



2. 辽宁省数字化矿山装备工程技术研究中心, 辽宁阜新 123000
2. LiaoNing Digital Mining Equipment Engineering Technology Research Center, Fuxin 123000, China
人脸识别一直是模式识别和计算机视觉领域的研究热点。人脸图像像素矩阵较大同时特征维数也较高,进行识别难度较大,因此设计出高效的特征提取器成为人脸识别的关键。其中最典型方法为主成分分析法(principal components analysis,PCA)[1],其思想首先,把一副图像按行或列拉直成一个高维列向量,然后,求取整个训练样本集高维列向量的协方差矩阵,求此协方差矩阵的特征向量和特征值得到投影变换矩阵,最后,把人脸图像高维特征通过投影变换矩阵映射到低维空间中,得到人脸的低维表示特征;在人脸识别研究中,利用PCA方法对高维特征进行降维处理,获得了良好的效果,是最为成功的线性鉴别分析方法之一。但实际的应用中,PCA方法进行线性鉴别分析通常会产生小样本问题(即样本个数远小于特征维数);被识别人脸图像是在非限制条件下提取时,应用PCA算法提取的特征并不适合作为分类的特征。
人们利用深度神经网络进行人脸识别主要分为2类:1)利用深度神经网络特征提取后再应用其他分类器进行识别[2, 3, 4, 5, 6];2)直接在深度神经网络增加分类层进行识别[7, 8]。汤晓鸥[9]等利用卷积神经网络进行人脸验证取得了良好的效果,在LFW人脸库上的识别率已经达到99.15%;解决了人脸识别问题中的二分类问题。
为了解决传统人脸识别方法在复杂背景下和人脸多姿态条件下进行识别时,识别率不高的问题,本文提出了一种特征加权融合人脸识别方法。本文的主要贡献是通过将人脸面部进行区域划分提取得到了人脸面部的局部特征,并结合整幅人脸的全局特征进行相似度矩阵的求取,通过各部分的贡献度不同进行加权得出最终判别结果,提出了基于相似度矩阵加权的深度网络模型(deep learning and weighted fusion,DLWF+)人脸识别方法。
1 基于相似度加权评分深度网络模型 1.1 问题描述利用传统深度信念网络[10, 11]进行人脸识别,输入的是整张人脸的像素级特征,忽略了人脸图像局部结构特征,网络难以学习得到人脸局部特征[12];在自然条件下,所获得的人脸图像通常受到背景、光照等外界因素的影响,很难确定哪些面部器官在识别过程中所起到的比重大,哪些器官起的比重小,使得在实际研究过程中对相似度加权的权值确定变得复杂。因此本文重点解决提取人脸局部特征的深度学习模型及多特征加权识别方法权值确定2个问题。
1.2 基本思想为建立人脸面部局部特征深度学习模型,首先利用人脸面部的主要特征点将人脸分成若干子区域;然后将这些小的子区域和整幅人脸经归一化处理,输入到对应的DBN网络进行训练,得到各个子区域和整幅人脸的相似度概率向量;最后将左眼、右眼、鼻子、嘴、下巴等器官和整个面部的相似度向量加权后进行分类。DLWF+分为以下4个主要阶段:
1)人脸面部区域划分
利用haar方法进行人脸检测,提取出人脸面部主要区域,并根据人脸面部主要器官左眼、右眼、鼻子、嘴巴、下巴等进行子区域的划分。
2)网络模型的构建并确定权值
利用上一步求取得到的各个区域和整幅人脸图像分别输入到对应的子网络中,进行权值的调整,完成网络模型的构建。对各个子区域分别进行识别得出识别率作为各自的权重。
3)求取面部隶属度矩阵
通过将测试集不同区域的采样块分别输入到对应的子网络中,取出个区域的相似度向量,并利用求得的各个相似度向量组成相似度矩阵。
4)加权求和得出识别结果。
将相似度矩阵进行加权得出测试图像对应于每个类别的综合评分,评分最高的类别即作为最终的识别结果。
1.3 基本原理 1.3.1 主动形状模型主动形状模型是由Cootes等[13, 14, 15]在1995年提出。该模型主要由全局形状模型和局部纹理模型构成。
1)全局形状模型
ASM利用点分布模型表示人脸形状Si,Si= 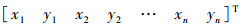 (n为特征点数目),其中具有N个训练样本的训练集表示为Ω={S1,S2,…,SN}。
(n为特征点数目),其中具有N个训练样本的训练集表示为Ω={S1,S2,…,SN}。
将训练样本对齐完成后,采用主成分分析(PCA)方法建立形状模型,过程如下:
①计算对齐完成后训练样本平均形状:

②计算形状向量的协方差矩阵:
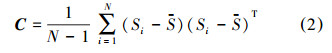
③对C进行特征分解,得到特征值λk(λk≥λk+1,λk≠0,k=1,2,…,2n)和特征向量Pk。
④提取前t个特征值  ,令
,令

式中:η为所选特征占总特征比例,一般为95%~98%。求得特征向量  ,最终求得全局形状模型:
,最终求得全局形状模型:

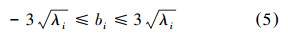
2)局部纹理模型
局部纹理模型构建过程如下:
①以第i个样本第j个标定点为中心,与相邻2点连线垂直方向一定长度范围(也称Profile邻域),内外各取k个点的灰度值作为该点灰度信息:

②求gij梯度dgij:
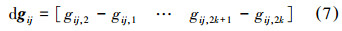

对训练样本集所有图像的第j个特征点进行相同操作,求得第j个特征点的N个局部纹理G1j,G2j,…,GNj。
③得到标记点j对应的平均纹理G j和协方差矩阵Cgj,即为该点的局部纹理模型。

局部纹理模型作用是在搜索过程中,确定每个特征点最佳候选点。其中,马氏距离d(G′j)最小的点,就是该特征点的最佳候选点。

利用上述模型方法提取到的77个面部特征点如图 1所示。
 | 图 1 人脸面部特征点 Fig. 1 Facial feature points |
DBN模拟人大脑的组织结构,由低级到高级地提取数据的抽象特征[16]。DBN由多个RBM堆叠而成,RBM被当做是一个动力学系统在给定一组状态(v,h)下的能量定义为
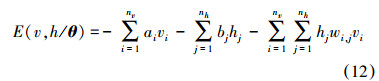
用向量形式表示为
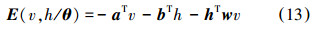
当给定模型参数θ={a,b,w}时,利用式(12)定义的能量函数,可以求出可视层v和隐含层h联合概率分布:

当给定可视层节点时,隐含层节点hi为0或1的条件概率分布为

当给定隐含层节点时,可视层节点vi为0或1的条件概率分布为

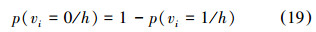
第k和k+1层隐含单元满足:
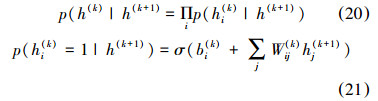
 | 图 2 DBN结构模型 Fig. 2 DBN structure model |
Softmax回归将只能够解决二分类问题的Logistic回归扩展至能够解决多分类问题。
假定Softmax回归模型训练样本来自k个不同的类别,共有m个,那么这m个训练样本组成的训练样本集为{(x(1),y(1)),…,(x(m),y(m))},则Softmax回归的假设函数为
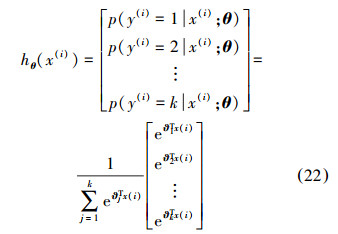
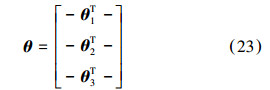
则模型代价函数定义:
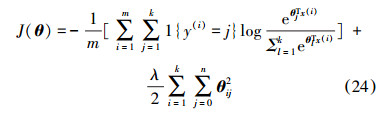
式中:1{ ·}表示指示函数,花括号中表达式为真,那么函数值为1,否则函数值为0。加号后面部分为了防止模型过拟合所加的权衰减项。其中,λ为模型参数,在实验部分确定。分析可知无法直接求取可以使J(θ)最小的θ的解析解,通过迭代优化算法求解。计算代价函数梯度公式为

本文研究重点内容如下:
1)面部区域划分
利用主动形状模型确定人脸面部主要特征点,对于每张人脸面部图像能得到一个特征点位置向量:

①左眼子区域划分
左眼区域采样框确定,根据左眼眼角确定采样框长,眉毛轮廓线最高点与眼睛轮廓线最低点确定采样框宽。为了获取左眼区域更多细节特征,长和宽同时向外延伸Lleye个像素。左眼区域长宽计算公式如下:
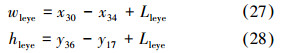
②右眼子区域划分
右眼区域采样框确定,根据右眼眼角确定采样框长,眉毛轮廓线最高点及眼睛轮廓线最低点确定采样框宽。为获取右眼区域更多细节特征,长和宽同时向外延伸Lreye个像素。此区域长宽计算公式为
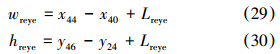
③鼻子子区域划分
鼻子区域采样框确定,根据鼻子轮廓线最低点及眉毛轮廓线最前端特征点确定鼻子区域采样框长。根据鼻子轮廓线最左边特征点及最右边特征点确定采样框的宽。长和宽同时向外延伸Lnose个像素。鼻子区域长宽计算公式如下:
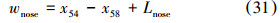

④嘴子区域划分
嘴部区域采样框确定,根据嘴部特征点的左右嘴角确定采样框长。根据嘴部轮廓最上面特征点及最下面特征点位置确定采样框宽。并且长和宽同时向外延伸Lmouth个像素。嘴部区域长宽计算公式为:
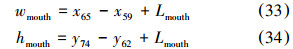
⑤下巴子区域划分
下巴区域采样框确定,根据与嘴角连线平齐的下巴轮廓线上2个特征点确定下巴采样框长,根据这2个特征点及下巴轮廓线最低点确定下巴采样框宽。长和宽同时向外延伸Lchin个像素。下巴区域长宽计算公式如下:
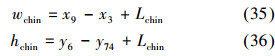
将一个m×n的图像矩阵I按上述长宽截取5个子区域并和整幅人脸图像组成训练集即
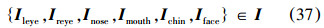
应用双线性内插法将上述区域归一化到固定大小,经过上述步骤截取得到的5个不同区域的采样块与整幅人脸图像一起构成了网络的训练样本集,如图 3所示。
 | 图 3 子区域划分 Fig. 3 Sub region division |
2)构造区域网络模型
由于截取得到的人脸面部5个子区域及整幅人脸图像大小不同,因此输入层结点个数也不相同,需要分别为5个人脸面部区域及整幅人脸图像构建相应的DBA网络,网络结构如图 4所示。
 | 图 4 子区域网络结构 Fig. 4 Sub region network structure |
隶属度求取网络是一个5层DBA网络,由1个输入层、1个输出层和3个隐含层构成。如表 1所示。
| 结点数目 | 左眼 | 右眼 | 鼻子 | 嘴巴 | 下巴 | 人脸 |
| 输入层 | w leye ×h leye | w reye ×h reye | w nose ×h nose | w mouth ×h mouth | w chin ×h chin | W face ×h face |
| 隐含层1 | β 1 leye ×L 1 | β 1 r eye ×L1 | β 1 nose ×L1 | β 1 mouth ×L1 | β 1 chin ×L1 | β 1 face ×L 1 |
| 隐含层2 | β 2 leye ×L2 | β 2 r eye ×L2 | β 2 nose ×L2 | β 2 mouth ×L2 | β 2 chin ×L2 | β 2 face ×L2 |
| 隐含层3 | β 3 leye ×L3 | β 3 r eye ×L 3 | β 3 nose ×L3 | β 3 mouth ×L3 | β 3 chin ×L3 | β 3 face ×L3 |
其中,β为各层神经元的缩放系数,用来决定特征的降维尺度,同时也决定了特征损耗的多少。Li为第i层的神经元个数。
输出层神经元个数为将要识别的类别数。
将提取得到的5个区域采样块及整个人脸分别输入到对应的DBN网络,经过自下而上逐层提取得到更抽象特征,输出层利用Softmax分类器求取各区域特征属于各类别的隶属度。求得的隶属度向量为Pi (P1,i P2,i … Pn,i)T。将各区域求出的隶属度向量进行组合便得到隶属度矩阵P。
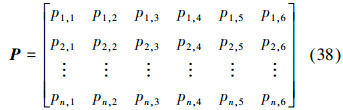
3)隶属度加权融合方法
利用在上一步骤中构建的DBN网络,求出各区域的正确识别率,识别率越高说明进行人脸识别时此区域起到的作用越大,识别率越低说明此区域起到的作用越小。将此识别率作为各区域权值系数确定依据。具体计算公式为

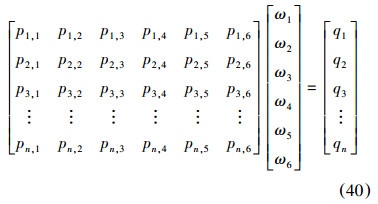
从而求得此待识别人脸图像隶属于各类别的综合评分向量 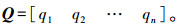 其中评分最高的类别,即为最终识别结果。
其中评分最高的类别,即为最终识别结果。
特征加权融合的人脸识别方法具体算法实现过程如下:
算法1 训练算法。
1)利用ASM模型标注LFW人脸库中全部13233幅图像,人脸面部特征点向量xi=(xi,0,yi,0,xi,1,yi,1,…xi,(n-1),yi,(n-1))。
2)根据面部特征点向量xi,确定5个采样区域位置,并计算5采样框的长和宽wleye、hleye、wreye、hreye、wnose、hnose、wmouth、hmoth、wchin、hchin。
3)在灰度化后原图像I中根据上步求出的采样框大小,进行采样得到5个子区域Ileye,Ireye,Inose,Imouth,Ichin}∈I,以眼睛区域为例:
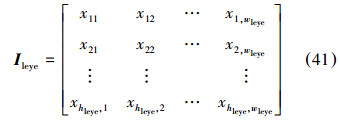
4)将5个子区域及整幅人脸图像利用双线性内插法归一化到规定大小,并拉直成列向量:
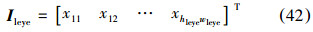
5)对5个子区域及整幅人脸图像进行灰度化、灰度拉伸等预处理操作,形成初调训练样本集,从将要用于测试的类别中选取一部分作为精调训练样本集。
6)利用得到的6个初调训练样本集分别对6个DBN网络应用对比散度方法[17]进行预训练调整各层权值矩阵Wi及偏置矩阵Bi。式中:i表示第i层。
7)应用反向传播方法,在精调训练样本集上对DBN网络各层权值矩阵Wi及偏置矩阵Bi精调。
8)训练完成后,将各层权值矩阵Wi及偏置矩阵Bi保存,供识别时使用。
算法2 分类算法
1)对于一张给定的待识别人脸图像,利用ASM模型提取出人脸面部特征点向量:
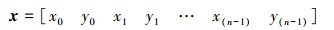
2) 根据面部特征点向量x,确定5个采样区域位置,并计算5采样框的长和宽wleye、hleye、wreye、hreye、wnose、hnose、wmouth、hmoth、wchin、hchin。
3)在原图像I中根据上步求出的采样框大小,进行采样得到5个子区域Ileye,Ireye,Inose,Imouth,Ichin}∈I。
4)将5个子区域及整幅人脸图像利用双线性内插法归一化到规定大小。而后进行灰度化、灰度拉伸等预处理操作。
5)将4)中得到的子区域拉直成列向量,输入到由训练完成的权值矩阵Wi及偏置矩阵Bi构造的DBN网络中,求出隶属度矩阵P。
6)将隶属度矩阵P与权值向量ω(ω1,ω2,ω3,ω4,ω5,ω6)相乘求出此待识别人脸图像隶属于各个类别的综合评分向量Q=[q1 q2 … qn]。
7)找出评分向量Q中获得评分最高的类,作为分类结果。
2 实验结果及分析本文算法分别在LFW(Labeled Faces in the Wild Database)人脸库和ORL(Olivetti research laboratory)人脸库上进行仿真实验,证明了本文算法的有效性。在LFW人脸库实验目的是为了验证本文算法在非限制条件下识别的有效性,同时,由于LFW人脸库中有13233幅人脸图像为DBN预训练提供了充足的训练样本,保证DBN参数能够趋近全局最优[18]。为了进一步评估本文算法通用性,在ORL人脸库上同样进行了比较和测试。进行本文实验硬件环境为:3.50GHz的Intel(R) Core(TM) i5-4690 CPU,8.00GB内存。
2.1 LFW人脸库上的实验LFW人脸库包含5749人的13 233幅人脸图像。其中,1 680人包含2幅及以上人脸图像,4 069人只有一幅人脸图像。图像分辨率为250×250,以JPEG格式存储,绝大多数为彩色图像,少数为灰度图像。LFW主要用于在非限制条件下人脸识别研究,以成为学术界和工业界识别性能评价基准。LFW人脸库能充分表现自然条件下人脸图像的变化,如光照、姿态、表情、背景、性别等。
本文选取人脸库中包含图像数目大于或等于25幅的人作为实验对象,包括29人共2458幅图像。每人随机选取5幅人脸图像作为训练样本,其余图像作为测试样本。将这些图像首先根据人脸面部五官的位置进行区域的划分,然后归一化到固定大小(下巴区域88×33、嘴部区域51×34、左眼和右眼区域44×31、鼻子区域32×46),由此生成训练、测试样本。
1) 隐含层单元设置压缩比不同时对比实验
DBN的分类能力主要取决于自下向上、多层提取得到特征的有效性。为了能够获得更多细节特征,5个区域长和宽分别向外扩大了Lleye、Lreye、Lnose、Lmouth、Lchin,它们的取值为各区域长的0.2倍。在构建DBN时,确定各隐含层神经元个数至关重要。因为LFW人脸库中图像都是在没有限制的自然条件下采集的,所以人脸图像特征较为复杂,并且含有较多噪声,为了能够有效提取人脸图像抽象特征,首先应该讨论网络构建问题中,不同隐含层神经元个数对网络识别性能的影响。实验结果如表 2所示。
| 隐含层缩放系数 | DBN识别率/% | DLWF识别率/% | DLWF+识别率/% |
| 0.70 | 55.75 | 56.25 | 58.45 |
| 0.75 | 64.50 | 66.75 | 69.35 |
| 0.80 | 68.25 | 70.25 | 73.85 |
| 0.85 | 71.10 | 74.50 | 79.25 |
| 0.90 | 82.50 | 85.25 | 88.55 |
由表 2可知,随着隐含层神经元缩放系数增加,深度神经网络能够更好地提取得到适合于分类的人脸图像抽象特征,但计算量也随之增大。同时,隐含层神经元数目相同时,本文提出算法的识别率均高于只输入整张人脸图像像素级特征的传统深度神经网络算法。
2) 训练样本数不同时对比实验
实验2的目的是为了测试本文算法在不同数量训练样本的情况下,与传统人脸识别算法在识别率方面所表现的优劣程度。由于在实际应用环境中很难采集得到大量有标签的训练样本,所以在具有较低的训练样本个数条件下,能取得较好的识别效果就变得尤为重要。表 3为深度神经网络隐含层结点数目的缩放系数为0.9时,在不同训练样本数目的条件下,与传统人脸识别方法进行比较的结果。
| 方法 | 微调阶段训练样本数/% | ||
| 5 | 10 | 15 | |
| PCA | 23 | 27 | 29 |
| SWM | 35.5 | 44 | 55 |
| DBN | 82.5 | 83.5 | 86 |
| FIP+LDA | 83 | 85.5 | 86 |
| DLWF | 85.25 | 87.5 | 88 |
| DLWF + | 86.5 | 88.25 | 89.5 |
由表 3可知,本文提出算法经过非监督的预训练,为DBN参数提供了较好的初始化值,再经过少量有标签的训练样本有监督的微调,便能达到较好的识别效果。随着训练样本数不断增加开始时识别准确率明显上升,而后趋于不变,表明本文算法在非限制条件下进行识别具有良好的鲁棒性。同时,表 3也表明了本文算法比直接输入整张人脸图像像素级特征的DBN识别准确率更高。传统的人脸识别算法如PCA、SVM等在训练样本个数较少时,所提取的底维特征分类能力并不强。随着训练样本个数增加,提取的特征分类能力有所增强,但在非限制条件下算法的识别精度并不高。
3) 类别数不同时对比实验
实验3目的是为了验证本文算法在非限制条件下的普适性和有效性。从LFW中选择拥有人脸图像数目大于或等于25幅图像的39个人作为实验的候选样本,从其中随机挑选出10、20、30人作为实验对象,每人随机挑选出5幅人脸图像作为训练样本,其余图像作为测试样本。每次随机选择不同人脸图像进行实验,求取平均值作为最终结果。本次实验采用的DBN网络隐含层缩放系数与实验2相同,实验结果如表 4所示。
| 方法 | 类别数/% | ||
| 10 | 20 | 30 | |
| PCA | 27.32 | 25.74 | 24.63 |
| SVM | 41.65 | 38.23 | 36.46 |
| DBN | 83.71 | 84.05 | 85.21 |
| FIP+LDA | 84.61 | 86.72 | 87.51 |
| DLWF | 85.93 | 87.16 | 88.76 |
| DLWF + | 86.72 | 87.84 | 91.63 |
经过在LFW人脸库上实验可知,本文提出的人脸识别算法在非限制条件下的鲁棒性和准确率均高于传统人脸识别算法。通过将人脸面部进行区域划分,分别提取局部抽象特征的方法,比传统仅输入整张人脸像素级特征方法更容易学习得到适合于分类的局部特征。并通过上述实验证明了本文算法在非限制条件下的有效性。
2.2 ORL人脸库上的实验ORL人脸库又称AT&T人脸库,是剑桥大学历时2年拍摄完成的,包含40个人,每个人有10幅不同姿态、表情、光照的图像,共400幅,其中人脸的姿态和光照变化较小,图像分辨率为112×92,图像背景为黑色,以PGM格式存储。实验过程中,神经网络首先利用LFW人脸库中所有人脸图像进行预训练,然后在ORL人脸库中每人随机选取5幅图像作为微调阶段训练样本集,其余的人脸图像作为测试样本集。
1) 隐含层单元数不同时对比实验
本实验目的是为了验证本文提出算法的通用性,以及在ORL人脸库上,不同隐含层缩放系数所表现出的识别性能的差异。表 5为DBN网络隐含层缩放系数不同时的识别结果。
| 隐含层缩放系数 | DBN识别率/% | DLWF识别率/% | DLWF+识别率/% |
| 0.70 | 44 | 57 | 61 |
| 0.75 | 52 | 64 | 67 |
| 0.80 | 71 | 77 | 82 |
| 0.85 | 82 | 86 | 89 |
| 0.90 | 94 | 97 | 97 |
从表 5可知,当隐含层缩放系数逐渐增加时,网络逐层提取得到的人脸图像抽象特征的分类识别能力逐渐增强。当网络隐含层缩放系数为0.9时,获得了较高识别率97%。
2) 与其他人脸识别方法对比实验
为了验证本文提出算法相对于传统人脸识别算法所具有的优越性,分别同PCA、SVM和传统DBN算法做了对比实验,表 6为本文提出算法在ORL人脸库上与其他算法进行对比的实验结果。实验结果表明本文算法具有较好的通用性,与传统人脸识别方法进行比较,在识别率方面具有较为明显的优势。
| 方法 | 识别率/% |
| PCA | 84.0 |
| SVM | 88.5 |
| DBN | 94.0 |
| FIP+LDA | 96.0 |
| DLWF | 97.0 |
| DLWF+ | 97.0 |
本文提出了一种特征加权融合人脸识别方法,首先通过提取面部特征点将人脸图像划分成多个局部区域采样区域,然后将采样区域通过归一化处理后分别输入到对应DBN网络中,求取相似度矩阵,最后进行加权求和得出最终判别结果并计算识别准确率。经过在LFW人脸库上实验证明了本文算法在非限制条件下进行人脸识别的有效性,并且能够自下而上提取得到适合于分类的抽象人脸特征。识别率达到了91.63%。同时在ORL人脸库上进行的实验充分证明了本文算法的通用性和有效性,识别率达到了较高的97%,表现出了比传统人脸识别更高的优越性。
| [1] | TURK M, PENTLAND A. Eigenfaces for recognition[J]. Journal of Cognitive Neuroscience, 1991, 3(1):71-86. |
| [2] | SUN Yi, WANG Xiaogang, TANG Xiaoou. Deep learning face representation from predicting 10, 000 classes[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA, 2014:1891-1898. |
| [3] | HU Junlin, LU Jiwen, TAN Y P. Discriminative deep metric learning for face verification in the wild[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA, 2014:1875-1882. |
| [4] | HUANG G B, LEE H, LEARNED-MILLER E. Learning hierarchical representations for face verification with convolutional deep belief networks[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA, 2012:2518-2525. |
| [5] | ZHU Zhenyao, LUO Ping, WANG Xiaogang, et al. Deep learning identity-preserving face space[C]//Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, NSW, Australia, 2013:113-120. |
| [6] | SUN Yi, WANG Xiaogang, TANG Xiaoou. Hybrid deep learning for face verification[C]//Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, NSW, Australia, 2013:1489-1496. |
| [7] | TAIGMAN Y, YANG Ming, RANZATO M A, et al. Deepface:Closing the gap to human-level performance in face verification[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA, 2014:1701-1708. |
| [8] | SUN Yi, CHEN Yuheng, WANG Xiaogang, et al. Deep learning face representation by joint identification-verification[J]. Advances in Neural Information Processing Systems. 2014. |
| [9] | HINTON G E, OSINDERO S, TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7):1527-1554. |
| [10] | HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786):504-507. |
| [11] | AREL I, ROSE D C, KARNOWSKI T P. Deep machine learning a new frontier in artificial intelligence research[J]. IEEE Computational Intelligence Magazine, 2010, 5(4):13-18. |
| [12] | COOTES T F, TAYLOR C J, COOPER D H, et al. Active shape models-their training and application[J]. Computer Vision and Image Understanding, 1995, 61(1):38-59. |
| [13] | MILBORROW S, NICOLLS F. Active shape models with SIFT descriptors and MARS[J]. VISAPP, 2014, 1(2):5. |
| [14] | MILBORROW S, BISHOP T E, NICOLLS F. Multiview active shape models with SIFT descriptors for the 300-W face landmark challenge[C]//Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops. Sydney, NSW, Australia, 2013:378-385. |
| [15] | Bengio Y, Delalleau O. On the expressive power of deep architectures[C]//Proceedings of the 22nd International Conference. Espoo, Finland, 2011:18-36. |
| [16] | HINTON G E. Training products of experts by minimizing contrastive divergence[J]. Neural Computation, 2002, 14(8):1771-1800. |
| [17] | BENGIO Y. Learning deep architectures for AI[J]. Foundations and Trends in Machine Learning, 2009, 2(1):1-127. |