 2020, Vol. 38
2020, Vol. 38 



2. 南瑞集团有限公司(国网电力科学研究院有限公司), 南京 211106;
3. 北京科东电力控制系统有限责任公司, 北京 100192
2. NARI Group Corporation Co., Ltd. (State Grid Electric Power Research Institute Co., Ltd.), Nanjing 211106, China;
3. Beijing Kedong Power Control System Limited Liability Company, Beijing 100192, China
随着电网规模的不断扩大、电力市场化改革的持续推进和新能源的大规模接入,电力系统的结构和运行方式日益复杂。传统的调度自动化系统已经难以满足电网运行监控的需求,急需将自然语言处理、语音识别等新一代人工智能技术与电网调度控制工作的业务场景相结合,提升调度控制工作的智能化水平[1-4]。
电网调度领域语言专业性较强,建立调度领域语言模型,实现调度专业词汇的可计算性是提高语音识别准确率的关键。而词向量可以考虑词汇的语法和语义信息,并将其编码到低维向量空间中,是实现调度词汇可计算性的重要技术[5-6]。该技术可以把由离散符号表达的语言转换为计算机能够处理的由数值表达的向量,使得自然语言具有可计算性。词向量的生成依赖于特定的语料库,目前出现了很多公开中文词向量库,但是这些词向量库是基于公开的中文语料生成,没有涵盖电网调度领域专业语料,制约了自然语言处理、语音识别等人工智能技术在电网调度领域的发展应用。
针对语音识别技术在电网调度领域应用中识别准确率不高的问题,本文基于电网调度规程、年度运行方式、调度日志、事故预案等电网调度专业语料库,采用Word2vec技术完成调度专业领域词汇向量库的构建,实现调度专业领域词汇的可计算性,同时基于所生成的调度专业词向量建立了电网调度领域专有语言模型,并对内蒙古电力(集团)有限责任公司调控语料进行测试分析,以提高电网调度各类应用场景下语音识别的准确率。
1 语音识别技术在电网调度领域应用的关键语音识别技术作为成熟的人工智能技术,可以迁移到电网调度领域辅助现有的应用场景[9],从而提高人机交互的便捷性和工作效率。语音识别技术在电网调控领域应用整体架构如图 1所示。

|
图 1 语音识别技术在电网调控领域应用整体架构 |
语音识别模型主要由声学模型和语言模型2大功能模块组成[7-8]。声学模型从输入的语音信号(时域信号)中提取出可以进行建模的声学观测特征向量序列;语言模型根据声学模型输出的结果,给出概率最大的文字序列。为了生成正确的文字序列,语言模型要尽可能多地封装所考虑的任务的语法、语义和语义特征。
声学模型和语言模型是提升语音识别准确率的关键。目前,循环神经网络等深度学习技术大幅提升了声学模型的准确率。语言模型则依赖于训练语料,利用调度领域专业语料构建调度专业词向量库是训练语言模型的基础。
2 调度领域专业词汇词向量的生成 2.1 词向量的生成方法词向量是对词典中的任意词指定一个固定长度的实值向量v(W)∈ Rm,其中,v(W)为W的词向量,Rm为m维的实数向量空间。利用机器学习算法处理自然语言实现自动语音识别,首先要将自然语言进行词向量处理。词向量生成方法主要有One-Hot编码和向量空间模型[9]2种。
(1)One-Hot编码是用一个很长的向量表示1个词汇,向量的长度为词典D的大小N,向量的分量只有一个1,其他全部为0。1的位置对应该词汇在词典中的索引。这种词向量的表示方式易受到维度灾难的影响,不能很好地衡量词汇之间的相似性,后续采用机器学习特别是深度学习进行自然语言处理和语音识别时很难取得良好效果。
(2)向量空间模型是将词汇映射到连续向量空间中的点,其中语义相似的词汇被映射为距离相近的点。这种方式依赖于词汇的分布假设(出现在相同上下文中的词汇具有相似语义),此类方法是根据词汇的上下文信息,通过训练将词汇映射成固定长度为n的向量,其中n
最常用的基于向量空间模型的词向量生成方法是Word2vec和Glove[10]。其中,Word2vec是一种具有较高计算性能的预测方法,它是神经概率语言模型的简化,核心是神经网络方法,采用连续词袋模型(Continuous Bag-Of-Words,CBOW)和Skip-Gram模型[11]将词语映像到同一坐标系中,用于学习语料库中的词汇向量。CBOW和Skip-Gram均为3层神经网络结构(如图 2所示)。

|
图 2 CBOW模型架构和Skip-Gram模型架构 |
两个模型均为词汇的One-Hot编码输入输出,输入层到隐藏层的参数矩阵为WV × N、隐藏层到输出层的参数矩阵为UV × N,两个参数矩阵共同构成参数空间
CBOW模型之中,在已经得知上下文W(t - 2),W(t - 1),W(t + 1),W(t + 2))前提下,预测当前词向量W(t),学习的目标函数为最大化对数似然函数,见公式(1):
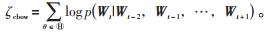
|
(1) |
Skip-Gram模型中,在已知当前词W(t)的前提下,预测其上下文W(t - 2),W(t - 1),W(t + 1),W(t + 2),目标函数见公式(2):

|
(2) |
Word2vec使用梯度上升法进行训练,为了提高训练性能,采用了Hierarchical Softmax和Negative Sampling两种求解策略[12]。
2.2 向量库的构建流程电网调度领域词汇词向量以调度历史语料为数据基础,采用Word2vec技术,考虑调度词汇在调度业务语境中的关系,建立调度领域词汇的词向量库。基本流程见图 3。

|
图 3 电网调度领域词向量库构建流程 |
(1)收集年度运行方式、调度规程、历史调度日志、事故预案等非结构化调度历史文档,形成调度历史语料库。
(2)对历史语料库进行数据预处理,主要包括中文分词、去除标点符号、去除停用词等一系列数据清洗和转换工作,形成调度领域初始词典。
(3)根据调度领域词汇在词典中出现的位置(索引)进行One-Hot编码,并根据词典编码将历史语料送入Word2vec模型进行训练,得到词向量,更新调度领域词典。
(4)经过训练将词汇转换为向量后,进行词向量评估,主要包括两种方式:一是采用词汇之间夹角余弦值来衡量词汇之间的相似程度,找到词汇之间的关联关系;二是通过词向量之间的计算进行简单的词汇逻辑关系推理,以衡量词向量的合理性。
3 算例分析 3.1 调控语料采用内蒙古电力(集团)有限责任公司调度控制中心调度运行管理系统中2010—2019年生成的调控领域相关语料,进行词向量训练。相关语料主要包括历年《电网运行方式》《电网调度规程》《电力通信系统管理规程》《电网生成事故调查规程》《继电保护和安全自动装置技术规程》等与内蒙古电网调度有关的非结构化文档,经过语料预处理后形成调度领域词典,以词典为基础对语料中的词汇进行One-Hot编码,并基于Word2vec训练调度词向量。
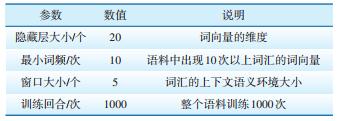
3.2 算法设置基于上述调控语料,采用Word2vec进行调度领域专业词汇词向量生成模型的训练,模型采用CBOW词,算法主要参数设置见表 1。模型训练完成后,将每个词汇的One-Hot编码送入模型,可以输出相应词汇的词向量,生成调度领域词向量词典。
| 表 1 算法参数设置 |
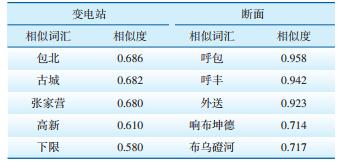
训练完成后形成调度领域专业词向量词典,基于该词典可以实现调度领域词汇之间的相似度计算、推理计算等。图 2 CBOW模型架构和Skip-Gram模型架构以“变电站”和“断面”两个词为例,采用夹角余弦相似性度量方法分别计算与其相似的前5个词汇,得到调度词汇之间的语义关系,结果见表 2。与“变电站”相似的词汇有“包北”“古城”“张家营”等;与“断面”相似的词汇有“呼包”“呼丰”等。在调度语料库中,“包北”“古城”“张家营”等属于“变电站”,这些词汇与“变电站”经常出现在相同的语义上下文中;“呼包”“呼丰”等属于“断面”,这些词汇与“断面”经常出现在相同的语义上下文中,因此具有相似的语义关系。
| 表 2 与“变电站”和“断面”2个词汇相似的前5个词汇 |
为了可视化展示不同调度词汇之间的相似性,采用t-TSNE降维算法进一步将20维词向量降至两维后以散点图的形式进行展示[13],见图 4。由图 4可见,语义相近的词汇在散点图中的位置相近。

|
图 4 部分调度领域词汇词向量的可视化展示 |
调度词向量生成之后,可以采用向量计算进行简单推理。例如:变电站-包北=断面-呼包,如图 5所示。如果前提给定“包北”属于“变电站”,通过推理可以得到“呼包”属于“断面”的结论。用符号来表达即“包北”:“变电站”::“呼包”:“断面”,其中“:”表示属于,“::”表示等于。

|
图 5 基于词向量的调度专业词汇推理 |
综上分析可知,采用Word2vec技术训练出的调度词汇语义向量,基本可以表达出调度专业词汇之间的语义关系。由于该技术受语料的影响较大,因此需要收集更多的历史调度语料,以使训练出的词汇向量能够更好地表达词汇之间的语义关系。
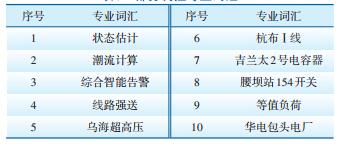
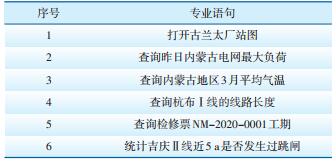
4 基于调度专业词向量的语音识别应用为了分析基于调度专业词向量建立的语音识别模型的性能,在内蒙古电力(集团)有限责任公司调控语料中分别抽取500个调控专业词汇和200条电力专业语句,对基于调度专业词向量语音识别方法与未基于调度专业词向量的语音识别方法进行比较分析。部分调控专业术语和语句如表 3和表 4所示。
| 表 3 部分调控专业词汇 |
| 表 4 部分调控专业语句 |
测试小组成员由5人(A—E)组成,每人分别采用两种语音识别方法对上述语料各测试3次,计算不同语音识别方法准确率的平均值。两种语音识别方法准确率对比见表 5。
| 表 5 两种语音识别方法准确率对比 |
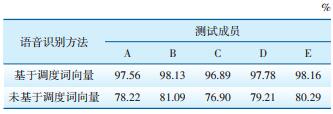
由表 5可知,基于Word2vec生成的调度专业词向量对提高语音识别准确率非常有效,可以将语音识别的准确率提高20%左右。而未基于调度专业词向量处理的语音识别方法难以识别大多数调控专业词汇,如设备名称、厂站名称、调度操作术语等,因此,计算调度专业词向量对构建面向调控应用场景的语音识别模型具有重要意义。
目前,语音识别模型已经在内蒙古电力(集团)有限责任公司电力调度控制分公司的智能调控机器人项目中应用,主要服务于倒闸操作、多轮对话等应用场景,大大提高了人机交互的友好性、便利性和智能性,为智能电网调控的实现奠定了基础。
5 结语近年来,以深度神经网络为主的机器学习算法在语音识别、自然语言处理、计算机视觉等诸多领域取得了重大进展,将人工智能技术与电网调度业务场景结合,能够大幅度提高调控人员的工作效率,保障电网的安全稳定运行。
本文采用Word2vec技术实现了调度词汇的向量化表达和调度词汇的可计算性,并基于内蒙古电网历史调控语料进行了分析验证,结果表明,按本文提出方法生成的调度词汇词向量能够很好地表达词汇在调度语境中的语义关系,基于生成的词向量建立的语音识别模型准确率较高,能够满足调度业务需求。
| [1] |
李明节, 陶洪铸, 许洪强, 等. 电网调控领域人工智能技术框架与应用展望[J]. 电网技术, 2020, 44(2): 393-400. |
| [2] |
范士雄, 李立新, 王松岩, 等. 人工智能技术在电网调控中的应用研究[J]. 电网技术, 2020, 44(2): 401-411. |
| [3] |
陶洪铸, 翟明玉, 许洪强, 等. 适应调控领域应用场景的人工智能平台体系架构及关键技术[J]. 电网技术, 2020, 44(2): 412-419. |
| [4] |
闪鑫, 陆晓, 翟明玉, 等. 人工智能应用于电网调控的关键技术分析[J]. 电力系统自动化, 2019, 43(1): 49-57. |
| [5] |
杨阳, 刘龙飞, 魏现辉, 等. 基于词向量的情感新词发现方法[J]. 山东大学学报(理学版), 2014(11): 51-58. |
| [6] |
Chen X, Xu L, Liu Z, et al. Joint learning of character and word embeddings[C]//Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires: AAAI Press, 2015: 1236-1242.
|
| [7] |
鄢发齐, 王春明, 窦建中, 等. 基于隐马尔可夫模型的电力调度语音识别研究[J]. 武汉大学学报(工学版), 2018, 51(10): 920-923. |
| [8] |
葛佳烨.基于深度学习的电网调度员双模态情绪识别研究[D].上海: 上海交通大学, 2019.
|
| [9] |
高阳.基于Word2Vec方法的情感分析研究及应用[D].厦门: 厦门大学, 2019.
|
| [10] |
Pawe Cichosz. A Case Study in Text Mining of Discussion Forum Posts:Classification with Bag of Words and Global Vectors[J]. International Journal of Applied Mathematics and Computer Science, 2018, 28(4): 787-801. DOI:10.2478/amcs-2018-0060 |
| [11] |
Zeyu Xiong, Qiangqiang Shen, Yueshan Xiong. New generation model of word vector representation based on CBOW or Skip-Gram[J]. Computers, Materials & Continua, 2019, 60(1): 259-273. |
| [12] |
Brendan T J, Douglas J K M, Michael N J. The role of negative information in distributional semantic learning[J/OL]. Cognitive Science, 2019, 43(5)[2020-09-22].https://onlinelibrary.wiley.com/doi/epdf/10.1111/cogs.12370.
|
| [13] |
魏世超, 李歆, 张宜弛, 等. 基于E-t-SNE的混合属性数据降维可视化方法[J]. 计算机工程与应用, 2020, 56(6): 66-72. |