
Research on the fusion of knowledge graph and lightweight graph convolutional network recommendation system
-
摘要: 基于协同过滤的算法是推荐系统中最重要的方法,由于冷启动和数据稀疏性的特点,限制了其推荐性能。为了应对以上问题,提出了知识图谱和轻量级图卷积网络推荐系统相结合的模型,该模型通过将知识图谱中的各个实体(项目)进行多次迭代嵌入传播以获取更多的高阶邻域信息,通过轻量聚合器进行聚合,进而预测用户和项目之间的评分。最后,在3个真实的数据集上MovieLens-20M、Last.FM和Book-Crossing的实验结果表明,该模型与其他基准模型相比可以得到较好的性能。Abstract: The algorithm based on collaborative filtering is the most important method in the recommendation system. However, the cold start and data sparsity characteristics limit its recommendation performance. We propose a model that combines a knowledge graph and a lightweight graph convolutional network recommendation system to address the aforementioned issues. The model embeds and propagates multiple items in the knowledge graph to obtain more high-order neighborhood information. It aggregates through a lightweight aggregator to predict the score between users and items. Finally, the experimental findings of MovieLens-20M, Last.FM and Book-Crossing on three real datasets show that compared with other benchmark models, this model can achieve better performance.
-
随着大数据技术的快速发展,互联网的用户量和信息量规模不断扩大,海量的信息资源导致了信息过载。推荐系统是目前最有效的信息过滤的方法,已经广泛地应用在人们的日常生活中,并且在搜索引擎、电子商务、社交媒体网站以及新闻门户网站等领域都取得了不错的成果。推荐系统的核心就是通过挖掘用户和物品的特征表示来预测某用户是否对一个项目产生了交互行为,比如点击、浏览、评分购买等交互形式。协同过滤[1-5](collaborative filtering, CF)是推荐系统中最有效的方法之一,它是利用集体智慧(collective intelligence, CI)的一个典型方法,从大量的数据中挖掘出与目标用户相类似的候选用户,然后根据这些候选用户的偏好项目组成一个目录推荐给目标用户。因此,协同过滤仍然是实现有效的个性化推荐[6-8]的一项基础任务。一个常见的协同过滤的范例是将学习到用户和项目的潜在特征表示向量,基于二者的表示向量进行预测,一些代表性模型有:因子分解机(factorization machines, FM)[9],宽广型网络(wide & deep learning for recommender systems ,Wide&Deep) [10],神经因子分解机(neural factorization machines, NFM)[11],深度因子分解机(a factorization-machine based neural network for CTR prediction, DeepFM)[12]等。尽管协同过滤方法具有有效性和通用性,但是它无法对项目的属性等相关信息、用户的配置文件以及上下文信息进行建模。近年来,图卷积网络(graph convolutional network, GCN)[13]由于具有在图结构数据上强大的特征提取能力,成为当前推荐系统中的研究热点。在现实生活中,周围的数据都是一些非结构化的数据,传统的神经网络结构并不能有效地从这种图结构数据中提取特征。本质上,图卷积网络是将传统的卷积神经网络强大的提取特征的能力扩展到图结构的数据上,它通过谱图卷积的一阶近似值在拓扑图上定义了图卷积操作,然后基于拓扑图不断地传播和聚合邻域节点的信息,最后学习到每个实体嵌入的特征。Wang等[14]提出一种神经图卷积(neural graph collaborative filtering, NGCF)模型,它通过图卷积网络的信息传播和聚合机制堆叠多个图卷积层,不断地将高阶邻居的协同信号传递到下一层,最后将所有层的节点的信息进行整合进行推荐。Wang等[15]在图卷积网络的基础上提出了基于知识图谱卷积推荐系统(knowledge graph convolutional network for recommender systems, KGCN)模型,此模型将融合了知识图谱之后,采取了标准的图卷积网络模型的一系列操作:特征变换、激活函数、邻域融合。尽管此模型取得了较好的效果,但是该模型由于是继承于标准的图卷积网络,并没有进行调整,因此可能相对比较繁重复杂。图卷积网络一开始提出是为了用于属性图上的节点分类的,在属性图上每个节点具有丰富的语义信息,而在协同过滤任务当中的用户–项目交互图中,每个节点只被标记为一个独热编码向量,除了标识作用以外没有其他具体的语义信息。非线性特征转换是提高一般神经网络架构的必要操作,然而在推荐系统中,由于数据的高度稀疏性,非线性特征转换对于协同过滤没有很大的提升性能反而会增加模型训练的难度。
针对以上问题,构建了SPGCN (simplifying and powering graph convolutional networks with knowledge graph for recommendation)模型。该模型基于知识图谱卷积推荐系统KGCN的构建思想,简化了在图卷积网络中的非线性激活、特征变换的操作,只包含了在协同过滤中图卷积网络模型中最基本的组件—邻域聚合,提升了模型预测的准确性。模型在两个传统的数据集上都取得较好的性能结果,验证了模型的有效性。
1. 相关工作
1.1 图卷积网络
图卷积网络是推荐系统中最流行的网络架构,它利用消息传递机制和聚合操作在图结构数据对协同信号进行建模进而用于推荐预测。
图卷积网络模型一般分为3部分:节点嵌入层、图卷积操作层和预测层。给定一个图
${\boldsymbol{G}} = ({\boldsymbol{V}},{\boldsymbol{E}})$ ,$\boldsymbol V$ 是节点的集合,$\boldsymbol E$ 是边的集合。节点嵌入层:对二部图上的实体节点进行编码,获得这些节点的初始低维嵌入向量,公式为
$$ {{\boldsymbol{x}}^0} = g(x,\rho ) $$ 式中:
$x$ 是实体节点的特征;${{\boldsymbol{x}}^0}$ 是经过处理的初始嵌入向量,可以分为用户嵌入向量${\boldsymbol{x}}_u^0$ 和项目嵌入向量${\boldsymbol{x}}_v^0$ ;$\rho $ 是待学习参数。图卷积操作层:主要包括对于各个节点的消息构造和更新节点的嵌入。当用户和项目之间有了交互行为,就可以将用户此次的操作信息构造为
$$ {{\boldsymbol{M}}_{u \leftarrow v}} = \xi ({\boldsymbol{x}}_u^0,{\boldsymbol{x}}_v^0,{p_{u,v}},\tau ) $$ 式中:
${p_{u,v}} = \dfrac{1}{{\sqrt {|{{\boldsymbol{N}}_u}| \cdot |{{\boldsymbol{N}}_v}|} }}$ 是协同信号的强度系数;$|{{\boldsymbol{N}}_u}|$ 和$|{{\boldsymbol{N}}_v}|$ 分别是与用户和项目直接相邻的节点,$|{{\boldsymbol{N}}_u}|$ 和$|{{\boldsymbol{N}}_v}|$ 是这些节点的度;$\xi $ 是协同信号构造函数,$\tau $ 是待学习的参数。嵌入更新操作更新用户的一阶邻居信号:$$ {\tilde x_u} = \omega ({x_u},\{ {{\boldsymbol{M}}_{u \leftarrow v}}|v \in {{\boldsymbol{N}}_u}\} ) $$ 式中:
${\tilde x_u}$ 为更新以后用户的嵌入表示;$ x^{2} $ 为聚合函数。类似的,也可以获得项目$ v $ 的消息构造和嵌入传播更新信号:$$ {{\boldsymbol{M}}_{v \leftarrow u}} = \xi ({\boldsymbol{x}}_v^0,{\boldsymbol{x}}_u^0,{p_{u,v}},\tau ) $$ $$ {\tilde x_v} = \omega ({x_v},\{ {{\boldsymbol{M}}_{v \leftarrow u}}|u \in {{\boldsymbol{N}}_v}\} ) $$ 通过上述过程就实现了在该二部图上节点的一次消息构造和嵌入传播更新。经过多次堆叠上述操作就可以获得高阶邻域信息,即用户节点的向量。
预测层:通过节点嵌入层和多层图卷积层,就可以得到最终的用户节点嵌入向量表示
${\boldsymbol{x}}_u^1,{\boldsymbol{x}}_u^2, \cdots , {\boldsymbol{x}}_u^l$ 和项目的节点嵌入表示${\boldsymbol{x}}_v^1,{\boldsymbol{x}}_v^2, \cdots ,{\boldsymbol{x}}_v^l$ 。此时,可以对用户$u$ 和任意项目$v$ 之间进行预测,即:$$ \widehat y = h({\boldsymbol{x}}_u^l,{\boldsymbol{x}}_v^l,\mu ) $$ 式中:预测函数
$h( \cdot )$ 可以使用多层感知机MLP实现;$\mu $ 是网络参数。1.2 融合知识图谱的图卷积网络
知识图谱[16-18]可以通过知识抽取和知识表示技术将人类知识以结构化的形式展示出来,为智能系统提供可供处理的先验知识,是表现客观世界中的实体以及实体之间的关系的知识库。知识图谱提供了不同物品之间各种各样的关系和可以捕获物品间的语义关系。为了缓解推荐系统中的数据稀疏性和冷启动问题,许多工作将知识图谱融入到推荐系统中。将知识图谱作为辅助信息整合到推荐系统当中,使得推荐系统利用先验知识进行推理获得更好的推荐性能。RippleNet[19]知识图谱特征学习与推荐系统算法的目标函数相结合从而将知识图谱作为额外信息,融入到推荐系统中。知识图谱注意力网络(knowledge graph attention network,KGAN)[20]进一步将注意力机制引入到模型中,从融合知识图谱的用户–商品交互图中传播高阶路径的信息。基于标签平滑正则的知识感知图神经网络(knowledge-aware graph neural networks with label smoothness regularization for recommender systems, KGNN-LS)[18]将知识图谱与用户相关的带权图相结合,进而使用图神经网络得到项目的向量嵌入向量表示。
2. 融合知识图谱和轻量级图卷积网络
基于知识图谱和轻量级图卷积网络推荐系统SPGCN模型将项目以及属性信息嵌入知识图谱中,以目标用户点击过的项目为基准,不断地将邻域节点信息汇聚,得到项目的向量嵌入表示。最后,用户和项目进行预测评分。
2.1 问题形式化
在一些典型的推荐场景中,有一组用户集合
${{u}} = \{ {{{u}}_1},{{{u}}_2}, \cdots ,{{{u}}_M}\}$ 和一组项目集合${{v}} = \{ {{{v}}_1},{{{v}}_2}, \cdots ,{{{v}}_M}\}$ 。用户–项目交互矩阵${\boldsymbol{Z}} \in {{\bf{R}} ^{M \times N}}$ ,这是基于用户的隐式反馈信息所定义的,当${{{Z}}_{uv}} = 1$ 即代表用户与项目之间有交互行为,比如点击、浏览、购物等行为;当${{{Z}}_{uv = 0}}$ 即代表用户和项目之间没有任何交互行为。此外,G代表利用知识图谱所构成的图,是由实体–联系–实体组成的三元组$({{h}},{{r}},{{t}}) ({{h}} \in {{E}}, {{r}} \in {{R}},{{t}} \in {{R}})$ 。E代表实体集,R代表关系。这3者分别代表知识图谱三元组头节点,关系以及尾节点。给定用户–项目交互矩阵
$\boldsymbol Z$ 和知识图谱$\boldsymbol G$ ,推荐系统的目标就是预测某用户是否和他之前从未有过交互的项目产生交互。目标函数是$\hat {{y}} = {{f}}({{u}},{{v}} | \theta ,{\boldsymbol{Z}},{\boldsymbol{G}})$ ,其中$\hat y$ 是用户和项目产生交互的概率,$\theta $ 是$f$ 目标函数的模型参数。2.2 基于知识图谱的轻量级图卷积网络
图1是SPGCN的整体架构图。模型中的知识图谱是基于项目的一些属性信息进行构建的三元组
$({{h}},{{r}},{{t}})$ ,对于任意一组用户$u$ 和项目$v$ ,首先通过计算目标用户$u$ 与三元组中各个关系实体的分数,经过归一化操作后得到目标用户$u$ 的个性化偏好信息。然后,将项目$v$ 的邻域节点和目标用户$u$ 的个性化信息相结合得到项目$v$ 的邻域信息。最后,使用轻量级聚合器将项目$v$ 和其邻域节点信息进行聚合得到项目$v$ 的一次迭代信息。 图 1 SPGCN模型架构Fig. 1 SPGCN model architecture
图 1 SPGCN模型架构Fig. 1 SPGCN model architecture 下载:
全尺寸图片
下载:
全尺寸图片
接下来将上述操作公式化,首先考虑一个用户和一个项目(实体)之间的关系,
$ \mu(v) $ 代表与此项目(实体)直接相连的实体集,${ r}_{{e_i},{e_j}}$ 代表实体${{{r}}_{{e_i}}}$ 和实体${{{r}}_{{e_j}}}$ 之间的关系,$H$ (比如:内积操作)计算用户$u$ 和一个关系$r$ 的分数,公式为$$ \varphi _r^u = {{H}}({\boldsymbol{u}},{\boldsymbol{r}}) $$ 式中:
${\boldsymbol{u}} \in {{\bf{R}}^d}$ 和${\boldsymbol{r}} \in {{\bf{R}}^d}$ 代表用户$u$ 和关系$r$ 的向量表示,$d$ 是其向量的维度。$\varphi _r^u$ 表示了一个关系$r$ 对于一个用户的重要程度。比如一个用户可能比较喜欢一首歌的歌词,而另外一个用户可能更喜欢一首歌的曲调,所以通过此公式可以计算一个实体关系对于用户的重要性程度。为了得到项目
$\boldsymbol v$ (实体)的邻域节点,可以计算节点v的邻域节点的线性表示:$$ {\boldsymbol{v}}_{{\boldsymbol{N}}(v)}^u = \sum\nolimits_{e \in {\boldsymbol{N}}(v)} {\tilde \varphi _{{{{r}}_{v,e}}}^u} {\boldsymbol{e}} $$ 式中
$\tilde \varphi _{{{\boldsymbol{r}}_{v,e}}}^u$ 是归一化后的用户–联系分数:$$ \tilde \varphi _{{{{r}}_{v,e}}}^u = \dfrac{{{\rm{exp}} (\varphi _{{{{r}}_{v,e}}}^u)}}{{\displaystyle\sum\limits_{{\boldsymbol{e}} \in {\boldsymbol{N}}(v)} {\varphi _{{{{r}}_{v,e}}}^u} }} $$ 式中:
$\boldsymbol e$ 是相应实体向量表示,用户–联系分数是计算一个实体的邻域表示的个性化过滤器,可以捕捉到用户的个性化特征,此处是一种特殊的注意力机制可以赋予不同的权重在其邻域节点。在实际应用中,每个实体的邻域大小${{N}}({{e}})$ 可能有所不同,为了计算方便,可以将v的邻域表示设为${\boldsymbol{v}}_{s(v)}^u$ ,其中${\boldsymbol{S}}(v)\mathop \Leftrightarrow \limits^\Delta \{ {\boldsymbol{e}}|{\boldsymbol{e}} \sim {\boldsymbol{N}}({{v}})\}$ 并且$|{\boldsymbol{S}}({{v}})| = {\boldsymbol{C}}$ 。最后就是将前面得到的邻域表示聚合在一起得、到最后的向量表示,公式为
$$ {\bf{agg}}_v^u = \sum\limits_{p = 0}^P {{\boldsymbol{v}}_{s(v)}^u} + v $$ 式中:
$p$ 代表迭代的次数,经过多次迭代得到实体$v$ 的邻域的高阶表示,就可以通过用户$u$ 和项目$v$ 的最终的向量表示的内积操作得到模型的预测结果:$$ \hat y = {{\boldsymbol{W}}_2}({\text{Relu}}({{\boldsymbol{W}}_1}({{\boldsymbol{u}}^{\text{T}}} \oplus {{\boldsymbol{v}}^u}))) $$ 式中:
${{\boldsymbol{W}}_1} \in {{\bf R}^{2d \times b}}$ ,${{\boldsymbol{W}}_{\text{2}}}\in$ Rb×1为待学习的多层感知机MLP的权重矩阵;$b$ 是多层感知机MLP的第1层神经元的个数。图1为本模型的整体架构,包括:输入层、轻量级的图卷积层、预测层3个部分。
${e^u}[h]$ 代表模型的输入部分,紧接着就是堆叠的轻量级的多层图卷积操作生成项目$v$ 的嵌入向量表示。最后,由于非线性的多层感知机MLP对于嵌入表示向量之间的复杂关系更好的拟合,所以将图卷积层学习到的项目的节点嵌入${e^u}[H]$ 与目标用户的向量表示连接起来输入到2层的多层感知机MLP中,就可以对目标用户$u$ 和目标项目$v$ 的评分$\hat y$ 进行预测。SPGCN模型是一种端到端的推荐系统模型。为了使计算更加有效,在训练过程的优化目标函数为
$$ \phi = \sum\limits_{u \in U} {\left(\sum\limits_{v(v:{z_{uv}} = 1)} {J({y_{uv,}}{{\hat y}_{uv}})} \right)} + \lambda ||F||_2^2 $$ 式中:
$u \in U$ 表示针对于用户集的每个用户;$v(v:{z_{uv}} = 1)$ 表示与此用户有交互的项目;$J$ 是交叉熵损失函数,最后一项是L2-正则化项。3. 实验及其结果分析
为了验证所提出模型的推荐性能,该模型在3个数据集MovieLens-20M、Last.FM、Book-Crossing上进行了实验,并将其与经典模型进行对比。
3.1 实验设置和数据集
本文实验运行环境为Win10系统、16GB内存,使用Pycharm软件和Tensorflow1.4版本框架搭建本模型。
本实验的参数设置如表1所示,采用Adam为梯度优化方法,Dropout设为0.6,迭代次数为100次,采样的邻域个数分别为4和8,嵌入维度分别为32和16,学习率分别为2×10−2和5×10−4。
表 1 实验参数设置Table 1 Experimental parameter settings数据集 MovieLens-20M Last.FM Book-Crossing 优化函数 Adam Adam Adam Dropout 0.6 0.6 0.6 迭代次数 100 100 100 邻域的个数 4 4 4 Batch size 65536 128 128 学习率 2×10−2 5×10−4 2×10−4 嵌入维度 32 16 16 在本实验中,采用了电影、音乐和数据3个不同邻域的数据集。在本实验使用的数据集MovieLens-20M、Last.FM和Book-Crossing的统计情况见表2。
表 2 数据集的相关情况Table 2 Statistics of datasets数据集 用户数量 项目数量 交互数量 实体数量 关系数量 知识图谱三元组 MovieLens-20M 138159 16954 13501622 102569 32 499474 Last.FM 1872 3846 42346 9366 60 15518 Book-Crossing 19676 20003 172576 25787 18 60787 MovieLens-20M:是推荐系统广泛使用的基准数据集,主要是多个用户对多个电影的评分等级信息,其中包括电影元数据信息(电影id、类型信息等)、用户相关信息(用户的职业、年龄等)。
Last.FM: 是关于用户听歌序列的数据集。它具有用户的隐性反馈的上下文信息 。在Last.FM中有两个文件,听歌记录与用户信息。
Book-Crossing: 这个数据集是Book-Crossing图书社区的278858个用户对271379本书进行的评分,包括显式和隐式的评分。
3.2 评估指标和对比方法
为了更好的评估模型,在本文中选择AUC(准确率)、F1(综合考量精确率和召回率)、precision(精确率)以及recall(召回率)4个指标作为评估指标。precision表示对测试集的结果分类后,其被正确分类占总体的比例,精确率越高,模型表现得越好。recall表示分类后正确判断的个数占全部正确数量的个数,其值越高,证明推荐效率越高。F1是一个根据precision和recall综合考虑的一个性能指标,F1越大说明模型的质量越高。AUC衡量了一个模型的整体性能指标,其值一般在0.5和1之间,值越高模型性能越好。如表3是判别混淆矩阵,混淆矩阵称为误差矩阵,每一列代表了预测的类别,每一列的总数代表预测的这个类别的数量,每一行代表数据的真实属性类别,每一行的总数代表了数据的这个真实类别的数量。
表 3 混淆矩阵Table 3 Confusion matrix预测 正样本 负样本 正样本 TP(真正例) FN(假反例) 负样本 FP(假正例) TN(真反例) 为了更好地评估该模型,本文采取以下3种经典的模型KGAN、RippleNet、KGCN作为对比方法:
KGAN 这是一个知识图谱和图卷积网络结合的经典模型,还加入了注意力机制,有效地提升了模型性能。
RippleNet 典型的将知识图谱联合推荐系统进行的训练的网络结构,通过在知识图谱中传播用户偏好,从而可以发现用户的不同兴趣爱好实现个性化推荐。
KGCN 利用知识图谱对项目的属性信息建模并将用户的个性化偏好信息,堆叠多个图卷积层将项目的邻域节点信息和本身节点消息传播和聚合。
3.3 实验结果
在这一节中,选取3种主流推荐模型作为对比实验。从表4中可以看出,在AUC和F1两个指标下,SPGCN模型在3个数据集上的效果均优于其他模型。SPGCN模型在Last.FM数据集上AUC和F1指标分别提升了4.1%和3.5%,在MovieLens-20M数据集上分别提升了0.1%和0.4%,在Book-Crossing数据集上提升了3.0%和2.7%。其原因是相比较于MovieLens-20M数据集,Last.FM和Book-Crossing两个数据集稀疏程度更大,也表明了在图卷积网络中的非线性激活函数、特征变换等操作对推荐系统中的协同过滤操作不会起到很大的提升。
表 4 AUC和F1指标的实验结果Table 4 Experimental results of AUC and F1 indicators数据集 MovieLens-20M Last.FM Book-Crossing 算法 AUC F1 AUC F1 AUC F1 RippleNet 0.950 0.910 0.776 0.700 0.715 0.650 KGAN 0.965 0.926 0.788 0.722 0.734 0.681 KGCN 0.977 0.930 0.776 0.708 0.738 0.688 SPGCN 0.978 0.934 0.817 0.743 0.768 0.715 在表5中,设置了在不同的嵌入维度值d影响下AUC的情况。随着嵌入维度的不断增加,在Last.FM和Book-Crossing数据集上AUC值越来越高,而在MovieLens-20M数据集上AUC性能稍微有些减弱,但是其收敛速度较快,这是由于增加嵌入维度的大小,可以将更多的信息编码,较好的提升了模型的推荐性能,但是嵌入的维度过高,也会造成过拟合现象,所以一定要选择合适的嵌入维度。
表 5 不同的嵌入维度对SPGCN 模型AUC指标的影响Table 5 AUC result of SPGCN with different dimension of embedding数据集 嵌入维度 16 32 64 128 MovieLens-20M 0.978 0.977 0.976 0.976 Last.FM 0.815 0.819 0.824 0.828 Book-Crossing 0.735 0.746 0.776 0.768 在表6中,设置了采样邻域节点个数分别为2、4、8、16影响下AUC值的情况。实验表明,当采样的邻域节点数为4时,本模型的性能最优。当采样的邻域节点个数过多,系统性能反而下降,这是因为结合了过多的邻域节点信息,易产生过拟合现象导致AUC的值降低。
表 6 不同的采样的邻域节点个数N下AUC的值Table 6 Value of AUC under different sampled neighborhood nodes N数据集 N 2 4 8 16 Last.FM 0.814 0.820 0.815 0.814 MovieLena-20M 0.977 0.978 0.976 0.975 Book-Crossing 0.722 0.735 0.783 0.786 如图2~图4所示,具体描述了Last.FM、MovieLens-20和Book-crossing等3个数据集上在预测样例数量K(在指定返回用户K个项目的情况下,本模型的性能)值分别为1、2、5、10、20、50、100时下precision和recall两个指标的折线图。实验结果表明,随着K的不断增加,本模型SPGCN在图2、图3和图4中的precision指标和recall指标均要高于KGCN的precision指标和recall指标,这就证明了本文模型总体的性能要优于KGCN。SPGCN模型的实验效果更好,得益于本模型采用的是轻量级聚合器的优势,简化了图卷积操作,降低了模型训练的难度,因而,在较高的K值也能表现出很好的性能。
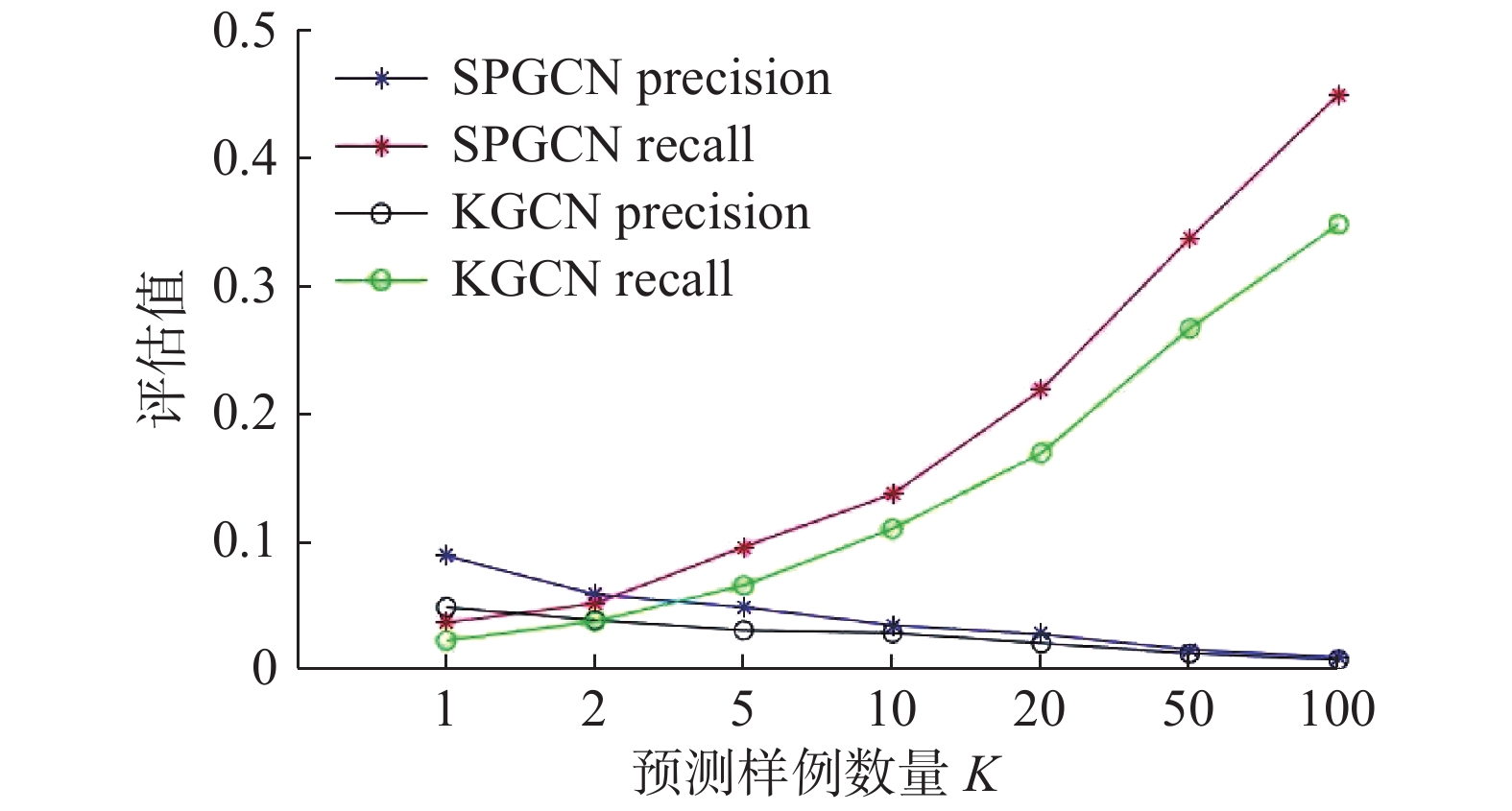 图 2 Last.FM数据集在不同的预测样例数量K下的实验结果Fig. 2 Experimental results of Last.FM under different number of prediction examples K下载:
全尺寸图片
图 2 Last.FM数据集在不同的预测样例数量K下的实验结果Fig. 2 Experimental results of Last.FM under different number of prediction examples K下载:
全尺寸图片
 图 3 Movie数据集在不同预测样例数量K下的实验结果Fig. 3 Experimental results of the Movie under different number of prediction examples K下载:
全尺寸图片
图 3 Movie数据集在不同预测样例数量K下的实验结果Fig. 3 Experimental results of the Movie under different number of prediction examples K下载:
全尺寸图片
 图 4 Book-Crossing数据集在不同的预测样例数量K下的实验结果Fig. 4 Experimental results of the Book-Crossing under different number of prediction examples K下载:
全尺寸图片
图 4 Book-Crossing数据集在不同的预测样例数量K下的实验结果Fig. 4 Experimental results of the Book-Crossing under different number of prediction examples K下载:
全尺寸图片
比较图2、图3和图4,可以发现SPGCN在Last.FM和Book-Crossing的表现效果比MovieLens-20M好,这是因为前者的稀疏程度更高,这也证明了模型也能更好地处理稀疏度更高的数据。
4. 结束语
为了实现更好的推荐,本文提出了一个基于知识图谱的轻量级的图卷积网络推荐系统的模型,在Last.FM、MovieLens-20M和Book-Crossing 3个数据集上进行训练和测试。
实验证明了传统的图卷积网络的特征变换、非线性激活等操作对协同过滤操作不会起很大的作用。因此将图卷积操作中聚合操作进行了改进,提升了模型的性能,并且模型在3个数据集上的取得了较好的效果。但是本模型的运算速度和基准模型的运算速度相差不大,因此在未来的工作中,可以考虑引入其他的辅助信息,比如社交网络等类似的信息实现更好的推荐,提高运算速度,进一步提高推荐性能。
-
图 1 SPGCN模型架构
Fig. 1 SPGCN model architecture
下载:
全尺寸图片
图 2 Last.FM数据集在不同的预测样例数量K下的实验结果
Fig. 2 Experimental results of Last.FM under different number of prediction examples K
下载:
全尺寸图片
图 3 Movie数据集在不同预测样例数量K下的实验结果
Fig. 3 Experimental results of the Movie under different number of prediction examples K
下载:
全尺寸图片
图 4 Book-Crossing数据集在不同的预测样例数量K下的实验结果
Fig. 4 Experimental results of the Book-Crossing under different number of prediction examples K
下载:
全尺寸图片
表 1 实验参数设置
Table 1 Experimental parameter settings
数据集 MovieLens-20M Last.FM Book-Crossing 优化函数 Adam Adam Adam Dropout 0.6 0.6 0.6 迭代次数 100 100 100 邻域的个数 4 4 4 Batch size 65536 128 128 学习率 2×10−2 5×10−4 2×10−4 嵌入维度 32 16 16 表 2 数据集的相关情况
Table 2 Statistics of datasets
数据集 用户数量 项目数量 交互数量 实体数量 关系数量 知识图谱三元组 MovieLens-20M 138159 16954 13501622 102569 32 499474 Last.FM 1872 3846 42346 9366 60 15518 Book-Crossing 19676 20003 172576 25787 18 60787 表 3 混淆矩阵
Table 3 Confusion matrix
预测 正样本 负样本 正样本 TP(真正例) FN(假反例) 负样本 FP(假正例) TN(真反例) 表 4 AUC和F1指标的实验结果
Table 4 Experimental results of AUC and F1 indicators
数据集 MovieLens-20M Last.FM Book-Crossing 算法 AUC F1 AUC F1 AUC F1 RippleNet 0.950 0.910 0.776 0.700 0.715 0.650 KGAN 0.965 0.926 0.788 0.722 0.734 0.681 KGCN 0.977 0.930 0.776 0.708 0.738 0.688 SPGCN 0.978 0.934 0.817 0.743 0.768 0.715 表 5 不同的嵌入维度对SPGCN 模型AUC指标的影响
Table 5 AUC result of SPGCN with different dimension of embedding
数据集 嵌入维度 16 32 64 128 MovieLens-20M 0.978 0.977 0.976 0.976 Last.FM 0.815 0.819 0.824 0.828 Book-Crossing 0.735 0.746 0.776 0.768 表 6 不同的采样的邻域节点个数N下AUC的值
Table 6 Value of AUC under different sampled neighborhood nodes N
数据集 N 2 4 8 16 Last.FM 0.814 0.820 0.815 0.814 MovieLena-20M 0.977 0.978 0.976 0.975 Book-Crossing 0.722 0.735 0.783 0.786 -
[1] COVINGTON P, ADAMS J, SARGIN E. Deep neural networks for YouTube recommendations[C]//Proceedings of the 10th ACM Conference on Recommender Systems. Boston Massachusetts USA. New York: ACM, 2016: 191−198. [2] YING R, HE RUINING, CHEN KAIFENG, et al. Graph convolutional neural networks for web-scale recommender systems[EB/OL]. New York: arXiv, 2018. (2018−06−06)[2021−07−08].https://arxiv.org/abs/1806.01973. [3] HE Xiangnan, HE Zhankui, SONG Jingkuan, et al. NAIS: neural attentive item similarity model for recommendation[J]. IEEE transactions on knowledge and data engineering, 2018, 30(12): 2354–2366. doi: 10.1109/TKDE.2018.2831682 [4] YUAN Fajie, HE Xiangnan, ALEXANDROS Karatzoglou, et al. Parameter-efficient transfer from sequential behaviors for user modeling and recommendation[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 1469−1478. [5] He Xiangnan, LIAO Lizi, ZHAGN Hanwang, et al. Neural collaborative filtering[C]//Proceedings of the 26th International Conference on World Wide Web. New York: ACM, 2017: 173−182. [6] 徐海文, 谭台哲. 基于知识图谱的个性化推荐系统构建[J]. 数字技术与应用, 2022, 40(3): 152−154,164. [7] 汪滢. 基于区块链技术的旅游产品个性化推荐系统[J]. 数字通信世界, 2022(3): 41–43. WANG Ying. Personalized recommendation system of tourism products based on blockchain technology[J]. Digital communication world, 2022(3): 41–43. [8] 王越群. 基于知识图谱的深度推荐系统研究[D]. 长春: 吉林大学, 2022. WANG Yuequn. Research on deep recommendation system based on knowledge graph[D]. Changchun: Jilin university, 2022. [9] RENDLE S, GANTNER Z, FREUDENTHALER C, et al. Fast context-aware recommendations with factorization machines[C]//Proceedings of the 34th international ACM SIGIR conference on Research and development in Information—SIGIR’11. New York: ACM Press, 2011: 635−644. [10] CHENG Heng-Tze, LEVENT Koc, JEREMIAH Harmsen, et al. Wide & deep learning for recommender systems[C]//Proceedings of the 1st workshop on deep learning for recommender systems. New York: ACM, 201: 7−10. [11] HE XIANGNAN, CHUA T S. Neural factorization machines for sparse predictive analytics[EB/OL]. New York: arXiv, 2017. (2017−08−16)[2021−07−01].https://arxiv.org/abs/1708.05027. [12] GUO HUIFENG, TANG RUIMING, YE YUNMING, et al. DeepFM: a factorization-machine based neural network for CTR prediction[EB/OL]. New York: arXiv, 2017. (2017−03−13)[2021−07−01].https://arxiv.org/abs/1703.04247. [13] KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. New York: arXiv, 2016. (2016−09−09) [2021−07−01].https://arxiv.org/abs/1609.02907. [14] WANG Xiang, HE Xiangnan, WANG Meng, et al. Neural graph collaborative filtering[EB/OL]. (2019−03−20)[2021−07−01].https://www.semanticscholar.org/paper/Neural-Graph-Collaborative-Filtering-Wang-He. [15] WANG Hongwei, ZHAO Miao, XIE Xing, et al. Knowledge graph convolutional networks for recommender systems[C]//The World Wide Web Conference on - WWW’19. New York: ACM Press, 2019: 3307−3313. [16] JI Shaoxiong, PAN Shirui, CAMBRIA E, et al. A survey on knowledge graphs: representation, acquisition, and applications[J]. IEEE transactions on neural networks and learning systems, 2022, 33(2): 494–514. doi: 10.1109/TNNLS.2021.3070843 [17] WANG Hongwei, ZHANG Fuzheng, ZHANG Mengdi, et al. Knowledge-aware graph neural networks with label smoothness regularization for recommender systems[C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York: ACM Press, 2019. [18] GUAN Saiping, JIN Xiaolong, WANG Yuanzhuo, et al. Shared embedding based neural networks for knowledge graph completion[C]//Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM, 2018: 247−256. [19] WANG Hongwei, ZHANG Fuzheng, WANG Jialin, et al. RippleNet: propagating user preferences on the knowledge graph for recommender systems[C]//Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM, 2018: 417−426. [20] WANG Xiang, HE Xiangnan, CAO Yixin, et al. KGAT: knowledge graph attention network for recommendation[C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York: ACM, 2019: 950−958.































































































