

DOI: 10.11992/tis.201603050

 , , ,
, , ,
2. 北京交通大学 交通数据分析与挖掘北京市重点实验室, 北京 100044
, , ,
2. Beijing Key Lab of Transportation Data Analysis and Mining, Beijing Jiaotong University, Beijing 100044, China
Egocentric视频是通过固定在拍摄者头、肩、手等部位或由拍摄者手持的穿戴式摄像机,在拍摄者自由运动过程中所拍摄的。Egocentric视频具有背景变化剧烈、目标尺度差异明显和视角时变性强的特点,同时存在拍摄视频不平顺、运动模糊、噪声大等问题,为基于此的计算机视觉任务带来极大的挑战。Multi-Egocentric视频是由处于同一场景中的多个个体所拍摄的不同视角、不同运动轨迹的视频,研究基于multi-egocentric视频的目标检测和匹配对于后续的场景理解等高级视觉任务具有重要的意义。
由于场景的复杂性和运动的多样性,基于视频的显著目标检测一直都是计算机视觉研究领域的难点问题之一。基于单视角视频的目标检测主要有基于单帧图像通过特征提取训练目标检测器的方法,如Pedro Felzenszwalb等[1]提出的可变性组件模型(deformable part model,DPM),基于目标成员的可变形部位,结合边界敏感的方法挖掘负样本,训练隐性支持向量机(latent,SVM)分类器检测目标,但对于视频中距离镜头较远的目标有漏检的情况;Lubomir Bourdev等[2]提出Poselet模型用带标注的三维人体动作关节点数据集训练SVM分类器,以检测人的头、躯干、背部等部位,该算法在清晰图像上取得较好的效果,但对于低质图像漏检率较高;利用时空特征和表面特征相结合的训练方法,如Philippe Weinzaepfel[3] 提出运动边模型(motion boundary,MB)将图像局部区域的颜色、光流以包的形式训练随机森林模型,得到的支持向量机(SVM)分类器可检测精确的目标边缘,但当目标无明显运动时,边缘检测结果不佳;基于多视角视频的目标检测利用多个不同视角的监控视频跟踪目标,检测目标行为,如KSusheel Kumar等[4]提出的实时多视角视频跟踪算法,应用在安全系统中。
Egocentric视频的分析和处理是近年来的研究热点之一,目前的研究主要集中于估计拍摄者所关注的显著区域,例如Hyun Soo Park[5]提出利用群体模式的几何关系得到成员交互关系,经训练后得到分类器预测显著区域,但此类方法无法获得显著区域中成员的精确位置;Lin等[6]在多个视频中利用不同运动模式对成员做匹配,然后利用条件随机场寻找时空一致性最高的成员,即为当前最显著成员,但此类方法需要每个成员同一时刻的动作具有差异性;通过多个视频寻找匹配点利用透视图原理计算出多个成员的位置和姿态,如Hyun Soo Park等[5]通过SfM[7]方法,恢复三维场景及成员位置和姿态,实现场景理解;利用多个视频间的相互运动关系进行成员检测,如Ryo Yonetani等[8] 利用一对成员互相拍摄的视频,根据超像素分割单位区域的局部相对运动和全局运动信息搜索其中一个成员,但此方法一次只能检测一个拍摄视频的成员面部。上述传统的基于视频的显著目标检测方法大多基于固定视角或视角微变的视频,而multi-egocentric视频中场景变化剧烈,目标运动稳定性低,如DPM[1]在视角变换剧烈时的检测效果下降;Poselets[2]算法在图像有轻微运动模糊时的性能受到较大影响;Motion Boundaries[3]算法在目标尺寸较小时出现漏检。基于此,本文提出了一种两步层进目标检测算法,将目标检测分为粗检测阶段和细检测两阶段,从而提高了基于Egocentric视频的目标检测的鲁棒性,并提出了multi-egocentric视频中的目标匹配算法,实现了多视角多目标的匹配。算法流程图如图 1。

|
| 图 1 本文算法流程(n为相机个数,即视角数,βi,i=1,2,…,11为目标编号) Fig. 1 The framework of our method (n represents the number of camera,βi,i=1,2,…,11 is target number) |
两步层进目标检测算法的主要思想是首先粗略定位目标位置,其次优化目标区域。算法分为两步:第1步是基于Boosting[9]模型的目标粗定位方法,融合多个检测器结果,最大限度覆盖目标区域,此种方法在一定程度上克服了Egocentric视频背景变化剧烈、目标尺度差异明显和视角时变性强等特点导致的检测结果不完整、漏检、错检等问题,提高了算法的鲁棒性;第2步采用基于局部相似度的区域优化方法对目标轮廓进行优化,得到更精确的目标区域。
1.1 基于Boosting模型的目标粗检测算法设输入的Egocentric视频集合为ψ={cl|l=1,2,…,n} ,其中n为视频个数,cl表示第l个相机拍摄的视频,则第l个视频的第j帧图像表示为f lj。假设有一系列目标检测器ξ={κi|i=1,2,…,m},其中m为检测器个数,κi表示第i个检测器,则第i个检测器针对图像f lj的检测结果用集合Blij来表示,且Blij={blijk|k=1,2,…,zlij},其中zlij 为检测器κi在图像f lj上检测出的目标个数,blijk=[xlijk ylijk $\tilde{x}$lijk $\tilde{y}$lijk slijk],xlijk、ylijk、$\tilde{x}$lijk、$\tilde{y}$lijk分别表示blijk的左上角x坐标、左上角y坐标、右下角x坐标、右下角y坐标、slijk表示blijk为显著目标的概率,且slijk∈(0,1),则所有检测器对图像f lj的检测结果为$B_{l}^{j}=\bigcup\limits_{i=1}^{m}{B_{li}^{j}}$。本文取m=4,分别为Motion Boundaries[3](MB)算法、DPM[1]算法、Poselets[2]算法和空间金字塔池化(sptial pyramid pooling,SPP Net )[10]算法。算法流程如图 2所示,图中Color表示仅用颜色特征:ColorFlow采用颜色和光流特征;Color Flow Warping采用颜色、光流以及形变特征,而Color Flow Warping Backward增加了反向特征。

|
| 图 2 基于boosting模型的目标粗检测算法流程 Fig. 2 Object detection based on boosting model |
在以上的检测算法中设置较低的检测阈值,可获得较多的目标候选区域,当然其中包含大量的冗余结果。根据目标候选区的空间位置关系进行区域融合得到目标粗检测结果。具体算法如下:
算法1 基于空间位置关系的区域融合算法
1) 由基于boosting模型的目标粗检测算法得到的显著目标候选区域集合Blj,b=[xy $\tilde{x}\tilde{y}$ s],b∈Blj作为算法输入。
2) 计算每个显著目标候选区域bi的面积Si= |yi-$\tilde{y}$i|×|xi-$\tilde{x}$i|,保留Blj中满足Si>θ1的显著目标候选区域,其中θ1为阈值。
3) 搜索Bli中有重叠的任意2个显著目标候选区域bi,bj;计算其重叠面积Sbi∩bj。如果Sbi∩bj >θ2,其中θ2为阈值,则根据式(1)更新显著目标区域并删除Bej中面积较小的那个显著目标候选区域
 |
(1) |
4) 重复执行3),直至无重叠的显著目标候选区域,算法结束。
1.2 基于局部相似度的目标区域优化算法由基于空间位置关系的区域融合算法得到融合后的显著目标区域中包含了较多的非目标区域,为了更精确地检测目标区域,本文提出基于局部相似度的区域优化算法对目标区域进行进一步的优化。首先对显著目标区域b∈Bli进行超像素分割,得超像素集合P={pi| i=1,2,…,n},由超像素空间位置设置超像素的边界属性:
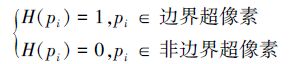 |
(2) |
对任意超像素pi,计算其属于显著目标可能性为
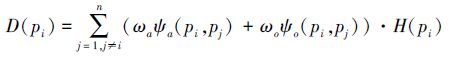 |
(3) |
式中:ψa(pi,pj)表示超像素pi和pj的颜色相似度,由颜色直方图特征向量的κ2距离确定,ψo(pi,pj)表示超像素pi和pj之间的运动相似度,由光流模直方图特征向量的κ2距离确定,ωa和ωo为权值。
计算所有超像素的显著目标可能性后,保留超像素集合P中D(pi)≥θ3(θ3为阈值)的超像素pi,从而得到优化后的显著目标区域,基于局部相似度的D计算式(3)的区域优化算法示意如图 3。
由于,经过两步层进目标检测后,得到了各个视角的Egocentric视频每帧中的显著目标检测结果,下面将对各个视角中的显著目标进行匹配。

|
| 图 3 基于局部相似度的区域优化算法 Fig. 3 Bounding box area optimization based on local similarity |
为了实现multi-egocentric中的多目标匹配,首先对数据集中关键帧的显著目标进行人工标注得到显著目标区域hη以及对应目标编号βη构建训练集H={(hη,βη)|η=1,2,…,Q;βη∈{0,1,…,$\tilde{Q}$}},其中Q为标注的目标个数,$\tilde{Q}$为目标分类数。基于HOG特征的目标匹配算法如下:
算法2 基于HOG特征的目标匹配算法
1) 输入H={(hη,βη)|η=1,2,…,Q,βη∈{0,1,…,$\tilde{Q}$}}作为输入;
2) 初始化SVM分类器参数,bins以及level;
3) 将hη按不同level划分为固定大小的矩形块;在每一个矩形块上统计梯度向量直方图(HOG),并将不同level的直方图特征连接起来组成特征向量vη;
4) 最后将vη和βη输入SVM分类器中进行训练;
5) 重复执行3)、4)直到所有显著目标区域训练完毕,输出SVM目标匹配模型。
基于HOG特征的目标匹配分类器训练流程如图 4所示。

|
| 图 4 基于HOG特征的目标匹配分类器训练流程(βi,i=1,2,…,η表示目标编号) Fig. 4 Object classification model training based on HOG feature(βi,i=1,2,…,ηrepresents match number of target region) |
由两步层进法检测得到多视角的显著目标后,基于HOG特征的目标匹配分类器实现多视角中多目标的匹配流程如图 5所示。

|
| 图 5 多视角多目标匹配算法流程(βi,i=1,2,…,η 表示显著目标区域匹配编号) Fig. 5 Multi-view and multi-object matching algorithm (βi,i=1,2,…,η represents match number of match target region) |
为了验证本文算法的有效性,采用Hyun Soo Park[3]的Party Scene 数据集进行目标检测和目标匹配实验。该multi-egocentric数据集进行目标检测和目标匹配实验。该数据集包括来自11个相机的第一视角视频数据,并且是同时拍摄同一场景得到的。每个视频共8 640帧,经同步后每个视频共8 566帧,本文取前914帧中的目标样本做手工标注,作为训练集;另选取50帧作为测试集,其包含没有任何目标个体的帧。本文的目标检测算法与MB、DPM、SPP Net、Poselets算法结果对比如图 6所示。SPP Net、DPM算法在随机窗口中搜索窗口包含目标概率最高的框,因此搜索结果可能不会完全覆盖目标区域,但相对准确,这也使得检测的显著目标轮廓不完整,如图 6中第1行、第2行所示;MB算法主要通过目标的运动信息检测目标边缘,但Egocentric 视频中的运动相对复杂,尤其是当目标运动不显著或目标只有局部运动时,MB算法无法检测到或只能部分检测到目标,如图 6中第1行、第3列,检测结果中漏检了目标的手部;而Poselets算法首先检测目标部位,再根据目标种类的不同合并符合模式的部位检测结果,因此检测结果中会产生一些孤立的部位检测结果,降低了检测结果的精度,如图 6中Poselets列所示;由Egocentric视频视角时变性导致的像第3行这样的拍摄角度不正的图像非常常见,而SPPNet、DPM算法对此种图像会有显著目标漏检的情况。本文算法在粗检测过程中综合了以上算法优势,并基于空间位置进行了区域融合,从而有效地避免了egocentric视频中目标尺度、运动差异较大而引起的漏检问题,而基于局部相似度的区域优化能很好地排除复杂背景的影响,因而具有较强的鲁棒性。本文算法的显著目标检测结果如图 6中第1列所示。

|
| 图 6 本文方法与DPM、SPP Net、Poselets算法结果对比图(Ours列为本文方法的检测结果,图中椭圆框中为算法漏检或错检的区域) Fig. 6 Comparison of our method with DPM、SPP Net and Poselets(missing or wrong detection areas are in ellipse boxes) |
本文提出的基于HOG特征的多目标匹配算法实验结果如图 7所示,可以看出,在大多数情况下,本文提出的算法能够有效地匹配多视角中的多个目标。但是当视频视角变化较大时,目标姿态不正,从而导致目标匹配失败,究其原因,因为训练是通过人工标注的包含目标的矩形框来完成的,从而导致训练样例包含更多的非目标区域给匹配结果的正确性带来影响,造成匹配结果不准确,如图 7中第3列的目标1和第4列的目标7;另外,由于提取特征时是通过将显著目标区域分成固定尺寸的bins(子块),因此当显著目标区域较小时,所划分的bins(子块)也就很少,提取的特征也就不显著,因此会出现结果错误,如图 7中第1列的目标2、5、3。

|
| 图 7 本文基于HOG特征的显著目标匹配算法结果和Ground-Truth对比图 Fig. 7 Comparison of Ground-Truth and object matching results of our method |
最后,本文采用F-measure方法评价目标检测算法。查准率和查全率的计算为
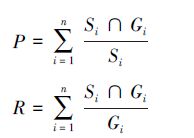 |
(4) |
式中:Si为目标检测算法检测的目标区域像素数,Gi为人工标注的目标区域像素数,n为目标数。
则F-measure为
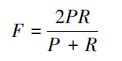 |
(5) |
目标匹配正确率的计算为
 |
(6) |
本文提出的鲁棒的multi-egocentric视频中的目标检测和目标匹配算法在整个数据集上的检测结果如表 1所示。
| 目标 | P | R | F | A |
| 显著目标 | 0.77 | 0.61 | 0.68 | 0.61 |
| 所有目标 | 0.28 | 0.39 | 0.33 | 0.21 |
4 结束语
本文对multi-egocentric视频中的多目标检测和匹配进行了研究,提出了基于boosting和局部相似度的两步层进目标检测算法,综合多种检测模型的优势以克服Egocentric视频中目标尺度差异明显和视角时变性强给检测带来的干扰。在显著目标检测基础上,对不同视角中的显著目标构建基于HOG特征的SVM分类器,实现多视角的多目标匹配,为后期的群体分析、场景理解等高级视觉任务提供了前期基础。multi-egocentric视频的处理和分析是一个极具挑战的研究课题,在后续的研究工作中,将进一步考虑融合局部相似度和全局相似度的显著目标区域检测方法,同时多视角之间的运动关联和目标自运动轨迹也是多视角视频分析中的重要线索。
| [1] | FELZENSZWALB P, MCALLESTER D, RAMANAN D. A discriminatively trained, multiscale, deformable part model[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, AK:IEEE, 2008:1-8. |
| [2] | BOURDEV L, MALIK J. Poselets:body part detectors trained using 3d human pose annotations[C]//Proceedings of the 2009 IEEE 12th International Conference on Computer Vision. Kyoto:IEEE, 2009:1365-1372. |
| [3] | WEINZAEPFEL P, REVAUD J, HARCHAOUI Z, et al. Learning to detect motion boundaries[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA:IEEE, 2015:2578-2586. |
| [4] | KUMAR K S, PRASAD S, SAROJ P K, et al. Multiple cameras using real time object tracking for surveillance and security system[C]//Proceedings of the 20103rd International Conference on Emerging Trends in Engineering and Technology. Goa:IEEE, 2010:213-218. |
| [5] | SOO PARK H, SHI Jianbo. Social saliency prediction[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA:IEEE, 2015:4777-4785. |
| [6] | LIN Yuewei, ABDELFATAH K, ZHOU Youjie, et al. Co-interest person detection from multiple wearable camera videos[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago:IEEE, 2015:4426-4434. |
| [7] | SNAVELY N, SEITZ S M, SZELISKI R. Photo tourism:exploring photo collections in 3D[J]. ACM transactions on graphics (TOG) , 2006, 25 (3) : 835-846 DOI:10.1145/1141911 |
| [8] | YONETANI R, KITANI K M, SATO Y. Ego-surfing first person videos[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA:IEEE, 2015:5445-5454. |
| [9] | FREUND Y, SCHAPIRE R. A short introduction to boosting[J]. Journal of Japanese society for artificial intelligence , 1999, 14 (5) : 771-780 |
| [10] | HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[M]//FLEET D, PAJDLA T, SCHIELE B, et al. Computer Vision-ECCV 2014. Switzerland:Springer International Publishing, 2014:346-361. |
| [11] | LAZEBNIK S, SCHMID C, PONCE J. Beyond bags of features:spatial pyramid matching for recognizing natural scene categories[C]//Proceedings of 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, NY, USA:IEEE, 2006, 2:2169-2178. |
| [12] | BURGES C J C. A tutorial on support vector machines for pattern recognition[J]. Data mining and knowledge discovery , 1998, 2 (2) : 121-167 DOI:10.1023/A:1009715923555 |
| [13] | DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, CA, USA:IEEE, 2005, 1:886-893. |
| [14] | ZHU Wangjiang, LIANG Shuang, WEI Yichen, et al. Saliency optimization from robust background detection[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH:IEEE, 2014:2814-2821. |