

DOI: 10.11992/tis.201601001

 , , ,
, , ,
, , ,
, , ,
在计算机视觉和模式识别领域,图像识别是一类相当常见的问题。它的作用是预测一幅图像的类别标签,或者标注出图像内容的属性。在使用分类器对图像所属类别进行预测之前,一般会使用合适的特征对图像进行描述。特征词袋(bag-of-features, BoF)是一种常用的简洁而高效的图像中级特征(mid-level feature)学习模型。一个基本的BoF模型通常包含5个部分,提取图像块、描述图像块、视觉词典学习编码(coding)和池化(pooling)[1]。其中,视觉词典学习作为BoF模型的核心, 集中了大量的研究工作,有不少基于监督[2]和无监督[3]的视觉词典学习算法被提出,比如K-means[4]、稀疏编码[5]等都可作为词典学习算法被集成在BoF模型中。对于如何找到更好的池化区域,来生成包含更多局部性信息的图像特征,同样吸引了众多研究者的目光。其中,空间金字塔模型(spatial pyramid matching)是一种常用的区域选取策略,他将特征图分割成为一个一个逐层细化的空间子区域,之后在这些子区域上分别进行池化操作[6]。Coates等[7]通过对特征图之间相似性的分析,使用贪婪方法,将相似性较高的特征图分为一组,从而使得特征表达获得了一定的旋转不变性,Jia等[8]对于空间金字塔模型进行了进一步的扩展,定义了一组超完备(over-complete)的池化区域,该区域是由所有在特征图上可能存在的矩形区域组成,并在此基础上提出了感受野学习(receptive field learning)的概念,通过在超完备词典生成的特征图上的超完备区域中选择那些最为有效区域。在这些被选择的池化区域上计算图像的特征表达。
本文的工作正是基于Jia等[9]提出的超完备区域的感受野学习方法的进一步改进,在感受野学习的同时考虑对视觉词典规模进行限制,同时实现BoF模型中的视觉单词和池化区域的精简,从而到达优化BoF模型结构的目的。另外,与其他的词典简化方法相比,该方法充分考虑到了池化的作用和分类任务对视觉单词的需求。
1 Bag-of-features模型BoF模型的核心思想是将图像表示成为一组无序特征的集合,通过统计每一种特征的响应强度来构造一个描述图像的直方图,即图像的中级特征表达。利用图像特征响应的直方图统计,可以训练分类器对图像中所表达的内容进行识别。BoF模型具有简洁、高效等特点,但同时BoF模型在最初提出时是为了解决图像检索问题,对每种特征在整幅图像中的出现次数进行统计,无法对结构信息和空间信息进行有效表示[9]。
BoF模型图像分类框架如图 1所示。

|
| 图 1 面向图像识别的Bag-of-features模型框架图 Fig. 1 Bag-of-features pipeline for image classification |
通常将输入图像(或低级特征,比如SIFT、HOG等)使用视觉词典中的视觉单词进行编码,从而得到一组特征响应的分布图。相对于BoF模型在图像检索领域的应用,局部空间的特征直方图对于图像识别具有更重要的作用。因此对于特征图进行分块池化操作,可以使特征表达中包含多个区域、多个尺度上的特征统计信息。
1.1 词典学习建立BoF模型的第一步就是使用学习算法获得一个视觉词典(codebook)。为此,要从训练样本中随机提取图像块(patch)。然后选择一个学习算法,使用这些图像块作为算法的训练样本。常用的词典学习算法有很多,总体上可分为有监督和无监督2类。在这里介绍两种高效的无监督词典学习方案,K-means和OMP-K学习算法[10]。
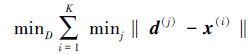 |
(1) |
K-means聚类算法[11]是一种快速而且易实现的学习算法,其通过最小化式(1) 中的平方距离来搜索训练数据的K个聚类中心,从而可以得到一个大小为K的词典。在式(1) 中,x(i)是由输入的图像块或者初级特征组成的向量,d(j)是所求的聚类中心,每一个聚类中心可以被视为一个视觉单词, 他们共同构成了一个完整的大小为K的词典D。
OMP-K是另外一种无监督学习算法,该算法通过交叉迭代公式(2) 中的损失函数,在服从约束条件的前提下最小化重构误差,来获得词典D。它与K-means算法的主要区别在于,在学习阶段每个图像块最多使用K个视觉单词计算最小误差,而K-means算法每个图像块仅属于一个视觉单词(聚类中心)。
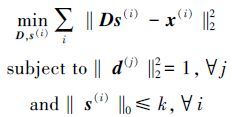 |
(2) |
式中:‖s(i)‖0使用0范数表示编码s(i)中非零元素的数量,每个视觉单词d(j)为词典D中一列。使用OMP-K算法计算式(2) ,可以得到词典D。
1.2 特征编码在完成词典学习之后,需要对输入的数据(图像或者初级特征)进行编码。软阈值(soft thresholding)编码通过计算数据与视觉单词之间的内积对数据进行编码,如式(3) 。其中,阈值α的引入,为编码后的特征带来一定的稀疏性[12]。
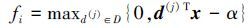 |
(3) |
但是,软阈值方法需要手工指定阈值α,为了克服手工指定参数对编码效果的影响。Coates等[4]提出了一种三角编码算法(triangle)。该方法中,当数据x(i)到视觉单词d(k)的距离大于数据x(i)到所有视觉单词d(k)的平均距离μ(z)时,特征对应的值为0,
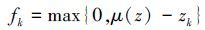 |
(4) |
式中:zk=‖x(i)-d(k)‖2表示数据到视觉单词的欧式距离,μ(z)是zk的平均值。
每一个样本在进行编码后,会得到K个特征图。这里,K为词典中视觉单词的个数。
1.3 池化池化作为BoF模型中的一个关键步骤,它通过聚合运算(比如:计算最大值或均值)将一个矩形区域内的特征转换成为一个标量值,从而减少特征的数量。除了降低特征表达的维数之外,池化能够为特征表达带来一些非常有用的特性,比如平移不变性。
另外,为获得更加丰富的特征空间分布的统计信息,规则网格结构、空间金字塔、超完备(如图 2)等池化区域方案被相继提出,使BoF特征保留了更多的局部统计信息。

|
| 图 2 Pooling区域 Fig. 2 Pooling regions |
通常,池化可以用如式(5) 的形式进行表示[13]
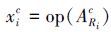 |
(5) |
式中:xic是池化后得到的特征,c和Ri分别表示特征图对应的视觉单词的下标,以及特征图上的池化的区域,ARic表示池化区域内的一组特征的集合,op(·)表示在ARic之上进行的聚合。
2 改进的感受野学习算法本节的算法是在Jia等[8]的基础上,增加对于视觉词汇数量增长的限制,从而实现感受野学习和选择有效视觉单词的双重效果。算法中使用了Perkins等[14]提出的grafting方法对特征的重要性进行判断,grafting全称梯度特征测试(gradient feature testing),需要候选特征的梯度值作为重要性判断的依据,因此要首先定义分类器及其目标函数。
2.1 分类器本文定义了一个多类线性分类器,使用BoF模型特征对标签进行预测,
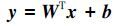 |
(6) |
式中:x是输入图像的特征表达向量,W和b分别为权值矩阵和偏置,y为分类器的预测结果。式(7) 定义了分类器的目标函数,通过最优化算法求出目标函数的最优解,来确定参数W和b
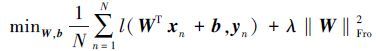 |
(7) |
式中:xn和yn分别表示训练样本和对应的标签,N是用于训练的样本总数。‖W‖Fro2是权值矩阵W的F-范数的平方,用于限制权值矩阵中元素值的大小,起到了降低结构复杂度和抑制过拟合的作用。上式第一项中的l(·)表示多类扩展二项负对数似然函数(BNLL),用于衡量线性分类器对于训练数据的适应程度,其具体定义为
 |
(8) |
式(8) 中的ln(·)表示自然对数函数,P是指标签的类别总数, W., i表示矩阵W中的一列。
2.2 感受野学习为了找到最为合适的感受野,将通过计算目标函数相对于每个特征对应的权值矩阵元素的梯度值来判断特征的重要性。首先,初始化一个空集合S来保存已选择的特征,所有没有被选择的特征组成一个候选集合Sc。在每次迭代中,针对候选集合Sc中每个特征计算一个分值,如式(9) 所示。选择分值最大的特征加入集合S,并将其从Sc中移除。直到集合S中特征的数量达到一个指定的值,迭代停止。此时集合S中特征所对应的感受野既是针对该分类任务最为有效的感受野。
与Jia等人提出的感受野学习方法[8]不同,本方法在计算特征分值的基础上进一步对特征图进行了区分,将未被选入的特征图所包含特征的分值进行衰减,使感受野学习的过程更加倾向于选取已被选择的特征图上的特征,如式(9)
 |
(9) |
式中:L(W, b)是式(6) 中所定义的目标函数,Wj, .表示矩阵W中的一行,η是针对未选中特征图中候选特征的衰减因子,其取值范围为 [0, 1) ,M(j)用于表示当前第j个特征是否在选中的特征图之上,其表示为
 |
(10) |
式中:如果特征图上含有已选中特征,则认为该图被选取,其M(j)值为1。
在每一次迭代后,新的特征被加入集合S。在此特征集合之上,需要对分类器参数W和b进行重新计算。将上次迭代计算出的W和b作为重新计算时的初始状态,以有效地减少计算参数所消耗的时间。
3 实验与分析 3.1 实现过程实验中主要使用了CIFAR-10数据库[19]对文中提出的算法进行训练和验证。CIFAR-10是由加拿大多伦多大学教授Hinton等发布的一个用于图像识别算法评估的数据库,该数据库中包含了50 000个训练样本和10 000个测试样本,共分为10类。
在使用样本训练和测试前,都要对样本数据进行归一化和白化处理,这样能够提高BoF模型特征的预测性能。
从训练样本中随机提取5×5的图像块用于词典学习,选择K-means作为词典学习的算法,以及triangle作为编码算法。输入图像经编码后会形成28×28的特征图,然后最大值池化会将每张特征图上7×7相邻但不重叠的空间区域聚合成为一个特征,因此每张特征图被降维到4×4的大小。超完备的池化区域以及对照实验都将基于这些池化后的特征图。
在训练分类器时,式(7) 中的参数λ固定为0.01,用于超完备池化区域和感受野学习实验。对于其他预定义的池化区域(比如网格结构和空间金字塔),在实验中使用L2-SVM作为分类器,其参数通过五折交叉验证的方式搜索确定。
3.2 算法性能测试表 1将本文提出的改进的感受野学习算法,同原有方法[8]以及几种常用的池化策略进行了比较。表中包括网格结构的池化区域(2×2,4×4) ,空间金字塔(spatial pyramid matching, SPM),超完备感受野(over-complete, OC),基于超完备感受野的感受野学习(OC+学习),本文方法是在超完备感受野上的实验结果(OC+改进算法)。
在未使用学习策略的池化方案中,由于超完备感受野能够较好地捕获特征图中的空间信息,因此得到了较高的分类精度。在增加学习策略之后冗余被消除,超完备感受野又获得了0.28%的提升。在此基础上使用本文方法,以一个较大的词典作为初始词典,同时在学习过程中对词典规模的增长进行了限制。例如在表 1中,分别以400和800为初始词典大小,将衰减因子η设为0.7和0.8,在词典规模为200时,学习到了4 408和5 370个特征。尽管使用的特征数有所减少,但是分类结果却比原有算法提高了0.23%和1.27%。该结果说明了改进算法的有效性。
3.3 参数η的影响本节实验中,在CIFAR-10数据库上比较了3种衰减因子η值下,学习算法所受到的影响(如图 3)。首先,使用K-means算法得到一个大小为1 600的词典。然后,以该词典生成的特征图为基础,分别将η值设为0、0.3和0.7,观察和比较在学习过程中,精度和词典规模的增长。其中,当η值设为0时(即不对词典的增长进行衰减),则本方法与Jia等提出的学习方法[8]等价。

|
| 图 3 不同η值对应的分类精度及词典规模增长曲线 Fig. 3 The curve of classification accuracy and codebook scale with different η |
在图 3(a)是分类精度跟随感受野数量(即感受野对应的特征数)增长的曲线,图 3(b)是视觉单词量随感受野数量增长的曲线。可以看出,在这3种η值情况下,精度的增长受到的影响不大,而视觉单词数量却受到了明显抑制,说明算法能够对于分类贡献较低的视觉单词进行识别。
在表 2中,池化区域为OC,比较了图 3中的实验在学习6 400个感受野时的状态。从表中可以看出,随着η值的增加,所需的视觉单词的数量不断下降。而且对于特征图数量增长一定程度上的限制,对分类结果也会有一些提高。现象也说明了基于梯度的贪婪算法并不能确保针对分类任务获得一个最优的特征集合。
| 词典规模 | 衰减因子 | 精度/% |
| 1 477(1 600) | 0 | 79.80 |
| 963(1 600) | 0.3 | 80.13 |
| 357(1 600) | 0.7 | 79.39 |
使用CIFAR-100数据库重复上述实验。这里,由于数据库有100类对象,更大的权值矩阵W使得算法对η值变得更敏感,因此实验中选择的η值为0、0.1和0.3。在表 3中,可以看到与CIFAR-10上类似的实验结果。
3.4 样本数量的影响为了研究训练样本数量对本文所描述的算法的影响程度,随机从CIFAR-10数据库中选择出多个样本子集作为训练数据,使用这些子集学习词典和感受野。除此之外,使用同样样本子集训练卷积神经网络(convolutional neural networks, CNN)[15],与本文中提出的算法进行对比。
| 词典规模 | 衰减因子 | 精度/% |
| 1 273(1 600) | 0 | 54.88 |
| 821(1 600) | 0.1 | 55.04 |
| 313(6 400) | 0.3 | 54.28 |

|
| 图 4 训练样本数量对分类精度和词典规模的影响 Fig. 4 Effects of training sample size on classification accuracy and codebook scale |
作为参照对象的CNN使用了Lin等人提出的Network in Network模型[16]。该模型曾在CIFAR-10数据库上获得了准确率89.21%的最好成绩。在实验中,逐渐的减少训练样本的数量,使用了完整的50 000个样本,以及随机抽取的20 000、10 000和5 000个样本分别进行试验。在本文算法的实现过程中,一组实验采用相同的初始词典大小,对于不同大小的训练集均取1 600个视觉单词,称为算法1。另一组随着样本数量的减少逐步扩大初始词典的规模,分别使用1 600,3 200,4 800和6 400个视觉单词,称为算法2。实验中的η被固定为0.3。
在图 4(a)中,可以发现在训练集规模较大的情况下,CNN模型具有更高的分类精度。伴随着训练样本数量的减少CNN模型的性能逐渐下降。当训练样本数量为10 000时,CNN模型同本文中的BoF模型性能相当。另外,算法2由于逐步提高了初始词典的大小,对于分类性能的损失产生了一定的补偿作用,因此略好于使用固定初始词典大小的算法1的结果。
在图 4(b)中,学习后的词典规模稳定在一定范围内。尽管算法2的初始词典大小在不断增加,但是实际使用的词典并没有随着初始词典而膨胀。因此,在计算能力允许的情况下,可以使用较大的初始字典,本文提出的方法可以学习到一个大小合适的模型。
通过以上分析,认为针对小样本集的目标识别问题,BoF模型依然是一种十分有效的工具。
3.5 分析讨论实验验证了方法的有效性,可将感受野学习和选择有效视觉单词相结合,用于对BoF模型的精简。尽管对于词典进行了大量的删减,但是对于精度仅产生了较小影响,从侧面说明了模型中包含了很多与分类无关的冗余参数。
然而,本文提出的方法仍有几点不足需要进一步改进。首先,通常对于参数η的调节缺少指导性的原则,只能通过尝试多个η值来估计合适的取值。其次,如何指定一个合适的特征数,同样缺乏指导原则。一般来说,可以指定一个较大的特征数,观测算法在验证集上的效果,从而做出判断。
4 结束语本文通过对现有的感受野学习方法的分析和研究的基础上,提出了一种改进型的感受野学习算法。相比于原有算法,本文提出的方法除了考虑生成特征的空间区域和词典对于分类的影响之外,还将去除词典中低效的视觉单词纳入学习过程。使用此方法,从词典大小和池化区域两方面对BoF模型的规模进行了精简。实验结果表明,本文提出的方法能够利用更少的词典规模形成更有效的特征表达,即使在使用相同初始词典的情况下,也可以较少冗余成分对于分类任务的干扰,提高BoF模型生成的特征表达的表达能力,从而提高分类精度。特别是在训练样本较小的情况下,具有一定的应用价值。
| [1] | HUANG Yongzhen, WU Zifeng, WANG Liang, et al. Feature coding in image classification:a comprehensive study[J]. IEEE transactions on pattern analysis and machine intelligence , 2013, 36 (3) : 493-506 |
| [2] | YANG Jianchao, YU Kai, GONG Yihong, et al. Linear spatial pyramid matching using sparse coding for image classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, 2009:1794-1801. |
| [3] | YU Kai, ZHANG Tong, GONG Yihong. Nonlinear learning using local coordinate coding[C]//Advances in Neural Information Processing Systems 22:23rd Annual Conference on Neural Information Processing Systems. Vancouver, British Columbia, Canada, 2009:2223-2231. |
| [4] | COATES A, NG A, LEE H. An analysis of single-layer networks in unsupervised feature learning[J]. Journal of machine learning research , 2011, 15 : 215-223 |
| [5] | GREGOR K, LECUN Y. Learning fast approximations of sparse coding[C]//Proceedings of the 27th International Conference on Machine Learning. Haifa, Israel, 2010. |
| [6] | LAZEBNIK S, SCHMID C, Ponce J. Beyond bags of features:spatial pyramid matching for recognizing natural scene categories[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, NY, USA, 2006, 2:2169-2178. |
| [7] | COATES A, NG A Y. Selecting receptive fields in deep networks[C]//Advances in Neural Information Processing Systems 24:25th Annual Conference on Neural Information Processing Systems. Granada, Spain, 2011:2528-2536. |
| [8] | JIA Yangqing, HUANG Chang, DARRELL T. Beyond spatial pyramids:receptive field learning for pooled image features[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, 2012:3370-3377. |
| [9] | SIVIC J, ZISSERMAN A. Video google:a text retrieval approach to object matching in videos[C]//Proceedings of the Ninth IEEE International Conference on Computer Vision. Nice, France, 2003:1470-1477. |
| [10] | COATES A, NG A Y. The importance of encoding versus training with sparse coding and vector quantization[C]//Proceedings of the 28th International Conference on Machine Learning. Bellevue, WA, USA, 2011. |
| [11] | JAIN A K. Data clustering:50 years beyond K-means[J]. Pattern recognition letters , 2010, 31 (8) : 651-666 DOI:10.1016/j.patrec.2009.09.011 |
| [12] | 汪启伟. 图像直方图特征及其应用研究[D]. 合肥:中国科学技术大学, 2014. WANG Qiwei. Study on image histogram feature and application[D]. Hefei, China:University of Science and Technology of China, 2014. |
| [13] | BOUREAU Y L, ROUX N L, BACH F, et al. Ask the locals:multi-way local pooling for image recognition[C]//Proceedings of the 2011 International Conference on Computer Vision. Barcelona, Spain, 2011:2651-2658. |
| [14] | PERKINS S, LACKER K, THEILER J. Grafting:fast, incremental feature selection by gradient descent in function space[J]. Journal of machine learning research , 2003, 3 : 1333-1356 |
| [15] | LECUN Y, BOSER B E, DENKER J S, et al. Handwritten digit recognition with a back-propagation network[C]//Advances in Neural Information Processing Systems 2:3rd Annual Conference on Neural Information Processing Systems. Vancouver, British Columbia, Canada. San Francisco, CA, USA, 1989:396-404. |
| [16] | KRIZHEVSKY A. Learning multiple layers of features from tiny images[D]. Toronto, Canada:University of Toronto, 2009. |