

DOI: 10.11992/tis.201610015


2. 哈尔滨工业大学 建筑计划与设计研究所, 黑龙江 哈尔滨 150006;
3. 黑龙江省寒地建筑科学重点实验室, 黑龙江哈尔滨, 150006
2. Architectural Planning and Design Institute, Harbin Institute of Technology, Harbin 150006, China;
3. Heilongjiang Cold Region Architectural Science Key Laboratory, Harbin 150006, China
可拓建筑策划 (extension architectural program,EAP) 是将可拓创新方法引入建筑策划领域,通过问题界定、可拓分析、可拓变换、策略评价等一系列程序来生成创新策略的方法,其目的是指导建筑设计创新[1]。可拓建筑策划过程中急需对场地、规模、功能、空间、形象、技术等方面的性能指标进行科学预测的方法。
随着计算机辅助建筑设计 (CAAD) 和信息技术的迅速发展,互联网中的建筑案例已成为建筑师不可或缺的数据资源。案例辅助建筑设计已经引起建筑学界的广泛关注。魏力恺构建并开发了基于建筑空间关系原型的建筑案例检索系统Architable[2],孟洁提出了基于案例推理 (case-based reasoning) 的建筑方案设计流程[3],段正励等提出了基于ArcGIS软件的杭州市工业建筑遗产案例库构建与综合分析方法[4],张颉等提出了基于建筑信息模型的建筑空间拓扑关系提取插件和案例检索方法[5],孙澄等提出了基于神经网络的严寒地区办公建筑节能性能预测与形态设计方法[6]。然而,上述方法均未涉及互联网中的海量案例,也缺乏比较深入的案例分析方法。因此,研究互联网中案例数据获取及从中挖掘知识的方法将具有重要意义。
决策树是一种常用的分类预测工具。它通过建立一个模型或分类器来预测类别,其优势是需要的数据准备很少,不需要任何领域知识,既擅长处理连续型变量,也擅长处理建筑案例中常见的离散型变量。基于决策树知识的可拓知识挖掘方法是决策树分类和可拓创新方法相交叉的结果。首先利用递推的基本思想构造决策树,并从中提取规则,然后分析当前面对的矛盾问题,利用这些规则预测可拓变换的实施效果,进而筛选出可行的变换[7]。该方法能够预测可拓建筑策划项目的性能指标 (通常难以通过计算获得) 是否满足策划要求,并给出不满足要求情况下性能指标变换的途径。相关研究还有赵燕伟等提出的基于改进BP神经网络的可拓分类器构建方法[8];李亚飞等提出的基于决策树分类的云南省迪庆地区景观类型预测方法[9];王茂军等[10]提出的基于决策树法的北京城市居民通勤距离模式挖掘方法。针对互联网中的海量建筑案例,我们提出了基于决策树分类的可拓建筑策划预测方法。
1 建筑案例数据的获取和预处理 1.1 数据获取可拓建筑策划分类的对象是建筑案例库中的案例,用物元[11]描述为
 |
(1) |
式中:c1,c2,…,cn为建筑案例的特征;v1,v2,…,vn为建筑案例特征对应的量值。案例特征应尽可能反映建筑的全部信息,分为建筑所处环境特征和建筑物自身特征。前者包括建筑基地的社会、人文、交通、环境、景观、经济等方面,后者包括基本信息、设计构思、场地、功能、空间、形象、技术、评价等方面 (见表 1)。两者通过空间方位属性相关联,可以形成每栋建筑物的完整数据。
| 数据类型 | 数据特征 |
| 人口 | 人口数量、密度、结构比例等,人口职业、就业、拥有机动车数量、通勤出发时间、出行时长、出行方式等 |
| 经济 | 区域居民人均收入、居民消费状况等 |
| 交通 | 城市道路等级、交通拥堵状况、公共交通类型及站点分布等 |
| 环境 | 地形、地貌、土壤等地质特征,水质、水情等水文特征,气温、湿度、降水、风向、空气质量指数 (AQI) 等 |
| 设施 | 教育、商业、办公服务设施等 |
| 基本信息 | 项目名称、项目类型、项目性质、项目等级、高度类别、项目位置、项目造价、建筑师、设计团队、设计单位、委托单位、设计风格、设计时间、建成时间 |
| 设计构思 | 设计出发点、设计应对策略 |
| 场地 | 场地形状、地形呼应方式、建筑群体组合方式 |
| 功能 | 主体功能、附属功能 |
| 空间 | 空间类型、首层平面形状、标准层平面形状 |
| 形象 | 表皮处理方式、立面开窗方式、虚实对比程度 |
| 技术 | 结构类型、主体材料、辅助材料、主被动技术 |
| 评价 | 评价内容、评价等级 |
| 技术指标 | 规划面积、总建筑面积、容积率、地上层数、地下层数、建筑高度、建筑密度、停车位数量 |
数据获取是运用数据采集软件将互联网中的案例数据获取到建筑案例库的过程。鉴于智能性和稳定性,本文选用火车采集器,从政府门户网站、建筑策划与设计机构网站、建筑案例共享平台、各类百科等网站来采集案例。首先需要设置网址采集规则、内容采集规则、导入数据库规则和其他规则,数据采集结果以二维关系数据表形式存储在MySQL软件中,多个数据表之间以主键和外键相关联。另外,火车采集软件能够制定采集计划来完成建筑案例库数据的动态更新。
1.2 数据预处理在分类与预测之前,需要进行数据预处理,包括数据转换、数据集成、数据归约等。
数据转换是参照项目名称-空间位置对照表、建筑中英文对照表、建筑同义词对照表、计量单位转换表,对案例数据进行转换处理,解决数据语义多样性问题。
数据集成是将来自多个数据源的数据进行合并,以提高分类的速度和精确性。为统一格式,在数据集成中起关键作用的空间方位属性用 (E, N) 来表示,例如:哈尔滨工业大学建筑学院的空间方位属性,记作 (126°37′53.85″E, 45°45′02.16″N)。
数据集成时经常出现属性值缺失、数据不一致、数据存在噪声等问题,这些问题将对预测结果产生重大影响。噪声数据常用回归分析、离群点分析等方法来进行光滑处理[12]。缺失值通过以下方式来处理:1) 当缺失值恰好为分类特征时,直接删除该条数据;2) 使用全局常量,如Unkown来填充;3) 使用属性所有值的中心度量 (如均值或中位数) 来填充;4) 使用其他演算推理的方式来批量填充。
数据值域不一致往往将造成预测结果与意义难以解释,常用数据归约的方法进行标准化处理。
2 可拓建筑策划分类预测方法可拓建筑策划分类预测的核心是决策树算法,利用信息熵的原理,选择具有最高信息增益的特征作为分裂特征,递归地构建决策树的分支。它包括模型构建、模型检验、模型应用3个环节,具体分为评价特征选取、评价信息元集生成、决策树模型构建和当前策划项目指标预测4个步骤,如图 1所示。

|
| 图 1 基于决策树分类的EAP预测方法流程图 Fig. 1 Flow chart of the predict method for EAP based on decision tree classification |
通过前期访谈、现场调研、模式构想、方案试做等环节,建筑师已经确定当前建筑策划项目的基本特征。现需要对它的性能指标进行预测,检验是否满足策划要求。首先确定要预测的性能指标,在决策树分类时将这些指标称为分类特征,如建筑风格、空间开放性、流线合理性、技术可行性、环境协调性等。确定分类特征后,根据建筑专业知识,选取与之密切相关的评价特征,如与建筑风格相关的评价特征 (包括屋顶类型、立面色彩、建筑材料等)。有时某些评价特征可能并未出现在建筑案例表中,需要根据表中数据计算,如容积率可通过规划用地范围内建筑面积总和与用地面积的比值计算得到。
2.2 选取目标数据生成评价信息元集根据可拓建筑策划的预测要求,从建筑案例库中选取相关案例,应尽可能选择评价等级较高的数据,以保证分类结果的准确性。将取出的案例删除其他特征,只保留分类特征和评价特征,得到建筑案例的评价信息元集,记作
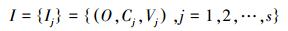 |
(2) |
该集合表示:对象O关于特征Cj的量值为Vj构成的信息元集合[7]。
将建筑案例评价信息元集随机地分为两组:一组是训练案例集,用于构建决策树模型,一般取建筑案例总量的80%~90%;另一组是检验案例集,取剩下的部分,用于检验模型的准确性。模型准确率是指检验案例集中被正确分类的建筑案例数量与该集合中建筑案例总数量的比值。
2.3 构建决策树提取分类规则知识决策树算法是将训练集递归地分裂成较小的子集,借助分裂准则来确定在每个结点上哪个属性能够产生最佳拆分[12]。用E(I) 表示对建筑案例评价信息元集I做出正确类别判断所需的信息量,记作
 |
(3) |
式中:pi是I中任意数据属于类Ci的概率,用|Ci|/|I|表示。
假设按评价特征A对I中的建筑案例进行划分,且特征A具有k个量值 (v1,v2,…,vk)。
2.3.1 特征A为离散型特征若特征A为离散型特征,如建筑平面类型、功能类型、空间组合形式等,将信息元集I分为k个子集(I1,I2,…,Ik),以特征A为根进行分类的信息熵定义为
 |
(4) |
式中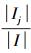
以特征A为根进行分类的信息增益定义为
 |
(5) |
为方便理解,将300个建筑案例组成的案例集作为信息元集,将建筑风格作为分类特征来说明决策树构建的原理。式 (3) 中,E(I) 表示未开始确定分裂特征时对300个案例进行分类所需的期望信息量。假定特征A是屋顶类型,可能取值为[坡屋顶、平屋顶、穹顶、其他类型屋顶],那么|I2|/|I|表示案例集中平屋顶的案例个数与案例总数的比。式 (4) 中,EA(I) 表示以屋顶类型为分裂点还需要的信息量。相应地,式 (5) 中G(A) 表示以屋顶类型进行划分我们得到了多少信息量。信息增量值越高,表明该特征对于分类的影响越大。根据式 (4)、式 (5) 可以求出其他特征 (如建筑材料) 的信息增益,选择信息增益最大的特征作为分裂特征。
2.3.2 特征A为数值型特征若特征A为数值型特征,如建筑面积、建筑层数等。首先将A的值按递增顺序排序,将每对相邻值的中点看作可能的分裂点,对于特征A的每个可能分裂点,计算EA(I),选择最小期望信息需求的点作为A的分裂点。I1是满足A≤分裂点的建筑案例集合,而I2是满足A≥分裂点的建筑案例集合。
决策树模型采用贪心算法,以自顶向下递归方式构建,直到达到下列条件之一终止:
①结点处的评价信息元属于同一个类;
②没有剩余特征用来进一步划分;
③给定的分支中没有信息元,即该子集为空,该结点不需要构建。
以上算法均在RapidMiner7.2软件中进行编辑,决策树模型的剪枝和准确性检验通过设置X-Validation命令的相关参数来完成,经过多次反复训练在很大程度上提升了模型的鲁棒性。
决策树模型构建完毕后,从根结点到叶结点的每条路径建立一个规则,以IF-THEN形式的分类规则表示,并用支持度 (support) 和置信度 (confidence) 进行评估。这些规则将形成分类知识库,作为建筑性能指标预测的依据。规则R可表示为R:A B [confidence,support]
以可拓建筑策划中的规则R1为例,R1可表示为
R1:屋顶类型=坡屋顶∧屋面材料=瓦片
建筑风格=欧式 (80%,40%)
上述规则表示,屋顶类型为坡屋顶并且屋面材料为瓦片的建筑案例中,建筑风格为欧式的案例占到80%。同时满足坡屋顶、屋面材料为瓦片、欧式风格的建筑案例占到所有案例的40%。
2.4 预测当前策划指标获取可拓变换途径提取当前建筑策划项目的评价特征,将其导入决策树模型,获得预测结果。若预测结果满足策划要求,则表明当前建筑策划方案是合理的,可以进入后续的建筑策划书生成与表达环节。
若预测结果不能满足策划要求,则需要改变当前建筑策划方案的某些特征,可拓学提供了5种基本变换,即置换变换、增删变换、扩缩变换、分解变换和复制变换,还有多特征的组合变换等。在可拓建筑策划中,可拓变换T定义为
 |
针对多特征的变换很容易产生组合爆炸,因此,需要对变换的结果进行取舍,获得可行的解变换,获取解变换的步骤如下。
1) 利用上述的决策树模型对变换后的项目数据进行预测,了解实施变换以后产生怎样的效果,并将预测结果中满足策划要求的变换提取出来,形成当前策划问题的解变换集。
2) 通过计算变换难度,对解变换集进行排序和评优。变换难度通过变换系数来定义:
①对于只存在类别差异,而不存在等级差异的建筑特征,如建筑平面类型、建筑材料类型等,无论变换为哪个值,变换系数都定义为1;
②对于存在等级差异的建筑特征,如建筑评价等级,当变换为降低等级时,无论降低几个等级,变换系数定义都为1;当提高一个等级时,变换系数定义为1;当提高两个等级时,变换系数定义为2,以此类推。
对于多个变换而言,其变换难度[7]按照每个变换系数加1后累乘再减1进行计算,定义为
变换难度=∏(变换系数+1)-1
对于建筑师而言,根据变换难度对解变换集进行排序后,排名越靠前的变换,可操作性越强,越容易产生最优策略。
3 实验与分析为了减少建筑建成后给周边环境带来的影响和破坏,在可拓建筑策划中需要预先评估建筑与周边环境的协调程度 (即建筑环境协调度)。因此,选取某建筑策划项目的建筑环境协调度预测为例,将火车采集器作为互联网案例数据抓取工具,将MySQL软件作为数据存储工具,将RapidMiner作为数据预处理和决策树构建工具,具体步骤如下。
1) 选取评价特征。首先将建筑环境协调度定义为分类特征,可能取值为差、一般、好,记作Y。根据建筑专业知识选取周边环境类型、总建筑面积、建筑主体材料、窗墙比、建筑与环境的形体穿插渗透关系 (即穿插渗透程度),并将这些参数作为评价特征,分别记作c1、c2、c3、c4、c5。为简化计算的难度,对评价特征的取值作出如下规定。
周边环境类型的可能取值为街道型、广场型、滨水型、植被型;总建筑面积的取值为原案例数据表中的值;建筑主体材料对原案例数据表中的材料进行归纳,可能取值为天然型、人工型、混合型;窗墙比将原案例数据表中的窗墙比数值进行归纳,可能取值为墙绝对主导型、墙主导型、窗墙对等型、窗主导型、窗绝对主导型,分别记作Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ;穿插渗透程度根据建筑与环境的穿插渗透关系进行评估,可能取值为无渗透、局部渗透、完全渗透。
2) 生成评价信息元表。通常直接从建筑案例库中选择案例数据。目前尚无这方面的数据,因此运用火车采集器抓取了ArchDaily网站最新发布的300个建筑案例,并导入MySQL中。经过转换评价特征值,填补缺失值,对不一致数据进行纠错后,最终得到建筑案例评价信息元表 (见表 2)。
| 序号 | 建筑名称 | 周边景观类型c1 | 总建筑面积c2/m2 | 建筑主体材料c3 | 窗墙比c4 | 穿插渗透程度c5 | 建筑环境协调度Y |
| 1 | 冰岛远足休息小屋 | 植被型 | 100 | 天然型 | Ⅱ | 完全渗透 | 好 |
| 2 | Linares科技园教学楼 | 广场型 | 4 800 | 人工型 | Ⅰ | 局部渗透 | 差 |
| 3 | 巴厘岛DRA住宅 | 滨水型 | 1 013 | 天然型 | Ⅱ | 完全渗透 | 好 |
| 4 | 双子住宅 | 植被型 | 743 | 混合型 | Ⅴ | 无渗透 | 好 |
| 5 | 南京国际青年文化中心 | 街道型 | 465 000 | 人工型 | Ⅲ | 无渗透 | 差 |
| 6 | 清华大学就业指导中心 | 街道型 | 21 000 | 天然型 | Ⅲ | 局部渗透 | 好 |
| 7 | Pink住宅 | 植被型 | 3 000 | 天然型 | Ⅲ | 局部渗透 | 好 |
| … | … | … | … | … | … | … | … |
| 300 | 悉尼邮轮码头 | 滨水型 | 4 600 | 混合型 | Ⅴ | 无渗透 | 一般 |
3) 构建决策树模型。首先,将评价信息元表导入RapidMiner软件,定义好分类特征后,运用X-Validation命令完成决策树模型的构建、检验与评估。该命令将评价信息元表随机分为10等份,依次将其中9份作为训练集,另外1份作为检验集,对模型进行10次评估,基本保证了该模型的鲁棒性。经评估,该模型准确率为84.60%,满足要求。其次,从上述模型中提取出决策树分类规则。由图 2和图 3可知,穿插渗透程度是影响决策树分类最显著的特征。

|
| 图 2 构建的决策树模型简图 Fig. 2 The chart of decision tree model |

|
| 图 3 提取的决策树分类规则 (部分) Fig. 3 The decision tree classification rules extracted |
4) 应用决策树模型。从当前建筑策划方案中提取该建筑的5项特征,其中周边景观类型c1为街道型,总建筑面积c2为4 000 m2,建筑主体材料c3为混合型,窗墙比c4为Ⅲ型,穿插渗透程度c5为无渗透,需要对建筑环境协调度Y进行预测。将该建筑数据导入上述决策树模型,预测结果为“差”,不满足策划要求。
为使预测结果变为“好”,需要对该建筑的特征实施可拓变换。由于基地条件限制,总建筑面积在建筑立项时已经确定,不能改变,因此,需要对特征c1、c3、c4、c5实施可拓变换,具体包括:
T11(Oi, c1, 街道型)=(Oi,c1, 广场型),
T12(Oi, c1, 街道型)= (Oi,c1, 滨水型),
T13(Oi, c1, 街道型)= (Oi,c1, 植被型),
T31(Oi, c3, 混合型)= (Oi,c3, 天然型),
T32(Oi, c3, 混合型)= (Oi,c3, 人工型),
T41(Oi, c4, Ⅲ)= (Oi,c4, Ⅰ),
T42(Oi, c4, Ⅲ)= (Oi,c4, Ⅱ),
…
T52(Oi, c5, 无渗透)=(Oi, c5, 完全渗透)
以上是针对单一特征值的变换,还包括多特征组合变换,最终共产生179(即4×3×5×3-1) 种变换,对应着179个变换后的策划项目数据。
利用决策树模型对这些数据进行预测。经测试,预测结果为好、一般、差的项目数据分别为69条、77条、33条。这69条数据对应的变换,即为当前策划问题的解变换。将项目数据按照变换难度重新进行排序,排名前5位的数据将作为最优策略提供给建筑师,用于指导策划方案修改 (见表 3)。
| 序号 | 建筑环境协调度Y | 周边环境类型c1 | 建筑主体材料c3 | 窗墙比c4 | 穿插渗透程度c5 | 可拓变换 | 变换难度 |
| 1 | 好 | 街道型 | 天然型 | Ⅲ | 局部渗透 | T31∩T51 | 3 |
| 2 | 好 | 街道型 | 混合型 | Ⅱ | 完全渗透 | T42∩T52 | 3 |
| 3 | 好 | 街道型 | 混合型 | Ⅳ | 完全渗透 | T43∩T52 | 5 |
| 4 | 好 | 广场型 | 人工型 | Ⅲ | 完全渗透 | T11∩T31∩T51 | 7 |
| 5 | 好 | 植被型 | 天然型 | Ⅱ | 无渗透 | T13∩T31∩T42 | 7 |
4 结论
基于决策树分类的可拓建筑策划预测方法是充分发挥可拓创新方法和决策树分类方法的优势,对当前策划项目的性能指标进行科学预测的方法。
1) 通过提出的建筑案例数据获取、数据预处理、决策树构建、分类预测、变换筛选等步骤,建筑师能够从互联网中的海量建筑案例中提取出决策树分类规则,并给出建筑性能指标的变换途径。
2) 案例检验表明,该方法是可行的,具有较强的操作性,能有效解决可拓建筑策划研究与应用的预测难题。
3) 将计算机领域的数据采集、决策树分类技术引入建筑学领域,能有效提升建筑师运用互联网数据的能力,加快计算机辅助可拓建筑策划的进程。
| [1] | 连菲. 可拓建筑策划的基本理论与应用方法研究[D]. 哈尔滨: 哈尔滨工业大学, 2010: 25-27. LIAN Fei. The study on basic theory and applying methods of extension architectural program[D]. Harbin: Harbin Institute of Technology, 2010: 25-27. |
| [2] | 魏力恺. 基于CBR和HTML5的建筑空间检索与生成研究[D]. 天津: 天津大学, 2013: 108-114. WEI Likai. Architectural spatial retrieval and generating based on CBR and HTML5[D]. Tianjin: Tianjin University, 2013: 108-114. |
| [3] | 孟洁. 基于案例推理的建筑方案设计流程研究[D]. 哈尔滨: 哈尔滨工业大学, 2014: 56-76. MENG Jie. Research on architectural scheme design process using case-based reasoning[D]. Harbin: Harbin Institute of Technology, 2014: 56-76. |
| [4] |
段正励, 刘抚英. 杭州市工业遗产综合信息数据库构建研究[J].
建筑学报, 2013, 33 (10): 45-48.
DUAN Zhengli, LIU Fuying. Study on the comprehensive information database of industrial heritage in Hangzhou[J]. Architectural journal, 2013, 33(10): 45-48. |
| [5] |
张颉, 李昌华, 李智杰. 基于拓扑特征的建筑信息模型检索方法[J].
计算机应用研究, 2016, 33 (3): 916-921.
ZHANG Jie, LI Changhua, LI Zhijie. Building information model retrieval based on topological features[J]. Application research of computers, 2016, 33(3): 916-921. |
| [6] |
孙澄, 韩昀松. 光热性能考虑下的严寒地区办公建筑形态节能设计研究[J].
建筑学报, 2016 (2): 38-42.
SUN Cheng, HAN Yunsong. A study on energysaving design of office building forms in the severe cold region regarding daylighting and thernal performanc[J]. Architectural journal, 2016(2): 38-42. |
| [7] | 杨春燕, 李小妹, 陈文伟, 等. 可拓数据挖掘方法及其计算机实现[M]. 广州: 广东高等教育出版社, 2010: 206-214. |
| [8] |
赵燕伟, 任设东, 陈尉刚, 等. 基于改进BP神经网络的可拓分类器构建[J].
计算机集成制造系统, 2015, 21 (10): 2807-2815.
ZHAO Yanwei, REN Shedong, CHEN Weigang, et al. Extension classifier construction based on improved BP neural network[J]. Computer integrated manufacturing systems, 2015, 21(10): 2807-2815. |
| [9] |
李亚飞, 刘高焕, 黄翀. 基于决策树分类的云南省迪庆地区景观类型研究[J].
资源科学, 2011, 33 (2): 328-334.
LI Yafei, LIU Gaohuan, HUANG Chong. Exploring landscapes based on decision tree classification in the Diqing region, Yunnan province[J]. Resources science, 2011, 33(2): 328-334. |
| [10] |
王茂军, 宋国庆, 许洁. 基于决策树法的北京城市居民通勤距离模式挖掘[J].
地理研究, 2009, 28 (6): 1516-1527.
WANG Maojun, SONG Guoqing, XU Jie. Data mining on commuting distance mode of urban residents based on the analysis of decision tree[J]. Geographical research, 2009, 28(6): 1516-1527. |
| [11] | YANG Chunyan, CAI Wen. Extenics: theory, method and application[M]. Beijing: Science Press, 2013: 20-27. |
| [12] | HAN Jiawei, KAMBER M, PEI Jian. 数据挖掘: 概念与技术[M]. 范明, 孟小峰, 译. 3版. 北京: 机械工业出版社, 2012: 55-65. |