

DOI: 10.11992/tis.201602003

 ,
,
2. 香港理工大学 计算机系, 香港 九龙 999077
,
2. Department of Computing, Hong Kong Polytechnic University, Kowloon 999077, China
聚类是一种常用的数据分析方法,在人工智能、模式识别和机器学习等领域[1-3]一直受到广泛关注。聚类作为一种无监督的数据分析技术,通过数据之间的疏密程度,将数据划分到不同的数据簇中,使得簇内的数据之间关系比较紧密,而簇之间的数据关系比较疏远。根据聚类使用方法的不同,将聚类分成常见的一些类别:基于划分的聚类算法[4-7]、基于层次的聚类算法[8-9]、基于密度的聚类算法[10-11]、基于图论的聚类算法[12]等。这些聚类算法在针对特定的数据集进行聚类时,通常能获得理想的聚类效果。但这些聚类性能的有效获得都离不开一个必要前提,那就是进行聚类时的数据必须是充分的,换句话说,这些聚类算法不适合处理数据不充分的情况。
但在实际生产、生活中,数据不充分的情况或数据受到污染的情况往往普遍存在。例如,在一个新领域收集数据之初,数据往往是不充足的。又或者由于受到硬件设备的不稳定性或环境等一些因素的影响,可能会采集到受噪声干扰的失真数据。对于不充足的数据和受到污染的数据进行聚类分析时,如果直接采用传统聚类方法,往往会造成聚类结果的不理想,甚至有时会出现聚类失效的结果。
如何有效解决数据量不足和数据受污染情况下的数据聚类性能问题,是近年来研究工作者的方向之一。其中,知识迁移[13]机制的引入是一种有效手段。知识迁移机制是指将历史数据 (也称为源域) 中提炼的有益知识应用到对当前数据 (也称为目标域) 聚类任务的指导,用于提高当前数据的聚类结果。历史数据与当前数据之间既存在着联系,也存在着明显的差别。目前,应用知识迁移机制来提高聚类性能的代表性算法有:在多任务中使用共享子空间进行聚类的LSSMTC算法[14]、使用K均值组合方法的CombKM算法[14]、使用自学习迁移机制的STC聚类算法[15]、使用特征和样本协同机制的Co-clustering聚类算法[16]及迁移谱聚类TSC算法[17]。这些基于知识迁移的聚类算法虽然提高了一定的聚类性能,但离实际应用还有一定差距,且这些聚类算法在进行聚类任务时需要完整的历史数据集,这在一些特殊场合,如保密需要,完整的历史数据是不可能获得的。所以,研究一种有隐私保护的高效迁移聚类算法具有必要性和实用性。
本文在经典的MECA聚类算法的基础上,通过对MECA算法的目标函数进行改造,使其具有学习历史知识的能力,进而提高算法在样本量不充分或受到污染情况下聚类的性能。
1 经典极大熵聚类算法在传统C均值聚类算法的基础上,通过引入具有明确物理含义的熵,产生出了具有简洁的数学表达式和明确物理含义特点的极大熵模糊聚类算法。极大熵模糊聚类算法有很多种不同的表达形式,其中文献[6-7]给出的是经典的极大熵模糊聚类算法,其具体表述如下。
假设样本空间X={xi|xi∈Rd, i=1, 2, …, N},其中,N表示样本点的个数,R是实数集, d表示样本点的维数。该样本包含C(1 < C < N) 个不同的类别,则经典的极大熵聚类算法 (MECA) 的目标函数可表示为
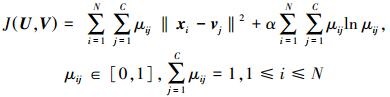 |
(1) |
式中:xi表示第i个样本点;vj表示第j类中心点;μij表示第i个样本点隶属于第j类的程度;‖xi-vj‖2表示第i个样本点与第j类中心点的距离;α是正则化系数,由μij构成隶属度矩阵U ∈RN×C,由vj构成中心点矩阵V∈Rd×C。
采用拉格朗日条件极值优化方法解得式 (1) 的最优聚类中心V和隶属度U的迭代公式为
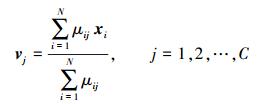 |
(2) |
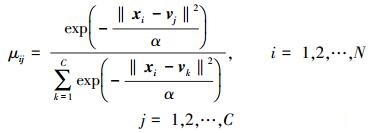 |
(3) |
根据上述推导,总结出MECA算法的具体步骤如下:
输入 数据集X,分类数C,正则化系数α,最大迭代次数T,终止阈值ε。
输出 最优隶属度U和聚类中心V。
1) 初始化迭代计数器t=0, 随机初始化隶属度矩阵U(0)。
2) 根据式 (2) 和1) 的隶属度矩阵U(t) 获得新的类中心V(t)。
3) 根据式 (3) 和2) 获得的类中心V(t) 计算得新的隶属度U(t+1)。
4) 当‖U (t+1)-U(t)‖ < ε或者t>T时算法终止,否则跳转到2)。
通过观察MECA算法的具体步骤可以看出,原始的MECA算法不具有知识迁移的能力。
MECA算法在数据量充足时,可以使用上述迭代过程获得有效的类中心和隶属度。但当样本量不充足或样本被污染的情况下,直接使用MECA算法获得的聚类中心往往严重偏离实际聚类中心,甚至有时会出现聚类失效的情况。因此,在数据量不足或数据受到污染情况下,研究有效的聚类算法,具有必要性和实际价值。
2 基于极大熵的知识迁移模糊聚类在知识迁移理论[13]中,当源域数据和目标域数据既存在一定的相关性,同时又存在着明显的差异时,可通过对源域有益知识的充分利用来指导目标域任务更好地完成。本文尝试通过将数据量充分的源域知识迁移至数据量不足或被污染的目标域的聚类任务中,来提高目标域的聚类性能。
为了实现源域知识到目标域迁移的目的,需要解决3个核心问题:
1) 迁移什么知识;
2) 如何迁移;
3) 什么时候迁移。
首先,解决源域到目标域迁移什么知识的问题。在基于划分的聚类算法中,隶属度和聚类中心点是对聚类结果具有决定性作用的两个因素。故本文选择隶属度和聚类中心点作为被迁移的知识。
其次,需要解决如何才能实现将源域的隶属度和聚类中心点知识迁移到目标域的聚类任务中的问题。我们通过以下两个规则来实现。
1) 隶属度重要程度受约束规则
该规则对应的公式为
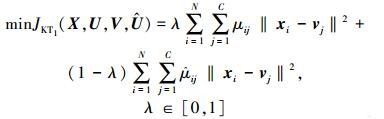 |
(4) |
式中:xi表示目标域中第i个样本点;vj表示目标域中第j类中心点;μij表示目标域中第i个样本点隶属于第j类的程度;
2) 聚类中心点变化最小规则
该规则的公式为
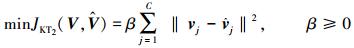 |
(5) |
式中:vj代表目标域的第j类中心点,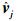
根据上述分析,针对经典MECA算法不具有知识迁移能力的不足,本文在MECA算法的基础上结合上述两个规则,提出基于极大熵知识迁移模糊聚类算法,即MEKTFCA算法。该算法的原理如图 1。

|
| 图 1 MEKTFCA算法原理图 Fig. 1 Overall framework of MEKTFCA algorithm |
MEKTFCA算法首先对源数据集,通过经典的MECA算法获得历史聚类中心,然后根据目标数据集和所获得的历史聚类中心,通过再次使用经典的MECA算法获得历史隶属度,最后通过MEKTFCA算法和历史聚类中心及历史隶属度获得最终的聚类结果。
融入了隶属度重要程度受约束规则和聚类中心点变化最小规则得到的MEKTFCA算法的具体目标函数为
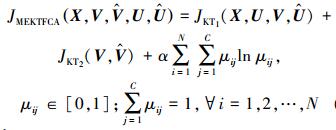 |
(6) |
其中
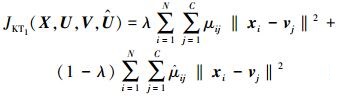 |
(7) |
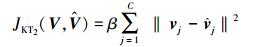 |
(8) |
观察式 (6) 可以看出,MEKTFCA算法从本质上来说是由3部分组成。第1部分是融入了对历史隶属度知识的学习的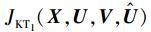
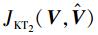
式 (6) 的参数求解问题,即为在有约束条件下求解最优的参数使得目标函数值最小。与MECA求最优解方法相同,我们采用拉格朗日乘子法进行求解,首先构造拉格朗日函数表达式, 即
 |
(9) |
式中ηi为Lagrange乘子。
根据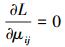
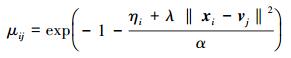 |
(10) |
因为有约束条件
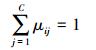 |
(11) |
将式 (10) 代入式 (11) 可得
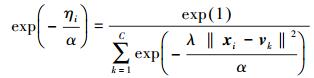 |
(12) |
将式 (12) 代入式 (10) 可得隶属度的迭代公式为
 |
(13) |
根据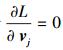
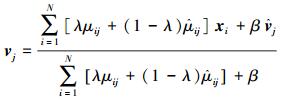 |
(14) |
根据上述的推导过程所获得的隶属度和聚类中心点的迭代公式,给出MEKTFCA算法的具体步骤如下。
输入 历史类中心点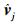
输出 最优隶属度U和聚类中心V。
1) 根据式 (3) 计算历史隶属度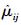
2) 初始化迭代计数器t=0。
3) 根据式 (14) 计算得到新的聚类中心V(t)。
4) 根据式 (13) 计算得到新的隶属度矩阵U(t+1)。
5) 当‖U (t+1)-U(t)‖ < ε或者t>T时算法终止,否则跳转到3)。
以上算法步骤同时回答了实现知识迁移中的第3个核心问题:什么时候迁移。通过算法步骤可以看到,在算法不断迭代过程中,隶属度和中心点的迭代公式中使用到了历史隶属度知识和历史类中心点知识。从而在算法的迭代过程中实现了知识的迁移。
3 实验结果及分析 3.1 实验设置为验证本文所提MEKTFCA算法的有效性,将构造一组模拟数据集和两组真实数据集作为实验所使用的迁移场景。同时,选择6种相关算法作为对比算法,对它们的聚类性能进行比较。这6种算法为:在多任务中使用共享子空间进行聚类的LSSMTC算法[14],使用K均值组合方法的CombKM算法[14],使用自学习迁移机制的STC聚类算法[15],使用特征和样本协同机制的Co-clustering聚类算法[16],迁移谱聚类TSC算法[17]以及经典的MECA算法[6-7]。
为了对聚类算法的结果进行客观比较,本文采用统一的NMI[18] (normalized mutual information) 和RI[19](rand index) 两种指标对实验结果进行评价。NMI的计算公式为
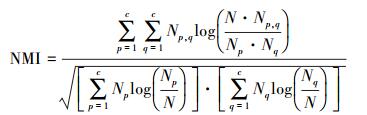 |
式中:N代表数据集的样本数目;Np代表聚类到p类的样本数目;Nq代表类标签为q的样本数目;Np, q代表同时聚类到p类和类标签为q的样本数目。RI评价指标的计算公式为
 |
式中:N00代表拥有不同类标签的两个样本聚类到不同类别中的个数;N11代表拥有相同类标签的两个样本聚类到相同类别中的个数。上述两种评价指标值的变化范围都为[0,1],且值越大,代表其算法的聚类性能越好。
在MEKTFCA算法中,涉及两个平衡因子λ和β如何取值的问题。本文采用网格搜索进行遍历寻优,其寻优的范围及其他对比算法的参数设置值如表 1所示。
| 算法 | 参数设置值 |
| LSSMTC | 共享子空间的维度l=1,任务数m=2,正则化参数λ=0.5 |
| CombKM | K等于聚类数 |
| STC | 平衡参数λ=3 |
| Co-clustering | 特征聚类数m=2 |
| TSC | 平衡因子λ=1,步长step=1 |
| MECA | 熵正则化参数γ∈{0.1:0.2:1}∪{2:1:10}∪ {20:10:100} |
| MEKTFCA | 熵正则化参数α∈{0.1:0.2:1}∪{2:1:10}∪ {20:10:100}平衡因子λ∈{0:0.1:1}平衡因子β∈{0:0.2:1}∪{2:1:10} ∪{20:10:100} |
本实验所采用的环境是:Intel i7-5600U 2.60 GHz 8 GB RAM;Windows 8 64 bit;MATLAB R2012b。实验所列结果数据均是在运行10次后求得的平均值。
3.2 模拟数据集实验结果和分析该实验是通过构造的模拟数据集来验证本文所提的MEKTFCA算法在样本量不足和受污染情况下聚类算法的有效性。本实验构造了一组源数据集S和3组目标数据集T1、T2、T3,其中源数据集和所有的目标数据集均包含3类2维的数据,这些数据的生成均采用高斯概率分布模型函数,生成时所使用的均值、方差及每个类别包含的样本数如表 2所示。
| 数据集 | 类别 | 均值 | 方差 | 样本数 |
| 源数据集S | 第1类 | 
|
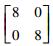
|
500 |
| 第2类 | 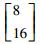
|
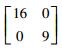
|
500 | |
| 第3类 | 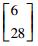
|

|
500 | |
| 目标数据集T1 | 第1类 | 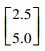
|
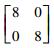
|
30 |
| 第2类 | 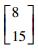
|
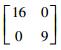
|
30 | |
| 第3类 | 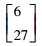
|
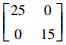
|
30 | |
| 目标数据集T2、T3 | 第1类 | 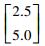
|
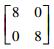
|
150 |
| 第2类 | 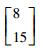
|
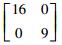
|
150 | |
| 第3类 | 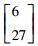
|

|
150 |
构造的源数据集S共含有1 500个样本,这个数据集数据量充足,并且能够从该数据集中提取出对目标数据集的聚类具有指导作用的有用知识。
构造的目标数据集T1共含有90个样本,只占源数据集S总数据量的6%,用于代表数据量不充足的场景,虽然数据集T1与数据集S的均值存在差异,但它们的方差相同,这用于体现迁移学习中的源数据集与目标数据集之间既存在着相似性,同时也存在着一定的差别的情况。
构造的目标数据集T2共含有450个样本,占源数据集S总数据量的30%。用目标数据集T2来代表目标数据量充分的场景。
构造的目标数据集T3与目标数据集T2的均值、方差和数据量完全相同。不同的是,数据集T3在数据集T2的基础上增加了方差为2、均值为0的高斯噪声,用于代表数据量充分但受到了噪声污染的场景。
上述构造的4组模拟数据集的数据分布如图 2所示。

|
| 图 2 模拟数据集分布图 Fig. 2 Data distribution of synthetic datasets |
在上述构造出来的各种迁移场景下,运行MEKTFCA算法和6种对比算法,得到的实验结果如表 3所示。因为TSC算法要求样本的维数要大于聚类数目,而在模拟数据集上不满足此条件,所以在表 3中我们使用“—”来表示此算法无法运行。
| 场景 | 评价指标 | LSSMTC | CombKM | STC | Co-lustering | TSC | MECA | MEKTFCA |
| S-T1 | NMI-mean | 0.674 1 | 0.759 4 | 0.155 6 | 0.737 2 | — | 0.737 2 | 0.802 4 |
| NMI-std | 0.036 3 | 1.170 3×10-16 | 0 | 1.170 3×10-16 | — | 1.170 3×10-16 | 0.002 2 | |
| RI-mean | 0.867 4 | 0.902 4 | 0.605 2 | 0.901 4 | — | 0.901 4 | 0.917 5 | |
| RI-std | 0.0194 | 1.170 3×10-16 | 1.170 3×10-16 | 2.340 6×10-16 | — | 2.340 6×10-16 | 0.007 1 | |
| S-T2 | NMI-mean | 0.734 3 | 0.787 6 | 0.169 4 | 0.771 9 | — | 0.764 9 | 0.834 8 |
| NMI-std | 0.032 4 | 0 | 2.925 7×10-17 | 0.009 9 | — | 7.401 5×10-17 | 0.001 9 | |
| RI-mean | 0.905 9 | 0.921 5 | 0.687 9 | 0.919 5 | — | 0.916 8 | 0.940 1 | |
| RI-std | 0.012 8 | 0 | 1.170 3×10-16 | 0.005 3 | — | 0 | 0.001 1 | |
| S-T3 | NMI-mean | 0.734 6 | 0.773 7 | 0.126 1 | 0.761 5 | — | 0.774 6 | 0.816 2 |
| NMI-std | 0.028 5 | 1.170 3×10-16 | 0 | 0.009 4 | — | 1.170 3×10-16 | 1.170 3×10-16 | |
| RI-mean | 0.899 5 | 0.914 7 | 0.587 8 | 0.911 1 | — | 0.914 8 | 0.937 2 | |
| RI-std | 0.010 8 | 1.170 3×10-16 | 0 | 0.002 6 | — | 0 | 1.170 3×10-16 |
观察表 3的实验结果可以得出如下结论:
1) 源数据集是S,目标数据集是T1,它们所代表的是数据量不足的场景。从该场景中的实验结果可以看出,没有使用任何迁移机制的MECA算法,在数据量不充分的情况下,其聚类性能要明显比使用了知识迁移的MEKTFCA算法差。因为MECA算法对数据量不充足的数据集进行聚类时,产生的聚类中心将会严重偏离实际的聚类中心,进而导致最终的聚类结果不理想。而MEKTFCA算法由于引入了知识迁移机制,在聚类过程中,通过学习由源数据集提取的历史类中心和历史隶属度中的有用知识,有效地改善了由于数据量不足而导致的聚类中心偏移的问题,最终提高了聚类性能。对于另外的4种对比算法,从它们的实验结果可以看出,虽然这些算法都使用了不同的机制来提高聚类结果,但由于算法本身的限制,在样本量不充足的场景下,其聚类结果不理想。
2) 源数据集是S,目标数据集是T2,它们所构成的是数据量较充足且无污染的场景。从该场景中的实验结果可以看出,由于目标数据集T2的数据量较充分,因此所有6种算法均取得比较理想的聚类结果。这也进一步说明了传统的聚类算法进行有效聚类的前提条件是数据量要充分。在这6种聚类算法中,由于MEKTFCA算法对源数据集所形成的历史中心点和历史隶属度双重有益知识进行了学习,它的聚类结果要优于其他5种算法。
3) 源数据集是S,目标数据集是T3,它们构成的是数据量较充分但受到污染的场景。从该场景中的实验结果可以看出,当数据受到污染时,其余5种对比算法的聚类性能要明显差于本文提出的MEKTFCA算法。因为数据集T3受到了污染,从而导致数据产生失真,数据集的聚类中心产生了显著的偏移,数据类别之间的界限变得模糊,最终使得这五种聚类算法的聚类性能不够理想。MEKTFCA算法在进行聚类时,通过调整两个平衡因子的权重来学习源数据集中有益的历史中心点知识和历史隶属度知识,这种迁移知识的学习机制提高了MEKTFCA算法在数据被污染情况下的聚类效果。这也使得MEKTFCA算法具有一定的抗噪性能。
3.3 文本数据集实验结果和分析第2个实验基于真实的文本数据集20 Newsgroups (20 NG)[20]构造的目标数据样本量不足的迁移场景来对MEKTFCA算法的有效性进行进一步验证。20 NG数据集包含大约20 000条新闻组信息,均匀地分布在20个不同的集合中。我们选择这20个集合中的4个来生成两组实验用的迁移场景:“comp VS sci”和“rec VS talk”。这两组迁移场景的数据集构成如表 4所示。
| 迁移场景 | 数据集 | 数据个数 | 维数 |
| comp VS sci | 历史 | 1 500 | 350 |
| 目标 | 150 | 350 | |
| rec VS talk | 历史 | 1 500 | 350 |
| 目标 | 150 | 350 |
这两组迁移场景所使用的数据集的来源见表 5所示。在构造这两组迁移场景时,源数据集和目标数据集之间有一定的相似性,同时又有明显的不同。如构造的“comp VS sci”迁移场景第1类的源数据集和目标数据集都来自同样的“comp”大类,但它们的子类是完全不同的。第2类的源数据集和目标数据集与此类似。因为20 NG数据集的原始数据的维数较大,因此实验之前我们使用工具BOW[21]对其进行了降维处理。本文所提的MEKTFCA算法及其6种对比算法在此数据集上的实验结果如表 6。
| 迁移场景 | 类别 | 源数据集 | 目标数据集 |
| comp VS sci | 1 | comp.os.ms-windows.misc | comp.windows.x |
| 2 | sci.crypt | sci.space | |
| rec VS talk | 1 | rec.autos | rec.sport.baseball |
| 2 | talk.politics.guns | talk.politics.mideast |
| 迁移场景 | 评价指标 | LSSMTC | CombKM | STC | Co-lustering | TSC | MECA | MEKTFCA |
| comp VS sci | NMI-mean | 0.390 2 | 0.108 1 | 0.275 2 | 0.281 0 | 0.860 2 | 0.689 1 | 1 |
| NMI-std | 0.246 3 | 0.273 2 | 0.161 7 | 0.295 8 | 1.170 3×10-16 | 0 | 0 | |
| RI-mean | 0.648 7 | 0.547 8 | 0.645 7 | 0.610 0 | 0.964 6 | 0.863 2 | 1 | |
| RI-std | 0.148 9 | 0.145 8 | 0.100 2 | 0.161 0 | 2.340 6×10-16 | 1.170 3×10-16 | 0 | |
| VS talk | NMI-mean | 0.027 9 | 0.165 1 | 0.188 8 | 0.025 1 | 0.822 6 | 0.066 6 | 0.905 3 |
| NMI-std | 7.314 2×10-18 | 0.108 4 | 0.007 5 | 0.008 8 | 1.170 3×10-16 | 0.077 4 | 0.026 0 | |
| RI-mean | 0.496 7 | 0.533 9 | 0.600 7 | 0.496 7 | 0.947 7 | 0.505 6 | 0.971 0 | |
| RI-std | 0 | 0.042 1 | 0.002 0 | 2.829 8×10-5 | 0 | 0.027 1 | 0.010 2 |
观察表 6的实验结果可以得出如下结论:
1) MEKTFCA算法和TSC算法在迁移场景“comp VS sci”上的聚类结果较其他5种算法的聚类结果优势明显。其他5种算法中,MECA算法的聚类结果最好,LSSMTC算法次之,Co-clustering算法、STC算法和CombKM算法的聚类结果明显差于其他算法。究其原因,主要是由于在此构造的真实场景上MEKTFCA算法和TSC算法的迁移学习机制比其他算法更有效。
2) MEKTFCA算法和TSC算法在构造的迁移场景“rec VS talk”上的聚类结果具有同样明显的优势,而其他5种算法的聚类结果却差很多。MECA算法因为在此迁移场景下,目标数据集的样本量不足,且没有引入任何迁移学习机制,导致最终的聚类结果较差。STC算法、CombKM算法、LSSMTC算法和Co-clustering算法尽管都使用了不同的迁移学习机制,但在此迁移场景下的效果不明显,所以它们的聚类结果也明显较差。而MEKTFCA算法和TSC算法在此迁移场景上的知识迁移效果明显,故取得较好的聚类结果。
3) 进一步观察表 6的实验结果可以发现,MEKTFCA算法在所构造的两组迁移场景上的聚类性能都明显高于经典的MECA算法,这主要是因为MEKTFCA算法是在MECA算法的基础上通过改变两个平衡因子的大小来调整对历史中心点和历史隶属度知识的学习权重。因为对迁移知识的有效学习,所以保证了MEKTFCA算法的聚类效果始终要比MECA算法的聚类效果好。
3.4 入侵检测数据集实验结果和分析最后一个实验使用的是真实的入侵检测数据集KDDCup99[22],使用该数据集形成一个目标数据集样本量不足的场景,通过将MEKTFCA算法应用到该场景,再次验证该算法的有效性。KDDCup99数据集来源于美国林肯实验室建立的一个模拟网络环境中收集的网络连接和审计数据。数据集中的数据包含不同类型的用户、各种不同类型的网络流量以及各种类型的网络攻击。该数据集共收集了9周时间的数据,其中7周时间的数据作为训练数据,约含有5 000 000个网络连接数据,另外2周时间的数据作为测试数据,约含有2 000 000个网络连接数据。整个数据集中的训练数据集和测试数据集之间有着不同的概率分布,即整个数据集具有一定的相似性,同时也存在着一定的差异性,满足知识迁移应用的条件。本文基于KDDCup99数据集构造的知识迁移场景只选择了数据集中常见的5种类型 (Normal、smurf、Neptune、satan、ipsweep) 作为源数据集和目标数据集的类别,选择每条网络连接记录中的32个连续型的特征属性作为样本数据的维度,源数据集的样本来自原始的训练数据集,目标数据集的样本来自原始的测试数据集。目标数据集的样本数量只占源数据集的样本数量的10%,且样本数量不大,表征的是目标数据集样本量不足的情况。具体的入侵检测迁移场景的数据集的样本个数、数据的维数和类别如表 7所示。
| 数据集 | 样本个数 | 维数 | 类别 |
| 源数据集 | 2 000 | 32 | 5 |
| 目标数据集 | 200 | 32 |
MEKTFCA算法和其他6种对比算法在该入侵检测数据集知识迁移场景上的执行结果如表 8所示。
| 评价指标 | LSSMTC | CombKM | STC | Co-clustering | TSC | MECA | MEKTFCA |
| NMI-mean | 0.402 1 | 0.383 4 | 0.397 0 | 0.302 5 | 0.284 5 | 0.409 0 | 0.756 9 |
| NMI-std | 0.045 3 | 0.008 3 | 0.061 2 | 0.126 9 | 0.023 1 | 6.409 9×10-17 | 0.023 6 |
| RI-mean | 0.508 4 | 0.497 6 | 0.498 3 | 0.492 8 | 0.447 5 | 0.514 3 | 0.902 2 |
| RI-std | 0.027 5 | 0.026 3 | 0.087 6 | 0.065 0 | 0.013 1 | 0 | 0.017 2 |
观察表 8实验结果可以看出,MEKTFCA算法在两大性能指标NMI和RI的均值要明显高于其他6种对比算法。与上述两个实验结果分析的原因相同,MEKTFCA算法由于从源数据集中学习了有益的历史中心点和历史隶属度知识,并对目标数据集的聚类过程形成有效指导,进而使得MEKTFCA算法在目标数据集样本量不足的情况下仍能取得比其他6种算法更好的聚类性能。这同时也进一步验证了对历史知识的有效学习对当前聚类任务的有效完成具有促进作用。
4 结束语由于传统聚类算法在数据样本量不足或数据受污染的情况下,其聚类效果往往不理想甚至失效,本文在经典的MECA算法的基础上通过引入知识迁移机制,提出了基于极大熵的知识迁移模糊聚类算法,即MEKTFCA算法。MEKTFCA算法通过引入的知识迁移机制使得在对数据量不足或受污染的目标域数据进行聚类时能够有效学习源域中有益的历史中心点和历史隶属度知识,进而提高了最终的聚类结果。通过一组模拟数据集和两组真实的数据集上的实验结果,可以得出本文所提MEKTFCA算法较6种相关算法在聚类性能上有明显的优越性。本文的创新点主要是,在MECA算法的基础了提出了一个新的知识迁移方法,该方法能有效解决实际生活中数据短缺和有噪声数据场景下的聚类性能问题。此外,本文所提的MEKTFCA算法也存在着局限性,如在不同应用场景下两个平衡参数如何进行有效确定的问题。这也是我们对该算法进行进一步研究的方向。
| [1] | CARIOU C, CHEHDI K. Unsupervised nearest neighbors clustering with application to hyperspectral images[J]. IEEE journal of selected topics in signal processing, 2015, 9(6): 1105-1116. DOI:10.1109/JSTSP.2015.2413371. |
| [2] | ALI A, BOYACI A, BAYNAL K. Data mining application in banking sector with clustering and classification methods[C]//Proceedings of 2015 International Conference on Industrial Engineering and Operations Management. Dubai, UAE, 2015: 1-8. |
| [3] | LI Shuai, ZHOU Xiaofeng, SHI Haibo, et al. An efficient clustering method for medical data applications[C]//Proceedings of 2015 IEEE International Conference on Cyber Technology in Automation, Control, and Intelligent System. Shenyang, China, 2015: 133-138. |
| [4] | LIKAS A, VLASSIS N, VERBEEK J J. The global k-means clustering algorithm[J]. Pattern recognition, 2003, 36(2): 451-461. DOI:10.1016/S0031-3203(02)00060-2. |
| [5] | BEZDEK J C. Pattern recognition with fuzzy objective function algorithms[M]. New York: Springer, 1981: 43-93. |
| [6] | KARAYIANNIS N B. MECA: maximum entropy clustering algorithm[C]//Proceedings of the 3rd IEEE International Conference on Fuzzy Systems. Orlando, USA, 1994, 1: 630-635. |
| [7] | LI Ruiping, MUKAIDONO M. A maximum-entropy approach to fuzzy clustering[C]//Proceedings of 1995 the 4th IEEE International Conference on Fuzzy System. Yokohama, Japan, 1995, 4: 2227-2232. |
| [8] | ZHANG Tian, RAMAKRISHNAN R, LIVNY M. BIRCH: an efficient data clustering method for very large databases[C]//Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data. New York, NY, USA, 1996: 103-114. |
| [9] | GUHA S, RASTOGI R, SHIM K. CURE: an efficient clustering algorithm for large databases[C]//Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data. New York, NY, USA, 1998: 73-84. |
| [10] | ESTER M, KRIEGEL H P, SANDER J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]//Proceeding of the Second International Conference on Knowledge Discovery and Data Mining. Portland, Oregon, USA, 1996: 226-231. |
| [11] | ANKERST M, BREUNIG M M, KRIEGEL H P, et al. OPTICS: ordering Points to Identify the Clustering Structure[C]//Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data. Philadelphia, Pennsylvania, USA, 1999: 49-60. |
| [12] | ARIAS-CASTRO E, CHEN Guangliang, LERMAN G. Spectral Clustering based on local linear approximations[J]. Electronic journal of statistics, 2011, 5: 1537-1587. DOI:10.1214/11-EJS651. |
| [13] | PAN S J, YANG Qiang. A survey on transfer learning[J]. IEEE transactions on knowledge and data engineering, 2010, 22(10): 1345-1359. DOI:10.1109/TKDE.2009.191. |
| [14] | GU Quanquan, ZHOU Jie. Learning the shared subspace for multi-task clustering and transductive transferclassification[C]//Proceedings of Ninth IEEE International Conference on Data Mining. Miami, FL, USA, 2009: 159-168. |
| [15] | DAI Wenyuan, YANG Qiang, XUE Guirong, et al. Self-taught clustering[C]//Proceedings of the 25th International Conference on Machine Learning. New York, NY, USA, 2008: 200-207. |
| [16] | GU Quanquan, ZHOU Jie. Co-clustering on manifolds[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA, 2009: 359-368. |
| [17] | JIANG Wenhao, CHUNG F L. Transfer spectral clustering[M]//FLACH P A, BIE T D, CRISTIANINI N. Machine Learning and Knowledge Discovery in Databases. Berlin Heidelberg: Springer, 2012: 789-803. |
| [18] | JING Liping, NG K M, HUANG J Z. An entropy weighting k-means algorithm for subspace clustering of high-dimensional sparse data[J]. IEEE transactions on knowledge and data engineering, 2007, 19(8): 1026-1041. DOI:10.1109/TKDE.2007.1048. |
| [19] | LIU Jun, MOHAMMED J, CARTER J, et al. Distance-based clustering of CGH data[J]. Bioinformatics, 2006, 22(16): 1971-1978. DOI:10.1093/bioinformatics/btl185. |
| [20] | DAI Wenyuan, XUE Guirong, YANG Qiang, et al. Co-clustering based classification for out-of-domain documents[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY, USA, 2007: 210-219. |
| [21] | MCCALLUM A K. Bow: a toolkit for statistical language modeling, text retrieval, classification and clustering[EB/OL]. 1996. http://www.cs.cmu.edu/mccallum/bow. |
| [22] | BAY S D, KIBLER D, PAZZANI M J, et al. The UCI KDD archive of large data sets for data mining research and experimentation[J]. ACM SIGKDD explorations newsletter, 2000, 2(2): 81-85. DOI:10.1145/380995. |