
Deep multiscale fusion attention residual network for facial expression recognition
-
摘要: 针对人脸表情呈现方式多样化以及人脸表情识别易受光照、姿势、遮挡等非线性因素影响的问题,提出了一种深度多尺度融合注意力残差网络(deep multi-scale fusion attention residual network, DMFA-ResNet)。该模型基于ResNet-50残差网络,设计了新的注意力残差模块,由7个具有三条支路的注意残差学习单元构成,能够对输入图像进行并行多卷积操作,以获得多尺度特征,同时引入注意力机制,突出重点局部区域,有利于遮挡图像的特征学习。通过在注意力残差模块之间增加过渡层以去除冗余信息,简化网络复杂度,在保证感受野的情况下减少计算量,实现网络抗过拟合效果。在3组数据集上的实验结果表明,本文提出的算法均优于对比的其他先进方法。Abstract: This paper proposes a deep multiscale fusion attention residual network based on the ResNet-50 model to solve the problems of the diversification of facial expression presentation and the susceptibility of facial expression recognition to nonlinear factors, such as illumination, posture, and occlusion. A novel attention residual module consisting of seven attention residual learning units with three branches is designed to perform multiple convolution operations on the input image in parallel and obtain multiscale features. To highlight important local areas, the attention mechanism is introduced simultaneously, which is conducive to the feature learning of the occluded images. Furthermore, a novel transition layer is added between the attention residual modules to remove redundant information, simplify the network complexity, reduce the amount of calculation while ensuring the receptive field, and realize the anti-overfitting effect of the network. Experimental results on three datasets demonstrate that the proposed algorithm is superior to other advanced methods.
-
情绪包含大量的情感信息,当人们面对面交流时,情绪会自动或不自觉地通过面部表情表现出来[1]。随着人工智能技术的飞速发展,人脸表情识别(FER)已成为计算机图像处理中一个重要的研究课题。
人脸表情识别主要包括预处理、特征提取和分类识别3个部分[2]。其中,算法识别精度高低主要由特征提取方法决定。人脸表情特征提取方法主要分为基于传统特征提取的方法和基于深度学习的方法[3]。传统的特征提取方法主要包括局部二值模式(LBP)[4]、类Haar特征[5]、Gabor小波变换[6]和方向梯度直方图(HOG)等。Li等[7]基于LBP方法提出了一种使用三个正交平面的局部二值基线方法(LBP-TOP),一定程度上消除了光照变化的影响,但旋转不变性使得算子对方向信息过于敏感。为了解决这一问题,Rivera等[8]学者提出的局部特征描述符LDN利用梯度信息使得算子对光照变化和噪声具有较强的鲁棒性。然而,传统的表情识别算法无法有效处理由于不同姿势、遮挡等引起的非线性面部外观变化,难以有效提高分类水平。
近年来,深度学习凭借其优异的特征提取能力逐步应用于人脸表情识别领域。Kim等[9]学者对适用于大规模图像识别的VGG-face模型进行渐进式微调识别人脸表情,但大多数人脸表情数据库样本较少导致该网络易出现过拟合问题。An等[10]学者提出了一种基于MMN线性激活函数的自适应模型参数初始化方法,可有效克服过拟合问题,但面对含有大量表情无关因素时算法鲁棒性较差。Xie等[11]学者提出了一种多路径变异抑制网络(MPVS-NET),但该网络速度较慢且不宜收敛。由于模糊的面部表情、低质的面部图像及注释者的主观性带来的不确定性,对定性的大规模面部表情数据集进行标注是非常困难的。针对这一问题,Wang等[12]学者提出了一种能有效抑制不确定性的自修复网络(SCN),防止网络过度拟合不确定的人脸图像。一般来说,深层网络更易提取到具有丰富语义信息的深层特征。但过深的网络容易出现梯度爆炸或梯度消失现象。针对这一问题,He等[13]学者提出了深度残差网络(ResNet),利用短路链接使得梯度正常回传,较好地解决了网络退化问题。但训练参数量仍旧较大,且残差网络并没有考虑不同尺度特征之间的相互关系对特征识别的影响,导致大量有效特征丢失。
上述研究均使用完整特征图作为特征输入,然而在实际分类任务中,特征的作用程度是不同的。为了突出对特征识别有效的信息,一些研究引入了注意力机制。Li等[14]学者提出了一种具有注意力机制的CNN网络结构可识别脸部遮挡区域,但网络依赖于人脸关键点检测,遮挡面积较大时,关键点难以与人脸数据集生成映射。在此基础上,Liu等[15]学者提出了一种条件CNN增强型随机森林算法(CoNERF),从显著引导的人脸区域中提取深层特征,抑制光照、遮挡和低分辨率带来的影响。然而上述方法仍保留了较多的冗余信息,且均为完整网络结构,不易迁移。Hu等[16]学者采用全新特征重标定方式提出一种通道注意力网络(SE-Net),显示建模特征通道之间的相互依赖关系,进而提升有用特征并抑制用处不大的特征,且能够直接集成到现有网络中,计算代价小,没有冗余信息。
针对上述问题,本文提出一种深度多尺度融合注意力残差网络(deep multi-scale fusion attention residual network, DMFA-ResNet),主要改进包括以下3个方面:
1)设计了一个由7个注意力残差学习单元构成的注意力残差模块,注意力残差学习单元由2条包含卷积层的支路和1个短路链接构成,将融合后的特征经过注意力机制,对输入图像进行并行多卷积操作,以获得图像多尺度特征,突出局部重点区域,有利于遮挡图像特征学习;
2) 提出多尺度融合模块,网络整体将各个注意力残差模块的特征输出进行多尺度融合,以获取更丰富的图像特征;
3)在网络模型中增加过渡层以去除冗余信息,在保证感受野的情况下简化网络复杂度。并使用全局平均池化+ Dropout的设计减少参数运算,使网络具有更好的抗过拟合性能。
1. DMFA-ResNet算法
1.1 ResNet网络结构
ResNet网络通过引入残差模块,在算法前向传播过程中使得卷积层之间形成跳跃连接,实现对输入、输出的恒等映射,并采用1×1、3×3的小卷积核,在解决网络退化问题的同时进一步加深网络,ResNet-50的基本残差学习单元如图1所示。
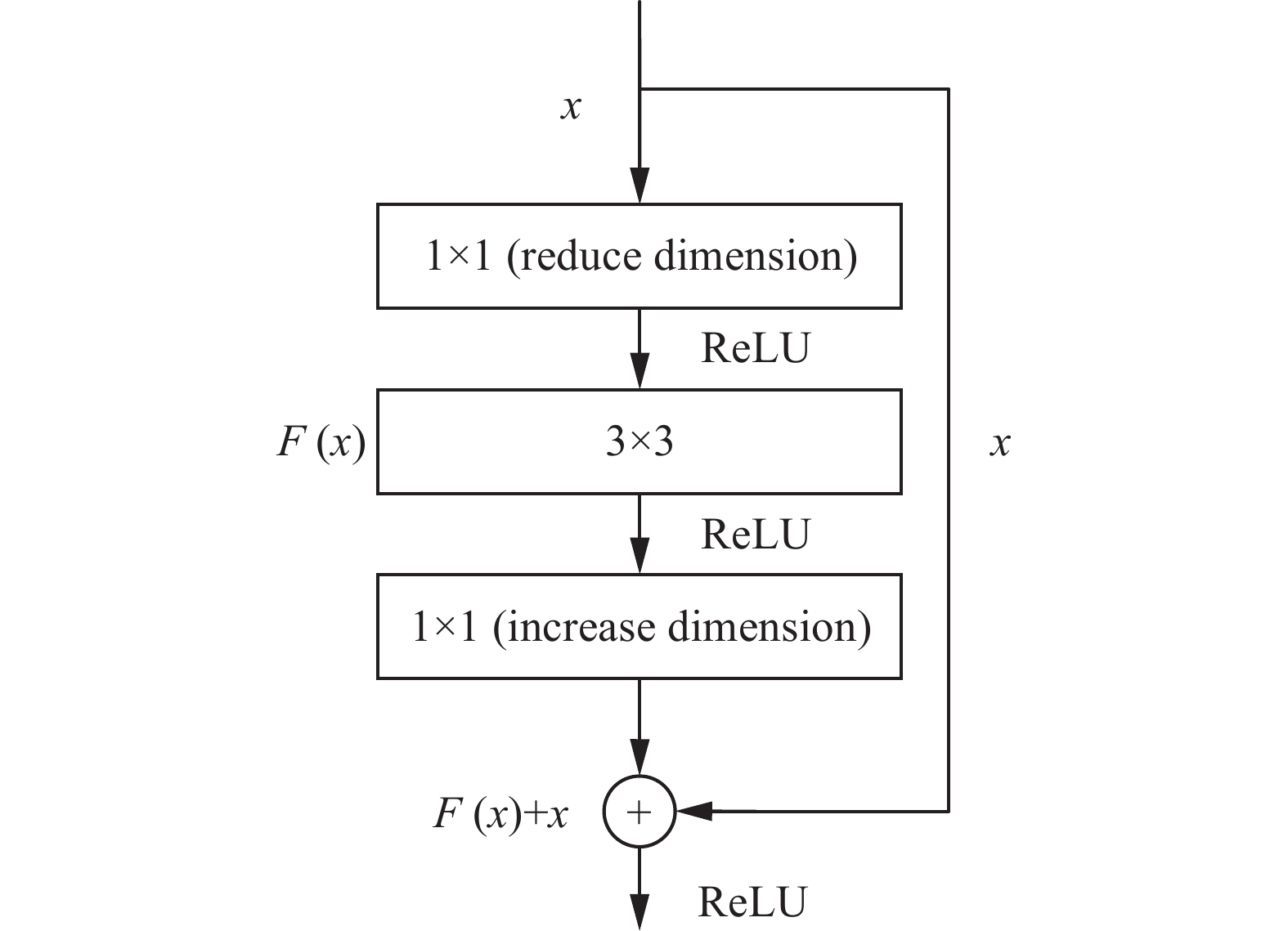 图 1 残差学习单元Fig. 1 Residual learning unit
图 1 残差学习单元Fig. 1 Residual learning unit 下载:
全尺寸图片
下载:
全尺寸图片
图1中,
$ x $ 表示输入,$ F(x) $ 表示残差映射,残差单元的输出为$$ H(x) = F(x) + x $$ (1) 当残差
$ F(x) = 0 $ ,残差学习单元的功能就是恒等映射;则深层$ L $ 的输出为$$ H({x_L}) = {x_l} + \sum_{i = l}^{L - 1} {F({x_i}} ) $$ (2) 其反向梯度为
$$ \frac{{\partial {\rm{LOSS}}}}{{\partial {x_l}}} = \frac{{\partial {\rm{LOSS}}}}{{\partial H({x_L})}} $$ (3) 其中
$\dfrac{{\partial {\rm{LOSS}}}}{{\partial {x_l}}}$ 为损失函数的梯度下降。1.2 SE-Net注意力模块
SE-Net是Hu等[16]学者提出的一种通道注意力网络,核心为特征压缩操作
$ {F_{sq}} $ 和特征激励操作$ {F_{ex}} $ 。$ {F_{sq}} $ 从通道维度将$ \left[ {H,W,C} \right] $ 的输入特征图压缩为$ \left[ {1,1,C} \right] $ 的输出特征图,使得每个二维特征通道转换为一个具有全局感受野的实数。$ {F_{ex}} $ 通过对每个通道生成权重,显式建模特征通道间的相关性,并逐通道加权到原始特征图上,完成通道维度上的特征重标定,加强关键特征,抑制非显著特征,从而提高网络的整体表征能力。2. 深度多尺度融合注意力残差网络
基于ResNet-50残差网络,本文提出一种深度多尺度融合注意力残差网络(DMFA-ResNet),该网络由注意力残差模块(attention residual module, ARM)、多尺度特征融合模块、过渡层、全局平均池化层、Dropout和Softmax分类层构成,网络结构如图2所示。
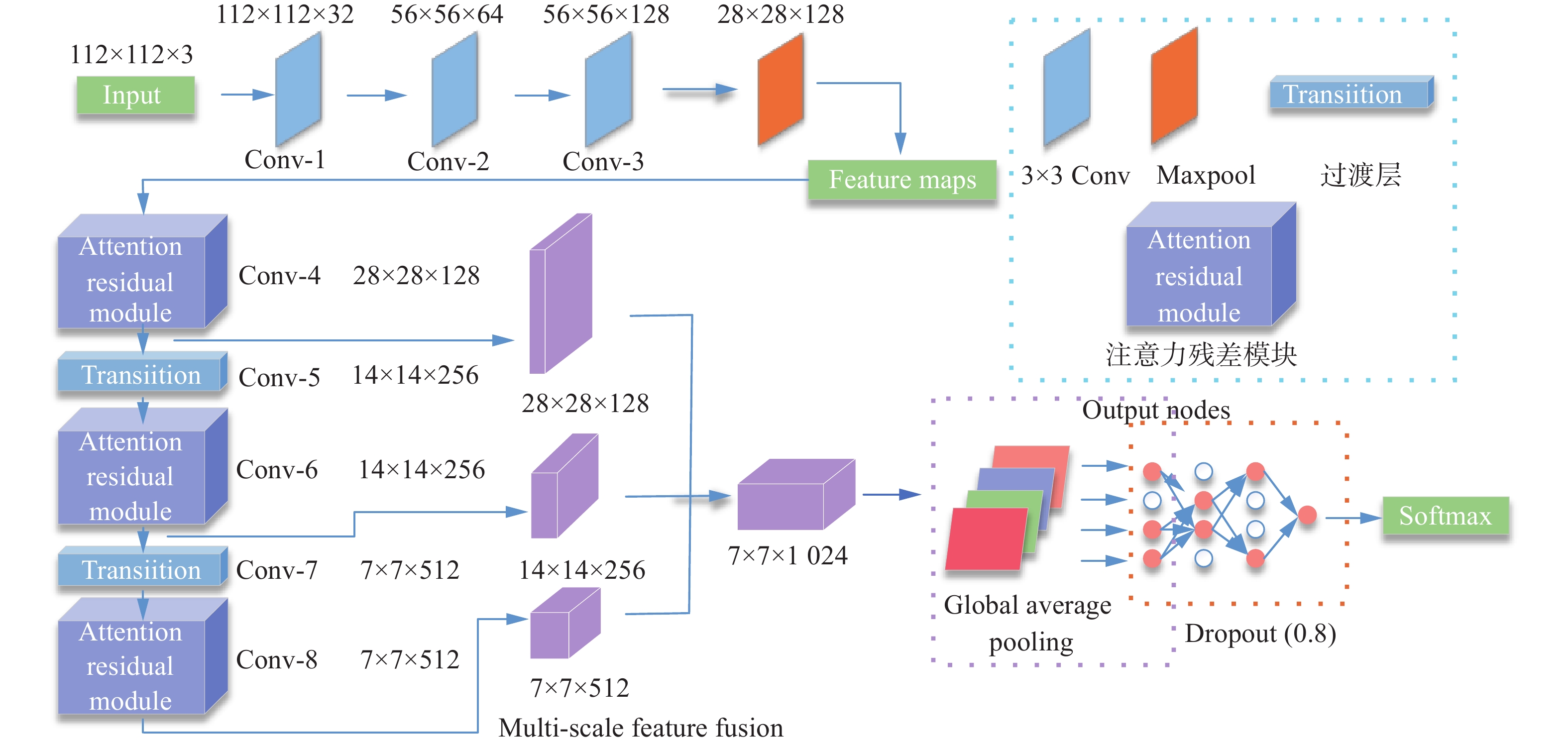 图 2 DMFA-ResNet结构图Fig. 2 DMFA-ResNet structure下载:
全尺寸图片
图 2 DMFA-ResNet结构图Fig. 2 DMFA-ResNet structure下载:
全尺寸图片
深度神经网络的输入图片一般较大,为避免后续计算量爆炸,需要将输入图片进行下采样后再输入进卷积神经网络。原ResNet网络将输入图像经过一个7×7大卷积层和最大池化层后,再输入进后续残差模块。7×7大卷积层和最大池化层将输入图片的分辨率从224×224下采样至56×56,在减少计算量的同时最大程度保留了原始图像细节信息。DMFA-ResNet使用3个3×3小卷积层代替原7×7大卷积层,在保证与原网络层相同感受野的前提下,进一步提升了网络深度,使得网络能够提取到更深层次的语义信息。
2.1 注意力残差模块
注意力残差模块(ARM)由7个具有3条支路的注意力残差学习单元构成。注意力残差学习单元由两条残差学习支路、一条恒等映射支路和SE-Net注意力模块构成。为了使输入经过3×3卷积层后的特征图维数相同,通过残差学习支路的第一个1×1卷积层对输入进行降维。通过对输入图像进行并行的多卷积操作,使得网络能够提取到不同深度的多尺度表情图像特征。再将这两条残差学习支路所提取到的特征采用Concat方法进行融合,即将两个需要融合的特征图的通道进行拼接,将两条残差学习支路输出的特征图融合后的特征通过1×1卷积进行升维,确保输入、输出的维数相等。最后利用注意力机制突出重点局部区域,获得图像更准确的特征以提高识别准确率,有利于遮挡图像的特征学习。注意力残差模块和注意力残差单元的结构图分别如图3、4所示。
 图 3 注意力残差模块Fig. 3 Attention residual module下载:
全尺寸图片
图 3 注意力残差模块Fig. 3 Attention residual module下载:
全尺寸图片
 图 4 注意力残差单元Fig. 4 Attention residual unit下载:
全尺寸图片
图 4 注意力残差单元Fig. 4 Attention residual unit下载:
全尺寸图片
2.2 过渡层
随着网络深度不断加深,运算参数量持续增多,容易使得网络过度学习输入与输出之间的映射关系,将大量干扰信息错认为重点特征。
在注意力残差模块之间引入由一个3×3卷积层和最大池化层组成的过渡层以去除冗余信息。3×3卷积层能够在不改变特征图大小的情况下增大维数,提升网络线性转换能力。最大池化层能够对输入图像进行下采样以减小参数矩阵的尺寸以及卷积层参数误差造成估计均值的偏移,其结构如图5所示。
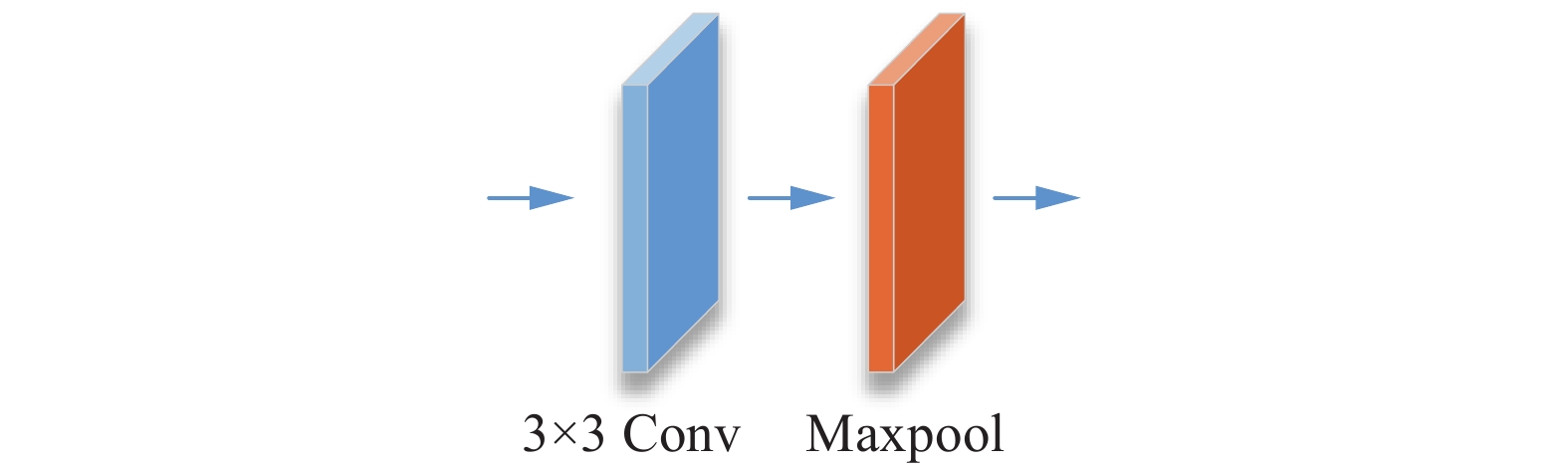 图 5 过渡层结构Fig. 5 Transition layer structure下载:
全尺寸图片
图 5 过渡层结构Fig. 5 Transition layer structure下载:
全尺寸图片
2.3 多尺度特征融合模块
经过各个注意力残差模块后,人脸表情图像的多尺度特征具有不同特点:浅层特征图尺寸较大,通道数较少,具有丰富的细节信息;深层特征图尺寸较小,通道数较多,包含丰富的抽象语义信息。因此本文设计了一个多尺度特征融合模块将3个注意力残差模块产生的多尺度特征图进行融合。首先将前两个注意力残差模块的输出特征经过最大池化操作下采样至7×7×128和7×7×256;然后通过Concat通道融合方法将下采样过后的输出特征图和最后一个注意力残差模块的输出特征图进行融合;再将融合后的特征图使用1×1卷积核进行升维,最终得到具有丰富特征信息的7×7×1024输出特征图。
2.4 全局平均池化+随机失活
通常情况下,神经网络都会添加全连接层减少特征位置对分类带来的影响。但人脸基本位于图像中央且占据绝大部分像素,位置信息并不重要。因此采用全局平均池化层代替全连接层加强特征图与类别的一致性,直接对空间信息进行求和实现降维,极大地减少了网络参数。Dropout原理又名随机失活原理,是指在网络训练过程中随意抛弃某些神经元,破坏特征信息之间密切的交互作用,使得网络不会过于依赖某些局部特征,增强模型泛化性。
本文使用全局平均池化+随机失活设计,简化网络复杂度,减少运算量,避免过拟合现象,进而提高网络泛化性。
3. 实验结果与分析
3.1 实验环境与评价指标
实验使用的深度学习框架为Tensorflow,计算机操作系统为Windows10,显卡型号为NVIDIA Quadro P4000,显存为8BG。
实验使用错误率(error rate)、准确率(accuracy rate)、混淆矩阵和F1-score作为评价指标。
错误率是指预测值与真实值不相同的样本数占总样本数的比例,准确率是指预测值与真实值相同的样本数占总样本数的比例。将真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)4个指标一起呈现在表格中称为混淆矩阵。F1-score为精准率和召回率的调和平均数,取值范围从0~1,其计算公式为
$$ {\rm{F1 {\text{-}} score = 2 \cdot \frac{{Pre \cdot Rec}}{{Pre + Rec}}}} $$ (4) 3.2 实验数据集及预处理
3.2.1 实验数据集
实验采取3个人脸表情数据库验证算法有效性,分别为CK+、JAFFE和Oulu-CASIA。
CK+数据集共有123名实验者,实验共使用981张标记图片用于本文实验。JAFFE数据集共包含213个图像、7类表情,平均每人每种表情有4张左右。Oulu-CASIA数据集由80个人的6类基本表情构成,实验选取可见光成像系统下的Strong强光图像集,在每个序列中选取最后5个峰值帧,形成共2400幅图像。
3.2.2 数据预处理
由于人脸表情识别数据库样本较少,本文使用裁剪、旋转以及遮挡方法对数据集进行扩充,具体步骤如下:
1)首先对CK+和JAFFE数据集进行裁剪处理,去除多余的背景,将背景对模型的影响降到最低。
2)分别将JAFFE数据集图像以顺时针、逆时针旋转5°后的图像扩充数据集,扩充完毕共852张标记图片用于实验,其中训练集680张,验证集172张,如表1所示。
表 1 JAFFE扩充数据集样本分布Table 1 Sample distribution of expanded JAFFE类别 数量/张 占比 愤怒 120 0.14 厌恶 116 0.13 恐惧 128 0.15 快乐 124 0.15 中性 120 0.14 悲伤 124 0.15 惊讶 120 0.14 3)通过在眼睛、嘴巴位置添加黑色框来模拟现实中存在的遮挡情况,如由墨镜、口罩等引起。
3.3 实验结果与分析
3.3.1 网络性能实验分析
1) 训练样本对性能影响
为探讨训练样本对网络性能的影响,设置训练样本数目对比实验。在其余参数量一致的情况下,在JAFFE扩充数据集(852张)上进行训练样本分别为341、511、680的对比实验,实验结果如表2所示。
表 2 训练样本对性能影响Table 2 Effect of training sample number on performance训练样本/个 验证样本/个 测试集识别率A/% 341 511 94.2 511 341 94.7 680 172 96.3 由表2可知,随着训练样本不断增多,网络性能逐步增强,当训练样本为680个时,网络识别率达到最高96.3%,因此在网络训练过程中,应尽可能增大训练样本数目,保证网络能够学习到足够信息。
2) 网络结构
为验证各个模块的有效性,设置包含针对不同模块的对比网络进行消融实验。在参数量基本一致的情况下,以改进的基础残差模块网络DFR (deep fusion residual network)为对比基准,将多尺度特征融合模块添加进网络结构中构成深度多尺度融合残差网络 DMFR (deep multi-scale fusion residual network),将注意力机制添加进网络结构中构成深度融合注意力残差网络DFAR (deep fusion attention residual network),在Oulu-CASIA数据集上进行表情识别消融实验,实验结果如表3所示。
表 3 表情识别消融实验Table 3 Ablation experiment of facial expression recognition方法 残差单元 多尺度融合 注意力机制 A/% DFR √ × × 91.16 DMFR √ √ × 91.69 DFAR √ × √ 91.53 DMFA-ResNet √ √ √ 92.57 由表3可知,改进的基础残差模块网络DFR在Oulu-CASIA数据集上的识别率为91.16%。当分别增加多尺度特征模块和注意力机制模块后,Oulu-CASIA的识别率分别提升到91.69%和91.53%,表明多尺度特征融合模块对网络的贡献大于注意力机制模块。
为探讨注意残差单元数目对网络性能的影响,设置注意残差单元数目对比实验。在其余参数量基本一致的情况下,将注意残差单元数目分别设置为4、5、6、7、8、9,并在JAFFE数据集上进行实验,实验结果由图6所示。
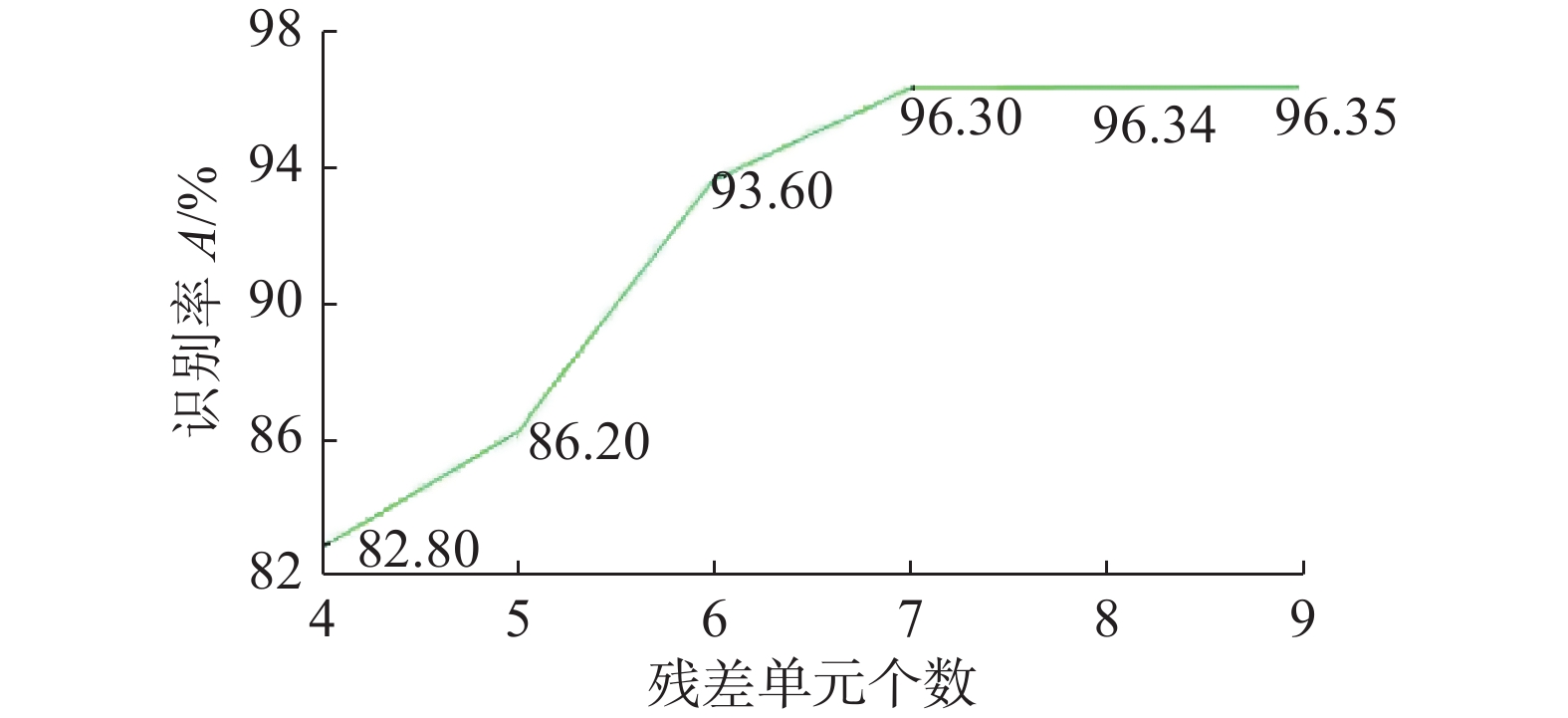 图 6 注意残差单元个数对性能的影响Fig. 6 Effect of the number of attention residual elements on peraformance下载:
全尺寸图片
图 6 注意残差单元个数对性能的影响Fig. 6 Effect of the number of attention residual elements on peraformance下载:
全尺寸图片
由图6可知,当注意残差单元个数小于7时,算法识别率随残差单元个数的增加增幅明显。当注意残差单元个数为9时,算法识别率达到最高96.35%。但注意残差单元个数大于7时,识别率增幅缓慢,考虑到网络复杂度对计算量及网络运行速度带来的影响,最终选择将7个注意残差单元作为一个注意残差模块。
3.3.2 无遮挡表情实验
表4是不同方法在Oulu-CASIA数据集上的测试结果。结果表明,DFR算法在Oulu-CASIA数据集上的识别率能够达到91.16%。DMFA-ResNet的识别率达到92.57%,比LCE的识别率高出9.31%,比IDFERM的识别率高出4.32%。
表5是不同方法在CK+和JAFFE数据集上的测试结果。结果表明,DFR算法在CK+和JAFFE数据集上分别能够达到99.68%和96.25%的识别率。比文献[22]在两个数据集中的识别率分别高出6.22%和1.5%,比文献[23]在两个数据集中的识别率分别高出2.92%和9.51%。
图7分别为DFR算法在CK+和JAFFE数据集的混淆矩阵,其中DFR能够在CK+数据集上对轻蔑、厌恶、恐惧、快乐、悲伤和惊讶这六种表情达到100%识别率;在JAFFE数据集上对恐惧及中性表情能够达到100%识别率,但惊喜表情容易被误判为中性表情,因此识别精度最低。
DFR算法对比其他先进算法在识别率上有很大提升,充分验证了改进的残差模块和过渡层能够提取更加精确的人脸表情特征。DMFA-ResNet算法在CK+和JAFFE数据集上的识别率分别为99.7%和96.3%,比DFR算法在两个数据集中分别提高0.02%和0.05%,证明了引入注意力机制模块和多尺度特征融合模块对提升人脸表情识别率是有利的。
3.3.3 遮挡表情实验
实际生活中,人脸表情图像采集会伴有遮挡情况,一般由墨镜、口罩等引起。若局部区域被遮挡,卷积神经网络就难以抓住重点区域进行特征提取,针对这种情况,本章将在遮挡的扩充数据集上进行实验。表6和表7分别为各种算法在CK+和JAFFE数据集上的遮挡。
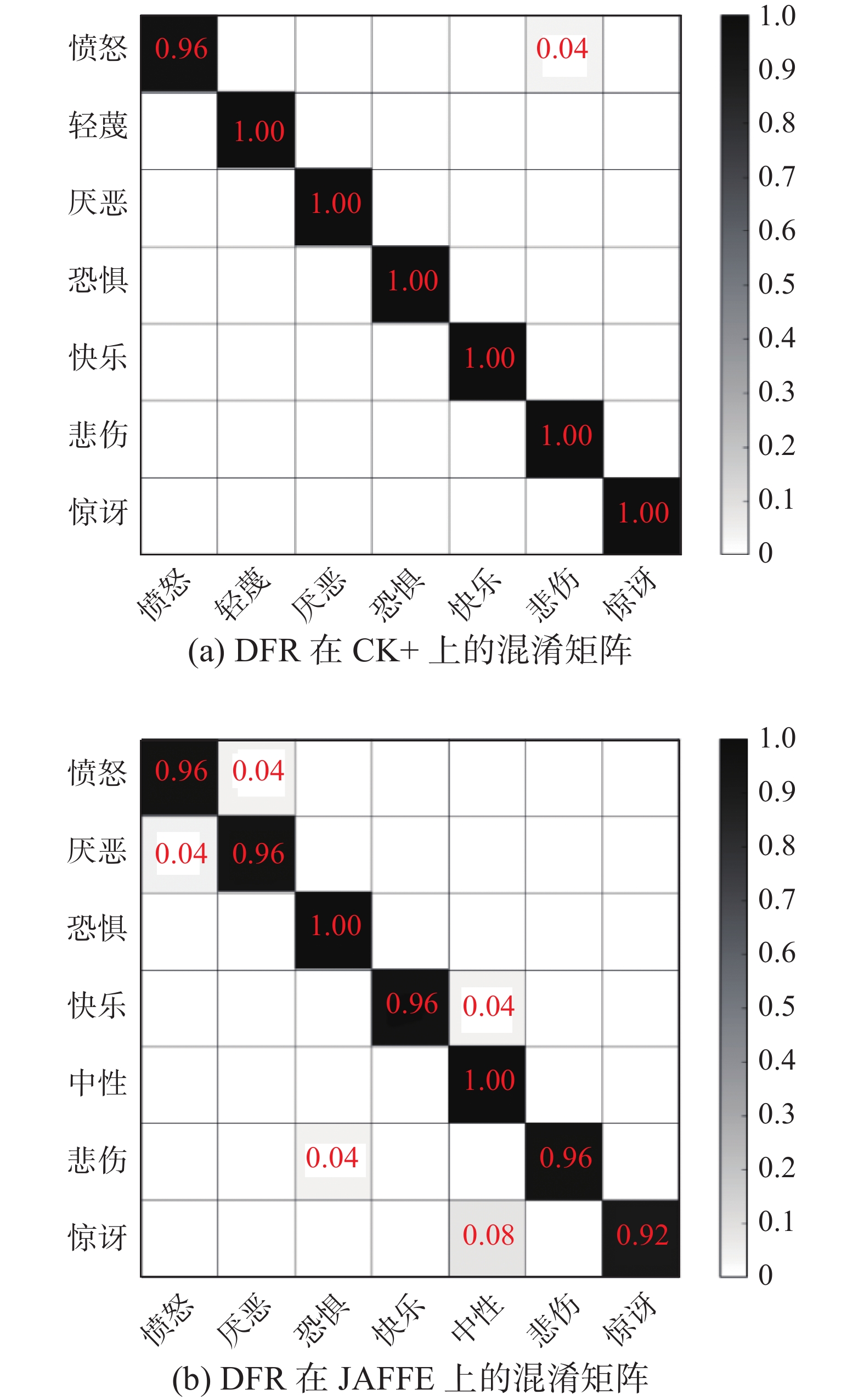 图 7 DFR在CK+和JAFFE数据集上的混淆矩阵Fig. 7 Confusion matrix of DFR on CK+ and JAFFE下载:
全尺寸图片
表 6 CK+上遮挡表情识别Table 6 occlusion facial expression recognition on CK+
图 7 DFR在CK+和JAFFE数据集上的混淆矩阵Fig. 7 Confusion matrix of DFR on CK+ and JAFFE下载:
全尺寸图片
表 6 CK+上遮挡表情识别Table 6 occlusion facial expression recognition on CK+% 方法 眼睛遮挡 嘴巴遮挡 PCA+SVM 89.04 83.84 CNN 91.69 89.17 DCGAN+CNN 87.83 85.43 end-to-end GAN 92.69 90.57 微调VGGface 89.90 87.34 MU-VGGNet 94.06 91.63 DFR 93.81 92.78 DMFA-ResNet 95.31 93.81 表 7 JAFFE上遮挡表情识别Table 7 Occlusion facial expression recognition on JAFFE% 方法 眼睛遮挡 嘴巴遮挡 Gabor 85.66 86.97 Gabor+gray-level matrix 88.88 90.90 WLDH 87.23 89.47 DFR 89.47 91.81 DMFA-ResNet 91.22 93.56 表8和表9分别为DMFA-ResNet算法在CK+和JAFFE数据集上的F1-score值。图8和图9分别为DMFA-ResNet算法在CK+和JAFFE数据集上的遮挡混淆矩阵。
表 8 CK+上遮挡表情F1-score值Table 8 F1-score of occlusion facial expression on CK +表情 眼睛遮挡 嘴巴遮挡 愤怒 0.89 0.96 轻蔑 0.86 0.76 厌恶 0.98 0.90 恐惧 0.99 0.75 快乐 0.99 1 悲伤 0.89 0.90 惊讶 1 0.90 表 9 JAFFE上遮挡表情F1-score值Table 9 F1-score of occlusion facial expression on JAFFE表情 眼睛遮挡 嘴巴遮挡 愤怒 0.96 0.96 厌恶 0.90 0.92 恐惧 0.88 0.89 快乐 0.94 0.94 中性 0.92 0.96 悲伤 0.82 0.88 惊讶 0.94 0.98  图 8 在CK+数据集上的遮挡混淆矩阵Fig. 8 Occlusion confusion matrix on the CK+下载:
全尺寸图片
图 8 在CK+数据集上的遮挡混淆矩阵Fig. 8 Occlusion confusion matrix on the CK+下载:
全尺寸图片
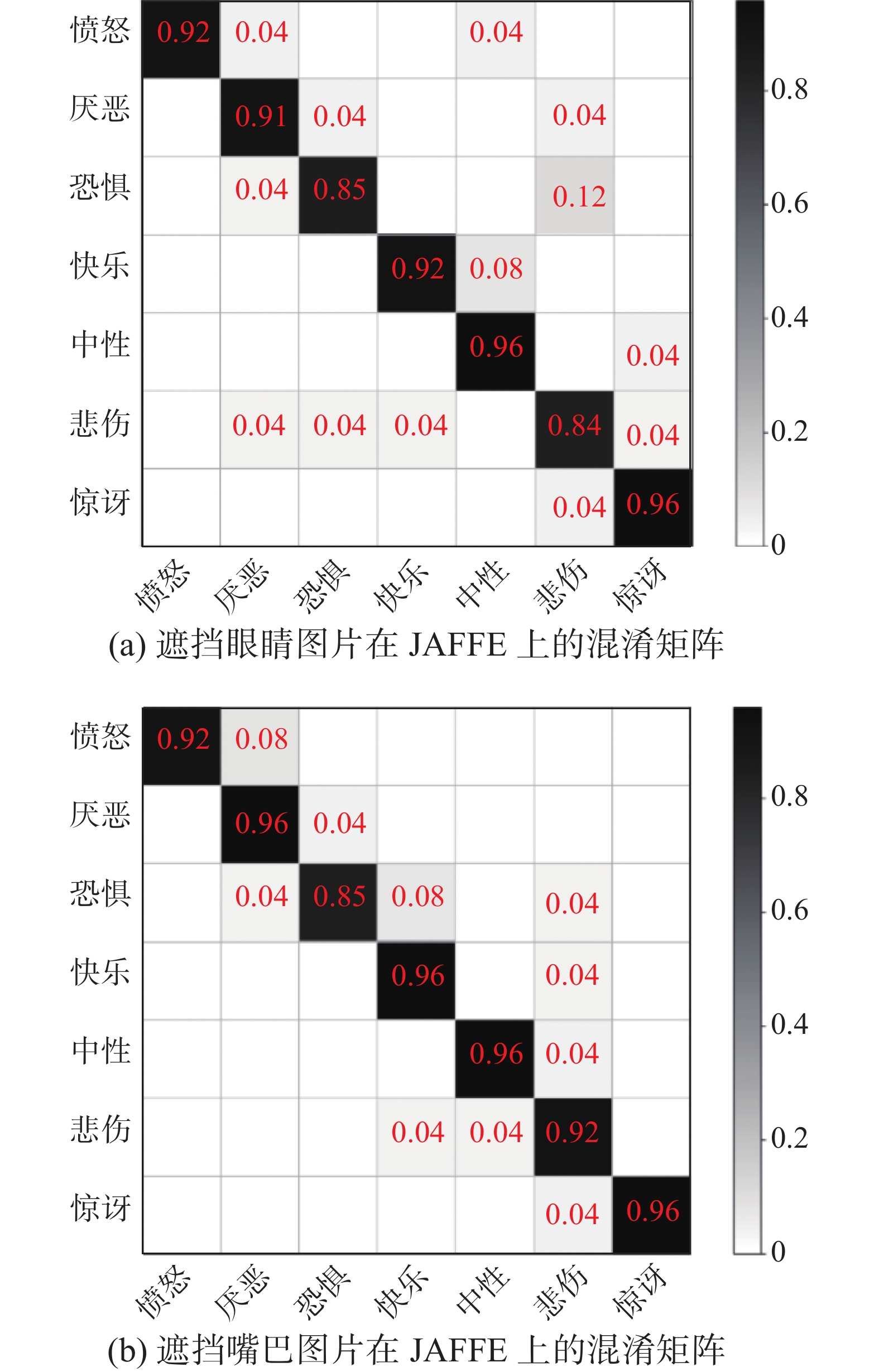 图 9 在JAFFE数据集上的遮挡混淆矩阵Fig. 9 Occlusion confusion matrix on the JAFFE下载:
全尺寸图片
图 9 在JAFFE数据集上的遮挡混淆矩阵Fig. 9 Occlusion confusion matrix on the JAFFE下载:
全尺寸图片
由表6、表7可知,对于遮挡图像,DMFA-ResNet比DFR算法在CK+和JAFFE数据集上的识别精度分别提升2.5%和1.5%,且DMFA-ResNet对遮挡表情的识别在两个数据集上均取得最高识别精度。
由表8和图8可知,遮挡眼睛后,DMFA-ResNet算法在CK+数据集上能够对害怕和惊讶两种表情达到100%识别率;遮挡嘴巴后,能够对困惑、快乐和惊讶3种表情达到100%识别率。而轻蔑和恐惧表情的F1-score分别只达到0.76和0.75,说明这两种表情的有效特征大部分在于嘴巴部分。
由图9和表9可知,遮挡眼睛情况下的悲伤表情F1-score仅达到0.82,说明悲伤表情的有效特征大部分在于眼睛部分,虽然该值达到最低,但DMFA-ResNet在JAFFE数据集上也取得相当不错的效果。由于该数据集样本间的差异较小,导致算法仍出现较多误判情况,无法完全精准识别某一类表情。以上实验结果证明了DMFA-ResNet在应对遮挡图像问题上的优越性,更适用于人脸表情识别任务。
4. 结束语
本文提出一种多尺度融合注意力残差网络(DMFA-ResNet)。该网络主要提出一种新的注意力残差模块,提高了网络对局部重点部位特征的提取,有利于学习到非遮挡部位的信息;提出多尺度融合模块,将各残差模块的输出进行融合以提取更加丰富的人脸表情特征;为了减少参与网络运算的参数量,在各个残差模块之间添加过渡层,主要进行下采样操作并使用全局平均池化+ Dropout设计防止网络过拟合。在CK+、JAFFE和Oulu-CASIA数据集上进行实验均取得了不错的效果,注意力残差模块对局部区域的特征能够进行有效提取,实验验证本文算法具有优越性。但所提算法为针对静态图像的表情识别算法,不适用于动态连续的视频识别,在接下来的工作中,可以重点研究基于视频的动态表情识别技术。
-
图 1 残差学习单元
Fig. 1 Residual learning unit
下载:
全尺寸图片
图 2 DMFA-ResNet结构图
Fig. 2 DMFA-ResNet structure
下载:
全尺寸图片
图 3 注意力残差模块
Fig. 3 Attention residual module
下载:
全尺寸图片
图 4 注意力残差单元
Fig. 4 Attention residual unit
下载:
全尺寸图片
图 5 过渡层结构
Fig. 5 Transition layer structure
下载:
全尺寸图片
图 6 注意残差单元个数对性能的影响
Fig. 6 Effect of the number of attention residual elements on peraformance
下载:
全尺寸图片
图 7 DFR在CK+和JAFFE数据集上的混淆矩阵
Fig. 7 Confusion matrix of DFR on CK+ and JAFFE
下载:
全尺寸图片
图 8 在CK+数据集上的遮挡混淆矩阵
Fig. 8 Occlusion confusion matrix on the CK+
下载:
全尺寸图片
图 9 在JAFFE数据集上的遮挡混淆矩阵
Fig. 9 Occlusion confusion matrix on the JAFFE
下载:
全尺寸图片
表 1 JAFFE扩充数据集样本分布
Table 1 Sample distribution of expanded JAFFE
类别 数量/张 占比 愤怒 120 0.14 厌恶 116 0.13 恐惧 128 0.15 快乐 124 0.15 中性 120 0.14 悲伤 124 0.15 惊讶 120 0.14 表 2 训练样本对性能影响
Table 2 Effect of training sample number on performance
训练样本/个 验证样本/个 测试集识别率A/% 341 511 94.2 511 341 94.7 680 172 96.3 表 3 表情识别消融实验
Table 3 Ablation experiment of facial expression recognition
方法 残差单元 多尺度融合 注意力机制 A/% DFR √ × × 91.16 DMFR √ √ × 91.69 DFAR √ × √ 91.53 DMFA-ResNet √ √ √ 92.57 表 4 不同方法在Oulu-CASIA数据集上的测试结果
Table 4 Test results of different methods on Oulu-CASIA data sets
表 5 不同方法在CK+和JAFFE数据集上的测试结果
Table 5 Test results of different methods on CK+ and JAFFE data sets
% 表 6 CK+上遮挡表情识别
Table 6 occlusion facial expression recognition on CK+
% 方法 眼睛遮挡 嘴巴遮挡 PCA+SVM 89.04 83.84 CNN 91.69 89.17 DCGAN+CNN 87.83 85.43 end-to-end GAN 92.69 90.57 微调VGGface 89.90 87.34 MU-VGGNet 94.06 91.63 DFR 93.81 92.78 DMFA-ResNet 95.31 93.81 表 7 JAFFE上遮挡表情识别
Table 7 Occlusion facial expression recognition on JAFFE
% 方法 眼睛遮挡 嘴巴遮挡 Gabor 85.66 86.97 Gabor+gray-level matrix 88.88 90.90 WLDH 87.23 89.47 DFR 89.47 91.81 DMFA-ResNet 91.22 93.56 表 8 CK+上遮挡表情F1-score值
Table 8 F1-score of occlusion facial expression on CK +
表情 眼睛遮挡 嘴巴遮挡 愤怒 0.89 0.96 轻蔑 0.86 0.76 厌恶 0.98 0.90 恐惧 0.99 0.75 快乐 0.99 1 悲伤 0.89 0.90 惊讶 1 0.90 表 9 JAFFE上遮挡表情F1-score值
Table 9 F1-score of occlusion facial expression on JAFFE
表情 眼睛遮挡 嘴巴遮挡 愤怒 0.96 0.96 厌恶 0.90 0.92 恐惧 0.88 0.89 快乐 0.94 0.94 中性 0.92 0.96 悲伤 0.82 0.88 惊讶 0.94 0.98 -
[1] BEN Xianye, REN Yi, ZHANG Junping, et al. Video-based Facial micro-expression analysis: a survey of datasets, features and algorithms[EB/OL].(2021-03-19)[2021-05-01].https://arxiv.org/abs/2201.12728v1. [2] CHEN Boyu, GUAN Wenlong, LI Peixia, et al. Residual multi-task learning for facial landmark localization and expression recognition[EB/OL].(2021-07-01)[2021-07-05].https://www.sciencedirect.com/science/article/pii/S0031320321000807. [3] LI Shan, DENG Weihong. Deep facial expression recognition: a survey[EB/OL].(2020-03-17)[2021-05-01]. https://ieeexplore.ieee.org/document/9039580. [4] ZHAO Guoying, PIETIKAINEN M. Dynamic texture recognition using local binary patterns with an application to facial expressions[J]. IEEE transactions on pattern analysis and machine intelligence, 2007, 29(6): 915–928. doi: 10.1109/TPAMI.2007.1110 [5] WHITEHILL J, OMLIN C W. Haar features for FACS AU recognition[C]//Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition. Southampton, UK, 2006: 5−101. [6] BARTLETT M S, LITTLEWORT G, FRANK M, et al. Recognizing facial expression: machine learning and application to spontaneous behavior[C]//Proceedings of 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, USA, 2005: 568−573. [7] LI Xiaobai, PFISTER T, HUANG Xiaohua, et al. A spontaneous micro-expression database: inducement, collection and baseline[C]//2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG). Shanghai, China, 2013: 1−6. [8] RIVERA A R, CASTILLO J R, CHA E O O. Local directional number pattern for face analysis: face and expression recognition[J]. IEEE transactions on image processing, 2013, 22(5): 1740–1752. doi: 10.1109/TIP.2012.2235848 [9] KIM T H, YU C, LEE S W. Facial expression recognition using feature additive pooling and progressive fine-tuning of CNN[J]. Electronics letters, 2018, 54(23): 1326–1328. doi: 10.1049/el.2018.6932 [10] AN Fengping, LIU Zhiwen. Facial expression recognition algorithm based on parameter adaptive initialization of CNN and LSTM[J]. The visual computer, 2020, 36(3): 483–498. doi: 10.1007/s00371-019-01635-4 [11] XIE Siyue, HU Haifeng, WU Yongbo. Deep multi-path convolutional neural network joint with salient region attention for facial expression recognition[J]. Pattern recognition, 2019, 92: 177–191. doi: 10.1016/j.patcog.2019.03.019 [12] WANG Kai, PENG Xiaojiang, YANG Jianfei, et al. Suppressing uncertainties for large-scale facial expression recognition[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA, 2020: 6897−6906. [13] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA, 2016: 770−778. [14] LI Yong, ZENG Jiabei, SHAN Shiguang, et al. Occlusion aware facial expression recognition using CNN with attention mechanism[J]. IEEE transactions on image processing, 2019, 28(5): 2439–2450. doi: 10.1109/TIP.2018.2886767 [15] LIU Yuanyuan, YUAN Xiaohui, GONG Xi, et al. Conditional convolution neural network enhanced random forest for facial expression recognition[J]. Pattern recognition, 2018, 84: 251–261. doi: 10.1016/j.patcog.2018.07.016 [16] HU Jie, SHEN Li, SUN Gang. Squeeze-and-excitation networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA, 2018: 7132−7141. [17] 江静, 邓伟洪. 持续学习改进的人脸表情识别[J]. 中国图象图形学报, 2020, 25(11): 2361–2369. doi: 10.11834/jig.200315 JIANG Jing, DENG Weihong. Facial expression recognition improved by continual learning[J]. Journal of image and graphics, 2020, 25(11): 2361–2369. doi: 10.11834/jig.200315 [18] 王善敏, 帅惠, 刘青山. 关键点深度特征驱动人脸表情识别[J]. 中国图象图形学报, 2020, 25(4): 813–823. doi: 10.11834/jig.190331 WANG Shanmin, SHUAI Hui, LIU Qingshan. Facial expression recognition based on deep facial landmark features[J]. Journal of image and graphics, 2020, 25(4): 813–823. doi: 10.11834/jig.190331 [19] 张文萍, 贾凯, 王宏玉, 等. 改进的Island损失函数在人脸表情识别上的应用[J]. 计算机辅助设计与图形学学报, 2020, 32(12): 1910–1917. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJF202012005.htm ZHANG Wenping, JIA Kai, WANG Hongyu, et al. Application of improved Island loss in facial expression recognition[J]. Journal of computer-aided design & computer graphics, 2020, 32(12): 1910–1917. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJF202012005.htm [20] LIU Xiaofeng, KUMAR B V K V, JIA Ping, et al. Hard negative generation for identity-disentangled facial expression recognition[J]. Pattern recognition, 2019, 88: 1–12. doi: 10.1016/j.patcog.2018.11.001 [21] YANG Huiyuan, CIFTCI U, YIN Lijun. Facial expression recognition by de-expression residue learning[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA, 2018. [22] XIE Siyue, HU Haifeng. Facial expression recognition using hierarchical features with deep comprehensive multipatches aggregation convolutional neural networks[J]. IEEE transactions on multimedia, 2019, 21(1): 211–220. doi: 10.1109/TMM.2018.2844085 [23] LOPES A T, DE AGUIAR E, DE SOUZA A F, et al. Facial expression recognition with convolutional neural networks: coping with few data and the training sample order[J]. Pattern recognition, 2017, 61: 610–628. doi: 10.1016/j.patcog.2016.07.026 [24] ZHANG Hepeng, HUANG Bin, TIAN Guohui. Facial expression recognition based on deep convolution long short-term memory networks of double-channel weighted mixture[J]. Pattern recognition letters, 2020, 131: 128–134. doi: 10.1016/j.patrec.2019.12.013 [25] YANG Biao, CAO Jinmeng, NI Rongrong, et al. Facial expression recognition using weighted mixture deep neural network based on double-channel facial images[J]. IEEE access, 2017, 6: 4630–4640. [26] KIM J H, KIM B G, ROY P P, et al. Efficient facial expression recognition algorithm based on hierarchical deep neural network structure[J]. IEEE access, 2019, 7: 41273–41285. doi: 10.1109/ACCESS.2019.2907327
















