
A survey on event extraction in new domains
-
摘要: 在当前互联网时代,大量新领域下的非结构文本数据中蕴含了海量信息。面向新领域的事件抽取方法研究能快速地构建领域知识库,用于支撑基于知识的下游应用。但现有事件抽取系统的领域限定性强,在新领域中从零构建会极度依赖事件体系和标注数据的质量及规模,需要大量人力和专家知识来定制模板和标注语料。而且数据集中常见在相同的上下文中出现多个相关联的事件实例,对事件抽取和真实性检测产生了极大阻碍。本文针对面向新领域的事件抽取这一新兴研究领域进行综述,从事件模板推导、多实例联合事件抽取、事件真实性检测三个研究方向介绍了相关工作的研究现状,并对目前存在的重点和难点问题进行了讨论,指出了下一步需要开展的研究工作。Abstract: In the current Internet era, numerous unstructured text data in new domains often contain high-volume information. Studies on event extraction in new domains can accelerate building of domain knowledge bases, supporting downstream knowledge-based applications. However, the existing event extraction methods have substantial limitations of the domain. Building event extraction systems from scratch in new domains will heavily depend on the quality and scale of event schemas and annotated data, requiring a lot of human efforts and expertise. Moreover, it is common in the datasets that multiple associated event instances often appear in the same context, heavily hindering event extraction and factuality prediction. This paper summarizes the emerging research field of event extraction in new domains and investigates current research status from three directions: event schema induction, collective event extraction, and event factuality prediction. In addition, this paper discusses the existing difficulties and challengings and indicates the potential research work to be carried out in the future.
-
在当前互联网时代中,我们身边充斥着规模庞大、类型多样的非结构化文本信息,例如各类新闻网站上的新闻、社交媒体中微信和微博等用户发表信息。非结构化知识均以自然语言形式体现,由于自然语言具有歧义性、非规范性和个性化表达等特点,同时语言还承载着丰富的知识积累以及在此基础上的思维推理过程,计算机难以对其进行直接处理和利用。
事件抽取(Event Extraction, EE)从这些非结构化文本信息中抽取结构化事件体系并分析实体在事件中所扮演的角色。这项任务有益于众多应用,例如问答系统[1]、搜索引擎[2]、推荐系统[3]等。因为完成上述应用的首要步骤是将输入的文本转化为计算机可以诠释和表示的形式,即帮助计算机理解文本的含义,而对文本的深度理解推理依赖于对文本中蕴含的结构化的事件信息的建模。
事件抽取技术既能够帮助企业更好地为用户推送产品和服务,又能够更好地把控舆情走势。因此,从非结构化文本中抽取结构化信息并衍生出相关应用,不仅对人们生活有诸多益处,而且符合企业营销和国家战略需要,同时也是传统基于浅层文本理解技术达到一定瓶颈之后的必然选择。
从近年来构建事件抽取系统的相关研究发展情况看,目前事件抽取的方法领域限定性太强,效果极度依赖于数据标注质量和标注规模等因素。针对新领域从零开始构建一个有效的事件抽取系统受到多方面的困难和阻碍。
1)人工构建模板难度大。为了面向新领域构建一个事件抽取系统,首先需要花费大量人力资源和时间成本来定制事件体系模板和标注训练语料,而且构建的事件体系模板在初期会随着语料的增多进行变化和更新。那么“如何得到可迭代的事件体系”成为了一个非常重要的研究问题。
2)多个事件间的联系难以建模。在现有事件抽取标注数据中,经常会出现在相同的上下文范围中依次描述了多个事件的现象。这些事件彼此之间具有一定的行文逻辑和语义联系,不考虑事件间的联系会导致训练数据运用不充分,降低事件抽取系统的性能,也进一步加剧了数据资源匮乏的问题。该问题在进行事件实例抽取时应最先考虑。
3)缺乏事件真实性检测。由于有一些本身并未发生的事件可能是以虚拟语气的形式或者在否定语境下被提及,自然语言理解系统的根据上下文语境精准预测事件真实性的能力在基于事件指称进行的下游应用中是十分重要的。
网络空间的迅猛发展给数据处理和信息理解带来了前所未有的机遇和挑战,尤其是面向新领域的以事件抽取为基础的文本理解和分析相关应用。本文结合为新领域构建事件抽取系统的发展现状以及目前以事件为核心的应用需求,阐述网络空间的壮大发展给构建事件抽取系统带来的重大影响和变革。并且按照“归纳事件体系–挖掘事件实例–评估事件属性”的系统架构,从构建事件抽取系统过程中涉及到的事件模板推导、多实例联合事件抽取、事件真实性检测这3个方面,分别对目前的困难与挑战和未来技术发展趋势进行了详细的分析和展望。
1. 面向新领域的事件抽取系统架构
本文对面向新领域的事件抽取系统进行归纳和分析,认为该系统架构由3个重要部分组成:归纳事件体系、挖掘事件实例、评估事件属性,如图1所示。
 图 1 面向新领域的事件抽取研究流程Fig. 1 Research process of event extraction in new domains
图 1 面向新领域的事件抽取研究流程Fig. 1 Research process of event extraction in new domains 下载:
全尺寸图片
下载:
全尺寸图片
目前的事件抽取研究主要聚焦于特定模板下的有监督层面,而且应用需求的领域限定性强,导致应用效果极度依赖于数据标注质量和标注规模等因素,最终体现为在新领域中从零开始构建一个有效的事件抽取系统需要花费大量资源定制事件体系模板和标注训练语料。在构建事件抽取系统的初期,所采用的事件体系模板会随着领域内语料(in-domain corpus)的增多产生变化和更新。因此,为了解决新领域下所面临的人工构建模板难度大等问题,在归纳事件体系时,应考虑通过构建无监督模型,利用新领域语料中的文本特征和实体信息进行事件模板推导(event schema induction, ESI)。
在事件抽取相关研究中发现,同一个句子中出现多个事件是一个很普遍的现象。据统计,在ACE 2005数据集中,同一句子中出现多个事件的比例占26%以上[4]。在同一个句子中的多个事件往往是不同类型且互相之间存在联系。此时,将多个事件都正确地抽取出来远比只有一个事件的情况困难。该问题在进行事件实例抽取时应最先考虑。所以,在新领域下挖掘事件实例时,应充分考虑到多个事件间的联系难以建模的问题,捕获上下文中不同事件触发词间的联系信息,进行多实例联合事件抽取(collective event extraction, CEE),减少系统对标注数据的依赖。
在将从新领域语料库中抽取得到的事件实例投入后续应用之前,需要进行属性评估。由于例如问答系统、搜索引擎、推荐系统等下游应用都需要真实发生的事件实例作为知识,构建面向新领域的事件抽取系统时应充分考虑到缺乏事件真实性检测的问题,从而在评估事件属性时,实现事件真实性检测(event factuality prediction, EFP)。
上述三部分内容有机统一在面向新领域的事件抽取这一系统架构下。事件模板推导属于归纳事件体系的研究部分,实现了可迭代模板的推导,提供了新领域下的事件抽取的基石。多实例联合事件抽取属于挖掘事件实例的研究部分,实现了多个事件实例的联合抽取,为新领域语料中理解复杂语境情况提供了方向。事件真实性检测属于评估事件属性的研究部分,为从新领域语料中抽取到的事件实例刻画了属性。下面分别针对这三项研究内容,介绍相关工作的研究现状,并分析问题与挑战。
2. 事件模板推导
2.1 事件模板定义
在介绍模板推导的相关工作和研究现状之前,需要先讨论研究的对象,即事件模板的研究历史。事件模板的形式随着事件实例的形式发展而改变。早期的事件模板推导工作研究的大多是利用文本模式串(patterns)来进行模板推导[5-7]。这个时期的事件实例多以“谓词–参数对(predicate-argument pairs)”的形式体现。此时的模板与现在的事件模板也具有一定形式上的区别,其表现形式更简单,具体体现为一种类似正则表达式的匹配串形式。在这之后,脚本(scripts)被提出用来对场景下的一系列事件和过程进行抽象概括和描述。Chambers等[8]在2011年尝试利用事件叙述链(narrative chains)来推导和归纳这种以场景为类别的模板。这几类研究与本文讨论的事件模板不同,故不详细展开讨论。
本文讨论的事件模板用于归纳和抽象特定类型事件中包含的主要事件角色。事件模板的结构如图2所示,其中的“袭击者”“目标”“工具”等被称为事件角色,由于其功能与槽相似,所以又被称为角色槽(slots)。为了保持一致,本文在后续均称其为“角色槽”。于是,特定类型的事件模板可以看作角色槽的集合。
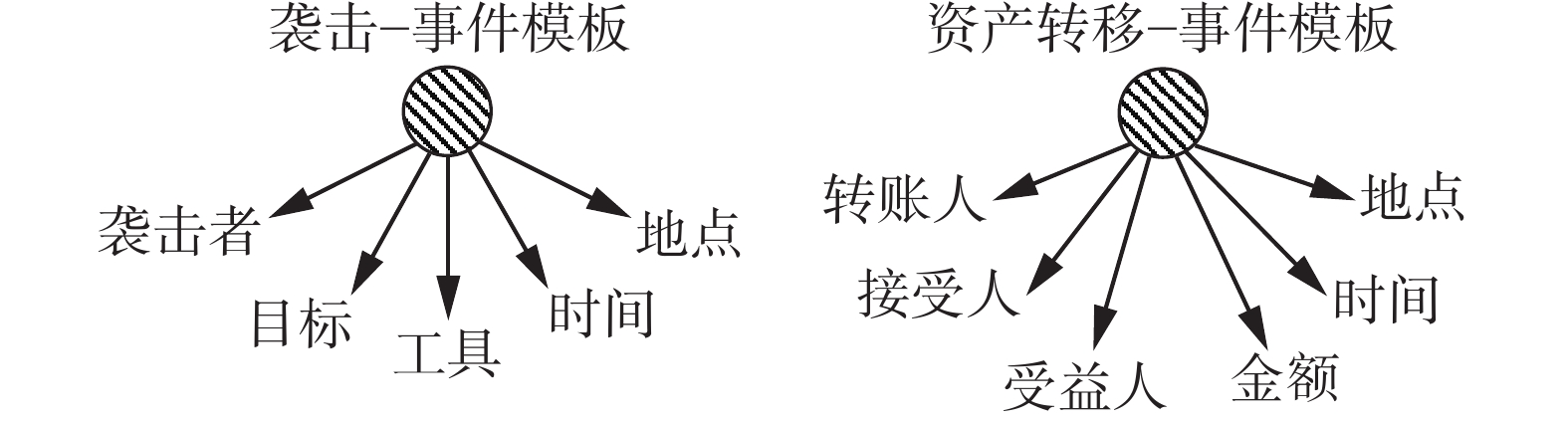 图 2 本文研究的事件模板Fig. 2 Examples of event schemas下载:
全尺寸图片
图 2 本文研究的事件模板Fig. 2 Examples of event schemas下载:
全尺寸图片
事件模板推导这个研究话题起源于MUC 4评测任务[9],该部分研究内容与此评测任务的工作具有很强的相关性。在这个评测任务中,语料包含了“纵火”、“袭击”、“爆炸”、“绑架”4种事件,在标注结果中相应的每种事件都设定了“犯罪者”、“犯罪工具”、“犯罪目标”、“受害者”4种角色槽。系统被要求输入文档级语料,输出各文档中实体头词(head word)所对应的角色,这也导致后续研究在分类角色的同时对是否需要区分事件类型产生了分歧,并采用了不同的评价方式。
2.2 基于概率生成式的方法
在基于MUC 4的研究中,研究者们更多利用事件谓词作为事件的主体,当时的主流方法包括了将事件谓词(predicates)和要素(arguments)联合建模分配的概率生成式方法[10-12]和为了推导事件槽而设计的特定场景下的聚类方法[13-16]。
Chambers等[10]在2013年首次利用概率生成式模型建模文档的生成过程,并利用Gibbs采样的方法进行参数估计。他们认为一个文档可以表示为一个经过实体指代消解或共指消解之后的实体集合,其中每一个实体的表示形式为一个三元组
$ < h,M,F > $ :$h$ 表示实体的中心词,$M$ 表示实体指称的集合,$F$ 表示实体类别特征和实体所处Wordnet同义词集特征的集合。Nguyen等[12]在2015年对该方法进行改进,他们首先将文档的生成过程进行改进,精简了其中对实体指称的建模,丰富了实体特征的表示,将每一个实体的表示形式改为三元组
$ < h,T,A > $ :$h$ 表示实体的中心词;$T$ 表示实体触发词特征集合,利用依存分析的结果进行计算;$A$ 表示实体属性特征集合,用于引入修饰语带来的信息。2.3 基于聚类的方法
在聚类方法中,Sha等[13]在2016年利用依存特征和点互信息,基于同一个句子中模板和角色操槽的限制,采用归一化割的聚类算法来计算每个实体所属角色类别。
Huang等[14]在2016年采用流水线架构,基于词义和AMR解析,利用将组合表示进行谱聚类的方法推导事件模板。
由于当时主流的方法都是先进行事件触发词和类别分析,再进行角色槽分析。Ahn等[15]在2017年提出了一种过程反转的方法,先利用表示学习进行角色分析,再进行类别聚类,并为事件模板推导提出了多种聚类时计算类别相似的方法。
Yuan等[16]在2018年利用生成式模型为实体和角色槽建立了同一空间下的表示方法,并基于这些实体表示和角色槽表示进行聚类,从而产生事件模板。
2.4 神经网络模型强化的方法
针对传统概率生成式方法和聚类方法均依赖于手工编制的文本特征提取,没有利用大规模文本中的文档及冗余信息,也不利于补充后续新领域语料进行迭代等问题。之后的研究者尝试利用神经网络来对事件模板和脚本进行建模[17-21]。
Liu等[20]在2019年提出基于神经隐变量的事件模板推导方法,通过利用新领域下语料中的实体信息、连续化的语义信息和文本冗余度信息来构建含有高维连续向量隐变量的概率生成式模型,利用神经变分推断方法进行后验分布的近似估计,同时赋予模型训练可迭代性,适合大规模语料库和基于批次的迭代学习。
Wang等[21]在2019年提出基于对抗生成网络的隐状态方法,基于对抗生成网络模型(generative adversarial networks, GANs)研究在线文本领域中的事件模板推导。该方法的优势在于能区分文本中每一个隐含事件,并依靠狄利克雷(Dirichlet)先验对每一个事件都进行建模。此外,该方法采用一个生成网络来捕获隐含事件的,并且使用一个判别器来将隐含事件重构得到的文档与真实文档区分开,从而具有比隐变量模型更快的收敛速度。
2.5 问题与挑战
上述几类事件模板推导工作在面对新领域时存在以下问题与挑战:
1)角色槽先验值选择难。上几节中提到的几类典型方法[12, 20-21]均需设定角色槽先验值或事件类型种数。在初次设定该值时,需要对数据集有一定的认识和处理经验。这个值是一个对实验结果和模型性能影响较大的超参数,通常的决策手段为在开发集设定规则进行调整。那么就需要预先标注一份开发集。通常在为新领域下的语料推导事件模板时,很难获得一份高质量的标注数据。这样两难的情况就制约了无监督事件模板推导方法的应用。
2)单个槽包含大部分信息。在主题模型相关研究中[22],经常会出现单个主题的top-
$N$ 词集合包含具有压倒性数量的大部分词表中的词,而其他主题中出现的词过于稀少。由于所使用的算法的相似性,相似的现象在无监督事件模板推导[10, 12, 16, 20-21]中也会出现。目前只能通过参数搜索进行缓解,无法完全回避,亟需相关方法在理论上的突破。3)对数据敏感,依赖相关性过滤。在文献[12, 21]中,针对无监督事件模板推导的输入文档和输出事件,设计了进行相关性过滤的实验。实验结果证明,预先根据相关性对输入文档进行过滤能有效提高模板匹配测试中的性能指标。由于语料库中存在不包含相关事件的文档,因此通过相关性过滤可以使得干扰项减少,从而拟合得到更符合需求的角色槽后验分布。此外,现有方法没有着重研究如何对输出事件进行过滤,这方面对于事件模板的输出应用将产生很大作用。
4)人工干预需求大。面向新领域的事件模板推导十分需要人工的引导。在模型调优时,输出的角色槽与标注的角色槽对应难。在模型最终输出时,由于模型中设置的角色槽数量通常大于实际值,导致在使用输出结果之前需要将模型输出的角色槽进行合并,再进行后续应用。目前最有效的组织输出结构的方法还是人工干预和贪心规则,但是并不能做到自动化。并且推导出的模板缺少“纵火”、“袭击”、“爆炸”等事件类型名称,或“袭击者”、“目标”、“工具”等角色槽名称,还需要标注人员花费人力进行槽类别名和事件类别名的归纳。
3. 多实例联合事件抽取
3.1 事件实例定义
从自然语言文本中抽取事件实例是一个关键又十分具有挑战性的工作。目前对事件抽取的任务定义大多数依照ACE 2005评测会议[23]或Rich ERE[24]中的规范进行原子事件实例(atomic event instances)的抽取,将原子事件实例(为了简洁,本文在后续中称之为“事件”)分为触发词(triggers)和事件要素(arguments)两部分。于是事件抽取任务也被分为两个子任务:识别和分类事件触发词的事件检测(Event Detection, ED),和将实体按照在事件中扮演的角色进行识别和分类的事件要素抽取(event argument extraction, EAE)。其中事件参数具体表现形式为“角色–实体对(role-entity pairs)”,也可以看作将实体进行分类并填入设定好的角色槽中产生的结果。虽然事件的表示形式在不同研究重点的工作中形态有一些差别,为了与上一步工作相匹配,本文也采用ACE 2005评测会议和Rich ERE中的定义的事件表示形式。
图3为事件实例的示意图,其中包含了一个“袭击”类型的事件实例。该实例刻画了文本中一个由“开火”触发的袭击事件,“美军”作为袭击者在“巴克达”对“巴勒斯坦饭店”和“记者”进行了袭击。
 图 3 本文抽取的事件实例Fig. 3 Examples of event instances下载:
全尺寸图片
图 3 本文抽取的事件实例Fig. 3 Examples of event instances下载:
全尺寸图片
3.2 引入多特征的方法
在事件抽取领域,目前存在多类涉及到探索事件间联系从而进行事件多实例联合抽取的工作。其中一类方法的中心思想是通过引入更多句子级的特征来增强对事件间联系的捕获。McClosky等[25]在2011年采用了将排序依存融入事件抽取系统的方法。Li等[26]在2013年采用了一种对于事件触发词和事件要素可结合的文本特征。Liu等[27-28]在2016年提出利用概率软逻辑的推理方法进行事件抽取。Yang等[29]在2016年和Keith等[30]在2017年分别提出利用不同的事件触发词特定的特征和文本关系性特征来在句子级增强对事件间关系的特征提取。
3.3 采用文档级特征的方法
第2类方法的核心思想是直接采用文档级别的特征提取方法进行处理[31-35]。Liao等[31]在2010年采用事件类型共现的统计方法引入文档级别信息进行联合抽取。Ji等[32]在2008年采用基于信息检索的方法扩大了信息利用的范围,并引入相似文档间的跨文档信息,最后采用最大间隔的计算方法进行全局解码。Hong等[33]在2011年提出利用实体类别一致性特征来引入跨实体的信息,从而在抽取事件实例的同时结合了其他候选事件的信息,这样做的好处是不仅利用了触发词的信息,还通过引入跨实体信息使得事件论元抽取也获得了一致性方面的提升。Reichart等[34]在2012年研究新闻报道场景中的多事件抽取问题,其中一个文档包含多个原子事件,利用包含角色标注隐信息边、事件标注隐信息边和全局限制隐信息边的图,构建特征模板,从而使用条件随机场算法进行建模和联合解码。Lu等[35]在2012年提出了一种基于隐变量的半马尔可夫条件随机场模型对文档级别的序列标注问题进行建模,利用这个结构预测框架可以进行结构优先性建模,从而能够满足多事件联合抽取。
3.4 基于深度学习的方法
基于特征提取的前两类方法需要工程量巨大的手工编制特征,其精细程度也会影响到事件抽取系统的识别效果,除此之外,从类别不平衡的数据上学习得到的特征也很难被用于稀疏类型的事件抽取中去。第3类方法是采用深度学习模块来对事件间的联系进行多层次或多级联编码,包括使用循环神经网络(recurrent neural networks, RNNs)作为基本编码单元的方法[36-38]和使用卷积神经网络(convolution neural networks, CNNs)作为基本编码单元的方法[39-41]。
作为其中具有代表性的工作,Chen等[39]在2015年改进了传统卷积神经网络模型,通过序列划分的方式将一个句子分为多个块,不仅扩展了语境长度,也侧面实现了为不同事件实例保存候选信息,为多事件联合抽取提供了一种基于位置划分的可行方向。
Nguyen等[36]在2016年提出JRNN模型。该方法在循环神经网络模型中结合一些手工编制的全局特征和局部特征,引入记忆向量和记忆单元来保存可能的候选事件表示,从而增强事件间的联系,这种方法也被认为是一种实现多事件联合抽取的软解码方式。
Liu等[4]在2018年提出基于图编码的多实例联合事件抽取方法JMEE。该方法通过句子的浅层依存信息构建词间连通图和信息传递快捷弧,利用图卷积加强有联系的词之间的信息交互,利用自注意力机制将结合了词间交互信息的语义表示进行组合从而进行事件触发词分类,进而实现事件要素抽取。
3.5 基于多任务的方法
之前所述的大部分方法都需要利用到实体标注信息,不能做到从文本直接到事件输出的端到端方式。此外,大多数的事件抽取系统都利用的是任务特定的分类器,仅考虑到任务级别的局部信息,而未考虑到相近任务中各实例之间的关联信息。比如,一个“死亡”类型的事件中的“受害者”角色极有可能会在同一个句子中“袭击”类型的事件中扮演“目标”角色。因此,基于多任务的事件抽取方法[42-43]应运而生,该类方法能利用多个子任务之间和多实例之间的信息进行推断,并利用全局信息进行约束抽取结果的产生。
Wadden等[42]在2019年提出DyGIE++模型,该方法首先枚举长度不超过限制的跨度集合,再利用一种共享跨度(spans)表示的图框架来进行多任务信息抽取,包括:实体识别、关系抽取、事件抽取和共指消解。在该图框架中,节点是可能作为实体和事件触发词的文本跨度,节点之间的边表示跨度之间的实体间关系、实体指称的共指关系、事件中触发词和事件要素的角色关系。其核心思想是首先利用预训练模型和上下文信息处理出跨度表示,然后轮流利用各任务的信息和监督信号,在图框架中迭代更新跨度表示,最后输出各任务分类结果。
Lin等[43]在2020年提出基于全局信息的多实例联合事件抽取方法OneIE。其基本思想为将一句话中的实体和事件等信息表示为一个信息图。图中节点为实体和触发词,边为“实体–实体”关系或者“触发词–要素”关系。其中节点和边均有类型,节点类型中包括实体类型(对应实体识别子任务)和触发词所代表的事件类型(对应事件检测子任务),边类型中包括实体间的关系(对应关系抽取子任务)和触发词与事件要素间的角色关系(对应事件要素抽取子任务)。该方法首先考虑每个单任务下的分类模式,得到实体、关系、事件触发词、事件要素的基本表示。然后按照预先定义的模板抽取多任务和多实例间的全局特征向量。并将基本表示与全局特征向量结合,利用束搜索(beam search)交替扩展节点和边,从而进行最优信息图的搜索,以实现端到端的多实例信息抽取。
3.6 建模为其他任务的方法
大部分多实例联合事件抽取方法都遵照序列建模分类的任务定义进行事件触发词和要素的抽取。目前也存在一些方法尝试放弃序列建模和分类,转而使用其他成熟的任务架构,如:机器阅读理解[44-46](machine reading comprehension,MRC)和文本生成[47-49](text generation)。
作为同时期的工作,文献[44-46]均采用了阅读理解的架构对事件抽取进行建模,分别为触发词抽取和事件要素抽取设计了不同的问题模板,利用BERT模型[47]来建模“问题–文本”对,最终将事件要素抽取的过程转化为起止位置预测[44-45]或二分类预测[46]。
利用文本生成进行事件抽取是近年来比较新的方式。Paolini等[48]在2021年提出TANL模型,利用翻译模型建模事件抽取。Li等[49]在2021年提出BARTGen模型,利用标注数据集时的副产品——事件模板信息,将事件要素抽取任务转化为一个模板填空的问题,从而强化事件要素抽取的效果。Lu等[50]在2021年提出了Text2Event。该方法针对事件实例具有复杂结构的特点,提出了一种序列化的事件表示体系。并且首次采用预训练的生成模型,进行文本序列到事件表示序列的建模,从而实现端到端(end-to-end)的多实例联合事件抽取。除此之外,为了保证模型输出的事件表示可以还原为事件实例,该方法还采用了基于Trie树的受限解码算法[51],并利用课程学习(curriculum learning)[52]的技巧,从易到难进行预训练模型的微调。
3.7 少样本学习的方法
多实例联合事件抽取研究大部分属于有监督学习,但也不缺乏领域内标注数据极少的情况。为了应对这样的场景,研究者们也针对少样本学习(few-shot learning)研究了多实例联合的事件抽取方法[44-45, 48, 53]。
Huang等[53]在2018年研究了少样本学习的极端情况——零样本学习(zero-shot learning)下的事件抽取方法。通过结合事件本体的结构信息,该方法将各类别的事件本体与事件实例的AMR解析[54]结果映射到同一语义空间中去,利用相似度为触发词判断事件类别。
由于在本文所采用的事件结构中,触发词为事件的中心,少样本学习主要集中于事件触发词,近年也出现了一些专注于触发词识别的少样本学习工作[55-57]。
Deng等[55]在2020年将动态记忆加入原型网络(prototype network),用于在K-way-N-shot的任务设定下学习各类事件类别的原型表示。Deng等[56]在2021年提出OntoED,采用事件本体中事件类别之间的关系、事件与角色之间的关系,结合事件实例与事件本体之间的关系,同时学习事件实例的表示和事件本体的表示,实现少样本学习下的事件检测。Cong等[57]在2021年采用PA-CRF建模事件类别原型表示之间的转移概率,并利用正态分布缓解在数据不足的情况下转移概率不确定性估计的问题。
3.8 问题与挑战
多实例联合事件抽取研究面临诸多挑战。相比一般的分类和回归任务,这些挑战主要体现在:事件结构较为复杂,建模多个子任务并将各部分输出这组合成事件具有挑战;额外设计的辅助结构存在计算效率瓶颈问题;引入需要处理才能得到的外部知识会导致处理错误的传递;监督信号过多,难以抉择,增加了模型选择的难度;对背景信息与领域知识缺少理解;难以处理具有不符合要求真实性的事件或隐喻的事件。
我们认为多实例联合事件抽取方法研究以下存在的问题和挑战:
1)联合抽取事件触发词和事件要素的框架还未做到最理想的联合模式。纵观从基于记忆单元的多实例联合事件抽取方法JRNN[36]开始的联合抽取框架[4, 36-37, 42-43],尽管它们采用了如记忆单元、外部句法信息、图卷积神经网络、多任务联合等方法进行对触发词和事件要素联合抽取,但是仍然不能绕开先触发词后角色关系的“伪联合”模式。换而言之,如今的联合抽取框架仍然不能做到触发词与事件要素的同步处理。这种现象某种程度上受到了事件结构的制约,也导致如今很多对事件抽取的改进都只在触发词方面十分有效,却在事件要素方面难以获得提升和突破。
2)引入的外部知识会存在错误传递的问题。例如,文献[4, 37]均采用了外部句法信息(即依存树结果)与神经网络模型相结合的方法。但即使在研究最多的英语语种上,也不能保证依存分析的结果完全正确。这就导致了引入的外部句法信息中存在不可忽视的噪声,这些噪声对后续的使用会存在一定的影响。而且随着句子长度的增强,现有依存分析方法的可靠性会下降。如何处理这些从上游处理中传递而来的噪声将成为一个非常值得研究和探讨的话题。
3)难以决定不同监督信号的重要程度。在训练过程中根据监督信号进行模型选择是十分重要的。根据现有的事件结构和评价层面,事件抽取可以分为事件触发词识别、触发词分类、事件要素识别和事件要素分类4个子任务和评价方面。每个子任务都相对独立,会产生独立的结果。除此之外,在引入多任务信息时,不同任务也会产生不同的监督信号,进一步加剧模型选择的困难程度。
4)对背景信息与领域知识缺少理解。现有模型没有外部知识,无法理解背景信息,如实体属性和场景切换等方面。这些信息可以通过外部知识库进行获取,但尚未有研究探索如何处理知识并将其结合进事件抽取方法中。除此之外,忽视外部知识带来的另一隐患就是对领域知识的缺乏,比如特定领域下的文本缩写、生词等代表的含义。这些不仅在特定领域下很重要,在特定场景下也很重要。
5)事件真实性的不确定与隐喻的现象。文本中事件可能处于不同时态、不同语态,这导致了这些事件可能并未真实发生。有些事件可能是假设状态下发生、即将发生、未来仅有可能发生、未来不可能发生或者过去没有发生。在事件知识的应用中,需要对抽取的事件的真实性进行判断和筛选。比如,若需要构建事件知识库,则不需要未发生的事件。同时文本隐喻也是一个十分常见的现象。一个隐喻事件可能仅仅通过一个不能作为触发词的动词或者动名词就能体现,但是不能用现有的事件结构进行表示。
4. 事件真实性检测
4.1 事件真实性定义
事件真实性检测是信息抽取中一个基本任务,其目的是识别事件指称在其语境下真实发生了的确定性。根据语料中文档作者的意愿,事件指称会反映出不同的真实性和不确定性。一个自然语言理解系统的精准预测事件真实性的能力对根据这些事件指称进行的下游推断任务具有很大的重要性。例如,如果要根据从语料中抽取出的事件建立一个事件知识库,其中非常关键的一点就是需要知道哪些事件反事实,从而不应该被加入到知识库中。
4.2 相关方法
事件真实性检测工作的方法大致可以分为四类,对这个任务的目标定义也从判别式分类变成了数值回归。
第1类是利用基于规则的方法[58-60],Nairn等[58]在2006年提出了一个基于手工编制的词法特征的判别式算法,其中将特定的从句表示动词和隐式签名用递归极性传递算法联系起来。Lotan等[60]在2013年提出利用词法和依存特征和隐式签名的递归的基于规则的系统TruthTeller。
第2类是利用人工设计的特征进行有监督机器学习的方法[61-64],Diab等[61]在2009年和Prabhakaran等[62]在2010年分别使用支持向量机和条件随机场模型,利用词法特征和依存特征来预测作者置信度。Lee等在2015年[64]提出把依存路径特征加入支持向量机模型。
第3类是规则和有监督学习的结合方法[65-67],Sauri等[65]在2012年和Stanovsky等[67]在2017年分别利用基于规则系统的输出来训练支持向量机模型。其中Stanovsky等[67]在2017年首次提出将事件真实性检测任务的目标改为[−3, +3]的回归分值,并发布了当时3个公开数据集的目标对齐规则。
第4类是基于深度学习和语义表示的方法[68-70],其中Qian等[68]在2019年采用了对抗生成网络,Rudinger等[69]在2018年利用长短期记忆网络对输入的语义序列信息和依存表示进行建模,Veyseh等[70]在2019年提出将词贡献矩阵和依存表示矩阵进行加权结合,并利用图卷积模型进行句子建模和信息编码。
4.3 相关数据集
目前应用较广泛的事件真实性检测数据集有以下4种。其中训练集、开发集、测试集的事件实例统计结果和上下文平均长度如表1所示。
FactBank[71]数据集建立在TimeBank[74]语料库之上。其中针对事件指称的真实性进行了离散的标注,标注类别分为四大类:事实(factual, CT+/−)、可能(probable, PR+/−)、可能(possible, PS+/−)、未知(unknown, Uu/CTu)。标注结果取得了相对较高的标注内一致性(Inter-Annotator Agreement, IAA),
$k = 0.81$ 。Meantime[72]数据集包括120篇英文新闻文章,及其在西班牙语、意大利语和荷兰语中的对照翻译语料。该数据集采用的事件指称真实性标注也是离散的,例如事实(factual)、反事实(counterfactual)、不确定可能性(uncertain possibility)和未来可能性(future possibility)。
UW是由Lee等[64]在2015年为事件检测和真实性检测开发并标注的数据集。该数据集通过众包(crowdsourcing)的方式为TempEval-3语料库[75]句子中的事件指称标注了范围在
$[ - 3, + 3]$ 内的浮点数分值。该分值的两端分别表示某事件一定没发生(−3)和一定发生了(+3)。该数据集的IAA也很高,事件检测的一致性F1达到92.6%,真实性检测的相关性达到83.1%。UDS-IH2[69, 74]的标注范围涵盖了英语通用依存树库[76](english universal dependencies, EUD)中所有的谓词。该数据集通过32位在Amazon Mechanical Turk平台招募的众包数据标注师,为每个事件指称注明了是否真实发生以及判断的置信度,置信度范围是
$[0,4]$ 。事件真实性检测的IAA为0.84。4.4 问题与挑战
我们认为上述事件真实性检测工作存在以下问题与挑战:
1)对事件要素和结构信息的忽视。从上述事件真实性检测方法可以看出,输入信息基本来源于事件指称及其所在的上下文,缺少对事件要素信息的利用。而事件要素是事件结构中重要的组成部分,引入事件要素信息不仅可以丰富事件指称,还能够增强上下文环境在事件真实性检测中的利用率,从而提高事件真实性检测的性能。
2)过度信赖简化的句法信息。在上述的第4类方法中,文献[70]采用依存句法构建信息图,并利用图卷积方法建模上下文,取得了性能提升。这类方法在多实例联合事件抽取中也获得了广泛应用[4],但是仅采用了粗类别的句法信息,将依存分析的结果信息进行了多方面的简化,丢失了边的方向性和类别标签,即没有利用细粒度句法信息。这样可能会存在信息缺失,从而难以将事件真实性检测的性能进一步提升。
3)多份数据集的信息没有有效利用。通过前文对事件真实性检测的分析和综述,可以发现事件真实性检测受领域的限制相对本文介绍的其他任务较小。但是,现有方法忽略了对多份数据集的联合使用,没有研究如何学习领域无关的、一般性较强的事件真实性判别模式来提高正则化效果。这导致了现有方法的迭代优化目标过于单一,可能只能在单个数据集上取得较好地性能。
5. 结束语
本文对面向新领域的事件抽取研究现状进行了较为全面的综述,归纳和分析了面向新领域的事件抽取系统架构,由三个重要部分组成:归纳事件体系、挖掘事件实例、评估事件属性。并针对面向新领域构建事件抽取系统时存在的人工构建模板难度大、多个事件间的联系难以建模、缺乏事件真实性检测等主要难点,分别对事件模板推导、多实例联合事件抽取、事件真实性检测等研究方向,综述了相关工作的研究现状,并分析了问题与挑战。
目前从海量新领域文本数据中抽取结构化信息已经逐渐成为研究热点。如何利用海量新领域下的文本数据构建大规模的事件体系、事件抽取系统和事件库,是信息抽取领域中值得深入探索的问题。与资源丰富的领域和深度垂直领域所不同的是,在新领域中可使用的资源少之又少。这使得以事件为核心的信息抽取在新领域中的难度更大。那么在新领域中如何减少构建事件体系的资源消耗、探究复杂语境描述中的事件抽取和事件真实性检测研究将成为未来潜在研究点。
-
图 1 面向新领域的事件抽取研究流程
Fig. 1 Research process of event extraction in new domains
下载:
全尺寸图片
图 2 本文研究的事件模板
Fig. 2 Examples of event schemas
下载:
全尺寸图片
图 3 本文抽取的事件实例
Fig. 3 Examples of event instances
下载:
全尺寸图片
-
[1] SRIHARI R, LI Wei. Information extraction supported question answering[C]//8th Text Retrieval Conference. Gaithersburg, USA: NIST, 1999: 500–511. [2] BASILE P, CAPUTO A, SEMERARO G, et al. Time event extraction to boost an information retrieval system[M]//Information Filtering and Retrieval. Cham: Springer International Publishing, 2016: 1–12. [3] LU Di, VOSS C, TAO Fangbo, et al. Cross-media event extraction and recommendation[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations. Stroudsburg, USA: ACL, 2016: 72–76. [4] LIU Xiao, LUO Zhunchen, HUANG Heyan. Jointly multiple events extraction via attention-based graph information aggregation[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, USA: ACL, 2018: 1247–1256. [5] SHINYAMA Y, SEKINE S. Preemptive information extraction using unrestricted relation discovery[C]//Proceedings of the main conference on Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics. Stroudsburg, USA: ACL, 2006: 304–311. [6] FILATOVA E, HATZIVASSILOGLOU V, MCKEOWN K. Automatic creation of domain templates[C]//Proceedings of the COLING/ACL on Main conference poster sessions. Stroudsburg, USA: ACL, 2006: 207–214. [7] QIU Long, KAN M, CHUA T. Modeling context in scenario template creation[C]//Proceedings of the 3rd International Joint Conference on Natural Language Processing. Stroudsburg, USA: ACL, 2008: 157–164. [8] CHAMBERS N, JURAFSKY D. Template-based information extraction without the templates[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2011: 976–986. [9] SUNDHEIM B M. Overview of the fourth message understanding evaluation and conference[C]//MUC4 '92: Proceedings of the 4th conference on Message understanding. New York, USA: ACM, 1992: 3–21. [10] CHAMBERS N. Event schema induction with a probabilistic entity-driven model[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, USA: ACL, 2013: 1797–1807. [11] CHEUNG J, POON H, VANDERWENDE L. Probabilistic frame induction[C]//Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2013: 837–846. [12] NGUYEN K H, TANNIER X, FERRET O, et al. Generative event schema induction with entity disambiguation[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Stroudsburg, USA: ACL, 2015: 188–197. [13] SHA Lei, LI Sujian, CHANG Baobao, et al. Joint learning templates and slots for event schema induction[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2016: 428–434. [14] HUANG Lifu, CASSIDY T, FENG Xiaocheng, et al. Liberal event extraction and event schema induction[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2016: 258–268. [15] AHN N. Inducing event types and roles in reverse: Using function to discover theme[C]//Proceedings of the Events and Stories in the News Workshop. Stroudsburg, USA: ACL, 2017: 66–76. [16] YUAN Quan, REN Xiang, HE Wenqi, et al. Open-schema event profiling for massive news corpora[C]//Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York, USA: ACM, 2018: 587–596. [17] MODI A, TITOV I. Inducing neural models of script knowledge[C]//Proceedings of the Eighteenth Conference on Computational Natural Language Learning. Stroudsburg, USA: ACL, 2014: 49–57. [18] RUDINGER R, RASTOGI P, FERRARO F, et al. Script induction as language modeling[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, USA: ACL, 2015: 1681–1686. [19] PICHOTTA K, MOONEY R J. Using sentence-level LSTM language models for script inference[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2016: 279–289. [20] LIU Xiao, HUANG Heyan, ZHANG Yue. Open domain event extraction using neural latent variable models[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2019: 2860–2871. [21] WANG Rui, ZHOU Deyu, HE Yulan. Open event extraction from online text using a generative adversarial network[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, USA: ACL, 2019: 282–291. [22] SRIVASTAVA A, SUTTON C. Autoencoding variational inference for topic models[C]//Proceedings of the 5th International Conference on Learning Representations. La Jolla, USA: ICLR, 2017. [23] GRISHMAN R, WESTBROOK D, MEYERS A. NYU’s English ACE 2005 system description[C]//Proceedings of the ACE 2005 Evaluation Workshop. Gaithersburg, USA: NIST, 2005: 1–7. [24] SONG Zhiyi, BIES A, STRASSEL S, et al. From light to rich ERE: annotation of entities, relations, and events[C]//Proceedings of the The 3rd Workshop on EVENTS: Definition, Detection, Coreference, and Representation. Stroudsburg, USA: ACL, 2015: 89–98. [25] MCCLOSKY D, SURDEANU M, MANNING C. Event extraction as dependency parsing[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2011: 1626–1635. [26] LIN Ying, JI Heng, HUANG Fei, et al. A joint neural model for information extraction with global features[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2020: 73–82. [27] LIU Shulin, LIU Kang, HE Shizhu, et al. A Probabilistic Soft Logic based approach to exploiting latent and global information in event classification[C]//30th AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI, 2016: 2993–2999. [28] LIU Shulin, CHEN Yubo, LIU Kang, et al. Exploiting argument information to improve event detection via supervised attention mechanisms[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2017: 1789–1798. [29] YANG Bishan, MITCHELL T M. Joint extraction of events and entities within a document context[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2016: 289–299. [30] KEITH K, HANDLER A, PINKHAM M, et al. Identifying civilians killed by police with distantly supervised entity-event extraction[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, USA: ACL, 2017: 1547–1557. [31] LIAO Shasha, GRISHMAN R. Using document level cross-event inference to improve event extraction[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2010: 789–797. [32] JI Heng, GRISHMAN R. Refining event extraction through cross-document inference[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2008: 254–262. [33] HONG Yu, ZHANG Jianfeng, MA Bin, et al. Using cross-entity inference to improve event extraction[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2011: 1127–1136. [34] REICHART R, BARZILAY R. Multi-event extraction guided by global constraints[C]//Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2012: 70–79. [35] LU Wei, ROTH D. Automatic event extraction with structured preference modeling[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2012: 835–844. [36] NGUYEN T H, CHO K, GRISHMAN R. Joint event extraction via recurrent neural networks[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2016: 300–309. [37] SHA Lei, QIAN Feng, CHANG Baobao, et al. Jointly extracting event triggers and arguments by dependency-bridge RNN and tensor-based argument interaction[C]//Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI, 2018: 5916–5923. [38] LIU Jian, CHEN Yubo, LIU Kang, et al. Event detection via gated multilingual attention mechanism[C]//Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI, 2018: 4865–4872. [39] CHEN Yubo, XU Liheng, LIU Kang, et al. Event extraction via dynamic multi-pooling convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Stroudsburg, USA: ACL, 2015: 167–176. [40] FENG Xiaocheng, HUANG Lifu, TANG Duyu, et al. A language-independent neural network for event detection[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2016: 66–71. [41] NGUYEN T H, GRISHMAN R. Modeling skip-grams for event detection with convolutional neural networks[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, USA: ACL, 2016: 886–891. [42] WADDEN D, WENNBERG U, LUAN Yi, et al. Entity, relation, and event extraction with contextualized span representations[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, USA: ACL, 2019: 5783–5788. [43] LIN Ying, JI Heng, HUANG Fei, et al. A joint neural model for information extraction with global features[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2020: 7999–8009. [44] LIU Jian, CHEN Yubo, LIU Kang, et al. Event extraction as machine reading comprehension[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, USA: ACL, 2020: 1641–1651. [45] DU Xinya, CARDIE C. Event extraction by answering (almost) natural questions[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, USA: ACL, 2020: 671–683. [46] LI Fayuan, PENG Weihua, CHEN Yuguang, et al. Event extraction as multi-turn question answering[C]//Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg, USA: ACL, 2020: 829–838. [47] PAOLINI G, ATHIWARATKUN B, KRONE J, et al. Structured prediction as translation between augmented natural languages[EB/OL]. (2021-01-28) [2021-12-10].https://www.researchgate.net/publication/348487215_Structured_Prediction_as_Translation_between_Augmented_Natural_Languages. [48] LI Sha, JI Heng, HAN Jiawei. Document-level event argument extraction by conditional generation[C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2021: 894–908. [49] LU Yaojie, LIN Hongyu, XU Jin, et al. Text2Event: controllable sequence-to-structure generation for end-to-end event extraction[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg, USA: ACL, 2021: 2795–2806. [50] DEVLIN J, CHANG M, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2019: 4171–4186. [51] CHEN Pinzhen, BOGOYCHEV N, HEAFIELD K, et al. Parallel sentence mining by constrained decoding[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2020: 1672–1678. [52] XU Benfeng, ZHANG Licheng, MAO Zhendong, et al. Curriculum learning for natural language understanding[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2020: 6095–6104. [53] HUANG Lifu, JI Heng, CHO K, et al. Zero-shot transfer learning for event extraction[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2018: 2160–2170. [54] WANG Chuan, XUE Nianwen, PRADHAN S. A transition-based algorithm for AMR parsing[C]//Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2015: 366–375. [55] DENG Shumin, ZHANG Ningyu, KANG Jiaojian, et al. Meta-learning with dynamic-memory-based prototypical network for few-shot event detection[C]//Proceedings of the 13th International Conference on Web Search and Data Mining. New York, USA: ACM, 2020: 151–159. [56] DENG Shumin, ZHANG Ningyu, LI Luoqiu, et al. OntoED: low-resource event detection with ontology embedding[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg, USA: ACL, 2021: 2828–2839. [57] CONG Xin, CUI Shiyao, YU Bowen, et al. Few-shot event detection with prototypical amortized conditional random field[C]//Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Stroudsburg, USA: ACL, 2021: 28–40. [58] NAIRN R, CONDORAVDI C, KARTTUNEN L. Computing relative polarity for textual inference[C]//Proceedings of the 5th International Workshop on Inference in Computational Semantics. Stroudsburg, USA: ACL, 2006: 1–10. [59] SAURI R. A factuality profiler for eventualities in text[D]. Waltham, USA: Brandeis University, 2008. [60] LOTAN A, STERN A, DAGAN I. Truthteller: Annotating predicate truth[C]//Proceedings of the 2013 Conference of the North American Chapter of the Association of Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2013: 752–757. [61] DIAB M T, LEVIN L, MITAMURA T, et al. Committed belief annotation and tagging[C]//Proceedings of the Third Linguistic Annotation Workshop on - ACL-IJCNLP '09. Suntec, Singapore. Stroudsburg, USA: ACL, 2009: 68–73. [62] PRABHAKARAN V, RAMBOW O, DIAB M. Automatic committed belief tagging[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Stroudsburg, USA: ACL, 2010: 1014–1022. [63] DE MARNEFFE M C, MANNING C D, POTTS C. Did it happen? the pragmatic complexity of veridicality assessment[J]. Computational linguistics, 2012, 38(2): 301–333. doi: 10.1162/COLI_a_00097 [64] LEE K, ARTZI Y, CHOI Y, et al. Event detection and factuality assessment with non-expert supervision[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal. Stroudsburg, USA: ACL, 2015: 1643–1648. [65] SAURI R, PUSTEJOVSKY J. Are you sure that this happened? Assessing the factuality degree of events in text[J]. Computational linguistics, 2012, 38(2): 261–299. doi: 10.1162/COLI_a_00096 [66] QIAN Zhong, LI Peifeng, ZHU Qiaoming. A two-step approach for event factuality identification[C]//2015 International Conference on Asian Language Processing. New York, USA: IEEE, 2015: 103–106. [67] STANOVSKY G, ECKLE-KOHLER J, PUZIKOV Y, et al. Integrating deep linguistic features in factuality prediction over unified datasets[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2017: 352–357. [68] QIAN Zhong, LI Peifeng, ZHU Qiaoming, et al. Document-level event factuality identification via adversarial neural network[C]//Proceedings of the 2019 Conference of the North. Stroudsburg, USA: ACL, 2019: 2799–2809. [69] RUDINGER R, WHITE A S, VAN DURME B. Neural models of factuality[C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: ACL, 2018: 731–744. [70] POURAN BEN VEYSEH A, NGUYEN T H, DOU Dejing. Graph based neural networks for event factuality prediction using syntactic and semantic structures[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, USA: ACL, 2019: 4393–4399. [71] SAURÍ R, PUSTEJOVSKY J. FactBank: a corpus annotated with event factuality[J]. Language resources and evaluation, 2009, 43(3): 227–268. doi: 10.1007/s10579-009-9089-9 [72] MINARD A, SPERANZA M, URIZAR R, et al. Meantime, the newsreader multilingual event and time corpus[C]//Proceedings of the 10th International Conference on Language Resources and Evaluation. Paris, France: LREC, 2016: 4417–4422. [73] PUSTEJOVSKY J, HANKS P, SAURI R, et al. The timebank corpus[J]. Corpus linguistics, 2003, 2003: 647–656. [74] WHITE A S, RUDINGER R, RAWLINS K, et al. Lexicosyntactic inference in neural models[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, USA: ACL, 2018: 4717–4724. [75] UZZAMAN N, LLORENS H, DERCZYNSKI L, et al. Semeval-2013 task 1: Tempeval-3: Evaluating time expressions, events, and temporal relations[C]//Proceedings of the 7th International Workshop on Semantic Evaluation. Stroudsburg, USA: ACL, 2013: 1–9. [76] MARNEFFE M, DOZAT T, SILVEIRA N, et al. Universal Stanford dependencies: A cross-linguistic typology[C]//Proceedings of the 9th International Conference on Language Resources and Evaluation. Paris, France: LREC, 2014: 4585–4592.













