

DOI: 10.3969/j.issn.1673-4785.201108007

 ,
,
,
,
2. 哈佛医学院 Dana-Farber癌症研究所,波士顿 马萨诸塞州 02115,美国
,
,
2. Dana-Farber Cancer Institute, Harvard Medical School, Boston, Massachusetts 02115, USA
随着Web应用的不断普及,网络服务为越来越多的用户使用。由于许多网络应用服务开发者安全意识的缺失,致使网络服务程序中存在大量的安全漏洞,这使得Web服务器成为黑客攻击的主要目标之一。最新的CVE漏洞趋势报告[1]显示,跨站脚本攻击(XSS)、SQL注入(SQL-inject)和远程文件包含(RFI)等基于HTTP协议[2]的网络攻击已经成为近年来互联网上最主要的攻击方式。
为了防御Web攻击,网络安全工作者研究和开发了多种方法[3-5]。入侵检测系统(intrusion detection system, IDS)是防御网络攻击的重要手段[6]。入侵检测方法主要分为两大类:误用检测(misuse detection)和异常检测(anomaly detection)。误用检测通过规则的方式来定义攻击行为的特征,例如Snort检测系统[7]。随着攻击方式的日益增加,误用检测方法的弊端越来越明显:攻击的增加导致检测规则的增加,这使得及时准确的更新、维护规则库越来越困难;而且,误用检测只能检测已知的攻击方式,对新的未知攻击方式则无能为力[8]。异常检测可以有效地克服误用检测的上述缺点。异常检测定义正常行为的特征,通过统计分析、数据挖掘的方法,学习得到正常行为的特征模型,当网络行为显著偏离正常的行为模式时则识别为异常行为。近年来提出了很多针对Web攻击的异常检测模型[9-10],这些模型多采用监督学习来学习正常访问行为的特征模式,利用学习样本的分布来确定正常和攻击行为的边界。然而,许多异常检测方法问题在于:1)模型在开始检测之前需要多次学习,通常需要大量的计算资源;2)由学习得到的正常行为模型需要进一步做精细的泛化处理,使得模型能够尽可能代表未学习过的正常样本,而泛化的困难性很多时候会大大地限制该模型的应用效果。
基于Web访问的统计研究表明,正常样本占总体样本的大多数,且行为模式相似;而攻击样本只占一小部分,且行为模式各异[11]。本文依据正常样本与攻击样本的统计差异,提出了一种基于文本聚类的非监督检测算法:采用层次聚类的过程逐步聚合样本,并用贝叶斯原则指导聚类过程,最终将正常和攻击样本聚合到不同的类别之中。本文方法在系统设计方面具有非监督学习方法的特点,省去了复杂的模型学习过程,简化了检测流程,以提高算法的适应性。在与多种经典检测方法的比较实验中,本文方法取得了较高的检测率,可以较好地抑制误报率。
1 相关研究工作异常检测方法最早被应用于传统入侵检测系统的设计。Mahoney和Chan[12]从正常的网络数据包序列建立马尔可夫模型来检测新的未知攻击方式。Portnoy等[11]提出了基于TCP协议的聚类方法。Warrender等[13]分析了特殊应用程序的正常系统调用序列以识别恶意程序。Sengar等[14]专门为VoIP(voice over Internet protocol)协议的通信设计了IDS系统,系统为协议生成相应的状态机以检测通信行为是否为攻击。周东清等[15]提出基于隐马尔可夫模型的DDoS(分布式拒绝服务)检测攻击方法。
针对Web攻击,Kruegel和Vigna[9-10, 16]提出了多种异常检测模型,它们是长度模型、字符分布、NFA和枚举类型。这些模型分别解析了HTTP协议请求,针对HTTP请求或请求中的属性进行检测,给出异常程度评价。它们都使用了有监督的方式来训练正常请求的模型参数和最佳的分类阈值。与此类似,本文研究的是基于HTTP协议的Web攻击检测。
本文利用现实情况中正常样本占总访问量的绝大多数、行为特征类似, 而攻击样本数量少、个体行为差别大的规律,提出了基于聚类的非监督检测方法,省去了训练样本的标记和训练过程,提高了系统的适应能力。需要特别指出的是,类似的分布规律也同样出现在IDS告警处理的研究中[17],这也是方法有效性成立的基础和方法设计的准则。
2 基于文本聚类的检测方法 2.1 算法假设HTTP请求一般由多个参数组成,参数中间用字符“&”隔开,每个参数以“属性名=属性值”的形式组织。参数值中放入恶意的代码是常见的针对特定程序和特定属性的攻击方式,未经充分检查的参数值可以引起Web服务端的信息泄露、服务崩溃,甚至导致Web服务器劫持。在包含多个参数的请求中,任意一个参数的属性值被检测到含有攻击代码则判定请求为攻击。虽然属性值可以取包括数字、字符和特殊符号等多种形式,但本文都看作是一个文本字符串。
在对现实Web访问数据的分析中,发现90%以上的访问请求都是正常的,恶意的攻击行为占总请求量的很小一部分[11]。正常访问和恶意攻击的概率密度函数符合如下的特点(如图 1所示):1)正常访问占绝大多数,攻击占很小一部分;2)正常访问的参数形式之间变化很小,具有很好的聚类特性;3)恶意的攻击与正常的样本模式之间有较大的差异,聚类特性较差。

|
| 图 1 样本分布示例 Fig. 1 Illustration of sample distribution |
Web服务的同一个页面或程序通常会被许多不同的用户以同样的形式访问;而且一个参数可以接受的数据类型一般都比较规范,例如属性名为“生日”的参数形式会是一个日期型字符串,不同的合法输入值之间比较相似。这就使得正常样本具备了上述特点1)和2)的分布特性。恶意攻击则来自于少数的恶意客户端,同样的攻击方式没有必要多次重复,同时攻击的形式也没有规律性,决定了上述攻击样本的分布特性。
2.2 距离定义本文处理的数据是字符串样本,而传统的欧式距离只适用于向量型的数据类型,本节将定义字符串数据间的距离度量。
2.2.1 样本间距离样本间距离是定义所有距离度量的基础。给定字符串样本x1=k1k2…km, x2=l1l2…ln, 其中ki=x1(i)是x1中第i个字符,lj=x2(j)是x2中第j个字符,m=L(x1)、n=L(x2)分别代表x1和x2的字符串长度。样本x1和x2的距离d(x1, x2)由下面3个部分组成。
1)字符串长度差异。
字符串长度差异是字符串间最基本的差异度量,定义为
 |
2)字符集差异。
样本x的字符集是组成样本字符串的所有字符的集合,用A(x)表示样本x的字符集。例如,x=“12332”时,A(x)={1, 2, 3}。字符集差异用于描述字符串在字符选择上的差异,当2个字符串的字符集在数量和类型方面存在较大不同,特别是出现不同类型的字符时,需给出惩罚。
定义字符集距离之前需要定义字符间的距离,字符k、l的距离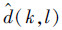
 |
表 1为算法中使用的3种字符类型,分别为数字类型、小写字符和大写字符、其他的字符。例如字符“/”和“-”不属于同类字符,字符间距离为10。
字符集A和字符b间的距离用d(A, b)表示,其中d(A, b)=d(b, A),定义为
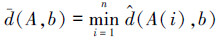 |
式中:n为字符集A中字符的数量,A(i)表示A中第i个字符。
字符集距离定义为字符和字符集间的距离之和,即字符串样本x1和x2间的字符集距离为
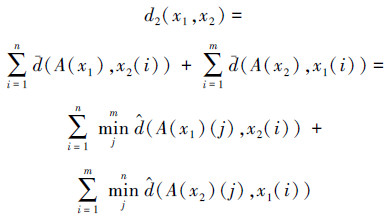 |
3)字符组合顺序差异。
字符组合顺序是用2个或多个连续字符为单位, 描述字符串间相似度的度量,例如字符串“abcdabcd”和“dcbadcba”在长度和字符集方面都相同,但字符的组合顺序大不相同。G(x)表示字符串样本x中连续出现2个字符的集合,#(G(x))表示集合G(x)中元素的数目,则x1和x2的字符组合顺序差异定义为
 |
d3(x1, x2)是x1和x2中不同的2-grams的数量。
因此,x1和x2的距离为
 |
样本x与聚类C={x1, x2, …, xn}间的距离定义为
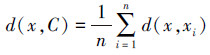 |
(1) |
类C1={x11, x12, …, x1m}与类C2={x21, x22, …, x2n}间的距离为
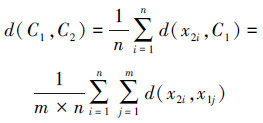 |
聚类C={x1, x2, …, xn}的类内距离为
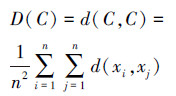 |
(2) |
如图 2所示,本文基于层次聚类的Web攻击检测算法包括4个部分组成:层次聚类算法、迭代聚类算法、最优方案选择算法和检测算法。

|
| 图 2 基于层次聚类的检测算法 Fig. 2 Agglomerative clustering based detection method |
层次聚类算法旨在形成初步的2类聚类,分别代表正常的聚类和异常的聚类,并且使得聚类符合2.1节中特点1)的条件。
样本集X={x1, x2, …, xn}的层次聚类的算法如下:
1)初始化,将每一个样本作为一个聚类,得到聚类集合C={C1, C2, …, Cn},其中Ci={xi};
2)选择Ci、Cj,满足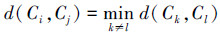
3)合并Ci、Cj,更新聚类集合C=C-Ci-Cj + Ci∪Cj;
4)选择CM,满足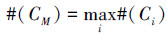
5)如果
6)将除CM以外的所有聚类合成一类CN=
7)记聚类CM和CN为C1、C2;
8)结束。
层次聚类算法得到了聚类C1和C2,其中C1包含整个样本集50%以上的样本,根据对正常样本和异常样本分布的假设,将C1和C2作为初步的正常样本和异常样本聚类,继续迭代聚类。
2.3.2 迭代聚类算法迭代聚类是以层次聚类中的初步分类方案为基础继续聚类过程,每一个聚类步骤将产生一个分类方案,这些分类方案序列是2.3.3节中算法的基础。
C1和C2是迭代聚类的数据源。根据样本数据的分布特性,C1仅仅包含了正常样本中聚类特性最好的一部分样本,C2还含有大量的正常样本。通过迭代聚类,将C2中的正常样本逐步聚合到C1中来。
C1和C2是对样本集的一种分类方案,将集合S={C1, C2}称为一种分类方案,迭代聚类的结果是一个分类方案的序列。
迭代聚类算法如下:
1)初始化,N=0;
2)记录分类方案SN={C1, C2},N=N+1;
3)从C2中选择样本x,满足d(C1, x)=
4)将x从C2移到C1,更新C1、C2,C1=C1∪{x},C2=C2-{x};
5)如果C2≠⌀,则转到步骤2);
6)结束。
2.3.3 选择最优方案算法本小节算法旨在选择满足2.1节中特点2)和3)的分类方案。选择最优聚类方案时,考虑使得分类误差最小,最小分类误差计算如下:
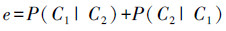 |
根据切比雪夫不等式,得到样本x分布在均值μ距离t以外的概率上界:
 |
所以图 3中,
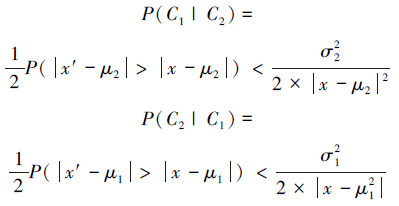 |

|
| 图 3 两类问题中的最小分类误差原则 Fig. 3 Minimum error principle in 2-class situation |
最小误差的上界e为
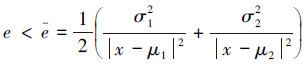 |
(3) |
用e近似最小分类误差e来衡量分类方案的优劣。
给定Si={C1, C2},x为Si-1到Si迭代聚类时从C2移到C1中的样本,式(3)中C1和C2的方差σ12和σ22分别用式(2)的类内距离D(C1)和D(C2)来计算,而x到类均值的距离|x-μ1|和|x-μ2|分别用式(1)中的样本与类间距离d(x, C1)和d(x, C2)计算,e的计算公式为
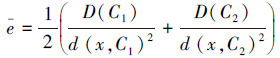 |
在分类方案序列S1, S2, …, SN中,选择使得e最小的分类方案S*,作为最优的分类方案。
2.3.4 检测算法最优的分类方案S*={C1, C2},则检测算法直接根据样本所属聚类的类别进行分类:
 |
式中:0表示正常样本,1表示异常样本。
3 实验和讨论标准的网络攻击样本库数量较少,其中比较著名的包括MIT林肯实验室的DARPA数据集[18-19]和KDDCup’99数据集[20]。因为这些数据集只含有少量的Web攻击,同时数据收集时间较早,无法有效地验证本文方法,所以采用笔者收集的域名为“njust.edu.cn”2010年上半年的网站log数据。经过人工和程序辅助的检查,用于本文实验的数据集含有大量的恶意攻击访问,其中包括SQL注入、跨站脚本攻击(XSS)、文件包含、漏洞溢出等。
表 2列出了NJUST数据集中3个子数据集的大致情况,数据集A样本数最小,正常的样本格式规整、形式单一;数据集B中含有大量的攻击样本,数量几乎与正常的样本数量相当;数据集C的样本总量最大,但攻击样本的比率最低。
| 数据集 | 样本数 | 正常样本 | 攻击样本 |
| A | 6 119 | 4 512 | 1 607 |
| B | 11 148 | 6 050 | 5 098 |
| C | 85 700 | 83 391 | 2 309 |
用文献[10-12]中的长度模型、字符分布模型和枚举类型模型与本文的文本聚类方法作比较。长度、字符分布和枚举类型的分类原则均采用原文中阈值高于最高正常样本异常度10%的经验策略。
实验目的是比较本文方法和经典方法的ROC曲线,即模型的分类能力。与其他模型直接输出测试样本的异常测度不同,文本聚类Web攻击检测算法只能给出样本的分类结果。在本文方法的层次聚类和迭代聚类过程中,取每一个最大聚类中的样本为正常样本,其他样本为异常样本。这样每一个聚类的中间步骤都作为一次分类,把这些分类结果的检测率和误报率绘制成文本聚类方法的ROC曲线。聚类方法的ROC曲线也反应了聚类的分类性能,可以用来验证2.3.3节中最优分类方案选择算法是否可以找到聚类方法的最优分类点。
NJUST数据集的3个子数据集分别被随机均分成训练集和测试集,用训练集训练模型,测试集测试模型的检测性能。因为文本聚类方法不需要事先训练,因此直接在测试集上测试聚类方法。
4种检测方法在A、B、C 3个数据集上的ROC曲线对比结果依次见图 4,本文方法在图中称为“文本聚类”。

|
| 图 4 数据集A、B、C上的ROC曲线对比 Fig. 4 ROC comparisons on dataset A, B and C |
从结果中可以看出:
文本聚类方法和长度模型都具有很高的检测率和较低的误报率,同时这2种方法在不同数据集上的性能表现都很稳定,最好的检测率和误报率几乎没有变化。
字符分布模型的性能根据数据集的不同起伏很大,特别是在具有大量攻击样本的数据集B上。说明字符分布模型对正常样本的形式要求很高,在正常样本形式简单和规则的条件下性能尚可,否则检测性能将大幅下降。
枚举类型在数据集A和B上性能差不多,这个模型容易产生很高的误报率。这是因为枚举类型模型不具有样本的泛化能力,只是机械地记录学习过的样本,遇到新的样本一律判定为异常行为。枚举类型模型在数据集C上的ROC曲线是连接点(0, 0)和点(1, 1)点的直线,表明模型对数据集C的数据没有任何分类能力。这是因为模型在检验数据类型是否为枚举类型时假设检验失败,从而判定模型无法检测数据集C的数据。
文本聚类方法在3个数据集上均表现出了最高的检测率和几乎为0的误报率,证实了聚类方法的有效性。在数据集B上有大量攻击样本的存在,攻击样本和正常样本的比率很高,这不满足2.1小节中二者比率很小的算法成立假立,说明虽然算法成立的假设是很严格的条件,但在适当放宽其中的一部分条件时,聚类算法仍然能够有效地检测攻击样本。
本文方法在实验中比经典模型显示出检测率高、误报率低和稳定性高的特点,并且无需事先训练。这是因为算法设计运用了现实数据统计规律,相当于使用了样本分布的先验知识,从而使得本文方法在3个实验中可以进行有效的检测。
4 结束语针对Web攻击检测研究表明,正常的Web访问行为占访问样本的大多数且行为模式类似、具有很好的聚类性;而攻击行为占访问样本少数且行为模式各异、聚类性差。基于这一规律,提出了一种基于文本聚类的非监督检测算法。另外,本文算法在NJUST现实数据集上取得了较高的检测率,从而证实了该方法的有效性。
本文算法基于非监督学习思想,省去了多数异常检测方法中复杂的学习训练过程,增强了方法的应用性。该方法尚存的缺点是聚类速度较慢,对于边界样本难于判断其类别,这将在未来的工作中研究改进。
| [1] | CHRISTEY S, MARTIN R A. Vulnerability type distributions in CVE [EB/OL]. [2011-08-20]. http://cwe.mitre.org/documents/vuln-trends.html. |
| [2] | FIELDING R, GETTYS J, MOGUL J, et al. RFC-2616: hypertext transfer protocol-HTTP/1.1[S]. Montreal: Internet Engineering Task Force (IETF), 1999. |
| [3] | INGHAM K L, SOMAYAJIB A, BURGEA J, et al. Learning DFA representations of HTTP for protecting web applications[J]. Computer Networks , 2007, 51 (5) : 1239-1255 DOI:10.1016/j.comnet.2006.09.016 |
| [4] | CORONA I, ARIU D, GIACINTO G. HMM-Web: a framework for the detection of attacks against web applications[C]//IEEE International Conference on Communications. Dresden, Germany, 2009: 1-6. |
| [5] | DURY A, HALLAL H H, PETRENKO A. Inferring behavioural models from traces of business applications[C]//IEEE International Conference on Web Services. Los Angeles, USA, 2009: 791-798. |
| [6] | BACE R. Intrusion detection[M]. [S.l.]: Macmillan Publishing Co. Inc., 2000 : 1 -4. |
| [7] | ROESCH M. Snort-lightweight intrusion detection for networks[C]//Proceedings of the 13th USENIX Conference on System Administration. Seattle, USA, 1999: 229-238. |
| [8] | CHANDOLA V, BANERJEE A, KUMAR V. Anomaly detection: a survey[J]. ACM Computing Surveys , 2009, 41 (3) : artical no. 15 |
| [9] | KRUEGEL C, VIGNA G. Anomaly detection of web-based attacks[C]//Proceedings of the 10th ACM Conference on Computer and Communications Security. Washington, DC, USA: ACM, 2003: 251-261. |
| [10] | KRUEGEL C, VIGNA G, ROBERTSON W. A multi-model approach to the detection of web-based attacks[J]. Computer Networks , 2005, 48 (5) : 717-738 DOI:10.1016/j.comnet.2005.01.009 |
| [11] | PORTNOY L, ESKIN E, STOLFO S. Intrusion detection with unlabeled data using clustering[C]//Proceedings of ACM CSS Workshop on Data Mining Applied to Security. Philadelphia, USA, 2001: 5-8. |
| [12] | MAHONEY M V, CHAN P K. Learning nonstationary models of normal network traffic for detecting novel attacks[C]//Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2002: 376-385. |
| [13] | WARRENDER C, FORREST S, PEARLMUTTER B. Detecting intrusions using system calls: alternative data models[C]//Proceedings of IEEE Symposium on Security and Privacy. Oakland, USA, 1999: 133-145. |
| [14] | SENGAR H, WIJESEKERA D, WANG H, et al. VoIP intrusion detection through interacting protocol state machines[C]//Proceedings of International Conference on Dependable Systems and Networks. Philadelphia, USA: IEEE/IFIP, 2006: 393-402. |
| [15] | 周东清, 张海锋, 张绍武, 等. 基于HMM的分布式拒绝服务攻击检测方法[J]. 计算机研究与发展 , 2005, 42 (9) : 1594-1599 ZHOU Qingdong, ZHANG Haifeng, ZHANG Shaowu, et al. A DDos attack detection method based on hidden Markov model[J]. Journal of Computer Research and Development , 2005, 42 (9) : 1594-1599 DOI:10.1360/crad20050921 |
| [16] | INGHAM K L, INOUE H. Comparing anomaly detection techniques for HTTP[C]//Proceedings of the 10th International Conference on Recent Advances in Intrusion Detection. Gold Goast, Australia, 2007: 42-62. |
| [17] | JULISCH K. Clustering intrusion detection alarms to support root cause analysis[J]. ACM Transactions on Information and System Security , 2003, 6 (4) : 443-471 DOI:10.1145/950191 |
| [18] | HAINES J W, LIPPMANN R P, FRIED D J, et al. 1999 DARPA intrusion detection system evaluation: design and procedures, TR-1062[R]. Lexington, USA: Lincoln Laboratory, Massachusetts Institute of Technology, 2001. |
| [19] | LIPPMANN R P, HAINES J W, FRIED D J, et al. The 1999 DARPA off-line intrusion detection evaluation[J]. Computer Networks , 2000, 34 (4) : 579-595 DOI:10.1016/S1389-1286(00)00139-0 |
| [20] | The UCI KDD Archive. KDD Cup 1999 data[EB/OL]. (1999-10-28)[2011-08-20]. http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html. |