


 , ,
, ,
2. 沈阳航空航天大学 电信学院, 辽宁 沈阳 110136
, ,
2. College of Electronic Information Engineering, Shenyang Aerospace University, Shenyang 110136, China
内发动机机制是认知的动力和源泉,是机器人最基本的认知发育机制。通过内发动机机制的不断完善,使生物体逐渐形成、发展和完善控制技能[1, 2]。认知科学研究表明,情感智能是内发动机机制不可或缺的组成部分,在生物自主行为决策中起着至关重要的作用[1, 2]。随着科学研究的不断深入,越来越多的研究者开始关注人类的情感智能,尝试采用多种方法将生物情感智能抽象化建模,指导机器人行为决策取得更佳的控制效果。2008年Ahn等[3]提出了基于情感和认知强化学习模型,考虑了来自情感的内在奖励和来自认知的外部奖励,研究表明将来自情感的内在奖励融入到学习和决策中,能提高学习速度和决策能力。2011年,Malfaz等[4]将害怕情感因数与Q学习结合起来,通过增加Q函数的权重,有效降低了危险的行为决策。2011年,Sequeira等[5]提出了基于情感内发动机机制的强化学习模型,将奖赏信号分为内部和外部2部分,细化为好奇心、动机、价值和控制部分,实验证明了智能体可以克服环境的缺点获得更好的决策。2013年,Abdi等[6]利用情感经验获得奖赏信号,利用TD Q学习算法,实现优化多智能体的行为决策。2003年刘明等[7]提出一种基于模糊逻辑的情感模型,将情感对环境和agent自身状态的评估的变化作为再励信号,用于引导agent的行为选择策略的学习。2008年,张惠娣等[8]将基于情感和认知的学习与决策模型引入到基于行为的移动机器人控制体系中,设计了一种自主导航控制系统,提高了基于行为的移动机器人在未知环境中的自主导航能力。2010年,胡云斗等[9]提出一种基于任务的机器人情感决策模型,建立从多种感知输入到多种行为输出的映射,以“福娃”机器人为平台验证了该方法的正确性和实用性。2011年,祝宇虹等[10]对害怕进行了人工情感建模,提出了带情感权重的Q学习加权策略,并将该策略应用于虚拟机器人的行为决策,取得了较高的成功率。目前,针对机器人的基于情感的内发动机仿生自主学习问题,很多学者做了大量的工作,但对未知环境的自主学习方法,仍需不断探索。
近年来,机器人的趋光特性作为认知领域的范例已经得到广泛重视,通过模拟生物的趋光行为,研究机器人内发动机机制的渐近过程,并把这些原理正确运用在机器人制造中,对认知科学的发展和应用起到了重要作用。针对机器人仿生自主学习问题,构建了基于情感因素的内发动机学习模型,包括评价、行为选择和取向环节,通过“感知—行动”的往复学习,使机器人逐渐形成、发展和完善趋光行为技能,采用模糊推理方法构建情感模型,将情感因素作为内发动机机制的内部奖赏信号,通过情感智能的作用,增加机器人趋光学习试探成功次数和减少学习步数。
1 机器人模型采用三轮式圆盘状移动机器人模型,结构如图 1所示,左右2个驱动轮用来控制速度与方向,后面方向轮用来保持机器人平衡。机器人圆盘前端有6个位置可以安装传感器,每个位置安装一个光敏传感器和一个超声波测距传感器,将6个位置的传感器分为左右2组,分别测定左侧和右侧的光强度和障碍物距离,每组3个传感器中测定光强度最大值做为该组传感器测定的光强度值,左侧光强度值为ol,右侧光强度值为or。每组3个传感器中测定与障碍物距离最小值做为该组传感器测定的与障碍物距离值,与左侧障碍物距离值为dl,与右侧障碍物距离值为dr。
 |
| 图 1 机器人结构Fig. 1 Robot structure |
根据神经生理学[11, 12, 13],生物体利用感受器、运动神经系统和效应器,通过自学习和自组织过程,逐渐完善运动技能的学习机制,如图 2所示。感受器是感觉器官,其功能是感知环境(或客体)状态,运动神经系统是调节特定技能的神经细胞群,根据环境(或客体)状态产生动作决策,效应器是机体的运动器官,其功能是根据运动神经系统动作决策对环境(或客体)施加操作。
 |
| 图 2 基于感觉运动系统的内发动机机制Fig. 2 Intrinsic motivation mechanism based on sensorimotor system |
生物学领域的研究表明,在生物体感觉运动系统中存在动机与内在目标和目的相关联的机制[1],即内发动机机制,这种机制是一种以感觉运动系统为基础,受生存、取向性、好奇心以及情感和信念驱使的学习机制[14, 15]。内发动机机制[1, 2]是生物体在不需要环境(或客体)数学模型的情况下,将环境(或客体)状态映射为对环境(或客体)的操作,并获得奖惩信号,成功的操作会获得奖赏信号,失败的操作则获得惩罚信号,生物体将奖惩信息转换成评价指标并生成取向信息,调整对环境的操作,这一过程在“感知-行动”环中周而复始地进行,生物体逐渐形成、发展和完善运动控制技能。其间情感在内发动机机制中起着重要的作用。
2.2 趋光情感模型情感是生物体一种特殊意识形式,是生物的认知过程中行为决策的关键因素,对情感进行科学分析和精确计算,就能够建立情感的数学模型。目前,以心理学、生物学和人工智能等学科为基础,研究人员采用多种方法构建情感模型。文中针对机器人模拟趋光行为问题,采用模糊推理方法构建了人工情感模型[16, 17],模糊逻辑更能体现情感状态推理的复杂性和不确定性的本质特征。人工情感模糊推理模型,如图 3所示。
 |
| 图 3 基于模糊推理的情感模型Fig. 3 The emotion model based on fuzzy reasoning |
图 3中输入是机器人所在位置光强度ob(t)和机器人与障碍物距离dm(t),各划分为5个等级,隶属度函数如图 4所示,机器人所在位置光强度ob(t)采用很高(PL)、高(PB)、中(PM)、低(PS)和很低(PW)5个等级,机器人与障碍物距离dm(t),采用很远(PL)、远(PB)、中(PM)、近(PS)和很近(PW)5个等级。人工情感模糊推理模型输出是机器人在趋光过程中产生的情感因子λ。
 |
| 图 4 ob(t)和dm(t)的隶属度函数Fig. 4 Membership function of ob(t)and dm(t) |
趋光过程中情感状态的设定,根据OCC情感模型[18]中的22种情感状态,根据趋光具体问题,考虑趋光过程中机器人操作结果对机器人情感的影响,选取6类情感E={Pride,Joy,Satisfaction,Disappointment,distress,Shame},Pride为骄傲情感,Joy为高兴情感,Satisfaction为满意情感,Disappointment为失望情感,distress为忧伤情感,Shame为羞愧情感。人工情感模型中模糊规则设计依据OCC模型中情感产生规则确定情感状态,如表 1,OCC模型中情感产生规则依据机器人对趋光操作结果的期望度确定,趋光操作结果包括趋光操作后机器人与光源距离ob(t)和机器人与障碍物距离dm(t),机器人每操作一次,需要重新确定情感状态。
| Emotion | Rule |
| Pride | The action is done by the agent and is approved by standards |
| Joy | The occurrence of a desirable event |
| Satisfaction | The occurrence of a confirmed desirable event |
| Disappointment | The occurrence of a unconfirmed desirable event |
| Distress | The occurrence of a undesirable event |
| Shame | The action is done by the agent and is unapproved by standards |
模糊规则共25条,设计如下:
1)如果光强度是很高,且障碍物距离是很远,则骄傲;
2)如果光强度是很高,且障碍物距离是远,则高兴;
3)如果光强度是很高,且障碍物距离是中,则满意;
4)如果光强度是很高,且障碍物距离是近,则不满意;
5)如果光强度是很高,且障碍物距离是很近,则忧伤;
6)如果光强度是高,且障碍物距离是很远,则高兴;
7)如果光强度是高,且障碍物距离是远,则高兴;
8)如果光强度是高,且障碍物距离是中,则满意;
……
文中采用了重心模糊推理方法得出精确化后的输出情感因子λ,公式为
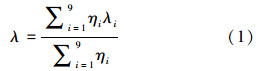
依据感觉运动系统的内发动机机制[2, 19, 20],设计了包含3个模块的机器人模型,如图 5所示,分别是评价模块、行为选择模块、取向模块。评价环节根据输入状态s(t)、奖惩信号r(t)和动作量a(t),对动作量a(t)进行评价输出评价值Ve(t),评价函数为
 |
| 图 5 基于情感智能的机器人趋光仿生模型Fig. 5 The robot phototaxis biomimetic model based on emotion intelligence |
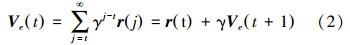
移动机器人基于内发动机自主学习算法步骤为
1)初始化行为选择和评价环节中各初始值,及各神经元连接权值;初始化机器人的各状态变量,并归一化;
2)根据环境状态量s(t),计算奖赏信号ro(t)、re(t);
3)行为选择环节根据状态量s(t)计算动作量a(t);
4)评价环节根据状态量s(t)和动作量a(t)对动作量评价,输出评价值Ve(t);
5)取向环节根据评价值Ve(t),计算取向信息,利用取向信息,调整动作量a (t+1)输出;
6)将动作量a(t+1)对环境实施操作,环境产生下一时刻的状态量s (t+1) ;
7)返回2),直到产生的各状态量满足智能体的期望性能指标,则执行8);
8)行为决策模块对动作量加权并对客体实施操作,客体产生下一时刻的状态量;
9)结束。
3 仿真实验 3.1 趋光实验为验证算法的有效性,采用MATLAB仿真软件,仿真环境中圆形表示光源位置,方形表示障碍物,环境中分布着有限个静态障碍物,以机器人的趋光学习为目标进行研究,光源位置和移动机器人起点位置可以任意设定,移动机器人运动起点位置注明“S”,终点位置注明“G”,设定光源所在位置光强是1坎德拉(Candela),与光源越远的位置光强越弱,按e指数规律减弱。机器人对环境是完全未知的,可以自定位,采用在线学习方式。机器人匀速移动,设定线速度v为0.5 m/s,采样时间是T=1 s。移动机器人进行试探学习,每次学习步数不超过1 000步,每次学习移动机器人从起始位置出发,到达光源附近位置停止,学习结束,准备进行下一次学习,如果学习步数超过1 000步仍未到达光源附件位置,则终止这次学习,进行下一次学习。趋光学习评价环节趋光输入域是x(t)= [ol(t),or(t),dl(t),dr(t),θ(t)]T,其中θ(t)为机器人当前方向与目标点的夹角。趋光学习行为选择环节输入域是s(t) = [ol(t),or(t),dl(t),dr(t)]T。
图 6是机器人在有障碍物的环境下趋光学习情况。图 6(a)是学习初期试探结果,机器人从起始位置出发并不向光源方向运动,说明机器人原本不具备趋光能力。图 6(b)是学习中期试探结果,机器人起始位置出发到达接近光源附近位置停止,但并未始终按光源所在方向移动,说明通过学习并未完全掌握趋光能力。6(c)是机器人从起始位置出发到达接近光源附近位置停止,始终按光源所在方向移动,说明已经掌握趋光能力。图 6(d)是移动机器人在趋光移动中感知光强的变化曲线,机器人在起点位置时,光强较弱,随着与光源距离的接近,光强逐渐增加,最后到达光源附近,感知的光强最强。
 |
| 图 6 机器人趋光学习过程曲线Fig. 6 The robot curve of phototactic learning |
图 7是机器人在趋光学习过程中的相邻动作评价值变化的收敛曲线。从曲线上可以看出,在学习初期、中期和末期,曲线波动幅度由大到小,说明机器人最初缺乏先验知识,学习随机性较大,动态性能较差,随着学习的进行,随机性减小,动态性能有所提高,机器人自组织、自学习的能力逐步完善,机器人逐渐学会了趋光移动技能,可以较好地模拟生物的趋光行为。将学习实验进行100次,统计学习成功的仿真实验步数并计算平均值,机器人平均需要420步的学习,逐渐学会了趋光行为。将该方法与没有情感智能作用的方法进行对比实验,在相同实验条件下,没有情感智能作用时,平均需要550步的学习。说明情感因数在机器人趋光行为决策中可以减少学习步数。
 |
| 图 7 机器人趋光仿真收敛曲线Fig. 7 The robot convergence curve of phototaxis simulation |
为了进一步验证算法的有效性,在相同实验条件下,将有无情感智能的2种情况做对比实验,改变实验参数折扣因子γ,2种方法分别进行100次试探学习,分别统计两者学习的试探成功次数。通过实验数据结果可以看出,在折扣因子选取不同的数值时,有情感智能作用下的试探成功次数多,如图 8所示。说明在机器人的趋光学习过程中,情感智能的引入能够提高机器人学习的试探成功率。
 |
| 图 8 机器人趋光试探成功次数对比实验Fig. 8 The comparative experiments of robot phototaxis training success rate |
通过对基于情感的内发动机机器人自主趋光行为的研究,使机器人通过自主学习逐渐形成、发展并完善了趋光能力。通过模拟生物的情感智能,采用模糊推理方法设计情感模型,提高了机器人趋光学习的试探成功率,减少了学习步数,实验表明情感智能可以增强机器人的行为决策能力。
| [1] | OUDEYER P, KAPLAN F. What is intrinsic motivation? a typology of computational approaches[J]. Frontiers in Neurorobotics, 2007, 1(6): 1-14. |
| [2] | SINGH S. Intrinsically motivated reinforcement learning: an evolutionary perspective[J]. IEEE Transactions on Autonomous Mental Development, 2010, 2(2): 70-82. |
| [3] | AHN H, PICARD R W. Affective cognitive learning and decision making: the role of emotions[C]//The 18th European Meeting on Cybernetics and Systems Research. [s.l.], 2006: 1-6. |
| [4] | MALFAZ M, SALICHS M A. Learning to avoid risky actions[J]. Cybernetics and Systems, 2011, 42(8): 636-658. |
| [5] | SEQUEIRA P, MELO F S, PAIVA A. Emotion-based intrinsic motivation for reinforcement learning agents[C]//Affective Computing and Intelligent Interaction. Berlin: Springer, 2011: 326-336. |
| [6] | ABDI J, MOSHIRI B, ABDULHAI B, et al. Short-term traffic flow forecasting: parametric and nonparametric approaches via emotional temporal difference learning[J]. Neural Computing and Applications, 2013,23:141-159. |
| [7] | 刘明, 许力. 人工情感在Agent行为选择策略中的应用[J]. 江南大学学报, 2003, 2(6):564-568.LIU Ming, XU Li. Study on artificial emotion and its application in the behavior selection strategy of agents[J]. Journal of Southern Yangtze University, 2003,2(6): 564-568. |
| [8] | 张惠娣,刘士荣. 基于情感与环境认知的移动机器人自主导航控制[J]. 控制理论与应用, 2008, 25(6): 995-1000.ZHANG Huidi, LIU Shirong. Autonomous navigation control for mobile robots based on emotion and environment cognition[J]. Control Theory & Applications, 2008, 25(6): 995-1000. |
| [9] | 胡云斗,胡丹丹,高庆吉. 一种基于任务的机器人情感决策模型的构建[J]. 机器人, 2010, 32(4):464-477.HU Yundou, HU Dandan, GAO Qingji. Construction of a robot emotion decision-making model based on tasks[J]. Robot, 2010, 32(4):464-477. |
| [10] | 祝宇虹,毛俊鑫. 基于人工情感与Q学习的机器人行为决策[J]. 智能工程, 2008, 61(7): 61-65.ZHU Yuhong, MAO Junxin. Robot's behavioral decision-making strategy based on artificial emotion and Q-learning[J]. Intelligent Engineering, 2008, 61(7): 61-65. |
| [11] | ASADA M, UCHIBE E, HOSODA K. Cooperative behavior acquisition for mobile robots in dynamically changing real worlds via vision-based reinforcement learning and development[J]. Artificial Intelligence, 1999, 110(2): 275-292. |
| [12] | HUMBERT J S, HYSLOP A M. Bioinspired visuomotor convergence[J]. IEEE Transactions on Robotics, 2010, 26: 121-30. |
| [13] | ZOLLO L, ESKIZMIRLILER S, TETI G, et al. An anthropomorphic robotic platform for progressive and adaptive sensorimotor learning[J]. Advanced Robotics, 2008, 22: 91-118. |
| [14] | BARANES A, OUDEYER P Y. Active learning of inverse models with intrinsically motivated goal exploration in robots[J]. Robotics and Autonomous Systems, 2013, 61(1): 49-73. |
| [15] | VIGORITO C M, BARTO A G. Intrinsically motivated hierarchical skill learning in structured environments[J]. IEEE Transactions on Autonomous Mental Development, 2010, 2(2): 132-143. |
| [16] | EI-NASR M S, YEN J. Agents, emotion intelligence and fuzzy logic[C]//Proceedings of the North American Conference on the Fuzzy Information Processing Society. Pensacola Beach, 1998,1:135-140. |
| [17] | DEGAONKAR V N, APTE S D. Emotion modeling from speech signal based on wavelet packet transform[J]. International Journal of Speech Technology, 2013, 16(1): 1-5. |
| [18] | ORTONY A. The cognitive structure of emotions[M]. Cambridge:Cambridge University Press, 1990:35-77. |
| [19] | OUDEYER P Y, KAPLAN F, HAFNER V V. Intrinsic motivation systems for autonomous mental development[J]. IEEE Transactions on Evolutionary Computation, 2007, 11(2): 265-286. |
| [20] | ZORAN M, MARKO M, MIHAILO L, et al. Neural network reinforcement learning for visual control of robot manipulators[J]. Expert Systems with Applications, 2013, 40(5): 1721-1736. |