 2019, Vol. 77
2019, Vol. 77中国气象学会主办。
文章信息
- 陈法敬, 陈静, 韦青, 李嘉鹏, 刘凑华, 杨东, 赵滨, 张志刚. 2019.
- CHEN Fajing, CHEN Jing, WEI Qing, LI Jiapeng, LIU Couhua, YANG Dong, ZHAO Bin, ZHANG Zhigang. 2019.
- 一种基于可预报性的暴雨预报评分新方法Ⅱ:暴雨检验评分模型及评估试验
- A new verification method for heavy rainfall forecast based on predictability Ⅱ: Verification method and test
- 气象学报, 77(1): 28-42.
- Acta Meteorologica Sinica, 77(1): 28-42.
- http://dx.doi.org/10.11676/qxxb2019.003
-
文章历史
- 2017-12-13 收稿
- 2018-06-22 改回




2. 浙江省气象台, 杭州, 310002;
3. 山西省气象局, 太原, 030002;
4. 中国气象局, 北京, 100081
2. The Meteorological Bureau of Zhejiang Province, Hangzhou 310002, China;
3. The Meteorological Bureau of Shanxi Province, Taiyuan 030002, China;
4. China Meteorological Administration, Beijing 100081, China
中国暴雨预报是气象部门最重要的天气预报业务之一,其中暴雨预报准确率的检验评估是其重要的组成部分(陶诗言,1980;矫梅燕,2010)。科学合理的暴雨预报检验评估方法不仅有助于预报员认识预报技术问题,改进完善预报方法,还有助于预报业务管理人员监控暴雨预报质量、比较不同地区暴雨预报能力,同时也是气象部门与社会公众交流暴雨预报业务能力的途径(陈法敬等,2015;Jolliffe, et al,2016)。因此,关于暴雨预报评分方法及其科学性和合理性的研究一直是预报员和预报业务管理人员研究的重要内容。
当前暴雨预报评分普遍采用二分类事件检验方法(WMO, 2009, 2015),即将暴雨预报与观测点进行匹配,统计暴雨事件发生或者不发生频数,计算预报评分,如成功指数(Threat Score, TS)、公平成功指数(Equitable Threat Score,ETS)、预报偏差(BIAS)、空报率(False Alarm Ratio,FAR)、命中率(Probability of Detection, POD)等。这些评分指数简明扼要,特别是TS评分,是中国预报员常用的暴雨预报检验评分(王雨等, 2013, 唐文苑等,2017)。但是,由于暴雨(24 h累计降水量大于等于50 mm)属于小概率事件,暴雨预报和观测样本较少,造成检验样本偏少,这时二分类事件检验方法中的双重惩罚问题表现得非常突出(Casati, et al, 2008),造成暴雨预报TS评分普遍偏低,通常为0.20左右(唐文苑等,2017),接近于TS评分值域的无技巧端。随着降水预报分辨率的提高,预报服务精细化程度越来越高,双重惩罚导致TS评分过低的问题更加突出,使得社会公众对气象部门暴雨预报直观认识存在偏差,并容易导致公众误解预报员的暴雨预报能力。
2017年中国气象局预报与网络司组织了暴雨预报检验评分心理期望值调研,了解预报员对暴雨预报评分的实际认识理解。从全国31个省、市、自治区气象台反馈的暴雨、大暴雨和特大暴雨预报评分期望值中位数(图 1)可见,预报员的暴雨预报评分期望值呈梯级下降特征。对于暴雨预报(50-99.9 mm),如实况出现暴雨量级,则评分为1.0,与TS评分相等;当实况出现中雨、大雨,或者大暴雨以上量级时,传统TS评分为0,而预报员评分分别为0.4、0.8、0.8;对于大暴雨量级预报(100-249.9 mm),当实况值出现大暴雨时,则评分为1.0,与TS评分相同;而实况为中雨、大雨,或者暴雨时,TS评分为0,但预报员评分赋值为0.1、0.5、0.8;对于特大暴雨量级预报(大于等于250.0 mm),当实况大于等于250 mm时,评分赋值为1.0,与TS评分相等;而实况为大雨、暴雨或者大暴雨量级时,TS评分为0,但预报员评分赋值为0.2、0.6和0.8。可见,预报员对暴雨预报评分的心理期望值与传统二分类事件暴雨预报TS评分值存在显著差异,对暴雨高报或者低报事件定义了一定的评分值。但调研的预报员评分期望值中位数在不同降水量级阈值处仍然呈现断崖式突变,如实况降水量级49.9和50.0 mm几乎没有区别,如果实况为49.9 mm,社会公众认为预报是非常准确的。因此,如何在预报员梯级下降评分基础上优化改进,避免断崖式突变,需要进行更多研究。Stephenson等(2008)采用渐进模型避开上述问题,结果表明,随着稀少事件的增加,所有传统评分都倾向极限值(0或者1)。

|
| 图 1 中国31个省、市、自治区气象台预报员对暴雨、大暴雨和特大暴雨预报评分期望中值 (a.暴雨,b.大暴雨,c.特大暴雨) Figure 1 Median values of expected forecast scores of forecasters from 31 provincial meteorological centers for 24-h heavy rainfall, heavy rainstorm and extreme flooding (a. heavy rainfall, b. heavy rainstorm, c. extreme flooding) |
中国位于东亚季风气候区,各地暴雨随东亚季风北进南撤和西进东退等变化而变化(中国科学院大气物理研究所,1998)。陈静等(2019)针对发展新型暴雨评分的需求,在分析影响预报员暴雨预报信心的主要因素(暴雨气候统计特征、影响系统运动尺度特征及数值模式预报能力)等基础上,构建了由暴雨气候频率、暴雨面积比率和模式暴雨预报成功指数3个分量组成的暴雨可预报性综合指数(Synthetic Predictability Index of Heavy Rainfall,SPI)数学计算模型,试验结果显示,SPI可以较好地反映中国暴雨可预报性的时空变化特征。随着副热带高压的北进南撤过程,4-8月,SPI大值中心从华南地区逐渐北推至长江、淮河及华北和东北地区,9月则随着副热带高压而南撤。在中国西部省区,如新疆、西藏、青海、甘肃、宁夏、内蒙古等SPI值明显偏小,为发展基于可预报性的暴雨预报检验评分奠定了较好的基础。
针对中国暴雨可预报性时空差异大,暴雨预报TS评分存在比较严重的双重惩罚现象,与预报员暴雨预报评分期望值存在明显差异的问题,构建一种暴雨预报检验评分新方法,并对2015-2016年4-9月中央气象台降水格点预报资料和预报员降水落区等级预报进行评分试验,分析结果的合理性和业务可行性,以期解决目前双重惩罚引起的二分类暴雨预报评分过低、导致公众对预报员暴雨预报能力存在认识误区等问题。
2 预报、观测及暴雨可预报性资料简介暴雨预报资料为2015-2016年4-9月中央气象台5 km×5 km水平分辨率的逐日定量降水格点预报产品和同期的中央气象台定量降水落区等级预报产品,预报时效为36 h。暴雨可预报性资料为同期逐日格点资料,水平分辨率为5 km×5 km(陈静等,2019)。预报检验站点为国家级地面自动气象观测站和遴选出的骨干区域自动气象站共11636个(图 2),采用双线性插值方法,将中央气象台5 km×5 km定量降水格点预报或者落区预报以及暴雨可预报性格点资料插值到这11636个站点,形成观测站降水预报和暴雨可预报性站点资料。检验所需的实况降水为中国44376个自动气象站降水观测资料。预报站点与观测站点的匹配方法将在3.3节详细介绍。

|
| 图 2 预报检验站点分布 Figure 2 The distribution of forecast verification stations |
利用e指数函数和暴雨可预报性综合指数SPI,构建e指数评分基函数和暴雨预报检验评分模型,优化改进预报员梯级递减评分值,下面详细介绍e指数评分基函数特征及暴雨预报评分模型构造方法。
3.1 基于e指数函数的暴雨预报评分基函数采用e指数函数构建暴雨预报评分基函数

|
(1) |
式中,Fx为预报降水量,Ox为观测降水量,σ2为指数常数(形态参数)。暴雨预报评分基函数是降水预报量、降水观测量、暴雨可预报性和指数常数的函数。图 3是SPI=1时预报暴雨量级(Fx=50 mm)、大暴雨量级(Fx=100 mm)和特大暴雨量级(Fx=250 mm)评分对形态参数σ的敏感性结果,指数常数σ对预报评分起着衰减调节的作用,σ值越小,衰减率越大,即预报与实况量级相差很大时,评分迅速衰减;σ值越大,衰减率越小,即预报与实况量级相差很大时,评分相差也不会很大。评分基函数尾端评分值对σ很敏感,σ值越大,尾端曲线越长。可见,引入e指数函数后,暴雨评分不连续性获得较好的改善,避免不同量级阈值处评分断崖式突变情况。

|
| 图 3 暴雨预报评分基函数对指数常数σ的敏感性试验 (a. Fx=50 mm, b. Fx=100 mm, c. Fx=250 mm) Figure 3 Sensitivity test of rainstorm forecast score basis function to exponential constant σ (a. Fx=50 mm, b. Fx=100 mm, c. Fx=250 mm) |
为了模型的评分曲线与图 1中预报员评分期望值尽量吻合,通过敏感性试验,确定了暴雨、大暴雨和特大暴雨预报评分基函数中的指数常数σ取值,得到如表 1的暴雨评分模型(Public-oriented Heavy Rainfall Forecast Score Table, 以下简称HRSwT)。从表 1可见评分模型是由评分基函数组成的4×4评分矩阵,包括了暴雨、大暴雨和特大暴雨量级预报评分。在矩阵对角线上,预报值与观测值量级相同,评分赋值为1.0;在矩阵对角线右上部分,属于过度预报型,评分基函数的变量是降水观测值和可预报性指标SPI,预报值Fx取暴雨分级下限值,指数常数σ为常数;在对角线左下半部分,观测值大于预报值,属于不足预报型,评分基函数的变量仍然是降水观测值和可预报性指标SPI,预报值Fx取暴雨分级上限值,指数常数σ为常数。矩阵第1列为暴雨漏报情况,即观测有暴雨而预报无,评分基函数变量是降水预报值和可预报性指标,而观测值为漏报暴雨等级的下限值,指数常数σ取为常数。可见,该模型既保持预报员暴雨预报评分心理预期值,又在各量级阈值处具有连续性,并通过暴雨的可预报性SPI增加不同气候区域暴雨预报评分的可比性。
| 预报Fx(mm) | |||||
| 10—49.9 | 50—99.9 | 100—249.9 | ≥250 | ||
| 实况Ox(mm) | 10—49.9 | S(Ox, P)|Fx=50, σ=25 | S(Ox, P)|Fx=100, σ=50 | S(Ox, P)|Fx=250, σ=150 | |
| 50—99.9 | S(Fx, P)|Ox=50, σ=25 | 1.0 | S(Ox, P)|Fx=100, σ=50 | S(Ox, P)|Fx=250, σ=150 | |
| 100—249.9 | S(Fx, P)|Ox=100, σ=50 | S(Ox, P)|Fx=100, σ=150 | 1.0 | S(Ox, P)|Fx=250, σ=150 | |
| ≥250 | S(Fx, P)|Ox=250, σ=150 | S(Ox, P)|Fx=100, σ=150 | S(Ox, P)|Fx=250, σ=150 | 1.0 | |
图 4是在可预报性SPI值为1.0、0.7和0.3三种情况下评分模型计算的暴雨(Fx=50 mm)、大暴雨(Fx=100 mm)和特大暴雨(Fx=250 mm)评分曲线。可见可预报性指标P对预报评分曲线S起着调节作用,P值越小,评分值越大;反之,P值越大,评分值越小。当P取值为0.7时,暴雨、大暴雨和特大暴雨评分与预报员预期值最为接近。

|
| 图 4 暴雨评分函数对可预报性指数P的敏感性试验 (a. Fx=50 mm, b. Fx=100 mm, c. Fx=250 mm) Figure 4 Sensitivity test of rainstorm scoring function to predictability index P (a. Fx=50 mm, b. Fx=100 mm, c. Fx=250 mm) |
预报值和观测值的匹配是预报检验方法中的重要环节。由于暴雨定时、定点、定量预报能力仍然有限,对公众而言,暴雨预报中存在一些时间、地点和量级上的误差是可以容忍的。例如,某地气象站预报了暴雨,实况出现49.9 mm时,传统TS评分为0,意味着预报完全错误,但是对于社会公众来说,实况出现49.9和50.0 mm几乎没有任何区别。再如,若预报北京天安门有暴雨,但实况是天安门降水为25.0 mm,而距离天安门5 km左右的海淀区白石桥发生了50 mm暴雨,在公众层面可能会认为预报基本正确,而传统暴雨TS评分为0。所以,Cherubini等(2002)提出的格点化邻域降水匹配方法更加合适。下面介绍本文预报检验点与观测点的匹配方法。
根据预报检验点与观测站点的邻域匹配(图 5),设某检验站降水预报值为Fx,定义Ox是一组以Fx点为中心,径向扩大30 km半径范围后的站点集合{O1, O2, …, ON},匹配站点数为ON,即预报Fx与ON个地面观测站降水实况进行匹配。由第2部分介绍可知,由于中国面积广大,观测站分布疏密不均,所以每个预报检验站的观测降水匹配站点数是不相等的,图 6是11636个预报检验站与44376个观测匹配站点空间分布和累计站数频数分布。由图 6a可见,观测匹配站个数从东到西、从南到北呈减少趋势,预报与观测匹配数最少为1个,位于青藏高原,最多超过100个,主要位于观测站密集的东部地区。总体而言,东部多于西部地区,南方多于东北。如北京,在30 km范围内可以匹配的站点数超过60个,而西藏拉萨不到20个。从图 6b可见,多数预报检验站点所匹配的观测站频数大都为20-40个。每一个预报检验站与每个匹配观测点均可计算预报评分值,由此每一个预报检验站可对应一组评分值集合。

|
| 图 5 预报检验点与观测站点的邻域匹配 Figure 5 Schematic diagram of neighborhood matching of forecast verification stations with observation stations |

|
| 图 6 预报检验匹配站点空间分布(a)和匹配站数累计频数分布(b) Figure 6 Spatial distribution of the matching station numbers of forecast verification stations (a) and frequency distribution of cumulative station numbers (b) |
由于一个预报值对应一组评分值集合,而预报员实际只希望每个站仅有一个评分值,如评分值集合中的最大值、集合平均值或者中值等方法。为强化暴雨预报位置准确率,采用距离权重评分最大值统计方法确定检验站暴雨评分值。
首先,利用e指数函数计算预报点Fx与观测点O(i)的距离权重w(di)(式(2)),式中di为预报评分点Fx与匹配观测点O(i)的距离,实况站与预报站距离越近,距离权重越大(图 7)。
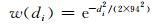
|
(2) |

|
| 图 7 距离权重系数随距离变化情况 Figure 7 Distance-weighted factor as a function of distance |
其次,利用式(2)对一组评分值进行距离权重订正,从订正后的评分值中挑选出最大值,如式(3),式中HRSw(Fx)为预报点Fx的暴雨预报评分值, N为邻域空间内参加评分的站点数。可见,距离权重系数可以避免单纯考虑评分高低而忽略预报与观测之间距离误差的影响。
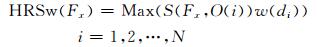
|
(3) |
假设检验日{tk, k=1, 2, …, T}, T为检验总日数,在第tk检验日有N个点有暴雨预报评分值,记为N(tk), 该组暴雨预报样本HRSw评分为
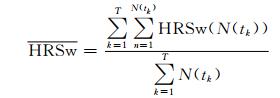
|
(4) |
利用第3部分介绍的暴雨评分模型评分计算和统计方法,分别采用暴雨可预报性综合指数月平均值和逐日值,在11636个预报检验站点上, 与44376个实况观测站点进行30 km的邻域法匹配,计算了2015和2016年中央气象台定量降水落区预报在中国31个省、市、自治区的TS评分和暴雨预报评分。图 8是两种可预报性综合指数计算的31个省、市、自治区和全国暴雨预报评分,可见,采用逐日可预报性方案和月平均的HRSw评分值总体相差不大,但前者评分值略高一些。如采用逐日可预报性综合指数的全国区域暴雨评分,2015和2016年分别为68.1%和65.2%,而采用月平均可预报性综合指数的全国区域暴雨评分,2015和2016年分别为67.2%和64.5%。此外还可以看到,2015年大部分省份HRSw值略高于2016年。从中国HRSw和TS暴雨预报评分值逐日演变对比(图 9)可见,HRSw评分与TS评分演变趋势较为一致,2015年两者相关系数为0.66,2016年为0.68,说明HRSw评分与TS评分在评估暴雨预报能力变化方面具有较好的一致性,但HRSw评分值明显大于TS评分值。究其原因,是由于新的HRSw评分不存在“双重惩罚”问题。图 10是2015和2016年暴雨TS评分与HRSw评分,可以看到,HRSw评分值可将TS=0的评分解析为0-40%,少数甚至可以解析到70%左右,HRSw的评分值明显高于TS评分。

|
| 图 8 2015年(a)和2016年(b)4-9月中央气象台24 h降水落区预报分省及中国区域的HRSw评分 Figure 8 HRSw scores of 24-hour heavy rainfall location forecast in China by the Central Meteorological Observatory from April to September in 2015 (a) and 2016 (b) |

|
| 图 9 2015年(a)和2016年(b)4-9月基于逐日可预报性的暴雨落区24 h预报HRSw评分和TS评分逐日演变 Figure 9 Daily HRSw scores based on daily SPI and TS scores of heavy rainfall location forecast in China from 1 April to 30 September of 2015 (a) and 2016 (b) |

|
| 图 10 基于2015-2016年逐日可预报性的暴雨落区24 h预报HRSw评分与TS评分 Figure 10 Scatter plot based on daily SPI and HRSw scores of heavy rainfall location forecast in China and TS scores from 2015 to 2016 |
图 11-13分别给出了暴雨预报TS=0时,HRSw评分值为0、39.4%、70.7%的3个暴雨个例预报与实况对比。2016年4月1日20时(北京时,下同)降水落区预报与观测的对比(图 11)可以看到,预报员落区预报在安徽和江西交界处有暴雨,而实况没有出现暴雨,预报失败,此时HRSw评分为0,符合实际预报情况;2016年9月25日20时降水落区预报与观测对比(图 12)可以看到,预报员落区预报有两个暴雨区,一个在四川和湖北交界处,另一个在安徽,而实况在四川与湖北交界处发生了大暴雨,而在安徽发生的是大雨,TS评分为0,而HRSw评分为39.4%,较TS评分更符合公众心理预期;图 13是TS评分为0,HRSw评分为70.7%的预报与观测降水对比,预报与实况对比与图 12类似,不再赘述。

|
| 图 11 2016年4月1日20时24 h降水落区预报(a)与观测(b) (预报评分TS=0.0,HRSw=0) Figure 11 Heavy rainfall location forecast (a) and observation (b) on 20:00 BT 1 April 2016 (forecast scores TS=0.0 and HRSw=0.0) |

|
| 图 12 2016年9月25日20时24 h降水落区预报(a)与观测(b) (预报评分TS=0.0,HRSw=39.4%) Figure 12 Heavy rainfall location forecast (a) and observation (b) on 20:00 BT 25 September 2016 (forecast scores TS=0.0 and HRSw=39.4%) |

|
| 图 13 2015年9月23日20时24 h降水落区预报(a)与观测(b) (预报评分TS=0.0,HRSw=70.7%) Figure 13 Heavy rainfall location forecast (a) and observation (b) on 20:00 BT 23 September 2015 (forecast scores TS=0.0 and HRSw=70.7%) |
此外,基于逐日可预报性SPI, 对2017年5月7-8日广州市暴雨和2017年6月23日北京市暴雨进行TS评分与HRSw暴雨评分试验,“5.7”广州特大暴雨TS评分为0,HRSw暴雨预报评分为3.22%,“6.23”北京区域性暴雨TS评分0.741,HRSw暴雨评分为98.7%,可以看出新的HRSw预报评分是合理的。
4.2 中央气象台格点降水预报暴雨评分利用前面介绍的暴雨评分模型评分计算和统计方法,采用逐日暴雨可预报性综合指数SPI值,在11636个预报检验站点上, 与44376个实况观测站点进行30 km的邻域法匹配,对2015-2016年7-10月中央气象台5 km×5 km精细化格点降水预报场计算TS评分和暴雨预报评分。评分结果与降水落区暴雨预报评分相似,大部分省2016年暴雨预报评分均高于2015年(图 14),全国区域的暴雨评分值2015年为73.63%,2016年为75.22%。图 15和16分别是暴雨预报评分与TS评分逐日演变和散点图,结果与中央气象台格点降水预报检验情况基本一致,不再赘述。



图 17给出了2017年4月1日至8月31日广州站和北京站可预报性综合指数、TS评分及HRSw评分。由图 17a可见,2017年4月1日至8月31日, 广州发生暴雨5次,暴雨评分8次,其中TS评分为0的有6次,对应的HRSw评分,1次同样为0,2次为20%-30%, 1次为50%左右,2次大于80%。由图 17b可见,2017年4月1日至8月31日, 北京发生暴雨3次,暴雨评分3次,其中TS评分为0的有1次,对应的HRSw评分则为60%左右。表明HRSw评分可以更好地解析TS评分为0的预报,更接近预报员预期值。

|
| 图 17 2017年4—8月广州站(a)和北京站(b)可预报性综合指数(黑色实线)、TS评分(黄点)及HRSw(实心三角形)评分(红色点代表观测站点发生暴雨) Figure 17 Time series of daily SPI (black solid line), TS (yellow dot) and HRSw (filled triangular) for Guangzhou (a) and Beijing (b) from 1 April to 31 August 2017 |
上述研究发现,HRSw和TS评分在数值上的差异,主要来源于两方面:(1)预报与观测资料的匹配方法差异;(2)在跨暴雨量级处的评分差异。对此,利用最新的2017年预报员24 h累计降水5 km精细化格点预报、4万多站点观测资料,对新评分方法HRSw进行了独立的验证试验。都采用邻域匹配法,在11636个预报检验站点上, 与44376个实况观测站点进行30 km邻域匹配,分别计算新TS(new)和HRSw,并按照传统点对点匹配方案计算旧TS(old),以查看消除资料匹配方法差异后的纯评分方法差异,考察导致旧TS评分偏低的成因中,预报、观测的相对位置偏离和评分评定中跨暴雨量级处断崖式下降两者所占比重。
图 18是基于逐日可预报性的2017年7-9月中央气象台24 h降水格点预报中国区域HRSw、旧TS、新TS逐日演变及分省评分值。新的2017年独立试验结果显示了新评分HRSw明显高于旧TS评分。同时较高数值的新TS评分表明,邻域匹配方法较大幅度提高了传统TS评分,这是因为邻域匹配法大幅度改善了“空报”和“漏报”,即预报、观测错位导致的双重惩罚。但传统TS评分的跨暴雨量级处的断崖式处理,还是使新TS评分明显低于HRSw评分,这说明新评分HRSw对跨量级处评分的缓慢变化处理,确实明显改善整体评分。

|
| 图 18 基于逐日可预报性的2017年7—9月中央气象台24 h降水格点预报中国区域HRSw、旧TS、新TS逐日演变(a)及分省评分值(b) Figure 18 Daily HRSw, TS (old) and TS (new) scores of (a) 24-hour quantitative gridded precipitation forecast of Central Meteorological Observatory over the entire China and (b) forecasts from individual provinces based on daily SPI from 1 July to 30 September 2017 |
针对当前暴雨预报检验采用二分类事件检验方法存在的双重惩罚使评分过低,没有考虑中国暴雨可预报性及时空分布不均,不便于对比分析不同区域暴雨预报能力等问题,基于中国区域暴雨可预报性综合评估指标,设计了一种基于可预报性的暴雨预报检验评分模型,介绍了方法的原理和构造,分析了理想评分,并利用所设计的新方法,对2015-2016年4-9月中央气象台逐日5 km×5 km水平分辨率的定量降水格点预报产品和中央气象台定量降水落区等级预报产品进行了暴雨预报评分试验,并与传统的TS评分进行对比,获得了以下结果和结论:
(1) 分析了预报员对暴雨预报评分期望值与传统的TS评分之间的显著差异,评分期望值呈现梯级下降特征,设计了一种基于可预报性的暴雨预报检验新方法。通过引入e指数函数,依据参数试验确定了暴雨、大暴雨和特大暴雨预报评分基函数中的指数常数σ取值,构建了暴雨评分模型。该模型可以较好地拟合预报员对暴雨预报评分的期望值,同时暴雨评分连续性获得较好的改善,避免不同量级阈值处的评分断崖式突变情况。
(2) 提出了预报与观测匹配的邻域匹配方法。预报与观测的匹配不再是传统检验方法中的点对点匹配,而是一个预报点匹配了一组观测集合,并利用距离权重评分最大值方法确定暴雨评分值,强化预报点与观测点距离对评分值的影响,实况站点离预报检验站点越近,距离权重系数越大,匹配站评分相应提高,提高了评分的合理性,避免了距离较远匹配站的高得分不利于提高预报位置精度的问题。
(3) 对中央气象台逐日5 km×5 km水平分辨率的定量降水格点预报产品和中央气象台定量降水落区等级预报产品进行了评分试验。暴雨预报准确率全国平均值为60%,其逐日演变特征与TS评分相似,而且将很多TS为0的暴雨预报个例评定为具有一定的预报评分,与预报员和公众的心理预期更加吻合。
需要指出的是,文中仅利用2008-2016年的5 km×5 km分辨率降水格点分析资料获得了定量化的暴雨可预报性综合指标。由于资料年代较短,暴雨气候频率和面积比率结果存在一定抽样不确定性,如4月在辽宁东南部存在可预报性大值中心,需要更多资料进行验证。从业务实施角度来看,采用逐日暴雨面积比率作为暴雨可预报性指标更为快捷方便。
致谢: 感谢中国气象局预报与网络司大力支持,感谢中国气象科学研究院孙继松研究员指导,感谢中国国家气象中心和数值预报中心支持。感谢北京市气象台、浙江省气象台、上海市气象台、广东省气象台、安徽省气象台、湖北省气象台等单位测试。| 陈法敬, 陈静. 2015. "SEEPS"降水预报检验评分方法在我国降水预报中的应用试验. 气象科技进展, 5(5): 6–13. Chen F J, Chen J. 2015. The application experiment of a new score for precipitation verification based on the SEEPS principle. Adv Meteor Sci Technol, 5(5): 6–13. (in Chinese) |
| 陈静, 刘凑华, 陈法敬, 等. 2019. 一种基于可预报性的暴雨预报评分新方法Ⅰ:中国暴雨可预报性综合指数. 气象学报, 77(1): 15–27. Chen J, Liu C H, Chen F J, et al. 2019. A new verification method for heavy rainfall forecast based on predictability I:Synthetic predictability index of heavy rainfall in China. Acta Meteor Sinica, 77(1): 15–27. (in Chinese) |
| 矫梅燕. 2010. 现代数值预报业务. 北京: 气象出版社: 162-176. Jiao M Y. 2010. Modern Numerical Weather Prediction. Beijing: China Meteorological Press: 162-176. (in Chinese) |
| Jolliffe I T, Stephenson D B. 2016.预报检验--大气科学从业者指南.李应林, 译.北京: 气象出版社, 1-10. |
| Jolliffe I T, Stephenson D B. Forecast Verification: A Practitioner's Guide in Atmospheric Science. Li Y L, trans. Beijing: China Meteorological Press, 1-10 (in Chinese) |
| 唐文苑, 周庆亮, 刘鑫华, 等. 2017. 国家级强对流天气分类预报检验分析. 气象, 43(1): 67–76. Tang W Y, Zhou Q L, Liu X H, et al. 2017. Analysis on verification of national severe convective weather categorical forecasts. Meteor Mon, 43(1): 67–76. (in Chinese) |
| 陶诗言. 1980. 中国之暴雨. 北京: 科学出版社: 1-10. Tao S Y. 1980. Heavy Rainstorm in China. Beijing: Science Press: 1-10. (in Chinese) |
| 王雨, 公颖, 陈法敬, 等. 2013. 区域业务模式6 h降水预报检验方案比较. 应用气象学报, 24(2): 171–178. Wang Y, Gong Y, Chen F J, et al. 2013. Comparison of two verification methods for 6 h precipitation forecasts of regional models. J Appl Meteor Sci, 24(2): 171–178. DOI:10.3969/j.issn.1001-7313.2013.02.005 (in Chinese) |
| 中国科学院大气物理研究所. 1998. 东亚季风和中国暴雨--庆贺陶诗言院士八十华诞. 北京: 气象出版社. Institute of Atmospheric Physics, Chinese Academy of Science. 1998. East Asian Monsoon and Chinese Rainstorm:Celebrating the Eighty Birthday of Tao Shiyan. Beijing: China Meteorological Press. (in Chinese) |
| Casati B, Wilson L J, Stephenson D B, et al. 2008. Forecast verification:Current status and future directions. Meteor Appl, 15(1): 3–18. |
| Cherubini T, Ghelli A, Lalaurette F. 2002. Verification of precipitation forecasts over the Alpine region using a high-density observing network. Wea Forecasting, 17(2): 238–249. DOI:10.1175/1520-0434(2002)017<0238:VOPFOT>2.0.CO;2 |
| Stephenson D B, Casati B, Ferro C A T, et al. 2008. The extreme dependency score:A non-vanishing measure for forecasts of rare events. Meteor Appl, 15(1): 41–50. |
| WMO. 2009. Recommendations for the verification and intercomparison of QPFs and PQPFs from operational NWP Models, revision 2 (WMO TD No. 1485). https://www.wmo.int/pages/prog/arep/wwrp/new/documents/WWRP2009_1.pdf, 2008.10 |
| WMO. 2015. Standardized Verification of deterministic NWP Products. http://www.wmo.int/pages/prog/www/DPS/Manual/Table-of-content_Manual-gdpfs.html, 2015.05.12 |