
Efficient acoustic source localization algorithm based on an inverse model
-
摘要: 与波束形成算法相比,广义互相关逆模型宽带声源定位算法提供了空间的高分辨率,但需要更高的计算量。为了提升广义互相关逆模型算法的计算效率,并尽可能保留其分辨率优势,本文提出了一种高效的声源定位算法。该算法首先去除麦克风阵列输出功率较小的网格点来压缩计算网格,其次,在几何因素条件下利用基于密度的聚类进一步压缩网格,最后仅用保留下的点进行计算,从而大大降低了计算规模。真实数据实验证明,本文所提算法能有效提升广义互相关逆模型算法的计算效率。Abstract: Compared with the beamforming algorithm, the wideband acoustic source localization based on the generalized crosscorrelation inverse model provides a higher spatial resolution and requires more computation. This paper proposes an acceleration algorithm to improve the computational efficiency of acoustic source localization and retain the existing resolution. By removing the grid points with the low output power of the microphone array, the computational grid is compressed. The geometric factor is also considered, and the density-based clustering algorithm is used to further compress the grid. Finally, only the reserved points are used for the calculation to reduce the calculation scale. Experiments with real data show that the proposed algorithm can improve computational efficiency significantly.
-
麦克风阵列是以特定方式排列,能够准确获取空间信息的一组声音采集系统。麦克风阵列声源定位(acoustic source localization,ASL)就是在阵列几何形状已知条件下,利用麦克风阵列输出信号中包含的空域–时域–频域信息,对声源进行正确的定位。近十几年来,基于麦克风阵列的ASL技术得到了迅速发展,并广泛应用于视频会议系统[1]、机器人听觉、语音增强[2]、语音识别[3]等领域。
与ASL算法相关联的麦克风阵列,目的是补偿麦克风与虚拟扫描点之间的时间或相位延迟,可以在时域或频域进行。频域技术使用麦克风信号的交叉频谱矩阵(cross spectral matrix, CSM),最常见的技术是波束形成。传统波束形成(conventional beamforming, CBF)具有鲁棒性且较为简单,然而由于旁瓣效应[4]的存在,使得其在低频率下的空间分辨率很差。为了提高空间分辨率,其他波束形成算法也被开发出来。Li等[5]使用矩阵方法保持恒定的波束宽度和低峰值旁瓣电平,同时保持自适应零强干扰能力。Yan等[6]提出了最小方差无失真响应(minimum variance distortionless response, MVDR)在球谐波域的波束形成,在低峰值旁瓣和窄主瓣宽度之间提供了一个合适的折衷。Kumar等[7]利用球谐域波束形成解决了球形麦克风阵列的近场声源定位问题。Salvati等[8]提出了一种基于对角卸载(diagonal unloading, DU)变换的波束形成方法,实现了低计算复杂度的鲁棒定位。Simard等[9]研究了传声器阵列中的源识别问题,证明了压缩感知波束形成方法也适用于近场聚焦球波模型,提高了源定位分辨率。Long等[10]从几何投影的角度阐述了声源定位问题,实现了在较短声信号帧内的声源定位,证明了其算法与传统算法之间的等价性。然而,这些算法对阵列误差敏感,且在低信噪比下受限。因此,研究一种鲁棒的高分辨率波束形成算法是非常必要的。
近年来,航空声学中许多反卷积方法被用于提高声源定位分辨率[11]。这是因为CBF输出可以表示为声源分布与波束形成器对点源的响应的卷积。通过对CBF波束形成器的波束图进行反卷积,可以得到清晰波束图下的实际声源分布,从而提高分辨率。Dougherty等[12]首次将CLEAN算法应用于声波阵列测量中。Brooks等[13]提出反卷积声源成像(deconvolution approach for the mapping of acoustic sources, DAMAS)算法用于声源定位。Sun等[14]提出了一种Ex-RL(extended richardson lucy)算法,提升了在二维移变反卷积声学图像测量问题中的分辨率。Bai等[15]提出了非凸L1/2正则化方法,提高了反卷积问题的空间分辨率和鲁棒性。DAMAS使研究者充分认识到反卷积的优点和可行性,但不幸的是,DAMAS需要较高的计算量,消耗较长运行时间和较大计算机内存。Ma等[16]提出了一种基于波束形成算法的压缩计算网格DAMAS算法,通过去除非正波束形成点,减小了计算规模,提高了计算效率。
在时域中最常用的方法是基于传声器对之间时延的广义互相关方法[17]。这个时间延迟可以用来为扫描区域上可能的源位置生成一个双曲线。所有双曲线(所有麦克风对)的交集确定出声源位置。Noël等[18]使用了与反问题相关的广义互相关(generalized cross correlation, GCC)来定位声源位置。反问题求解使理论互相关函数和测量互相关函数之间的差异最小化。他们最终得到了一个声源图,其中包含了从各个方向接收到的与麦克风阵列相关的角能量流。具有良好的应用前景。Padois等[19]提出了一种快速的声源定位技术,能够检测主要声源和反射信号,他们提出了一个基于GCC的最小化问题,但与Noël等[18]的理论公式和求解方法不同,利用了两种不同的稀疏表示来解决该最小化问题。Chu等[20]提出了一种基于聚焦点与麦克风对之间时延估计差异的累积概率的方法,解决了传播模型矩阵最优阈值随聚焦点距离、阵列几何形状和阵列大小而变化的问题。
然而,传播模型矩阵计算以及求解反卷积所带来的高计算量问题始终没有解决。Ma等[16]提出的压缩计算网格DAMAS算法为我们提供了优化思路,本文对Ma Wei等的压缩网格算法进行了改进,提出了一种基于密度聚类的压缩网格算法,利用几何信息对网格点进行聚类,去除噪声点,将该算法运用到Padois等[19]提出的声源定位技术中,最终取得了比原算法更高的计算效率。
1. 声源定位技术
1.1 麦克风阵列信号
考虑如下声场,点声源位于坐标
${{\boldsymbol{r}}_s}$ 处,其产生的信号$s\left( {{{\boldsymbol{r}}_s},t} \right)$ 被设置在${{\boldsymbol{r}}_m}$ $\left( {m = 1,{\text{2}},\cdots,M} \right)$ 处的M个麦克风所记录。设在自由场条件下被第m个麦克风记录的声压信号$ {p_m} $ 为$$ {p_m}\left( t \right) = {\alpha _m}\left( {{{\boldsymbol{r}}_s}} \right)s\left( {{{\boldsymbol{r}}_s},t - \Delta {t_{ms}}} \right) + {n_m}\left( t \right) $$ 式中:
${\alpha _m}\left( {{{\boldsymbol{r}}_s}} \right)$ 是传播过程中的衰减系数,$ {n_m}\left( t \right) $ 是由背景或传感器噪声产生的不相关噪声。声源s和麦克风m之间的传播时间$ \Delta {t_{ms}} $ 为$$ \Delta {t_{ms}} = \frac{1}{c}{\left\| {{{\boldsymbol{r}}_m} - {{\boldsymbol{r}}_s}} \right\|_2} $$ 式中:c为声速,
$ {\left\| \cdot \right\|_p} $ 表示矩阵或向量的p范数。麦克风阵列信号$y\left( {{{\boldsymbol{r}}_s},t} \right)$ 为麦克风信号的算数平均:$$ y\left( {{r_s},t} \right){\text{ = }}\frac{{\text{1}}}{N}\sum\limits_{i = 1}^N {{p_i}\left( t \right)} $$ 1.2 时域波束形成
声源定位的麦克风阵列信号的输出功率
${y_e}\left( {{{\boldsymbol{r}}_s}} \right)$ 定义为$$ {y_e}\left( {{{\boldsymbol{r}}_s}} \right) = {\rm{E}}\left\{ {y{{\left( {{{\boldsymbol{r}}_s},t} \right)}^2}} \right\} = \int_{ - \infty }^{ + \infty } {\frac{1}{{{N^2}}}\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^N {{p_i}\left( t \right){p_j}\left( t \right){\rm{d}}t} } } $$ 其中
${\rm{E}}\left\{ \cdot \right\}$ 为数学期望。麦克风阵列信号的输出功率也可以写为$$ {y_e}\left( {{{\boldsymbol{r}}_s}} \right) = \frac{1}{{{N^2}}}\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^N {\left( {{p_i} \cdot {p_j}} \right)\left( \tau \right)} } $$ 式中:
$ \left( {{p_i} \cdot {p_j}} \right) $ 表示对应的两个麦克风信号在时延$ \tau = \left( {\Delta {t_{js}} - \Delta {t_{is}}} \right) $ 时的互相关函数,即$$ \left( {{p_i} \cdot {p_j}} \right)\left( \tau \right) = \int_{ - \infty }^{ + \infty } {{p_i}\left( t \right){p_j}\left( {t + \tau } \right)} {\rm{d}}t $$ 由于在上式中的自相关项
$ \left( {i = j} \right) $ 不包含时延估计的信息,因此,不予考虑。此外,根据互相关函数的对称性,可以将多余的麦克风对去除。因此,如果在一组${{\boldsymbol{r}}_l}$ $\left( {l = 1,{\text{2}},\cdots,L} \right)$ 扫描点上搜索源位置,则修改后的麦克风阵列信号的输出功率$y{'_e}\left( {{{\boldsymbol{r}}_s}} \right)$ 定义为$$ y{'_e}\left( {{{\boldsymbol{r}}_s}} \right) = \frac{1}{{{N_p}}}\sum\limits_{i = 1}^N {\sum\limits_{j > i}^N {\left( {{p_i} \cdot {p_j}} \right)\left( {\Delta {t_{jl}} - \Delta {t_{il}}} \right)} } $$ 式中
$ {N_p} $ 为麦克风对的数量。1.3 广义互相关GCC
为计算GCC函数,需要利用麦克风信号在角频率
$ \omega $ 处的互谱的傅里叶逆变换,计算公式为$$ \left( {{p_i} \circ {p_j}} \right)\left( \tau \right) = \int_{ - \infty }^{ + \infty } {{W_{ij}}\left( \omega \right){C_{ij}}\left( \omega \right)\exp \left( {{\rm{j}}\omega \tau } \right)} {\rm{d}}\omega $$ 式中:
$ {W_{ij}}\left( \omega \right) $ 为权值函数,$ {C_{ij}}\left( \omega \right) $ 为$$ {C_{ij}}\left( \omega \right) = \left( {\int_{ - \infty }^{ + \infty } {{p_i}\left( t \right)\exp \left( { - {\rm{j}}\omega t} \right){\rm{d}}t} } \right){\left( {\int_{ - \infty }^{ + \infty } {{p_j}\left( t \right)\exp \left( { - {\rm{j}}\omega t} \right){\rm{d}}t} } \right)^*} $$ 因此,麦克风阵列信号的修正功率可以表示为
$$ y{'_e}\left( {{r_s}} \right) = \frac{1}{{{N_p}}}\sum\limits_{i = 1}^N {\sum\limits_{j > i}^N {\int_{ - \infty }^{ + \infty } {{W_{ij}}\left( \omega \right){C_{ij}}\left( \omega \right)\exp \left( {{\rm{j}}\omega \tau } \right)} {\rm{d}}\omega } } $$ 1.4 逆模型
对于包含源向量
${\boldsymbol{x}}$ (对应源信号的功率)的寻优问题J,其最小化依赖于测量噪声源图${\boldsymbol{ y}}'$ (CBF所得结果)和模型源映射$\bar {\boldsymbol{y}}$ 的损失函数$ \rho $ ,是减小旁瓣和杂散瓣影响从而提高声源定位精度的一种方法。从而,寻优问题定义为$$ J\left( x \right) = \mathop {\min }\limits_x \rho \left( {y',\bar y} \right) $$ 定义源映射模型为线性系统,即
$$ \bar {\boldsymbol{y }}= {\boldsymbol{Ax}} $$ (1) 式中
${\boldsymbol{A}}$ 为传播模型矩阵[21]。为计算传播模型矩阵,考虑${{\boldsymbol{r}}_k}$ 位置处的声源,时延估计$ \Delta {t_{ij,k}} $ 为$$ \Delta {t_{ij,k}} = \frac{1}{{{c_0}}}{\left\| {{{\boldsymbol{r}}_i} - {{\boldsymbol{r}}_k}} \right\|_2} - \frac{1}{{{c_0}}}{\left\| {{{\boldsymbol{r}}_j} - {{\boldsymbol{r}}_k}} \right\|_2} = \Delta {t_{ik}} - \Delta {t_{jk}} $$ 矩阵
${\boldsymbol{A}}$ 中元素定义为$$ a\left({{\boldsymbol{r}}}_{k},{{\boldsymbol{r}}}_{l}\right)=\frac{1}{{N}_{p}}\displaystyle \sum _{i=1}^{N}\displaystyle \sum _{j > i}^{N}\left\{\begin{aligned} &1,\quad \left|\Delta {t}_{ij,k}-\Delta {t}_{ij,l}\right|\leqslant \varepsilon \\ &0,\quad {其他}\end{aligned}\right. $$ 如果时延估计的差值很小,则设置为1,否则设置为0,这意味着只需要考虑靠近源位置的扫描点的贡献[21]。令代价函数
$ \rho $ 表示欧氏距离,从而线性最小二乘问题可以定义为$$ J\left( {\boldsymbol{x}} \right) = \mathop {\min }\limits_x \left\| {{\boldsymbol{y}}' - {\boldsymbol{Ax}}} \right\|_2^2 $$ 2. 基于密度聚类的压缩网格算法
广义互相关逆模型算法虽能有效提升分辨率,但其计算复杂度较高。当网格点数目比较大时,无论是传播模型矩阵的计算,还是该逆模型的求解都会耗费相当长的时间。因此,本节提出了一种能有效提升计算效率的算法。图1为本文所提算法的算法流程图。
 图 1 算法流程Fig. 1 Algorithm flow
图 1 算法流程Fig. 1 Algorithm flow 下载:
全尺寸图片
下载:
全尺寸图片
2.1 传统波束形成
CBF公式为
$$ b\left( {\boldsymbol{r}} \right) = \frac{1}{{{{\left\| {{\boldsymbol{v}}\left( {\boldsymbol{r}} \right)} \right\|}^{\text{4}}}}}{\boldsymbol{v}}{\left( {\boldsymbol{r}} \right)^H}{\boldsymbol{E}}\left\{ {{{p}}{{{p}}^{\rm{H}}}} \right\}{\boldsymbol{v}}\left({\boldsymbol{ r }}\right) $$ 式中:
${\boldsymbol{E}}\left\{ {{{p}}{{{p}}^{\rm{H}}}} \right\}$ 表示互谱矩阵,$ p $ 表示声压函数,${\boldsymbol{v}}\left( {\boldsymbol{r}} \right) = \left[ {{v_1}\left( {\boldsymbol{r}} \right){v_2}\left( {\boldsymbol{r}} \right)\cdots{v_M}\left( {\boldsymbol{r}} \right)} \right]$ 为聚焦点${\boldsymbol{r}}$ 所对应的导向向量,其中元素表达式为$$ {v_m}\left( {\boldsymbol{r}} \right) = \frac{{\left\| {{\boldsymbol{r}} - {{\boldsymbol{r}}_m}} \right\|}}{{\left\| {\boldsymbol{r}} \right\|}}\exp \{ - jk\left\| {{\boldsymbol{r}} - {{\boldsymbol{r}}_m}} \right\|\} $$ 式中:
$\left\| {\boldsymbol{r}} \right\|$ 为聚焦点到麦克风阵列中心的距离,$\left\| {{\boldsymbol{r}} - {{\boldsymbol{r}}_m}} \right\|$ 为聚焦点到第$ m $ 个麦克风的距离,$ k $ 为波数。2.2 压缩网格算法
为了消除麦克风自噪声污染,特别是由与麦克风相互作用的湍流引起的自噪声污染,对角卸载(DR)通常应用于CSM,通过去除(消零)CSM的对角线项,并解释分母中CMS项数的变化。
$$ b\left( {\boldsymbol{r}} \right) = \frac{{{\boldsymbol{v}}{{\left( {\boldsymbol{r}} \right)}^{\rm{H}}}{\boldsymbol{E}}{{\left\{ {{{p}}{{{p}}^{\rm{H}}}} \right\}}_{{\text{diag = 0}}}}{\boldsymbol{v}}\left({\boldsymbol{ r}} \right)}}{{{{\left\| {{\boldsymbol{v}}\left({\boldsymbol{ r}} \right)} \right\|}^{\text{4}}} - \displaystyle\sum\nolimits_{m = 1}^M {{{\left| {{v_m}\left({\boldsymbol{ r}} \right)} \right|}^4}} }} $$ 当DR应用于CSM时,CBF会有负值出现。这些波束形成非正的网格点被认为是冗余点,从而可以将其从扫描区域的原始计算网格中剔除[16]。在压缩网格算法中,去除这些输出功率低于阈值的点,仅保留满足条件的点,即
$$ b\left( {\boldsymbol{r}} \right) > \xi $$ 则方程(1)转化为
$$ \tilde {\boldsymbol{y}} = \tilde{\boldsymbol{ A}}\tilde {\boldsymbol{x}} $$ 式中:
$\tilde {\boldsymbol{A}} \in {{\bf{R}}^{\tilde {{R}} \times \tilde {{R}}}},\tilde {\boldsymbol{x}} \in {{{R}}^{\tilde {{R}} \times 1}},\tilde {\boldsymbol{y}} \in {{\bf{R}}^{\tilde {{R}} \times 1}}$ ,$\tilde {{R}}$ 为保留的网格点的数目。2.3 基于密度的聚类
通过上述步骤后保留下来的点都聚集在声源附近,若声场中声源个数为n,则应该有n块较为密集的点集以及一些零散点,而这些零散点正好是我们所不需要的。所以,运用基于密度的聚类,将聚类结果的核心点保留,去除远离声源的点。
一种比较有代表性的基于密度的聚类算法是DBSCAN(density-based spatial clustering of applications with noise)[22]。它以元素之间的紧密程度作为判别条件,以此来决定它们是否属于一类,最终将所有紧密相连的元素划分为同一类。
DBSCAN算法认为“最大相连”的点集可以构成一个簇,此处的“最大相连”的意思是:构成簇的点集必然是互相紧密相连的,与簇中的点密度可达的点必然属于这个簇。DBSCAN算法流程如下:
1)筛选核心点:对所有点进行邻域计算,按照如上规则划分核心点、边界点和噪声点。
2)删除噪声点:将所有噪声点剔除,只保留核心点和边界点;
3)生成簇:扫描整个数据集,找到任意一个核心点,对该核心点进行扩充。扩充的方法是寻找从该核心点出发的所有密度相连的数据点。遍历该核心点的邻域内的所有核心点(因为边界点是无法扩充的),寻找与这些数据点密度相连的点,直到没有可以扩充的数据点为止,这些点就形成了一个簇;
4)循环执行步骤3),直到原始点集为空,至此就划分出了所有簇。
2.4 含有正性约束的Gauss-Seidel迭代法
通过上述步骤,则我们问题转化为求解
$$ \hat {\boldsymbol{y}} = \hat {\boldsymbol{A}}\hat {\boldsymbol{x}} $$ 式中:
$\hat {\boldsymbol{A}} \in {{\bf{R}}^{\hat {{R}} \times \hat {{R}}}},\hat {\boldsymbol{x}} \in {{\bf{R}}^{\hat {{R}} \times 1}},\hat y \in {{\bf{R}}^{\hat {{R}} \times 1}}$ ,$\hat {{R}}$ 为经过两步去除后剩下的网格点数。我们用带有正性约束的Gauss-Seidel迭代法来求解$ \hat x $ :$$ r_n^{\left( i \right)} = \sum\limits_{n'}^{n - 1} {{A_{nn'}}x_{n'}^{\left( {i + 1} \right)}} + \sum\limits_{n' = n}^L {{A_{nn'}}x_{n'}^{\left( i \right)}} - {y_n} $$ $$ x_n^{\left( {i + 1} \right)} = \max \left( {x_n^{\left( i \right)} - \frac{{r_n^i}}{{{A_{nn}}}},0} \right),n = 1,2,\cdots,L,\quad i = 1,2,\cdots,K $$ 式中:
$ L $ 表示格点数,$ K $ 表示迭代次数。$ r_n^{\left( i \right)} $ 是每步迭代的残差,第一次迭代时初始值$ r_n^{\left( {\text{1}} \right)} $ 可以取做0或$ {B_n} $ 。3. 实验
本文所用数据来自多通道脉冲响应数据库[23]。该数据库数据测试场景设置如下,传感器阵列为8通道等间隔线性阵列,阵列间隔为0.08 m;声源到阵列中心(0 m,0 m)的连线与阵列正方向成15°~ 345°,分辨率为15°,且声源到阵列中心(0 m,0 m)的距离为1 m和2 m,混响为160 ms, 360 ms, 610 ms。实验中,将麦克风坐标按实测场景设置为(−0.28 m,0 m), (−0.20 m,0 m), (−0.12 m,0 m), (−0.04 m,0 m), (0.04 m,0 m), (0.12 m,0 m), (0.20 m,0 m), (0.28 m,0 m),从数据库中选取混响为160 ms,声源到阵列中心距离为1 m的数据进行实验。
图2为单声源在45°时传统波束形成法的定位结果,其主瓣较宽,旁瓣较高,空间分辨率低。图3为对使用压缩网格算法后的剩余点进行DBSCAN算法聚类的结果,其中,棕色区域为使用压缩网格算法所剔除的点,深蓝色区域为使用DBSCAN算法计算出的噪声点,浅蓝色区域为计算出的边缘点,黄色区域为核心点区域,即基于密度聚类的压缩网格算法所确定出的最终计算范围。
 图 2 CBF结果Fig. 2 Result of CBF下载:
全尺寸图片
图 2 CBF结果Fig. 2 Result of CBF下载:
全尺寸图片
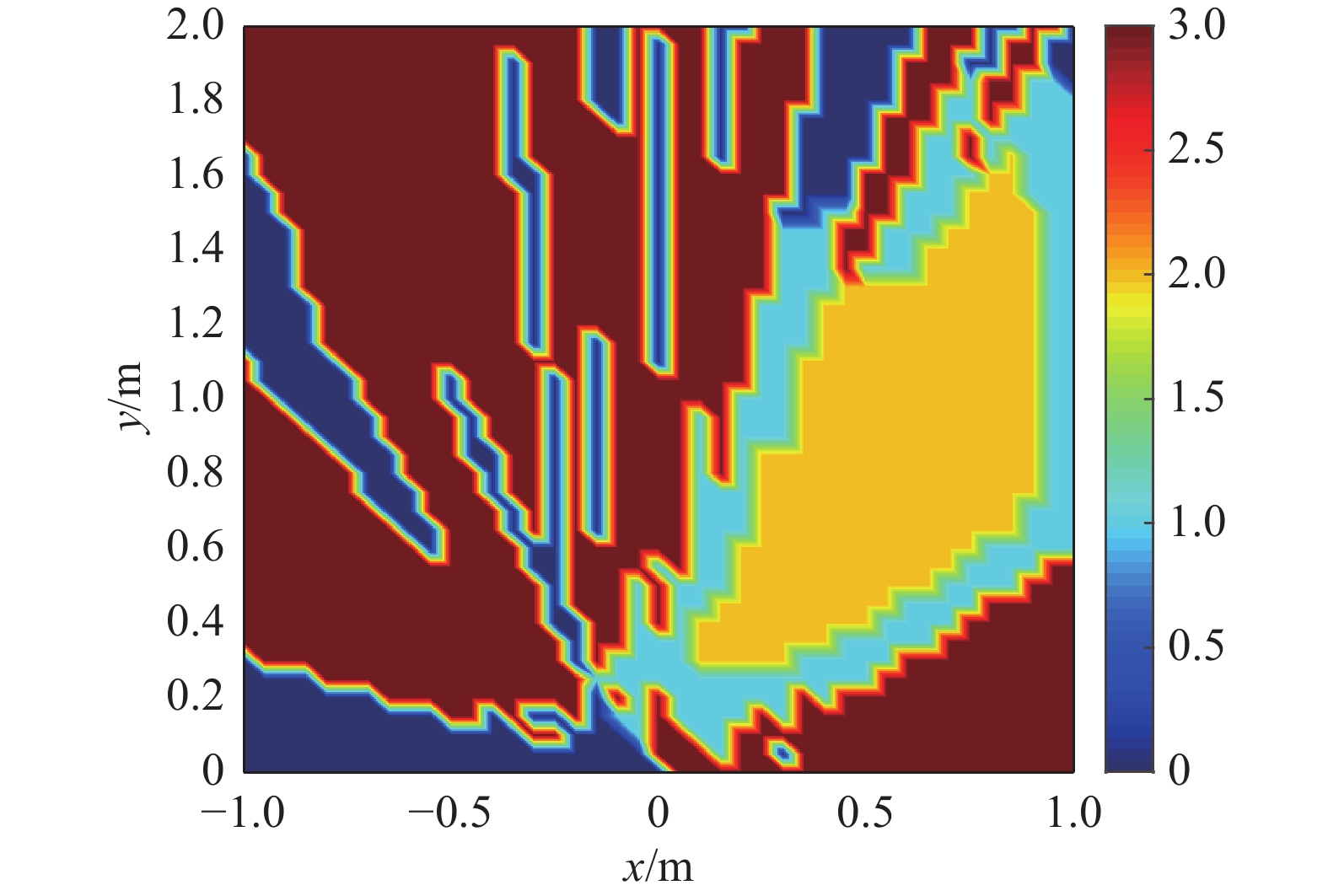 图 3 聚类结果Fig. 3 Result of clustering下载:
全尺寸图片
图 3 聚类结果Fig. 3 Result of clustering下载:
全尺寸图片
图4为单声源在30°,每个网格点大小为0.05 m×0.05 m,总网格点数为1 681时的定位结果,与图2的CBF定位结果相比,图4中结果主瓣较窄,有较高的空间分辨率。图4(a)为原算法[19]定位结果,图4(b)为基于聚类的压缩网格算法定位结果,图中2种算法的均方根误差(RMSE)相差不超过0.05 m,定位效果基本一致。图5为双声源定位结果,声源分别处于75°、90°角,每个网格点大小为0.04 m×0.04 m,总网格点数为2 601,图中两算法RMSE总偏差不超过0.08 m。基于聚类的压缩网格算法基本保留了原算法的高空间分辨率优势。
 图 4 单声源定位结果Fig. 4 Localization result of one source下载:
全尺寸图片
图 4 单声源定位结果Fig. 4 Localization result of one source下载:
全尺寸图片
表1为3种算法计算规模与计算时间的对比,结果为10组数据结果的算术平均。基于密度聚类的压缩网格算法将计算规模降至最低,矩阵A计算时间以及声源位置求解时间均为3种算法中最短。时间由MATLAB R2018b的tic-toc函数给出,实验设备为2.40 GHz的四核处理器,16.0 GB内存的计算机。表2为3种算法在不同信噪比(SNR)下定位精度的对比,评价参数选用均方根误差(RMSE),单位为m,分辨率为0.05 m。基于密度聚类的压缩网格算法与原算法以及压缩网格算法相比,在3种信噪比级别下RMSE相差均不超过0.05 m。图6和图7分别给出了不同网格点个数下,3种算法求解传播模型矩阵与声源位置求解的时间对比图,由于基于密度聚类的压缩网格算法很大程度的降低了计算规模,所以计算时间最短。
 图 5 双声源定位结果Fig. 5 Localization result of two sources下载:
全尺寸图片
图 5 双声源定位结果Fig. 5 Localization result of two sources下载:
全尺寸图片
 图 6 传播模型矩阵计算时间Fig. 6 Computation time of the propagation model matrix下载:
全尺寸图片
图 6 传播模型矩阵计算时间Fig. 6 Computation time of the propagation model matrix下载:
全尺寸图片
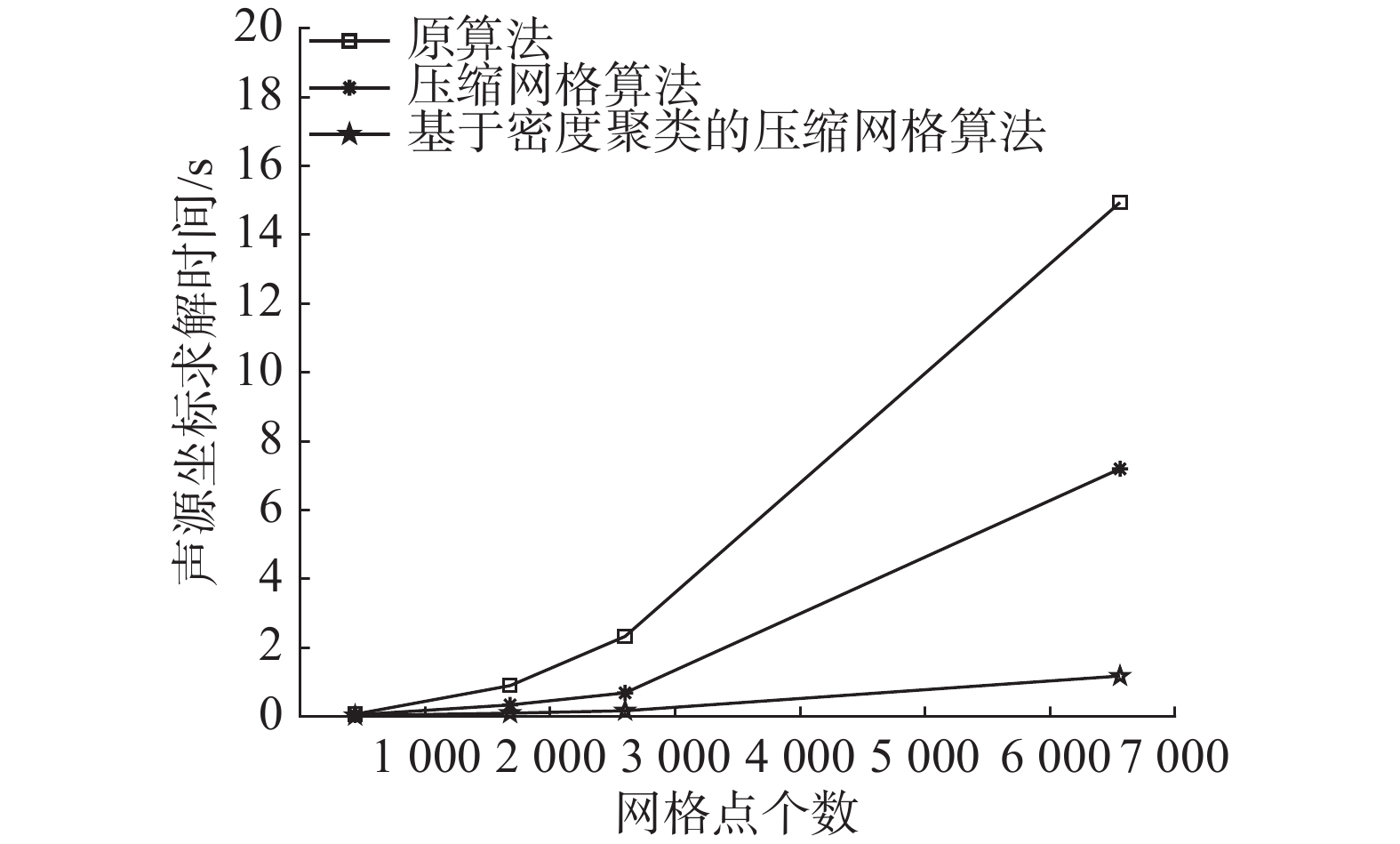 图 7 声源位置求解时间Fig. 7 Computation time of the source location下载:
全尺寸图片
图 7 声源位置求解时间Fig. 7 Computation time of the source location下载:
全尺寸图片
基于密度聚类的压缩网格算法有效提升了定位效率,且在定位误差相差不大的前提下,保留了原始逆模型算法的高空间分辨率优势。图3中黄色区域是所提算法对网格点进行压缩后的最终计算区域,极大的缩小了计算规模,这也是所提算法能有效提升效率的关键所在。表1中数据以及图6图7证明,无论是传播模型矩阵的计算时间,还是声源坐标的求解时间,本文所提的新算法均优于所对比的两类算法。表2中数据表明,在所设条件下,本文所提算法在3种信噪比下与对比算法的RMSE相差不超过0.05m,定位精度的小幅降低在所提升的计算效率前可以接受。图2与图4及图5的对比非常明显,传统波束形成算法主瓣宽,旁瓣高,分辨率较低,而逆模型算法能有效提升空间分辨率,且通过对比图4(a)与(b)以及图5(a)与(b)发现,本文所提算法很好地保留了逆模型算法的分辨率优势。
4. 结束语
为了快速定位声源位置,提出了一种基于密度聚类的压缩网格算法。首先,移除传统波束形成结果中不满足阈值条件的点,然后将几何因素考虑在内,利用基于密度的聚类,删除噪声点,保留核心点,以此来减小问题规模。通过实验与原算法进行对比,结果表明本文所提的算法可以有效的提升计算效率。
-
图 1 算法流程
Fig. 1 Algorithm flow
下载:
全尺寸图片
图 2 CBF结果
Fig. 2 Result of CBF
下载:
全尺寸图片
图 3 聚类结果
Fig. 3 Result of clustering
下载:
全尺寸图片
图 4 单声源定位结果
Fig. 4 Localization result of one source
下载:
全尺寸图片
图 5 双声源定位结果
Fig. 5 Localization result of two sources
下载:
全尺寸图片
图 6 传播模型矩阵计算时间
Fig. 6 Computation time of the propagation model matrix
下载:
全尺寸图片
图 7 声源位置求解时间
Fig. 7 Computation time of the source location
下载:
全尺寸图片
表 1 计算效率对比
Table 1 Comparison of computational efficiency
-
[1] 李晓飞, 刘宏. 机器人听觉声源定位研究综述[J]. 智能系统学报, 2012, 7(1): 9–20. LI Xiaofei, LIU Hong. A survey of sound source localization for robot audition[J]. CAAI transactions on intelligent systems, 2012, 7(1): 9–20. [2] 鲍长春, 项扬. 基于深度神经网络的单通道语音增强方法回顾[J]. 信号处理, 2019, 35(12): 1931–1941. BAO Changchun, XIANG Yang. Review of monaural speech enhancement based on deep neural networks[J]. Journal of signal processing, 2019, 35(12): 1931–1941. [3] 高庆吉, 赵志华, 徐达, 等. 语音情感识别研究综述[J]. 智能系统学报, 2020, 15(1): 1–13. GAO Qingji, ZHAO Zhihua, XU Da, et al. Review on speech emotion recognition research[J]. CAAI transactions on intelligent systems, 2020, 15(1): 1–13. [4] MICHEL U. History of acoustic beamforming[C]//1. st Berlin beamforming conference. Berlin: DLR, 2006, 1–17. [5] LI Jian, XIE Yao, STOICA P, et al. Beampattern synthesis via a matrix approach for signal power estimation[J]. IEEE transactions on signal processing, 2007, 55(12): 5643–5657. doi: 10.1109/TSP.2007.899343 [6] YAN Shefeng, SUN Haohai, SVENSSON U P, et al. Optimal modal beamforming for spherical microphone arrays[J]. IEEE transactions on audio, speech, and language processing, 2011, 19(2): 361–371. doi: 10.1109/TASL.2010.2047815 [7] KUMAR L, HEGDE R M. Near-field acoustic source localization and beamforming in spherical harmonics domain[J]. IEEE transactions on signal processing, 2016, 64(13): 3351–3361. doi: 10.1109/TSP.2016.2543201 [8] SALVATI D, DRIOLI C, FORESTI G L. A low-complexity robust beamforming using diagonal unloading for acoustic source localization[J]. IEEE/ACM transactions on audio, speech, and language processing, 2018, 26(3): 609–622. doi: 10.1109/TASLP.2017.2789321 [9] SIMARD P, ANTONI J. Acoustic source identification: experimenting the ℓ1 minimization approach[J]. Applied acoustics, 2013, 74(7): 974–986. doi: 10.1016/j.apacoust.2013.01.012 [10] LONG Tao, CHEN Jingdong, HUANG Gongping, et al. Acoustic source localization based on geometric projection in reverberant and noisy environments[J]. IEEE journal of selected topics in signal processing, 2019, 13(1): 143–155. doi: 10.1109/JSTSP.2018.2885410 [11] PADOIS T, SGARD F, DOUTRES O, et al. Acoustic source localization using a polyhedral microphone array and an improved generalized cross-correlation technique[J]. Journal of sound and vibration, 2017, 386: 82–99. doi: 10.1016/j.jsv.2016.09.006 [12] DOUGHERTY R, STOKER R. Sidelobe suppression for phased array aeroacoustic measurements[C]//4th AIAA/CEAS Aeroacoustics Conference. Toulouse: AIAA, 1998: 2242. [13] BROOKS T F, HUMPHREYS W M. A deconvolution approach for the mapping of acoustic sources (DAMAS) determined from phased microphone arrays[J]. Journal of sound and vibration, 2006, 294(4/5): 856–879. [14] SUN Dajun, MA Chao, MEI Jidan, et al. Improving the resolution of underwater acoustic image measurement by deconvolution[J]. Applied acoustics, 2020, 165: 107292. doi: 10.1016/j.apacoust.2020.107292 [15] BAI Baohong, LI Xiaodong. Acoustic sources mapping based on the non-negative L1/2 regularization[J]. Applied acoustics, 2020, 169: 107456. doi: 10.1016/j.apacoust.2020.107456 [16] MA Wei, LIU Xun. Compression computational grid based on functional beamforming for acoustic source localization[J]. Applied acoustics, 2018, 134: 75–87. doi: 10.1016/j.apacoust.2018.01.006 [17] KNAPP C, CARTER G. The generalized correlation method for estimation of time delay[J]. IEEE transactions on acoustics, speech, and signal processing, 1976, 24(4): 320–327. doi: 10.1109/TASSP.1976.1162830 [18] NOËL C, PLANEAU V, HABAULT D. A new temporal method for the identification of source directions in a reverberant hall[J]. Journal of sound and vibration, 2006, 296(3): 518–538. doi: 10.1016/j.jsv.2005.12.056 [19] PADOIS T, DOUTRES O, SGARD F, et al. Time domain localization technique with sparsity constraint for imaging acoustic sources[J]. Mechanical systems and signal processing, 2017, 94: 85–93. doi: 10.1016/j.ymssp.2017.02.035 [20] CHU Zhigang, WENG Jing, YANG Yang. Determination of propagation model matrix in generalized cross-correlation based inverse model for broadband acoustic source localization[J]. The journal of the acoustical society of America, 2020, 147(4): 2098. doi: 10.1121/10.0000973 [21] VELASCO J, PIZARRO D, MACIAS-GUARASA J. Source localization with acoustic sensor arrays using generative model based fitting with sparse constraints[J]. Sensors, 2012, 12(10): 13781–13812. doi: 10.3390/s121013781 [22] ESTER M, KRIEGEL H P, SANDER J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]// KDD'96: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining. Portland: AAAI, 1996, 34: 226−231. [23] HADAD E, HEESE F, VARY P, et al. Multichannel audio database in various acoustic environments[C]//2014 14th International Workshop on Acoustic Signal Enhancement. Juan-les-Pins: IEEE, 2014: 313−317








































































