
Incomplete multi-view subspace learning through dual low-rank decompositions
-
摘要: 多视图数据在现实世界中应用广泛,各种视角和不同的传感器有助于更好的数据表示,然而,来自不同视图的数据具有较大的差异,尤其当多视图数据不完整时,可能导致训练效果较差甚至失败。为了解决该问题,本文提出了一个基于双重低秩分解的不完整多视图子空间学习算法。所提算法通过两方面来解决不完整多视图问题:一方面,基于双重低秩分解子空间框架,引入潜在因子来挖掘多视图数据中缺失的信息;另一方面,通过预先学习的多视图数据低维特征获得更好的鲁棒性,并以有监督的方式来指导双重低秩分解。实验结果证明,所提算法较之前的多视图子空间学习算法有明显优势;即使对于不完整的多视图数据,该算法也具有良好的分类性能。Abstract: Multi-view data are very common in real-world applications. Different viewpoints and sensors tend to facilitate better data representation. However, data from various perspectives show a significant variation. Especially when only incomplete multi-view data are available, the corresponding multi-view learning may result in poor performance or even training failure. This study proposes a multi-view learning algorithm called IMSL (Incomplete Multi-View Subspace Learning through Dual Low-Rank Decompositions) to tackle this issue. The proposed algorithm addresses the incomplete multi-view problem in two ways: (1) Latent factors are introduced into a dual low-rank decomposition subspace framework to mine missing information in the multi-view data. (2) IMSL seeks a more robust subspace through pre-learned low-dimensional features of multi-view data. Furthermore, the supervised data are used to guide dual low-rank decompositions. Experimental results show that the proposed algorithm outperforms the previous multi-view subspace learning algorithms on the adopted incomplete multi-view datasets. Pre-learning low-dimensional features of multi-view data, on the other hand, can improve robustness, and dual low-rank decomposition can be guided in a supervised manner.
-
近年来,多视图[1-2]数据分析已经引起了越来越广泛的关注,由于科技的发展,不同类型的传感器可以从多个角度采集数据,这为我们提供了丰富的样本。但是,随之也带来了相关挑战,多视图数据中的同一类标签往往对应多个不同的样本,甚至是异构的。这导致了一个学习困难的问题,若多视图的类内数据相似性低于同一视图不同类之间的相似性,将会导致算法效果较差甚至失败。一般来说,多视图数据分析可采用3种策略:1)特征自适应算法[3-4],旨在寻找一个公共空间,不同视图之间的特征可以在该空间中很好地对齐;2)分类器自适应算法[5],旨在获得适用不同的视图的分类器;3)深度学习算法[6-7],旨在构建层次结构以捕获更多区分性特征以减轻视图分歧。本文主要采用特征自适应策略来寻找不同视图之间共享的低秩子空间。
在特征自适应方面,子空间学习[8-9]成为较热的研究热点,并在许多领域得到了广泛的运用。具体而言,子空间学习本质上是试图找到一个合适的子空间,在该子空间中尽可能地保留原始特征的区分性表示。子空间学习被引入多视图数据分析中以减轻不同视图之间的特征差异,通过常规子空间学习方法获得公共特征空间,可以解决维数诅咒和不同视图之间分布差异的问题。
低秩约束[10]已经在数据表示中被广泛采用,它最初通过找到最低秩表示并检测噪声或离群值来帮助发现数据的多个结构。因此,Zhang等[11]采用了双重低秩分解来处理大量损坏的数据情况,但是他们只是将数据在原始的高维空间中进行低秩分解,并没有考虑到多视图之间的类结构信息与视图结构信息。此外,低秩约束被集成到子空间学习框架中以帮助处理高维数据,多视图数据的投影子空间结构可以通过低秩约束的感知位置重构特性被挖掘,从而达到减轻不同视图之间的差异的效果。
当数据在恢复底层结构方面受到限制时,从不足的观测数据中挖掘潜在的知识就变得很必要。潜在因子[12-14]在许多数据挖掘和机器学习应用场景中起着关键作用,它通过使用贪婪搜索、推断或近似算法试图寻找一些人或机器无法观测到的隐藏变量。在本文中,潜在因子被引入双重低秩分解子空间学习框架中以帮助恢复视图数据中丢失的信息,这与传统的多视图数据分析方法区分开来。
一般来说,对于常规的多视图数据分析算法,它们关注的核心问题是如何在数据分析过程中尽量减小不同视图之间的差异,这导致它们大都需要一个必要的前提条件:在训练阶段需要完整的视图信息参与算法的训练。然而,当多视图数据不完整[15]时,这些常规的多视图数据分析算法则效果较差甚至失败。不幸的是,许多现实应用场景条件苛刻,例如本文关注的不完整多视图问题,它的视图信息就是残缺的。常规的多视图数据分析算法无法很好地解决该问题,幸运的是,Liu等[16]提出可以通过潜在因子来帮助修复不完整的视图信息,这为本文的不完整多视图问题提供了一个很好的解决思路。
为了克服上述挑战,本文提出了一种基于双重低秩分解的不完整多视图子空间学习算法(incomplete multi-view subspace learning through dual low-rank decompositions,IMSL),所提算法可以解决不完整多视图问题。算法的主要思想是基于双重低秩[17]分解子空间学习框架,引入潜在因子修复丢失的信息。此外,本文通过预先学习多视图数据的低维特征来有效地促进视图之间的特征对齐。本文的主要贡献总结可以归纳如下:
1)基于双重低秩分解多视图子空间学习框架,引入潜在因子以解决不完整多视图问题,并以有监督的方式来指导双重低秩分解。
2)通过预先学习多视图数据的低维特征来促进不同视图之间的特征对齐,保证算法具有更好的鲁棒性。
3)在人脸识别、物体分类等数据集上,大量的实验验证了所提算法的有效性,相较于传统的多视图学习算法有明显优势。
1. 不完整多视图子空间学习
1.1 问题形式化
在不完整多视图数据分析场景下,给定多视图数据
${{\boldsymbol{X}}} = [{{{\boldsymbol{X}}}_1}\;\;{{{\boldsymbol{X}}}_2}\;\; \cdots \;\;{{{\boldsymbol{X}}}_m}]$ ,每个视图${{{\boldsymbol{X}}}_i} \in {{\bf{R}}^{d \times {n_i}}}$ ,这里一共有$ m $ 个视图,其中$ d $ 是原始特征维数,$ {n_i} $ 代表单个视图中的样本数量。多视图数据共包括$ C $ 类样本,但单个视图并不包含所有类别样本,不同视图数据之间具有分布差异。因此,只是单纯地对多视图进行低秩分解解析结构信息并不足以帮助我们取得较好的实验效果,还需要意识到丢失信息的重要性。所以本文基于双重低秩分解子空间学习框架,引入潜在因子挖掘丢失的视图信息,致力于寻找多视图数据的共享子空间来传递视图数据中的判别性区分能力并减轻不同视图之间的分布差异。如图1所示,相同的颜色表示数据同类别,相同的形状表示数据同视图,所提算法通过不完整多视图对齐预先学习多视图数据的低维特征,并通过施加潜在因子的双重低秩分解将视图结构与类别结构彼此分开。 图 1 本文的算法框架Fig. 1 Algorithm framework of this paper
图 1 本文的算法框架Fig. 1 Algorithm framework of this paper 下载:
全尺寸图片
下载:
全尺寸图片
1.2 不完整多视图对齐
多视图数据分析中,不同视图由于不同来源可能具有不同的分布,为了保证它们可以传递有效的知识,将它们进行特征对齐[18]是非常必要的。此外,预先学习数据的低维特征将在算法迭代过程中保持固定,这提高了算法的鲁棒性。假设
${{{\boldsymbol{Y}}}_i} \in {{\bf{R}}^{p \times {n_i}}}$ 是每个视图预先学习到的低维特征,${{\boldsymbol{Y}}} = [{{{\boldsymbol{Y}}}_1}\;\;{{{\boldsymbol{Y}}}_2}\;\; \cdots \;\;{{{\boldsymbol{Y}}}_m}] \in {{\bf{R}}^{p \times n}}\left(n = \displaystyle\sum_i {{n_i}} \right)$ ,这里$ p $ 表示降维后的低维特征的维度。本文通过拉普拉斯矩阵[19]来进行多视图的特征对齐并获得它们的低维特征表示,具体细节为$$ {{\boldsymbol{Y}}} = \mathop {\arg \min }\limits_{{\boldsymbol{Y}}} \frac{{{\text{tr}}({{{\boldsymbol{Y}}}^{\rm T}}{{{\boldsymbol{S}}}_w}{{\boldsymbol{Y}}})}}{{{\text{tr}}({{{\boldsymbol{Y}}}^{\rm T}}{{{\boldsymbol{S}}}_b}{{\boldsymbol{Y}}})}} $$ (1) 这里
${{{\boldsymbol{S}}}_w} \in {{\bf{R}}^{n \times n}}$ 与${{{\boldsymbol{S}}}_b} \in {{\bf{R}}^{n \times n}}$ 分别代表多视图数据的类内拉普拉斯矩阵与类间拉普拉斯矩阵。本文旨在预先学习低维特征的过程中尽量保留更多的类内信息而尽量增大类间的差异,具体的拉普拉斯矩阵定义为$$ {\boldsymbol{G}}_{w}^{ij}=\left\{\begin{split} &{\rm{exp}}\left(-\dfrac{{\Vert {x}_{i}-{x}_{j}\Vert }^{2}}{2{\sigma }^{2}}\right),\quad {l}_{i}={l}_{j}\\ &0,\quad {其他}\end{split} \right.$$ $$ {\boldsymbol{G}}_{b}^{ij}=\left\{\begin{split} &{\rm{exp}}\left(-\dfrac{{\Vert {x}_{i}-{x}_{j}\Vert }^{2}}{2{\sigma }^{2}}\right),\quad {l}_{i}\ne {l}_{j}\\ &0,\quad{其他}\end{split} \right.$$ 式中:
$ {x_i} $ 、$ {x_j} $ 分别表示多视图的第$ i $ 和第$ j $ 个样本;$ {l_i} $ 、$ {l_j} $ 分别是$ {x_i} $ 与$ {x_j} $ 的标签信息;$ \sigma $ 为高斯核的带宽。${{{\boldsymbol{S}}}_w} = {{{\boldsymbol{G}}}_w} - {{{\boldsymbol{D}}}_w}$ ,${{{\boldsymbol{S}}}_b} = {{{\boldsymbol{G}}}_b} - {{{\boldsymbol{D}}}_b}$ ,其中${{\boldsymbol{D}}}_w^{}$ 、${{\boldsymbol{D}}}_b^{}$ 分别为对角矩阵且${{\boldsymbol{D}}}_w^{ii} = \displaystyle\sum\nolimits_j {{{\boldsymbol{G}}}_w^{ij}}$ 、${{\boldsymbol{D}}}_b^{ii} = \displaystyle\sum\nolimits_j {{{\boldsymbol{G}}}_b^{ij}}$ ,至此,${{\boldsymbol{Y}}}$ 可通过式(2)特征分解得到:$$ {{{\boldsymbol{S}}}_w}{{\boldsymbol{Y}}} = \upsilon {{{\boldsymbol{S}}}_b}{{\boldsymbol{Y}}} $$ (2) 式中:
$ \upsilon $ 是${{{\boldsymbol{S}}}_w}$ 相对于${{{\boldsymbol{S}}}_b}$ 的特征值;${{\boldsymbol{Y}}}$ 是最小的$ p $ 个特征值所对应的特征向量。预先学习的低维特征可以在低维空间中减轻原始空间中多视图的分布散度。1.3 基于双重低秩分解的子空间学习
在不完整多视图问题中,如何恢复丢失部分的视图信息是我们解决该问题的重点。为了恢复丢失部分的视图信息,本文首先假定丢失部分的视图信息是可观测的,因此多视图数据可以定义为
${{\boldsymbol{X}}} = [{{{\boldsymbol{X}}}^O},{{{\boldsymbol{X}}}^U}]$ ,${{{\boldsymbol{X}}}^O}$ 为保留的视图信息,${{{\boldsymbol{X}}}^U}$ 为丢失的视图信息。因此,针对多视图数据,引入低秩约束子空间学习公式:$$ \mathop {\min }\limits_{Z} {\text{ rank}}({{\boldsymbol{Z}}})\;\;{\text{ s}}{\text{.t}}{\text{. }}{{\boldsymbol{Y}}} = {{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{XZ}}} $$ (3) 式中:
$ {\text{rank}}( \cdot ) $ 代表矩阵的秩;${{\boldsymbol{Z}}} \in {{\bf{R}}^{n \times n}}$ 代表多视图的低秩重构系数矩阵,这可以帮助指导多视图的局部位置感知重建。众所周知,秩最小化问题[20]为非收敛性问题,Liu等[16]利用凸替代来解决该问题,即核范数。因此,式(3)可被重新定义为$$ \mathop {\min }\limits_{Z} {\text{ }}{\left\| {{\boldsymbol{Z}}} \right\|_ * }\;\;{\text{ s}}{\text{.t}}{\text{. }}{{\boldsymbol{Y}}} = {{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{XZ}}} $$ (4) 式中
$ {\left\| \cdot \right\|_ * } $ 代表矩阵的核范数,等于矩阵的奇异值之和。假设式(4)具有唯一解,那么
${{\boldsymbol{Y}}} \subseteq {\text{span}}({{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}})$ ,因此,可以将${{\boldsymbol{Y}}}$ 和${{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}$ 整合为$[{{\boldsymbol{Y}}},{{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}]$ 且进行奇异值分解,即$[{{\boldsymbol{Y}}},{{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}] = {{\boldsymbol{U\varSigma}} }{{{\boldsymbol{V}}}^{\rm T}}$ ,其中${{\boldsymbol{V}}} = [{{{\boldsymbol{V}}}_{Y}},{{{\boldsymbol{V}}}_{X}}]$ 。$[{{\boldsymbol{Y}}},{{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}]$ 经过奇异值分解后可分为${{\boldsymbol{Y}}} = {{\boldsymbol{U\varSigma V}}}_{Y}^{\rm T}$ 和${{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}} = {{\boldsymbol{U\varSigma V}}}_{X}^{\rm T}$ 。将这两式代入式(4)的约束条件可得${{\boldsymbol{U\varSigma V}}}_{Y}^{\rm T} = {{\boldsymbol{U\varSigma V}}}_{X}^{\rm T}{{\boldsymbol{Z}}}$ ,化简后可得${{\boldsymbol{V}}}_{Y}^{\rm T} = {{\boldsymbol{V}}}_{X}^{\rm T}{{\boldsymbol{Z}}}$ ,推导得${{\boldsymbol{Z}}} = {{{\boldsymbol{V}}}_{X}}{{\boldsymbol{V}}}_{Y}^{\rm T} = [{{{\boldsymbol{V}}}_{{{X}^O}}};{{{\boldsymbol{V}}}_{{{X}^U}}}]{{\boldsymbol{V}}}_{Y}^{\rm T}$ 。至此,目标函数的约束条件可被整理为$$ \begin{gathered} {{\boldsymbol{Y}}} = {{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{XZ}}} = {{{\boldsymbol{P}}}^{\rm T}}[{{{\boldsymbol{X}}}^O},{{{\boldsymbol{X}}}^U}][{{{\boldsymbol{V}}}_{{{X}^O}}};{{{\boldsymbol{V}}}_{{{X}^U}}}]{{\boldsymbol{V}}}_{Y}^{\rm T} = \\ {{{\boldsymbol{P}}}^{\rm T}}{{{\boldsymbol{X}}}^O}{{{\boldsymbol{V}}}_{{{X}^O}}}{{\boldsymbol{V}}}_{Y}^{\rm T} + {{{\boldsymbol{P}}}^{\rm T}}{{{\boldsymbol{X}}}^U}{{{\boldsymbol{V}}}_{{{X}^U}}}{{\boldsymbol{V}}}_{Y}^{\rm T}= \\ {{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{XZ}}} + {{\boldsymbol{U\varSigma V}}}_{{{X}^U}}^{\rm T}{{{\boldsymbol{V}}}_{{{X}^U}}}{{{\boldsymbol{\varSigma }}}^{ - 1}}{{{\boldsymbol{U}}}^{\rm T}}{{\boldsymbol{Y}}} = \\ {{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{XZ}}} + {{\boldsymbol{LY}}} \\ \end{gathered} $$ (5) 式中
${{\boldsymbol{U\varSigma V}}}_{{{X}^U}}^{\rm T}{{{\boldsymbol{V}}}_{{{X}^U}}}{{{\boldsymbol{\varSigma}} }^{ - 1}}{{{\boldsymbol{U}}}^{\rm T}}={{\boldsymbol{L}}}$ 。由式(5)可知,${{\boldsymbol{L}}}$ 包含了丢失的视图信息,因此对${{\boldsymbol{L}}}$ 进行优化求解即可对${{{\boldsymbol{X}}}^U}$ 优化求解,从而达到恢复丢失的视图信息的效果。因此式(4)可以被重新定义:$$ \mathop {\min }\limits_{{Z},{L}} {\text{ }}{\left\| {{\boldsymbol{Z}}} \right\|_ * } + {\left\| {{\boldsymbol{L}}} \right\|_ * }\;\;{\text{ s}}{\text{.t}}{\text{. }}{{\boldsymbol{Y}}} = {{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{XZ}}} + {{\boldsymbol{LY}}} $$ (6) 式(6)与常规的低秩约束子空间学习相比,引入潜在因子以处理不完整多视图问题。从几何角度分析,式(6)实际上提出了通过列重构[21]与行重构[18]来重构低维视图特征,列重构通常被认为是字典学习,行重构则被称为潜在因子。在数据矩阵中,列空间代表主要特征,行空间代表关键对象部分,当数据中的某些样本丢失(即数据矩阵中的某些列为空),通过行重构来恢复数据是非常行之有效的。
然而,潜在因子只能够帮助我们恢复丢失的视图信息,而对于多类别的多视图数据,若同一类别的不同视图特征差异较大,这将导致低秩约束
${{\boldsymbol{Z}}}$ 无法揭示类结构信息。实际上,多视图数据包含类结构和视图差异结构,类结构旨在揭示类信息的全局结构,视图差异结构旨在保留不同类之间的视图信息,两种独立的结构相互交织在一起。因此,${{\boldsymbol{Z}}}$ 可被分解为两个低秩部分[22],即$$ \begin{gathered} \mathop {\min }\limits_{{{{\boldsymbol{Z}}}_c},{{{\boldsymbol{Z}}}_v},{{\boldsymbol{L}}}} {\text{ }}{\left\| {{{{\boldsymbol{Z}}}_c}} \right\|_ * } + {\left\| {{{{\boldsymbol{Z}}}_v}} \right\|_ * } + {\left\| {{\boldsymbol{L}}} \right\|_ * } \\ {\text{s}}{\text{.t}}{\text{. }}{{\boldsymbol{Y}}} = {{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}({{{\boldsymbol{Z}}}_c} + {{{\boldsymbol{Z}}}_v}) + {{\boldsymbol{LY}}} \\ \end{gathered} $$ (7) 这里
${{{\boldsymbol{Z}}}_c} \in {{\bf{R}}^{n \times n}}$ 代表的是类结构的低秩表示,${{{\boldsymbol{Z}}}_v} \in {{\bf{R}}^{n \times n}}$ 代表的是视图差异结构的低秩表示。由式(7)可知,低秩约束${{\boldsymbol{Z}}}$ 被分解为${{{\boldsymbol{Z}}}_c}$ 和${{{\boldsymbol{Z}}}_v}$ ,这样类结构信息和视图差异结构信息被彼此分离,避免了较大的视图差异影响类信息的全局结构。此外,为了放松原始问题,本文将稀疏项${{\boldsymbol{E}}} \in {{\bf{R}}^{p \times n}}$ 引入目标函数,将原本的硬约束转换为软约束,避免了潜在的过拟合问题。至此,目标函数可被归纳为$$ \begin{gathered} \mathop {\min }\limits_{{{{\boldsymbol{Z}}}_c},{{{\boldsymbol{Z}}}_v},{{\boldsymbol{L}}}} {\text{ }}{\left\| {{{{\boldsymbol{Z}}}_c}} \right\|_ * } + {\left\| {{{{\boldsymbol{Z}}}_v}} \right\|_ * } + {\left\| {{\boldsymbol{L}}} \right\|_ * } + \lambda {\left\| {{\boldsymbol{E}}} \right\|_1} \\ {\text{s}}{\text{.t}}{\text{. }}{{\boldsymbol{Y}}} = {{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}({{{\boldsymbol{Z}}}_c} + {{{\boldsymbol{Z}}}_v}) + {{\boldsymbol{LY}}} + {{\boldsymbol{E}}} \\ \end{gathered} $$ (8) 式中
$ {\left\| \cdot \right\|_{\text{1}}} $ 表示矩阵的1范数。这里,我们只是采用无监督的方式来指导多视图的双重低秩分解。但是,无监督的方式无法将类结构信息与视图差异结构信息完全地剥离开来,因此有必要利用多视图的标签信息来完成双重低秩分解。1.4 监督信息对齐
在不完整多视图问题中,本文期望通过有监督的方式将相互交织在一起的类结构信息与视图差异结构信息分离开来,因此针对类结构与视图差异结构,本文定义了两个监督图正则化项以此来指导多视图的双重低秩分解。假设类结构的低维特征
${{{\boldsymbol{Y}}}_c} = {{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}{{{\boldsymbol{Z}}}_c}$ ,视图差异结构的低维特征${{{\boldsymbol{Y}}}_v} = {{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}{{{\boldsymbol{Z}}}_v}$ ,本文旨在最小化类内相似性的同时最大化视图间的差异性,以此来保留更多的类内信息并消除视图差异的影响。具体的正则化项定义为$$ \begin{gathered} {{{\boldsymbol{R}}}_c} = \displaystyle\sum\nolimits_{i,j} {({{{\boldsymbol{Y}}}_{c,i}} - {{{\boldsymbol{Y}}}_{c,j}})} {{\boldsymbol{W}}}_{i,j}^c \\ {{{\boldsymbol{R}}}_v} = \displaystyle\sum\nolimits_{i,j} {({{{\boldsymbol{Y}}}_{v,i}} - {{{\boldsymbol{Y}}}_{v,j}})} {{\boldsymbol{W}}}_{i,j}^v \\ \end{gathered} $$ (9) 式中:
${{{\boldsymbol{Y}}}_{c,i}}$ 、${{{\boldsymbol{Y}}}_{c,j}}$ 分别为${{{\boldsymbol{Y}}}_c}$ 的第$ i $ 和第$ j $ 个样本;${{{\boldsymbol{Y}}}_{v,i}}$ 、${{{\boldsymbol{Y}}}_{v,j}}$ 分别为${{{\boldsymbol{Y}}}_v}$ 的第$ i $ 和第$ j $ 个样本;${{\boldsymbol{W}}^c_{i,j}}$ 、${{{\boldsymbol{W}}}^v_{i,j}}$ 则分别是类结构的低维特征与视图差异结构的低维特征的权重矩阵[23],它们的具体定义$$ {\boldsymbol{W}}_{i,j}^{c}=\left\{\begin{split} &1,\quad{x}_{i}\in {{N}}_{{k}_{1}}({x}_{j})\text{,}且\text{ }{l}_{i}={l}_{j}\\ &0,\quad{其他}\end{split}\right. $$ (10) $$ {\boldsymbol{W}}_{i,j}^{v}=\left\{\begin{split} &1,\quad {x}_{i}\in {{N}}_{{k}_{2}}({x}_{j})\text{,}且\text{ }{l}_{i}\ne {l}_{j}\\ &0,\quad{其他}\end{split}\right. $$ (11) 这里,
$ {l_i} $ 、$ {l_j} $ 分别是$ {x_i} $ 与$ {x_j} $ 的标签信息,${x_i} \in {{{\boldsymbol{N}}}_{{k_1}}}({x_j})$ 表示$ {x_i} $ 属于同类别的$ {x_j} $ 的$ {k_1} $ 个最近邻居集合,${x_i} \in {{{\boldsymbol{N}}}_{{k_2}}}({x_j})$ 表示$ {x_i} $ 属于同视图的$ {x_j} $ 的$ {k_2} $ 个最近邻居集合。至此,本文采用类似LDA函数的形式来统一式(9)以求最小化类内方差且最大化同视图,但不同类的边际分布差异,其具体形式为$$ \begin{gathered} {{\boldsymbol{R}}}({{\boldsymbol{P}}},{{{\boldsymbol{Z}}}_c},{{{\boldsymbol{Z}}}_v}) = \dfrac{{{{{\boldsymbol{R}}}_c}}}{{{{{\boldsymbol{R}}}_v}}} = \dfrac{{{\text{tr}}({{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}{{{\boldsymbol{Z}}}_c}{{{\boldsymbol{L}}}_c}{{({{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}{{{\boldsymbol{Z}}}_c})}^{\rm T}})}}{{{\text{tr}}({{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}{{{\boldsymbol{Z}}}_v}{{{\boldsymbol{L}}}_v}{{({{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}{{{\boldsymbol{Z}}}_v})}^{\rm T}})}} = \\ {\text{tr}}({{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}{{{\boldsymbol{Z}}}_c}{{{\boldsymbol{L}}}_c}{({{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}{{{\boldsymbol{Z}}}_c})^{\rm T}}) - {\text{tr}}({{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}{{{\boldsymbol{Z}}}_v}{{{\boldsymbol{L}}}_v}{({{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}{{{\boldsymbol{Z}}}_v})^{\rm T}}) \\ \end{gathered} $$ (12) 式中
${{{\boldsymbol{L}}}_c}$ 、${{{\boldsymbol{L}}}_v}$ 分别是${{{\boldsymbol{W}}}^c}$ 和${{{\boldsymbol{W}}}^v}$ 的拉普拉斯矩阵。由此,同一类中的局部流形结构得以保留,且减轻了视图流形的影响。1.5 目标函数和优化
至此,有监督的双重低秩分解可以将相互交织在一起的多视图数据中的类结构与视图结构分离开来,而在此双重低秩分解下学习到的健壮子空间使类内数据更加紧凑,同时最大化同一视图内不同类别的数据之间的边际分布差异。因此,基于双重低秩分解的不完整多视图子空间学习的目标函数可以被定义为
$$ \begin{gathered} \mathop {\min }\limits_{{{{\boldsymbol{Z}}}_c},{{{\boldsymbol{Z}}}_v},{{\boldsymbol{L}}},{{\boldsymbol{P}}},{{\boldsymbol{E}}}} {\text{ }}{\left\| {{{{\boldsymbol{Z}}}_c}} \right\|_ * } + {\left\| {{{{\boldsymbol{Z}}}_v}} \right\|_ * } +\\ {\left\| {{\boldsymbol{L}}} \right\|_ * } + \lambda {\left\| {{\boldsymbol{E}}} \right\|_1} + \alpha {{\boldsymbol{R}}}({{\boldsymbol{P}}},{{{\boldsymbol{Z}}}_c},{{{\boldsymbol{Z}}}_v}) \\ {\text{s}}{\text{.t}}{\text{. }}{{\boldsymbol{Y}}} = {{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{X}}}({{{\boldsymbol{Z}}}_c} + {{{\boldsymbol{Z}}}_v}) + {{\boldsymbol{LY}}} + {{\boldsymbol{E}}},{\text{ }}{{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{P}}} = {{{\boldsymbol{I}}}_{P}} \\ \end{gathered} $$ (13) 式中
$ \lambda $ 和$ \alpha $ 是平衡参数。${{{\boldsymbol{P}}}^{\rm T}}{{\boldsymbol{P}}} = {{{\boldsymbol{I}}}_{P}}$ 表示对P施加正交约束,这可以避免子空间${{\boldsymbol{P}}}$ 的任意小的平凡解。问题可以通过已有的算法——增广拉格朗日方法(ALM)来解决,于是本文引入3个松弛变量
${{{\boldsymbol{J}}}_c}$ 、${{{\boldsymbol{J}}}_v}$ 和${{\boldsymbol{K}}}$ 将式(13)转换为最小化问题,即$$ \begin{gathered} \mathop {\min }\limits_{{{\boldsymbol{Z}}_c},{{\boldsymbol{Z}}_v},{\boldsymbol{L}},{\boldsymbol{P}},{\boldsymbol{E}}.{{\boldsymbol{J}}_c},{{\boldsymbol{J}}_v},{\boldsymbol{K}}} {\left\| {{{\boldsymbol{J}}_c}} \right\|_*} + {\left\| {{{\boldsymbol{J}}_v}} \right\|_*} +\\ {\left\| {\boldsymbol{K}} \right\|_*} + \lambda {\left\| {\boldsymbol{E}} \right\|_1} + \alpha {{\boldsymbol{R}}}\left({{\boldsymbol{P}}}, {{\boldsymbol{Z}}}_{c}, {\boldsymbol{Z}}_{v}\right)\\ \text { s.t. } {\boldsymbol{Y}}={\boldsymbol{P}}^{\rm{r}} {{\boldsymbol{X}}}\left({\boldsymbol{Z}}_{c}+{\boldsymbol{Z}}_{v}\right)+{\boldsymbol{L Y}}+{\boldsymbol{E}} \text {, }\\ {{\boldsymbol{Z}}}_{c}={{\boldsymbol{J}}}_{c}, {{\boldsymbol{Z}}}_{\rm{v}}={{\boldsymbol{J}}}_{{v}},{{\boldsymbol{L}}}={{\boldsymbol{K}}}, {{\boldsymbol{P}}}^{\rm{x}} {{\boldsymbol{P}}}={{\boldsymbol{I}}}_{{P}} \end{gathered} $$ (14) 式(14)的拉格朗日函数形式为
$$ \begin{gathered} \varGamma=\left\|{\boldsymbol{J}}_{c}\right\|_{*}+\left\|{\boldsymbol{J}}_{v}\right\|_{*}+\|{{\boldsymbol{K}}}\|_{*}+\lambda\|{\boldsymbol{E}}\|_{1}+\alpha {\boldsymbol{R}}\left({\boldsymbol{P}}, {\boldsymbol{Z}}_{c}, {\boldsymbol{Z}}_{v}\right)+\\ \left\langle {\boldsymbol{Y}}_{1}, {\boldsymbol{Y}}-{\boldsymbol{P}}^{r} {\boldsymbol{X}}\left({\boldsymbol{Z}}_{t}+{\boldsymbol{Z}}_{v}\right)-{\boldsymbol{L Y}}-{\boldsymbol{E}}\right\rangle+\left\langle {\boldsymbol{Y}}_{2}, {\boldsymbol{Z}}_{t}-{\boldsymbol{J}}_{c}\right\rangle+\\ \left\langle {\boldsymbol{Y}}_{3}, {\boldsymbol{Z}}_{v}-{\boldsymbol{J}}_{v}\right\rangle+\left\langle {\boldsymbol{Y}}_{4}, {\boldsymbol{L}}-{\boldsymbol{K}}^{\prime}\right\rangle+\\ \frac{\mu}{2}\left(\left\|{\boldsymbol{Y}}-{\boldsymbol{P}}^{r} {\boldsymbol{X}}\left({\boldsymbol{Z}}_{t}+{\boldsymbol{Z}}_{v}\right)-{\boldsymbol{L Y}}-{\boldsymbol{E}}\right\|_{F}^{2}+\left\|{\boldsymbol{Z}}_{c}-{\boldsymbol{J}}_{c}\right\|_{F}^{2}+\right.\\ \left.\left\|{\boldsymbol{Z}}_{v}-{\boldsymbol{J}}_{v}\right\|_{P}^{2}+\|{\boldsymbol{L}}-{\boldsymbol{K}}\|_{P}^{2}\right) \end{gathered} $$ (15) 式中:
${{{\boldsymbol{Y}}}_1}$ 、${{{\boldsymbol{Y}}}_2}$ 、${{{\boldsymbol{Y}}}_3}$ 和${{{\boldsymbol{Y}}}_4}$ 是4个拉格朗日乘子;$ \mu > 0 $ 是惩罚参数;$ \left\langle {} \right\rangle $ 表示矩阵的内积,即$\left\langle {{{\boldsymbol{A}}},{{\boldsymbol{B}}}} \right\rangle = {\text{tr}}({{{\boldsymbol{A}}}^{\rm T}}{{\boldsymbol{B}}})$ 。我们无法同时更新优化${{{\boldsymbol{J}}}_c}$ 、${{{\boldsymbol{J}}}_v}$ 、${{{\boldsymbol{Z}}}_c}$ 、${{{\boldsymbol{Z}}}_v}$ 、${{\boldsymbol{L}}}$ 、${{\boldsymbol{K}}}$ 、${{\boldsymbol{E}}}$ 和${{\boldsymbol{P}}}$ ,幸运的是,我们可以通过交替方向乘子法(altermating direction method of multipliers, ADMM)依次地解决每个子问题,并不断地迭代更新优化这些参数直至收敛。具体而言,当我们更新其中一个参数时,需要固定其他参数。假设当前迭代次数为$ t $ ($ t \geqslant 0 $ ),$ t + 1 $ 次迭代具体各项的更新为1)固定
$ {{{\boldsymbol{J}}}_v} $ 、$ {{{\boldsymbol{Z}}}_c} $ 、$ {{{\boldsymbol{Z}}}_v} $ 、$ {{\boldsymbol{L}}} $ 、$ {{\boldsymbol{K}}} $ 、$ {{\boldsymbol{E}}} $ 和$ {{\boldsymbol{P}}} $ ,将它们视为常数项,从而得到$ {{{\boldsymbol{J}}}_c} $ 的更新公式:$$ \begin{gathered} {{\boldsymbol{J}}}_c^{t + 1} = \mathop {\arg \min }\limits_{{{{\boldsymbol{J}}}_c}} {\left\| {{{{\boldsymbol{J}}}_c}} \right\|_ * } + \left\langle {{{\boldsymbol{Y}}}_2^t,{{\boldsymbol{Z}}}_c^t - {{{\boldsymbol{J}}}_c}} \right\rangle + \frac{\mu }{2}\left\| {{{\boldsymbol{Z}}}_c^t - {{{\boldsymbol{J}}}_c}} \right\|_F^2 =\\ \mathop {\arg \min }\limits_{{{{\boldsymbol{J}}}_c}} \frac{1}{\mu }{\left\| {{{{\boldsymbol{J}}}_c}} \right\|_ * } + \frac{1}{2}\left\| {{{{\boldsymbol{J}}}_c} - ({{\boldsymbol{Z}}}_c^t + {{\boldsymbol{Y}}}_2^t/\mu )} \right\|_F^2 \end{gathered} $$ (16) 2)固定
$ {{{\boldsymbol{J}}}_c} $ 、$ {{{\boldsymbol{Z}}}_c} $ 、$ {{{\boldsymbol{Z}}}_v} $ 、$ {{\boldsymbol{L}}} $ 、$ {{\boldsymbol{K}}} $ 、$ {{\boldsymbol{E}}} $ 和$ {{\boldsymbol{P}}} $ ,将它们视为常数项,从而得到$ {{{\boldsymbol{J}}}_v} $ 的更新公式:$$ \begin{aligned} {\boldsymbol{J}}_{v}^{t+1} &=\underset{{\boldsymbol{J}}_{v}}{\operatorname{argmin}}\left\|{\boldsymbol{J}}_{v}\right\|_{m}+\left\langle {\boldsymbol{Y}}_{3}^{t}, {\boldsymbol{Z}}_{v}^{t}-{\boldsymbol{J}}_{v}\right\rangle+\frac{\mu}{2}\left|{\boldsymbol{Z}}_{v}^{t}-{\boldsymbol{J}}_{v}\right|_{p}^{2} =\\ &\underset{{\boldsymbol{J}}_{v}}{\arg \min } \frac{1}{\mu}\left\|{\boldsymbol{J}}_{v}\right\|_{m}+\frac{1}{2} \| {\boldsymbol{J}}_{v}-\left.\left({\boldsymbol{Z}}_{v}^{t}+{\boldsymbol{Y}}_{3}^{t} / \mu\right)\right|_{p} ^{2} \end{aligned} $$ (17) 3)固定
$ {{{\boldsymbol{J}}}_c} $ 、$ {{{\boldsymbol{J}}}_v} $ 、$ {{{\boldsymbol{Z}}}_v} $ 、$ {{\boldsymbol{L}}} $ 、$ {{\boldsymbol{K}}} $ 、$ {{\boldsymbol{E}}} $ 和$ {{\boldsymbol{P}}} $ ,将它们视为常数项,从而$\varGamma$ 对$ {{{\boldsymbol{Z}}}_c} $ 进行求导得:$$ \begin{gathered} 2\alpha {{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}{({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{XZ}}}_c^{t + 1}{{{\boldsymbol{L}}}_c} - {{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}[{{\boldsymbol{Y}}} - {({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^t) -\\ {{{\boldsymbol{L}}}^t}{{\boldsymbol{Y}}} - {{{\boldsymbol{E}}}^t}] + {{\boldsymbol{Z}}}_c^{t + 1} - {{\boldsymbol{J}}}_c^{t + 1} + \frac{ - {{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}{{\boldsymbol{Y}}}_1^t + {{\boldsymbol{Y}}}_2^t}{\mu} = 0 \\ \end{gathered} $$ 化简得:
$$ \begin{gathered} 2\alpha {{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}{({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{XZ}}}_c^{t + 1}{{{\boldsymbol{L}}}_c} + ({{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}{({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{X}}} + {{\boldsymbol{I}}}){{\boldsymbol{Z}}}_c^{t + 1} =\\ {{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}({{\boldsymbol{Y}}} - {({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{XZ}}}_v^t - {{{\boldsymbol{L}}}^t}{{\boldsymbol{Y}}} - {{{\boldsymbol{E}}}^t}) + {{\boldsymbol{J}}}_c^{t + 1} + \\ \frac{ {{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}{{\boldsymbol{Y}}}_1^t - {{\boldsymbol{Y}}}_2^t}{\mu} \\ \end{gathered} $$ (18) 4)固定
$ {{{\boldsymbol{J}}}_c} $ 、$ {{{\boldsymbol{J}}}_v} $ 、$ {{{\boldsymbol{Z}}}_c} $ 、$ {{\boldsymbol{L}}} $ 、$ {{\boldsymbol{K}}} $ 、$ {{\boldsymbol{E}}} $ 和$ {{\boldsymbol{P}}} $ ,将它们视为常数项,从而$\varGamma$ 对$ {{{\boldsymbol{Z}}}_v} $ 进行求导得:$$ \begin{gathered} 2\alpha {{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}{({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{XZ}}}_v^{t + 1}{{{\boldsymbol{L}}}_v} - {{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}({{\boldsymbol{Y}}} - {({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^{t + 1})- \\ {{{\boldsymbol{L}}}^t}{{\boldsymbol{Y}}} - {{{\boldsymbol{E}}}^t}) + {{\boldsymbol{Z}}}_v^{t + 1} - {{\boldsymbol{J}}}_v^{t + 1} + \frac{ - {{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}{{\boldsymbol{Y}}}_1^t + {{\boldsymbol{Y}}}_3^t}{\mu} = 0 \\ \end{gathered} $$ 化简得:
$$ \begin{gathered} 2\alpha {{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}{({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{XZ}}}_v^{t + 1}{{{\boldsymbol{L}}}_v} + ({{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}{({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{X}}} + {{\boldsymbol{I}}}){{\boldsymbol{Z}}}_v^{t + 1} = \\ {{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}({{\boldsymbol{Y}}} - {({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{XZ}}}_c^t - {{{\boldsymbol{L}}}^t}{{\boldsymbol{Y}}} - {{{\boldsymbol{E}}}^t}) + {{\boldsymbol{J}}}_v^{t + 1} +\\ \frac{{{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^t}{{\boldsymbol{Y}}}_1^t - {{\boldsymbol{Y}}}_3^t}{\mu} \\ \end{gathered} $$ (19) 5)固定
$ {{{\boldsymbol{J}}}_c} $ 、$ {{{\boldsymbol{J}}}_v} $ 、$ {{{\boldsymbol{Z}}}_c} $ 、$ {{{\boldsymbol{Z}}}_v} $ 、$ {{\boldsymbol{L}}} $ 、$ {{\boldsymbol{E}}} $ 和$ {{\boldsymbol{P}}} $ ,将它们视为常数项,从而得到$ {{\boldsymbol{K}}} $ 的更新公式为$$ \begin{gathered} {{\boldsymbol{K}}}_{}^{t + 1} = \mathop {\arg \min }\limits_{K} {\left\| {{\boldsymbol{K}}} \right\|_ * } + \left\langle {{{\boldsymbol{Y}}}_4^t,{{\boldsymbol{L}}}_{}^t - {{\boldsymbol{K}}}} \right\rangle +\\ \frac{\mu }{2}\left\| {{{\boldsymbol{L}}}_{}^t - {{\boldsymbol{K}}}} \right\|_F^2 = \\ \mathop {\arg \min }\limits_{K} \frac{1}{\mu }{\left\| {{\boldsymbol{K}}} \right\|_ * } + \frac{1}{2}\left\| {{{\boldsymbol{K}}} - \left({{\boldsymbol{L}}}_{}^t + \dfrac{{{\boldsymbol{Y}}}_4^t}{\mu} \right)} \right\|_F^2 \\ \end{gathered} $$ (20) 6)固定
$ {{{\boldsymbol{J}}}_c} $ 、$ {{{\boldsymbol{J}}}_v} $ 、$ {{{\boldsymbol{Z}}}_c} $ 、$ {{{\boldsymbol{Z}}}_v} $ 、$ {{\boldsymbol{K}}} $ 、$ {{\boldsymbol{E}}} $ 和$ {{\boldsymbol{P}}} $ ,将它们视为常数项,从而$\varGamma$ 对$ {{\boldsymbol{L}}} $ 进行求导得:$$ \begin{gathered} - ({{\boldsymbol{Y}}} - {({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^{t + 1}) - {{{\boldsymbol{L}}}^{t + 1}}{{\boldsymbol{Y}}} - {{{\boldsymbol{E}}}^t}){{{\boldsymbol{Y}}}^{\rm T}} + \\ {{{\boldsymbol{L}}}^{t + 1}} - {{{\boldsymbol{K}}}^{t + 1}} + \frac{ - {{\boldsymbol{Y}}}_1^t{{{\boldsymbol{Y}}}^{\rm T}} + {{\boldsymbol{Y}}}_4^t}{\mu} = 0 \\ \end{gathered} $$ 化简得:
$$ \begin{gathered} {{{\boldsymbol{L}}}^{t + 1}} = \left({{\boldsymbol{Y}}} - {({{{\boldsymbol{P}}}^t})^{\rm T}}{{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^{t + 1}) - {{{\boldsymbol{E}}}^t}\right){{{\boldsymbol{Y}}}^{\rm T}} + {{{\boldsymbol{K}}}^{t + 1}} + \\ \frac{{{\boldsymbol{Y}}}_1^t{{{\boldsymbol{Y}}}^{\rm T}} - {{\boldsymbol{Y}}}_4^t}{\mu} {({{\boldsymbol{Y}}}{{{\boldsymbol{Y}}}^{\rm T}} + {{\boldsymbol{I}}})^{ - 1}} \\ \end{gathered} $$ (21) 7)固定
$ {{{\boldsymbol{J}}}_c} $ 、$ {{{\boldsymbol{J}}}_v} $ 、$ {{{\boldsymbol{Z}}}_c} $ 、$ {{{\boldsymbol{Z}}}_v} $ 、$ {{\boldsymbol{L}}} $ 、$ {{\boldsymbol{K}}} $ 和$ {{\boldsymbol{P}}} $ ,将它们视为常数项,从而得到$ {{\boldsymbol{E}}} $ 的更新公式:$$ \begin{gathered} {{{\boldsymbol{E}}}^{t + 1}} = \mathop {\arg \min }\limits_{E} \lambda {\left\| {{\boldsymbol{E}}} \right\|_1}+ \\ \left\langle {{{\boldsymbol{Y}}}_1^t,{{\boldsymbol{Y}}} - {{({{{\boldsymbol{P}}}^t})}^{\rm T}}{{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^{t + 1}) - {{{\boldsymbol{L}}}^{t + 1}}{{\boldsymbol{Y}}} - {{{\boldsymbol{E}}}^t}} \right\rangle + \\ \frac{\mu }{2}\left\| {{{\boldsymbol{Y}}} - {{({{{\boldsymbol{P}}}^t})}^{\rm T}}{{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^{t + 1}) - {{{\boldsymbol{L}}}^{t + 1}}{{\boldsymbol{Y}}} - {{{\boldsymbol{E}}}^t}} \right\|_F^2 =\\ \mathop {\arg \min }\limits_{E} \frac{\lambda }{\mu }{\left\| {{\boldsymbol{E}}} \right\|_1} + \\ \frac{1}{2}\left\| {{{\boldsymbol{E}}} - \left({{\boldsymbol{Y}}} - {{({{{\boldsymbol{P}}}^t})}^{\rm T}}{{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^{t + 1}) - {{{\boldsymbol{L}}}^{t + 1}}{{\boldsymbol{Y}}} + \frac{{{\boldsymbol{Y}}}_1^t}{\mu }\right)} \right\|_F^2 \\ \end{gathered} $$ (22) 8)固定
$ {{{\boldsymbol{J}}}_c} $ 、$ {{{\boldsymbol{J}}}_v} $ 、$ {{{\boldsymbol{Z}}}_c} $ 、$ {{{\boldsymbol{Z}}}_v} $ 、$ {{\boldsymbol{L}}} $ 、$ {{\boldsymbol{K}}} $ 和$ {{\boldsymbol{E}}} $ ,将它们视为常数项,从而$\varGamma$ 对$ {{\boldsymbol{P}}} $ 进行求导得:$$ \begin{gathered} 2\alpha {{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1}{{{\boldsymbol{L}}}_c}{({{\boldsymbol{Z}}}_c^{t + 1})^{\rm T}} - {{\boldsymbol{Z}}}_v^{t + 1}{{{\boldsymbol{L}}}_v}{({{\boldsymbol{Z}}}_v^{t + 1})^{\rm T}}){{{\boldsymbol{X}}}^{\rm T}}{{{\boldsymbol{P}}}^{t + 1}}- \\ {{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^{t + 1})({({{\boldsymbol{Y}}} - {{{\boldsymbol{L}}}^{t + 1}}{{\boldsymbol{Y}}} - {{{\boldsymbol{E}}}^{t + 1}})^{\rm T}} - \\ {({{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^{t + 1}))^{\rm T}}{{{\boldsymbol{P}}}^{t + 1}}) + ( - {{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^{t + 1}){({{\boldsymbol{Y}}}_1^t)^{\rm T}})/\mu = 0 \\ \end{gathered} $$ 化简得:
$$ \begin{gathered} {{\boldsymbol{P}}}^{t+1}=\left(2 \alpha {{\boldsymbol{X}}}\left({{\boldsymbol{Z}}}_{t}^{{t}+1} {{\boldsymbol{L}}}_{t}\left({{\boldsymbol{Z}}}_{t}^{{t}+1}\right)^{\rm{T}}-{{\boldsymbol{Z}}}_{v}^{p+1} {{\boldsymbol{L}}}_{v}\left({{\boldsymbol{Z}}}_{v}^{p+1}\right)^{\rm{T}}\right) {{\boldsymbol{X}}}^{\rm{T}}+\right.\\ \left.{\boldsymbol{X}}\left({\boldsymbol{Z}}_{t}^{p+1}+{\boldsymbol{Z}}_{v}^{n+1}\right)\left({\boldsymbol{X}}\left({\boldsymbol{Z}}_{t}^{s+1}+{\boldsymbol{Z}}_{v}^{t+1}\right)\right)^{{\rm{T}}}\right)^{-1}*\\ \Bigg({{\boldsymbol{X}}}\left({{\boldsymbol{Z}}}_{t}^{n+1}+{{\boldsymbol{Z}}}_{v}^{n+1}\right)\left({{\boldsymbol{Y}}}-{{\boldsymbol{L}}}^{+1} {{\boldsymbol{Y}}}-{{\boldsymbol{E}}}^{n+1}\right)^{{\rm{T}}}+\\ \frac{{{\boldsymbol{X}}}\left({{\boldsymbol{Z}}}_{t}^{n+1}+{\boldsymbol{Z}}_{v}^{n+1}\right)\left({{\boldsymbol{Y}}}_{1}^{*}\right)^{\rm{T}}}{ \mu}\Bigg) \end{gathered} $$ (23) 式(16)、(17)、(20)可通过奇异值阈值(SVT)运算求解得,式(18)、(19)可通过Sylvester方程求解,式(22)可通过收缩算子进行求解,详细的算法流程在算法1中列出。参数
$ \mu $ 、$ \rho $ 、$ \varepsilon $ 、$ {\mu _{\max }} $ 和$ {t_{\max }} $ 参考了相关的多视图分析算法RMSL[17]。其他的参数$ \lambda $ 、$ \alpha $ 则在实验中调节,并在实验章节中给出分析。算法1:IMSL的算法描述
输入:
$ {{\boldsymbol{X}}} $ 、$ {{{\boldsymbol{L}}}_c} $ 、$ {{{\boldsymbol{L}}}_v} $ 、$ \lambda $ 、$ \alpha $ 。输出:
$ {{{\boldsymbol{Z}}}_c} $ 、$ {{{\boldsymbol{Z}}}_v} $ 、$ {{\boldsymbol{L}}} $ 、$ {{\boldsymbol{E}}} $ 、$ {{\boldsymbol{P}}} $ 。初始化:
$ {{\boldsymbol{Z}}}_c^0 = {J}_c^0 = {{\boldsymbol{Z}}}_v^0 = {{\boldsymbol{J}}}_v^0 = 0 $ ,$ {{{\boldsymbol{E}}}^0} = 0 $ ,$ {{\boldsymbol{Y}}}_1^0 = 0 $ ,${{\boldsymbol{Y}}}_2^0 = 0$ ,$ {{\boldsymbol{Y}}}_3^0 = 0 $ ,$ {{\boldsymbol{Y}}}_4^0 = 0 $ ,$ \mu = {10^{ - 6}} $ ,$ {\mu _{\max }} = {10^6} $ ,$ {t_{\max }} = 50 $ ,$ \varepsilon = {10^{ - 6}} $ ,$ t = 0 $ 。1)循环开始;
2)固定其他变量,根据式(16)更新
${{\boldsymbol{J}}}_c^{t + 1}$ ;3)固定其他变量,根据式(17)更新
${{\boldsymbol{J}}}_v^{t + 1}$ ;4)固定其他变量,根据式(18)更新
${{\boldsymbol{Z}}}_c^{t + 1}$ ;5)固定其他变量,根据式(19)更新
${{\boldsymbol{Z}}}_v^{t + 1}$ ;6)固定其他变量,根据式(20)更新
${{\boldsymbol{K}}}_{}^{t + 1}$ ;7)固定其他变量,根据式(21)更新
${{{\boldsymbol{L}}}^{t + 1}}$ ;8)固定其他变量,根据式(22)更新
${{{\boldsymbol{E}}}^{t + 1}}$ ;9)固定其他变量,根据式(23)更新
${{{\boldsymbol{P}}}^{t + 1}}$ 并对其正交化;10) 更新拉格朗日算子:
$$\begin{gathered} {{\boldsymbol{Y}}}_1^{t + 1} = {{\boldsymbol{Y}}}_1^t + \mu ({{\boldsymbol{Y}}} - {({{{\boldsymbol{P}}}^{t + 1}})^{\rm T}}{{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^{t + 1}) - {{{\boldsymbol{L}}}^{t + 1}}{{\boldsymbol{Y}}} - {{{\boldsymbol{E}}}^{t + 1}}) \\ {{\boldsymbol{Y}}}_2^{t + 1} = {{\boldsymbol{Y}}}_2^t + \mu ({{\boldsymbol{Z}}}_c^{t + 1} - {{\boldsymbol{J}}}_c^{t + 1}) \\ {{\boldsymbol{Y}}}_3^{t + 1} = {{\boldsymbol{Y}}}_3^t + \mu ({{\boldsymbol{Z}}}_v^{t + 1} - {{\boldsymbol{J}}}_v^{t + 1}) \\ {{\boldsymbol{Y}}}_4^{t + 1} = {{\boldsymbol{Y}}}_4^t + \mu ({{\boldsymbol{L}}}_{}^{t + 1} - {{\boldsymbol{K}}}_{}^{t + 1}) \end{gathered}$$ 11)更新惩罚参数
$ \mu $ ,$ \mu = \min (\rho \mu ,{\mu _{\max }}) $ ;12)检查收敛条件,即
$$ \begin{gathered} {\left\| {{{\boldsymbol{Y}}} - {{({{{\boldsymbol{P}}}^{t + 1}})}^{\rm T}}{{\boldsymbol{X}}}({{\boldsymbol{Z}}}_c^{t + 1} + {{\boldsymbol{Z}}}_v^{t + 1}) - {{{\boldsymbol{L}}}^{t + 1}}{{\boldsymbol{Y}}} - {{{\boldsymbol{E}}}^{t + 1}}} \right\|_\infty } < \varepsilon \\ {\left\| {{{\boldsymbol{Z}}}_c^{t + 1} - {{\boldsymbol{J}}}_c^{t + 1}} \right\|_\infty } < \varepsilon \\ {\left\| {{{\boldsymbol{Z}}}_v^{t + 1} - {{\boldsymbol{J}}}_v^{t + 1}} \right\|_\infty } < \varepsilon \\ {\left\| {{{\boldsymbol{L}}}_{}^{t + 1} - {{\boldsymbol{K}}}_{}^{t + 1}} \right\|_\infty } < \varepsilon \end{gathered}$$ 或
$ t $ 达到$ {t_{\max }} $ ,其中$ {\left\| \cdot \right\|_\infty } $ 表示矩阵的无穷范数;13)更新迭代次数
$ t $ ,$ t = t + 1 $ ;14)结束循环。
上述算法中,2)、3)、6)的核范数计算与4)、5)、7)、9)的矩阵乘法和逆运算为主要耗时部分。2)、3)的SVD计算的时间复杂度为
$ O({n^3}) $ ,6)的SVD计算的时间复杂度为$ O({p^3}) $ ,$ n $ 为多视图的样本大小,$ p $ 为降维的维数。如果在实验中选择较小的降维维数,可以加速6)中的计算。4) 采用Sylvester方程求解,因此主要耗时部分为矩阵乘法、逆运算和Sylvester方程求解,可推导出其时间复杂度为$ O(d{n^2} + {n^3}) $ ,$ d $ 为原始特征维数。5)与4)求解过程相同,时间复杂度为$ O(d{n^2} + {n^3}) $ 。类比可以推导出7)与9)的时间复杂度分别为$O(p{n^2} + pdn) pdn)$ 、$ O(d{n^2} + n{d^2} + {d^3}) $ 。8)采用收缩算子进行求解,其时间复杂度为$ O(pn) $ 。通常在实验中设置$ p \ll n $ 且$ p \ll d $ ,因此综上所述,算法1的时间复杂度为$O(T(d{n^2} + {n^3} + {d^3} + n{d^2}))$ ,$ T $ 为所提算法的迭代次数。2. 实验
2.1 数据集
本文分别在3组多视图数据集上验证了所提算法的实验效果,它们分别是人脸数据集CMU-PIE、物体数据集ALOI-100和COIL-100。
CMU-PIE是一个多视图人脸数据集,总共有68类样本,采取同一对象的但具有不同姿势的样本之间有着较大的差异,每个对象的每个姿势都有着21种不同的照明变化,这里采用C05、C07、C09、C27和C29来构建训练集与测试集,且它们中的图像都被裁剪为32×32的尺寸。
ALOI-100和COIL-100都为多视图物体数据集,都包含100个类别物体和7200张图像。ALOI-100和COIL-100都是利用旋转角度进行采样的,因此每个类中的图像都相隔85°,共有72张图像。本文设定4种视图:v1 [0°, 85°]、v2[90°, 175°]、v3[180°, 265°]和v4[270°, 355°](v表示view),且它们中的图像被裁剪为64×64的尺寸。
2.2 实验设置
在实验部分,对于CMU-PIE多视图人脸数据集,我们选取不同数量、不同姿势的视图作为数据集,从视图的每个类别中随机选择10张图像构建训练集,剩下的图像作为测试集。而为构造不完整多视图实验场景,随机从训练集的每个视图中挑选10个类别移除。而对于ALOI-100和COIL-100这两个多视图物体数据集,依次选择两个视图作为训练集,剩下的两个视图作为测试集,构建不完整多视图训练集。此外,我们使用最近邻分类器(KNN)来评估最终性能。
本文主要采用特征提取算法与多视图数据分析算法进行比较:LDA[24]、LPP[23]、LatLRR[16]、LRCS[25]、RMSL[17]和CLRS[26](CLRS1表示施加低秩约束,CLRS2表示未施加低秩约束)。其中,CLRS、LDA、RMSL属于有监督的方法,LPP、LatLRR为无监督的方法,LRCS为弱监督方法。对于这些对比算法,同样采用最近邻分类器(KNN)来评估最终性能。
2.3 结果分析
在CMU-PIE多视图人脸数据集上的实验结果如表1与表2所示,Task 1~Task 9分别表示为{C05, C07}、{C07, C09}、{C27, C29}、{C05, C09, C27}、{C09, C27, C29}、{C05, C07, C09}、{C05, C09, C27, C29}、{C05, C07, C09, C27}、{C05, C07, C09, C27, C29}。由表1与表2可知,所提算法在CMU-PIE人脸数据集的大部分测试任务中都排名第一。对于LPP与LDA,LPP通过热核函数来区分不同类别,LDA通过监督信息将同类特征与异类特征加以区分,但是在不同视图之间同类特征之间存在较大差异时会导致传统的监督学习算法性能低于无监督学习算法。由表中不难看出,基于低秩约束的方法是优于传统的特征提取算法的,尤其对于有损坏的CMU-PIE数据集,这验证了低秩约束对带有稀疏误差项的噪声有很好的抑制效果。但是相较于算法RMSL、LRCS、CLRS与IMSL,算法LatLRR只是简单地施加低秩约束,并未考虑到在多视图场景中不同类别的特征相似性较大的可能,这导致了LatLRR在多视图测试案例中性能较差。算法LRCS则针对多视图场景提出学习不同视图相对应的子空间并将它们对齐,这尽可能地保留了不同视图各自的特征,但是当同类特征差异大于异类特征时则会导致该算法效果较差。算法RMSL针对同类特征差异较大的问题提出了双重低秩分解来减小不同视图对同类别数据进行低秩分解时造成的影响,然而它对不完整多视图场景并没有一个很好的解决效果。算法CLRS则旨在学习由各个视图特定的投影所共享的无视图低秩投影来减小视图之间的语义差距,并施加有监督的正则化项来耦合不同视图的类内数据。但是当视图数据不完整时,各个视图特定的投影所共享的特征可能趋向于非常少,这就导致最终获得的共享低秩投影性能下降。最后,算法IMSL针对不完整多视图场景提出了引入潜在因子的双重低秩分解子空间的学习方法,潜在因子帮助挖掘丢失的视图信息,此外,预先学习的低维不完整多视图特征与监督信息对齐也进一步促进了不同视图之间的特征对齐。因此IMSL的性能是优于以上算法的。
表 1 在原始的CMU-PIE人脸数据集上各算法的分类精度Table 1 Accuracy of algorithms on original CMU-PIE face datasets% 任务 LPP LDA LatLRR LRCS RMSL CLRS1 CLRS2 IMSL Task 1 34.120.39 51.980.20 24.380.42 77.750.41 74.150.03 60.700.45 61.720.19 79.550.04 Task 2 41.110.79 65.250.56 23.420.50 71.510.48 74.780.65 67.380.22 70.320.63 78.640.23 Task 3 35.800.48 62.000.41 23.830.11 63.780.96 72.060.13 63.030.53 60.360.88 76.640.62 Task 4 57.540.04 67.870.12 30.890.40 67.330.33 76.690.47 57.890.11 54.410.82 79.290.47 Task 5 59.840.28 72.500.91 30.950.53 69.200.64 77.450.35 57.580.10 57.580.15 78.920.37 Task 6 59.350.83 73.150.50 32.300.02 76.990.27 75.450.26 52.490.86 59.470.49 77.830.02 Task 7 59.940.31 75.020.48 43.410.56 67.230.25 76.140.37 61.340.48 74.700.84 78.720.22 Task 8 63.720.70 75.740.65 43.520.46 79.030.31 75.600.74 65.170.17 63.560.67 81.250.38 Task 9 64.340.63 75.550.26 49.740.29 79.060.18 76.280.17 67.010.18 66.550.73 80.510.50 表 2 在损坏的CMU-PIE人脸数据集上各算法的分类精度Table 2 Accuracy of algorithms on corrupted CMU-PIE face datasets% 任务 LPP LDA LatLRR LRCS RMSL CLRS1 CLRS2 IMSL Task 1 9.270.35 19.600.25 9.460.48 16.480.40 16.250.46 29.510.72 28.360.11 29.480.37 Task 2 9.910.57 26.400.23 9.090.81 17.870.13 18.180.80 28.140.34 32.020.61 29.820.90 Task 3 10.320.92 30.130.47 8.380.49 17.600.10 15.110.17 31.220.13 30.150.37 28.300.03 Task 4 18.970.62 16.800.62 16.080.39 15.680.46 18.230.52 23.150.81 22.860.97 33.460.81 Task 5 18.430.41 12.980.95 16.030.66 15.980.81 16.980.49 25.130.52 22.990.32 33.210.20 Task 6 17.540.86 12.420.09 17.370.75 15.510.31 17.650.26 25.490.75 23.530.62 34.550.40 Task 7 19.350.04 12.700.93 20.970.80 15.850.18 15.840.73 27.980.33 27.570.56 37.430.49 Task 8 18.480.61 10.310.45 24.900.38 15.800.93 16.810.14 26.140.76 27.840.61 36.930.89 Task 9 17.180.56 10.580.50 24.750.13 16.730.64 16.740.34 32.370.17 31.070.81 40.100.63 在COIL-100多视图物体数据集上的实验结果如图2所示,显然所提算法的平均性能在大部分测试任务中要好于所有对比算法,且受不同的视图组合影响较小。在ALOI-100多视图物体数据集上的实验结果如图3所示。对于不同的视图组合,所有算法的平均性能相差不大,这表明了两个视图之间的发散度在一定程度上是等效的。LRCS与RMSL的性能较接近于所提算法,甚至LRCS在一些测试任务中表现出更优性能,这是由于该视图组合可能同类别特征差异性较小,导致双重低秩分解的效果相较于常规的低秩分解可能较差,但是在不完整的多视图场景下,施加了潜在因子的双重低秩分解子空间学习框架仍然保证了所提算法胜任绝大多数的测试任务。
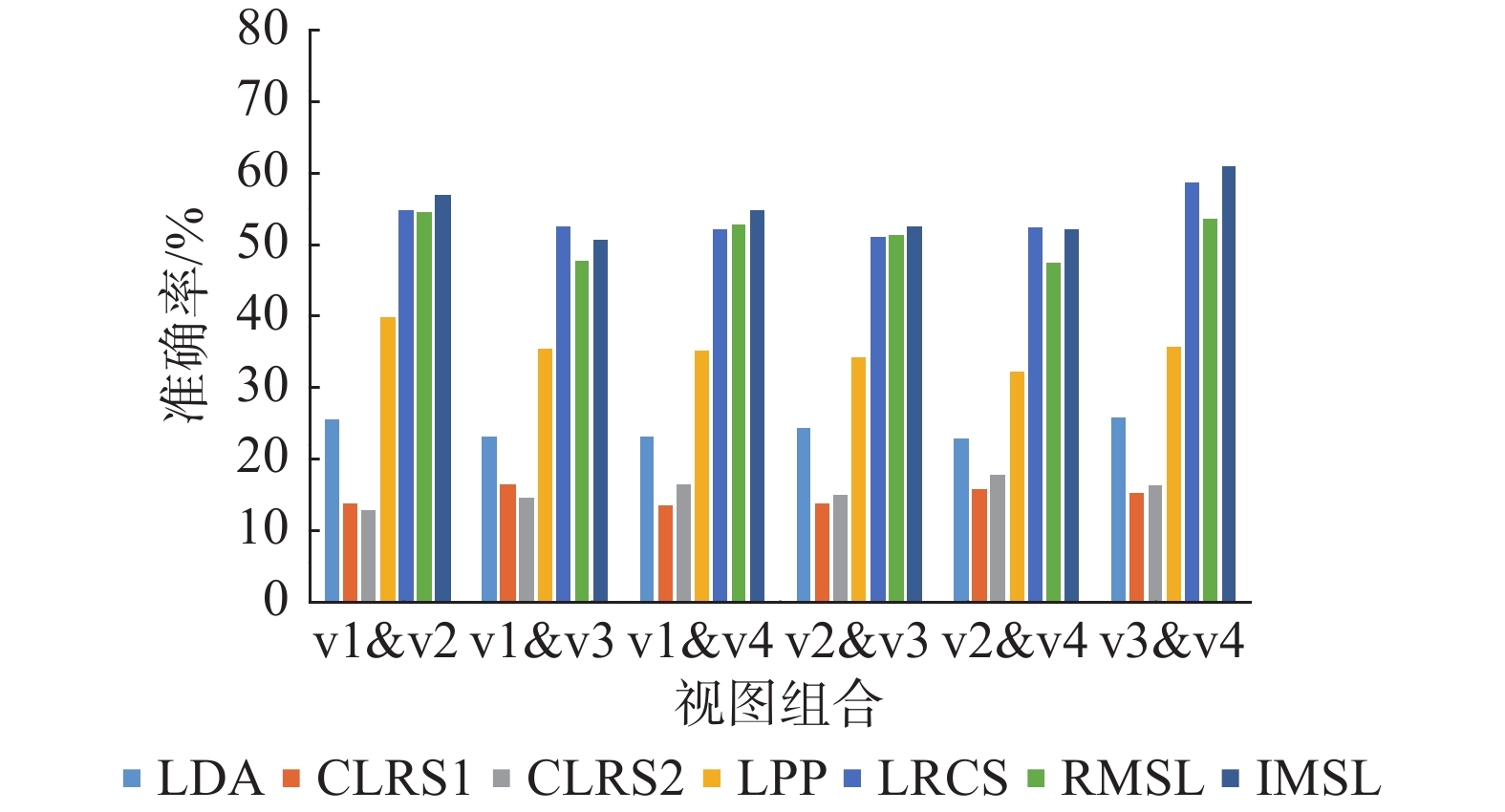 图 2 在COIL-100数据集上各算法的分类准确率Fig. 2 Accuracy of algorithms on COIL-100 datasets下载:
全尺寸图片
图 2 在COIL-100数据集上各算法的分类准确率Fig. 2 Accuracy of algorithms on COIL-100 datasets下载:
全尺寸图片
 图 3 在ALOI-100数据集上各算法的分类准确率Fig. 3 Accuracy of algorithms on ALOI-100 datasets下载:
全尺寸图片
图 3 在ALOI-100数据集上各算法的分类准确率Fig. 3 Accuracy of algorithms on ALOI-100 datasets下载:
全尺寸图片
2.4 模型分析
本节将分析所提算法的收敛性,并评估不同子空间维度下所提算法的准确变化,此外还验证监督信息、对齐项等正则化参数的有效性。在本节中,主要评估以下参数:子空间维度参数
$ p $ 、稀疏项参数$ \lambda $ 、监督信息对齐项参数$ \alpha $ 。这里以CMU-PIE数据集作为测试案例,通过固定其他参数来逐一测试它们对于算法的意义。图4(a)展示了以{C05 C07}作为测试案例,所提算法的准确率随迭代次数逐渐增大的变化趋势。显而易见,所提算法收敛速度较快,识别精度迅速上升并在5次迭代后保持一个较稳定的值。
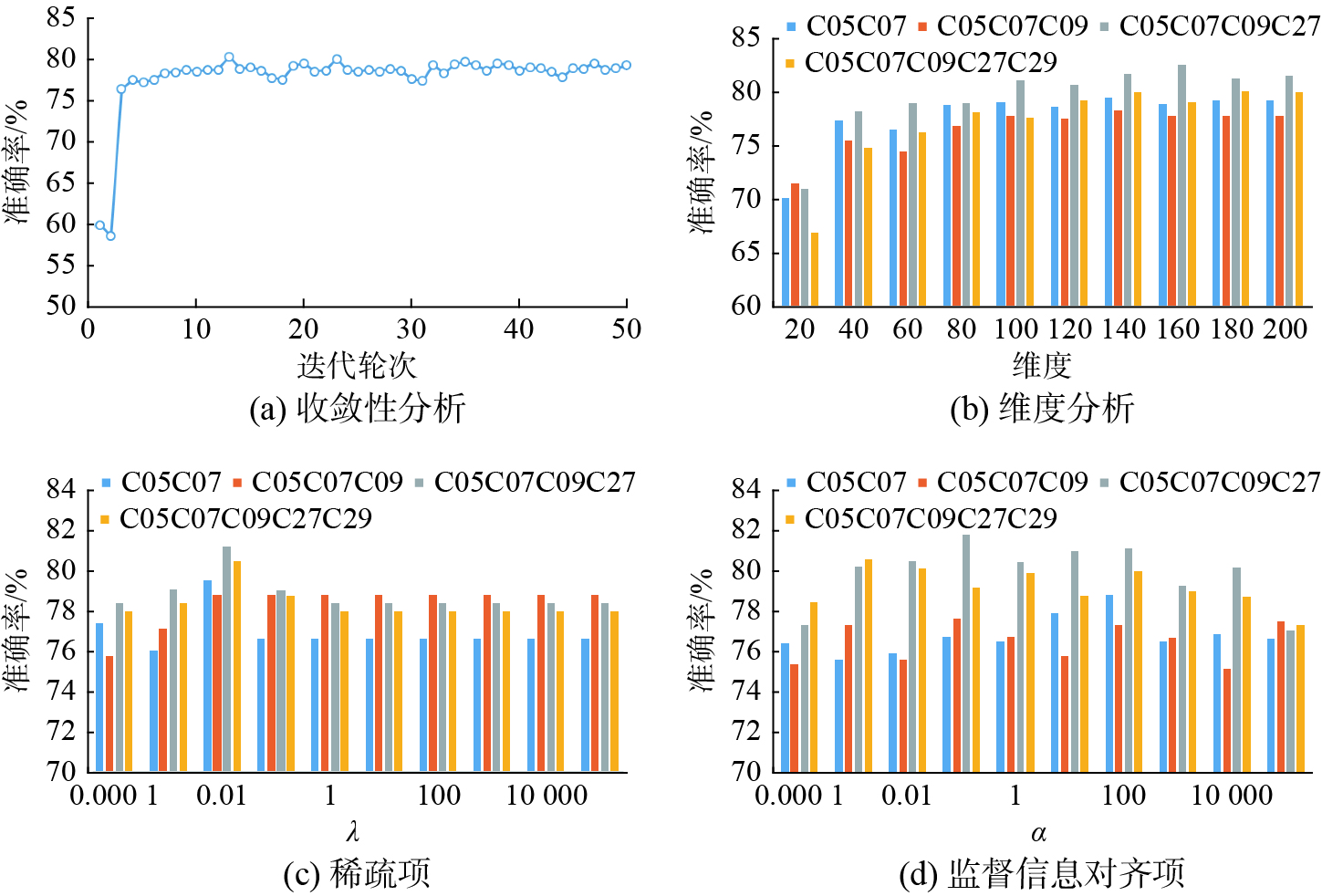 图 4 参数分析Fig. 4 Parameter analysis下载:
全尺寸图片
图 4 参数分析Fig. 4 Parameter analysis下载:
全尺寸图片
图4(b)展示以{C05C07,C05C07C09,C05C07C09C27,C05C07C09C27C29}作为测试案例,所提算法在不同子空间维度下的准确率变化。从图中不难看出,随着维度的增加,算法的精度先是逐步上升,在达到一定维度后转为平稳趋势。
图4(c)与图4(d)展示了以{C05C07,C05C07C09,C05C07C09C27,C05C07C09C27C29}为测试案例,正则化参数对所提算法准确率的影响。由图可知,当监督信息对齐项参数
$ \alpha $ 趋向于0时算法性能较差,这验证了监督信息对齐项的有效性。稀疏项参数$ \lambda $ 在较小值时取得的效果较好,且随着参数值的增大算法精度趋向于稳定或一定的下降。3. 结束语
为了解决不完整多视图问题,本文提出了一种基于双重低秩分解的不完整多视图子空间学习算法。所提算法基于双重低秩分解子空间学习框架,引入潜在因子挖掘丢失的视图信息,并通过预先学习多视图的低维特征来进行特征对齐。此外,通过监督信息来进一步地促进双重低秩分解,避免了视图结构差异对全局类结构造成的影响。在3个数据集上的实验效果证明了所提算法的优越性。
-
图 1 本文的算法框架
Fig. 1 Algorithm framework of this paper
下载:
全尺寸图片
图 2 在COIL-100数据集上各算法的分类准确率
Fig. 2 Accuracy of algorithms on COIL-100 datasets
下载:
全尺寸图片
图 3 在ALOI-100数据集上各算法的分类准确率
Fig. 3 Accuracy of algorithms on ALOI-100 datasets
下载:
全尺寸图片
图 4 参数分析
Fig. 4 Parameter analysis
下载:
全尺寸图片
表 1 在原始的CMU-PIE人脸数据集上各算法的分类精度
Table 1 Accuracy of algorithms on original CMU-PIE face datasets
% 任务 LPP LDA LatLRR LRCS RMSL CLRS1 CLRS2 IMSL Task 1 34.120.39 51.980.20 24.380.42 77.750.41 74.150.03 60.700.45 61.720.19 79.550.04 Task 2 41.110.79 65.250.56 23.420.50 71.510.48 74.780.65 67.380.22 70.320.63 78.640.23 Task 3 35.800.48 62.000.41 23.830.11 63.780.96 72.060.13 63.030.53 60.360.88 76.640.62 Task 4 57.540.04 67.870.12 30.890.40 67.330.33 76.690.47 57.890.11 54.410.82 79.290.47 Task 5 59.840.28 72.500.91 30.950.53 69.200.64 77.450.35 57.580.10 57.580.15 78.920.37 Task 6 59.350.83 73.150.50 32.300.02 76.990.27 75.450.26 52.490.86 59.470.49 77.830.02 Task 7 59.940.31 75.020.48 43.410.56 67.230.25 76.140.37 61.340.48 74.700.84 78.720.22 Task 8 63.720.70 75.740.65 43.520.46 79.030.31 75.600.74 65.170.17 63.560.67 81.250.38 Task 9 64.340.63 75.550.26 49.740.29 79.060.18 76.280.17 67.010.18 66.550.73 80.510.50 表 2 在损坏的CMU-PIE人脸数据集上各算法的分类精度
Table 2 Accuracy of algorithms on corrupted CMU-PIE face datasets
% 任务 LPP LDA LatLRR LRCS RMSL CLRS1 CLRS2 IMSL Task 1 9.270.35 19.600.25 9.460.48 16.480.40 16.250.46 29.510.72 28.360.11 29.480.37 Task 2 9.910.57 26.400.23 9.090.81 17.870.13 18.180.80 28.140.34 32.020.61 29.820.90 Task 3 10.320.92 30.130.47 8.380.49 17.600.10 15.110.17 31.220.13 30.150.37 28.300.03 Task 4 18.970.62 16.800.62 16.080.39 15.680.46 18.230.52 23.150.81 22.860.97 33.460.81 Task 5 18.430.41 12.980.95 16.030.66 15.980.81 16.980.49 25.130.52 22.990.32 33.210.20 Task 6 17.540.86 12.420.09 17.370.75 15.510.31 17.650.26 25.490.75 23.530.62 34.550.40 Task 7 19.350.04 12.700.93 20.970.80 15.850.18 15.840.73 27.980.33 27.570.56 37.430.49 Task 8 18.480.61 10.310.45 24.900.38 15.800.93 16.810.14 26.140.76 27.840.61 36.930.89 Task 9 17.180.56 10.580.50 24.750.13 16.730.64 16.740.34 32.370.17 31.070.81 40.100.63 -
[1] XU Chang, TAO Dacheng, XU Chao. A survey on multi-view learning[EB/OL]. (2013−04−20)[2021−07−01]. https://arxiv.org/abs/1304.5634. [2] 吴钟强, 张耀文, 商琳. 基于语义特征的多视图情感分类方法[J]. 智能系统学报, 2017, 12(5): 745–751. doi: 10.11992/tis.201706026 WU Zhongqiang, ZHANG Yaowen, SHANG Lin. Multi-view sentiment classification of microblogs based on semantic features[J]. CAAI transactions on intelligent systems, 2017, 12(5): 745–751. doi: 10.11992/tis.201706026 [3] ZHANG Changqing, HU Qinghua, FU Huazhu, et al. Latent multi-view subspace clustering[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017 : 4333−4341. [4] BRBIĆ M, KOPRIVA I. Multi-view low-rank sparse subspace clustering[J]. Pattern recognition, 2018, 73: 247–258. doi: 10.1016/j.patcog.2017.08.024 [5] WU Xinxiao, JIA Yunde. View-invariant action recognition using latent kernelized structural SVM[M]//Computer Vision-ECCV 2012. Berlin: Springer Berlin Heidelberg, 2012: 411−424. [6] ZHU Pengfei, HUI Binyuan, ZHANG Changqing, et al. Multi-view deep subspace clustering networks[EB/OL]. (2019−08−06) [2021−07−01]. https://arxiv.org/abs/1908.01978. [7] XIE Yuan, LIN Bingqian, QU Yanyun, et al. Joint deep multi-view learning for image clustering[J]. IEEE transactions on knowledge and data engineering, 2021, 33(11): 3594–3606. doi: 10.1109/TKDE.2020.2973981 [8] DING Zhengming, SUH S, HAN J J, et al. Discriminative low-rank metric learning for face recognition[C]//2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG). Ljubljana: IEEE, 2015, 1: 1−6. [9] SHAO Ming, KIT D, FU Yun. Generalized transfer subspace learning through low-rank constraint[J]. International journal of computer vision, 2014, 109(1/2): 74–93. [10] LIU Guangcan, LIN Zhouchen, YAN Shuicheng, et al. Robust recovery of subspace structures by low-rank representation[J]. IEEE transactions on pattern analysis and machine intelligence, 2013, 35(1): 171–184. doi: 10.1109/TPAMI.2012.88 [11] ZHANG Fanlong, YANG Jian, TAI Ying, et al. Double nuclear norm-based matrix decomposition for occluded image recovery and background modeling[J]. IEEE transactions on image processing, 2015, 24(6): 1956–1966. doi: 10.1109/TIP.2015.2400213 [12] YU C N J, JOACHIMS T. Learning structural SVMs with latent variables[C]//ICML’09: Proceedings of the 26th Annual International Conference on Machine Learning. New York: ACM, 2009: 1169−1176. [13] LI Jia, NAJMI A, GRAY R M. Image classification by a two-dimensional hidden Markov model[J]. IEEE transactions on signal processing, 2000, 48(2): 517–533. doi: 10.1109/78.823977 [14] DING Zhengming, SHAO Ming, FU Yun. Missing modality transfer learning via latent low-rank constraint[J]. IEEE transactions on image processing, 2015, 24(11): 4322–4334. doi: 10.1109/TIP.2015.2462023 [15] DING Zhengming, ZHAO Handong, FU Yun. Missing modality transfer learning[M]//Learning Representation for Multi-View Data Analysis. Cham: Springer International Publishing, 2018: 147−173. [16] LIU Guangcan, YAN Shuicheng. Latent Low-Rank Representation for subspace segmentation and feature extraction[C]//2011 International Conference on Computer Vision. Barcelona: IEEE, 2011: 1615−1622. [17] DING Zhengming, FU Yun. Robust Multi-view Subspace Learning through dual low-rank decompositions[C]//AAAI'16: Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. New York: ACM, 2016: 1181−1187. [18] DING Zhengming, SHAO Ming, FU Yun. Incomplete multisource transfer learning[J]. IEEE transactions on neural networks and learning systems, 2018, 29(2): 310–323. doi: 10.1109/TNNLS.2016.2618765 [19] 程旸, 王士同. 基于局部保留投影的多可选聚类发掘算法[J]. 智能系统学报, 2016, 11(5): 600–607. doi: 10.11992/tis.201508022 CHENG Yang, WANG Shitong. A multiple alternative clusterings mining algorithm using locality preserving projections[J]. CAAI transactions on intelligent systems, 2016, 11(5): 600–607. doi: 10.11992/tis.201508022 [20] LIU Guangcan, ZHOU chenlin, YONG Yu. Robust subspace segmentation by low-rank representation[C]// International Conference on Machine Learning. Haifa: DBLP, 2010: 663−670. [21] RAZZAGHI P, RAZZAGHI P, ABBASI K. Transfer subspace learning via low-rank and discriminative reconstruction matrix[J]. Knowledge-based systems, 2019, 163: 174–185. doi: 10.1016/j.knosys.2018.08.026 [22] SU Ya, LI Sheng, WANG Shengjin, et al. Submanifold decomposition[J]. IEEE transactions on circuits and systems for video technology, 2014, 24(11): 1885–1897. doi: 10.1109/TCSVT.2014.2329375 [23] HE Xiaofei, NIYOGI P. Locality preserving projections[J]. Advances in neural information processing systems, 2003, 16(1): 186–197. [24] BELHUMEUR P N, HESPANHA J P, KRIEGMAN D J. Eigenfaces vs. Fisherfaces: recognition using class specific linear projection[J]. IEEE transactions on pattern analysis and machine intelligence, 1997, 19(7): 711–720. doi: 10.1109/34.598228 [25] DING Zhengming, FU Yun. Low-rank common subspace for multi-view learning[C]//2014 IEEE International Conference on Data Mining. Shenzhen: IEEE, 2014 : 110−119. [26] DING Zhengming, FU Yun. Robust multiview data analysis through collective low-rank subspace[J]. IEEE transactions on neural networks and learning systems, 2018, 29(5): 1986–1997. doi: 10.1109/TNNLS.2017.2690970























































































































































































































































































