
Knowledge distillation method for fetal ultrasound section identification
-
摘要: 胎儿超声切面识别是产前超声检查的主要任务之一,直接影响了产前超声检查的质量。近年来,深度神经网络方法在临床超声辅助诊断方面取得了许多进展。然而,已有研究大多应用预训练模型微调进行迁移学习,这不仅容易导致参数冗余和过拟合问题,而且限制了在实际应用中的实时分析能力。本文提出用于胎儿超声切面识别的知识蒸馏方法。第1阶段,在学生教师网络模型中采用残差网络,对二者隐藏层特征融入注意力机制,提取隐藏层关键信息,进行一次知识迁移,使学生网络获得先验权重;第2阶段,使用教师网络模型指导学生网络模型进行知识蒸馏训练,进一步从整体上提升知识迁移的性能。实验结果表明:学生网络在提升各项性能的同时,降低了模型复杂度,有利于超声设备终端的部署和实时分析能力的提升。Abstract: Fetal ultrasound section recognition is one of the main tasks of prenatal ultrasonography, which directly affects the quality of prenatal ultrasonography. In recent years, by the Deep Neural Network method, we have made great advances in clinical ultrasound-assisted diagnosis. However, most of the existing studies have applied fine-tuned pre-trained model for migration learning, which not only easily leads to parameter redundancy and overfitting problems, but also limits the real-time analysis capability in practical applications. Therefore, this paper proposes a knowledge distillation method for fetal ultrasound section recognition. In the first stage, a residual network is used in the student and teacher network model to incorporate attention mechanisms for both hidden layer features, extract key information in the hidden layer, and perform one knowledge migration so that the student network can obtain a priori weight. In the second stage, the teacher network model is used to guide the student network model to perform knowledge distillation training, so as to further improve the performance of knowledge migration in an overall manner. The experimental results show that the student network reduces the model complexity while improving various performances, which is beneficial to the deployment of ultrasound device terminals and real-time analysis capability.
-
产前超声检查是监测胎儿在母体内生长情况的重要步骤,在传统产前超声检查的过程中,临床医生利用超声设备获得胎儿各个部位的二维超声标准切面,并在此基础上测量各种体征数据,以评估胎儿在母体内的发育情况,预测早产的风险。但产前超声检查用到的切面种类多、不同切面的主要结构和复杂程度都不一样,使用传统方式手动获取切面会面临很多问题,如:1)标准切面的获取难度大,对超声医生的临床经验依赖度极高;2) 因不同超声医生专业水平的差异,获取到的标准切面结果可能不同,切面图像的规范性得不到保障;3) 临床工作效率低,易使孕妇受检时间过长,引起不良反应。近年来,随着深度神经网络在医学图像分析领域的发展与应用,为解决传统方法的弊端,研究人员逐渐将深度神经网络应用到胎儿超声切面图像的自动识别任务中,辅助医生进行诊断。
Maraci等[1]采用动态纹理分析和支持向量机(SVM)算法[2]对产妇孕中期的超声检查视频的每帧图像进行标准切面识别。SVM算法是一种利用高维映射来解决机器学习中线性不可分问题的算法,但在数据量过大时,其鲁棒性和准确率无法得到保证,所以SVM算法的性能是有限的。随着大数据和深度神经网络的发展,各种深度神经网络方法被应用在胎儿超声切面图像识别任务中。Baumgartner等[3]首次提出了基于图像级别标签的弱监督方法,使用卷积神经网络对胎儿标准切面图像进行实时自动检测,其F1评价指标达到了0.791 8,且在回溯帧检索中的准确率达到了90.09%。Maraci等[4]使用条件随机场模型从超声检查视频的每一帧图像对胎儿心脏切面进行检测。条件随机场模型[5]是一种判别式模型,在观测序列的基础上对目标序列进行建模,可以通过超声视频的每一帧及其前后帧所提供的序列化信息来检测胎儿心脏切面,但此方法在训练时的收敛速度极慢。Ryou等[6]提出了一种基于随机森林的矢状面胎儿全域定位方法,利用卷积神经网络对胎儿头部、身体和非胎儿切面进行识别。Cheng等[7]用基于卷积神经网络的迁移学习模型对胎儿腹部二维超声切面进行识别,分别使用两个卷积神经网络CaffeNet[8]、VGGNet[9]进行对比实验,基于CaffeNet的迁移学习模型达到了平均77.3%的准确率,基于VGGNet的迁移学习模型达到了77.9%的准确率。
近年来,越来越多的研究人员将深度神经网络应用于临床辅诊任务中。随着计算机硬件设备的不断发展,在图形处理器(GPU)上训练各种深度神经网络已不是一件难事。但庞大神经网络模型在训练过程中的计算资源占用量是巨大的,不可避免地耗费大量时间开销对输入数据进行处理,极大限制了实际应用时的运行效率。同时,在目前的研究和应用中,多使用预训练模型针对不同任务进行微调,该方式极易造成参数冗余的问题,增加不必要的时间开销,难以提高实时分析能力;且在实际部署时,深度神经网络模型占用大量内存,对终端设备的计算资源需求高。
针对以上问题,本文提出改进的两阶段知识蒸馏方法,在保留分类性能的同时提升模型的实时分析能力。首先,根据胎儿超声切面图像的特征,调研和使用几种主流分类模型进行实验,综合考量其计算资源占用量和分类性能,选择Resnet8和Resnet101分别作为学生网络和教师网络。再者,通过第1阶段,使用预训练好的教师网络的隐藏层信息初始化学生网络的中间层,将Resnet101模型的隐藏层输出作为Resnet8模型中间层训练的标签信息,使学生网络的中间层获得初始化的先验权重;最后,通过第2阶段进行知识蒸馏,将教师网络的负样本标签蕴含的软标签信息“蒸馏”,作为此阶段训练的监督信息。通过以上方法得到的学生网络模型,在分类性能的各项指标上超过教师网络模型,且其计算资源占用量大幅降低,模型被有效压缩,加快了实际应用时的分析速度。
1. 胎儿超声切面分类与网络压缩
1.1 胎儿超声切面分类
针对医学超声图像分类任务的特点,分别选取MobileNetV2、MobileNetV3small、Resnet8、VGG16、Resnet34和Resnet101模型。前3个模型属于轻量级模型,适合从中选择合适的学生网络;后3个模型参数数量较多,适合作为教师网络的选项,其参数量对比如表1所示。由表1可得,前3个模型与后3个模型相比,参数数量更少,具有更轻量级的特征。基于此,设计对比实验从前3个模型中选择合适的学生网络,从后3个模型中选择合适的教师网络。MobileNetV1是Andrew等[10]提出的一种神经网络结构,利用深度可分离卷积减少了参数数量,从而降低计算量,提高计算效率。这种神经网络模型适合部署到移动端或嵌入式系统中,但其不足之处在于该网络是一种较简单的单通道结构,在任务中的准确率等性能表现往往不能达到预期目标。随着ResNet和DenseNet等网络的提出,研究人员验证了卷积层输出的复用对提升网络性能的有效性,MobileNetV2[11]应运而生,引入具有线性瓶颈的逆残差结构模块,一定程度改善了原有MobileNetV1模型的不足。MobileNetV3[12]是该系列的最新版本,包含MobileNetV3Small和MobileNetV3Large两种模型,结合自动机器学习技术以及人工微调构建了更轻量级的模型。本文所述的Resnet8模型是对Resnet18模型进行改造而形成的层数和参数数量更少的轻量级模型,由7层卷积层与1层全连接层构成。由表1可知,在评价计算资源占用量指标的参数数量上,Resnet8模型比其他两个轻量级模型具有一定优势。
表 1 不同分类模型参数量对比Table 1 Parameter comparison of different models模型名称 网络深度 参数数
量/106模型文件
大小/MBMobileNetV2 54 2.25 9.27 MobileNetV3small 49 1.24 5.12 Resnet8 8 1.00 4.02 VGG16 16 134.39 537 Resnet34 34 21.33 85.5 Resnet101 101 43.09 173 1.2 知识蒸馏方法
近年来,随着大数据和深度神经网络的不断发展,在强大的GPU上训练各种复杂的神经网络模型已不是一件难事。但在实际部署时,因用户端终端设备的运算能力有限,使得复杂模型的部署变得困难;在实际应用方面,深度神经网络需要巨大的时间开销对输入数据进行处理,极大限制了实时分析能力。基于此,研究人员逐渐将目光放在模型压缩领域的各项研究上来。知识蒸馏作为模型压缩的一大分支,也不断取得各项进展。Bucilua等[13]首次提出模型压缩的概念,这种方法能将有效信息从深度神经网络模型转移到训练浅层模型,而不会显著降低原有模型的精度。Romero等[14]提出FitNet,不仅利用教师网络最后一层神经元的输出信息,还利用了其中间层信息,成功训练了较原有教师网络更深但更窄的学生网络。Hinton等[15]正式将这种学习模式定义为“知识蒸馏”,并提出了带温度系数T的Softmax函数。通过此函数将教师网络的负样本信息输出的概率分布“蒸馏”出来,以对学生网络的训练提供额外的监督信息。他们在MNIST数据集上进行初步试验,证明了带温度系数T的Softmax函数对深度神经网络模型精度提高的有效性;并分别在语音数据集和大型数据集JFT上进行对比实验,证明了知识蒸馏对模型精度提高和模型压缩的有效性。受课程学习(curriculum learning)的启发,Jin等[16] 发现由学生网络和教师网络间的结构差异而造成蒸馏失败的问题,并针对此提出了路由约束提示学习方法。2019年Phuong等 [17]从理论上论述了知识蒸馏中学生网络具有快速收敛的泛化边界的原因,解释了知识蒸馏的工作原理。2020年Ji等[18]分别从风险界、数据效率和不完美的老师3个角度进一步对广义神经网络上的知识蒸馏方法进行了理论解释。目前的知识蒸馏方法已扩展到师生学习[14]、相互学习[19]、辅助教学[20]、终身学习[21]和自主学习[22]等模式。通过知识蒸馏训练后的学生网络,能保留甚至超过教师网络的性能,网络结构比教师网络更简单,减少了冗余参数,能有效提高实时分析性能,缓解终端部署和实际应用的困难。
虽然现有知识蒸馏方法已经取得了良好的效果,但也具有一定局限性。神经网络的隐藏层特征表达往往蕴含了丰富的有用信息,现有方法仅依托于神经网络最后一层神经元输出信息,提供的监督信息是有限的。考虑到隐藏层特征表达和映射对深度神经网络模型的影响,在传统知识蒸馏方法中融入隐藏层的特征表达,将在一定程度上为学生网络提供更丰富的监督信息。首先,在第1阶段,通过对学生网络预先进行训练,使其学到教师网络隐藏层丰富的特征表达,获得优于原始学生网络中间层的权重信息;第2阶段,对已学习到教师网络隐藏层特征表达的学生网络进行知识蒸馏。同时,考虑到在教师网络训练时会产生很多中间模型(anchor points[16] ),应使用结构相似的神经网络模型作为学生网络,以便于学生网络从其中间模型更好地进行特征学习,从而提升知识蒸馏的效率。基于此,本文使用师生学习模式,提出改进的两阶段知识蒸馏方法。
1.2.1 知识蒸馏方法
众所周知,基于深度神经网络的分类任务都具有共同的特征:神经网络最后一层神经元的输出信息都会通过一个Softmax函数,如式(1)所示,将输出信息变成概率分布,才能与标签信息求其极大似然值,此种经过Softmax层直接输出的信息被称为硬标签信息。
$$ {{q}}_{{i}}=\dfrac{{\rm{exp}}\left({{z}}_{{i}}\right)}{{\displaystyle\sum }_{\text{j}}{\rm{exp}}\left({{z}}_{{j}}\right)} $$ (1) 式中:
$q_i $ 是教师网络输出每一类的概率分布;$z_i $ 是最后一层的神经元的输出信息。但由于Softmax函数只输出概率分布的独热编码,会均一化所有负样本标签的信息,将负样本标签的概率都还原为0,弱化了负样本标签的概率信息对模型训练的影响。对此,Hinton等[15]提出带温度系数T的Softmax函数,如式(2)所示,此种经过温度系数T的输出信息被称为软标签信息。最后一层神经元的输出信息通过带温度系数T的Softmax函数后,能“蒸馏”出负样本标签的概率信息,为学生网络的训练提供更为丰富的“暗知识”,使学生网络不只接受正样本标签的监督训练。
$$ {{q}}_{{i}}=\dfrac{{\rm{exp}}\left(\dfrac{{{z}}_{{i}}}{{T}}\right)}{{\displaystyle\sum }_{\text{j}}{\rm{exp}}\left(\dfrac{{{z}}_{{j}}}{{T}}\right)} $$ (2) 式中:
$q_i $ 是教师网络输出每一类的软标签;$z_i $ 是最后一层的神经元的输出信息;T为温度系数。根据不同的温度蒸馏出的知识占比不同,需进行对比实验选出最适合的温度系数T。实验数据图片在不同温度系数 T 下的预测概率如图1所示。 图 1 不同温度系数T下的概率分布Fig. 1 Probability distribution with different parameter T
图 1 不同温度系数T下的概率分布Fig. 1 Probability distribution with different parameter T 下载:
全尺寸图片
下载:
全尺寸图片
知识蒸馏方法基于软标签信息,在给定教师网络的条件下,使用教师网络最后一层神经元的输出信息经过带温度系数T的Softmax函数,将其预测的所有类别的概率分布“蒸馏”,作为知识蒸馏的监督信息,指导学生网络进行训练。此方法为学生网络的训练提供了来自教师网络的先验知识,本质上是在学生网络的训练中加入一种新的正则化机制。具体流程图如图2所示。
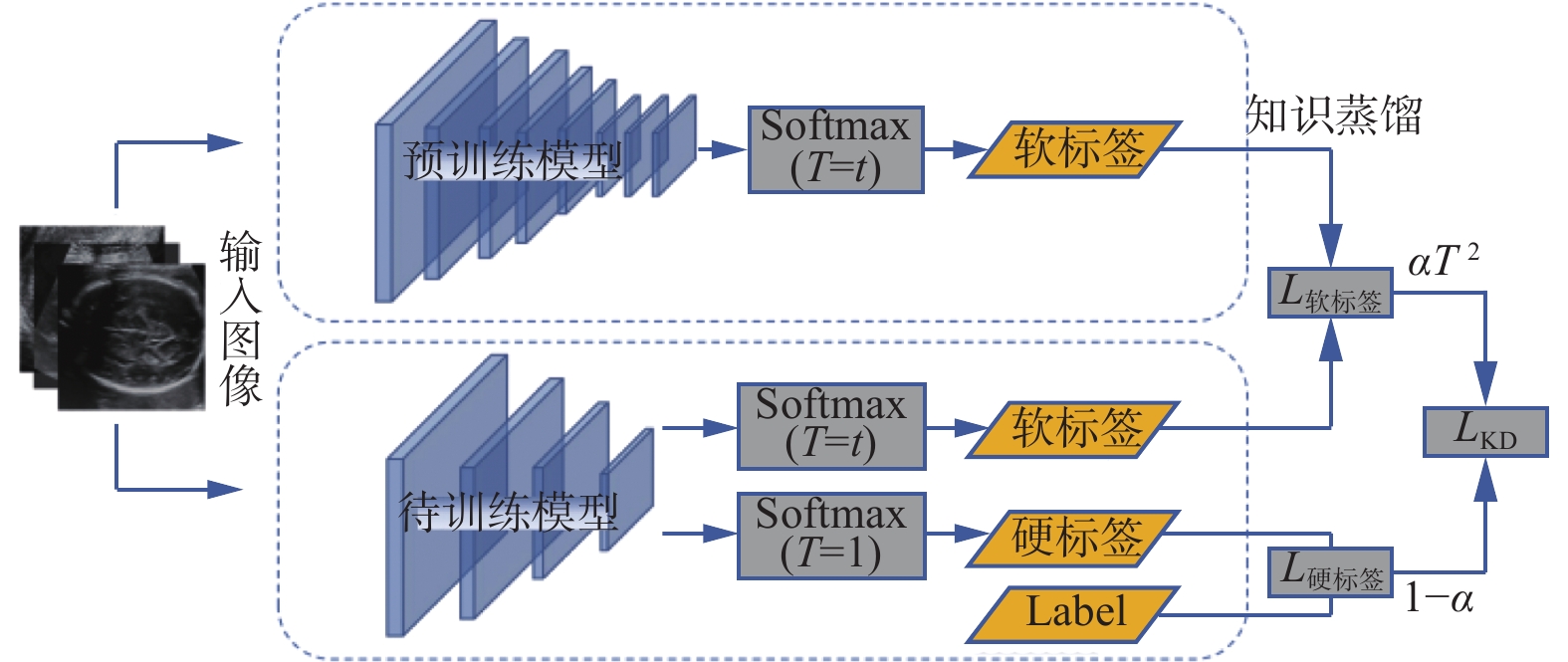 图 2 知识蒸馏网络结构Fig. 2 Network structure of knowledge distillation下载:
全尺寸图片
图 2 知识蒸馏网络结构Fig. 2 Network structure of knowledge distillation下载:
全尺寸图片
最终损失函数表达式为
$${L_{\rm KD}}\left( {{{\boldsymbol{W}}_s}} \right) = \alpha {T^2}\varphi \left( {{\boldsymbol{W}}_s^{\rm{T}},{\boldsymbol{W}}_t^{\rm{T}}} \right) + \left( {1 - \alpha } \right)\psi \left( {{{\boldsymbol{W}}_s},{\boldsymbol{Y}}_{\rm label}} \right)$$ (3) 式中:
$ \alpha $ 为蒸馏强度;T为温度系数;$\varphi $ 为KL散度;${\boldsymbol{W}}_s^{\rm{T}}$ 为学生网络经过带温度系数T的Softmax层的权重矩阵;${\boldsymbol{W}}_t^{\rm{T}} $ 为教师网络的权重矩阵;$\psi $ 为交叉熵;${\boldsymbol{W}}_s $ 为学生网络的硬标签信息;${\boldsymbol{Y}}_{\rm label} $ 为输入图像的标签信息。1.2.2 改进的两阶段知识蒸馏方法
在第1阶段,旨在提取教师网络隐藏层的特征表达,将其作为此阶段训练的监督信息,以此来指导学生网络的中间层权重的初始化,使其学习到教师网络的隐藏层特征表达。第1阶段流程如图3所示。
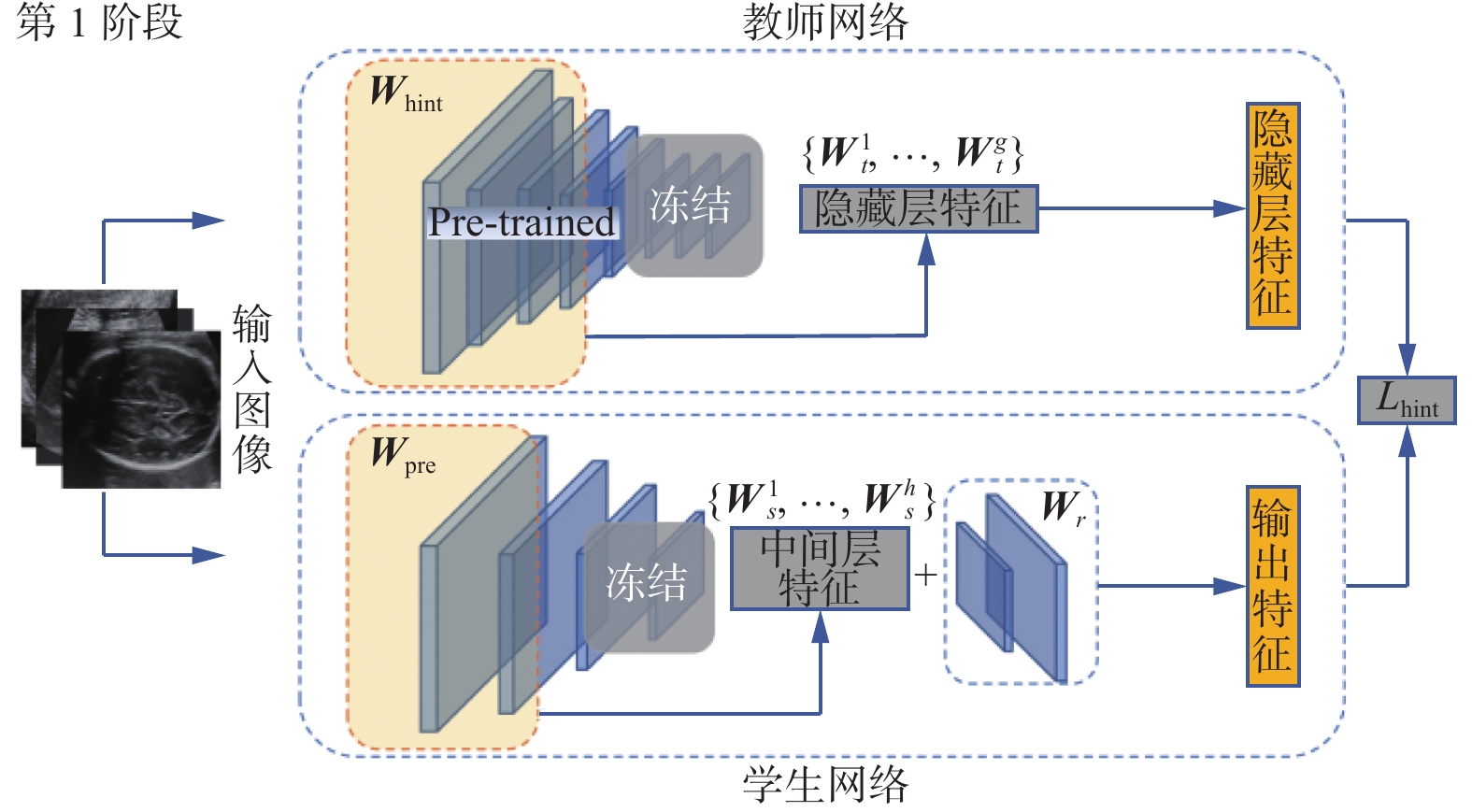 图 3 第1阶段网络结构Fig. 3 Network structure of the first stage下载:
全尺寸图片
图 3 第1阶段网络结构Fig. 3 Network structure of the first stage下载:
全尺寸图片
为获得基于教师网络隐藏层特征表达的学生网络,
${\boldsymbol{W}}_s $ 需冻结学生网络的最后一层残差连接层、池化层以及全连接层,仅训练学生网络的第一层至中间层h的权重矩阵。训练集$D=\{(x_1,y_1), $ $ (x_2,y_2),\cdots,(x_i,y_i)\}$ ,其中,$x_i \in x \subset {\bf{R}}^{s \times s \times c}$ 即通道数为c的输入大小为$s \times s $ 的图像数据,$y_i \in (0,5) $ 即输入的图像数据的标签信息,在本文中代表属于编号为0~5的6类标签;${\boldsymbol{W}}_{\rm pre}=\{{\boldsymbol{W}}^1_s,{\boldsymbol{W}}^2_s,\cdots,{\boldsymbol{W}}^h_s\}$ 即教师网络隐藏层前g层的特征表达;${\boldsymbol{W}}_{\rm pre}=\{{\boldsymbol{W}}^1_s,{\boldsymbol{W}}^2_s,\cdots, {\boldsymbol{W}}^h_s\}$ 即学生网络中间前h层的特征表达。为解决教师网络前g层输出特征与学生网络前h层输出特征表达的维度不匹配问题,加入随机初始化权重的卷积回归层。最终通过最小化损失函数来优化和卷积回归层,其表达式为$$ {L_{\rm hint}}\left( {{{\boldsymbol{W}}_{\rm pre}},{{\boldsymbol{W}}_r}} \right) = \frac{1}{2}\left\| {\mu \left( {x;{{\boldsymbol{W}}_{\rm hint}}} \right)}- r\left( {\upsilon \left( {x;{{\boldsymbol{W}}_{\rm pre}}} \right);{{\boldsymbol{W}}_r}} \right)\right\|^2$$ (4) 式中:
$\mu $ 为教师网络隐藏层函数;$\upsilon $ 为学生网络中间层函数;r为卷积回归函数。为保证教师网络隐藏层输出特征和学生网络卷积回归层输出特征维度一致,$ \mu $ 函数和r函数应具有相同的非线性性质。经过第1阶段训练的学生网络模型已经具有基于教师网络隐藏层特征表达的中间层权重信息,类比教师教授学生知识的环节,相当于学生已经在教师布置的预习任务中获得了一定量的知识储备,为接下来的教师教学打下基础,即为第2阶段的知识蒸馏训练做铺垫。在第2阶段,使用知识蒸馏方法再次对学生网络进行训练,通过最小化损失函数去优化学生网络模型,不断迭代,直至其损失函数值收敛。
1.2.3 学生网络和教师网络结构
综合各种分类模型在胎儿超声切面数据集上的性能,考虑到分类性能与计算资源占用量之间的平衡,将Resnet8作为学生网络模型,其层数浅、参数量少,具体参数如表2所示;将ResNet101作为教师网络模型,其层数深、参数量大,具体参数如表3所示。二者都具有良好的分类性能,且二者具有相同的残差结构,可以方便学生网络学习教师网络的特征表达。
表 2 学生模型网络参数Table 2 Network parameters of student module层名 卷积核尺寸及个数 步长 填充 Conv1 3×3,16 1 1 Layer1 3×3,16 1 1 3×3,16 1 Layer2 3×3,32 2 1 3×3,32 1 Layer3 3×3,64 2 1 3×3,64 1 Avgpool 8×8 1 0 Fc — — — Softmax — — — 表 3 教师模型网络参数Table 3 Network parameters of teacher module层名 卷积核尺寸及个数 步长 填充 Conv1 3×3 1 1 Layer1 ${3}\times\left\{\begin{aligned}&1\times{1,64}\\ &{3}\times{3,64}\\&{1}\times{1,256}\end{aligned}\right.$ 1 1 Layer2 ${4}\times\left\{\begin{aligned}&1\times{1,128}\\&{3}\times{3,128}\\&{1}\times{1,512}\end{aligned}\right.$ 1 1 Layer3 ${23} \times \left\{\begin{aligned}&{1} \times {1,256}\\&{3} \times {3,256}\\&{1} \times {1,102\;4}\end{aligned}\right.$ 1 1 Layer4 ${3} \times \left\{\begin{aligned}&{1} \times {1,512}\\ &{3} \times {3,512}\\&{1} \times {1,248}\end{aligned}\right.$ 1 1 Avgpool 8×8 1 0 Fc — — — Softmax — — — 2. 实验设计
2.1 实验平台
本实验在GPU深度神经网络集成计算平台上进行,操作平台为Ubuntu,使用的GPU为Nvidia GeForce RTX 3090Ti,显存为24 GB,使用的深度神经网络框架为PyTorch。
2.2 实验准备
实验采用的数据是胎儿超声切面数据集,由BCNatal收集,涵盖了来自两个医学中心共计12 400张胎儿超声切面图像,图像格式为PNG,均做了匿名处理。此数据集包含了6类切面类型,各类型切面图像概览如图4所示。胎儿超声切面图像作为产前检查的重要依据,均由专业的超声科阅片医师进行手动标注,每类切面的临床意义其数据分布情况如表4所示,其中“其他类型”的存在可以提高模型对于不同类别在有干扰情况下的准确率。
 图 4 胎儿超声切面概览Fig. 4 Examples of fetal ultrasound section images下载:
全尺寸图片
表 4 数据集分布情况Table 4 Component distribution of datasets
图 4 胎儿超声切面概览Fig. 4 Examples of fetal ultrasound section images下载:
全尺寸图片
表 4 数据集分布情况Table 4 Component distribution of datasets切面类型 临床用途 图像数量 胎儿腹部 胎儿形态学特征 711 胎儿头部 检测胎儿神经发育情况 3 092 胎儿股骨 估算胎儿体重 1 040 胎儿胸腔 检测胎儿心脏和肺部发育情况 1 718 母体宫颈 预测早产风险 1 626 其他类型 4 213 总计 12 400 本实验将此数据集划分为训练集和测试集,其比例约为4∶1,具体分布情况如表5所示。为满足不同分类模型对输入图像大小的限制,预先将图像进行了拉伸缩放的预处理方式,将其调整为像素尺寸。同时,为了提高彩超图像在基于ImageNet预训练模型上的泛化能力,对原始超声图像进行归一化等预处理。
表 5 实验数据集分布情况Table 5 Experimental component distribution of datasets数据
类型胎儿
腹部胎儿
头部胎儿
股骨胎儿
胸腔胎儿
宫颈其他
类型总计 训练集 569 2 474 832 1 374 1 301 3 370 9 920 测试集 142 618 208 344 325 843 2 480 总计 711 3 092 1 040 1 718 1 626 4 213 12 400 2.3 实验步骤
2.3.1 胎儿超声切面分类实验
针对本文所述的胎儿超声切面分类任务的特点,使用不同深度神经网络分类模型进行实验,并评估各种模型在胎儿超声切面数据集上的准确率及其损失函数值。在MobileNetV2、MobileNetV3Small、Resnet8、VGG16、Resnet34、Resnet101模型上进行分类实验。此阶段的学习率为1×10−6,并设置Warmup机制,首先使用较大的学习率进行训练,然后逐渐逼近实验设置的学习率;本实验中的损失函数使用交叉熵函数,优化方法采用自适应梯度下降法(adam)算法,此方法较随机梯度下降(SGD)算法能取得更优的效果。
2.3.2 改进的两阶段知识蒸馏实验
本方法对现有知识蒸馏方法进行改进,先进行第1阶段训练,将教师网络隐藏层的输出信息作为监督信息,将其迁移到学生网络的中间层,使学生网络的中间层获得教师网络的隐藏层特征表达作为监督信息训练的初始权重。在第2阶段,使用知识蒸馏方法对既得学生网络模型进行二次训练,整体训练流程为
1) 将实验所用数据集进行预处理和数据集划分,分别用于训练和测试;
2) 将训练集输入Resnet101模型,训练教师网络,使用测试集测试其分类性能,并保存性能最好的Resnet101模型作为教师网络;
3) 固定教师网络模型参数,将其隐藏层的输出信息作为学生网络中间层知识迁移的监督信息;
4) 冻结学生网络的最后3层参数,即全连接层、最后池化层、和最后一层残差网络层。为解决教师网络中间层输出特征和学生网络中间层输出特征维度不一致的问题,需在学生网络中间层的最后添加一个卷积回归层。
5) 在第1阶段,将训练集输入学生网络,使用步骤3)获得的教师网络隐藏层特征表达作为监督信息,训练学生网络中间层
$W_{\rm pre}$ 和$W_r $ 。使用$L_{\rm hint}$ 作为损失函数,通过反向传播算法不断迭代优化式(4),最小化其损失函数值,直到收敛。保存此阶段训练的学生网络模型。6) 用知识蒸馏方法对步骤5)获得的学生网络模型进行二次训练。将学生网络直接训练的输出作为硬标签信息,结合教师网络最后一层神经元的输出经过带温度系数T的Softmax层后的软标签信息,将二者加权求和作为监督信息,最小化
$ L_{\rm KD}$ 来优化学生网络的权重参数。通过反向传播算法迭代式(3),最小化损失值,直到收敛。同时计算各种性能指标,保存性能最佳的学生网络模型。7) 用训练好的学生网络模型进行预测,测试其各项性能指标。
2.4 评价指标
针对本任务,使用多个评价指标,即准确率(Acc)、宏精确率(MacroPre)、宏召回率(MacroRecall)、宏F1-score值(MacroF1)和前向传播时的计算力(FLOPs)。Acc即预测正确的样本类别占总样本的比例,体现了模型的预测能力。精确率在二分类中即正确预测为该类别的占全部预测为该类别的比例,在多分类中,对每个标签分别计算其精确率,再对其取算数平均(Macro),得到MacroPre;召回率在二分类中即正确预测为该类别的样本数占全部实际为该样本的比例,在多分类中,对每个标签分别计算其召回率,再对其取算数平均,得到MacroRecall;F1值在二分类中,即对精确率和召回率的评估,在多分类中,对于每个标签,分别计算其F1值,然后对其取算数平均,得到 MacroF1。以上参数数值越大,分类模型的性能越好。FLOPs(fLoating point operations),即浮点运算数,衡量模型复杂度,体现了模型的运算能力。
分别计算每一类的Prei、Recalli、F1的公式为
$$ \text{Pr}{\text{e}}_{{i}}\text=\frac{\text{T}{\text{P}}_{{i}}}{\text{T}{\text{P}}_{{i}}\text{+F}{\text{P}}_{{i}}} $$ $$ \text{Recal}{\text{l}}_{{i}}\text=\frac{\text{T}{\text{P}}_{{i}}}{\text{T}{\text{P}}_{{i}}\text{+F}{\text{N}}_{{i}}} $$ $${{F}_{1_i}}\text=\frac{\text{2}\times {\text{Pre}}_{{i}}\times \text{Recal}{\text{l}}_{{i}}}{{\text{Pre}}_{{i}}\text{+Recal}{\text{l}}_{{i}}} $$ 对既得的每一类的Pre和Recall以及F1,再使用Macro算法。先分别求出每个类别对应的值,再对其求算数平均值:
$$ 宏精确率: \text{MacroPre=}\frac{{1}}{{N}}\sum _{{i=1}}^{{N}}\text{Pr}{\text{e}}_{{i}} $$ $$ 宏召回率: \text{MacroRecall=}\frac{{1}}{{N}}\sum _{{i=1}}^{{N}}\text{Recal}{\text{l}}_{{i}} $$ $$ 宏{\rm F_1}值: \text{MacroF1=}\frac{{1}}{{N}}\sum _{{i=1}}^{{N}}{{F}_{1_i}} $$ Acc可计算为
$$ \text{Acc=}\frac{{\text{TP}}_{{i}}+\text{T}{\text{N}}_{{i}}}{\text{T}{\text{P}}_{{i}}+\text{T}{\text{N}}_{{i}}+\text{F}{\text{P}}_{{i}}+\text{F}{\text{N}}_{{i}}} $$ 式中:TPi、TNi、FPi、FNi分别代表第i类别的正阳性、正阴性、假阳性和假阴性。
卷积核 FLOPs 的计算为
$$ \text{FLO}{\text{P}}_{{s}}{=2\;{{HW}}}\left({{C}}_{{in}}{{K}}^{{2}}{+1}\right){{C}}_{\text{out}} $$ 式中:H、W 和Cin分别是输入特征图的高度、宽度和通道数; K是卷积核宽度 (假定卷积核长宽相等), Cout是输出通道数。全连接层 FLOPs 的计算为
$$ \text{FLO}{\text{P}}_{{s}}=\left({2I-1}\right){O} $$ 式中:I 是输入维数;O是输出维数。
在本文中,为了凸显本方法的有效性,还关注各个模型的网络深度、显存占用量、GPU占用率、损失值、模型文件大小等性能指标。
3. 实验结果与分析
3.1 胎儿超声切面分类实验
使用不同的分类模型,在相同的训练集和验证集上进行对比训练,从其计算资源占用情况、准确率和损失值来衡量其分类性能。其中损失值为交叉熵函数的输出,体现了分类模型的预测值和真实值之间的概率分布情况,本实验中选用损失值低于0.1的指标作为分类器取得了好的效果的基准,具体情况如表6所示。
表 6 各神经网络模型性能对比Table 6 Experimental results with different neural network methods模型名称 Acc/% 显存占用量/MB GPU占用率/% MFLOPs 损失值 模型文件大小/MB MobileNetV2 93.27 1384 21 2420 0.0651 9.27 MobileNetV3small 89.35 116 8 64 0.0939 5.12 Resnet8 92.22 172 9 624 0.0932 4.02 VGG16 94.52 2630 39 15530 0.0898 537 Resnet34 93.15 1970 27 56940 0.0757 85.5 Resnet101 97.50 12656 51 123570 0.0786 173 由表6可知,在准确率性能的表现上,Resnet101模型较VGG16模型提升了2.98%个百分点,较Resnet34模型提升了4.35%,较Resnet8模型提升了5.28%,取得了最优的准确率性能表现。在计算资源占用量方面,Resnet101模型的网络深度是Resnet8模型的近12倍,相比其他两个较大的模型也增加了近3~5倍,训练时的显存占用量和GPU占用率和FLOPs也是最高的。综上所述,充分表明Resnet101模型具有最好的分类性能的同时,其计算资源占用量也最庞大,适合作为教师网络进行后续实验,以验证知识蒸馏方法能否在保留其分类性能的情况下将模型压缩,并达到提升实时性分析能力的目的。
在学生网络的选择方面,应考虑模型本身的参数数量和计算资源占用情况,尽量减少冗余参数;同时,学生网络本身的分类准确率也是重要指标之一,不能为了压缩模型的大小,使得分类性能得不到保证。由表6可得,轻量级模型MobileNetV2、MobileNetV3Small和Resnet8模型都具有较好的基本分类性能,但MobileNetSmall在准确率上的表现却不如其他两个模型。对比MobileNetV2和Resnet8的各项性能指标,虽然前者在准确率性能指标上超过后者1.05%,但其显存占用量是后者的近8倍,在GPU占用率和FLOPs等性能上也处于劣势。Resnet8模型有较好的分类性能,其在训练时的计算资源占用量是更轻量级的,最终得到的模型文件大小较前两者也是最小的。基于此,本文综合考虑准确率和计算资源占用量,同时假设与教师网络模型具有相同残差结构的Resnet8模型,能更好地学习到以Resnet101网络特征表达作为监督信息的“知识”,选用Resnet8模型作为学生网络,如表7所示。
综上所述,Resnet101模型在胎儿超声切面分类任务中具有最优异的分类性能,较Resnet8模型具有5.28%的准确率指标提升。综合各种分类模型在胎儿超声切面数据集上的性能,考虑到分类性能与计算资源占用量之间的平衡,将Resnet8作为学生网络,将ResNet101作为教师网络,此二者都具有良好的分类性能,且具有相同的残差结构,可以方便学生网络学习教师网络的隐藏层特征表达,提高泛化能力。学生网络模型和教师网络模型在训练时的资源占用情况对比如表8。
表 7 学生网络和教师网络计算资源占用Table 7 Occupation of computational resource of student and teacher models模型名称 参数
量/106显存占用
量/MBGPU占
用率/%MFLOPs 模型文件
大小/MBResnet8 1.00 172 9 624 4.02 Resnet101 43.09 12 656 51 123 570 173 表 8 不同温度系数T的性能对比Table 8 Experimental results with different parameter T温度系数T 准确率/% 宏精确率/% 宏召回率/% 宏F1值 5 97.38 97.85 96.34 0.970 3 10 96.05 94.83 95.98 0.953 8 20 95.60 94.39 95.20 0.947 8 30 95.56 94.42 95.06 0.947 2 40 95.48 94.46 94.79 0.946 1 由表8可知,Resnet8模型较Resnet101模型的训练参数量减少了近4 210万,在训练时的显存占用和GPU使用率上也更具优势,模型文件大小也缩小近43倍,占用的计算资源不再冗余,FLOPs缩小了近198倍,提升了实际部署的可行性。
3.2 温度参数T对比实验
使用不同的温度系数T进行对比实验,选择5、10、20、30、40作为实验的温度参数T,其分类可视化混淆矩阵如图5所示。
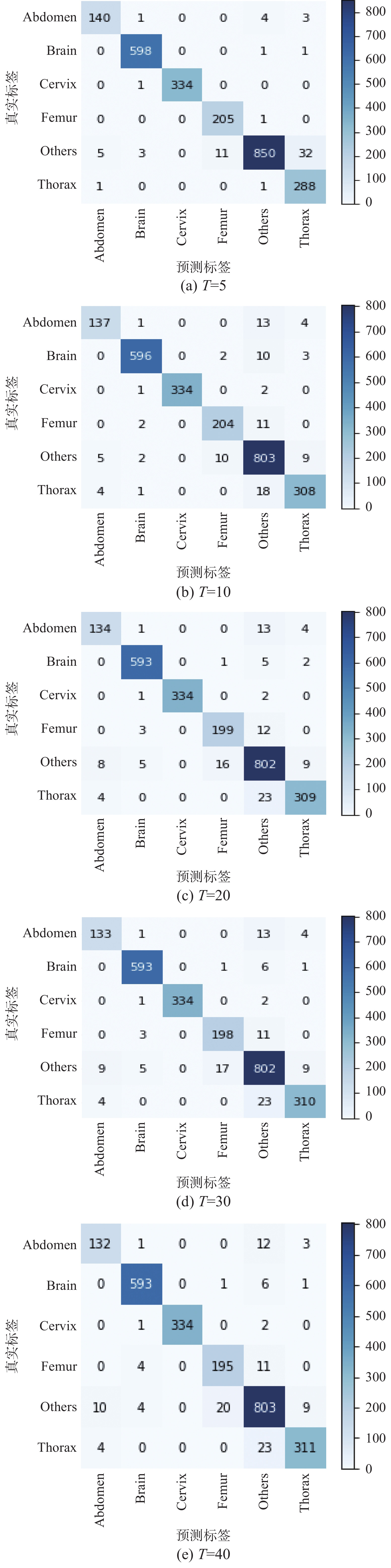 图 5 不同温度系数T的知识蒸馏分类混淆矩阵Fig. 5 Confusion matrix of knowledge distillation classification with different parameter T下载:
全尺寸图片
图 5 不同温度系数T的知识蒸馏分类混淆矩阵Fig. 5 Confusion matrix of knowledge distillation classification with different parameter T下载:
全尺寸图片
比较学生网络在不同温度系数T的训练结果,选择最合适的T作为整个实验中的温度系数T。由表9可得,当温度系数T=5时,学生网络在准确率、宏准确率、宏召回率、宏F1值等性能指标相比其他温度系数T得到的模型是最具优势的。同时,在温度系数T=5的情况下,通过现有知识蒸馏方法训练的学生网络模型与学生网络单独训练时得到的模型的性能相比,各项性能都得到了提升,较原有学生网络的准确率提升5.16%,并不断逼近教师网络模型的准确率,在宏精确率和宏F1值上都超过了教师网络模型,涨幅分别为1.19%和0.07%,且其计算资源占用量远小于原始教师网络。基于此,选择T=5作为实验中的温度参数T。
表 9 不同优化方法的性能对比Table 9 Performance comparison of different models模型名称 准确率/% 宏精确率/% 宏召回率/% 宏F1值 Resnet101 97.50 96.66 97.29 0.969 6 Resnet8 92.22 92.69 87.95 0.900 0 Resnet8+stage1 93.75 92.62 91.87 0.922 0 Resnet8+KD 97.38 97.85 96.34 0.970 3 Resnet8+Hint 98.59 98.25 98.17 0.982 1 3.3 改进的两阶段知识蒸馏方法实验
3.3.1 第1阶段有效性实验
Resnet8模型与Resnet8+stage1模型相比,前者是Resnet8模型直接训练得到的学生网络模型;而后者是经过改进的两阶段知识蒸馏方法第1阶段的Resnet8模型,再直接训练得到的学生网络模型。由图6可知,Resnet8+stage1模型在除“其他类型”切面图像外的各个分类的成功样本数较Resnet8模型增加3~20例不等。由表9可知,Resnet8+stage1模型较Resnet8模型在准确率上提升了1.53%,宏召回率提高3.92%,宏F1值提高2.2%,仅在宏精确率上降低0.07%。以上实验结果充分表明了改进的两阶段知识蒸馏方法的第1阶段训练的必要性和有效性,具有相同残差结构的学生网络在第1阶段的训练中,从教师网络的隐藏层特征表达能学习到有用的权重信息。
 图 6 混淆矩阵对比Fig. 6 Confusion matrix with different methods下载:
全尺寸图片
图 6 混淆矩阵对比Fig. 6 Confusion matrix with different methods下载:
全尺寸图片
3.3.2 第2阶段有效性实验
Resnet8+stage1模型与Resnet8+Hint模型相比,前者是经过改进的两阶段知识蒸馏方法第1阶段的Resnet8模型,再直接训练得到的学生网络模型;后者是经过改进的两阶段知识蒸馏方法的学生网络模型。由图7可知,Resnet8+Hint模型较Resnet8+stage1模型,在每个类别正确的分类样本数的最大增幅达到了27.2%(腹部类切面图像);由表9可知,Resnet8+Hint模型较Resnet8+stage1模型的各项指标性能有了大幅提升,准确率提升4.84%,宏精确率提升5.63%,宏召回率提升6.3%,宏F1值提升8.21%,以上实验结果充分表明改进的两阶段知识蒸馏方法的第2阶段训练的有效性。
 图 7 混淆矩阵对比Fig. 7 Confusion matrix with different methods下载:
全尺寸图片
图 7 混淆矩阵对比Fig. 7 Confusion matrix with different methods下载:
全尺寸图片
3.4 传统和改进的知识蒸馏方法对比
Resnet8+KD模型与Resnet8+Hint模型相比,前者是经过传统知识蒸馏方法训练得到的学生网络模型,后者是经过改进的两阶段知识蒸馏方法训练得到的学生网络模型。由图8可知,Resnet8+Hint模型的主要提升在于“胎儿股骨”和“胎儿胸腔”切面的分类结果上,而Resnet8+KD模型在这两类上的分类性能是次与前者的。由表9可知,Resnet8+Hint模型的准确率较Resnet8+KD模型提升1.21%,宏精确率提升了0.4%,宏召回率提升了1.83%,宏F1值提升了1.18%,以上各项性能指标的提升都充分证明了改进的两阶段知识蒸馏方法的有效性。
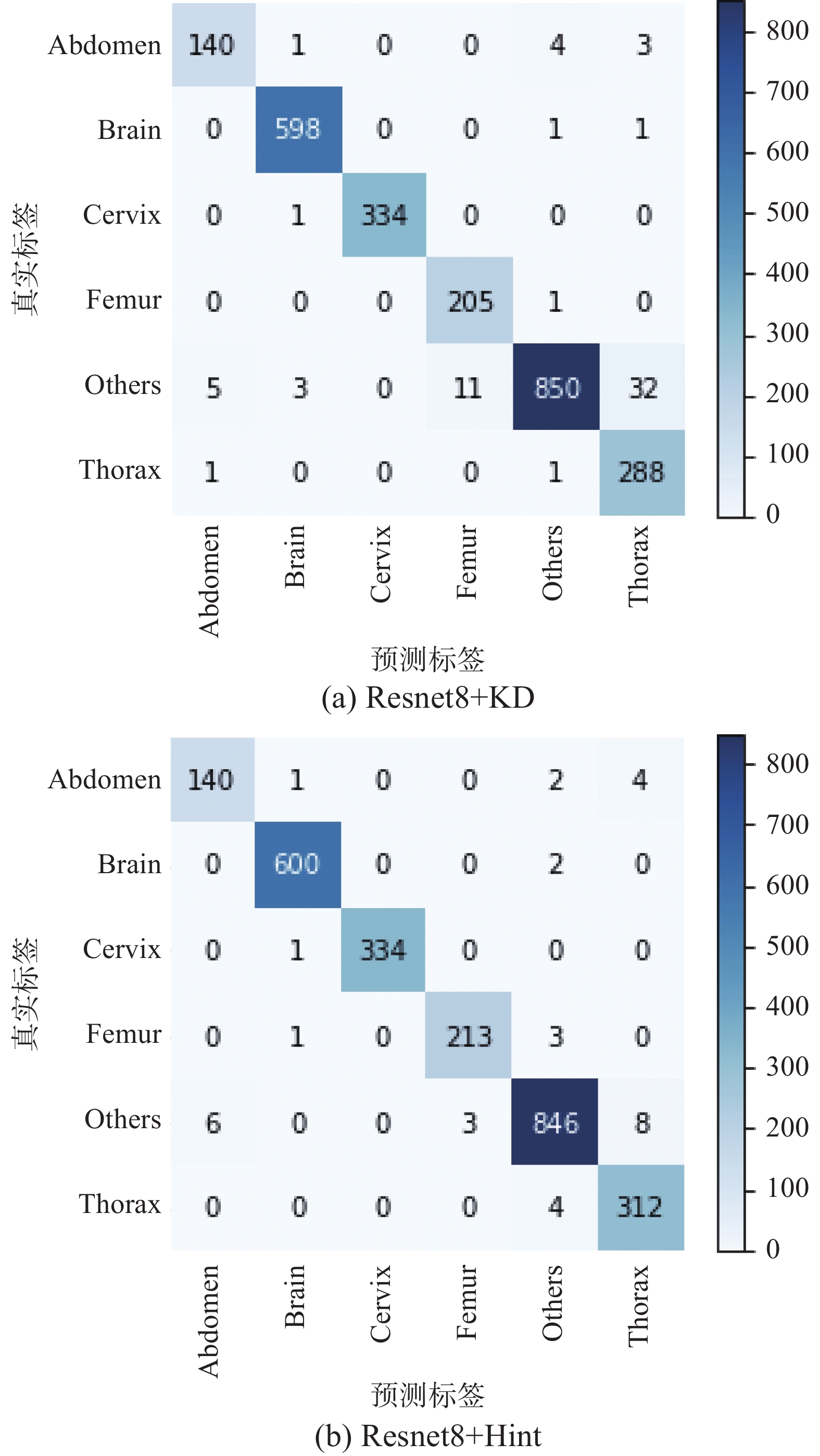 图 8 混淆矩阵对比Fig. 8 Confusion matrix with different methods下载:
全尺寸图片
图 8 混淆矩阵对比Fig. 8 Confusion matrix with different methods下载:
全尺寸图片
经过改进的两阶段知识蒸馏方法的学生网络模型在各项分类指标都取得了大幅提升,较原有学生网络模型,准确率提升6.37%,其他各项性能也得到了明显提升。较传统知识蒸馏方法训练的学生网络模型,准确率提升1.21%,且在准确率指标上超过教师网络模型1.09%。实验表明,在改进的两阶段知识蒸馏方法的第1阶段,与教师网络具有相同残差结构的学生网络能以教师网络的隐藏层特征表达作为监督信息,获得良好的中间层初始权重,为第2阶段知识蒸馏打下了良好基础。同时,使用层数浅、参数量较少的学生网络,可以有效避免模型因层数过深、参数量过大产生的过拟合问题,提升了模型的泛化能力,在保留分类性能的同时成功将模型参数量进行压缩。综上所述,充分表明了改进的两阶段知识蒸馏方法在提升学生网络模型各项性能的有效性。
4. 结束语
针对医学图像的特点,考虑到深度神经网络模型在实际应用时的实时性能,本文提出了一种用于胎儿超声切面识别的改进的两阶段知识蒸馏方法。利用两种结构相似,但计算量相差较大的残差网络,即Resnet8作为学生网络,Resnet101作为教师网络,通过现有知识蒸馏方法和改进的两阶段知识蒸馏方法在胎儿超声切面数据集上进行实验,分别达到97.38%和98.59%的准确率,后者在各项分类的性能指标上都取得了突破,由此可以得出改进的两阶段知识蒸馏方法优于现有知识蒸馏方法的结论。通过对比实验,表明改进的两阶段知识蒸馏方法的第1阶段,在具有相同残差结构的学生网络和教师网络之间进行隐藏层特征迁移的必要性和有效性。通过改进的两阶段知识蒸馏方法得到的学生网络模型Resnet8+Hint在准确率和各项性能上远超原有学生网络模型,在分类性能方面超过了教师网络模型,在计算资源占用量方面,大幅降低了对计算资源的需求,同时加快了实际应用时的分析速度,表明本文所述的改进的两阶段知识蒸馏方法的有效性。
-
图 1 不同温度系数T下的概率分布
Fig. 1 Probability distribution with different parameter T
下载:
全尺寸图片
图 2 知识蒸馏网络结构
Fig. 2 Network structure of knowledge distillation
下载:
全尺寸图片
图 3 第1阶段网络结构
Fig. 3 Network structure of the first stage
下载:
全尺寸图片
图 4 胎儿超声切面概览
Fig. 4 Examples of fetal ultrasound section images
下载:
全尺寸图片
图 5 不同温度系数T的知识蒸馏分类混淆矩阵
Fig. 5 Confusion matrix of knowledge distillation classification with different parameter T
下载:
全尺寸图片
图 6 混淆矩阵对比
Fig. 6 Confusion matrix with different methods
下载:
全尺寸图片
图 7 混淆矩阵对比
Fig. 7 Confusion matrix with different methods
下载:
全尺寸图片
图 8 混淆矩阵对比
Fig. 8 Confusion matrix with different methods
下载:
全尺寸图片
表 1 不同分类模型参数量对比
Table 1 Parameter comparison of different models
模型名称 网络深度 参数数
量/106模型文件
大小/MBMobileNetV2 54 2.25 9.27 MobileNetV3small 49 1.24 5.12 Resnet8 8 1.00 4.02 VGG16 16 134.39 537 Resnet34 34 21.33 85.5 Resnet101 101 43.09 173 表 2 学生模型网络参数
Table 2 Network parameters of student module
层名 卷积核尺寸及个数 步长 填充 Conv1 3×3,16 1 1 Layer1 3×3,16 1 1 3×3,16 1 Layer2 3×3,32 2 1 3×3,32 1 Layer3 3×3,64 2 1 3×3,64 1 Avgpool 8×8 1 0 Fc — — — Softmax — — — 表 3 教师模型网络参数
Table 3 Network parameters of teacher module
层名 卷积核尺寸及个数 步长 填充 Conv1 3×3 1 1 Layer1 ${3}\times\left\{\begin{aligned}&1\times{1,64}\\ &{3}\times{3,64}\\&{1}\times{1,256}\end{aligned}\right.$ 1 1 Layer2 ${4}\times\left\{\begin{aligned}&1\times{1,128}\\&{3}\times{3,128}\\&{1}\times{1,512}\end{aligned}\right.$ 1 1 Layer3 ${23} \times \left\{\begin{aligned}&{1} \times {1,256}\\&{3} \times {3,256}\\&{1} \times {1,102\;4}\end{aligned}\right.$ 1 1 Layer4 ${3} \times \left\{\begin{aligned}&{1} \times {1,512}\\ &{3} \times {3,512}\\&{1} \times {1,248}\end{aligned}\right.$ 1 1 Avgpool 8×8 1 0 Fc — — — Softmax — — — 表 4 数据集分布情况
Table 4 Component distribution of datasets
切面类型 临床用途 图像数量 胎儿腹部 胎儿形态学特征 711 胎儿头部 检测胎儿神经发育情况 3 092 胎儿股骨 估算胎儿体重 1 040 胎儿胸腔 检测胎儿心脏和肺部发育情况 1 718 母体宫颈 预测早产风险 1 626 其他类型 4 213 总计 12 400 表 5 实验数据集分布情况
Table 5 Experimental component distribution of datasets
数据
类型胎儿
腹部胎儿
头部胎儿
股骨胎儿
胸腔胎儿
宫颈其他
类型总计 训练集 569 2 474 832 1 374 1 301 3 370 9 920 测试集 142 618 208 344 325 843 2 480 总计 711 3 092 1 040 1 718 1 626 4 213 12 400 表 6 各神经网络模型性能对比
Table 6 Experimental results with different neural network methods
模型名称 Acc/% 显存占用量/MB GPU占用率/% MFLOPs 损失值 模型文件大小/MB MobileNetV2 93.27 1384 21 2420 0.0651 9.27 MobileNetV3small 89.35 116 8 64 0.0939 5.12 Resnet8 92.22 172 9 624 0.0932 4.02 VGG16 94.52 2630 39 15530 0.0898 537 Resnet34 93.15 1970 27 56940 0.0757 85.5 Resnet101 97.50 12656 51 123570 0.0786 173 表 7 学生网络和教师网络计算资源占用
Table 7 Occupation of computational resource of student and teacher models
模型名称 参数
量/106显存占用
量/MBGPU占
用率/%MFLOPs 模型文件
大小/MBResnet8 1.00 172 9 624 4.02 Resnet101 43.09 12 656 51 123 570 173 表 8 不同温度系数T的性能对比
Table 8 Experimental results with different parameter T
温度系数T 准确率/% 宏精确率/% 宏召回率/% 宏F1值 5 97.38 97.85 96.34 0.970 3 10 96.05 94.83 95.98 0.953 8 20 95.60 94.39 95.20 0.947 8 30 95.56 94.42 95.06 0.947 2 40 95.48 94.46 94.79 0.946 1 表 9 不同优化方法的性能对比
Table 9 Performance comparison of different models
模型名称 准确率/% 宏精确率/% 宏召回率/% 宏F1值 Resnet101 97.50 96.66 97.29 0.969 6 Resnet8 92.22 92.69 87.95 0.900 0 Resnet8+stage1 93.75 92.62 91.87 0.922 0 Resnet8+KD 97.38 97.85 96.34 0.970 3 Resnet8+Hint 98.59 98.25 98.17 0.982 1 -
[1] MARACI M A, NAPOLITANO R, PAPAGEORGHIOU A, et al. Searching for structures of interest in an ultrasound video sequence[C]//Proceedings of the 5th International Workshop on Machine Learning in Medical Imaging. Boston, USA, 2014: 133–140. [2] PLATT J. Sequential minimal optimization: a fast algorithm for training support vector machines[J]. Advances in kernel methods-support vector learning, 1998, 7:1–22. [3] BAUMGARTNER C F, KAMNITSAS K, MATTHEW J, et al. SonoNet: real-time detection and localisation of fetal standard scan planes in freehand ultrasound[J]. IEEE transactions on medical imaging, 2017, 36(11): 2204–2215. [4] MARACI M A, BRIDGE C P, NAPOLITANO R, et al. A framework for analysis of linear ultrasound videos to detect fetal presentation and heartbeat[J]. Medical image analysis, 2017, 37: 22–36. [5] LAFFERTY J D, MCCALLUM A, PEREIRA F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the 18th International Conference on Machine Learning. San Francisco, USA, 2001: 282–289. [6] RYOU H, YAQUB M, CAVALLARO A, et al. Automated 3D ultrasound biometry planes extraction for first trimester fetal assessment[C]//Proceedings of the 7th International Workshop on Machine Learning in Medical Imaging. Athens, Greece, 2016: 196–204. [7] CHENG P M, MALHI M S. Transfer learning with convolutional neural networks for classification of abdominal ultrasound images[J]. Journal of digital imaging, 2017, 30(2): 234–243. [8] DONAHUE J. CaffeNet(GitHubPage)[EB/OL]. (2016-05-6)[2021-05-11].https://github.com/BVLC/caffe/tree/master/models/bvlc_reference_caffenet [9] SIMONYAN K. VGG team ILSVRC-2014 model with 16 weight layers (GitHub Page)[EB/OL]. (2016-05-16)[2021-05-11]. https://gist.github.com/ksimonyan/211839e770f7b538e2d8 [10] HOWARD A G, ZHU Menglong, CHEN Bo, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL]. (2017-04-17)[2021-05-11]. https://arxiv.org/abs/1704.04861v1. [11] SANDLER M, HOWARD A, ZHU Menglong, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA, 2018: 4510–4520. [12] ANDREW A, SANDLER M, GRACE C, et al. Searching for mobileNetV3[EB/OL]. (2019-05-06)[2021-05-11].https://arxiv.org/abs/1905.02244v3. [13] BUCILUǍ C, CARUANA R, NICULESCU-MIZIL A. Model compression[C]//Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Philadelphia, USA, 2006: 535–541. [14] ROMERO A, BALLAS N, KAHOU S E, et al. FitNets: hints for thin deep nets[J]. (2014-12-19)[2021-05-11]. https://arxiv.org/abs/1412.6550v2. [15] HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[EB/OL]. (2015-03-09)[2021-05-11].https://arxiv.org/abs/1503.02531. [16] JIN Xiao, PENG Baoyun, WU Yichao, et al. Knowledge distillation via route constrained optimization[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision . Seoul, Korea , 2019: 1345–1354. [17] PHUONG M H, LAMPERT C H. Towards understanding knowledge distillation[C]//Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA, 2019. [18] JI Guangda, ZHU Zhanxing. Knowledge distillation in wide neural networks: risk bound, data efficiency and imperfect teacher[EB/OL]. (2020-10-20)[2021-05-11].https://arxiv.org/abs/2010.10090. [19] ZHANG Ying, XIANG Tao, HOSPEDALES T M, et al. Deep mutual learning[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA, 2018: 4320–4328. [20] MOBAHI H, FARAJTABAR M, BARTLETT P L. Self-distillation amplifies regularization in Hilbert space[EB/OL]. (2020-02-13)[2021-05-11].https://arxiv.org/abs/2002.05715v1. [21] ZHAI Mengyao, CHEN Lei, TUNG F, et al. Lifelong GAN: continual learning for conditional image generation[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision . Seoul, South Korea, 2019: 2759–2768. [22] YUAN Li, TAY F E H , LI Guilin, et al. Revisit knowledge distillation: a teacher-free framework[C]//Proceedings of the International Conference on Learning Representation. Addis Ababa, Ethiopia, 2020.








































