 2018, Vol. 13
2018, Vol. 13



尽管人工智能学科已经诞生60多年了,从技术、产品和产业上看都有了巨大的发展,积累了丰富的经验和教训。但是,目前在人工智能学界仍然普遍存在一种思想倾向,只重视模拟单一智能功能的技术和方法研究,轻视关乎智能模拟全局的基础理论(涉及智能的形成机制、智能的逻辑规律和智能的数学基础等)研究。甚至有少数人公开宣扬人工智能是一门实践性科学,它能解决某类智能问题即可,不需要也不存在什么通用理论。面对这些片面认识和主张,人工智能通用理论体系的建立,更加具有重大的理论意义和现实意义。
1 研究背景 1.1 人工智能的理论危机20世纪中叶人工智能学科的诞生开创了智能信息处理的新纪元。众所周知,各种人工智能学派都是在布尔信息处理和标准逻辑(数理逻辑)基础上建立和发展起来的[1],20世纪80年代的人工智能理论危机暴露了布尔信息处理和标准逻辑的应用局限性[2-3]:
1)由于布尔信息处理和标准逻辑只是根据命题真值而不考虑命题内容进行的推理,尽管它具有可机械执行,无需领域背景知识支撑的优点,但在机械执行过程中也带来了工作效率十分低下、无法克服因信息处理算法的时空复杂度带来的组合爆炸的缺点;
2)由于布尔信息处理和标准逻辑只考虑了确定性推理的需要,必须满足非此即彼的理想化约束。而智能信息处理需要面对的现实问题往往具有各种不确定性,推理的各种逻辑要素常常有信息缺损和不断变化的情况,不允许像传统数学问题那样进行理想化处理,带有亦此亦彼性特征。对于这类问题,布尔信息处理和标准逻辑束手无策,无所适从。
1.2 两种不同的发展倾向人工智能的理论危机之后,国际上出现了两种完全相反的发展倾向[3-5]:
1)尽可能回避甚至放弃人工智能的逻辑主义路线,大力发展非逻辑的结构主义(人工神经网络)和行为主义(刺激—反应)路线。在这一发展倾向下,近几十年来基于大数据处理的深度神经网络、各种计算智能、群体智能和机器学习方法有了长足的进步,取得了举世瞩目的应用成果。
2)继续坚持逻辑主义路线,并针对处理各种不确定性的需要,近几十年来涌现出了几十种非标准逻辑和一批不确定性推理理论,它们虽然可满足某些智能信息处理的应用需求,但有时会出现无法容忍的反常结果,这表明这些非标准逻辑和不确定性推理方法在理论上并不成熟,人们还没有精确掌握其立论依据和有效使用范围。
1.3 作者的个人选择作者相信,对于智能系统来说,结构、功能和行为是三位一体的关系,不能绝然分开孤立存在。而思维和智能本质上都是一种信息处理过程,它们必然受到某种逻辑规律的约束,人工智能理论危机的意义并不是在否定逻辑,而是在告诉人们,智能信息处理中的逻辑规律不仅包含专门针对确定性推理的标准逻辑,还包含处理各种不确定性的非标准逻辑,所以逻辑主义路线不能放弃,一定要继续坚持和发展[6]。作者根据概率论和已有的不确定性推理理论,系统深入研究了这一路线的发展状况和存在问题,发现已提出的各种非标准逻辑虽然都可以把标准逻辑作为特例包含在自己的体系之内,但它们都不像标准逻辑那样具有普适性,一般都只能适用于某种不确定性中的某个特殊状态下的推理需要,偏离了这个特殊状态使用,推理结果就会出现偏差,偏离大到一定程度后就会出现无法容忍的反常结果。最明显的实例是已获得广泛应用的3个命题级非标准逻辑:模糊逻辑、概率逻辑和有界逻辑。根据概率论的研究结论,它们只能分别适用于相容性相关中的3种不同状态下的不确定性推理:模糊逻辑只适用于两个连续值命题之间具有最大相吸相关的状态,概率逻辑只适用于具有独立相关的状态,有界逻辑只适用于具有最大相斥相关的状态。而相容性相关关系本身是可以从最大相吸状态变化到独立相关状态,再变化到最大相斥状态的(见图1)一个连续的区间,不是3个孤立点。

|
Download:
|
| 图 1 从概率论看3个非标准逻辑适用的状态点 Fig. 1 See the state point of application of 3 nonstandard logic from the theory of probability | |
在这里不难想象,如果偏离了这3个特殊状态点去任意使用这3个非标准逻辑,其推理结果必然会出现偏差。如在独立相关或最大相斥相关状态下不恰当地使用模糊逻辑进行推理,必然会出现无法容忍的反常结果,而现在的实际情况是,许多人都在不分场合地盲目使用模糊逻辑,只要不出现无法容忍的反常结果,一般人都不会选择其他的非标准逻辑使用!历史的经验确实如此,在标准逻辑的应用中,从来都是用一把“万能钥匙”来解决一切问题,没有人会环顾左右而言它。为什么会犯如此低级的错误而不能觉察?因为确定性推理只有一种状态,没有任何不确定性引起的差别存在,用一种标准逻辑来描述就足够了。但是,在专门针对各种不确定性推理而建立的非标准逻辑群中,由于不确定性状态的千差万别,如同密码锁一样,所以必须严格贯彻“一个密码开一把锁”的原则,绝对不允许盲目地乱点鸳鸯谱,是传统的逻辑观把人带入了迷途。
为改变这种根据经验知识建立非标准逻辑系统,而后又不问适用条件盲目使用它来进行各种不确定性推理的混乱状况,作者在20世纪90年代就从人工智能的应用研究转入到人工智能的逻辑基础理论研究,试图根据智能信息处理中需要处理的各种不确定性的特殊需求,精确抽象出一个类似门捷列夫元素周期表的命题泛逻辑理论框架来(见图2),用它来实现智能信息处理中需要“一串密钥开一把密码锁”的特殊需求。

|
Download:
|
| 图 2 命题泛逻辑的理论框架 Fig. 2 Theoretical framework for propositional universal logic | |
命题泛逻辑理论框架的结构是一个四维空间[0,1]4,空间的中心点O代表有界逻辑,当它的命题真度由连续值(代表命题真值的不确定性)退化为二值时,就退化为适用于确定性推理的标准逻辑(又称为刚性逻辑,在刚性逻辑之外的其他部分称为柔性逻辑)。从O点伸出的4个坐标轴
作者的这一研究目标已初步实现,1996年在中国科学杂志上提出泛逻辑概念[7],2001年在科学出版社出版专著《泛逻辑学原理》,公布了完整的泛逻辑研究纲要,并实现了纲要中的命题泛逻辑部分[8] 。2005年在瑞士日内瓦的蒙特勒召开了首届世界泛逻辑大会,作者应邀在大会上报告“Research on Universal Logics in China”,引起国际同行的关注和认可,决定第二届世界泛逻辑学术会议在中国进行[9-10]。2006年作为中国人工智能学会纪念人工智能学科诞生50周年系列丛书之一、英文版Principle of Universal Logics在科学出版社和西北工业大学出版社联合出版,国内外发行[11]。2007年第二届世界泛逻辑大会在西北工业大学举行,作者是大会两主席之一。2012年作者根据命题泛逻辑的代数结构特征,抽象出泛逻辑的数学基础——连续值逻辑代数[12]。本文将进一步讨论一个重要的理论话题,上述泛逻辑理论体系的建立有没有严密的数学基础理论支撑。如果没有,说明它还没有脱离经验设计的局限性,在应用中必然缺乏普适性意义。如果它有严密的数学基础理论支撑,那这个数学基础理论是什么?数学界是否认可这个数学理论的存在?这是关系到人工智能学科是否已经从实践经验性学科走向理论性学科的重要标志!
从数学理论支撑角度看,概率论是目前数学界唯一公认的从确定性出发研究随机性和不确定性的数学工具[13],作者在建立命题泛逻辑(包含刚性命题逻辑和柔性命题逻辑)的过程中,实际上已将概率论扩展为广义概率论,其明显的标志是将概率论中的相关系数扩张为广义相关系数。具体的贡献有两点:
1)概率论中的相关系数只考虑了两个命题(事件)之间的相容(相生)性相关关系,即从最大相吸相关关系开始,不断向下连续变化到独立相关关系,再不断向下连续变化到最大相斥相关关系。我们引入的广义相关系数已全面考虑了两个命题(事件)之间的相容(相生)性相关和不相容(相克)性相关,即增加了从最大相斥相关关系继续向下连续变化到不同程度的冷战关系,再向下连续变化到不同程度的热战关系,这种相关性扩张更加符合描述客观存在的各种相关关系的需要。
2)在概率论中,原来只给出了最大相吸相关、独立相关和最大相斥相关3个特殊点的逻辑运算公式组,对三点之间连续分布的其他点的逻辑运算公式组没有给出,是用条件概率计算公式来代替的。我们在广义概率论中,把广义相关系数中的每一个点的逻辑运算公式组全都给出了,没有一点遗漏,大大方便了不确定性推理。
所以,广义概率论是对概率论的必要补充和扩张,在数学上具有合理性和严密性。作者提出的连续值逻辑代数,因其离不开广义相关系数的参与,所以也是建立在广义概率论基础上的抽象代数理论。作者的研究表明,将各种智能信息处理原理建立在广义概率论基础上是完全合理和严密的。从本文可以看出,如果进一步把广义概率论与汪培庄教授的因素空间理论[14-16]密切结合起来,精确刻画信息和知识在因素空间中的组织形态和变换规律,将会形成关于智能科学的更加完善的数学基础理论,共同支撑智能信息处理的逻辑基础——泛逻辑学理论。
从应用检验的角度看,钟义信教授的机制主义人工智能理论[17-19]是一个通用的人工智能理论体系,它是从模拟人类智能的形成机制入手来建立机器智能系统的,可以应用到各种不同智能信息处理的场合,具有普适性意义,如果在其中进行泛逻辑的应用检验,那是最有效的检验。所以我们三人研究结果的密切结合,将标志着人工智能的通用理论—智能信息处理的逻辑基础—智能信息处理的数学基础三位一体关系的正式形成。
2 关于智能信息处理的哲学思考 2.1 确定论宇宙观是不确定论宇宙观在局部时空中的特例我们周围存在大中小3个不同的宇宙,它们都处在不断地演化发展之中。大宇宙由各种天体系统运行的时空环境组成;中宇宙由地球上各种生命系统繁衍生息的时空环境组成;小宇宙由人脑思维活动的时空环境(或人体各系统运行的时空环境)组成,它们都是开放的复杂巨系统,具有非线性涌现、自组织、自适应、生态平衡等效应,永远处在不断演化发展的过程中。能源时代形成的确定论宇宙观是演化论宇宙观在局部时空范围中的特例,具有明显的应用局限性。
广义地讲,3个宇宙都具有自然智能,它们能够根据系统的外部环境变化改变自己的内部状态和外部行为方式,以便更好地适应环境,在激烈的生存竞争中求得一席之地立足,所以它们都能成为智能模拟的样板,这是计算智能的立论基础。狭义地讲,智能是专门指人脑思维活动中表现出的一种能力,它能根据自身生存目标和眼前存在的问题,恰如其分地选择或者制定解决问题的策略和方法,并可根据实施效果不断改进提高。即能通过经验记忆和归纳学习,不断优化自己的知识结构和决策方法,提高自己的识别问题和解决问题的水平。
2.2 传统数学问题与智能信息处理的差别传统数学问题是全面接受非真即假约束的理想问题,可用标准逻辑或刚性集合精确描述,用经典形式演绎解决。智能问题常包含各种不确定性,具有亦此亦彼性,只能用非标准逻辑或柔性集合描述,无法通过经典形式演绎解决。
人在解决智能问题时,常会综合使用本能、直觉、归纳发现、经验知识、启发式搜索、原理性知识和假设前提等进行不确定性推理,选择可信度较高的答案执行,并按执行效果进行修改完善。人工智能在自动证明数学定理时,也不是按形式演绎规则机械执行的,因为组合爆炸会快速消耗掉计算机的时空资源,无法顺利到达证明的终点!只有模拟资深数学家的洞察力,用启发式搜索算法发现可能的最佳证明路径和方法,才能快速接近目标,不能盲目依靠经典形式演绎规则进行机械式推理。
可见,智能方法常是牺牲可靠性和完备性获得求解问题的真实性和即时性。而传统数学方法则是忽视真实性和即时性确保求解问题的可靠性和完备性。未来数学的发展方向应该是给行之有效的智能信息处理原理和方法以严格的数学描述。
2.3 应该关注智能系统的时效性还有一种具有典型意义的智能问题,即两个独立智能体之间的博弈问题,它可看作高度简化了的生存竞争问题或生态平衡问题,其只考虑了我和非我两方的存在。在二元智能博弈问题中,由于双方同在一个时空环境之中,必须遵守共同的博弈规则,所以这里不仅要比较对弈双方解决眼前问题的智力高低、两者付出的智能多少,更重要的是比较两者智率的大小(解决问题的快慢)。静态看机器的智力和智能都是设计者注入的人类有关能力的一个真子集(永远不可能是全集),在人机大战中机器之所以能反过来战胜对弈的人,是因为机器思考执行同样一个问题时的智率远高于人脑,达到数百万倍以上。这与压缩式风洞实现超高音速吹风的工作原理(将空气长时间低速压缩进入高压气罐,然后瞬间进行超高音速释放)十分相似。
所以,在比较人机智能的高低时,时效性是一个重要因素。即智能系统(智力、智能、智率)演化的时常数
刚性推理范式是基于二值逻辑的推理,其中所有逻辑要素都受非此即彼性约束。传统数学能用刚性推理来求解问题,是它事先已将现实问题中所有不确定性全部忽略,抽象为规律确定不变、状态真假分明、已知条件齐全的理想化问题,可机械式求解。
更深层的哲学信念是:之所以能如此理想化地抽象,是因为人们相信世间万物都受确定不变的客观规律控制,时间是标量,不确定性是人类对客观规律和问题的状态掌握不充分引起的近似性。人类认知的前进方向是不断消除这些认知的不确定性,实现对客观规律和状态参数的全部精准掌握,最后实现绝对的确定性。于是认为,理想化的过程本质上是一个由表及里、去粗取精、去伪存真的必要过程,不会造成认识上的任何损失。
耗散结构理论的创立者伊•普里戈金的专著《确定性的终结》(1996年问世,1998年出中文版)的出版[21],宣告了确定性哲学信念的终结,它不符合客观世界的实际情况,犯了认知的方向性误判,必须改正。
2.5 智能信息处理为何必须用柔性推理范式求解人类之所以有智能,是因为人可根据现实问题的真实状况和变化趋势,在已有经验启发下选择最有效的原理、途径和方法去解决问题。如果这次失败了,可从头再来反复不断地试探下去,并能通过一次次的经验教训的积累进行学习改进,不断完善自身解决问题的能力。
更深层的哲学信念是:相信世间万事万物都处在不断演化发展过程中,时间是矢量,过去、现在和未来扮演着不同的角色,不确定性是客观世界的本质属性,确定性是人在局部时空环境中形成的近似性认知。人类认知的前进方向是不断消除这些近似性认知,精准把握各种不确定性在生态平衡中的演化发展规律,理想化是人类在局部时空中解决问题时不得不采用的权宜之计。
智能信息处理中的柔性推理范式是包含某些不确定性的逻辑推理模式簇,需要处理的不确定性组合不同,推理使用的具体模式必然不同,不可乱点鸳鸯谱。
2.6 在智能信息处理中需要两种推理范式同时并存各司其职刚性推理范式的特点是:具有逻辑上的严密性和推理路径的完备性,推理过程可机械式一无反顾地进行下去,对有解的理想问题(不管结论是真是假)一定可以获得最后结果。尽管计算机在无启发式知识指导下使用会出现组合爆炸,但人类专家可利用启发性经验知识优化证明过程,快速接近目标。
柔性推理范式的特点是:可精确描述现实问题中包含的各种不确定性,有针对性地进行相应的推理运算,获得准确的结果,不必因为理想化而丢掉许多有用的信息。尽管柔性推理计算过程十分复杂,使用起来很不方便快捷,但是对于计算机信息处理而言,这是轻而易举的事情,而且复杂的演算过程可以放在后台由软硬件执行,用户程序不必关心。在智能信息处理中,许多问题的存在价值就在于它包含的某些不确定性,如果全部都理想化处理了,那么这个问题就根本不存在了,如自动驾驶问题、人脸识别问题、语音识别问题等。
现代数学的发展方向:使用刚性推理范式的传统数学需要向精确描述各种不确定性的方向全面扩张,以便包容智能信息处理中的柔性推理范式,数学不仅不能再将它们继续作为另类来看待,而且要让它们走向数学舞台的中央,这是智能时代对现代数学提出的最大需求!
2.7 有关智能信息处理的若干基本假设建立智能信息处理的理论体系需要如下基本假设的支撑,在证明中它们可作为公理使用。
假设1 宇宙由两个世界、四大要素组成
宇宙是由物质世界和信息世界组成的对立统一体。物质对象在物理空间中具有占位性(表现为对象的排它性)和惯性(表现为移动对象需要付出的力和能)。物质结构、质量、力和能量是物质世界中的基本科学问题。信息对象在可能性空间中具有占位性(表现为对象的排它性)和惯性(表现为移动对象需要付出的智力和智能)。信息结构、信息量、智力、智能和智率是信息世界中的基本科学问题。
有这样一种科学假设:宇宙由无数的信息子对偶组成,对偶的开合决定了它是物质态还是信息态,两个世界之间可相互联系和转换,时间是把两个世界关联起来的同步信号。
假设2 不确定性是宇宙万物的本质特征
在能源时代人类面对的是封闭的简单机械系统,形成的宇宙观是确定论:人们普遍相信事物的发展变化是由确定不变的客观规律控制的,时间是一个标量,不确定性是由于人们没有精确全面掌握这些客观规律和研究对象的状态参数而引起的,解决问题的科学方法论是还原论,微积分和标准逻辑是其理论基础。
信息时代人类面对的是复杂性开放系统,其中一切事物无不处在演化发展过程中,随着新事物不断涌现,新规律不断显现出来,这说明宇宙在本质上是不确定的,时间是一个矢量,过去、现在和未来分别扮演着不同角色,形成的科学宇宙观是不确定论。因为人们根本不可能在了解整个时空内的全部信息的状态下去认识世界、解决问题,所以不确定性永远无法回避,形成的科学方法论只能是演化论,它必须适应涌现效应和生态平衡的需要,其理论基础必然发生根本性改变。这是智能信息处理中必须面对和解决的新问题。
假设3 必须严格区分两类不同性质的矛盾
与确定性推理排斥一切矛盾不同,在不确定性推理中必须严格区分逻辑矛盾和辩证矛盾,它们是两类不同性质的矛盾。逻辑矛盾是在任何一个逻辑系统中都不允许出现的判定性错误,必须予以排除。如在二值逻辑中判定命题
智能信息处理要面对现实世界中可能存在的各种确定性和不确定性,其右极限是:现实中可能存在的所有不确定性全部包含在待解决的问题中,只有最完整的柔性逻辑才能描述和求解。而传统数学中的形式演绎是智能信息处理的左极限:它通过抽象或忽略,可把现实中所有的不确定性全部理想化为确定性,允许用刚性逻辑描述和求解。一般智能信息处理介于两个极限之间,其中部分因素是确定的,部分因素是不确定的(见图3)。

|
Download:
|
| 图 3 智能信息处理对逻辑学的需求 Fig. 3 The need for intelligent information processing to logic | |
如前所述,命题泛逻辑的研究目标是建立一个命题泛逻辑理论框架,其结构是一个四维空间
下面简单介绍相对于这个研究目标已经具备了哪些研究基础。
3.2 布尔信息处理的有关情况1)基于逻辑推理法的布尔信息处理
英国数学家G. Boole 1854年在《思维规律》中提出布尔逻辑算子组,它为标准逻辑(刚性逻辑)奠定了理论基础[22],可满足布尔信息处理的全部需要。图4给出了布尔逻辑算子组在概率论中的集合意义:设对象域

|
Download:
|
| 图 4 布尔逻辑算子组及其在概率论中的集合意义 Fig. 4 Boolean logic operator group and its set meaning in probability theory | |
2)基于神经网络信息变换法的布尔信息处理
1943年心理学家McCulloch和数学家W. Pitts提出二值神经元信息变换模型

|
Download:
|
| 图 5 二值神经元M-P模型的基本结构 Fig. 5 The basic structure of the two value neuron M-P model | |
3)布尔信息处理的完备性分析
可以以二元信息处理为例来讨论而不失一般性,因为3元信息处理可由两个二元信息处理来完成

|
Download:
|
| 图 6 布尔信息处理的完备性分析 Fig. 6 Completeness analysis of Boolean information processing | |
4)布尔信息处理的最基本模式分析
从图6还可以看出,布尔逻辑算子组
可见在布尔信息处理中有两类方法:一类是标准逻辑推理法,另一类是布尔神经元信息变换法。两者相互等价,是一一对应的关系。由模式参数
上面就是基于标准逻辑推理法和二值神经元信息变换法的刚性信息处理范式的概貌,它们是完备的。基于柔性逻辑推理法和基于柔性神经元信息变换法的柔性信息处理范式将在它们的基础上通过放开某些约束条件,引入相应的不确定性来实现。
3.3 连续值信息处理的有关情况连续值逻辑推理法。1920年波兰学者J. Luckasiewicz提出三值逻辑,1921年美国学者E.L. Post提出多值逻辑[25],其中包括具有连续值的有界逻辑:
其实,在二值逻辑中布尔算子组已有4种形式不同但是结果等价的计算公式:
| $\begin{array}{c}x \wedge y = \min \left( {x,y} \right) = xy = \Gamma \left[ {x + y - 1} \right] = \\{\mathop{\rm ite}\nolimits} \left\{ {\left. {\left. {\min \left( {x,y} \right)} \right|\max \left( {x,y} \right) = 1;0} \right\}} \right.\\x \vee y = \max \left( {x,y} \right) = x + y - xy = \Gamma \left[ {x + y} \right] = \\{\mathop{\rm ite}\nolimits} \left\{ {\left. {\left. {\max \left( {x,y} \right)} \right|\min \left( {x,y} \right) = 0;1} \right\}} \right.\\x \to y = {\mathop{\rm ite}\nolimits} \left\{ {\left. {\left. 1 \right|x \leqslant y;y} \right\}} \right. = \min \left( {1,x/y} \right) = \\\Gamma \left[ {1 - x + y} \right] = {\mathop{\rm ite}\nolimits} \left( {\left. y \right|x = 1;1} \right)\end{array}$ |
当命题的真值从二值

|
Download:
|
| 图 7 4个非标准逻辑引发的思考 Fig. 7 Thinking caused by 4 nonstandard logic | |
模糊逻辑:
| $\begin{array}{c}\neg x = 1 - x;x \wedge y = \min \left( {x,y} \right);x \vee y = \max \left( {x,y} \right);\\x \to y = {\mathop{\rm ite}\nolimits} \left\{ {\left. {\left. 1 \right|x \leqslant y;y} \right\}} \right.\end{array}$ |
概率逻辑:
| $\begin{array}{c}\neg x = 1 - x;x \wedge y = xy;x \vee y = x + y - xy;\\x \to y = \min \left( {1,x/y} \right)\end{array}$ |
有界逻辑:
| $\begin{array}{c}\neg x = 1 - x;x \wedge y = \Gamma \left[ {x + y - 1} \right];\\x \vee y = \Gamma \left[ {x + y} \right];x \to y = \Gamma \left[ {1 - x + y} \right]\end{array}$ |
突变逻辑:
| $\begin{array}{c}\neg x = 1 - x;x \wedge y = {\mathop{\rm ite}\nolimits} \left\{ {\left. {\left. {\min \left( {x,y} \right)} \right|\max \left( {x,y} \right) = 1;0} \right\}} \right.;\\x \vee y = {\mathop{\rm ite}\nolimits} \left\{ {\left. {\left. {\max \left( {x,y} \right)} \right|\min \left( {x,y} \right) = 0;1} \right\}} \right.;\\x \to y = {\mathop{\rm ite}\nolimits} \left( {\left. y \right|x = 1;1} \right)\end{array}$ |
进一步研究发现,这4个非标准逻辑之间有严格的大小顺序关系,是连续变化区间中的4个特殊点,尽管前3个连续值逻辑算子组已由概率论证明:模糊逻辑算子组在最大相吸相关时成立;概率逻辑算子组在独立相关时成立;有界逻辑算子组在最大相斥相关时成立,可以说是有可靠的数学理论支撑。唯独突变逻辑算子组没有数学理论依据。但是,我们可以证明,模糊逻辑算子组是柔性信息处理算子组的上极限,突变逻辑算子组是柔性信息处理算子组的下极限,所以我们不能轻易否定突变逻辑算子组的存在价值。而且人们有理由进一步思考,在这4种逻辑算子的间隙中是否还存在其他的柔性信息处理算子组?这些柔性信息处理算子组都代表什么逻辑?能在什么情况下使用?
3.4 三角范数理论的启发1942年K. Menge提出三角范数(triangular norm)概念,主要研究各种算子中不同运算模型应共同满足的抽象定义、一般性质和生成方法,常用的连续值域为
柔性命题的真度与刚性命题的真值有很大差别,因为标准逻辑是在矛盾对立(分明集合)中确定命题的真值,满足非真即假的理想化约束。而柔性逻辑是在矛盾对立统一(柔性集合)中确定柔性命题的真度,满足亦真亦假性,它真假有度,矛盾双方共处一体。所以在柔性命题的真度中,可通过真度数值的不同变化,来包容辩证矛盾并实现矛盾双方的相互转化。

|
Download:
|
| 图 8 用Schweizer算子簇扩张概率论 Fig. 8 Extension probability theory with Schweizer operater cluster | |
1)柔性命题真度的确定方法
参照刚性命题真值的定义方法,定义柔性命题的真度是论域

|
Download:
|
| 图 9 柔性命题真度的定义 Fig. 9 The definition of the truth degree of the flexible propositions | |
用什么可靠方法来精确确定论域

|
Download:
|
| 图 10 柔性命题真度的确定方法 Fig. 10 A method for determining the truth degree of flexible propositions | |
2) 两级间接定义的方法在智能信息处理中具有普适性意义
在智能信息处理中常常需要把原始数据库中的数据(常是布尔信息)归纳抽象为知识,然后再把知识库中较低层的知识归纳抽象为更高层的知识,如此一层一层地不断归纳抽象下去,知识的粒度越来越大,关系网络越来越简化,直到知识的粒度和关系网络的复杂度满足智能决策的需要为止。概率论已是一个公认的数学基础理论,它在理论上架起了从确定性推理(分明关系)出发通向随机性(不确定性知识、不分明集合)推理的桥梁,可操作性好,可靠性高。上面这种通过在因素空间
1) 18种不同的柔性信息处理模式
把没有引入其他不确定性的连续值逻辑运算模型组称为命题泛逻辑的基模型组,作者已研究证明常用的基模型组就是有界逻辑算子组,它仅包容了命题真度的不确定性

|
Download:
|
| 图 11 18种柔性信息处理模式 Fig. 11 Eighteen kinds of flexible information processing mode | |
2) 常用的7种基模型
从图11可以看出,常用的基模型有7个,它们是:
①非运算的基模型
②与运算的基模型
③或运算的基模型
④蕴含运算的基模型
⑤等价运算的基模型
⑥平均运算的基模型 x®y =
⑦组合运算的基模型 x©y
其中
图12列举了我们研究发现的命题泛逻辑中能够包容的5种不确定性,它们对各型逻辑运算基模型的影响方式和程度如图13所示。命题真度不确定性的引入已经告诉我们,当把标准逻辑命题真值的二值属性

|
Download:
|
| 图 12 命题泛逻辑中能够包容的5种不确定性 Fig. 12 Five kinds of uncertainty that can be contained in propositional universal logic | |

|
Download:
|
| 图 13 各种不确定性对基模型组的调整函数 Fig. 13 The adjustment function of a variety of uncertainty to the base model group | |
1)命题真度误差的不确定性
在概率测度中允许出现估计误差,无估计误差的是可加概率测度(additive measure),满足
利用三角范数理论可以证明,误差系数的连续变化对柔性命题逻辑运算基模型的调整可由N性生成元完整簇
| $N\left( {x,k} \right) = {\varPhi ^{ - 1}}\left( {N\left( {\varPhi \left( {x,k} \right)} \right),k} \right)$ |
它对6种二元运算基模型L(x, y)的作用方式是:
| $L\left( {x,y,k} \right) = {\varPhi ^{ - 1}}\left( {L\left( {\varPhi \left( {x,k} \right),\varPhi \left( {y,k} \right)} \right),k} \right)$ |
误差系数是不确定性推理密码串
2) 两个命题之间广义相关关系的不确定性
图14描述了广义相关关系的不确定性,通过广义相关系数

|
Download:
|
| 图 14 柔性广义相关关系的不确定性 Fig. 14 Uncertainty of flexible generalized correlation | |
其中
利用三角范数理论可以证明,广义相关系数h对逻辑运算基模型的影响全部反映在T性生成元完整簇
广义相关系数是不确定性推理密码串
3) 两命题之间相对权重的不确定性
两命题之间相对权重的不确定性用偏袒系数
利用三角范数理论可以证明,偏袒系数
| $L(x,y,\beta ) = L(2\beta x,{\rm{ }}2(1 - \beta )y)$ |
偏袒系数是不确定性推理密码串
4) 组合运算中决策阈值的不确定性
在有界逻辑中组合运算模型为
| $\begin{array}{c}{C^e}\left( {x,y} \right) = {\rm{ite}}\{ {\rm{min}}\left( {e,\max \left( {0,x + y - e} \right)} \right)|x + y < 2e;\\N\left( {{\rm{min}}\left( {N\left( e \right),{\rm{max}}\left( {0,N\left( x \right) + N\left( y \right) - N\left( e \right)} \right)} \right)} \right)|\\x + y{\rm{ > }}2e;e\} = {\rm{min}}\left( {1,{\rm{max}}\left( {0,x + y - e} \right)} \right)\end{array}$ |
它是一个完整的组合算子簇,其中引入了决策阈值
决策阈值
目前我们尚未发现第5种影响柔性命题逻辑运算模型的不确定性因素存在。
4.4 7种逻辑运算的公理及模型1)非运算公理及模型
非运算公理 非运算模型
非运算模型 非运算模型只受误差系数k的影响,是
| $N(x,k){\rm{ }} = {\varPhi ^{ - 1}}(1 - \varPhi (x,k),k){\rm{ }} = {\rm{ }}{(1 - {x^n})^{1/}}^n$ |
其中,
一般两次非运算的误差系数可不相等
2)与运算公理及模型
与运算公理 与运算模型
与运算模型 与运算模型可受
当
与运算模型有4个特殊算子:模糊与算子
一般情况下,因两个命题x, y可能是真度相等,而不一定是
3) 或运算公理及模型
或运算公理 或运算模型
或运算模型 或运算模型可受
| $\begin{array}{c}S\left( {x,y,k,h,\beta } \right) = \\{\left( {1 - {{\left( {{\rm{max}}\left( {0,2\beta {{\left( {1 - {x^n}} \right)}^m} + 2\left( {1 - \beta } \right){{\left( {1 - {y^n}} \right)}^m} - 1} \right)} \right)}^{1/m}}} \right)^{1/n}}\end{array}$ |
当
一般情况下,因两个命题
在
4) 蕴涵运算公理及模型
蕴涵运算公理 蕴涵运算模型
蕴涵运算模型 蕴涵运算模型可受
当
一般情况下MP规则
5)等价运算公理及模型
等价运算公理 等价运算模型
等价运算模型 等价运算模型可受k, h, β的联合影响,是一个运算模型完整簇,即
| $\begin{array}{c}{Q(x,y,k,h,\beta ) = }\\{{\rm{ite}}\left\{ {\left. {{{\left( {1 + \left| {2\beta {x^{nm}} - 2\left( {1 - \beta } \right){y^{nm}}} \right|} \right)}^{1/mn}}} \right|} \right\}}\\\left. {m \leqslant 0;{{\left( {1 - \left| {2\beta {x^{nm}} - 2\left( {1 - \beta } \right){y^{nm}}} \right|} \right)}^{1/mn}}} \right\}\end{array}$ |
当
6)平均运算公理及模型
平均运算公理 平均运算模型
平均运算模型 平均运算模型可受
当
常见的平均算子:几何平均
7)组合运算公理及模型
组合运算公理 组合运算模型
组合运算模型 组合运算模型可受
| $\begin{array}{c}{C^e}(x,y,k,h,\beta ) = {\rm{ite\{ min}}(e,{\rm{ }}({\rm{max}}(0,{\rm{ }}2\beta {x^{nm}} + \\2(1 - \beta ){y^{nm}} - {e^{nm}}){)^{1/mn}}|2\beta x + 2(1 - \beta )y < 2e;\\(1 - ({\rm{min}}(1 - {e^n},{\rm{ }}({\rm{max}}(0,{\rm{ }}2\beta {\left( {1 - {x^n}} \right)^m} + 2(1 - \beta ){\rm{ }}{\left( {1 - {y^n}} \right)^m} - \\{\left( {1 - {e^n}} \right)^m}){)^{1/m}}){)^{1/n}})|2\beta x + 2(1 - \beta )y > 2e;e\} \end{array}$ |
当
概率组合
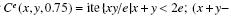
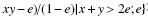
通过上面的讨论,我们已全面掌握了柔性命题逻辑中18种信息处理模式的类型编码
在刚性逻辑中有了可靠性和完备性的保证,就可以在各种应用场合安全地使用,没有任何例外。刚性逻辑具有可靠性和完备性的充分条件是满足以下规律:L1幂等律,
前面已经知道,将各种不确定性引入逻辑系统之后,推理的结果因为不确定参数
虽然具有可靠性和完备性,但其中的规律L3和L4不成立。现行的概率逻辑
L1 幂等律
L2 幂等律
L3 矛盾律
L4 排中律
L5 对合律
L6 MP规则
这些安全使用柔性命题逻辑的必要性条件说明,我们一定要打破在标准逻辑中养成的思维定式,以为选择了一组满足
由于神经元信息变换模式与逻辑推理模式有一一对应的关系,上述关于柔性命题逻辑的研究成果可用来把M-P神经元模型扩张为连续值神经元(相当于基模型状态),然后再引入其他各种不确定性,继续扩张为柔性神经元模型(详细见图15),这里不一一叙述了。
4.7 柔性信息处理完整算子库及其正反向利用方式1)我们可进一步想象,柔性命题逻辑或者柔性神经元模型本身就是一个关于各种不确定性信息处理的完整的命题级算子库,其中包括了各种可能存在的命题级算子,没有一个遗漏。使用者通过算子的类型属性编码

|
Download:
|
| 图 15 柔性神经元模型 Fig. 15 Flexible neuron model | |

|
Download:
|
| 图 16 完整的命题级算子库 Fig. 16 A complete library of propositional operators | |
2)应用程序使用算子库的两者方式。正向使用算子库的方式是:已知处理对象的因素空间关系网络
反向使用算子库的方式是:已知待识别对象的实测数据集合
这两种使用方式还可在信息处理程序中混合使用。
5 下一步的研究工作 1) 柔性命题逻辑在生成其他逻辑中的作用上面介绍的是一维空间[0,1]中的柔性命题逻辑,用

|
Download:
|
| 图 17 生成其他逻辑的有关规则 Fig. 17 Rules for generating other logic | |
例如二维柔性命题逻辑由两个一维柔性命题逻辑定义:
| ${\mathit{\boldsymbol{L}}^2}\left( {\mathit{\boldsymbol{x}},\mathit{\boldsymbol{y}},\mathit{\boldsymbol{k}},\mathit{\boldsymbol{h}},\mathit{\boldsymbol{\beta }}} \right) = \left\langle L({x_1},{y_1},k,h,\beta ),L({x_2},{y_2},k,h,\beta ) \right\rangle$ |
它可以描述不分明概念的前后变迁过程,命题真度在变迁前后都有精确值描述,可上下自由变化。
如果严格满足
三维柔性命题逻辑由3个一维柔性命题逻辑定义:
| $\begin{array}{c}{\mathit{\boldsymbol{L}}^3}\left( {\mathit{\boldsymbol{x}},\mathit{\boldsymbol{y}},\mathit{\boldsymbol{k}},\mathit{\boldsymbol{h}},\mathit{\boldsymbol{\beta }}} \right) = \langle L\left( {{x_1},{y_1},k,h,\beta } \right),\\L\left. {\left( {{x_2},{y_2},k,h,\beta } \right)} \right),L\left( {{x_3},{y_3},k,h,\beta } \right) \rangle \end{array}$ |
它可以描述不分明概念的历史变迁过程,命题真度在变迁前、现在、未来都有精确值描述,可上下自由变化。
如果严格满足
利用降值规则可通过一维柔性命题逻辑生成离散值命题逻辑,如三值逻辑
对柔性命题逻辑

|
Download:
|
| 图 18 需要深入研究的逻辑 Fig. 18 The logic needs to be studied in depth | |
关键是定义各种柔性量词,用数学方法描述各种辩证逻辑规律,这需要进一步深入长期的研究[32]。
6 结束语从这些研究成果可以看出,数理形式逻辑(即标准逻辑,简称刚性逻辑)在理论上没有错误,不应该像某些人鼓吹的那样“推翻重建”。但是也应该看到,尽管数理形式逻辑可描述和解决所有满足“非此即彼性”约束的理想化问题,是一个通用性的逻辑工具(万能钥匙)。可是在面对智能信息处理中大量且普遍存在的、具有“亦此亦彼性”特征的现实问题时,它是无能为力的,必须有针对性地建立各种数理辩证逻辑(即泛逻辑,简称柔性逻辑)。建立数理辩证逻辑的基本途径和方法是在数理形式逻辑基础上,逐步放开某些方面的“非此即彼性”约束,引入相应的“亦此亦彼性”。本文的研究结果表明,这条研究途径是可行的,也证明了正确使用数理辩证逻辑的基本要求是:必须严格地贯彻辨证施治的原则,精确地利用“一把钥匙开一把锁”的方法解决问题。
| [1] |
何华灿. 人工智能导论[M]. 西安: 西北工业大学出版社, 1988: 1–4.
( 0) 0)
|
| [2] |
涂序彦. 人工智能: 回顾与展望[M]. 北京: 科学出版社, 2006: 77–111. TU Xuyan. Artificial intelligence: review and prospect[M]. Beijing: Science Press, 2006: 77–111. ( 0)
|
| [3] |
钟义信. 高等人工智能原理: 观念·方法·模型·理论[M]. 北京: 科学出版社, 2014.
(0)
|
| [4] |
GABBAY D M, GUENTHNER F. Handbook of philosophical logic[M]. 2nd ed. 2001: 1–10.
(0)
|
| [5] |
陈波. 从人工智能看当代逻辑学的发展[J]. 中山大学学报论丛: 社会科学版, 2000, 20(2): 10-19. CHEN Bo. Artificial intelligence and contemporary logic study[J]. Supplement to the journal of sun Yatsen university, 2000, 20(2): 10-19. ( 0)
|
| [6] |
何华灿, 何智涛. 对智能科学逻辑基础研究的战略思考[J]. 智能技术, 2006, 1(2): 53-62. HE Huacan, HE Zhitao. Strategic thinking on the basic research of intelligent science logic[J]. Smart technology, 2006, 1(2): 53-62. ( 0)
|
| [7] |
何华灿, 刘永怀, 何大庆. 经验性思维中的泛逻辑[J]. 中国科学(D辑), 1996, 39(3): 225-234. HE Huacan, LIU Yinghuai, HE Daqing. Generalized logic in experience thinking[J]. Science in China series e-technological sciences, 1996, 39(3): 225-234. ( 0)
|
| [8] |
何华灿. 泛逻辑学原理[M]. 北京: 科学出版社, 2001: 1–18. HE Huacan. Universal logics principle[M]. Beijing: Science Press, 2001: 1–18. ( 0)
|
| [9] |
HE Huacan. Principle of universal logics[M]. Beijing: Science Press, 2006: 1–20.
(0)
|
| [10] |
BÉZIAU J Y. From paraconsistent logic to universal logic[J]. Sorites, 2001(12): 5-32. (0)
|
| [11] |
BEZIAU J Y. Logica universalis-towards a general theory of logic[M]. Basel: Birkhauser Verlag, 2005: 10–16.
(0)
|
| [12] |
HE Huacan. The outline on continuous-valued logic algebra[J]. International journal of advanced intelligence, 2012, 4(1): 1-30. (0)
|
| [13] |
盛骤, 谢式千, 潘承毅. 概率论与数理统计[M]. 4版. 北京: 高等教育出版社, 2008. SHENG Zhou, XIE Shiqian, PAN Chengyi. Probability and mathematical mtatistics[M]. 4th ed. Beijing: Higher Education Press, 2008. ( 0)
|
| [14] |
汪培庄. 因素空间与概念描述[J]. 软件学报, 1992, 3(1): 30-40. WANG Peizhuang. Factor space and description of concepts[J]. Journal of software, 1992, 3(1): 30-40. ( 0)
|
| [15] |
汪培庄, 李洪兴. 知识表示的数学理论[M]. 天津: 天津科学技术出版社, 1994: 1–12.
(0)
|
| [16] |
刘增良. 因素神经网络理论[M]. 北京: 北师大出版社, 1990: 7–13.
(0)
|
| [17] |
钟义信. 信息科学与技术导论[M]. 3版. 北京: 北京邮电大学出版社, 2015: 15–22.
(0)
|
| [18] |
ZHONG Yixin. The law of " information conversion and intelligence creation[M]//BURGIN M, HOFKIRCHNER W. Information Studies and the Quest for Transdisciplinarity. Singapore: World Scientific, 2017: 165–190.
(0)
|
| [19] |
ZHONG Yixin. A theory of semantic information[J]. China communications, 2017, 14(1): 1-17. (0)
|
| [20] |
何华灿. 智能论-关于人脑和其它各种系统中信息处理规律的科学[J]. 人工智能学报, 1982, 1(3): 1-18. HE Huacan. Intelligence-the science of information processing laws in the human brain and other systems[J]. Journal of artificial intelligence, 1982, 1(3): 1-18. ( 0)
|
| [21] |
[比]伊利亚·普里戈金. 确定性的终结——时间、混沌与新自然法则[M]. 湛敏, 译. 上海: 上海科技教育出版社, 1998: 1–12.
(0)
|
| [22] |
莫绍揆. 数理逻辑概貌[M]. 北京: 科学技术文献出版社, 1989: 45–56.
(0)
|
| [23] |
MCCULLOCH W S, PITTS W. A logical calculus of the ideas immanent in nervous activity[J]. Bulletin of mathematical biophysics, 1943, 5: 115-133. DOI:10.1007/BF02478259 (0)
|
| [24] |
MINSKY M L, PAPERT S. Perceptron[M]. Cambridge: MIT Press, 1969: 1–8.
(0)
|
| [25] |
王元元. 计算机科学中的逻辑[M]. 北京: 科学出版社, 1989: 1–25.
(0)
|
| [26] |
刘永怀. 基于广义范数的不确定性推理理论研究[D]. 西安: 西北工业大学, 1996: 20–34. LIU Yonghuai. Research on the uncertainty reasoning based on generalized norm[D]. Xi’an: Northwestern Polytechnical University, 1996: 20–34. ( 0)
|
| [27] |
贾澎涛. 基于柔性逻辑的时间序列数据挖掘研究[D]. 西安: 西北工业大学, 2008: 54–62. JIA Peng. Research on time series data mining based on flexible logic[D]. Xi’an: Northwestern Polytechnical University, 2008: 54–62. ( 0)
|
| [28] |
陈佳林. 柔性逻辑的健全性研究与应用[D]. 北京: 北京邮电大学, 2011: 1–21. CHEN Jialin. The study and application of flexible logic[D]. Beijing: Beijing University of Posts and Telecommunications, 2011: 1–21. ( 0)
|
| [29] |
周红军. 计量逻辑及其应用[M]. 北京: 科学出版社, 2015: 2–12.
(0)
|
| [30] |
祝峰, 何华灿. 粗集的公理化[J]. 计算机学报, 2000, 23(3): 330-333. ZHU Feng, HE Huacan. The axiomatization of the rough set[J]. Chinese journal of computers, 2000, 23(3): 330-333. ( 0)
|
| [31] |
张文修. 不确定性推理原理[M]. 西安: 西安交通大学出版社, 1996: 36–64.
(0)
|
| [32] |
何华灿, 何智涛, 王华. 论第2次数理逻辑革命[J]. 智能系统学报, 2006, 1(1): 29-37. HE Huacan, HE Zhitao, WANG Hua. On the second revolution of mathematical logic[J]. CAAI transactions on intelligent systems, 2006, 1(1): 29-37. ( 0)
|