 2017, Vol. 75
2017, Vol. 75中国气象学会主办。
文章信息
- 熊敏诠. 2017.
- XIONG Minquan. 2017.
- 基于集合预报系统的日最高和最低气温预报
- Calibrating daily 2 m maximum and minimum air temperature forecasts in the ensemble prediction system
- 气象学报, 75(2): 211-222.
- Acta Meteorologica Sinica, 75(2): 211-222.
- http://dx.doi.org/10.11676/qxxb2017.023
-
文章历史
- 2016-08-25 收稿
- 2016-12-26 改回



不确定性是天气预报的特征,集合预报是对不确定性进行描述的概率预报系统。集合后处理技术关注点是如何提高集合概率预报,有直方图法 (Hamill,et al, 1997, 1998)、集合映射 (Roulston,et al,2003)、贝叶斯模型平均法 (Raftery,et al,2005)、逻辑回归 (Hamill,et al,2004)、非奇次高斯回归 (Gneiting,et al,2005)、相似法 (Hamill,et al,2006)、“预报同化”法 (Stephenson,et al,2005) 等。近些年有较多的深入研究和发展,例如:Wilks等 (2007)对比3种不同的后处理技术在集合气温和降水概率预报中的优劣,得到训练样本长度和预报技巧有密切关系。Schmeits等 (2010)根据ECMWF的20 a总降水量集合再预报数据集,对比分析了EPS原始预报、修正的BMA和扩展逻辑方法在降水概率预报上的优劣。Roulin等 (2012)使用扩展的逻辑回归提高EPS降水概率预报。Mendoza等 (2015)使用不同的统计后处理技术,结合高分辨率的区域气候模式,实现降尺度的日降水概率预报。
在多模式集合、集成技术领域,中国学者有多方面进展,例如:陈超辉等 (2010)开展了有限区域模式的多模式短期超级集合预报研究。王敏等 (2012)基于集合2 m气温预报,对比了非均匀高斯回归方法与自适应卡尔曼滤波偏差订正方法订正效果。刘琳等 (2013)基于T213集合预报极端降水天气预报指数,对中国极端强降水天气进行预报试验和分析。刘建国等 (2013)根据全球多模式集合预报 (TIGGE) 资料,进行地面日均气温贝叶斯模型平均概率预报及其检验与评估。刘永和等 (2013)对TIGGE资料在沂沭河流域6 h降水集合预报能力做了分析。杜钧等 (2014)揭示了“集合异常预报法”和集合预报在极端高影响天气预报中的优越性。马旭林等 (2015)利用日本气象厅区域集合预报的850 hPa气温资料,分析了基于卡尔曼滤波递减平均法的集合预报综合偏差订正。
由于次网格的不确定性影响,集合预报系统对近地面气象要素预报可靠性不如高层大气要素,如何提高近地面的气温和降水概率预报是统计后处理技术发展的主要方向。另外,确定性预报也有着巨大需求,特别是在短期预报中,人们总是根据确定性预报做出决策,集合预报提供了未来天气演变的多种可能性,通过适当的方法提炼出确定性信息也需要深入研究。针对近地面日最高 (低) 气温预报,根据集合预报系统的统计特征量,提出了BP-SM方法,明显提高了预报准确率。
2 资料和方法 2.1 资料根据2015年12月1日至2016年3月31日08时 (北京时,下同) 的欧洲中心集合预报产品,预报时效为0到240 h都是6 h间隔输出,共51个预报成员,可得到集合平均、最低、最高、中数、众数、离散度共7个统计量。以集合预报系统6 h间隔的2 m气温的集合统计特征量,每天4个时次的高 (低) 值作为日最高 (低) 值,并为预报模型输入量。在集合统计量得到的诸多日最高 (低) 值中,由集合平均得到的日最高 (低) 气温通常有较高的精度,当对集合预报系统进行评价时,就以此作为日最高 (低) 气温的DMO (模式直接输出);针对中国512个台站 (图 1),在2016年3月1日至3月31日08时,逐日进行日最高 (低) 气温多个时效的预报。

|
| 图 1 512个测站的分布 Figure 1 Geographic distribution of 512 stations in China |
BP (Back-Propagaion) 网络是人工神经网络的重要组成部分,广泛应用于诸多领域,其由3个环节构成,一是正向传播:信号从输入层经隐层到输出层;二为反向传播:预测误差从输出层,经原来的通道到达输入层;三是迭代过程:设立误差目标,当正向传播未达到目标值,通过反向传播,调整网络权值和阈值,反复迭代直至达到目标值。本研究使用集合预报的7个统计量作为输入层的7个节点,由Kolmogorov定理,隐层节点数设为15,输出层是1个节点,即预测和实际观测之差。构成3层网络进行日最高 (低) 气温预报,以预测误差 (观测值减DMO) 为目标值,出于实用考虑,迭代过程均为1000步,同时,网络学习过程采用经典的动量梯度法,步长为0.05。
泛化性是BP网络好坏的关键,一方面是BP算法本身固有缺陷造成的,网络训练过程中较易陷入局部极小而“难以自拔”,影响到网络性能;相关参数选取缺乏理论指导等。另一方面来自于问题的复杂性,首先是训练样本和独立 (预报) 样本差异,本研究使用的滚动建模中70个训练样本距离预报日最近的也要提前1 d,当作120 h预报时,相差就达到了5 d,3月中国气温变化剧烈,在某些时段某个地区容易出现偏高 (低) 气温,那么,偏高 (低) 的输入量就易出现偏高 (低) 的输出,即异常值;同时,训练样本变化易致网络权值变动,对于动态建模而言,每天都有最新的样本增加,得到的训练结果会有差异,当新样本数值上出现较大差异时,网络的权值变动也大,表现为BP网络对历史样本“记忆”功能缺失及网络稳定性变化。由此,提出BP神经网络-自忆 (简称BP-SM) 建模方法。
自相关函数是描绘时间序列过去对未来的影响,EPS预报误差时序普遍有一阶或二阶记忆特征。如开展上海南汇 (58369)2016年3月1日08时24 h预报,以2015年12月21日至2016年2月29日08时的24 h集合平均日最高气温预报为训练样本,得到预报偏低 (共有66 d) 和偏高 (4 d) 两个序列,预报偏低的误差序列自相关函数 (图 2) 表明上一期会影响到下一期,当时滞大于3时,自相关函数位于两倍标准误差带中,为单边衰减、二阶截尾。可使用自回归动态建模,通过历史数据对未来进行预测:

|
| 图 2 2015年12月21日至2016年2月29日08时上海南汇 (58369) DMO日最高气温24 h预报偏低的误差序列自相关函数 Figure 2 Autocorrelation function of error series for DMO underestimated daily 2 m maximum air temperature forecasts over Nanhui of Shanghai during the period of 21 Dec 2015-29 Feb 2016 at 08:00 BT |
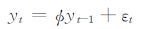
|
(1) |
式中,yt是预报误差;ø为自回归系数,即yt记忆能力的强弱;yt-1是一阶滞后的预报误差;εt为现期;{εt}t=-∞∞满足E(εt)=0、E(εt2)=σ2、E(εtεt′)=0(t≠t′) 的白噪声过程,序列y0、y1、y2……yt-1、yt都以式 (1) 相类似的表达,使用递归替代法,yt可写成初始值yt-1和ε在第0期到第t期的历史值的函数:
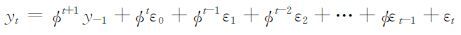
|
(2) |
由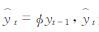
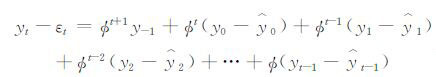
|
(3) |
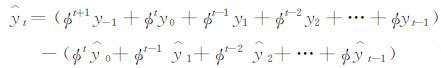
|
(4) |
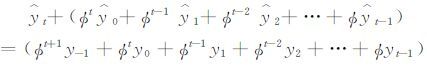
|
(5) |
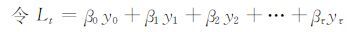
|
(6) |
式中,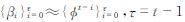
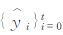
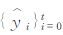
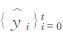
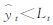
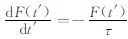
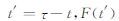
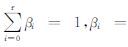
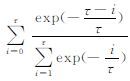
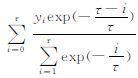
采用滚动建模方法进行实时训练和预报,例如:当要做2016年3月1日08时的24 h预报,就以2015年12月26日至2016年2月27日集合产品为训练样本建模,而2016年3月1日08时的120 h预报,其训练样本则是2015年12月21日至2016年2月22日的资料,依此类推。模型就可以反映出数值模式最近的误差特点,有助于提高预报精度。
预报评价方面,日常业务中使用预报绝对误差、准确率和技巧评分,具体如下:最高 (低) 气温预报平均绝对误差: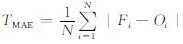
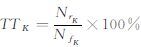
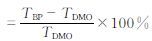
通过BP-SM方法得到的预报绝对误差小于相应的BP方法,称为“正效应”;反之,为“负效应”;若BP预测值位于期望区内,则两者一致 (重合);将“正效应”中的各单站预报绝对误差降低值求和、再取平均,即得“正效应”产生的预报误差减少值;同理,有“负效应”站点的预报绝对误差增加值的均值为“负效应”增加的误差值,由此,可以直观地分析两种方法预报的优劣。在512个台站1至10 d的日最高气温预测中,有如下特点 (图 3a):首先,对于中长时效 (3至10 d),BP-SM法有一定优势,例如第10天的预报,“正效应”绝对误差降低值2.41℃,而“负效应”引起的增加值是1.71℃,两者数值相差较大,对应是预报准确率的明显提高;其次,随着时效的延长,“负效应”预报次数逐渐下降,而“正效应”次数总体均衡或略有增长,如第1天“正 (负) 效应”次数是2688(3091),第10天是3814(1064);最后,BP算法并不是十分完善的神经网络,“正效应”和“重合”次数大致是3000:10000,占有相当比例,既便是在较高的“重合”次数中还有异常值,表明BP-SM方法的积极意义和深入分析之价值。

|
| 图 3 2016年3月DMO、BP和BP-SM方法的日最高气温预报比较 (a.1至10 d的BP-SM方法“正 (负) 效应”预报次数和误差增减值; b.上海南汇24 h预报误差的逐日比较 (主图),1—5 d的预报误差和绝对误差月均值比较 (子图); c.拉萨市24 h预报误差的逐日比较 (主图),1—5 d的预报误差和绝对误差月均值比较 (子图)) Figure 3 Comparisons of DMO, BP and BP-SM for monthly mean daily 2 m maximum air temperature forecasts during the period of 1-31 Mar 2016, (a) frequency, increment and decrement to forecast errors of positive and negative effects for BP-SM method over 10 d lead time; (b) comparisons (main diagram) of daily 24 h forecast errors over Nanhui of Shanghai, and monthly mean of daily 2 m minimum air temperature forecast errors and absolute errors (subgraph) over 5 d lead time; (c) comparisons (main diagram) of daily 24 h forecast errors over Lhasa and monthly mean of daily 2 m minimum air temperature forecast errors and absolute errors (subgraph) over 5 d lead time) |
上海南汇日最高气温24 h预报误差逐曰变化曲线 (图 3b主图):DMO误差起伏大,最大值8.97℃(5日),最小值-0.470℃(6日),预报值大多低于实况;BP方法只在头几天有较高的预报精度,但中下旬误差曲线走势完全不同于DMO,而且预报值明显比实况高;BP-SM的误差曲线和DMO的线型走势相近,特别是在中下旬,有力地修正了原始BP预报误差曲线,较大幅度地降低了误差,主要原因是BP-SM考虑了EPS预报误差的历史信息。5个不同时效的误差月均值:DMO (BP-SM、BP) 分别是:2.833℃(0.637℃、-1.648℃)、2.965℃(0.666℃、-1.464℃)、2.838℃(0.483℃、-1.656℃)、2.580℃(0.293℃、-2.005℃)、2.155℃(-0.360℃、-2.198℃)。平均绝对误差 (简称“MAE”,下同) 月均值:2.863℃(1.589℃、1.935℃)、2.987℃(1.656℃、2.06℃)、2.909℃(1.632℃、2.057℃)、2.670℃(1.627℃、2.287℃)、2.554℃(1.796℃、2.624℃)。BP-SM的误差在所有5个时效中是最小的,尤其是显著降低了误差 (图 3b子图);在较长时效 (第4天和第5天) 预报中,BP-SM方法的有效性增强。
在日常天气预报业务中,BP-SM方法的使用分两步进行,以上海南汇站为例,在2016年3月30日08时,进行日最高气温的24 h预报,下文较详细地介绍了预报过程。第1步 (历史资料的BP建模和SM方法计算):选择2016年1月19日至2016年3月29日08时的日最高气温24 h预报,共计70 d资料作为训练样本集,每天的日最高气温7个预报统计量作为BP方法的输入值,而BP网络的目标值是DMO误差,完成BP网络的构建;根据DMO误差正、负值划分成预报“偏低”和“偏高”两个序列,“偏低”序列有67 d,只有3 d属于预报“偏高”,使用式 (6) 可分别得到两个边界值-0.32和2.27℃。第2步 (实时预报):将当天7个日最高气温24 h预报的统计量输入到已建好的模型中,2016年3月30日08时EPS在上海南汇的7个预报统计量依次是:16.27、16.41、18.15、15.1、16.12、15.8、0.67℃,经BP网络预报值是23.11℃;根据上一步SM方法求得的边界值加上DMO的24 h预报 (16.27℃),即有[15.95℃,18.54℃];BP法预报已经超出SM方法确定的边界,可判定BP网络输出属于异常值,就以邻近边界的18.54℃作为BP-SM方法最终预报。3月30日08时—31日08时上海南汇日最高气温观测值是18.7℃,那么,DMO (BP-SM、BP) 预报误差是2.43℃(0.16℃、-4.41℃),BP-SM法预报精度高。
拉萨 (55591) 日最高气温24 h预报误差逐日变化曲线 (图 3c主图):DMO误差曲线总体平稳,BP-SM和BP方法预报基本重合,只有3 d的预报有较大的差别,在1日、26日、28日的BP-SM (BP) 方法预报误差值对应是:0.053℃(-2.974℃)、-0.714℃(-3.299℃)、-2.655℃(-5.292℃),BP-SM法的预报值更接近于实况。5个不同时效的误差月均值:DMO (BP-SM、BP) 分别是:10.725℃(-1.476℃、-1.844℃)、10.928℃(-1.672℃、-2.003℃)、10.893℃(-1.790℃、-2.008℃)、10.904℃(-1.661℃、-2.096℃)、10.812℃(-1.047℃、-1.605℃)。MAE月均值:10.725℃(1.759℃、1.987℃)、10.928℃(2.034℃、2.083℃)、10.893℃(1.881℃、2.024℃)、10.904℃(2.204℃、2.455℃)、10.812℃(1.647℃、2.0312℃)。在1至5 d的预报中 (图 3c子图),BP-SM方法都有优势。
BP网络预测精度和数值模式预报能力密切相关。有较大误差的训练样本反馈在网络权值上,网络不稳定性增大,导致较大的输出偏差,表现为网络学习和记忆是不稳定的,有别于人类大脑记忆的稳定性,也是泛化性问题的反映;中长期 (2 d以上) 预报中,数值模式预报误差逐渐增大,BP-SM方法有较好的效果;对于短时 (1 d) 预报,BP方法预报有较高精度,需要更细致的分析,BP-SM方法才能达到预期。
3.2 绝对误差、准确率和技巧评分空间分布日最高气温未来5 d的预报,DMO的MAE≤2℃的站点位于:东北地区和华北平原大部分地区、长江中下游平原北部,但是,在青藏高原东部和南部,DMO的MAE超过了4℃,局部地区超过16℃。BP-SM方法得到的误差分布上,MAE≤2℃的站点数在DMO相对应的区域都有所扩大,并且新增了青藏高原中部、内蒙古高原、黄土高原、四川盆地和云南的部分地区,中国的大部分地区的误差都小于4℃,较之DMO,有明显的提高。从技巧评分来看 (图 4a—e),对青藏高原上站点气温预报提高显著,一般超过60%的正技巧,局部超过80%;其他大部分地区也有较高的正技巧;只有在东北北部、内蒙古中部、华北平原西南部和华南西部的部分地区,呈现负技巧,数值大致在0至-20%,随着预报时效的延长,负技巧面积向东略有扩大。负技巧区出现在DMO预报准确率比较高的地区:负技巧站点的DMO绝对误差≤2℃准确率基本在70%以上,而在华北平原及其以北地区的相应站点DMO准确率大多超过80%,部分达到90%,反映了当模式预报有较高准确率、预报偏差微弱时,通过BP-SM方法达到更高的准确率还需要深入的研究。

|
| 图 4 2016年3月BP-SM方法在1至5 d气温预报的月平均技巧评分 (a—e.最高气温, f—j.最低气温) Figure 4 Monthly mean skill-scores of temperature forecasts over China for the period of 1 Mar 2016-31 Mar 2016(a-e.daily 2 m maximum air temperature, f-j.daily 2 m minimum air temperature) |
最低气温预报MAE低于最高气温,在江南、华南地区DMO的5 d预报中MAE大都在2℃以内,准确率也在70%以上,在中国南方的部分地区超过了80%(日最高气温准确率高值区出现在长江以北的平原地区),青藏高原东部和南部的误差值也有所下降。BP-SM方法在中国大部分地区都小于2℃,既使在青藏高原也低于4℃,明显降低了DMO预报误差;不同时效都有较高的准确率,在中国中部和东部沿海的部分地区的预报准确率超过了80%。技巧评分方面 (图 4f—g),青藏高原东部超过了60%,负技巧评分也出现在原始DMO准确率较高的站点,主要位于中国南方、华北和西北的部分地区,但是负技巧分都较小 (0至-10%)。
从日最高 (低) 气温预报技巧空间分布来看,在青藏高原东部和南部都有较高的正技巧,BP-SM方法对日最高气温预报准确率提高能力好于日最低气温;负技巧评分站点有相对固定的“区域性”特点,随着预报时效的延长 (从1到5 d的预报),该区域逐渐向附近扩散、面积也增大;而且负技巧区通常出现在DMO准确率较高的站点。
3.3 不同误差范围准确率的变化特点预报技巧评分是根据所有预报绝对误差的总和计算的,没有考虑到预报误差的离散度,结果是某个较大的预报误差可能会导致整个预报评分大幅的变化;基于神经网络方法预报的过拟合现象是普遍存在的,个别时次的预报异常容易对评分产生负面影响,技巧评分就难以全面反映该方法预报的优劣;同时,日常实践中,预报异常值往往可以通过主、客观方式得到有效抑制,人们更为关心的是某个具体误差段的准确率;因此只是笼统地给出所有预报误差段的技巧评分难以全面反映方法的优劣,那么,以日常使用的准确率为基准,绘出了绝对误差≤2℃(1℃) 准确率不同变化方向的站点数比率。
图 5a显示了各个预报时效中,512个台站预报评分正负技巧站点数和分值。日最高气温中,BP-SM在1至5 d的预报正技巧比例 (站点数) 是86%(440)、82%(420)、77%(394)、74%(379)、68%(348),而相应的预报技巧分是38%、35%、33%、32%、30%。

|
| (a.日最高气温的正技巧比较, b.日最高气温的负技巧比较, c.日最低气温的正技巧比较, d.日最低气温的负技巧比较) 图 5 2016年3月DMO和BP-SM方法在不同误差范围的技巧评分比较 (a. positive skill-score of daily 2 m maximum air temperature forecasts, b. negative skill-score of daily 2 m maximum air temperature forecasts, c. positive skill-score of daily 2 m minimum air temperature forecasts, d. negative skill-score of daily 2 m minimum air temperature forecasts) Figure 5 The comparisons of skill-scores in different error ranges for DMO and BP-SM method during 1-31 Mar 2016 |
通过BP-SM方法得到的预报绝对误差≤1℃准确率呈现上升趋势的比例 (站点数) 有87%(445)、84%(430)、82%(420)、81%(415)、75%(384);对于绝对误差≤2℃准确率,也有相似的变化特点,图形上处于“绞合”状态。即在较小预报误差范围内,BP-SM方法优势凸出。负技巧评分而言 (图 5b),1至5 d站点比例依次是14%、18%、23%、26%、32%,平均分值是-11%、-12%、-12%、-13%、-14%;而绝对误差≤1℃准确率呈下降趋势的站点比例为14%、16%、18%、19%、26%。所以,在较小预报误差范围内,BP-SM方法优势凸出。
日最低气温的预报误差比较也有上述类似特点。BP-SM方法预报正技巧 (图 5c)1至5 d的站点比例为71%、67%、61%、64%、59%;绝对误差≤1℃准确率有提高的站点比例依次是73%、70%、68%、66%、63%;平均正技巧分值是27%、27%、28%、26%、26%。负技巧站点数则在29%—41%;准确率下降 (绝对误差≤1℃) 的站点数介于26%和37%;而负技巧得分大约为-11%。
综上所述,BP-SM方法在5 d的预报中正技巧站点数有较高的比例,分值也大多位于30%附近,日最高气温预报的提高幅度要略好于最低气温。对于绝对误差≤2℃(1℃),正技巧站点数占比和分值都要高于总体评价,同时,负技巧站点数也比较低,说明在人们较关注的预报误差范围,BP-SM方法表现更佳。结合实际气象工作者通行的预报准确率分析,BP-SM方法表现出了更优越的预报特性,说明了BP神经网络的泛化问题,BP-SM方法虽然能大幅减少由此引发的异常值,但是还不能完全排除,也由于BP网络的高度非线性,难以得到精确的数值解,所以就表现在DMO预报准确率比较高的部分站点出现负技巧现象。
3.4 系统偏差比较根据日最高气温的24 h预报资料。对预报系统偏差进行分析,加深对BP-SM方法的认识,有助于方法完善和逐步提高预报精度。
散点图 (图 6) 直观地展现了预报的系统偏差,在对称轴 (y=x) 附近 (图 6a),离散点呈发散、非对称性,图中使用不同颜色表示误差范围,由于DMO预报误差普遍较大,远距离的数值点显得较多;另外,数值点大多位于对称轴线的下方,即DMO预报“偏低”。BP-SM方法 (图 6b) 减小了系统性偏差,数值点在对称轴附近呈现收敛、对称性,远离对称轴的离散点较少,大多数集中于0—3℃,点的密度变得更紧凑、密集;数据点以对称轴为轴心呈“准对称”分布,DMO预报“偏低”现象得到有效校正。DMO在6个误差范围站次数 (图 6c) 依次是4070、3630、2590、1830、1290、2440,而BP-SM为6810、4660、2410、1080、488、397,误差在0—1℃、1—2℃范围的预报站次数增加明显,同时又大幅降低了>5℃误差站次。

|
| (a.DMO和实况, b.BP-SM和实况, c.DMO和BP-SM比较) 图 6 2016年3月日最高气温24 h预报-实况散点图和不同预报误差范围站次数对比 (a. DMO and Obs, b. BP-SM and OBs, c. DMO and BP-SM) Figure 6 Forecast-observation scatterplots and frequencies of different error ranges for daily 2 m maximum air temperature forecasts at 24 h lead time during 1-31 Mar 2016 |
在中国的预报误差空间分布上,中西部地区DMO预报能力较弱,以100°E为界,分析中国西部、东部地区预报误差变化特点。西部地区,尤其是青藏高原东部地区,大致是0—20℃(图 7a),实况和DMO差别悬殊,DMO预报偏低,个别站次的误差超过了20℃,而经过BP-SM方法再预报后,得到极大的改进。图 7a和b前后对比,表明在东部和西部,散点分布都变得更“收敛和对称”,BP-SM有效降低了数值模式预报的系统偏差。西部地区的DMO柱状图 (图 7c) 在6个误差范围中站次数分别是139、175、200、236、190、544,而改进后为562、392、255、145、76、54;DMO预报误差迥异于其他地区,其中误差大于5℃站次较多,改进后,预报精度提高十分明显,特别是在较大误差预报。东部地区 (图 7d) 有相似的特点。

|
| (a.DMO和实况, b.BP-SM和实况) DMO和BP-SM方法的日最高气温24 h预报在不同误差范围站次数对比 (c.100°E以西地区,d.100°E以东地区) 图 7 2016年3月100°E以西和以东地区日最高气温24 h预报-实况散点图 (a) DMO, (b) BP-SM. Frequency comparisons between DMO and BP-SM methods in various error ranges over different areas:(c) to the west of 100°E, (d) to the east of 100°E Figure 7 Forecast-observation scatterplots for daily 2 m maximum temperature forecasts at 24 h lead time over the west and east of 100°E in the during 1-31 Mar 2016: |
不同区域的DMO系统性偏差表现各异,可能是次网格不确定性、中国天气及地理复杂性密切相关,散点图呈发散、非对称性分布,将预报误差由小到大划分成6个区段,相应的预报站次数并非均匀地落在每个区段中,DMO预报次数随着误差增大而逐渐衰减,只是到了>5℃段有“翘尾”现象,因为文中将误差>5℃都统一划归到此段的缘故;而在西部地区DMO预报误差次数在6个区段的分布形态就比较奇特,可能是误差分段和集合预报在此区域的低准确率两方面原因引起的。BP-SM方法则将DMO误差各异分布都转换成一致的衰减形态,而且衰减率也明显增大。
4 结论和讨论(1) BP-SM和BP方法预报精度对比分析中:随着预报时效的延长,BP-SM方法优势也逐渐增大,“负效应”预报次数明显下降,表明BP-SM法能有效地减少BP网络预报异常值。上海南汇多个预报时效比较中:BP网络的不稳定性导致较大的预报误差;而BP-SM法避免了上述现象,在较长时效预报中,BP-SM法有更大的正向作用。通过上海南汇和拉萨两单站的DMO预报误差变化特点,可初步获悉EPS误差时空特点和BP网络预报准确度有密切关系。以上海南汇为例,较细致地介绍了BP-SM方法日常预报过程。
(2) BP-SM方法十分显著地提高了日最高 (低) 气温预报准确率,尤其是在青藏高原东部和南部地区。和DMO相比,BP-SM方法在大部分地区都有较高的正技巧,部分地区超过了60%,负技巧站点通常出现在DMO预报准确率较高的部分地区,技巧分值较小 (0—-20%)。
(3) 具体比较了绝对误差≤2℃(1℃) 准确率变化特点,在未来5 d预报中,BP-SM方法在此误差范围内的正技巧站点比例表现出更大的优势,同时,对日最高气温预报准确率的提高能力要略好于日最低气温。探讨了BP-SM方法出现负技巧预报的原因,说明BP-SM方法有较强的非线性映射能力,当面对函数逼近精度和模型容错性等问题时,还要与天气变化特点相联系,可能会达到更好的预报效果。
(4) 实况-预报散点图及在东、西部站点比较中,DMO呈现发散、非对称性分布特点,而BP-SM方法减小了系统性偏差,数值点也收敛、对称地分布。BP-SM方法也改变了DMO在6个误差区段分布形态的不一致性,使得误差越大区段站点数越少,分布结构呈快速衰减趋势。
传统的动力统计释用方法通常根据模式输出的动力因子进行建模预报,实践中如何获得最优预报子集往往是难点,也是预报质量优劣的关键;当面临集合预报海量的因子输出时,预报因子集选择将显得尤为困难;BP-SM方法直接使用集合气温预报统计特征值,避免了上述问题。日最高 (低) 气温是日常气象研究和业务服务的重要预报量,受到广泛的关注,基于集合预报系统而提出快速、准确建模和优化的BP-SM方法,可操作性强、实用性好、能在实践中发挥作用并将得到进一步完善。
| 陈超辉, 李崇银, 谭言科, 等. 2010. 基于交叉验证的多模式超级集合预报方法研究. 气象学报, 68(4): 464–476. Chen C H, Li C Y, Tan Y K, et al. 2010. Research of the multi-model super-ensemble prediction based on cross-validation. Acta Meteor Sinica, 68(4): 464–476. DOI:10.11898/1001-7313.20100410 (in Chinese) |
| 杜钧, GrummR H, 邓国. 2014. 预报异常极端高影响天气的"集合异常预报法":以北京2012年7月21日特大暴雨为例. 大气科学, 38(4): 685–699. Du J, Grumm R H, Deng G. 2014. Ensemble anomaly forecasting approach to predicting extreme weather demonstrated by extremely heavy rain event in Beijing. Chinese J Atmos Sci, 38(4): 685–699. DOI:10.3878/j.issn.1006-9895.2013.13218 (in Chinese) |
| 刘建国, 谢正辉, 赵琳娜, 等. 2013. 基于TIGGE多模式集合的24小时气温BMA概率预报. 大气科学, 37(1): 43–53. Liu J G, Xie Z H, Zhao L N, et al. 2013. BMA probabilistic forecasting for the 24-h TIGGE multi-model ensemble forecasts of surface air temperature. Chinese J Atmos Sci, 37(1): 43–53. DOI:10.3878/j.issn.1006-9895.2012.11232 (in Chinese) |
| 刘琳, 陈静, 程龙, 等. 2011. 基于集合预报的中国极端强降水预报方法研究. 气象学报, 71(5): 853–866. Liu L, Chen J, Cheng L. 2011. Study of the ensemble-based forecast of extremely heavy rainfalls in China: Experiments for July 2011 cases. Acta Meteor Sinica, 71(5): 853–866. (in Chinese) |
| 刘永和, 严中伟, 冯锦明, 等. 2013. 基于TIGGE资料的沂沭河流域6小时降水集合预报能力分析. 大气科学, 37(3): 539–551. Liu Y H, Yan Z W, Feng J M, et al. 2013. Predictability of 6-hour precipitation in the Yishu River basin based on TIGGE data. Chinese J Atmos Sci, 37(3): 539–551. DOI:10.3878/j.issn.1006-9895.2012.11078 (in Chinese) |
| 马旭林, 时洋, 和杰, 等. 2015. 基于卡尔曼滤波递减平均算法的集合预报综合偏差订正. 气象学报, 73(5): 952–964. Ma X L, Shi Y, He J, et al. 2015. The combined descending averaging bias correction based on the kalman filter for ensemble forecast. Acta Meteor Sinica, 73(5): 952–964. (in Chinese) |
| 王敏, 李晓莉, 范广洲, 等. 2012. 区域集合预报系统2 m温度预报的校准技术. 应用气象学报, 23(4): 395–401. Wang M, Li X L, Fan G Z, et al. 2012. Calibrating 2 m temperature forecast for the regional ensemble prediction system at NMC. J Appl Meteor Sci, 23(4): 395–401. DOI:10.11898/1001-7313.20120402 (in Chinese) |
| Gneiting T, Raftery A E, Westveld A H, et al. 2005. Calibrated probabilistic forecasting using ensemble model output statistics and minimum CRPS estimation. Mon Wea Rev, 133(5): 1098–1118. DOI:10.1175/MWR2904.1 |
| Hamill T M, Colucci S J. 1997. Verification of Eta-RSM short-range ensemble forecasts. Mon Wea Rev, 125(6): 1312–1327. DOI:10.1175/1520-0493(1997)125<1312:VOERSR>2.0.CO;2 |
| Hamill T M, Colucci S J. 1998. Evaluation of Eta-RSM ensemble probabilistic precipitation forecasts. Mon Wea Rev, 126(3): 711–724. DOI:10.1175/1520-0493(1998)126<0711:EOEREP>2.0.CO;2 |
| Hamill T M, Whitaker J S, Wei X. 2004. Ensemble reforecasting: Improving medium-range forecast skill using retrospective forecasts. Mon Wea Rev, 132(6): 1434–1447. DOI:10.1175/1520-0493(2004)132<1434:ERIMFS>2.0.CO;2 |
| Hamill T M, Whitaker J S, Mullen S L. 2006. Reforecasts: An important dataset for improving weather predictions. Bull Amer Meteor Soc, 87(1): 33–46. DOI:10.1175/BAMS-87-1-33 |
| Mendoza P A, Rajagopalan B, Clark M P, et al. 2015. Statistical postprocessing of high-resolution regional climate model output. Mon Wea Rev, 143(5): 1533–1553. DOI:10.1175/MWR-D-14-00159.1 |
| Raftery A E, Gneiting T, Balabdaoui F, et al. 2005. Using Bayesian model averaging to calibrate forecast ensembles. Mon Wea Rev, 133(5): 1155–1174. DOI:10.1175/MWR2906.1 |
| Roulin E, Vannitsem S. 2012. Postprocessing of ensemble precipitation predictions with extended logistic regression based on hindcasts. Mon Wea Rev, 140(3): 874–888. DOI:10.1175/MWR-D-11-00062.1 |
| Roulston M S, Smith L A. 2003. Combining dynamical and statistical ensembles. Tellus A, 55(1): 16–30. DOI:10.3402/tellusa.v55i1.12082 |
| Schmeits M J, Kok K J. 2010. A comparison between raw ensemble output, (modified) Bayesian model averaging, and extended logistic regression using ECMWF ensemble precipitation reforecasts. Mon Wea Rev, 138(11): 4199–4211. DOI:10.1175/2010MWR3285.1 |
| Stephenson D B, Coelho C A S, Doblas-Reyes F J, et al. 2005. Forecast assimilation: A unified framework for the combination of multi-model weather and climate predictions. Tellus A, 57(3): 253–264. DOI:10.3402/tellusa.v57i3.14664 |
| Wilks D S, Hamill T M. 2007. Comparison of ensemble-MOS methods using GFS reforecasts. Mon Wea Rev, 135(6): 2379–2390. DOI:10.1175/MWR3402.1 |