

DOI: 10.11992/tis.201603039

 ,
,
2. 北京交通大学 现代信息科学与网络技术北京市重点实验室, 北京 100044
,
2. Beijing Key Laboratory of Advanced Information Science and Network Technology, Beijing Jiaotong University, Beijing 100044, China
图像超分辨率 (super resolution,SR)[1-4]重建是计算机视觉中一个重要的问题,在医学成像、安全监控、遥感卫星等领域中起着重要的作用,已经得到了广泛的应用。通常,图像超分辨率的任务就是从一幅或多幅低分辨率 (low resolution,LR) 的输入图像来重构出一幅高分辨率 (high resolution,HR) 的输出图像。虽然这是一个病态的问题,但由于应用的需求以及人们研究的兴趣,许多方法相继被提出来解决这个问题。最简单方法就是利用插值算法,比如最邻近插值、双三次线性插值等。虽然这些插值算法运算简单,复杂度低,但重建的图像精度不高,边缘模糊,很难满足实际应用中图像的需求。
为了提高图像重建的质量,更有效的方法是基于学习的方法, 利用图像的统计先验[5-6]知识或者机器学习 (machine learning,ML)[7-9]技术来学习一个从LR图像块到HR图像块的映射函数。最近比较流行的方法是基于字典或样本学习的方法。其中表现较好的是基于字典学习的超分辨率重建算法,它通常是建立在稀疏编码 (sparse coding,SC)[10]基础上的,其假设自然的图像块可以通过字典原子的线性组合来稀疏表示。但这些方法由于在重建图像的时候需要进行一定时间的稀疏编码,实时性较差。最近,Timofte等[11]在重建阶段绕开了稀疏编码的部分,通过将一个单一的大字典划分为多个小字典,在保留图像重建精度的前提下,重建速度有了明显的改善。
受以上文献的启发,本文提出了一种快速重建图像的模型,在提高图像重建速度的同时力争改善图像的重建质量。在我们的算法中,将字典原子和LR特征之间的相关性作为测量依据,将整个数据集划分为多个子空间,然后在每一类子空间上独立地学习高低分辨率图像之间的映射关系。实验结果表明,在标准的自然图像测试集上,我们提出的算法重建的图像细节更加清晰,效果更好。
1 基于字典对的图像超分辨率重建这一部分简要介绍基于字典对的图像SR。主要包括基于邻域嵌入 (neighbour embedding,NE) 和稀疏编码 (SC) 的方法。
1.1 基于邻域嵌入的超分辨率重建邻域嵌入的方法假设LR图像块和其对应的HR图像块有着相似的局部几何流形。Chang等[12]通过使用局部线性嵌入的流形学习方法,将这个假设用于图像SR。由于在LR和HR的特征空间中,流形被认为有着相似的几何结构,这也就意味着只要有足够的样本,就可以使用在LR特征域中局部近邻样本的权重来重建出HR特征域中的图像块。
对于在LR特征空间中输入的一个图像块,搜寻训练集中与其欧氏距离最近的K个图像块作为它的邻域。通过计算一个带有约束的最小二乘问题得到该邻域中的样本表示输入图像块的K个系数权值,然后利用这K个权值和训练集中HR特征空间对应的K个图像块的线性组合即可重建出HR图像块。最终将所有的HR图像块合并到一起,并且平均相邻图像块重叠区域的像素值得到重建的HR图像。
1.2 基于稀疏编码的超分辨率图像重建邻域嵌入的方法需要在整个训练集中选择邻近的图像块,当需要提高图像重建的效果时,训练集会变得越来越大,计算的复杂度也将越来越高。为了解决这一问题,Yang等[13]通过字典对的学习将稀疏编码的方法用于图像SR。假设LR图像块和HR图像块有相同的稀疏表示系数,在整个训练集上一起学习高低分辨率字典对,如式 (1):
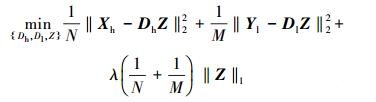 |
(1) |
式中:N和M分别表示HR图像块和LR图像块的维数;Xh和Yl分别表示训练样本中高低分辨率图像块;Dh和Dl分别表示高分辨率字典和低分辨率字典;Z是图像块对应的稀疏表示系数。对于输入的LR图像块,计算其在字典Dl下相应的稀疏表示系数α。最终利用这个系数α和学习好的字典Dh即可重建出HR图像块。
这样通过稀疏编码的方式将整个训练集转化成固定大小的字典,避免了训练集变大带来的困难。Zeyde等[14]在以上框架的基础上,通过在字典学习过程中进行的几个重要的修正改善了运行的速度。由于重建图像时稀疏模型的求解需要消耗一定的时间,所以上述所有基于字典对学习的方法中图像重建的速度仍然是相对较慢的。
2 快速线性回归的图像超分辨率重建针对以上存在的问题,我们将稀疏表示和回归的方法结合起来。对于字典训练,本文用一种新的相关性的聚类方法来替代K-means聚类方法将整个训练样本集有效地划分为多个子空间。同时直接利用LR特征和HR特征之间的关系提出了一种新的线性映射模型,避免了重建过程中稀疏编码的求解。该算法主要包括两个阶段,分别是训练阶段和重建阶段。
2.1 训练阶段首先我们收集包含一一对应的HR图像Xh={X1, X2, …, Xu}和LR图像Yl={Y1, Y2, …, Yu}的图像对训练集。将每一幅LR图像Ym通过插值,得到和HR图像一样大小的LR图像Ym′,然后对成对的高低分辨率图像分别提取高低分辨率特征。
为了仅得到图像的高频信息,我们对每一幅HR图像Xm做如下处理:
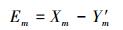 |
(2) |
然后对仅含有高频信息的图像Em进行分块,将每一个大小为
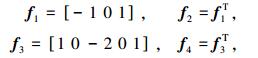 |
(3) |
式中T表示转置。通过对图像Ym′进行滤波处理,即可得到其相应的4幅梯度图像。同样对这4幅梯度图像进行分块,并在各自相同的位置分别取出一个大小为
由于多个滤波器处理后提取的LR特征维数增加会使计算的复杂度提高,我们通过降维的方式来减少后续训练和重建过程中计算的成本。本文采用PCA对LR特征向量进行降维处理,通过一个投影算子B∈Rnl×4n来降低
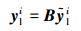 |
(4) |
式中特征向量yli∈Rnl,nl < 4n。如此即可得到在图像Ym′和Xm相同位置处分别提取的特征yli和xhi组成的一一对应的特征对{yli, xhi},进而将所有训练图像提取的特征作为训练集的整个特征空间I={yli, xhi},其中i=1, 2, …, Ns,Ns表示整个训练集中特征的数量。
不同于式 (1) 中Yang等[13]同时训练高低分辨率字典对,本文仅将LR特征{yli}i=1Ns⊆Rnl作为训练字典的样本,同时不必再训练HR字典。如式 (5),我们利用K-SVD[15]训练字典D={dk},k =1, 2, …, K。
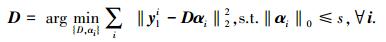 |
(5) |
式中:D∈Rnl×K,向量αi是对应于每个训练样本yli的稀疏表示系数。
值得注意的是,传统的基于字典对的图像SR方法在对原始样本数据进行训练得到字典之后便舍弃了对它们的使用,而对于本文的算法这些原始数据却仍是至关重要的。我们将D中的每个原子dk作为聚类的中心,按式 (6) 计算每个原子dk与所有的LR特征{yli}i=1Ns的相关性。
 |
(6) |
式中:Tki表示第k个原子与第i个LR特征的内积;dk表示训练字典D中的第k列原子;yli表示整个特征空间I中的第i个LR特征。然后选取对应于Tki值最大的M个yli,将这些yli作为一类。设dk对应类中的LR特征为Yk={ylk1, ylk2, …, ylkM},由于在整个特征空间I中yli和xhi总是成对出现的,从而可以得到对应于Yk的HR特征Xk={xhk1, xhk2, …, xhkM}。这样即可得到一个含有Yk和Xk的特征子空间,从而将整个训练的特征空间I划分为K个特征子空间。相比于传统的聚类方法中某个训练样本只能属于某个特定的类,我们这种新的聚类方式,可以将同一个训练样本划分到多个类中共享,进而可以提高训练的精度使得重建图像的效果更好。
最后,一旦得到了划分后的特征子空间,对每一个字典原子dk,在其对应的特征子空间上计算相应的投影矩阵。设xhki和ylki分别是HR特征Xk和LR特征Yk中的一对高低分辨率特征向量,它们的维数分别为n和nl。本文通过学习n个线性回归函数来独立预测HR特征向量中的n个值,在每一个特征子空间上按式 (7) 来计算从LR特征Yk∈Rnl×M映射到HR特征Xk∈Rn×M的回归投影矩阵Ck*∈Rn×nl:
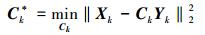 |
(7) |
以上的回归问题类似于一个线性最小二乘问题,因此有如下闭式解:
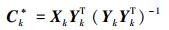 |
(8) |
最终可得到字典D中所有原子对应的投影矩阵组成的集合P={Ck*}k=1K。在整个训练过程中我们充分使用了所有的原始高低分辨率图像含有的信息来学习回归函数,以提高后续图像重建的精度。值得一提的是:以上的整个训练过程,包括字典的训练、特征空间的划分以及投影矩阵的求解我们都可以在线下进行计算。
2.2 重建阶段通过式 (5) 和式 (8) 可以分别得到训练好的字典D={dk}k=1K及投影矩阵集P={Ck*}k=1K。在重建过程中,利用字典原子dk和投影矩阵Ck*之间一一对应的关系即可快速地重建出HR图像。
对于输入的一幅LR测试图像Y,同训练阶段中预处理过程一样,先将其进行bicubic插值得到LR图像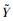
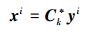 |
(9) |
将HR特征xi添加到对应的LR图像块sLi上,就可以得到我们想要的HR图像块sHi:
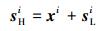 |
(10) |
最终,通过将所有的图像块sHi整合到一起,并且平均每个图像块的重叠区域来得到我们重建的HR图像X。
从整个重建的过程中可以看出,同基于稀疏表示字典对的方法相比,我们提出的算法在重建图像时省去了稀疏编码的部分,降低了计算的复杂度,提高了图像SR重建的速度。
2.3 本文算法的整体流程我们将本文提出的算法称为快速线性回归算法 (fast linear regression,FLR)。重建算法的训练阶段总结如下。
输入训练集中HR图像集Xh={X1, X2, …, Xu}和LR图像集Yl={Y1, Y2, …, Yu}。
输出训练字典D={dk}k=1K,投影矩阵集P={Ck*}k=1K。
1) 对Yl中的每一幅LR图像Ym进行插值放大,得到和HR图像一样像素大小的LR图像Ym′。
2) 通过式 (2) 得到含有高频信息的图像Em,并对其进行分块作为提取的HR特征xhi。
3) 利用式 (3) 中的滤波器对图像Ym′进行滤波提取梯度特征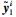
4) 将LR特征{yli}i=1Ns作为训练字典的样本,利用式 (5) 学习字典D={dk}k=1K。
5) 将D中的每个原子dk作为聚类的中心,利用式 (6) 对特征空间I进行划分,同时得到对应于dk的LR特征集Yk={ylk1, ylk2, …, ylkM}和HR特征集Xk={xhk1, xhk2, …, xhkM}组成的特征子空间。
6) 分别在每个dk对应的特征子空间上利用式 (8) 计算各自相应的投影矩阵Ck*,从而得到投影矩阵集合P={Ck*}k=1K。
由于训练阶段的所有计算过程均可在线下进行,这使得重建阶段更加高效。整个算法的重建阶段总结如下。
输入 LR测试图像Y,字典D={dk}k=1K,投影矩阵集P={Ck*}k=1K。
输出 HR重建图像X。
1) 对图像Y进行bicubic插值放大得到LR图像
2) 对
3) 利用式 (6) 寻找D中和yi最邻近的原子dk,得到P中dk对应的投影矩阵Ck*。
4) 通过式 (9) 重建出HR特征xi,再利用式 (10) 得到HR图像块sHi。
5) 将所有的图像块sHi整合起来得到最终重建的HR图像X。
3 实验结果与分析实验编程环境为MATLAB 2014,计算机的配置为Inter (R) Core (TM) i5-4460 CPU @3.20 Hz,主频为3.20 GHz,8 GB内存,windows 7操作系统。
实验选用比较常用的两个标准自然图像测试集,一个是来自参考文献[16]中包含5幅图像的Set5测试集,另一个是来自参考文献[14]中包含14幅图像的Set14测试集作为整个实验的测试图像集。同样,为了更好地体现与其他参考文献算法比较的公平性,实验中我们使用Yang等[13]提出的算法中的91幅图像作为训练集图像,字典的大小同参考文献[11, 14]一样为1 024列,对LR图像分别进行2倍和3倍尺度的超分辨率重建。由于人的视觉感知系统对亮度的变化更加敏感,先将彩色图像转换到YUV颜色空间,然后仅对亮度信号Y进行放大重建,而其他信号通过简单的bicubic插值来放大。整个实验中,我们对比了比较有代表性的基于邻域嵌入和稀疏表示的算法,以及基于回归和快速重建的算法。除了主观的视觉评价外,本文采用峰值信噪比 (PSNR) 以及图像重建的运行时间分别评价图像的重建质量和重建速度。
由于篇幅有限,这里我们只展示2幅图像通过不同方法进行3倍重建的视觉效果。为了更好地观察图像重建的效果,我们对两幅图像的局部均进行了放大处理。其中,图 1是对来自于测试集Set 14中像素大小为768×512的Monarch图像重建的结果,图 2是对来自于测试集Set 5中像素大小为288×288的Bird图像重建的结果。从图 1和图 2中可以看出,图 (b) bicubic插值方法重建的图像过于平滑并且存在振铃效应;图 (c) Yang等[13]的方法在边缘处有着锯齿效应;图 (d) Zeyde等[14]与图 (e) ANR[11]的方法相差不多,基本可以保持图像的边缘结构,但某些纹理等细节之处仍不是很好;从图 (f) 可见本文的FLR方法在重建纹理细节和消除伪边缘与锯齿两方面均取得了不错的效果,重建的图像更加清晰边缘更加锐利,在视觉效果上更接近于原始的HR图像。

|
| 图 1 测试集Set 14 Monarch图像放大3倍的不同方法超分辨结果对比 Fig. 1 Comparison of Monarch image from Set 14 with upscaling ×3 for different method |

|
| 图 2 测试集Set 5 Bird图像放大3倍的不同方法超分辨结果对比 Fig. 2 Comparison of Bird image from Set 5 with upscaling ×3 for different method |
表 1定量地展示了不同算法在测试图像集Set 5和Set 14上针对不同放大因子的平均PSNR和运行时间。相比于其他评价指标[17],PSNR的值可以更好地代表人的感知效果。而运行时间的快慢是体现算法能否很好地应用到实际中的重要指标。从表 1中最后一行的实验数据可以看出,本文提出的快速线性回归算法 (FLR) 要明显好于基于邻域嵌入和稀疏表示的算法以及其他方法。其中,图像的重建质量为29.15 dB,重建时间仅为0.93 s。比基于邻域嵌入的算法 (NE+LLE)[16]PSNR值高0.55 dB,速度快4.2倍;比Zeyde等[14]PSNR值高0.48 dB,速度也要快2.4倍。相比于单独基于线性回归 (SF)[7]的方法,其实验结果来自于参考文献[18],我们的FLR算法平均PSNR要比其高0.95 dB,由于两种方法提取的特征不同,我们的算法速度上要快26.4倍之多。和目前最快重建算法之一的ANR[11]相比,本文的方法运行时间与其相差不多,但图像重建的PSNR要高0.50 dB。另外,同最近提出的卷积神经网 (SRCNN)[9]方法相比,它的实验结果来自于参考文献[19],我们的FLR算法PSNR也要高0.15 dB,速度提高5.4倍。值得一提的是,SRCNN需要通过GPU训练大约72 h,而本文的FLR仅需要花费24 min就可以完成训练。另外,我们的算法并没有进行优化,也没有通过并行计算来加速,这一切都为以后在实际应用中提供了极大的可能性。
| Data set | NE+LLE[17] | Zeyde[14] | SF[7] | ANR[11] | SRCNN[9] | FLR | |
| factor | PSNR/Time | PSNR/Time | PSNR/Time | PSNR/Time | PSNR/Time | PSNR/Time | |
| Set 5 | x2 | 35.77/4.19 | 35.78/2.40 | 35.63/20.46 | 35.83/0.73 | 36.34/3.00 | 36.58/0.76 |
| x3 | 31.84/1.98 | 31.90/1.13 | 31.27/11.89 | 31.92/0.45 | 32.393.00/ | 32.60/0.45 | |
| Set 14 | x2 | 31.76/8.85 | 31.81/4.92 | 31.04/39.11 | 31.80/1.56 | 32.18/4.90 | 32.30/1.67 |
| x3 | 28.60/3.91 | 28.67/2.27 | 28.20/24.59 | 28.65/0.91 | 29.00/5.00 | 29.15/0.93 |
4 结束语
针对传统基于稀疏编码超分辨率算法图像重建速度慢以及重建效果不理想的问题,我们将稀疏表示和回归的方法有效地结合在一起,提出了一种快速的线性回归算法。通过将字典原子作为聚类中心,将字典原子和LR特征的相关性作为测量依据,有效地将整个特征空间划分为多个子空间,同时学习了一个简单并且有效的线性映射回归函数。实验结果表明,该算法不仅实现了计算复杂度低,运行时间快的目的,而且相比于大多数目前较好的不同算法,图像的重建质量也有了明显的改善。
| [1] | BHAVSAR A V. Range image super-resolution via reconstruction of sparse range data[C]//Proceedings of the 2013 International Conference on Intelligent Systems and Signal Processing. Gujarat, India, 2013: 198-203. |
| [2] | YANG Minchun, WANG Y C F. A self-learning approach to single image super-resolution[J]. IEEE transactions on multimedia, 2013, 15(3): 498-508. DOI:10.1109/TMM.2012.2232646. |
| [3] | PARK S C, PARK M K, KANG M G. Super-resolution image reconstruction: a technical overview[J]. IEEE signal processing magazine, 2003, 20(3): 21-36. DOI:10.1109/MSP.2003.1203207. |
| [4] | LI Xin, ORCHARD M T. New edge-directed interpolation[J]. IEEE transactions on image processing, 2001, 10(10): 1521-1527. DOI:10.1109/83.951537. |
| [5] | FATTAL R. Image upsampling via imposed edge statistics[J]. ACM transactions on graphics (TOG), 2007, 26(3): 95. DOI:10.1145/1276377. |
| [6] | FREEMAN W T, JONES T R, PASZTOR E C. Example-based super-resolution[J]. IEEE computer graphics and applications, 2002, 22(2): 56-65. DOI:10.1109/38.988747. |
| [7] | YANG C Y, YANG M H. Fast direct super-resolution by simple functions[C]//Proceedings of 2013 IEEE International Conference on Computer Vision. Sydney, Australia, 2013: 561-568. |
| [8] | SUN Jian, XU Zongben, SHUM H Y, et al. Image super-resolution using gradient profile prior[C]//Proceedings of 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, USA, 2008: 1-8. |
| [9] | DONG Chao, LOY C C, HE Kaiming, et al. Learning a deep convolutional network for image super-resolution[M]//FLEET D, PAJDLA T, SCHIELE B, et al. Computer Vision-ECCV 2014. Switzerland: Springer, 2014: 184-199. |
| [10] | OLSHAUSEN B A, FIELD D J. Sparse coding with an overcomplete basis set: a strategy employed by V1[J]. Vision research, 1997, 37(23): 3311-3325. DOI:10.1016/S0042-6989(97)00169-7. |
| [11] | TIMOFTE R, DE V, VAN GOOL L. Anchored neighborhood regression for fast example-based super-resolution[C]//Proceedings of 2013 IEEE International Conference on Computer Vision. Sydney, Australia, 2013: 1920-1927. |
| [12] | CHANG Hong, YEUNG D Y, XIONG Yimin. Super-resolution through neighbor embedding[C]//Proceedings of the 2004 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC, USA, 2004. |
| [13] | YANG Jianchao, WRIGHT J, HUANG T S, et al. Image super-resolution via sparse representation[J]. IEEE transactions on image processing, 2010, 19(11): 2861-2873. DOI:10.1109/TIP.2010.2050625. |
| [14] | ZEYDE R, ELAD M, PROTTER M. On single image scale-up using sparse-representations[M]//BOISSONNAT J D, CHENIN P, COHEN A, et al. Curves and Surfaces. Berlin Heidelberg: Springer, 2012: 711-730. |
| [15] | AHARON M, ELAD M, BRUCKSTEIN A. rmK—SVD: an algorithm for designing overcomplete dictionaries for sparse representation[J]. IEEE transactions on signal processing, 2006, 54(11): 4311-4322. DOI:10.1109/TSP.2006.881199. |
| [16] | BEVILACQUA M, ROUMY A, GUILLEMOT C, et al. Low-complexity single-image super-resolution based on nonnegative neighbor embedding[C]//Proceedings of British Machine Vision Conference 2012. Guildford, Surrey, UK, 2012: 1-10. |
| [17] | YANG C Y, MA C, YANG M H. Single-image super-resolution: a benchmark[M]//FLEET D, PAJDLA T, SCHIELE B, et al. Computer Vision-ECCV 2014. Switzerland: Springer, 2014: 372-386. |
| [18] | TIMOFTE R, DE SMET V, VAN GOOL L. A+: adjusted anchored neighborhood regression for fast super-resolution[M]//CREMERS D, REID I, SAITO H, et al. Computer Vision—ACCV 2014. Switzerland: Springer, 2014: 111-126. |
| [19] | SCHULTER S, LEISTNER C, BISCHOF H. Fast and accurate image upscaling with super-resolution forests[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA, 2015: 3791-3799. |