



0 引 言
随着机械设备状态监测技术的进步,监测数据的种类越来越多,数据量越来越大,常规的分析方法难以对大量高维数据进行有效处理,因此从大量数据中选取出与故障诊断相关的信息成为一个重要问题。关联规则挖掘作为关联知识发现中最常用的方法[1],可以轻易地发现数据之间的联系,能够挖掘出潜在有意义的信息。因此,为了剔除冗余信息,发现特征值与故障之间潜在的联系,通过分析潜在规律实现更精准快速的故障诊断,将关联规则挖掘的方法引入到故障诊断中[2-3]。
关联规则挖掘方法的研究中,传统关联规则挖掘是基于Apriori算法的布尔型关联规则挖掘,但是用于故障诊断的数据大多是量化属性值[4],需要对数据进行离散化处理,将数据值映射到区间,实现由量化值到布尔型的转变[5]。常见的均匀划分区间会出现边界过硬问题[6]。基于模糊概念的挖掘方法可以解决边界过硬问题,但是会出现隶属度和隶属函数确定的问题[7]。使用聚类方法忽略了数据之间的关系[8]。
符号聚合近似(Symbolic Aggregate appro-Ximation,SAX)是一种数据压缩及信息提取方法,可以根据数据密度特点将数据序列离散化并转换成符号序列[9]。鉴于此,笔者提出一种基于SAX关联规则挖掘的方法,并将其用于故障诊断中。首先对数据进行特征提取;然后利用SAX方法将特征值序列离散化,划分为若干独立区间,用特定符号表示相应区间,使量化属性转变为布尔型;最后利用关联规则挖掘数据之间隐含的关系,求取与故障相关的最小故障特征集合,并利用该集合进行故障诊断。转子故障模拟试验结果表明:该方法可以有效挖掘故障与特征值之间的关系,提高故障识别率及计算效率。
1 方法原理 1.1 关联规则挖掘关联规则挖掘于1993年由R.AGRAWAL等人[10]首先提出,是知识发现(Knowledge Discovery in Database,KDD)研究的重要内容。关联规则挖掘的目的是在事务数据库中找出满足用户给定的最小支持度和最小置信度要求的关联规则,整个挖掘过程可分解为2步:①发现所有的事务支持度大于最小支持度的项集。②在找出频繁项集的基础上产生强关联规则。关联规则是形如X⇒Y的逻辑蕴含式,其中X⊂I,Y⊂I,且X∩Y=φ。设I={i1,…,im}为所有项目的集合,D为事务数据库,事务T是一个项目子集(TI)。每一个事务具有唯一的事务标识TID。
设A是一个由项目构成的集合,称为项集。事务T包含项集A,且AT。如果项集A中包含k个项目,则称其为k项集。项集A在事务数据库D中出现的次数占D中总事务的百分比称为项集的支持度。如果项集的支持度超过用户给定的最小支持度阈值,就称该项集是频繁项集。如果事务数据库D中有s%的事务包含X∪Y,则称关联规则X⇒Y的支持度为s%。将项集X的支持度记为support(X),规则的信任度则为support(X∪Y)/support(X)。
用于故障诊断中的规则X⇒Y,X作为特征及特征属性的集合,Y为故障类型的集合。
1.2 符号聚合近似(SAX)SAX是一种符号化方法,可以将连续数值用离散的、抽象的符号表示成符号序列。首先,将数值序列标准化,公式如下:

|
(1) |
式中:A是原始数据,B是A标准化后的值,μ和σ分别是原始数据的均值和标准差。
标准化后的序列服从高斯分布,然后设置N-1个“断点”将高斯分布围成的面积N等分,这样就划分为N个独立区间,每个区间用一个符号表示。将标准化后的数据与断点比较,便会映射为相应的符号。如图 1所示曲线,如果划分为4个区间,则要设置3个断点-0.67、0和0.67,可将高斯分布的面积划分为3个等面积区域,然后将标准化后的数据与断点比较,小于-0.67的值可用符号a表示,以此类推,其他几个区间分别用b、c、d表示。

|
| 图 1 SAX示意图 Fig.1 Schematic diagram of SAX |
a、b、c、d 4个符号的集合称为符号集,用这4个符号来表示时间序列,可以表示为符号序列“S=dddcbaaa”,从而实现了连续数据的离散化。
2 基于SAX的关联规则挖掘关联规则方法的目的是找寻关系,当其应用于故障诊断中时,主要是挖掘特征与故障之间潜在的关系。而关系通常由布尔型数据表示,在经济、金融和社会学等领域关联规则挖掘方法的应用中,通常有对应的布尔型关系数据来表征,但是,在机械设备故障监测中,数据通常是连续的,无法对数据直接进行挖掘,因此在关联规则挖掘之前需要对数据进行离散化处理。
针对这一问题,笔者引入SAX符号化的方法,将每组特征数据划分为若干独立区间,每个区间用一个符号表示。不同特征用不同符号表示,用i(i=1,2,3……)表示特征下的第i个特征,用{a,b,c,……}分别代表不同属性区间,如a2表示的是第2个特征下的a属性区间。设置最小支持度和最小置信度,再用Apriori算法对符号化后的特征进行关联规则挖掘。
基于SAX的关联规则挖掘流程如图 2所示。

|
| 图 2 基于SAX的关联规则挖掘流程图 Fig.2 Flow chart of SAX-based association rule mining |
首先,对工程装置按照需求进行数据采集,获取不同状态下的数据集,并利用时域和频域等指标对数据进行特征提取,组成特征向量;其次,利用SAX方法根据数据分布密度将特征向量进行离散化并转化为符号序列;再次,利用关联规则挖掘离散化的特征和故障模式之间的关联关系,得到每种状态下的特征规则库;最后,将后续采集过程中的数据按照前2步进行处理,选取与规则库对应的规则进行比对和数据降维,并采用智能识别方法进行模式识别和故障诊断。
3 实例分析 3.1 试验设置及特征提取转子系统振动信号相对于其他设备具有更明确的物理意义,因此采用转子故障试验进行分析和验证。通过实验室Bently RK4转子故障模拟试验台采集转子故障信号。试验系统由调速台、电机、转轴、双圆盘、滑动轴承和基座等组成。试验中,模拟不平衡故障时所加配重为1 g;模拟不对中故障时在轴承座与底座接触面放置厚度为0.5 mm的塞尺;通过在底座卡槽中固定碰摩块来模拟与转轴的摩擦故障。加速度传感器布置在靠近联轴器端转子支撑座的垂直方向。转速设定为3 000 r/min,采样频率为16 kHz,采样点数为4 096,试验台及采集方案如图 3所示。

|
| 图 3 转子故障模拟试验台 Fig.3 Rotor fault simulation test bed |
试验共采集正常、不平衡、不对中和碰摩4类样本各40组,其中20组用来进行数据挖掘,另外20组用来进行测试。由于频域特征能够表现转子故障特点,因此选用了0.5倍频、1倍频、1.5倍频、2倍频、3倍频、4倍频、5倍频和6倍频8个倍频分量的幅值作为特征向量。
3.2 基于SAX的数据预处理将每类样本20组共80组待挖掘数据的特征值组成8×80的特征值矩阵。每一种特征值视为一个1×80样本特征序列进行SAX符号化处理,其中SAX的压缩比为1,符号集为4,同样用等密度和等宽度方法进行离散化,然后将数据归一化后画出分布图,如图 4所示。

|
| 图 4 离散化数据对比 Fig.4 Comparison of discretization data |
离散化数据的目的是在保留原始数据特征分布的前提下将数据规则化,利于关联规则的挖掘。从图 4中可以看出,SAX离散化效果最好,不仅保留了原始数据的数据分布特点,并且使数据变得平滑,利于关联规则挖掘。
为了量化离散化效果,采用区间类信息熵做对比。第i个区间类信息熵Ii的定义如下[11]:
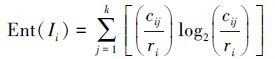
|
(2) |
式中:k为类别个数,cij为第i个区间中类别为j的事例个数,ri为第i个区间中总的事例个数。
信息熵的值越大表明区间中类别越混杂,离散效果越差。当区间中只有一个类别时,信息熵为0,表明离散效果最好。
下面对用等密度、等宽度以及SAX离散化方法对数据进行离散化,对每列特征数据划分4个区间,共8个特征,得到8×4的数据方阵,然后对区间进行类信息熵计算,得到8×4的信息熵,将计算结果按特征计算平均信息熵,画出折线图,结果如图 5所示。从图中可以看出,用SAX方法得到的平均信息熵最低,效果最好;其次是等宽度的离散化方法;效果最差的是等密度的离散化方法。

|
| 图 5 信息熵对比 Fig.5 Comparison of information entropy |
3.3 关联规则挖掘结果分析
将3.2节中得到的故障特征矩阵中所有32个符号和4种转子状态作为包含有36个项的项集,每一组数据的符号向量和故障类型作为一个事物构建成包含80组事物的事物集。利用基于Apriori的关联规则挖掘方法进行挖掘,设置支持度为0.6,置信度为0.9。由于故障诊断所需的数据挖掘主要目的是得到与故障相关的特征信息,所以设置关联规则后项为4种转子状态。经挖掘后共得到368条规则,其中部分长规则如表 1所示。
| 前项 | 后项 | 支持度 | 置信度 | |||||||
| 0.5f | 1f | 1.5f | 2f | 3f | 4f | 5f | 6f | |||
| a1 | a2 | a3 | a4 | a5 | a6 | a7 | a8 | 正常 | 0.60 | 1 |
| - | d2 | - | c4 | - | - | b7 | b8 | 不平衡 | 0.75 | 1 |
| a1 | c2 | a3 | d4 | c4 | - | b7 | b8 | 不对中 | 0.85 | 1 |
| - | d2 | - | c4 | d5 | d6 | d7 | d8 | 碰摩 | 0.60 | 1 |
由表 1可见,正常样本每个倍频的幅值均较低且比较稳定,不平衡样本具有最高的1倍频和较高的2倍频幅值,不对中故障有较高的1、3倍频幅值和最高的2倍频幅值,而碰摩故障除1倍频相对较低外,2、3、4、5、6倍频均相对较高。以上挖掘结果符合转子故障的特点,证明挖掘结果有效。
长规则可以较好地总结故障原理,但在故障诊断中不利于数据降维,而短规则可以挖掘出故障相关程度最高的特征值,可以大大减少数据量,提高计算效率。试验挖掘出的短规则如表 2所示。
| 前项 | 后项 | |||||||
| 0.5f | 1f | 1.5f | 2f | 3f | 4f | 5f | 6f | |
| - | a2 | - | - | - | - | - | - | 正常 |
| - | d2 | - | c4 | - | - | - | - | 不平衡 |
| - | c2 | - | d4 | - | - | - | - | 不对中 |
| - | - | - | - | - | - | d7 | - | 碰摩 |
由表 2可见,4类状态样本的短规则最小事物合集仅包含1、2、5倍频3个特征值的信息,实现了由8维矩阵到3维矩阵的降维。为了验证该方法的有效性,将每类样本20组数据用来训练,20组数据用来测试,分别采用FCM、BP和GASVM方法来进行分类,分别选用全部8维特征值和挖掘得到的3维特征值进行测试,测试结果如表 3所示。
| 方法 | 原始特征 | SAX方法 | |||
| 准确率/% | 用时/s | 准确率/% | 用时/s | ||
| FCM | 85 | 0.079 2 | 95 | 0.072 7 | |
| BP | 95 | 4.584 3 | 100 | 2.224 0 | |
| GASVM | 100 | 0.919 6 | 100 | 0.869 5 | |
从表 3可以看出,利用关联规则挖掘降维后的特征向量进行故障诊断时,由于避免了无效数据干扰,所以在一定程度上提高了识别率;同时,由于维数降低,所以提高了计算效率,节约了计算时间,取得了较好的结果。
实际应用时工程装置故障数据较少,某些类型故障数据缺失。当无法通过实际装置数据获取故障特征数据库时,可通过仿真建模获取数据或通过同类型试验设备进行试验,对试验数据进行处理以得到规则库。由于本文采用的SAX方法通过数据的分布密度进行离散化以获得符号集,不同组数据之间的具体数值差距和数值范围对这一过程没有影响,且进一步的数据挖掘和诊断建立在符号集上,所以SAX方法对试验数据和真实设备之间的数据通用具有良好的鲁棒性,便于进行实际应用。
4 结 论(1) 利用SAX对转子故障特征向量进行处理,根据数据分布密度离散化数据,得到符号化数据集合,便于进行关联规则挖掘,与常用的等宽度和等密度离散化方法相比,可以得到更高的信息熵,在实现数据离散化的基础上保留了有效信息。
(2) 将离散化后的转子故障特征矩阵作为事物集,并进行关联规则挖掘,得到表征故障特征与故障模式之间关系的规则库,得出故障相关的敏感特征,与理论分析相符。
(3) 利用关联规则挖掘的规则库进行故障诊断,通过几种常见识别方法的诊断结果,可以看出基于SAX的关联规则挖掘方法可以有效提高故障诊断的效率和准确率,且不受分类器的影响。
| [1] | 何月顺.关联规则挖掘技术的研究及应用[D].南京:南京航空航天大学,2010. http://cn.bing.com/academic/profile?id=b1a89497aab733b95d4e0b3106a92b4a&encoded=0&v=paper_preview&mkt=zh-cn |
| [2] | 朱清香, 焦朋沙, 刘晶, 等. 矩阵加权关联规则在故障诊断系统中的应用[J]. 工业工程, 2013, 16(2): 87–91. |
| [3] | 杜华. 基于关联规则的船舶供电系统故障检测方法研究[J]. 计算机测量与控制, 2014, 22(1): 233–235. |
| [4] | 孟海东, 李丹丹, 吴鹏飞. 基于数据场的量化关联规则挖掘方法设计[J]. 计算机与现代化, 2013(1): 8–11. |
| [5] | SRIKANT R, AGRAWAL R. Mining quantitative association rules in large relational tables[J]. ACM SIGMOD Record.ACM, 1996, 25(2): 1–12. 10.1145/235968 |
| [6] | 李乃乾, 沈钧毅. 量化关联规则挖掘及算法[J]. 小型微型计算机系统, 2003(12): 2275–2277. |
| [7] | ABADEH M S, HAMID M, JAFAR H. Design and analysis of genetic fuzzy systems for intrusion detection in computer networks[J]. Expert System with Applications, 2011, 38: 7067–7075. 10.1016/j.eswa.2010.12.006 |
| [8] | 闫明月, 侯忠生, 高颖. 一种面向布尔时间序列的关联规则挖掘算法[J]. 控制与决策, 2012, 27(10): 1447–1451. |
| [9] | JESSICA L,EAMONN K,STEFANO L,et al.A symbolic representation of time series with implications for streaming algorithms[C]//ACM SIGMOD Workshop on Research Issue in Data Mining and Knowledge Discovery.San Diego,CA,2003:2-11. |
| [10] | AGRAWAL R,IMIELINSKI T,SWAMI A.Mining association rules between set of items in large databases[C]//ACM SIGMOD Conference on Management of Data,Washington,DC,1993:207-216. |
| [11] | 梁红旗. 数值属性离散化方法研究[J]. 信息技术, 2008(5): 99–101. |