
Person search algorithm based on multi-granularity matching
-
摘要: 行人搜索旨在从一系列未经裁剪的图像中对行人进行定位与识别,融合了行人检测和行人重识别两个子任务。现有的方法设计了基于Faster R-CNN的端到端框架来解决此任务,但是行人检测和重识别两个子任务之间存在特征优化目标粒度不一致问题。为了解决这一问题,提出一种双全局池化结构,使用全局平均池化提取检测分支的共性特征,使用基于注意力机制的全局K最大池化提取re-ID分支的特性特征,为两个子任务提取符合各自粒度特性的特征。同时由于re-ID子任务的细粒度特性,还提出一种改善粒度匹配的画廊边界框加权算法,把查询人和画廊边界框的分辨率差异纳入相似度计算。实验证明融入多粒度的方法有效地提高了单阶段算法在CHUK-SYSU和PRW数据集上的性能。Abstract: Person search aims to locate and recognize a specified person from a series of uncropped images, which combines Pedestrian Detection and Person Re-identification (re-ID). Existing methods based on Faster R-CNN have been widely used to solve the two subtasks jointly. However, the optimization goals of the two subtasks are inconsistent. To alleviate this issue, we propose a dual global pooling structure, which applies Global Average Pooling to extract common features in detection branch and applies Global K-Max Pooling to extract discriminative features in re-ID branch. In this way, our method successfully extracts features that conform to the granularity characteristics of the two subtasks. In addition, to relieve the granularity mismatch problem, we propose a multi-granularity gallery boxes re-weighting algorithm, which incorporates granularity difference into similarity measurement. Extensive experiments show that our method greatly improves the performance of the end-to-end framework on two widely used person search datasets, CUHK-SYSU and PRW.
-
行人搜索旨在从跨摄像头下找到与待查询目标行人类别相同的行人在场景中的位置,与行人重识别(re-ID)[1]任务相比,它包含从画廊(gallery)中生成行人边界框和匹配行人两个过程。实际应用获取的图像往往是包含场景信息的完整图像,没有手动标注的行人位置信息,导致现有的re-ID方法无法直接使用。而行人搜索更适合于实际应用,例如视频监视、查找罪犯,跨摄像机人员跟踪以及人机交互等。由于人体姿势、场景照明、行人遮挡、分辨率、背景杂乱等因素的复杂变化,使得行人搜索任务具有挑战性,近年来引起了越来越多的研究关注。现有的行人搜索方法将这项任务分为行人检测和行人重识别两个子任务。在一个端到端的多任务框架中处理两个子任务(单阶段方法),或者通过级联行人检测器和行人re-ID特征提取器(两阶段方法),训练两个独立的网络分别处理两个子任务。
目前, 现有的单阶段行人搜索方法大多是基于Faster R-CNN[2]的端到端框架, 虽然该多任务框架是高效且易于训练的, 但是存在行人检测和re-ID 分支特征优化目标冲突的问题。检测分支旨在从画廊中获取边界框(bounding boxes), 并对边界框进行二分类, 只区分行人和背景, 而不区分行人的具体类别, 其关注的是行人之间的粗粒度共性特征;而re-ID分支是将检测出的各个疑似目标行人与查询行人进行匹配的过程, 其关注的是不同行人之间的细粒度个性特征。粗粒度共性关注的是全局的特征, 细粒度个性关注的是局部的特征, 导致行人检测和re-ID 分支特征优化目标冲突。本文在现有的单阶段模型OIM[3]中融入注意力机制和多粒度的思想, 提出了一种双全局池化结构(dual global pooling), 使网络可以灵活捕捉全局和局部的联系, 并对两个不同的分支提取出符合自身粒度特性的特征, 从而改善了特征之间的共性和特性冲突问题。
同时由于re-ID子任务的细粒度特性, 我们发现从画廊里检测到的不同边界框粒度差异较大。我们把边界框的分辨率定义为它的粒度, 分辨率越高, 粒度越细;分辨率越低, 粒度越粗。粗粒度的边界框往往更容易与查询人计算出较高的相似度, 因为粗粒度的边界框中, 行人特征比较模糊, 网络无法提取出具有判别性的细粒度特征, 从而产生错误的匹配结果。为了缓解粒度不匹配问题, 本文提出了一种画廊边界框粒度加权算法(granularity weighted similarity, GWS),无需改变模型的复杂度, 将画廊边界框的粒度差异纳入相似度计算, 为不同粒度的画廊边界框赋予不同的权重, 提高细粒度边界框的权重, 降低粗粒度边界框的权重。
本文采用端到端的单阶段的行人搜索框架OIM作为基准模型, 目标是改进行人检测和re-ID分支特征优化目标冲突问题, 以及特征相似度计算时查询行人和画廊边界框粒度不匹配的问题。本文主要工作和贡献如下:
1)针对检测和re-ID分支特征优化目标冲突问题, 提出一种基于注意力机制的双全局池化结构, 对检测分支使用全局平均池化结构 (global average pooling, GAP)提取粗粒度特征, 对re-ID分支使用全局K最大池化结构(global K-max pooling, GKMAP)[4]进行细粒度特征提取。
2)针对特征相似度计算时查询行人和画廊边界框粒度不匹配的问题, 提出一种画廊边界框粒度加权算法GWS, 把画廊边界框的粒度差异纳入相似度计算, 使粗粒度的边界框获得较低的权重, 细粒度的边界框获得较高的权重。
3)实验证明我们的方法极大地提高了单阶段行人搜索算法在CUHK-SYSU[3]和PRW[3]上的性能。
1. 相关工作
行人搜索作为re-ID技术的衍生, 如图1(a)所示,历史并不算久。早期行人检测和re-ID被当作两个独立的领域进行研究, 近年来随着深度学习的不断发展, 研究者们提出了融合行人检测和re-ID的检索思想, 行人搜索的概念应运而生。目前, 基于深度学习的行人搜索主要分为单阶段方法和两阶段方法,如图1(b)所示。
 图 1 行人搜索技术示意Fig. 1 Schematic diagram of person search
图 1 行人搜索技术示意Fig. 1 Schematic diagram of person search 下载:
全尺寸图片
下载:
全尺寸图片
1.1 端到端的单阶段方法
单阶段方法[3,5-8]是指在一个端到端的网络中实现行人搜索的功能, 主流的方法是沿用Faster R-CNN框架并加以改进从而实现多任务的功能。最具代表性的是Xiao等[3]在2017年提出的行人搜索框架OIM。OIM将基于ResNet50[9]的Faster R-CNN当作骨干网络, 通过在网络中增加一个re-ID分支以实现行人识别的功能, 并提出了一种在线实例匹配损失函数, 使网络可以在具有大而稀疏的分类任务中更好地收敛;为了进一步提高网络减小类内差异的能力,Xiao等[5]提出IAN,沿用Faster R-CNN 框架并通过引入中心损失增强行人特征的判别性;为了充分利用图像的上下文信息,Yan等[6]在Faster R-CNN的顶部建立了图模型来学习行人的上下文信息;为了准确提取边界框内的行人特征, Dong等[7]提出BINet,在训练阶段, 除了画廊图像外, 还以裁剪后的行人图片为输入来帮助模型基于人的外观识别身份,此外还设计了两个交互损失来实现两个级别的分支之间的双向交互。为了充分利用查询行人的信息,QEEPS[8]提出以查询为导向的方法,在处理画廊图像时将查询图片送入网络,并受SEblock[8]启发,利用QSSE-Net[8]辅助画廊图像进行行人特征的提取。
1.2 级联的两阶段方法
两阶段方法[10-11]是指先根据检测器从画廊中检测出所有候选人员, 再将其输入到re-ID特征提取器中进行识别。Chen等[10]首次提出单阶段的方法存在特征优化目标冲突的问题, 并提倡使用行人检测器和re-ID网络级联的方式实现行人搜索算法, 即为检测和re-ID提供两个参数独立的模型。Zheng等[11]测试了检测器和识别器的各种组合, 提出了用于训练的级联微调策略和用于匹配的置信加权相似度(confidence weighted similarity, CWS), 将分类置信度从检测器传输到re-ID网络,有效地提高了识别的效果。一般来说,两阶段的方法在精度上优于单阶段的方法,但是在速度上略逊一筹。实际应用中往往对行人搜索任务的实时性要求较高,因此将两个子任务融合在一个端到端的框架中解决显得更加方便和高效, 同时也更符合人类处理问题的方式。
2. 基于注意力机制的多粒度特征建模
在计算机视觉领域, 注意力机制主要是为了让模型把注意力放在感兴趣的区域, 基本原理很简单:它认为, 网络中每层不同特征(可以是不同通道的, 也可以是不同位置的)的重要性不同, 后面的层应该更注重其中重要的信息, 抑制不重要的信息。在本节中, 首先概述基于Faster R-CNN的单阶段行人搜索模型OIM的整体结构, 然后针对检测和re-ID分支优化目标粒度不一致的问题, 介绍改进后的模型。
2.1 OIM模型框架
图2显示了基于Faster R-CNN的单阶段行人搜索方法OIM的模型结构,其在Faster R-CNN顶部卷积特征的基础上,添加了用于检测、回归和re-ID的多任务分支,使模型可以在一个端到端的框架内共同处理行人检测和行人re-ID任务。如图2所示,给定一张待查询的图像作为输入,首先经过ResNet50的第一部分(res1-res4),将输入图片从原始像素变换到卷积特征图,然后在这些特征图上建立一个RPN[2]网络(region proposal network, RPN), 从而得到预测候选人的区域提案(region proposals)。在对这些区域提案进行非极大值抑制[13](non-maximum suppression, NMS)后,保留128个区域提案,并利用RoI-Align[14]层将这些区域提案转化为1024×14×14的特征区域。接着将这些池化后的特征区域输入到ResNet50的第二部分(res5)和一个全局平均池化层(global average pooling, GAP)。最后经过2 048维全连接层进行分类和回归,经过全连接层提取L2归一化后的256维特征,用OIM损失[3]对提取的行人特征进行优化。
 图 2 行人搜索模型OIM结构Fig. 2 Structure of person search model OIM下载:
全尺寸图片
图 2 行人搜索模型OIM结构Fig. 2 Structure of person search model OIM下载:
全尺寸图片
2.2 双全局池化结构
OIM由检测(包括分类和回归)和re-ID 两个分支组成,并在全连接层之前共享了一个全局平均池化层(如图2所示)。全局池化层通过改变卷积特征图的空间维度,往往可以帮助网络实现更好的分类,然而由于检测和re-ID特征的粒度特性不同,使用相同的池化方法无法为每个分支提取出最优的特征。行人检测是粗粒度的任务,关注的是行人这一类别特征之间的整体相似性,需要降低局部判别性特征带来的差异性和对分类结果的影响。如图3所示,基于这一特性,本文在检测分支中保留了全局平均池化的结构,便于网络提取出全局共性信息。而re-ID是细粒度的任务,不同类别的行人由于外形、穿着等原因可能看起来很相似,同时同一类别的行人图像可能由于姿态、光照等因素看起来反而不那么相似,因此该任务有着“类间间距小,类内间距大”的特点。对于网络来说,应该更加关注那些能够区分行人的局部特征。本文受到ELoPE[4]的启发,在网络的re-ID分支中融入了注意力机制,如图3所示,用全局K最大池化结构(global K-max pooling, GKMAP)代替了原来的全局平均池化结构。GKMAP通过提取特征图中K个最重要的局部位置,使得用于re-ID的特征更具判别性。全局平均池化是对最后一个卷积层输出的每一个特征图的所有值进行平均运算,而全局K最大池化是对最后一个卷积层输出的每一个特征图先选定K个最大值,然后对每个特征图中的K个最大值进行平均运算。
 图 3 改进后的OIM模型结构Fig. 3 Structure of improved OIM model下载:
全尺寸图片
图 3 改进后的OIM模型结构Fig. 3 Structure of improved OIM model下载:
全尺寸图片
全局K最大池化定义如下:给定输入图像
$ x $ ,$y\in {\bf{R}}^{C\times H\times W}$ 是最后一个卷积层的输出, 其中${C}$ 是通道数, 每一个通道内的特征图的大小为$ H\times W $ 。给定一个
$c\in \left\{\mathrm{1,2},\cdots, C\right\}$ , 降序排列后的向量${\boldsymbol V}_{c}$ 定义如下:$$ {\boldsymbol V}_{c}={\rm{sort}}\left\{{y}_{c,h,w}|h\in \left\{1,2,\cdots, H\right\},w\in \left\{1,2,\cdots ,W\right\}\right\} $$ (1) 基于给定K值的全局K最大池化的定义如下:
$$ {\rm{GKMAP}}=\frac{1}{K}\sum _{k=1}^{K}{V}_{c,k} $$ (2) 如果
$ K $ =$ H\times W $ ,式(2)则可以表示标准的全局平均池化。全局平均池化的定义如下:
$$ {\rm{GAP}}=\frac{1}{H\times W}\sum _{k=1}^{H\times W}{V}_{c,k} $$ (3) 本文中,通过引入双全局池化结构,改进后的OIM模型可以为检测分支提取出全局的粗粒度共性特征,为re-ID分支提取出局部的细粒度个性特征,从而能够灵活捕捉全局和局部的联系,专注于提取符合两个子任务粒度特性的特征。
3. 边界框多粒度加权的相似度计算
OIM模型在计算查询人和画廊图像的相似度时,将画廊中检测到的不同边界框权重视作相等,这就产生了查询行人和画廊边界框粒度不匹配的问题。为了改善粒度不匹配问题,本文提出一种画廊边界框粒度加权相似度计算(granularity weighted similarity, GWS)。
GWS算法定义如下:给定一个查询人边界框
$ q $ 和一个画廊边界框$ g,q $ 和$ g $ 的相似度计算定义如下:$$ {\rm{sim}}\left(q,g\right)=\frac{\displaystyle\sum _{i=1}^{n}{x}_{{q}_{i}}{x}_{{g}_{i}}}{\left|{X}_{q}\right|\cdot \left|{X}_{g}\right|} $$ (4) 其中
${X}_{q}=\left\{{x}_{{q}_{1}},{x}_{{q}_{2}},\cdots, {x}_{{q}_{n}}\right\}$ 和${X}_{g}=\left\{{x}_{{g}_{1}},{x}_{{g}_{2}},\cdots, {x}_{{g}_{n}}\right\}$ 分别表示$ q $ 和$ g $ 的特征。我们用
${\rm{area}}\left(b\right)={b}_{w}\cdot{b}_{h}$ 定义边界框的面积,并定义函数$ d\left(q,g\right) $ 来衡量$ q $ 和$ g $ 之间的粒度差异。$$ d\left(q,g\right)=\left\{\begin{aligned} &\dfrac{{\rm{area}}\left(g\right)}{{\rm{area}}\left(q\right)},\quad{\rm{area}}\left(g\right) < {\rm{area}}\left(q\right)\\ &1,\quad {其他} \end{aligned}\right. $$ (5) 式中:
$ d\left(q,g\right) $ 的值越接近1, 说明$ q $ 和$ g $ 之间的粒度差异越小,$ d\left(q,g\right) $ 的值越小, 说明$ g $ 相对于$ q $ 的粒度越粗。检测框g的权重变化函数w(q, g)如图4所示。
 图 4
图 4$ \mathit{w}\left(\mathit{q},\mathit{g}\right) $ 示意图Fig. 4 Structure of$ \mathit{w}\left(\mathit{q},\mathit{g}\right) $ 下载:
全尺寸图片
定义阈值
$ {k}_{1} $ 和$ {k}_{2} $ ,$ {k}_{1} $ 表示开始降低权重时横坐标$ d\left(q,g\right) $ 的阈值,$ {k}_{2} $ 表示$ d\left(q,g\right) $ 为0时纵坐标$ w\left(q,g\right) $ 的值, 若$d\left(q,g\right)\geqslant {k}_{1}$ , 则$w\left(q,g\right)$ 设置为1,保持不变;若$ d\left(q,g\right) < {k}_{1} $ , 则按照线性衰减因子降低检测框$ g $ 权重。粒度加权相似度计算GWS的定义如下:
$$ {\rm{GWS}}\left(q,g\right)={\rm{sim}}\left(q,g\right) \cdot w\left(q,g\right) $$ (6) GWS算法是受到CWS算法[11]的启发, 当画廊边界框的质量较低(如包含大范围背景或者边界框分类错误)时, re-ID的准确率不可避免地会受到影响, CWS通过将检测置信度纳入相似度计算来解决这个问题, 使得那些高质量的边界框比低质量的边界框拥有更高的权重, 从而计算出更符合实际的相似度。通过实验证明, GWS可以在CWS的基础上进一步提高OIM的精度。
置信度加权相似度计算CWS的定义如下:
$$ {\rm{CWS}}\left(q,g\right)={\rm{sim}}\left(q,g\right)\cdot {\rm{det}}\left(g\right) $$ (7) $$ {\rm{det}}\left(g\right)=\frac{{\rm{exp}}\left({W}_{{y}_{i}}X\right)}{\displaystyle\sum_{c=1}^{C}{\rm{exp}}\left({W}_{c}X\right)} $$ (8) 其中
$ C=2 $ 和$ y=\left\{\mathrm{0,1}\right\} $ 代表前景和背景边界框两种类别。$\mathrm {det}\left(g\right)$ 表示网络的检测分支为边界框$ g $ 预测的置信度。综上,本文提出的GWS可以和CWS融合成一种新的画廊边界框加权算法GWS+, 定义如下:
$$ {{\rm{GWS}}\left(q,g\right)}^+={\rm{sim}}(q,g)\cdot w(q,g)\cdot {\rm{det}}(g ) $$ (9) 4. 实验结果
4.1 数据集
CUHK-SYSU:CUHK-SYSU是一个大型行人搜索数据集, 由摄像机拍摄的街道行人照片和从电影中收集的照片两部分组成。它包含1818张画廊图像, 8432个带标签的行人和96143个带标注的边界框。每个被标记的行人都分配有一个类别标签, 并且属于同一个类别标签的行人至少以不同的角度出现在两张不同的画廊图像中, 未标记类别的行人被标记为未知人员。训练集包含11 206个画廊图像和5 532个行人类别, 而测试集包含6 978个画廊图像和 2900个查询人。在测试集中, 对于每个查询人, 其画廊图像的数目在50~4 000,本文实验默认将画廊图像的数目设置为100。
PRW:PRW数据集由从大学校园中拍摄的视频中提取的11 816个视频帧组成。它包含932个带标签的行人和34 304个带标注的边界框。与CUHK-SYSU类似, 标注分为带标签的行人类别和未标记的行人。训练集包含5 704张图像和482个行人类别, 测试集包含2 057名查询人员, 每个人都将在具有6112张图像的画廊中进行搜索。因此, 画廊大小明显大于CUHK-SYSU的默认设置。
4.2 评价指标
本文使用mAP (mean average precision)[3]和CMC (cumulative matching characteristics)[3] 作为衡量行人搜索性能的标准指标。 由于行人搜索包含了检测边界框的过程, 因此仅当排名候选框与真值边界框 (ground truth) 的IoU(Intersection over Union)大于0.5时才被认为是正确的, 这是与re-ID方法的主要区别。
4.3 实验设置
使用PyTorch来实现OIM模型,并在NVIDIA 2080Ti GPU上运行实验。采用ImageNet[15]预先训练的ResNet50作为骨干网络,把前4个残差块(res1-res4)用作主干网络,然后用标准的RPN生成行人候选边界框,接下来经过RoI-Align层将候选框的尺寸重塑为14×14,然后经过ResNet50的res5残差块。在训练过程中,采用SGD算法,将动量设置为0.9,权重衰减设置为0.0001,批量大小设置为2。对于CUHK-SYSU,学习速率被初始化为0.001, 在40 000迭代之后下降到0.0001,并保持不变, 直到50 000迭代。
4.4 实验结果与分析
将在CUHK-SYSU和PRW数据集上进行消融实验,以探索本文提出的方法对实验结果的贡献,包括双全局池化结构和GWS算法。基于PyTorch重新实现了OIM模型,表1给出在两个数据集上进行的消融实验结果,其中OIM是我们重新实现的基准模型,OIM+GWS是基准模型加上GWS算法,OIM+CWS是基准模型加上CWS算法,OIM+GWS+是基准模型加上融合了CWS的GWS算法。2pool是使用双全局池化结构改进后的模型,2pool+GWS是双全局池化结构和GWS算法,2pool+CWS是双全局池化结构和CWS算法,2pool+GWS+是双全局池化结构加上融合了CWS的GWS算法。
双全局池化结构的有效性:表2给出在CUHK-SYSU数据集上单全局池化结构与双全局池化结构的对比实验(其中K=4)。其中OIM_1GAP表示使用单全局平均池化的基准模型,OIM_1GAP表示使用单全局最大池化的模型,OIM_1GKMP表示使用单全局K最大池化的模型,OIM_2pool表示使用双全局池化结构改进后的模型。通过分析可以看出,无论是共享全局平均池化层,还是共享全局K最大池化层, 使用双全局池化层的效果要优于共享全局池化层, 说明对检测分支和re-ID[15]分支使用不同的池化方法可以优化特征共性–特性冲突问题。同时,由于本文方法对模型的改动是微小的,与OIM基准模型相比,本文方法对速度的影响是微小的,与OIM相差无几。
K的取值:在CHUK-SYSU数据集上, 在GKMAP中为K选择合适的值的实验探究如图5所示。 当K=1时与GMP等效, K =196时与GAP等效(最后一个卷积层的空间尺寸为 14×14)。如图5所示,观察到K=4时, 结果的效果是最佳的。
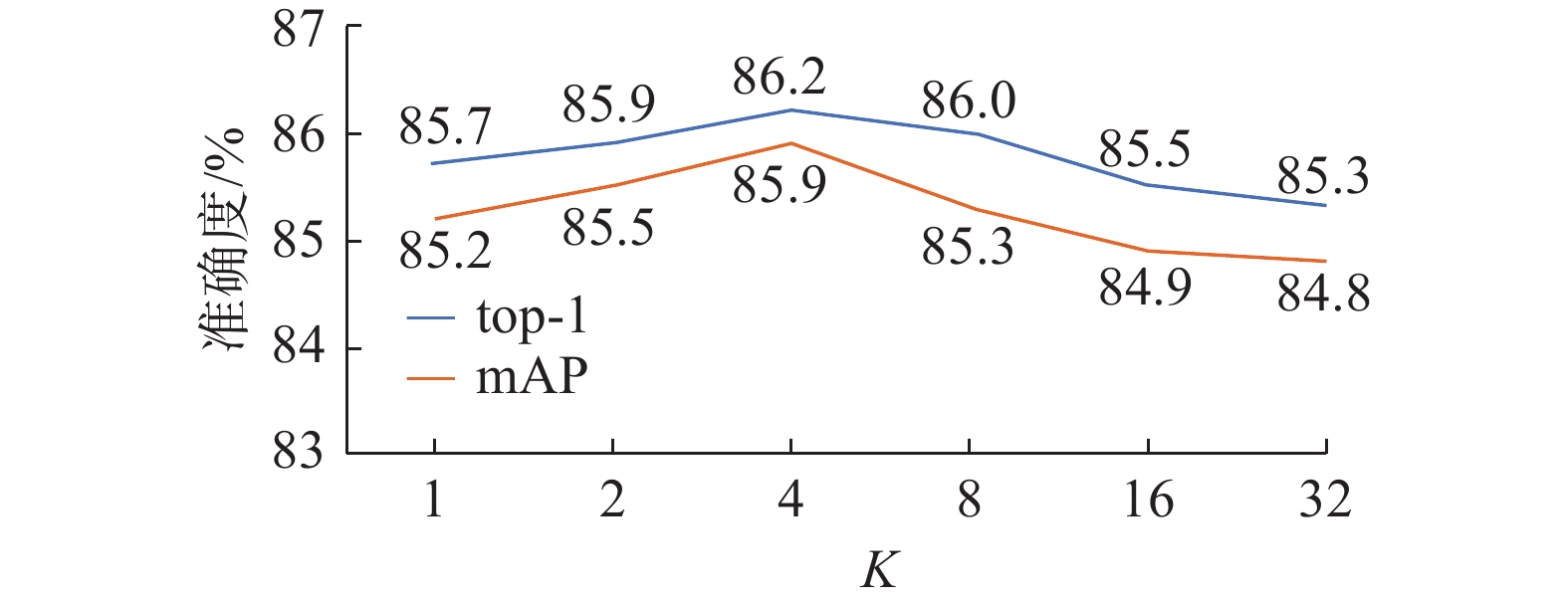 图 5 K的取值对比实验Fig. 5 Different values of K下载:
全尺寸图片
图 5 K的取值对比实验Fig. 5 Different values of K下载:
全尺寸图片
GWS的有效性:图6给出GWS的可视化结果示例,GWS修正了OIM的错误结果。我们分别选择了
$ {k}_{1} $ =0.8 和$ {k}_{2} $ =0.8。在表1中,将GWS应用到OIM后,在CUHK-SYSU上, mAP和top-1分别提高了0.5%和0.4%;在PRW上,mAP和top-1分别提高了0.4%和0.3%。将GWS添加到改进后的2pool_OIM中,在CUHK-SYSU上,mAP和top-1分别提高了0. 4%和0.4%;在PRW上, mAP和top-1分别提高了0.3%和0.2%。同时从表1可以看到,融合了CWS的GWS+在OIM和改进后的OIM仍然保持有效性,以上结果证明了GWS的确可以改善粒度不匹配问题。 图 6 GWS可视化结果示例Fig. 6 Visualization examples of GWS下载:
全尺寸图片
表 1 本文方法在CUHK-SYSU和PRW上的实验结果Table 1 Result of proposed method on CUHK-SYSU and PRW
图 6 GWS可视化结果示例Fig. 6 Visualization examples of GWS下载:
全尺寸图片
表 1 本文方法在CUHK-SYSU和PRW上的实验结果Table 1 Result of proposed method on CUHK-SYSU and PRW% 方法 CUHK-SYSU PRW mAP top-1 mAP top-1 OIM 84.7 85.3 34.0 75.9 OIM+GWS 85.2 85.7 34.4 76.6 OIM+CWS 86.9 87.2 35.7 77.2 OIM+GWS+ 87.3 87.6 36.0 77.5 2pool 85.9 86.2 35.1 76.8 2pool+GWS 86.3 86.6 35.4 77.0 2pool+CWS 87.7 87.7 36.3 77.9 2pool+GWS+ 88.1 87.9 36.6 78.1 表 2 单双全局池化层结构对比实验(取K=4)Table 2 Experiments of different pooling structures% 方法 mAP top-1 $ \Delta $mAP $ \Delta \mathrm{t} $op-1 OIM_1GAP 84.7 85.3 — — OIM_1GMP 85.0 85.4 0.3 0.1 OIM_1GKMP 85.5 85.7 0.8 0.4 OIM_2pool 85.9 86.2 1.2 0.9 5. 结束语
本文针对单阶段行人搜索模型存在的特征优化目标冲突问题,在现有的单阶段模型中融入注意力机制和多粒度的思想,提出了一种双全局池化结构,使网络可为不同分支提取出符合自身粒度特性的特征。针对查询人和画廊边界框粒度不匹配的问题,本文提出一种改善粒度匹配的画廊边界框加权算法,将检测框的分辨率差异纳入相似度计算中从而改善了粒度不匹配的问题。本文方法有效地提高了单阶段算法在CHUK-SYSU和PRW数据集上的性能。
-
图 1 行人搜索技术示意
Fig. 1 Schematic diagram of person search
下载:
全尺寸图片
图 2 行人搜索模型OIM结构
Fig. 2 Structure of person search model OIM
下载:
全尺寸图片
图 3 改进后的OIM模型结构
Fig. 3 Structure of improved OIM model
下载:
全尺寸图片
图 4
$ \mathit{w}\left(\mathit{q},\mathit{g}\right) $ 示意图Fig. 4 Structure of
$ \mathit{w}\left(\mathit{q},\mathit{g}\right) $ 下载:
全尺寸图片
图 5 K的取值对比实验
Fig. 5 Different values of K
下载:
全尺寸图片
图 6 GWS可视化结果示例
Fig. 6 Visualization examples of GWS
下载:
全尺寸图片
表 1 本文方法在CUHK-SYSU和PRW上的实验结果
Table 1 Result of proposed method on CUHK-SYSU and PRW
% 方法 CUHK-SYSU PRW mAP top-1 mAP top-1 OIM 84.7 85.3 34.0 75.9 OIM+GWS 85.2 85.7 34.4 76.6 OIM+CWS 86.9 87.2 35.7 77.2 OIM+GWS+ 87.3 87.6 36.0 77.5 2pool 85.9 86.2 35.1 76.8 2pool+GWS 86.3 86.6 35.4 77.0 2pool+CWS 87.7 87.7 36.3 77.9 2pool+GWS+ 88.1 87.9 36.6 78.1 表 2 单双全局池化层结构对比实验(取K=4)
Table 2 Experiments of different pooling structures
% 方法 mAP top-1 $ \Delta $mAP $ \Delta \mathrm{t} $op-1 OIM_1GAP 84.7 85.3 — — OIM_1GMP 85.0 85.4 0.3 0.1 OIM_1GKMP 85.5 85.7 0.8 0.4 OIM_2pool 85.9 86.2 1.2 0.9 -
[1] 刘皓. 基于深度学习的行人再识别问题研究[D]. 合肥: 合肥工业大学, 2017. LIU Hao. Research on problems of person re-identification based on deep learning[D]. Hefei: Hefei University of Technology, 2017. [2] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031 [3] XIAO Tong, LI Shuang, WANG Bochao, et al. Joint detection and identification feature learning for person search[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA, 2017: 3376−3385. [4] HANSELMANN H, NEY H. ELoPE: fine-grained visual classification with efficient localization, pooling and embedding[C]//Proceedings of 2020 IEEE Winter Conference on Applications of Computer Vision. Snowmass, USA, 2020: 1236−1245. [5] XIAO Jimin, XIE Yanchun, TILLO T, et al. IAN: the individual aggregation network for person search[J]. Pattern recognition, 2019, 87: 332–340. [6] YAN Yichao, ZHANG Qiang, NI Bingbing, et al. Learning context graph for person search[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA, 2019: 2153−2162. [7] DONG Wenkai, ZHANG Zhaoxiang, SONG Chunfeng, et al. Bi-directional interaction network for person search[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA, 2020: 2836−2845. [8] MUNJAL B, AMIN S, TOMBARI F, et al. Query-guided end-to-end person search[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA, 2019: 811−820. [9] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA, 2016: 770−778. [10] CHEN Di, ZHANG Shanshan, OUYANG Wanli, et al. Person search via a mask-guided two-stream CNN model[C]//Proceedings of the 15th European Conference on Computer Vision. Munich, Germany, 2018: 764−781. [11] ZHENG Liang, ZHANG Hengheng, SUN Shaoyan, et al. Person re-identification in the wild[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA, 2017: 3346−3355. [12] LAN Xu, ZHU Xiatian, GONG Shaogang. Person search by multi-scale matching[C]//Proceedings of the 15th European Conference on Computer Vision. Munich, Germany, 2018: 553−569. [13] HOSANG J, BENENSON R, SCHIELE B. Learning non-maximum suppression[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA, 2017: 6469−6477. [14] HE Kaiming, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy, 2017: 2980−2988. [15] DENG Jia, WEI Dong, RICHARD Socher, et al. ImageNet: A large-scale hierarchical image database[C]// Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. Florida, USA, 2009:248−255.






















































