU
下载:
全尺寸图片
图 10 FOD数据集检测结果
Fig. 10 FOD data set detection results
下载:
全尺寸图片
表 1 K-means重聚类锚定框大小
Table 1 K-means re-clustering anchor box size
特征图 锚定框大小 中尺度 (4,4);(5,4);(5,7) 小尺度 (2,2);(3,2);(4,3) 表 2 本文与其他模型数据集检测精度和时间对比
Table 2 Comparison of detection accuracy and time between this paper and other model data sets
模型 P/% R/% 0.5mAP/% 0.95mAP/% 时间/ms FRC 26.1 84.1 58.6 44.6 900 SSD 73.9 24.7 48.8 38.4 143 YOLO-v3 71.4 85.8 85.8 69.2 49 YOLO-v5 84.7 71.8 77.0 59.1 47 本文算法 80.3 90.3 91.8 74.6 50 表 3 本文与其他模型各种类别检测精度对比
Table 3 Comparison of detection accuracy of various categories between this paper and other models
% 类别 本文 SSD FRC YOLO-v3 YOLO-v5 六角扳手 92.7 50.5 72.9 92.2 77.0 瓶盖 99.1 91.8 72.1 98.9 75.8 树枝 67.5 4.8 56.5 40.7 93.0 续表 3 类别 本文 SSD FRC YOLO-v3 YOLO-v5 圆环 89.7 65.8 61.1 89.6 17.1 夹子 99.6 35.2 71.2 99.4 90.0 刀头 99.7 8.1 40.3 95.7 94.3 耳机 85.3 48.2 48.6 83.2 93.2 垫片 89.2 39.3 23.1 81.3 78.3 钥匙 99.1 34.9 45.8 97.5 63.2 树叶 91.1 55.5 68.3 82.1 88.0 铁丝 65.4 11.9 48.7 64.7 70.5 行李锁 99.7 91.3 94.0 99.8 49.0 螺母 99.8 7.9 11.0 99.5 97.2 钢笔 96.4 86.7 80.1 96.7 92.9 插头 99.7 99.1 99.7 99.5 99.7 螺丝 99.4 22.3 27.9 94.0 76.3 螺丝刀 88.4 67.9 79.4 72.1 76.5 扳手 74.5 50.0 44.9 22.1 10.2 石头 95.2 40.1 36.8 96.4 88.5 U盘 99.1 67.8 73.3 97.1 98.7 拉链 99.5 44.1 69.8 97.9 93.8 表 4 超分辨率特征金字塔和纹理信息特征提取模块的有效性
Table 4 Effectiveness of multi-scale super-resolution feature pyramid and texture information feature extraction module
模型 P/% R/% 0.5mAP/% 0.95mAP/% 时间/ms FOD-RDN 80.3 90.3 91.8 74.6 50 采用SFPN 75.1 87.9 88.2 71.6 52 去除TIEM 74.2 85.6 87.1 70.2 47 表 5 双通道检测器的有效性
Table 5 Effectiveness of the dual-channel detector
模型 P/% R/% 0.5 mAP /% 0.95 mAP /% 时间/ms 双通道 80.3 90.3 91.8 74.6 50ms 三通道 72.4 86.9 88.2 70.3 53ms -
[1] O'DONNEL M J. Airport foreign object debris (FOD) detection equipment[EB/OL]. [2021−10−14].https://www.faa.gov/documentLibrary/media/Advisory_Circular/150_5210_24.pdf. [2] 张道玲, 燕翔. 浅析机场跑道FOD监测系统[J]. 城市道桥与防洪, 2019(12): 186−188. ZHANG Daoling, YAN Xiang. Brief analysis of airport runway FOD monitoring system[J]. Urban roads bridges & flood control, 2019(12): 186−188. [3] 周云霆, 余南阳, 范若琛. 跑道异物检测光学传感器舱环控系统实验研究[J]. 制冷与空调, 2021, 35(1): 27–31. ZHOU Yunting, YU Nanyang, FAN Ruochen. Experimental study on the environmental control system of the optical airport runway foreign object debris sensor cabin[J]. Refrigeration & air conditioning, 2021, 35(1): 27–31. [4] 刘天畅, 周越. 民机试飞中基于图像分割和水雾模型FOD检测[J]. 电气自动化, 2020, 42(4): 107–109. doi: 10.3969/j.issn.1000-3886.2020.04.033 LIU Tianchang, ZHOU Yue. FOD detection based on image segmentation and water mist model in test flight of civil aircraft[J]. Electrical automation, 2020, 42(4): 107–109. doi: 10.3969/j.issn.1000-3886.2020.04.033 [5] LIANG Wei, ZHOU Zhangli, CHEN Xiangyang, et al. Research on airport runway FOD detection algorithm based on texture segmentation[C]//2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference. Chongqing: IEEE, 2020: 2103−2106. [6] 张怡, 孙永荣, 刘梓轩, 等. 基于RTK定位的图像差分跑道异物检测[J]. 电子测量与仪器学报, 2020, 34(10): 51–56. doi: 10.13382/j.jemi.B2003027 ZHANG Yi, SUN Yongrong, LIU Zixuan, et al. Image difference detection of FOD based on RTK positioning[J]. Journal of electronic measurement and instrumentation, 2020, 34(10): 51–56. doi: 10.13382/j.jemi.B2003027 [7] XU Haoyu, HAN Zhenqi, FENG Songlin, et al. Foreign object debris material recognition based on convolutional neural networks[J]. EURASIP journal on image and video processing, 2018, 2018(1): 21. doi: 10.1186/s13640-018-0261-2 [8] 鞠默然, 罗海波, 王仲博, 等. 改进的YOLO V3算法及其在小目标检测中的应用[J]. 光学学报, 2019, 39(7): 0715004. doi: 10.3788/AOS201939.0715004 JU Moran, LUO Haibo, WANG Zhongbo, et al. Improved YOLO V3 algorithm and its application in small target detection[J]. Acta optica sinica, 2019, 39(7): 0715004. doi: 10.3788/AOS201939.0715004 [9] 吴天舒, 张志佳, 刘云鹏, 等. 基于改进SSD的轻量化小目标检测算法[J]. 红外与激光工程, 2018, 47(7): 0703005. doi: 10.3788/IRLA201847.0703005 WU Tianshu, ZHANG Zhijia, LIU Yunpeng, et al. A lightweight small object detection algorithm based on improved SSD[J]. Infrared and laser engineering, 2018, 47(7): 0703005. doi: 10.3788/IRLA201847.0703005 [10] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779−788. [11] FARHADI A, REDMON J. Yolov3: An incremental improvement[C]//Computer Vision and Pattern Recognition. Berlin: Springer, 2018: 1804−2767. [12] 郭玥秀, 杨伟, 刘琦, 等. 残差网络研究综述[J]. 计算机应用研究, 2020, 37(5): 1292–1297. GUO Yuexiu, YANG Wei, LIU Qi, et al. Survey of residual network[J]. Application research of computers, 2020, 37(5): 1292–1297. [13] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 936−944. [14] DENG Chunfang, WANG Mengmeng, LIU Liang, et al. Extended feature pyramid network for small object detection[J]. IEEE transactions on multimedia, 2022, 24: 1968–1979. doi: 10.1109/TMM.2021.3074273 [15] 陈科圻, 朱志亮, 邓小明, 等. 多尺度目标检测的深度学习研究综述[J]. 软件学报, 2021, 32(4): 1201–1227. CHEN Keqi, ZHU Zhiliang, DENG Xiaoming, et al. Deep learning for multi-scale object detection: a survey[J]. Journal of software, 2021, 32(4): 1201–1227. [16] 李彬, 喻夏琼, 王平, 等. 基于深度学习的单幅图像超分辨率重建综述[J]. 计算机工程与科学, 2021, 43(1): 112–124. LI Bin, YU Xiaqiong, WANG Ping, et al. A survey of single image super-resolution reconstruction based on deep learning[J]. Computer engineering and science, 2021, 43(1): 112–124. [17] 李海丰, 韩红阳. 复杂背景下机场道面细带状结构病害检测算法[J]. 北京航空航天大学学报, 2022, 48(1): 36–44. LI Haifeng, HAN Hongyang. Algorithm to detect thin strip-shaped structural diseases on airport pavement in complex background[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(1): 36–44. [18] DONG Chao, LOY C C, HE Kaiming, et al. Learning a deep convolutional network for image super-resolution[C]//European Conference on Computer Vision. Cham: Springer, 2014: 184−199. [19] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770−778. [20] 司念文, 张文林, 屈丹, 等. 卷积神经网络表征可视化研究综述[J]. 自动化学报, 2022, 48(8): 1890–1920. doi: 10.16383/j.aas.c200554 SI Nianwen, ZHANG Wenlin, QU Dan, et al. Review on visualization of convolutional neural network representation[J]. Acta automatica sinica, 2022, 48(8): 1890–1920. doi: 10.16383/j.aas.c200554 [21] 卢泓宇, 张敏, 刘奕群, 等. 卷积神经网络特征重要性分析及增强特征选择模型[J]. 软件学报, 2017, 28(11): 2879–2890. LU Hongyu, ZHANG Min, LIU Yiqun, et al. Convolution neural network feature importance analysis and feature selection enhanced model[J]. Journal of software, 2017, 28(11): 2879–2890. [22] NEUBECK A, VAN GOOL L. Efficient non-maximum suppression[C]//18th International Conference on Pattern Recognition. Hong Kong: IEEE, 2006: 850−855. [23] HARTIGAN J A, WONG M A. Algorithm AS 136: a K-means clustering algorithm[J]. Applied statistics, 1979, 28(1): 100. doi: 10.2307/2346830 [24] LU Bin, ZHOU Lijuan, ZHANG Shudong, et al. Detection of small objects in complex long-distance scenes based on Yolov3[C]//2021 4th International Conference on Data Science and Information Technology. Shanghai: ACM, 2021: 98−102. [25] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 [26] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[C]//European Conference on Computer Vision. Cham: Springer, 2016: 21−37.





























































