
Retinal vascular image segmentation based on residual channel attention
-
摘要: 视网膜血管分割是诊断许多早期眼睛相关疾病的重要步骤。本文将整体嵌套边缘检测(holistically-nested edge detection,HED)网络应用于视网膜血管图像分割,并对该模型进行了一系列改进:针对现有方法识别边缘和精细血管能力不足的问题,引入了一种新的改进的高效通道注意(modified efficient chanel attention,MECA)模块,并且采用了双残差结构加深模型结构,提取更加精细的血管结构,为了防止模型加深产生过拟合问题,引入了结构化丢弃模块。为了进一步提高模型的灵敏度,本文在HED网络的特征融合阶段加入融合了MECA模块的短连接结构。实验表明,所提网络的灵敏度相比于目前最先进的方法有了明显提升,这说明本文所提方法具有最先进的识别视网膜血管的能力。Abstract: Segmentation of retinal blood vessels is an important step in the diagnosis of many early eye-related diseases. In this paper, the holistically-nested edge detection (HED) network is applied to retinal vascular image segmentation, and a series of improvements are made to the model: a new modified efficient channel attention (MECA) module is introduced to address the lack of ability of existing methods to identify edges and fine vessels, and a double residual structure is used to deepen the model structure to extract finer vascular structures. A structured DropBlock module is introduced to prevent overfitting problems from model deepening. In order to further improve sensitivity of the model, a short connection structure incorporating the MECA module is added in the feature fusion phase of the HED network. Experiments show that compared with the current state-of-the-art methods, the sensitivity of the proposed network is significantly improved, which indicates that the proposed method has the state-of-the-art ability to identify retinal vessels.
-
视网膜血管分割在眼相关疾病的早期诊断中具有重要意义,通过观察眼底血管系统,可以很容易地诊断和跟踪许多疾病(如糖尿病和高血压)。在临床实践中,视网膜血管系统通常由眼科医生根据眼底图像手动分割。这种手动分割是一项烦琐、费力且耗时的任务。为了减少人工分割的工作量并提高视网膜血管分割的准确性、处理速度和再现性,大量的研究工作致力于开发全自动或半自动的视网膜血管分割方法。然而,视网膜血管有许多细小而脆弱的血管,而且这些血管紧密相连,视网膜血管树结构相当复杂。
现有的方法可以通过是否使用了人工预先标注血管信息分为有监督方法和无监督方法。大多数无监督方法都是基于血管固有的特征的,主要包括形态学方法[1-2]、匹配滤波方法[3]、血管跟踪方法[4]。
视网膜血管分割的监督方法是基于二进制像素分类,即预测像素属于血管类还是非血管类。机器学习方法包括两个步骤:第1步,手工制作特征来捕捉目标像素的内在特征,Staal等[5]提出了一种基于脊的特征提取方法,该方法利用了血管的细长结构,Soares等[6]利用多尺度2D Gabor小波变换进行特征提取;第2步,使用诸如神经网络[7]、支持向量机[8]和随机森林[9]等各种分类器与从局部斑块提取的手工特征结合使用,用于对斑块的中心像素进行分类。上述监督方法依赖于由专家设计的相关特征表示,这通常需要复杂的特征设计过程和丰富的特征设计经验。
为了解决这些问题,基于深度学习的方法被用于视网膜血管的自动分割,并取得了很好的结果[10-16]。Oliveira等[10]结合多尺度平稳小波变换和全卷积网络(FCN)分割眼底图像局部斑块内的视网膜血管。Zhang等[11]在U-Net中引入了基于边缘检测的机制,用来改进模型的性能。Wu等[12]介绍了一种用于视网膜血管分割的多尺度网络跟踪网络(MS-NFN)。Wang等[14]将通道注意机制应用于U-Net结构中的“跳跃连接”来进一步提高血管分割能力。在文献[15]中通道注意力机制只采用了平均池化用来聚集血管空间信息,但是最大池化同样收集了血管另一个重要的空间信息,用来推断更精细的通道方向注意力[16]。但是由于视网膜血管结构复杂,细小血管众多,而且有病理性结构(渗出物、出血、视盘)影响,导致现有网络结构的灵敏度(模型识别血管的能力)普遍不高。
为了解决以上问题,本文提出了一种基于残差通道注意力的改进HED网络模型用于视网膜血管分割。所提网络模型主要有以下4个特点:1)受文献[15]启发,本文改进了ECA模块,并将其命名为改进的高效通道注意力(modified efficient chanel attention,MECA),该模块在保持性能的同时大大降低了网络的复杂性;2)将传统的随机丢弃模块替换为结构化丢弃(DropBlock)模块,有效避免模型产生过拟合现象;3)将MECA模块加入残差结构中,提出了双残差通道注意力模块(DRCAM),充分考虑了特征图通道间的相关性,提高了模型识别微小血管的能力;4)在HED网络的特征融合阶段加入短连接结构,并把MECA模块也融入短连接结构中,充分降低低级语义信息中的噪声和进一步提高模型的灵敏度,即识别精细血管的能力。
1. 网络结构与算法原理
1.1 结构化丢弃模块
随机丢弃模块(Dropout)是一个被广泛采用的防止过拟合的方法之一,但是随机丢弃模块通常在全连接层使用,在卷积层起到的作用微乎其微。这是因为在卷积层中特征图相邻位置元素的特征信息差别很小,所以某个元素被丢弃掉时,该元素的语义信息仍然可以通过卷积网络流通过来。所以本文采用了DropBlock[17],这是一种结构化的随机丢弃模块。该结构把特征图的一小部分方块区域一起丢掉,如图1(b)所示,而不是随机的丢弃方块,如图1(c)所示。
 图 1 Dropout和DropBlock丢弃方块原理Fig. 1 Principle of discarding blocks about Dropout and DropBlock
图 1 Dropout和DropBlock丢弃方块原理Fig. 1 Principle of discarding blocks about Dropout and DropBlock 下载:
全尺寸图片
下载:
全尺寸图片
DropBlock模块主要有两个参数
$ {S_b} $ 和$ \gamma $ ,$ {S_b} $ 表示丢弃的方块的大小,$ \gamma $ 表示伯努利函数的概率。$ \gamma $ 通过如下公式得到$$ \gamma =\frac{(1-K) S_{f}^{2}}{S_{b}^{2}\left(S_{f}-S_{b}+1\right)^{2}} $$ (1) 式中:
$ {S_b} $ 表示丢弃的方块的大小,$ {S_f} $ 表示输入特征的大小,K表示保留方块的概率。1.2 改进高效通道注意力模块
SE(squeeze and excitation block)模块[18]就是最初的通道注意力(channel attention,CA)模块,该模块通过将输入的特征图进行全局平局池化然后进行激活,获得每个通道的权重,最后使用获得的权重对输入的特征图通道进行加权,从而抑制不重要的特征,增强重要的特征(例如细小的血管特征)。最近,一些研究采用了各种方法用来改进SE模块,然而这些方法在改进模块性能的同时不可避免的增加了模型的复杂度。文献[15]提出了一种高效通道注意力(efficient channel attention,ECA)模块,该模块利用一维卷积来避免SE模块在跨通道信息交流中的降维操作,从而在保持优越性能的同时大大降低了模型的复杂度。然而在ECA中只有平均池化用来聚集空间信息,但是最大池化同样收集了特征图的另一个重要的空间信息,可以用来推算更精细的通道注意力。
因此,本文设计了一种改进高效通道注意力(MECA)模块,该模块采用平均池化和最大池化两种方式来获得更精细的通道注意力,如图2所示。模块首先将输入特征图
$ F \in {{\bf{R}}^{H \times W \times C}} $ 通过平均池化和最大池化生成$ {F_{{\rm{mp}}}} \in {{\bf{R}}^{1 \times 1 \times C}} $ 和$ {F_{{\rm{ap}}}} \in {{\bf{R}}^{1 \times 1 \times C}} $ ,分别通过以下公式得到: 图 2 改进高效通道注意力模块Fig. 2 Modified efficient chanel attention module下载:
全尺寸图片
图 2 改进高效通道注意力模块Fig. 2 Modified efficient chanel attention module下载:
全尺寸图片
$$ {F}_{{\rm{mp}}}^{c}=\max\left({F}^{c}\left({i}\text{,}{j}\right)\right),0 < c < C,0 < i < H,0 < j < W $$ (2) $$ F_{{\text{ap}}}^c = \frac{1}{{H \times W}}\sum\limits_{\mu = 1}^H {\sum\limits_{j = 1}^W {{F^c}\left( {i,j} \right)} } ,0 < c < C $$ (3) 式中:H、W、C分别代表输入特征图的高度、宽度、通道数的数量,
$ {F}^{c}\left({i},{j}\right) $ 表示第C个通道特定位置的像素值。然后将两个生成的特征图通过一个共享权重的一维卷积层,获得两个输出特征向量,用来生成一个通道注意力图
${M} \in {{\bf{R}}^{1 \times 1 \times C}}$ 。$$ M\left( F \right) = \sigma \left( {{\text{CONV}}\left( {{F_{{\text{ap}}}}} \right) + {\text{CONV}}\left( {{F_{{\text{mp}}}}} \right)} \right) $$ (4) 式中:CONV (·)代表一维卷积层,
$ \sigma $ (·)代表激活函数。MECA在本文中使用的一维卷积的核被设置为3(k=3),即每使用一个MECA只增加3个参数,这直接证明了MECA是一个非常轻量级的模块。1.3 双残差通道注意力模块
在识别视网膜血管结构时,浅层网络可能会限制网络提取所需血管特征的能力。本文认为构建更深层次的神经网络可以学习更复杂的血管特征,所以构建了双残差结构来代替HED网络中的原始卷积单元,用来提取更加精细的血管结构。该结构由ReLU激活、批处理归一化(BN)和卷积层组成的预激活残差块构成。但是单纯增加网络层数可能会阻碍训练,还可能出现退化和过拟合问题,所以将传统的随机丢弃模块替换为性能更强的结构化丢弃模块。
MECA模块通过自动学习来学习每个特征通道的权重,并使用获得的权重来增强本文需要的血管特征和抑制对视网膜血管分割任务不重要的特征。换句话说,MECA可以提取通道之间的通道统计,从而进一步增强网络的区分视网膜血管的能力。
基于上述工作本文提出了双残差通道注意力模块(double residual channel attention module,DRCAM),如图3所示。
 图 3 双残差通道注意力模块Fig. 3 Double residual channel attention module下载:
全尺寸图片
图 3 双残差通道注意力模块Fig. 3 Double residual channel attention module下载:
全尺寸图片
1.4 网络结构
图4显示了本文所提模型的详细结构,该模型是从传统HED网络改进而来。图中虚线框内为预训练部分,将原始的卷积块替换为DRCAM模块,并将传统的池化层替换为扩张卷积层,这么做的主要目的是为了在增加感受野的同时,保证特征图的输入尺寸不变。方便后续进行特征融合。图4虚线框外的部分为侧输出部分,将经过预训练的特征图通过16个1×1的卷积进行融合,然后通过一个MECA模块,最后通过由高到低短连接结构,将具有不同级别的语义信息的特征图进行特征融合,这么做能够使模型充分利用不同级别的语义信息进行训练,减少低级语义信息中的噪声。
 图 4 本文所提网络模型的整体结构Fig. 4 Overall structure of the proposed network module下载:
全尺寸图片
图 4 本文所提网络模型的整体结构Fig. 4 Overall structure of the proposed network module下载:
全尺寸图片
2. 实验及结果分析
2.1 数据集和实验参数配置
本文使用DRIVE和STARE两个公共的视网膜眼底图像数据集来评估本文提出的模型。 DRIVE数据集包含40幅分辨率为565×584的彩色眼底图像。20幅图像用来训练,20幅图像用来测试。STARE数据集包含20幅605×700的彩色眼底图像。由于STARE数据集未划分训练集和测试集,本文采用文献[19]中的留一法进行交叉验证。
由于DRIVE和STARE数据集数据量很少,为了避免模型在训练过程中产生过拟合现象,需要对以上两个数据集进行数据增强。首先将预处理后的图像进行−90°~90°随机旋转,然后将图片随机进行水平或垂直翻转,概率各为50%。最后采用滑窗方式对图像进行随机切片,在每张眼底图像中裁剪出5000个48×48的重叠图像块。采用这种数据增强方式,以上两个数据集将会获得1200000个小图像块,取前90%用于网络训练,后10%用于验证。
训练细节:预训练阶段,优化算法为Adam,所有可以训练的卷积核都采用HED初始化方法初始化参数,epoch为150,初始学习率设置为0.01,在连续6次迭代以后损失函数都没有变化,则学习率衰减为原来的一半。输出阶段使用预训练阶段训练好的模型参数继续进行学习,epoch为100,初始学习率设置为0.001,在连续5次迭代以后损失函数都没有变化,则学习率衰减为原来的一半。
结构化丢弃模块的丢弃方块的大小设置为7,为了使模型的性能达到最好,根据经验本文将DRIVE数据集中的结构化丢弃模块的方块保留概率设置为0.85,将STARE数据集中的结构化丢弃模块的方块保留概率设置为0.78。
2.2 图像预处理
视网膜血管图像存在亮度不均匀以及血管与背景之间的对比度较低等问题,为了使模型能够更好地捕获细小血管的更多特征,必须对视网膜血管图像进行预处理。首先提取RGB图像的3个通道,受文献[20]启发,本文采用红绿通道比例为3∶7进行组合并进行灰度变换。然后归一化眼底视网膜灰度图像,采用对比度受限的自适应直方图均衡化(CLAHE)最后进行伽马校正。图5为预处理前后结果图。
 图 5 预处理结果Fig. 5 Typical image after preprocessing下载:
全尺寸图片
图 5 预处理结果Fig. 5 Typical image after preprocessing下载:
全尺寸图片
2.3 性能评价指标
为了评估本文采用的模型的性能,采用了以下指标:准确度
$ {A_{{\text{cc}}}} $ 、灵敏度$ {s_e} $ 、特异性$ {s_p} $ 和受试者工作特征曲线ROC的曲线下面积AUC。AUC可用于衡量分割性能,因为它是评估两分类的指标,并且具有不受不平衡数据影响的特点。如果AUC值为1,则表示分割无瑕疵。2.4 结果分析
本文在HED网络结构上进行了5组消融实验,用来验证本文提出的改进方法和网络结构是否有效。模型1在原始的HED网络结构中加入残差结构和底部短连接结构;模型2在模型1的基础上加入了通道注意力;模型3则采用了改进高效通道注意力代替原始的通道注意力模块;模型4在模型3的基础上加入了DRCAM;模型5也就是本文最终采用的方法,在底部短连接结构中也加入改进高效通道注意力模块,并把结构化丢弃模块的丢弃方块的大小设置为7,以达到最好的分割性能。
从表1中可以得出:1)原始的HED网络主要用来进行边缘检测,通过对网络结构进行一些改进,该网络在视网膜血管图像分割领域也有不错的表现;2)通过引入普通的通道注意力,网络的各项性能仅有略微提升;3)通过在网络中加入MECA模块,模型的灵敏度大幅提升,在DRIVE和STARE数据集上分别提升了2.18%和2.96%,其他各项指标均有不同幅度的提升,这表明本文提出的MECA模块是有效的;4)通过采用DRCAM结构,模型的灵敏度进一步提高,虽然特异性略有降低,但是可以通过调整结构化丢弃模块的参数来优化;5)通过优化结构化丢弃模块和进一步引入MECA模块使本模型在灵敏度上取得了最好的性能,在其他指标上也与最先进的方法相差无几。
表 1 DRIVE和STARE数据集上的消融实验结果Table 1 Results of ablation study on DRIVE and STARE dataset% 模型 DRIVE STARE $ {s_e} $ $ {s_p} $ $ {A_{{\text{cc}}}} $ AUC $ {s_e} $ $ {s_p} $ $ {A_{{\text{cc}}}} $ AUC 模型1 78.26 97.14 95.09 97.56 77.74 96.69 95.13 97.21 模型2 79.16 97.31 95.47 97.83 78.24 97.01 95.21 97.38 模型3 81.34 97.69 95.93 98.22 81.20 98.23 95.73 97.91 模型4 82.65 97.51 96.05 98.16 82.97 97.97 95.95 98.23 模型5 83.56 98.07 96.53 98.56 84.52 98.78 96.43 98.55 图6给出了5组模型在DRIVE数据集一副彩色视网膜血管图像的分割结果和专家的手动分割结果图。通过与专家的手动分割结果图对比,可以看出通过引入MECA模块,模型可以识别出更精确的微小血管,通过优化结构化丢弃模块参数和进一步引用MECA模块,模型识别出的微小血管更加清晰,并且识别出的血管结构更加完整。
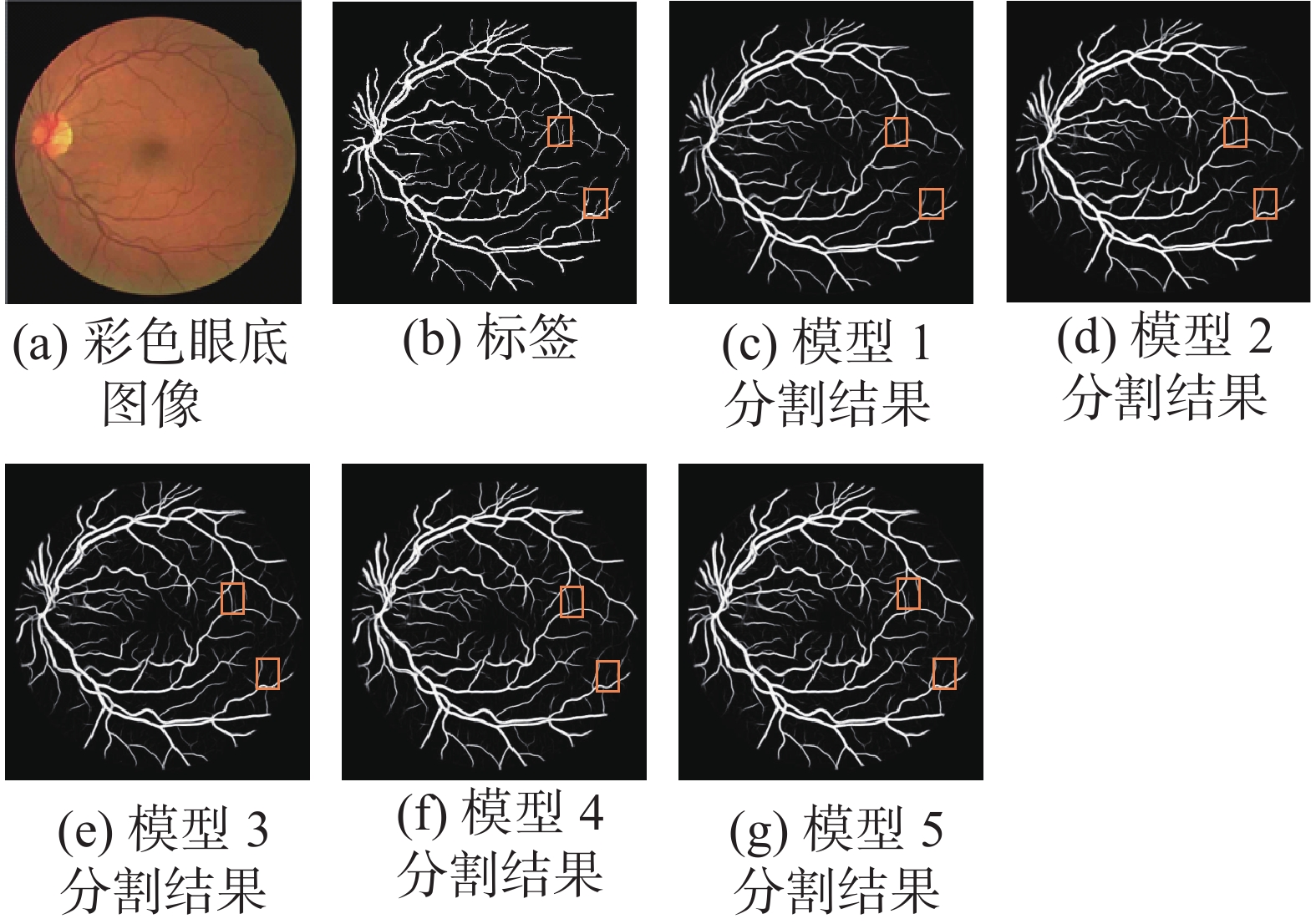 图 6 消融实验分割结果Fig. 6 Segmentation results of ablation experiments下载:
全尺寸图片
图 6 消融实验分割结果Fig. 6 Segmentation results of ablation experiments下载:
全尺寸图片
在表2和表3中,本文总结了每个模型的发布年份以及它们在DRIVE、和STARE数据集上的性能。结果表明,本文所提方法在DRIVE和STARE数据集上的综合分割性能更好,虽然特异性
$ {s_p} $ 和准确度$ {A_{{\text{cc}}}} $ 都略低于目前的最先进方法,但是灵敏度$ {s_e} $ 有大幅度的提升,分别高于目前最先进方法1.18%、0.96%。这说明本文所提方法具有最先进的识别视网膜微小血管的能力,并且AUC也略高于其他先进方法。表 2 本文方法和其他方法在DRIVE数据集上结果Table 2 Results of the proposed method with other methods on DRIVE dataset% 类型 方法 年份 $ {s_e} $ $ {s_p} $ $ {A_{{\text{cc}}}} $ AUC 无监督方法 文献[1] 2006 69.96 97.30 94.40 — 文献[3] 2011 72.60 97.56 94.97 — 文献[2] 2019 79.10 97.00 95.70 — 有监督方法 文献[5] 2004 — — 95.16 96.14 文献[6] 2016 78.34 97.99 96.54 — 文献[21] 2018 77.35 98.57 96.38 98.33 文献[22] 2018 80.36 97.78 95.56 98.00 文献[23] 2020 83.34 98.97 96.63 97.34 本文算法 2021 84.52 98.78 96.43 98.55 表 3 本文方法和其他方法在STARE数据集上结果Table 3 Results of the proposed method with other methods on STARE dataset% 类型 方法 年份 se sp Acc AUC 无监督方法 文献[1] 2006 73.44 97.64 94.52 — 文献[3] 2011 74.10 97.51 94.34 — 文献[2] 2019 73.60 98.10 96.00 — 有监督方法 文献[5] 2004 71.94 97.73 94.41 89.84 文献[6] 2016 78.14 97.88 96.12 — 文献[12] 2018 78.44 98.18 95.67 98.07 文献[14] 2019 79.40 98.16 95.67 97.72 文献[24] 2019 81.26 97.88 95.94 97.96 文献[25] 2020 80.68 98.38 96.56 98.12 文献[26] 2021 81.20 98.32 96.58 98.38 文献[27] 2021 82.60 98.24 96.85 本文方法 2021 83.56 98.07 96.53 98.56 3. 结束语
本文提出了一种基于残差通道注意力的视网膜血管图像分割方法,首先,本文针对最近提出的高效通道注意力(ECA)模块进行了一些改进,提出了改进高效通道注意力模块(MECA),这样可以使神经网络有效地提取更精细的血管结构。然后加深了HED网络结构,提出了双残差结构,并用结构化丢弃模块替换了原始的随机丢弃模块,把MECA嵌入残差结构中,进一步加强了模型识别精细血管的能力。最后,在HED网络结构的特征融合阶段加入短连接结构,并把MECA模块融入到短连接结构中来进一步增强模型的灵敏度。通过在DRIVE和STARE数据集上的实验表明,所提方法的综合分割性能最优,且在检测血管的灵敏度性能方面明显大于目前先进的方法,灵敏度的提高对早期眼部相关疾病的临床检测具有重要意义,这说明本文所提方法具有很强的应用潜力。本文所提方法尚未考虑血管的连通性,这也将是下一步工作的重点。
-
图 1 Dropout和DropBlock丢弃方块原理
Fig. 1 Principle of discarding blocks about Dropout and DropBlock
下载:
全尺寸图片
图 2 改进高效通道注意力模块
Fig. 2 Modified efficient chanel attention module
下载:
全尺寸图片
图 3 双残差通道注意力模块
Fig. 3 Double residual channel attention module
下载:
全尺寸图片
图 4 本文所提网络模型的整体结构
Fig. 4 Overall structure of the proposed network module
下载:
全尺寸图片
图 5 预处理结果
Fig. 5 Typical image after preprocessing
下载:
全尺寸图片
图 6 消融实验分割结果
Fig. 6 Segmentation results of ablation experiments
下载:
全尺寸图片
表 1 DRIVE和STARE数据集上的消融实验结果
Table 1 Results of ablation study on DRIVE and STARE dataset
% 模型 DRIVE STARE $ {s_e} $ $ {s_p} $ $ {A_{{\text{cc}}}} $ AUC $ {s_e} $ $ {s_p} $ $ {A_{{\text{cc}}}} $ AUC 模型1 78.26 97.14 95.09 97.56 77.74 96.69 95.13 97.21 模型2 79.16 97.31 95.47 97.83 78.24 97.01 95.21 97.38 模型3 81.34 97.69 95.93 98.22 81.20 98.23 95.73 97.91 模型4 82.65 97.51 96.05 98.16 82.97 97.97 95.95 98.23 模型5 83.56 98.07 96.53 98.56 84.52 98.78 96.43 98.55 表 2 本文方法和其他方法在DRIVE数据集上结果
Table 2 Results of the proposed method with other methods on DRIVE dataset
% 类型 方法 年份 $ {s_e} $ $ {s_p} $ $ {A_{{\text{cc}}}} $ AUC 无监督方法 文献[1] 2006 69.96 97.30 94.40 — 文献[3] 2011 72.60 97.56 94.97 — 文献[2] 2019 79.10 97.00 95.70 — 有监督方法 文献[5] 2004 — — 95.16 96.14 文献[6] 2016 78.34 97.99 96.54 — 文献[21] 2018 77.35 98.57 96.38 98.33 文献[22] 2018 80.36 97.78 95.56 98.00 文献[23] 2020 83.34 98.97 96.63 97.34 本文算法 2021 84.52 98.78 96.43 98.55 表 3 本文方法和其他方法在STARE数据集上结果
Table 3 Results of the proposed method with other methods on STARE dataset
% 类型 方法 年份 se sp Acc AUC 无监督方法 文献[1] 2006 73.44 97.64 94.52 — 文献[3] 2011 74.10 97.51 94.34 — 文献[2] 2019 73.60 98.10 96.00 — 有监督方法 文献[5] 2004 71.94 97.73 94.41 89.84 文献[6] 2016 78.14 97.88 96.12 — 文献[12] 2018 78.44 98.18 95.67 98.07 文献[14] 2019 79.40 98.16 95.67 97.72 文献[24] 2019 81.26 97.88 95.94 97.96 文献[25] 2020 80.68 98.38 96.56 98.12 文献[26] 2021 81.20 98.32 96.58 98.38 文献[27] 2021 82.60 98.24 96.85 本文方法 2021 83.56 98.07 96.53 98.56 -
[1] MENDONCA A M, CAMPILHO A. Segmentation of retinal blood vessels by combining the detection of centerlines and morphological reconstruction[J]. IEEE transactions on medical imaging, 2006, 25(9): 1200–1213. doi: 10.1109/TMI.2006.879955 [2] FAN Zhun, LU Jiewei, WEI Caimin, et al. A hierarchical image matting model for blood vessel segmentation in fundus images[J]. IEEE transactions on image processing, 2019, 28(5): 2367–2377. doi: 10.1109/TIP.2018.2885495 [3] YOU Xinge, PENG Qinmu, YUAN Yuan, et al. Segmentation of retinal blood vessels using the radial projection and semi-supervised approach[J]. Pattern recognition, 2011, 44(10/11): 2314–2324. [4] AL-DIRI B, HUNTER A, STEEL D. An active contour model for segmenting and measuring retinal vessels[J]. IEEE transactions on medical imaging, 2009, 28(9): 1488–1497. doi: 10.1109/TMI.2009.2017941 [5] STAAL J, ABRAMOFF M D, NIEMEIJER M, et al. Ridge-based vessel segmentation in color images of the retina[J]. IEEE transactions on medical imaging, 2004, 23(4): 501–509. doi: 10.1109/TMI.2004.825627 [6] SOARES J V B, LEANDRO J J G, CESAR R M, et al. Retinal vessel segmentation using the 2-D Gabor wavelet and supervised classification[J]. IEEE transactions on medical imaging, 2006, 25(9): 1214–1222. doi: 10.1109/TMI.2006.879967 [7] FAN Zhun, MO Jiajie. Automated blood vessel segmentation based on de-noising auto-encoder and neural network[C]//2016 International Conference on Machine Learning and Cybernetics. Jeju: IEEE, 2017: 849−856. [8] 韩璐,毕晓君. 多尺度特征融合网络的视网膜OCT图像分类[J]. 智能系统学报, 2022, 17(2): 360–367. HAN Lu, BI Xiaojun. Retinal optical coherence tomography image classification based on multiscale feature fusion[J]. CAAI transactions on intelligent systems, 2022, 17(2): 360–367. [9] FAN Zhun, RONG Yibiao, LU Jiewei, et al. Automated blood vessel segmentation in fundus image based on integral channel features and random forests[C]//2016 12th World Congress on Intelligent Control and Automation. Guilin: IEEE, 2016: 2063−2068. [10] OLIVEIRA A, PEREIRA S, SILVA C A. Retinal vessel segmentation based on fully convolutional neural networks[J]. Expert systems with applications, 2018, 112: 229–242. doi: 10.1016/j.eswa.2018.06.034 [11] ZHANG Yishuo, CHUNG A C S. Deep supervision with additional labels for retinal vessel segmentation task[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2018: 83−91. [12] WU Yicheng, XIA Yong, SONG Yang, et al. Multiscale network followed network model for retinal vessel segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2018: 119−126. [13] FU Huazhu, XU Yanwu, LIN S, et al. DeepVessel: retinal vessel segmentation via deep learning and conditional random field[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2016: 132−139. [14] WANG Bo, QIU Shuang, HE Huiguang. Dual encoding U-net for retinal vessel segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2019: 84−92. [15] WANG Qilong, WU Banggu, ZHU Pengfei, et al. ECA-net: efficient channel attention for deep convolutional neural networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 11531−11539. [16] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the European conference on computer vision. Munich: Springer, 2018: 3−19. [17] GUO Changlu, SZEMENYEI M, PEI Yang, et al. SD-unet: a structured dropout U-net for retinal vessel segmentation[C]//2019 IEEE 19th International Conference on Bioinformatics and Bioengineering. Athens: IEEE, 2019: 439−444. [18] HU Jie, SHEN Li, SUN Gang. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132−7141. [19] ORLANDO J I, PROKOFYEVA E, BLASCHKO M B. A discriminatively trained fully connected conditional random field model for blood vessel segmentation in fundus images[J]. IEEE transactions on biomedical engineering, 2017, 64(1): 16–27. doi: 10.1109/TBME.2016.2535311 [20] LISKOWSKI P, KRAWIEC K. Segmenting retinal blood vessels with deep neural networks[J]. IEEE transactions on medical imaging, 2016, 35(11): 2369–2380. doi: 10.1109/TMI.2016.2546227 [21] YAN Zengqiang, YANG Xin, CHENG K T. A three-stage deep learning model for accurate retinal vessel segmentation[J]. IEEE journal of biomedical and health informatics, 2019, 23(4): 1427–1436. doi: 10.1109/JBHI.2018.2872813 [22] 吴晨玥, 易本顺, 章云港, 等. 基于改进卷积神经网络的视网膜血管图像分割[J]. 光学学报, 2018, 38(11): 133–139. WU Chenyue, YI Benshun, ZHANG Yungang, et al. Retinal vessel image segmentation based on improved convolutional neural network[J]. Acta optica sinica, 2018, 38(11): 133–139. [23] YANG Tiejun, WU Tingting, LI Lei, et al. SUD-GAN: deep convolution generative adversarial network combined with short connection and dense block for retinal vessel segmentation[J]. Journal of digital imaging, 2020, 33(4): 946–957. doi: 10.1007/s10278-020-00339-9 [24] MOU Lei, CHEN Li, CHENG Jun, et al. Dense dilated network with probability regularized walk for vessel detection[J]. IEEE transactions on medical imaging, 2020, 39(5): 1392–1403. doi: 10.1109/TMI.2019.2950051 [25] 张赛, 李艳萍. 基于改进HED网络的视网膜血管图像分割[J]. 光学学报, 2020, 40(6): 76–85. ZHANG Sai, LI Yanping. Retinal vascular image segmentation based on improved HED network[J]. Acta optica sinica, 2020, 40(6): 76–85. [26] 罗文劼, 韩国庆, 田学东. 多尺度注意力解析网络的视网膜血管分割方法[J]. 激光与光电子学进展, 2021, 58(20): 439–452. LUO Wenjie, HAN Guoqing, TIAN Xuedong. Retinal vessel segmentation method based on multi-scale attention analytic network[J]. Laser & optoelectronics progress, 2021, 58(20): 439–452. [27] ATLI İ, GEDIK O S. Sine-Net: a fully convolutional deep learning architecture for retinal blood vessel segmentation[J]. Engineering science and technology, an international journal, 2021, 24(2): 271–283. doi: 10.1016/j.jestch.2020.07.008























