

DOI: 10.11992/tis.201605019


2. 厦门大学 福建省仿脑智能系统重点实验室,福建 厦门 361005
2. Fujian Key Laboratory of the Brain-like Intelligent Systems, Xiamen 361005, China
时下,社交媒体正成为人们生活中不可或缺的一部分,通过微博、微信等工具,人们可以随意发表对电影、商品的喜恶,对社会事件的个人观点,甚至对国家政策的看法。如何从包含这些信息的大规模数据中获取诸如情感倾向在内的潜在信息,对于产品导向、广告精确投放、国家舆情控制等领域都具有重要意义,社交信息的数据挖掘与分析正成为研究者们关注的热门课题。
对英文社交媒体(如Tweet)的情感分析已经有很多进展,分析的方法主要分为有监督方法[1-5]和基于词典或逐点互信息(PMI)[7]的无监督方法。而类似针对中文社交媒体的情感分析工作则仍处于起步阶段,所使用的方法大都源于英文情感分析方法,但由于社交媒体表现形式的多样化和中文网络语境多变性等原因,传统分类方法仍存在很大改进空间,本文针对目前存在的两个问题进行建模:
1) 情感词典时效性差,中文新词的出现更为频繁,基于统计的方法在短周期内难以判断其情感;
2) 传统方法未考虑多情绪源之间的关联。
这里的多情绪源是指微博中可能出现的能够体现其情感的多种异构特征,如情感词、表情符号、图片和视频等。并且这些情绪源之间存在以下在情感分析上可以进行互补利用的关联关系:
1) 不同情绪源表达的情感强度可能不同,强情绪源可以对弱情绪源进行极性加强;
2) 同一情绪下不同情绪源之间存在较强的关联性,例如在“哈哈”表情下出现正情感词的概率较大。
根据以上分析,我们提出了一种多情绪源关联模型,该模型对微博中的情感词和表情符号两种情绪源及其之间的关联进行建模。我们的实验结果显示,该模型在微博数据上优于经典分类算法,并且该模型具有拓展性,可以继续加入诸如图片和视频在内的其他情绪源。
1 情感分析相关工作文本情感分析近几年逐渐成为热门研究课题,其内容主要包括情感极性分析和主客观分析等,本文主要关注情感极性分析。目前情感极性分析的方法主要分为两类:有监督的分类器学习方法和无监督的基于情感词典或者PMI的方法。
1.1 有监督方法有监督方法大多通过机器学习技术从文本中选取合适的特征构建分类器,包括朴素贝叶斯、最大熵和支持向量机等,进而对不同情感进行分类。
分类器选择上,Pang等[1]用以上3种分类器将影评分为正、负两类极性,引入了一元语法特征、二元语法特征、词性特征和词位置特征等8种组合特征, 最终使用基于出现与否的一元语法特征SVM分类器效果最好,在其语料集中达到83%的准确率。
特征选择上,D.Kushal等[2]对语法规则、n-gram特征进行了分析;Hatzivassiloglou等[3]使用了情感词作为特征,对句子级别的情感倾向进行了分析;J.C.Na等[4]对指定词语和否定短语特征进行了分析。
这类机器学习方法,例如多特征SVM情感分类方法,并未考虑到不同特征之间的关联关系。
1.2 无监督方法无监督方法利用文本中带有情感的词汇的情感倾向,综合考虑文本的语法规则、句法构成等要素对文本进行情感极性的判别,通常采用投票的方法。在该类方法中,主要依靠文本分析,并未关注社交媒体信息中情绪源多并且不同情绪源之间存在关联性的特点。
基于情感词方法的基础是判断词的情感,对词汇的情感判断方法包括:基于情感词典、基于监督学习[5]和基于种子词[7-9]的方法等。
常用的中文情感词典有知网情感分析用词语集、台湾大学中文情感极性词典(NTUSD)和大连理工大学中文情感词汇本体库等。基于情感词典的方法主要缺陷在于覆盖面窄、无法包含网络新词。
Wilson等[5]提出了一种二步分类的有监督方法判断短语的极性:1) 判断将短语分类为有极性和中性; 2) 将第1步中得出的有极性短语进一步划分为4类极性,每一步使用不同的特征进行分类,分类器相同(BoosTexter AdaBoost.HM[6])。最终在其数据集上准确率达到75.9%。
Turney[7]提出了一种判断单词情感的方法,通过在大规模语料集中分别计算目标单词与正负极性种子词(正种子词:excellent;负种子词:pool)的逐点互信息,将两个结果进行对比得出目标单词的情感,最终在其数据集中达到82.8%的准确率,缺点是需要大规模语料集,运算量大。
此外,Xia H.等[9]研究了英文社交媒体中出现的情感标记信号在无监督情感分析中的应用,取得了良好的效果。
1.3 中文微博情感极性分析研究现状中文微博情感极性分析主要方法来源于上文提及的英文文本情感分析相关方法[10]。
目前,由中国中文信息学会(CIPS)主办的中文倾向性分析评测(The Fifth Chinese Opinion Analysis Evaluation, COAE)聚集了该领域大量研究成果。COAE评测由2008年开始每年举办一次,发布中文倾向性分析的相关任务,包括情感识别、新词发现、观点句提取和评价对象识别等。表 1给出了COAE2013 http://ccir2013.sxu.edu.cn/COAE.aspx任务1(基于否定句的句子级倾向性分析)的最佳评测结果。
| 参数 | 褒义 | 中性 | 贬义 |
| 准确率 | 0.741 | 0.445 | 0.836 |
| 召回率 | 0.619 | 0.725 | 0.464 |
| F1 | 0.674 | 0.551 | 0.597 |
| 精度 | 0.615 |
最佳结果[11]使用了集成学习的方法,通过多次欠采样训练NB、ME、SVM基分类器,通过product rule融合多个基分类器。该方法针对标注数据集较少的情况,提高了分类器的鲁棒性和泛化能力。
在中文微博情感分析的多种方法中,SVM方法虽然引入了不同特征,但是认为特征之间相互独立;基于规则投票的方法主要依赖情感词典和语法规则,也有引入表情符号等情绪源的方法,但未考虑不同情绪源之间的关联。
此外,谢丽星等[12]提出了基于层次结构的SVM分类方法,选取主题相关特征构建分类器对微博情感进行三分类。通过分句考虑了3类极性的句子数目以及首尾句情感极性,并且依据主题选取了多种特征训练分类器,在其数据集上达到67.283%的准确率。但通过对我们的6171条微博进行分析发现,句子数目大于2的微博仅占12%,因此分句对情感分析效果不大。此外由于本文针对没有主题标签的微博,因此最终在实验中选择文献[12]中与主题无关的不分句最佳特征SVM以及无关联多情绪源模型作为对比方法。
2 算法实现多情绪源关联模型受基于词典投票的情感分析方法启发,对包括情感词在内的多情绪源及其间的关联进行建模(本文只考虑情感词和表情两种情绪源)。因此本章从基于词典投票的分类模型,到加入表情特征进行改进,近而引入后验概率联合建模3个过程来介绍模型的产生原理,最后介绍多情绪源关联模型的构建方法(算法将微博分为负面、中性和正面3种情感)。
2.1 原理框图图 1~3分别展示了3种情感分类模型的组成原理,可以看出相比其他两类模型只考虑单一或者相互独立的情绪源特征,本文提出的多情绪源关联模型综合考虑了不同情绪源及其之间的关联进行建模,并且在第2.4节的实验中证明了这种关联对于情感分析的作用。

|
| 图 1 情感词投票模型 Fig. 1 Word voting model |

|
| 图 2 无关联模型 Fig. 2 Uncorrelated model |

|
| 图 3 多情绪源关联模型 Fig. 3 Emotional multi-source correlation model |
本节介绍了传统方法中基于情感词典投票的情感分类模型,并对其进行了概率转换,再依据否定词和感叹句对情感词极性进行了修正。
2.2.1 情感词典概率模型基于情感词典的分析方法将情感词典中标注为正负极性的情感词作为特征,先对文本进行分词(本文中涉及的分词工具使用了中科院计算所开发的ICTCLAS50分词系统http://www.ictclas.org/),将正负情感词在文本中出现次数的差值作为文本正负情感判断的依据。根据式(1)进行极性投票判断。
 |
(1) |
如果将以上判断方法用概率模型进行表示,可以得到式(2)。
 |
(2) |
式中: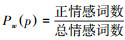

针对中文微博里存在否定词、感叹句等语法结构的特点,本文对情感词的极性权值进行了修正。
与文献[12]中类似,模型对否定词的出现进行了处理,自定义了24个常用否定词,如表 2所示,将以否定词为中心,大小为3窗口的中出现的情感词极性反转。
| 自定义否定词 |
| 不、不会、不可能、不是、不应该、并非、并不、不、不会、没、无、非、莫、勿、未、否、别、无、不曾、未必、没有、不要、难以、未曾、毫无、毫不 |
感叹句通常起到的是加强语义的作用,而对于语句的情感影响也会起到类似的加强效果。我们认为出现感叹句的句子中,情感词表达效果翻倍,因此使用了最为直接的处理方法,将感叹句中的情感词个数在原基础上乘以2。
2.3 无关联的情感词和表情模型很多情况下,单独使用情感词难以判断微博所表达的极性,因此可以通过引入其他情绪源来综合判断极性,我们考虑了表情符号作为联合特征,因为表情和情感词在微博情感分析中具有如下优势互补的特性。
1) 微博中情感词分布广泛,一条微博中往往包含多个情感词。但仅利用情感词进行情感判别的缺点在于情感词典时效性差:情感新词出现较频繁,但刚出现时数量少,使用基于统计的新词极性判别方法在新词出现初始周期内难以对新词进行识别和判断。
2) 微博上表情符号的使用相对固定,但利用表情进行情感判别的缺点在于一条微博中表情个数不多,同时并非所有微博都包含表情。
此外,经过试验表明,微博表情特征的以下特点也能够提升情感分类效果:
1) 微博表情对情感的表达比文本更为直接和显著;例如微博“终于通关了
2) 微博表情可能直接作为句子成分出现在句子当中。例如“今天下雨了,不过
因此我们对情感词和表情符号联合建模,以综合利用二者在微博情感判断中的互补优势,和表情特征的自身判别优点,具体模型如式(3)~(5)所示:
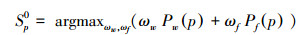 |
(3) |
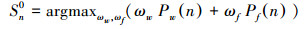 |
(4) |
 |
(5) |
式中:

2.3节模型认为情感词与表情之间是相互独立的,没有考虑情感词和表情之间的关联关系,以及这种关系对情感极性判断的影响,因此这里引入了后验概率对其进行修正。
表 3给出了一个例子,在该例中,虽然出现的情感词都为正极性,但表情符号却只有负面表情,通过2.3模型进行判断,将这条微博错分成负极性。
| 类型 | 实例 |
| 正面情感微博 | 天兔遇上给力的海航,终于跟坐快艇似的回到广州。杭州之行说起来还算圆满吧,多年未见的大学死党、越来越漂亮的老妹鱼头阿奋来平,还有闺蜜菁菁茜女人想念大家了。表情:“泪” |
| 正情感词 | 给力;圆满;漂亮 |
| 负表情符号 | 泪 |
通过2.3中的方法,对这条微博的情感极性判断为负,但实际极性为正面情感。我们引入了概率模型P(w, f|p),P(w, f|n)来增强类似的情感极性判断,构建了关联模型(6)~(8):
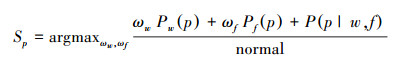 |
(6) |
 |
(7) |
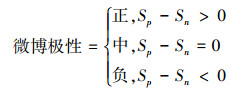 |
(8) |
式中:normal为归一化因子。
 |
P(p|w, f)和P(n|w, f)计算如下(默认P(p)=P(n)=0.5):
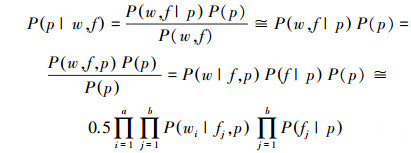 |
(9) |
类似地
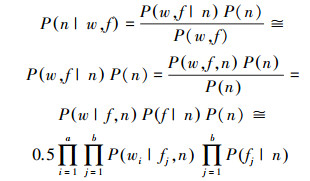 |
(10) |
式中:a和b分别表示一条微博中情感词和表情符号的个数。而P(wi|fj, p)、P(fj|p)、P(wi|fj, n)、P(fj|n)是对数据集进行统计后得出的结果。该模型认为词与词(表情与表情)之间相互独立;但是词与表情、词与微博极性、表情与微博极性之间存在关联,用情感词与表情之间的关联得出的结果来改善原始结果。
此外,为了消除P(p|w, f)与P(n|w, f)中多小数相乘使值过小的问题,实际计算时,取
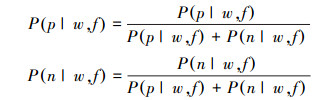 |
在表 3所示的示例中,使用2.3节中的方法进行极性判断,结果如下:
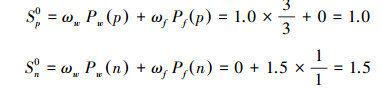 |
因此,Sp0-Sn0 < 0,3.3判断为负极性,而在关联模型中:P(p|w, f)=1,P(n|w, f)=0,Sp-Sn=0
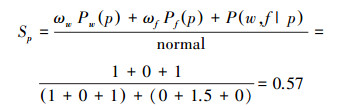 |
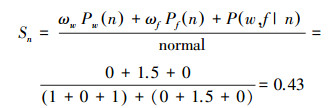 |
Sp-Sn=0.14>0,最终结果为正性(本数据集下,取ωw=1,ωf=1.5)。分类正确的原因是通过“泪”与上述情感词之间的关联性,考虑了“泪”与上述情感词出现情况下,分类为正极性的概率。
多情绪源关联模型不限于情感词和表情符号两个情绪源,可以通过加入更多的情绪源,例如图片、视频等,来拓展关联模型。
3 实验结果与分析 3.1 实验数据及验证方法上文中提及的COAE评测给出了公共数据集,但由于其数据集中所包含的有表情微博数量十分稀少,不适合测试本方法,因此本文通过新浪微博API爬取微博信息,并对爬取的6 171条微博进行了人工标注,经过统计,微博数据来自社会、电影、电视剧、美食、娱乐八卦、科技等多个领域。
所选择数据集中正极性微博所占比例偏大,中极性比例偏小,并且含有表情的微博较多(主要分布于电影、电视剧、娱乐八卦和美食等领域),但用于比较的各个分类方法所用数据集相同,不会对结果比较造成影响。
我们所使用的情感词典为大连理工大学中文情感词汇本体库http://ir.dlut.edu.cn/EmotionOntologyDownload.aspx?以及自定义的少量新词(如坑爹、给力等),一共27 488个(正极性词13 556个,负极性词13 932个)。在分词时,使用ICTCLAS50自定义词典接口,调用了情感词典和否定词典。
模型中,使用表情符号和情感词进行了联合建模,表情符号选择微博常用表情中默认的50个表情符号,如
| 极性 | 微博数目 | 比例/% |
| 正极性 | 4 196 | 67.9 |
| 中性 | 621 | 10.0 |
| 负极性 | 1 354 | 21.9 |
| 含表情微博 | 5 182 | 84 |
3.2 对比实验说明
对比实验1采用文献[12]中一步三分类最佳特征组合(去除了情感短语和中文是否出现这两个特征),此外因为本文数据集中的微博包含的多句子情况少,因而不考虑分句的情况进行第2次分类;同时本文的情感极性分析针对无主题标签的微博,因此不考虑主题特征。在文献[12]所做的实验中,url特征与主客观分类对最终效果有负面影响,因此也不将这两个因素考虑在内。此外,选用的情感词典和表情符号、标点符号也与之不同。最终使用的特征表示如表 5所示,用词袋模型(BOW)表示。其中否定词采用与3.2.2中相同处理方法。对比实验二采用3.3节中方法。实验采用五折交叉验证。
| 序号 | 类型 | 特征描述 | 维度 | 备注 |
| 1 | 表情 | 正、负向表情符号个数(50个表情) | 2 | 微博常用表情中的默认表情 |
| 2 | 情感词 | 正、负向情感词个数(2 461个情感词) | 2 | 使用大连理工大学词典 |
| 3 | 形容词 | 形容词个数 | 1 | |
| 4 | 动词 | 动词个数 | 1 | |
| 5 | 感叹号 | 是否出现!或! | 1 | |
| 6 | 问号 | 是否出现?或? | 1 |
3.3 实验结果及分析
分类器说明:
1) 关联模型:多情绪源关联模型(情感词、表情关联建模);
2) NB:朴素贝叶斯模型,所使用的特征与对比实验一的SVM方法相同,使用BOW表示特征;
3) 传统词典:传统的基于情感词典以及规则进行投票的方法(2.2中的方法);
4) 词典+表情:传统基于情感词典及规则进行投票的方法,辅以表情特征(2.3中的方法)。
5) SVM:文献[12]中一步三分类方法。
从表 6的实验结果可以看出,本文提出的多情绪源关联模型分类效果最佳,达到85.3%,比传统基于情感词加表情投票的方法高出了1.9%,比同类多特征SVM高出了2.4%。说明了对情绪源进行关联性建模,能够有效提高情感分类效果,表明不同情绪源之间的关联关系与情感极性也是相关的。缺点在于对情绪源单一的微博(例如无表情的微博)则主要依赖于传统情感词典分类方法。
| 方法 | 正极性 | 中极性 | 负极性 | 准确率 | |||
| P | R | P | R | P | R | ||
| 关联模型 | 0.906 | 0.945 | 0.506 | 0.395 | 0.806 | 0.779 | 0.853 |
| NB | 0.945 | 0.753 | 0.270 | 0.747 | 0.657 | 0.537 | 0.705 |
| 传统词典 | 0.833 | 0.617 | 0.162 | 0.617 | 0.608 | 0.312 | 0.550 |
| 词典+表情 | 0.894 | 0.925 | 0.507 | 0.369 | 0.750 | 0.763 | 0.834 |
| SVM | 0.870 | 0.945 | 0.538 | 0.330 | 0.769 | 0.702 | 0.829 |
| 注:P、R分别表示准确率(Precision)和召回率(Recall)。 | |||||||
3.4 错误分析
本节中对混合概率模型的错误分类样本进行了分析,研究了造成分类错误的原因,如表 7所示。
| 序号 | 错误类别描述 | 示例 |
| 1 | 情感词未包含在词典中 | 各种消失。信号标识消失时间消失电池电量各种消失苹果系统ios7真心是坑爹啊。 |
| 2 | 无表情符号特征 | 有时候突然不能输入中文,关机重启后正常。已发生两次。 |
| 3 | 负面表情或情感词表达正面或中性情感 | 略凶残的相机效果,自恋狂可以点赞。 |
| 4 | 反问句式加强了负面情感 | 坑不坑! |
| 5 | 反讽句式 | 3天内出现4次这种情况,还能不能一起愉快地玩耍了? |
| 6 | 转折句式 | 其实我还是挺喜欢ios7的如果他不卡的话 |
| 7 | 正面表情表达中性 | 同志们不好意思,我刚才发错了,那个是草稿箱里的表情:“嘻嘻”“哈哈” |
实验结果表明,在缺乏表情符号特征的微博中分类效果较差,主要原因还是由于当没有表情特征时,分类器只依赖于情感词以及简单规则进行分类。此外,对转折句、反讽句等句式的判断存在不足,原因是微博中很多反讽句式的出现往往是伴随着网络新词出现的,并且没有明显的句式标识词(例如,“这小偷真是太机智了”),使得对反讽句和转折句的判断比较困难。
3.5 对比分析通过在同一数据集上对不同模型的实验表明,多情绪源关联模型能够很好地解决基于情感词判别方法时效性差的问题,并且在分类时综合考虑了不同情绪源之间的关联性,提高了分类效果。相对于对比实验2的普通情感词和表情建模的方法,多情绪源关联模型通过引入后验概率,利用情感词与表情符号之间的关联性,加强情感判断性能。另外,使用对比实验1中的SVM分类器时,虽然加入了包括表情、否定词在内的多特征,但认为不同特征之间相互独立。多情绪源关联模型所能解决的一些错分类问题如表 8所示。
| 序号 | 错误类别描述 | 示例 | 关联模型 | SVM模型 | 3.3模型 |
| 1 | 情感词与表情间的关联关系主导分类结果 | 趴在墙上不能更萌 表情:“可怜” | 正确 | 错误 | 错误 |
| 2 | 微博包含否定词 | 这啥,太不稳定了,又抽风般地自己好了 | 正确 | 正确 | 正确 |
| 3 | SVM误判 | 祈福。我叫不生气!! 表情:“蜡烛”“生病”“抓狂” | 正确 | 错误 | 正确 |
4 结论及展望
新浪微博作为时下最为流行的社交网站之一,不仅是民众钟爱的社交工具,更是研究者挖掘数据的天堂,其商业价值和学术价值都不断升温。本文对微博数据挖掘领域的情感分析进行了研究,提出多情绪源关联模型,针对传统基于词典的方法重新进行了关联性建模,使得分类准确率相比传统模型(3.3节模型)提高了1.9%;相比多特征SVM提高了2.4%。但该方法仍是较为简单的情感分析方法,就方法本身而言,也存在很大的提升空间,可以对以下几个方面进行改进:
1) 拓展模型,引入更多情绪源,包括图片和视频等,使模型更适合于微博语境。
2) 在概率模型中引入更加复杂的语法规则分析,例如祈使句式、多重否定、反讽句等;
3) 挖掘微博用户之间的社交网络关系对情感分析的影响,通过有关联用户来参与判断情感。
| [1] | PANG Bo, LEE L, VAITHYANATHAN S. Thumbs up?:sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA:ACM, 2002, 10:79-86. |
| [2] | DAVE K, LAWRENCE S, PENNOCK D M. Mining the Peanut gallery:opinion extraction and semantic classification of product reviews[C]//Proceedings of the 12th International Conference on World Wide Web. Budapest, HU:ACM, 2003:519-528. |
| [3] | YU HONG, HATZIVASSILOGLOU V. Towards answering opinion questions:separating facts from opinions and identifying the polarity of opinion sentences[C]//Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA:ACM, 2003:129-136. |
| [4] | NA J C, SUI H, KHOO C, et al. Effectiveness of simple linguistic processing in automatic sentiment classification of product reviews[C]//MCILWAINE I C. Knowledge Organization and the Global Information Society:Proceedings of the Eighth International ISKO Conference. Wurzburg, Germany:Ergon Verlag, 2004:49-54. |
| [5] | WILSON T, WIEBE J, HOFFMANN P. Recognizing contextual polarity in phrase-level sentiment analysis[C]//Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA:ACM, 2005:347-354. |
| [6] | SCHAPIRE R E, SINGER Y. BoosTexter:a boosting-based system for text categorization[J]. Machine Learning , 2000, 39 (2/3) : 135-168 DOI:10.1023/A:1007649029923 |
| [7] | TURNEY P D. Thumbs up or thumbs down?:semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA, USA:ACM, 2002:417-424. |
| [8] | 朱嫣岚, 闵锦, 周雅倩, 等. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报 , 2006, 20 (1) : 14-20 ZHU Yanlan, MIN Jin, ZHOU Yaqian, et al. Semantic orientation computing based on HowNet[J]. Journal of Chinese information processing , 2006, 20 (1) : 14-20 |
| [9] | HU Xia, TANG Jiliang, GAO Huiji, et al. Unsupervised sentiment analysis with emotional signals[C]//Proceedings of the 22nd international conference on World Wide Web. Rio de Janeiro, Brazil:ACM, 2013:607-618. |
| [10] | 赵妍妍, 秦兵, 刘挺. 文本情感分析[J]. 软件学报 , 2010, 21 (8) : 1834-1848 ZHAO Yanyan, QIN Bing, LIU Ting. Sentiment analysis[J]. Journal of software , 2010, 21 (8) : 1834-1848 DOI:10.3724/SP.J.1001.2010.03832 |
| [11] | 魏现辉, 任巨伟, 何文译, 等. DUTIR:中文短文本倾向性分析及要素抽取方法研究[C]//第五届中文倾向性分析评测研讨会论文集.太原, 2013:116-129. WEI Xianhui, REN Juwei, HE Wenyi, et al. DUTIR:method research of sentiment analysis and elements extraction of Chinese short text[C]//Proceedings of the Fifth Chinese Opinion Analysis Evaluation. Taiyuan, 2013:116-129. |
| [12] | 谢丽星, 周明, 孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取[J]. 中文信息学报 , 2012, 26 (1) : 73-83 XIE Lixing, ZHOU Ming, SUN Maosong. Hierarchical structure based hybrid approach to sentiment analysis of Chinese micro blog and its feature extraction[J]. Journal of Chinese information processing , 2012, 26 (1) : 73-83 |