


 , , ,
, , ,
2. 江阴职业技术学院江苏省信息融合软件工程技术研发中心, 江苏江阴 214405;
3. 江阴职业技术学院计算机科学系, 江苏江阴 214405
, , ,
2. Information Fusion Software Engineering Research and Development Center of Jiangsu Province, Jiangyin Pdyteehnie College, Jiangyin 214405, China;
3. Department of Computer Science, Jiangyin Pdyteehnie College, Jiangyin 214405, China
迁移学习是机器学习领域的一个新方向,是对机器学习能力的一次拓展,具有很重要的研究价值。文献[1]讨论了迁移学习的应用,现阶段研究进展及对未来迁移学习潜在的问题。文献[2]推广了传统的AdaBoost算法,提出Tradaboosting迁移学习算法,该算法思想是利用boosting的技术来过滤掉辅助数据中那些与源训练数据最不相像的数据。其中boosting的作用是建立一种自动调整权重的机制,于是重要的辅助训练数据的权重将会增加,不重要的辅助训练数据的权重将会减小。调整权重之后,这些带权重的辅助训练数据将会作为额外的训练数据,与源训练数据一起来提高分类模型的可靠度。文献[3]通过维数约简的思想,设法学习出一个低维隐特征空间,使得源域的数据和目标域的数据在该空间的分布相同或接近对方。文献[4, 5, 6, 7]将协同学习、正则化、模糊理论等用于迁移学习,取得了很好的效果。文献[8]同样提出了基于正则化的迁移学习模型,文献[9]提出了图协同正则化的迁移学习。文献[10]将迁移学习的思想用于广告显示。
前面对迁移学习的研究,大多是在源域的数据样本具体标签已知的假设下进行的。本文针对源域中不同类别的数据均值和目标域中少量有标签的数据已知的分类问题,以最小最大概率机分类算法模型为基础,提出TL-MPM算法,本算法最大的优点是并不知道源域的数据训练样本的具体标签,仅知道均值信息,从而减小了对标记源域的数据所需花费的代价。
1 最小最大概率机 1.1 线性部分假设x和y 为2维分类问题的2个随机变量 ,服从某种分布 x~($\bar x$,Σx), y~($\bar y$,Σy),这里 x,y∈Rd, Σx,Σy∈Rd×d,$\bar x$,$\bar y$,Σx,Σy分别为随机变量x和y的均值和方差。最小最大概率机实现分类的目的就是找到一个超平面aT z-b=0,(a,z∈Rd,b∈R)[11],将2类样本在样本估计的均值和方差的前提下,按照最大概率分离 ,所以分类问题可以描述为
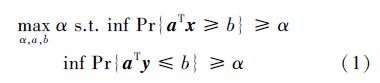


目标函数(3)为凸优化问题[15],假设求得最优解为a*,对应k取得最小值k*,此时(2)式中的不等号变为等号,可得
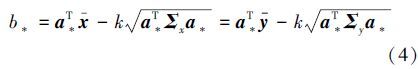
对于测试样本xnew,若a*Txnew-b*≥0则xnew为正样本;反之xnew为负样本。
1.2 非线性部分
样本映射到非线性:x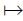 φ(x)~(${\bar \varphi }$(x),Σφ(x))yφ
(y)~(${\bar \varphi }$(y),Σφ(y)),这里
φ:RdRn,核函数可写为K(xi,xj)=φ(xi)Tφ(xj)。核函数用于最小最大概率机,决策超平面写为
aTφ(z)-b=0,其中a,φ(z)∈Rn。表达式(3)非线性形式为
φ(x)~(${\bar \varphi }$(x),Σφ(x))yφ
(y)~(${\bar \varphi }$(y),Σφ(y)),这里
φ:RdRn,核函数可写为K(xi,xj)=φ(xi)Tφ(xj)。核函数用于最小最大概率机,决策超平面写为
aTφ(z)-b=0,其中a,φ(z)∈Rn。表达式(3)非线性形式为

如果a中有一分量正交于 φ(xi),i=1,2,…,Nx和 φ(yi),i=1,2,…,Ny的子空间,Nx、Ny分别为正负标记样本的个数,那么这个分量不会影响到目标函数的结果,因此可以将a写成

设γ=[α1α2…αNxβ1β2… βNy], [Kx]i=K(xj, zi)为核函数,[${\tilde k}$x]i=${1 \over {{N_x}}}\sum {_{j = 1}^{{N_x}}} $ K(xj,zi),[${\tilde k}$y]i=${1 \over {{N_y}}}\sum {_{j = 1}^{{N_y}}} $ K(yj,z i)则约束条件可表示为

又假设1m为m维全1列向量,且${\tilde K}$x= Kx-1Nx${\tilde k}$xT,同样形式${\tilde K}$y=Ky-1 Ny${\tilde k}$yT,其中i=1,2,…,Nx时zi= xi,i=Nx+1,…,Nx+Ny 时zi=y i-Nx,那么正负样本的协方差表达式可表示为
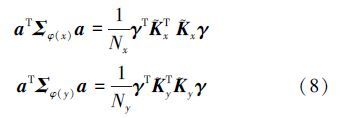
经过上面核化后,约束条件和协方差的表达式变为(7)式和(8)式的形式,带入a表示的 非线性表达式(5)式可得γ表示的非线性目标函数:

显然,与线性部分算法一致。当γ取最优解γ*,对应k取得最小值k*,可得
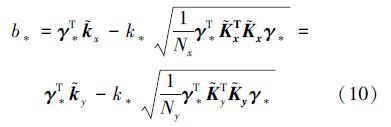
对于测试样本xnew,若 a*T φ(xnew)-b*=∑Nx+Nyi[γ*]i K(zi,xnew)≥0,则xnew为正样本;反之xnew为负样本。
2 基于最小最大概率机的迁移学习分类算法 2.1 TL-MPM算法的应用背景实际问题中,有时候当前分类目标的标记样本并不充分,这样对于分类结果的预测会带来很大偏差。而当前分类目标往往和上一阶段的分类目标比较,既有新的变化,又具有某些类似的特性。比如超市不同季度的营业额、银行不同月份的贷款数、公司每个阶段的出货量、港务每年吞吐量等,一般情况每个阶段虽然有波动,不会有太大的偏差,但由于种种原因,上个阶段的样本信息,并不能完全得知;即使得知,也不能直接将所有信息用在当前阶段中,因为上一阶段的均值往往是易于得知,并且各个阶段数据均值波动基本很小。所以上一阶段均值是对当前阶段极为有用的信息。这样在当前阶段信息不充分的情况下可以充分利用上个阶段的均值信息进行迁移学习。
2.2 TL-MPM算法的理论依据在最小最大概率机训练的过程中,如式(3)所描述的,通过最小化$\sqrt {{a^T}\sum {_xa} } $和$\sqrt {{a^T}\sum {_ya} } $a之和,使得样本在超平面所在空间分布为线性可分的形式,但在样本很少的情况下,协方差和均值并不能很好地代表整体的协方差和均值,那么训练出来的a值实际上并不是最优的。对于相关但不相同的数据,源域的数据和目标域的数据具有相似性,所以均值波动性并不大,可以预测目标域的数据均值与源域的数据均值或多或少是相近的,所以在训练过程中,可以利用源域的数据均值和目标域的数据均值实现数据迁移学习。在具体的实现中,是通过最小化源域的数据均值和目标域的数据均值在超平面所在空间的欧氏距离来实现的。假设源域的数据正负类样本的均值分别为${\bar x}$s和${\bar y}$s,目标域少量数据的样本的均值分别为${\bar x}$t和${\bar y}$t,可得超平面所在空间的均值之间的线性距离可以表示为
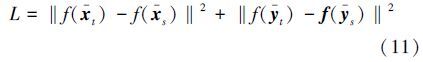
均值之间的非线性距离表示为

TL-MPM算法的理论依据是:若两个领域相关,源域的数据和目标域的数据在超平面所在空间的均值应相近。通过在MPM线性目标式(3)中增加 λL,非线性目标式(5)中增加λLk实现两个域之间的迁移学习。加入迁移学习项后的线性目标函数可以写为
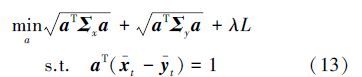
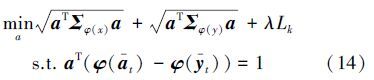

|
| 图 1 TL-MPM算法 Fig. 1 Flowchart of TL-MPM |
为了更清晰地展示TL-MPM算法的作用原理及效果,在二维数据上做了线性算法的模拟实验。图 2为源域样本分布,横轴x表示样本的一维,纵轴y表示样本的二维,图中“×”表示目标域正样本,“+”号表示目标域负样本,菱形和正方形分别表示已知的目标域正样本和负样本,实心圆表示目标域正样本和负样本均值,空心圆表示源域正样本和负样本均值。虚线为目标域少量标记样本在MPM算法下得到的分类超平面,实线为TL-MPM算法下得到的分类超平面。

|
| 图 2 源域样本分布 Fig. 2 Source domain samples |
由图 3可以明显看出,源域正负样本的均值和目标域样本的均值相差并不是很大。正是由于这种源域样本与目标域样本的相关性,经过源域的数据均值与目标域的数据均值的迁移学习,得到的目标域的分类超平面更为准确。

|
| 图 3 二维数据模拟实验 Fig. 3 Two-dimensional simulation experiment |
由于分类超平面为aT x-b=0,那么样本在超平面所在空间的分布可以写为f(x)=aTx-b,所以对线性迁移学习约束项中的前半部分可推导为
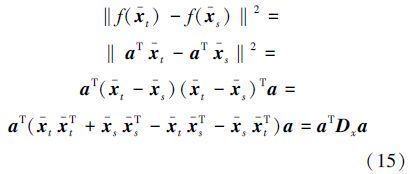
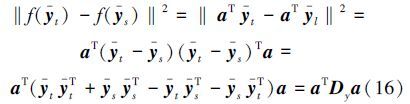
那么,基于最小最大概率机的迁移学习算法对应的线性迁移学习约束项有简单的形式:
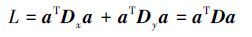
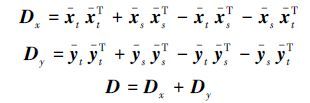
最小化aT Da等价于最小化$\sqrt {{a^T}Da} $,为了便于运算,在不影响结果的情况下,所以基于最小最大概率机的迁移学习算法可以化简成下面形式的目标函数:
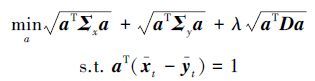
具体求解过程见本文第4部分。由于加入了约束项,b*的表达发生了变化。注意到引入项对正负类的贡献不同,用η(0≤η≤1)表示正类在整个样本中所占的比率。一般情况下η可设置为0.5,那么判别式可由下面公式推导求出:
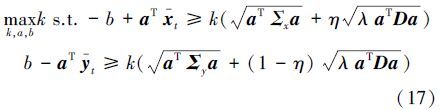
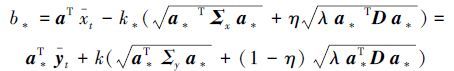
核表示方式是将数据映射到高维空间来增加线性学习器的学习能力。通过选择恰当的核函数来替代内积,可以隐式地将训练数据非线性映射到高维空间。
对应于线性分布,f(φ(x))=aTφ(x)-b为样本在非线性超平面所在空间的分布,且aTφ(x)=γT${\tilde k}$x,非线性迁移学习约束项的前半部分可以推导为
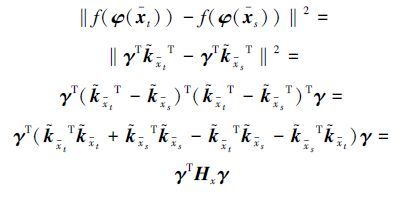
非线性迁移学习约束项的后半部分可推导为

那么,基于最小最大概率机的迁移学习算法对应的迁移学习线性约束项有简单的形式:
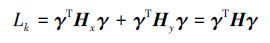
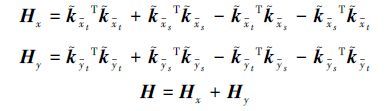
最小化γT Hγ等价于最小化 $\sqrt {{\gamma ^T}H\gamma } $,为了便于运算,在不影响结果的情况下,基于最小最大概率机的迁移学习算法可以化简成下面形式的目标函数:
显然非线性目标函数求解方法与线性一致。当γ取最优解γ*时,对应k取得最小值k*,求取b*推理与线性部分类似,得到b*的表达式为
对于测试样本xnew,若:a*Tφ(xnew)-b*=∑Nl+Nui[γ*]iK(zi, xnew)≥0,则xnew为正样本;反之xnew为负样本。
3 TL-MPM算法解法流程线性部分和非线性部分目标函数形式相同,都是非线性有约束优化问题,并且是凸优化问题。有好多方法可以选择[16, 17, 18],比如拟牛顿法,Rosen梯度投影法等,这里我们用递归最小二乘法对修正优化问题进行求解,下面只解析线性目标函数求解过程。
1)令a=a0+Fv,F的列正交于 ${\bar x}$t- ${\bar y}$t;
2)式(16)可写为
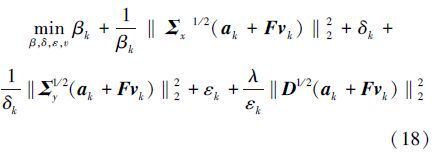
3)令a0=( ${\bar x}$t- ${\bar y}$ t)/‖${\bar x}$t- ${\bar y}$t‖22,β0=1,δ0=1,ε0=1并带入(18)得到最小二乘问题,求解得v0;
4)k=1;
5)ak=ak-1+Fvk-1,βk=$\sqrt {a_{k - 1}^T\sum {_x} {a_{k - 1}}} $,δk= λ$\sqrt {a_{k - 1}^T\sum {_y} {a_{k - 1}}} $,εk=$\sqrt {a_{k - 1}^TD{a_{k - 1}}} $并带入(18)式求解得vk;
6)k=k+1;
7)重复步骤5、6直到收敛或满足停止条件;
8)最后求得:a*=ak,k*=1/(βk+δk+εk), b*=a*T${\bar x}$-k*(β<sub>k+ηεk)。
4 实验结果与分析为了验证TL-MPM算法的有效性,在常用的真实数据集:20 News Groups数据集上进行实验。20 News Groups数据集的信息如表 1所示。
| 大类 | 小类 | 样本个数 |
| comp | comp.graphics | 997 |
| comp.windows.x | 998 | |
| comp.os.mswindows.misc | 992 | |
| comp.sys.ibm.pc.hardware | 997 | |
| comp.sys.mac.hardware | 996 | |
| rec | rec.motorcycles | 997 |
| rec.autos | 998 | |
| rec.sport.baseball | 998 | |
| rec.sport.hockey | 998 | |
| talk | talk.politics.mideast | 1 000 |
| talk.politics.misc | 998 | |
| talk.politics.guns | 1 000 | |
| talk.religion.misc | 999 | |
| sci | sci.crypt | 998 |
| sci.med | 998 | |
| sci.space | 999 | |
| sci.electronics | 999 |
为了方便实验的描述,对实验中涉及的有关符号给出相应的定义,如表 2所示。
| 符号 | 定义 |
| Ds | 源域数据集 |
| Dt | 目标域数据集 |
| T-LMPM | 仅利用目标域少量数据训练得到的目标域MPM线性分类器 |
| T-KMPM | 仅利用目标域少量数据训练得到的目标域MPM非线性分类器 |
| LTL-MPM | 本文提出的TL-MPM算法得到的线性分类器 |
| KTL-MPM | 本文提出的TL-MPM算法得到的非线性分类器 |
首先对数据集分成源域训练数据和目标域训练数据,具体的处理结果如表 3所示。
| Datasets | Ds | Dt |
| comp vs rec | comp.graphics rec.motorcycles | comp.windows.x rec.autos |
| comp vs sci | comp.os.mswindows.misc sci.crypt | comp.sys.ibm.pc.hardware sci.med |
| comp vs talk | comp.sys.mac.hardware talk.politics.mideast | comp.os.mswindows.misc talk.politics.guns |
| rec vs talk | rec.autos talk.politics.misc | rec.sport.baseball talk.religion.misc |
| rec vs sci | rec.autos sci.space | rec.sport.hockey sci.electronics |
| sci vs talk | sci.med talk.religion.misc | sci.space talk.politics.mideast |
其次,由于20News Groups文本数据集的特征数很大,为了实验的方便,用主元分析法对数据集的特征做降维预处理,取前100维构成新的实验数据。
4.2 少量目标域训练样本上的实验结果与分析实验中取源域中的全部数据,分别取目标域中的1%、5%、10%的数据训练TL-MPM算法分类器和MPM算法分类器。在T-MPM和TL-MPM算法中的核函数都选取高斯核函数,参数σ在(0.001,0.01,0.1,1,10,100,1 000)中选取。TL-MPM算法中的参数在(0.001,0.01,0.1,1,10,100,1 000)中选取。对表 3处理好的6个真实分类数据集分别随机独立重复10次实验,选取最优参数下的取值,表 4、表 5和表 6分别记录了10次独立重复实验正确率的均值。
| 数据集 | T-LMPM | T-KMPM | LTL-MPM | KTL-MPM |
| comp vs rec | 71.71 | 72.96 | 72.56 | 78.42 |
| comp vs sci | 66.46 | 74.16 | 72.22 | 76.49 |
| comp vs talk | 90.96 | 99.15 | 99.48 | 99.75 |
| rec vs talk | 60.51 | 71.29 | 66.26 | 76.14 |
| rec vs sci | 62.49 | 71.00 | 64.17 | 76.48 |
| sci vs talk | 68.21 | 77.24 | 67.98 | 76.44 |
| 数据集 | T-LMPM | T-KMPM | LTL-MPM | KTL-MPM |
| comp vs rec | 61.46 | 80.92 | 64.19 | 83.94 |
| comp vs sci | 58.72 | 76.33 | 63.29 | 79.56 |
| comp vs talk | 94.13 | 99.41 | 97.74 | 99.83 |
| rec vs talk | 57.36 | 76.30 | 60.80 | 78.60 |
| rec vs sci | 57.12 | 78.81 | 57.49 | 81.50 |
| sci vs talk | 57.42 | 86.34 | 63.98 | 86.75 |
| 数据集 | T-LMPM | T-KMPM | LTL-MPM | KTL-MPM |
| comp vs rec | 76.46 | 85.51 | 80.05 | 86.06 |
| comp vs sci | 70.87 | 84.75 | 75.00 | 83.70 |
| comp vs talk | 96.16 | 99.32 | 98.66 | 99.69 |
| rec vs talk | 65.30 | 81.64 | 66.74 | 81.56 |
| rec vs sci | 64.93 | 84.89 | 70.17 | 85.90 |
| sci vs talk | 70.49 | 90.18 | 72.17 | 89.09 |
观察并比较表 4、表 5、表 6中T-LMPM和T-KMPM、LTL-MPM和KTL-MPM的列。发现T-KMPM在各数据集上的分类结果优于T-LMPM,KTL-MPM在各数据集上的分类结果优于LTL-MPM。说明该真实数据集是非线性的,线性分类方法有一定的局限性。另外,LTL-MPM在各数据集上的分类结果优于T-LMPM,KTL-MPM在各数据集上的分类结果优于T-KMPM,说明源域对目标域的分类起到了一定程度的作用。但提高的多少取决于两域相关性。注意到,在comp vs rec,comp vs sci,rec vs talk和rec vs sci四个数据集中,本文算法对实验结果有很大程度的提高,说明在这四类数据集上源域与目标域数据的相似性比较高。在comp vs talk数据集上提高程度很小,说明该数据集上源域和目标域相似度不高。在sci vs talk数据集上没有提高,反而下降,源域对目标域数据起了反作用,说明该数据集上源域和目标域相似度很低。
4.3 目标域训练样本变化对分类结果的影响少量目标域训练样本上实验说明该真实数据集是非线性数据,线性算法并不能很好反应数据的分类情况,为了观察TL-MPM算法在样本变化时的有效性,实验中用其非线性算法训练分类器。实验中取源域中的全部数据,取目标域中的1%、5%、10%、20%、30%、40%、50%的数据训练KTL-MPM算法分类器,取目标域中的1%、5%、10%、20%、30%、40%、50%的数据训练T-KMPM算法分类器。其他设置同4.2节。图 4~9分别为6个数据集上的实验结果绘制的折线图。

|
| 图 4 comp vs rec分类精度变化 Fig. 4 Classification accuracy trends of comp vs rec |

|
| 图 5 comp vs sci分类精度变化 Fig. 5 Classification accuracy trends of comp vs sci |

|
| 图 6 comp vs talk分类精度变化 Fig. 6 Classification accuracy trends of comp vs talk |

|
| 图 7 rec vs talk分类精度变化 Fig. 7 Classification accuracy trends of rec vs talk |

|
| 图 8 rec vs sci分类精度变化 Fig. 8 Classification accuracy trends of rec vs sci |

|
| 图 9 sci vs talk分类精度变化 Fig. 9 Classification accuracy trends of sci vs talk |
观察发现,在目标域训练样本增加时,两种算法的精确度都有提高,在目标域训练样本量较少时(10%以内),除sci vs talk数据集,其他数据集上KTL-MPM算法都好于T-KMPM算法,说明样本较少时,本文提出算法的优势很明显。在目标域训练样本增加到一定程度时,两算法的精度差距在逐渐缩小,最后几乎一致,甚至被T-KMPM算法反超,说明样本增大时,目标域的训练数据的信息越来越多,偏差越来越小,迁移过来的源域均值信息已经无法矫正该偏差,因为这个偏差已经小于了源域与目标域之间的偏差。这时迁移过来的源域均值信息甚至转化为了噪声信息,所以精确度反而变低。
另外,本文算法并没有增加算法的时间复杂度,分析算法部分可知,该算法线性部分的时间复杂度为O(kd3),非线性部分的时间复杂度为O(kn3),这是因为在最小二乘递归过程中需要求矩阵的逆,其中k为迭代次数,d、n分别为目标域训练样本的维数和个数。
5 结束语本文针对目标域标记数据个数很少,而源于数据仅知道均值的背景下,提出了基于最小最大概率机的迁移学习分类算法,将源域的均值数据用来修正目标域因训练数据少而带来的分类偏差。实验表明,在目标域训练样本个数很少的情况下,取得了很好的效果,另外将最小最大概率机分类算法扩展到了迁移学习的领域。由于该算法仅利用了源域数据的均值信息,并不能从多方面挖数据的相似之处,这既是该算法的优点,也是本算法的不足之处。
| [1] | PAN S J, YANG Qiang. A survey on transfer learning[J]. IEEE transactions on knowledge and data engineering, 2010, 22(10):1345-1359. |
| [2] | DAI Wenyuan, YANG Qiang, XUE Guirong, et al. Boosting for transfer learning[C]//Proceedings of the 24th International Conference on Machine learning. New York, NY, USA, 2007:193-200. |
| [3] | PAN S J, KWOK J T, YANG Qiang. Transfer learning via dimensionality reduction[C]//Proceedings of the 23rd National Conference on Artificial Intelligence. AAAI, 2008, 2:677-682. |
| [4] | 张景祥, 王士同, 邓赵红, 等. 具有协同约束的共生迁移学习算法研究[J]. 电子学报, 2014, 42(3):556-560. ZHENG Jingxiang, WANG Shitong, DENG Zhaohong, et al. Symbiosis transfer learning method with collaborative constraints[J]. Acta electronica sinica, 2014, 42(3):556-560. |
| [5] | 于重重, 吴子珺, 谭励, 等. 非平衡集成迁移学习模型及其在桥梁结构健康监测中的应用[J]. 智能系统学报, 2013, 8(1):46-51. YU Chongchong, WU Zijun, TAN Li, et al. Unbalanced integrated transfer learning model and its application to bridge structural health monitoring[J]. CAAI transactions on intelligent systems, 2013, 8(1):46-51. |
| [6] | 毕安琪, 王士同. 基于SVC和SVR约束组合的迁移学习分类算法[J]. 控制与决策, 2014, 29(6):1021-1026. BI Anqi, WANG Shitong. Transfer classification learning based on combination of both SVC and SVR's constraints[J]. Control and decision, 2014, 29(6):1021-1026. |
| [7] | 蒋亦樟, 邓赵红, 王士同. ML型迁移学习模糊系统[J]. 自动化学报, 2012, 38(9):1393-1409.JIANG Yizhang, DENG Zhaohong, WANG Shitong. Mamdani-larsen type transfer learning fuzzy system[J]. Acta automatica sinica, 2012, 38(9):1393-1409. |
| [8] | LONG Mingsheng, WANG Jianmin, DING Guiguang, et al. Adaptation regularization:a general framework for transfer learning[J]. IEEE transactions on knowledge and data engineering, 2014, 26(5):1076-1089. |
| [9] | LONG Mingsheng, WANG Jianmin, DING Guiguang, et al. Transfer learning with graph co-regularization[J]. IEEE transactions on knowledge and data engineering, 2014, 26(7):1805-1818. |
| [10] | PERLICH C, DALESSANDRO B, RAEDER T, et al. Machine learning for targeted display advertising:transfer learning in action[J]. Machine learning, 2014, 95(1):103-127. |
| [11] | LANCKRIET G R G, EL GHAOUI L, BHATTACHARYYA C, et al. A robust minimax approach to classification[J]. The journal of machine learning research, 2003(3):555-582. |
| [12] | ISII K. On the sharpness of Chebyshev-type inequalities[J]. Annals of the institute of statistical mathematics, 1963(14):185-197. |
| [13] | BERTSIMAS D, SETHURAMAN J. Moment problems and semidefinite optimization[M]//WOLKOWICZ H, SAIGAL R, VANDENBERGHE L. Handbook of Semidefinite Programming. 3rd ed. US:Springer, 2000:469-509. |
| [14] | CHERNOFF H. The selection of effective attributes for deciding between hypotheses using linear Discriminant functions[C]//The Proceedings of the International Conference on Frontiers of Pattern Recognition. New York, USA, 1972:55-60. |
| [15] | 陈宝林. 最优化理论与算法[M]. 2版. 北京:清华大学出版社, 2005. CHEN Baolin. Optimization theory and algorithm[M]. 2nd ed. Beijing:Tsinghua University Press, 2005. |
| [16] | PLAN Y, VERSHYNIN R. Robust 1-bit compressed sensing and sparse logistic regression:a convex programming approach[J]. IEEE transactions on information theory, 2012, 59(1):482-494. |
| [17] | BENSOUSSAN A, TEMAM R. Equations aux derivees partielles stochastiques non iineaires[J]. Israel journal of mathematics,1972,11(1):95-129. |
| [18] | BOYD S, VANDENBERGHE L, FAYBUSOVICH L. Convex optimization[J]. IEEE transactions on automatic control, 2006, 51(11):1859. |