


 , ,
, ,
, ,
, ,
在各种不同的模糊推理系统之中,Takagi-Sugeno-Kang(TSK)模糊系统提供了一个合理的框架,将一个非线性系统分解成若干局部线性模型。因为传统的数学模型无法描述复杂非线性系统的行为,所以T-S模糊系统的潜在应用范围很广。近年来,在进行复杂非线性系统的控制器设计过程中,将TSK模糊控制方法和各种控制策略(随机控制、滑模变结构控制等)相结合,成为目前控制线性系统控制领域的一个研究热点。但是,基于数据驱动的TSK模糊系统建模并不简单,并且可能会产生一个非线性规划问题。在模糊系统模型中,模糊规则包括前件隶属度函数以及相应的后件参数,寻找到最优的模糊规则是模糊系统建模过程中较为重要的工作。
一些数值优化算法,例如通过梯度下降优化技术[2, 3]的模糊神经网络技术、均衡模型复杂度和精确度的遗传算法[4]、Levenberg-Marquardt算法[5]等,已经被广泛应用于模糊系统建模领域。基于数据驱动的TSK模糊系统建模过程中有2个步骤非常关键:一是确定模糊规则前件,在这一步中将输入空间划分成一定数量的模糊域;二是估计模糊规则后件参数向量,在这一歩中在每一个用于建立模糊系统的模糊域中对系统的行为进行描述。我们常常利用聚类技术划分输入空间并且确定模糊规则前件的隶属度函数,例如K均值算法[6]、模糊c均值算法及其扩展[7]、减法聚类算法[8]、Gath-Geva聚类算法[9]、Gustafson-Kessel聚类算法[10]、向量量化(VQ)算法[11]等。
在模糊规则前件确定之后,对后件参数的估计可以看作是在输入输出数据的积空间的一个线性回归问题。传统的回归算法将所有的后件参数视为回归系数并且将它们单独处理。但一方面,这些方法忽视了存在于TSK模糊模型中的分块结构信息;另一方面,冗余的模糊规则不可避免地导致模糊模型的复杂度变高以及过拟合的问题。
为了解决当前TSK模糊系统建模问题中的模糊规则复杂及规则冗余的问题。Luo M等提出了H-sparseFIS算法[12],这是一种层次结构稀疏表示方法,能有效地降低模糊规则的冗余度。本文对TSK模糊系统的建模过程做了进一步的优化:在前件学习时采用一种具备特征选择功能的聚类方法FCA算法来获取更为精简有效的特征组合,从而降低模糊规则的复杂度;在估计模糊规则后件参数过程中,利用存在于TSK模糊模型中的分块结构信息,将分块结构稀疏表示引入TSK模糊系统建模的框架中,利用块匹配追踪算法[12]选择出较为重要的模糊规则,同时减少了非零后件参数的数目,进一步减少模糊规则的条数,有效地降低了规则的冗余度。
1 TSK模糊系统概况在这一部分,首先对TSK模糊系统的一些基本概念进行回顾,然后对模糊系统字典和模糊系统子字典的概念进行介绍。这些子字典构成了一个有意义的分块结构TSK模糊系统字典。
TSK模糊系统是由前件和后件形式为“IF-THEN”的模糊规则组成的,模糊规则的后件被定义为一个仿射函数。对于一个n维输入变量xi=(xi1,xi2,…,xin)T∈Rn,第j条规则可以表示成下面这种形式:
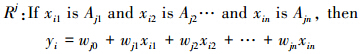
式中j=1,2,…,r。在文中使用钟形隶属度函数对模糊语言命题Ajk(xik)进行描述:
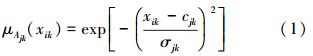
式中:k=1,2,…,n,cjk和σjk分别表示相应的钟形隶属函数的均值和方差。TSK模糊系统的输出函数可以表示为
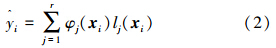
式中φj(xi)表示输入变量xi对于第j条规则的触发强度:
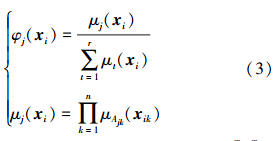
而lj(xi)=wj0+wj1xi1+wj2xi2+…+wjnxin=[1,xiT]Twj是输入变量xi对于第j条规则的输出结果,其中wj=[wj0,wj1,wj2,…,wjn]T表示第j条规则后件的参数。
接下来介绍一下TSK模糊系统建模在数据驱动方面的一些概念。先来看一下输入输出数据集
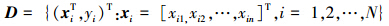
式中xi和yi分别表示第i个n维输入和输出变量。为了简洁,用MDr表示有r条规则的TSK模糊系统,且这个系统是从数据集D进行学习的。将TSK模糊系统MDr的输出表示成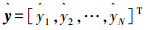 :
:
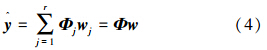
式中:Φ∈RN×r(n+1)是由r个块结构Φj∈RN×(n+1)构成,也就是说,Φ=[Φ1,Φ2,…,Φr]。
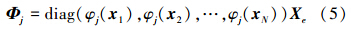
式中:j=1,2,…,r,Xe=[1,XT],其中X=[x1,x2,…,xN]。相应的,w=[w1T,w2T,…,wrT]∈Rr(n+1)。根据定义,Φ∈RN×r(n+1)叫做TSK模糊系统MDr的字典,成分Φj∈RN×(n+1)是对应于第j条规则的子字典。很明显,这个TSK模糊系统字典是一个分块结构。在这个意义上讲,模糊模型输出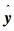 可以用模糊规则子字典的一个线性组合表示。
可以用模糊规则子字典的一个线性组合表示。
在模糊规则前件提取中,使用FCA聚类算法对样本输入空间进行划分并确定模糊规则前件的隶属度函数。在这个过程中,FCA算法能够对噪声特征和不重要的特征进行约减。之后,对模糊系统字典的分块结构信息进行阐述,并将TSK模糊系统建模过程转化为一个分块结构稀疏恢复问题。在模糊规则选取的过程之中,我们使用块正交匹配追踪算法,这样,就能减少模糊系统的规则数目。
2.1 模糊规则前件提取在很多特定的情况下,专家可以根据先验知识提供一些模糊规则。但在大多数情况下,对于划分输入空间和确定模糊规则前件的隶属度函数,通常使用统计学方法或聚类技术。本文使用FCA算法从数据集D提取模糊规则前件。
通过FCA算法[13],每个类均与一条模糊规则相联系。通过类在每个变量上的投影产生模糊规则前件的钟形隶属度函数Ajk,也就是说,在每一维上的类中心和方差被视为钟形隶属度函数Ajk的均值cjk和方差σjk,这里,j=1,2,…,r,k=1,2,…,n。
一旦模糊规则前件确定下来,模糊字典Φ以及所包含的模糊规则子字典Φj(j=1,2,…,r)也可以通过式(5)获得。一般来说,通过对模糊规则回归模型的后件参数估计的方法来对TSK模糊系统进行建立。基于FCA算法的TSK模糊系统的建模流程图如图 1所示。
 |
| 图 1 基于FCA聚类算法的TSK模糊系统模型流程图 Fig. 1 Flowchart of TSK fuzzy system modeling on the basis of FCA clustering |
FCA算法是一种加权模糊聚类算法,该算法在实现对数据进行聚类的同时,可以按样本特征对聚类的贡献进行排序。因此,本文先使用FCA算法实现模糊划分并挑选出对聚类贡献较大的若干特征生成模糊规则前件,从而化简了模糊规则的复杂度。
依据上文,样本集的输入部分可以表示为X=[x1,x2,…,xN],∀xi=[xi1,xi2,…,xin]T∈Rn,C为聚类数目,集合V=[v1,v2,…,vC],∀vi=[vi1,vi2,…,vin]T∈Rn表示聚类中心,μij表示样本xi隶属于第j类的隶属度,W=[w1,w2,…,wn]是样本特征的权重,此处wk>0且α为其参数,β=[β1,β2,…,βN]是样本的权重,此处βi>0且γ为其参数,建立目标函数如下:
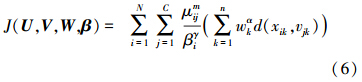
式中:d(xik,vjk)=(xik-vjk)2,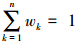 ,
,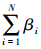 =1,
=1,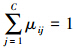 ,m>1。
,m>1。
在FCA算法中,U、V、W和β在γ和α满足一定条件的时候能够使得J(U,V,W,β)达到局部最优,下面分别给出U、V、W和β的迭代更新表达式:
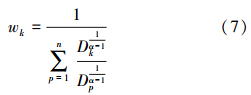
式中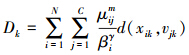 。
。
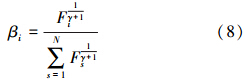
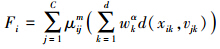 。
。
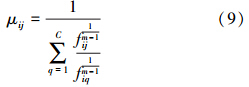
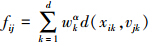 。
。
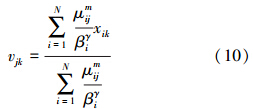
根据上述更新规则,在有限次迭代后,J(U,V,W,β)将会收敛到局部极小值或鞍点。具体FCA算法(算法1)如下。
1)输入:输入输出数据集的输入部分X=[x1,x2,…,xN],聚类数r,初始聚类中心V0以及误差控制量ε>0(其中V0可不设定)。
2)初始化:根据数据集信息随机初始化U0,随机产生满足条件的W0、β0,若未输入初始聚类中心,则通过公式(10)计算初始聚类中心。
3)步骤:
FOR n=1,2,…
使用式(7)迭代产生Wn+1
使用式(8)迭代产生βn+1
使用式(9)迭代产生Un+1
使用式(10)迭代产生Vn+1
IF
|J(Un+1,Vn+1,Wn+1,βn+1)-J(Un,Vn,Wn,βn)|<ε
break
ELSE n=n+1
4)输出:Un+1、Vn+1、Wn+1和βn+1。
2.2 模糊规则选取的分块结构稀疏表示通常,使用LS算法对模糊规则后件参数向量wi估计的方式有2种,一种是通过求解LS问题的w=[w1,w2,…,wr]全局学习,另外一种是通过求解r个独立的加权LS问题wi(i=1,2,…,r)的局部学习。然而,全局学习在估计过程中将后件参数独立对待,忽略了存在于模糊系统字典Φ中的分块结构。局部学习是对每一条模糊规则分别估计后件参数,其实质是一种结构化学习;然而所有的结果参数wi(i=1,2,…,r)都未经选择就进行估计了,这就导致了所有的模糊规则都参与了模糊系统的建模。事实上,一些模糊规则是不必要的,删去它们并没有很显著的影响一个模型的效果。更为严重的是,过多的模糊规则难免会导致过拟合问题,并使得泛化效果变差。
为了克服上述问题,利用分块结构的优势,并利用一个LS算法对分块结构稀疏表示的TSK模糊系统进行建模,作为对传统稀疏表示的继承,分块结构稀疏表示首次在组LASSO[14]中进行介绍和研究。它介绍了一种回归模型,在这种回归模型中,很多贡献小的分块的回归系数能够在保证模型精度较高的条件下削减接近于零。
 |
| 图 2 分块结构稀疏表示 Fig. 2 Block-structured sparse representation |
在TSK模糊系统的建模过程中,模糊规则的数目越多,模型的精度一般更高;但是,太多的模糊规则也会不可避免地将模糊系统变得复杂,甚至会导致过拟合问题。所以,模糊规则的选取变成了一个很关键的问题,要选取一个合理的参数化问题既要能控制规则数目也能够控制训练误差。利用TSK模糊模型的块结构的优势,找到了一种TSK模糊规则选择的块结构回归方法。在系统建模过程中,这种方法将许多贡献小的块的后件参数wi(i=1,2,…,r)缩减至零。它们可以表示成如下优化问题
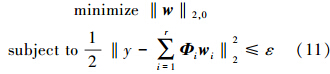
式中:‖w‖2,0=‖(‖w1‖2,‖w2‖2,…,‖wr‖2)‖0实际上反映的是模糊规则的数目,并且ε表示模型精度的上限。优化问题(11)的目的是使得结果参数向量w尽可能的块稀疏并均衡模型的精度和复杂度。通过图 2来说明这种块结构稀疏回归。
2.3 块正交匹配追踪算法应用于TSK模糊系统建模在过去的研究中,优化问题(11)已被证明是NP难问题;然而,通常有2种方法求近似解:1)松弛方法,例如‖·‖2,1范数凸优化近似求解的一般方法;2)分块(分组)贪婪选择算法,例如块正交匹配追踪算法(block OMP算法)、块匹配追踪算法(OMP算法)等。在本文中,使用块正交匹配追踪算法去解决优化问题(11),因为该算法在计算代价方面有优势。
作为OMP算法的一个继承,在稀疏回归时,分块OMP算法进行的是块变量的选择而不是对单个变量的选择。它以一种非常直观的方式运作。在每一步迭代中,根据减少的残差选择最优块。一旦块被选定,在已经选定的块上执行LS最小化获得对相应系数的估计。每次迭代结束,算法检查停止条件是否已经达到。这个停止条件通常是残差的最小范围或者是迭代的最大次数。在TSK模糊系统建模的框架中,因为块变量wi是与第i条模糊规则的后件参数向量相联系的,故对块变量的选择,实际上就是对模糊规则的选择。
使用分块OMP算法(算法2)对模糊规则进行选取的过程如下。
1)输入:依据数据集D生成的TSK模糊系统字典Φ=[Φ1,Φ2,…,Φr]。
2)初始化:初始化标签集I(0)=Ø,后件参数向量w(0)=0,残差r(0)=y。
3)步骤:
FOR K=1,2,…
令j(k)=arg maxj(r(k-1))TΦj(ΦjTΦj)-1ΦjTr(k-1)
IF终止条件为真,break
设定I(k)=I(k)∪j(k)
通过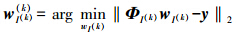 计算当前的后件参数向量w(k)并且设置w(I(k))c(k)=0
计算当前的后件参数向量w(k)并且设置w(I(k))c(k)=0
更新当前残差r(k)=y-Φw(k)
4)输出:I(k)中选定的模糊规则子字典,以及模糊规则后件参数向量wk。
在第k次迭代,I(k)⊂{1,2,…,r}表示已选模糊子字典的标签集;w(k)∈Rr(n+1)表示模糊规则后件参数向量;r(k)=y-Φw(k)表示相应的残差。初始化后件参数向量为w(0)=0,残差为r(0)=y。ΦI(k)表示对Φ进行限制的变量集是{Φi:i∈I(k)}。
在第k次迭代中选取的最好的规则要使残差减少得越多越好,事实上,在第k次迭代中第j条模糊规则子字典产生的误差为
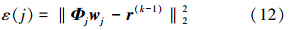
为了将其最小化,则wj*=(ΦjTΦj)-1ΦjTr(k-1),此处,j=1,2,…,r,将w*j带入ε(j)得
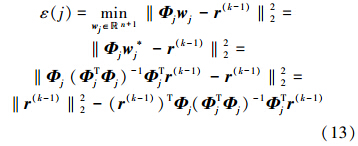
为了保证误差尽可能多地减少,在第k次迭代过程中,选择出的模糊规则子字典Φj(k)要满足
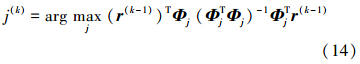
在I(k)中已经选定的模糊规则子字典将不会再被选取,假设在k次迭代之后选取的模糊规则为Rj(k),那么通过式(15)估计后件参数向量w(k):
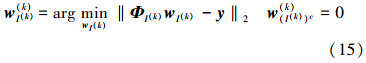
在算法2中(I(k))c表示I(k)的补集。wI(k)(k)的最优值是通过将下面的二次导数置零获得:
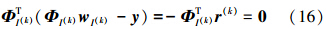
所以,所有在标签集I(k)中选择过的模糊规则子字典将不会再被式(14)选取。
2.4 已选模糊规则后件的稀疏正则化本文提出了一个分块结构的稀疏回归模型来挑选一个TSK模糊模型最重要的模糊规则。在这一部分,稀疏表示进一步被应用于减少TSK模糊规则最小非零后件参数。通过块OMP算法选择出最重要的k条规则之后,可以用Φk表示模糊系统字典。最普通的用于寻找后件参数的方法是
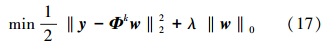
这里的参数λ是用于平衡模型的误差以及后件中非零参数的数目。不过已经证明了带有‖·‖0范数的稀疏正则项的补偿函数是NP难的。一般情况下,会用平滑补偿函数的松弛算法对上述问题进行近似求解。在多种估计方法中,一种较为常用的方法就是将‖·‖0范数改成‖·‖1范数。这样,优化问题(17)被改写成
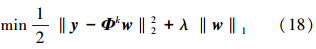
上述优化问题在信号和图像处理领域有广泛和深入的研究,跟经典的l1范数支持向量回归一样。有几种较为成熟的算法去解决上述问题,比如迭代重加权最小二乘算法、最小角回归算法以及迭代收缩算法,本文采用L1范式最小二乘方法[15]对上述问题进行求解。
2.5 FCA-sparseTSK应用于TSK模糊系统建模在这一部分中,将算法1与块算法2相结合,提出了一种有效的TSK模糊系统建模的方法,称之为FCA-sparseTSK(算法3)。该模型在划分输入空间过程中采用了FCA聚类算法,对权重较小的特征进行去除,从而化简了模糊规则;在选择模糊规则过程中采用了Block OMP算法,挑选出较为重要的若干规则,去除了冗余规则,并利用稀疏表示的方法对后件参数进行估计。所以,通过FCA-sparseTSK建立的模糊系统的模糊规则数及非零后件参数的数目均得到了约减。
FCA-稀疏TSK(FCA-sparseTSK)算法如下:
1)输入:输入输出数据集D。
2)特征优化:通过FCA聚类算法进行模糊划分并挑选出权重较大的特征生成TSK模糊系统字典。
3)块结构稀疏:运行Block OMP算法选择出k条重要的模糊规则子字典并得到相应的类中心。
4)优化学习:将上一步得到的类中心最为初始类中心,再次运行FCA聚类算法,并产生一个新的模糊系统字典。
5)稀疏表示:根据稀疏表示对相应的模糊规则后件参数进行估计。
6)输出:优化的TSK模糊系统。
3 实验用数值实验证明所提出FCA-sparseTSK模型的有效性并与相关算法比较。在本实验中,将初始的模糊规则条数设置为30。设输入输出数据集的形式如下所示:
根据相关实验的具体情况选择不同的评价指标,例如均方误差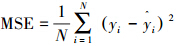 和平均绝对误差
和平均绝对误差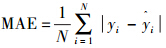 。这里
。这里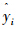 表示TSK模糊系统对应变量xi(i=1,2,…,N)的输出。
表示TSK模糊系统对应变量xi(i=1,2,…,N)的输出。
本文所有实验均对数据进行标准化处理,并采用五折交叉验证的方法对FCA-sparseTSK算法中所涉及到的参数进行寻优。算法中,m和α的寻优范围设置为(1,3],γ的寻优范围为(0,2],寻优步长均为0.1。根据五折交叉验证,数据集被分成5个子集,对于每种算法,均进行5次建模。每次建模,取5个子集中的1个作为测试集,剩余的4个作为训练集。本文的算法与genfis2、genfis3以及H-sparseFIS算法[12]相比较,验证FCA-sparseTSK算法的有效性。
3.1 合成数据集为了体现本文方法的优势,利用下面生成函数产生数据集。对于任意输入xi=[xi1,xi2,xi3]T,产生输出yi=xi1sin(xi1)+xi2cos(xi2)+xi3。根据此方法,在取值范围xik∈[-10,10] (k=1,2,3)内等间距取样,生成2 000个样本。为了测试本文提出算法对噪音和特征识别的能力,使用normrnd(0,1,2 000,2)生成2 000×2的噪声矩阵,将该矩阵与原矩阵合成为新的数据集,该数据集共计2 000个样本,5个特征(后2个特征为噪声特征)。
经过FCA聚类算法,得到各样本特征的权重如图 3所示,从图中显示的结果中发现,数据集中人工引入的两维噪声特征的权重都非常低,故可以将这2个特征去除,对模糊规则进行了优化,减少噪声特征对系统的干扰,提高系统的精度。另外,测试数据集的真实输出与模型输出的比较如图 4所示。将FCA-sparseTSK和其他3种相关算法进行比较,结果如表 1所示,表中列举出五折交叉验证中测试集的MAE并计算出平均MAE及其标准差。
 |
| 图 3 合成数据集样本特征权重 Fig. 3 Feature weights of synthetic datasets |
 |
| 图 4 五折交叉验证测试数据集实际输出和模型输出比较 Fig. 4 Comparison of actual output and model’s output over testing data |
从表 1中能够发现,通过对样本特征的优化,去除掉两条噪声特征,不仅使得模糊规则得到化简,而且相对于其他算法,模型的精度更高;通过本文模型与未约减规则数的模型相比较,在保证模型精度基本一致的前提下,本文算法平均约减规则13.2条,故对冗余规则的去除是有效的。
| 算法 | 特征数 | 性能指标 | 1 | 2 | 3 | 4 | 5 | 均值 |
| genfis2 | 5 | MAE 规则数 | 0.048 4 21 | 0.045 6 18 | 0.067 1 20 | 0.061 8 21 | 0.044 8 19 | 0.053 5±0.010 2 19.8 |
| genfis3 | 5 | MAE 规则数 | 0.277 3 20 | 0.266 4 20 | 0.285 2 20 | 0.302 3 20 | 0.278 9 20 | 0.282 0±0.013 2 20 |
| H-sparseFIS | 5 | MAE 规则数 | 0.044 7 25 | 0.048 5 25 | 0.075 8 16 | 0.088 4 15 | 0.082 4 19 | 0.068 0±0.020 0 20 |
| FCA-sparseTSK | 3 | MAE 规则数 MAE 规则数 | 0.011 2 30 0.014 3 13 | 0.010 7 30 0.012 7 18 | 0.010 8 30 0.015 9 16 | 0.011 7 30 0.018 6 16 | 0.011 6 30 0.016 2 17 | 0.011 2±0.000 5 30 0.015 5±0.002 2 16.8 |
该数据集从UCI machine learning repository获取,记录了不同尺寸的NACA 0012机翼在不同风动速度和攻角下的性能,共计1 503个样本,5条特征。输入分别为频率、攻角、弦长、自由流速度以及吸力面位移厚度,输出为声压等级。各算法在五折交叉验证中测试集的MSE及规则数目如表 2所示。
| 算法 | 特征数 | 性能指标 | 1 | 2 | 3 | 4 | 5 | 均值 |
| genfis2 | 5 | MSE 规则数 | 0.050 3 11 | 0.054 7 10 | 0.052 3 11 | 0.056 5 10 | 0.045 8 11 | 0.051 9±0.004 2 10.6 |
| genfis3 | 5 | MSE 规则数 | 0.057 9 15 | 0.067 5 15 | 0.064 0 15 | 0.074 6 15 | 0.064 3 15 | 0.065 7±0.006 1 15 |
| H-sparseFIS | 5 | MSE 规则数 | 0.042 3 12 | 0.048 8 13 | 0.045 5 11 | 0.059 3 12 | 0.048 2 13 | 0.048 8±0.006 4 12.2 |
| FCA-sparseTSK | 3 | MSE 规则数 MSE 规则数 | 0.045 3 30 0.040 4 12 | 0.047 4 30 0.049 7 11 | 0.039 4 30 0.035 4 10 | 0.051 6 30 0.053 2 10 | 0.042 4 30 0.039 5 11 | 0.045 2±0.004 7 30 0.043 6±0.007 5 10.8 |
表 2结果显示,对于airfoil self-noise数据集,使用FCA-sparseTSK构建出的模型性能最好。本文所提出的模型相比于genfis2、genfis3和H-sparseFIS性能有所提升,并且FCA-sparseTSK去除掉2条不重要的特征,化简了模糊规则的复杂程度,使模糊系统变得简洁;通过与未约减规则数的实验相比较,本文算法平均约规则19.2条,且误差与未约减规则时基本一致,故对冗余规则的去除是有效的。
3.2.2 Machine CPU performance数据集该数据集从knowledge extraction based on evolutionary learning(KEEL)获取,记录了相对CPU性能数据,共计209个样本,6条特征。数据输入分别为机器周期时间(MYCT)、最小内存(MMIN)、最大内存(MMAX)、快速存储器(CACH)、最小通道(CHMIN)、最大通道(CHMAX),输出为CPU的相对性能(PRP)。各算法在五折交叉验证中测试集的MAE及规则数目如表 3所示。
| 算法 | 特征数 | 性能指标 | 1 | 2 | 3 | 4 | 5 | 均值 |
| genfis2 | 6 | MAE 规则数 | 0.056 9 6 | 0.046 9 5 | 0.070 7 6 | 0.056 9 5 | 0.074 8 4 | 0.061 2±0.011 4 5.2 |
| genfis3 | 6 | MAE 规则数 | 0.074 6 5 | 0.058 3 5 | 0.076 8 5 | 0.069 1 5 | 0.091 0 5 | 0.074 0±0.011 9 5 |
| H-sparseFIS | 6 | MAE 规则数 | 0.056 9 6 | 0.035 7 4 | 0.048 9 5 | 0.052 7 4 | 0.060 0 7 | 0.050 8±0.009 4 5.2 |
| FCA-sparseTSK | 5 | MAE 规则数 MAE 规则数 | 0.053 2 30 0.043 9 4 | 0.036 7 30 0.040 0 4 | 0.062 8 30 0.047 8 5 | 0.048 6 30 0.040 7 4 | 0.055 9 30 0.058 6 6 | 0.051 4±0.009 7 30 0.046 2±0.007 6 4.6 |
表 3结果显示,对于machine CPU performance数据集,使用FCA-sparseTSK构建出的模型性能最好。本文所提出的模型相比于genfis2、genfis3和H-sparseFIS性能有所提升,并且FCA-sparseTSK去除掉1条不重要的特征,化简了模糊规则的复杂程度;通过与未约减规则数的实验相比较,本文算法平均约规则25.4条,且精度与未约减规则的模型相比略有提升,故对冗余规则的去除是有效的。 3.2.3 Stock prices数据集
该数据集从KEEL获取,由10个航空航天公司从1988年1月到1991年10月的日常股票价格,共计950个样本,9条特征。用前9个公司的股票价格作为输入,对第10个公司的股票价格进行估计。各算法在五折交叉验证中测试集的MAE集规则数目如表 4所示。
| 算法 | 特征数 | 性能指标 | 1 | 2 | 3 | 4 | 5 | 均值 |
| genfis2 | 9 | MAE 规则数 | 0.041 0 21 | 0.039 5 22 | 0.043 9 21 | 0.041 1 21 | 0.043 1 24 | 0.041 7±0.001 8 21.8 |
| genfis3 | 9 | MAE 规则数 | 0.132 3 20 | 0.130 9 20 | 0.129 8 20 | 0.130 0 20 | 0.133 7 20 | 0.131 3±0.001 6 20 |
| H-sparseFIS | 9 | MAE 规则数 | 0.038 6 22 | 0.044 7 17 | 0.049 4 20 | 0.046 9 22 | 0.042 5 22 | 0.044 4±0.004 1 20.6 |
| FCA-sparseTSK | 6 | MAE 规则数 MAE 规则数 | 0.047 4 30 0.047 3 17 | 0.044 4 30 0.047 6 17 | 0.049 6 30 0.047 1 18 | 0.046 7 30 0.047 2 17 | 0.045 5 30 0.047 2 17 | 0.046 7±0.002 0 30 0.047 6±0.000 7 17.6 |
表 4结果显示,对于stock数据集,genfis2构建出的模型性能最好。本文所提出的模型与genfis2和H-sparseFIS相比性能大体一致,但FCA-sparseTSK去除掉3条不重要的特征,大大化简了模糊规则的复杂程度,使模糊系统变得简洁;通过与不约减规则数的实验相比较,本文算法平均约减掉12.4条规则,且误差与未约减规则时基本持平,故对冗余规则的去除是有效的。
4 结束语本文提取出存在于TSK模糊系统中的分块结构信息,将模糊系统建模问题转化为一个结构化的稀疏恢复问题。FCA-sparseTSK算法在构建模糊系统的过程中,对样本特征进行优化,选取重要的模糊规则并对规则的后件参数进行估计。在合成数据集以及真实数据集上的实验证明,FCA-sparseTSK模型能够在保证系统性能的前提下,同时化简模糊规则并消减冗余模糊规则。
| [1] | DING B.Dynamic output feedback predictive control for nonlinear systems represented by a Takagi-Sugeno model[J].IEEE Transactions on Fuzzy Systems,2011,19(5):831-843. |
| [2] | JANG J S R.ANFIS:adaptive-network-based fuzzy inference system[J].IEEE Transactions on Systems,Man and Cybernetics,1993,23(3):665-685. |
| [3] | QIN Hao,YANG S X.Adaptive neuro-fuzzy inference systems based approach to nonlinear noise cancellation for images[J].Fuzzy Sets and Systems,2007,158(10):1036-1063. |
| [4] | WANG Di,ZENG Xiaojun,KEANE J A.An evolving-construction scheme for fuzzy systems[J].IEEE Transactions on Fuzzy Systems,2010,18(4):755-770. |
| [5] | LUGHOFER E.Evolving fuzzy systems-methodologies,advanced concepts and applications[M].Heidelberg:Springer,2011:81-85. |
| [6] | JAIN A K.Data clustering:50 years beyond K-means[J].Pattern recognition letters,2010,31(8):651-666. |
| [7] | TSEKOURAS G E.On the use of the weighted fuzzy c-means in fuzzy modeling[J].Advances in Engineering Software,2005,36(5):287-300. |
| [8] | YAGER R R,FILEV D P.Generation of fuzzy rules by mountain clustering[J].Journal of Intelligent and Fuzzy Systems,1994,2(3):209-219. |
| [9] | GATH I,GEVA A B.Unsupervised optimal fuzzy clustering[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1989,11(7):773-780. |
| [10] | GUSTAFSON D E,KESSEL W C.Fuzzy clustering with a fuzzy covariance matrix[C]//IEEE Conference on Decision and Control including the 17th Symposium on Adaptive Processes.San Diego,USA,1978:761-766. |
| [11] | LUGHOFER E.Extensions of vector quantization for incremental clustering[J].Pattern Recognition,2008,41(3):995-1011. |
| [12] | LUO Minnan,SUN Fuchun,LIU Huaping.Hierarchical structured sparse representation for T-S fuzzy systems identification[J].IEEE Transactions on Fuzzy Systems,2013,21(6):1032-1043. |
| [13] | 皋军,王士同.具有特征排序功能的鲁棒性模糊聚类方法[J].自动化学报,2009,35(2):145-153.GAO Jun,WANG Shitong.Fuzzy clustering algorithm with ranking features and identifying noise simultaneously[J].Acta Automatica Sinica,2009,35(2):145-153. |
| [14] | YUAN Ming,LIN Yi.Model selection and estimation in regression with grouped variables[J].Journal of the Royal Statistical Society:Series B (Statistical Methodology),2006,68(1):49-67. |
| [15] | KIM S J,KOH K,LUSTIG M,et al.A interior-point method for large-scale τ1-regularized least squares[J].IEEE Journal on Selected Topics in Signal Processing,2007,1(4):606-617. |