 2019, Vol. 19
2019, Vol. 19


2. 中国农业大学 经济管理学院, 北京 100083
近年来,数量庞大的农业人口实现地域和职业转变,但其社会身份的重建与转换仍面临重大挑战。逻辑上,加快农民工融入城市进程,有助于增加劳动供给、扩大内需,释放新的人口红利。相反,若农民工仍存过客心理,他们将很难以主人翁的姿态为城市服务[1]。因此,助推农民工突破心理壁垒,适应社会角色转变,增强城市归属感与认同感,是当前以人为核心的新型城镇化战略的重要议题之一。社区是城市社会的基本单元,是农民工融入城市进程中的组织载体与空间场域。2011年,民政部发布文件明确提出要充分发挥社区功能,推动农民工融入城市生活。在此背景下,本文依托布迪厄的场域理论,致力于解析社区场域与农民工城市身份认同的逻辑关系。这项研究有助于我们重新审视社区在农民工融入城市中的作用,为政府部门制定社区相关政策提供依据,还能为有序推动农民工市民化提供借鉴与参考。
一、文献回顾 (一) 身份认同相关研究身份认同通常包含两重含义:一是身份,是个体在社会中的定位,是对我是谁的自我认知;二是认同,是对我和谁一样的自我认知[2]。相关的研究发端于哲学领域,随后传播至心理学领域,在被引入社会学领域后,得到了空前的广泛关注,并逐步成为社会学的重要研究范畴[3]。Akerlof和Kranton将身份认同引入经济学领域,并纳入了新古典经济学框架,还以此为基础提出了身份认同经济学[4]。国内关于身份认同的经济学研究也并不少见,李书娟和徐现祥考察了省级官员对家乡身份认同产生的经济效应[5],续继和黄娅娜则探讨了中国传统的“男主外,女主内”的性别认同观念对婚姻关系及劳动就业的影响[6]。
由于户籍制度这一特殊国情的存在,国内身份认同领域中关注农民工群体的研究相当丰富。研究的焦点主要集中在三个方面:一是农民工身份认同的现实状况。已有研究表明,作为中国户籍制度背景下特有的弱势群体,越来越多的农民工,尤其是新生代农民工面临着进退失据的身份认同困境,成为双重边缘人[7]。一方面,农民工从农村迁徙至城市,希望有朝一日扎根城市,但城市社会中的种种歧视与排斥,导致他们难以真正融入;另一方面,他们长期远离家乡故土,成员权利不断淡化,缺乏社会存在感。二是农民工城市身份认同的经济社会效应。已有研究表明,认同城市身份会对农民工的职业规划、发展定位等产生正向激励,还有助于增加农民工的劳动供给[8],改变农民工消费方式、增加文化娱乐等符号性消费[1]。三是影响农民工城市身份认同的关键因素。过往学者从多个层面探讨了影响农民工城市身份认同的因素,概括起来主要包括制度约束、家乡资源、城市生活体验、社会交往状况、人力资本水平、流入地公共服务、住房状况等[9-10],这其中也有学者关注到社区因素,包括社区类型、社区环境、社区选举、社区公共服务等[11],不过,这些研究大多是将社区因素作为控制变量,在研究中仅仅一带而过。
(二) 社区相关研究社区一词源于德国社会学家滕尼斯1887年出版的《Community and Society》一书,在书中,滕尼斯强调社区是具有共同价值观念的人们组成的生活共同体。当前,中文语境下的社区概念可以从两个层面来理解,一是地域性,即具有一定的时空边界;二是社会性,即人们在共同生活过程中,在彼此相互了解的基础上形成的亲密关系和心理归属感。
社区是城市的基本单元,是人们生活的组织载体。大量研究指出社区在农民工城市融入进程中的重要作用,并指出社区融入是农民工融入城市的必经阶段或必要组成部分[12-13]。还有部分研究从社区融入视角分析了农民工融入城市社会面临的困境,探讨了影响农民工社区融入的因素。刘传江和周玲[14]指出农民工需要尽快融入城市社区,积极构建社会资本的积累和形成机制,以弥补离开农村社区带来的社会资本损失。刘建娥[12]基于社区融入视角,指出农民工城市社会融入水平偏低,社区服务体系滞后是其中的重要原因。肖云和邓睿[13]将研究视点置于城市社区空间内,发现新生代农民工融入城市社区过程中,在人际关系、社会活动等方面具有向同质群体的内卷化倾向。唐有财和侯秋宇[15]构建了一个身份、场域和认同的社区参与分析框架,并从上述三个维度分析流动人口社区参与的影响因素。研究表明,户籍制度形成的制度性身份是影响流动人口社区参与的核心变量,流动人口的融入城市意愿和本地人归属感对社区参与也具有显著影响。
(三) 文献评述综合身份认同与社区的两类文献,我们不难发现:一是在探讨身份认同影响因素的研究当中,已有研究虽对社区因素有所关注,但大多数研究只是将社区因素作为控制变量,不仅欠缺针对性,而且在内生性问题处理上也存在不足。二是已有研究大多是从社区融入视角,阐述农民工社区融入的现状以及影响因素,缺乏专门探讨社区状况对农民工城市身份认同影响的系统性研究。三是已有研究欠缺理论层面的分析,鲜有研究构建社区因素对农民工城市身份认同的理论分析框架。有别于以往文献,本文可能的边际贡献在于:一是与已有研究中仅将社区因素作为控制变量所不同,本文专门聚焦社区状况,探究社区状况对农民工城市身份认同的影响。二是本文使用2014年社会融合与心理专项调查,利用倾向得分匹配法和逆向概率加权法纠正潜在的选择性偏误,并通过调整数据、调整变量等方法进行检验,最终获得稳健、可信的研究结论。三是本文依托布迪厄的场域理论,基于社区场域视角,构建社区状况对农民工城市身份认同影响的分析框架,理解其中的内在逻辑。
二、分析框架对场域的解读,是一个不断深化、不断辨析的发展过程。场最初是一个物理学概念,指的是相互依存的事实的整体,传播至心理学领域后转向人的世界,在社会学中勒温、涂尔干等学者进行拓展深化,最终布迪厄成为场域理论的集大成者,他开创性地提出了场域理论,并将场域作为核心的理论工具。在布迪厄看来,场域可以定义为建立在社会关系基础上、具有自身独特逻辑的客观系统[16]。社会行动者就像磁场中具有能动性的粒子,一旦进入某种场域,就会表现出与该场域相符合的状态、相匹配的行为,以及该场域中特有的表达代码[17]。
在布迪厄的研究体系中,场域不仅是一种理论工具,还是一套方法论、一个开放性的概念。他认为,在高度分化的社会里,世界是由具有相对自主性的小世界构成的,而这些小世界便是一个个场域,比如文化场域、教育场域等。它们之间既相互独立,又相互联系,共同构成了社会这个最大的场域。作为城市的基础细胞,社区是人们生活中不可或缺的重要组成部分,因而在社区相关研究中引入场域理论,是一个值得探索的重要视角[18]。本文尝试从社区场域视角,理解社区状况与农民工城市身份认同的关系,并思考社区状况的差异如何影响农民工的城市身份认同。
国内已有学者尝试将布迪厄的场域理论引入社区研究。例如,孙炳耀[18]利用场域理论解释中国居民社区行动的历史、现状、成长及原因。尹广文[19]指出,在城市社会管理体制从单位制过渡到社区制后,社区便成为各种力量和不同利益主体之间彼此互动和相互博弈的集中的实践场域。赵晓红和鲍宗豪[20]在研究新生代农民工社区认同过程中,也指出社区是新生代农民工精神家园的空间载体,是融入城市的重要驿站和开展日常生活实践的重要场域。肖云和邓睿[13]在研究中进一步阐述了社区场域的概念,他们指出场域是由共同的组织制度、价值观念和场域意识所构成的生活共同体。场域中的社区成员是具有精神属性和能动意识的人,他们在共同的社区空间中必然会形成属于“我群”的惯习,表现为社会经历中稳定的心理和行为倾向,包括非正式的习惯态度、交往技巧、语言风格和生活方式等[16]。
综上可知,实质上,社区场域是一种生活共同体,一种微缩了社会的组织模式。同一社区场域中的成员会形成属于“我群”的惯习,表现为社会经历中稳定的心理和行为倾向;相反,不同社区场域的成员则会表现出异质性的心理与多样性的行为。对于广大农民工而言,社区场域就如同磁场,他们便是磁场中的粒子,一旦进入某种社区场域,便会逐渐形成“我群”的状态与行为。身份认同指的是个体对自我特性的一致性认可,也是个体对其群体资格或范畴资格在心理层面的认知评价、情感体验[21]。对于农民工而言,认同城市身份是融入城市社会的重要维度,往往被视为农民工融入城市社会的最高层次、核心标志。由此,本文提出研究假说:在不同的社区场域当中,农民工对城市身份的认同会存在显著差异,即社区状况会显著影响农民工的城市身份认同。

|
图 1 场域视角下社区状况对农民工城市身份认同的影响逻辑 |
本文使用的数据是2014年国家卫生健康委员会组织开展的中国流动人口动态监测调查(China Migrants Dynamic Survey,简称CMDS)中的C模块①,即基于社会融合试点城市开展的“社会融合与心理专项调查”。样本覆盖北京市朝阳区、山东省青岛市、福建省厦门市、浙江省嘉兴市、广东省深圳市、广东省中山市、河南省郑州市和四川省成都市等八个社会融合试点城市,虽然这八个城市并非随机抽取,但城市内样本均采用分层、多阶段、与规模成比例的PPS抽样方法,具有一定的代表性[22]。调查对象为在流入地居住一个月以上,非本区(县、市)户口的15~59周岁流动人口。调查的总样本量为16000个,由于关注的是进城农民工,因此,本文仅考虑流动人口中的农业户籍部分,在对其他变量的缺失值、错误值处理后,共获取13927个基准样本。
① 具体信息详见国家卫生健康委员会流动人口数据平台http://www.chinaldrk.org.cn/wjw/#/home。
(二) 变量选择与描述1.被解释变量——城市身份认同。在对心理层面社会融入或是城市身份认同的度量方面,多数文献采用外来人口(或进城农民工)是否认同自己是本地人这一指标[10-11]。社会融合与心理专项调查询问被访者是否认同自己是本地人,被访者回答的选项分别为是和否,样本范围内,认同自己是本地人的农民工2784人,占比为19.99%;不认同自己是本地人的农民工11141人,占比为80.01%。
2.核心解释变量——社区状况。本文从社区基础条件和社区软环境两个层面切入,选取社区类型、邻居构成情况表征社区基础条件,选取健康档案和社区文体活动表征社区软环境。这其中,健康档案和社区文体活动属于个人行为,但考虑两项活动均发生在社区这一空间载体,且两项活动均以社区施动为基本前提,强调社区施动后,个体与社区之间的关系与互动,因此用以衡量社区软环境。各变量具体情况如下所示:
(1) 社区类型。问卷询问被访者居住在什么样的社区中,回答包括商品房社区、经济适用房社区、机关事业单位社区、工矿企业社区、未经改造的老城区、城中村或棚户区、城郊接合部、农村社区与其他社区。为了便于后文运用倾向得分匹配法纠正选择性偏误,本文还将社区类型划分为高端社区和低端社区两类。其中,商品房社区、经济适用房社区、机关事业单位社区、工矿企业社区为高端社区,样本范围内,居住在高端社区的农民工3215人,比例为23.09%;未经改造的老城区、城中村或棚户区、城郊接合部、农村社区与其他社区为低端社区,样本范围内,居住在低端社区的农民工10710人,比例为76.91%。
(2) 邻居构成情况。问卷询问被访者邻居主要是谁,回答选项包括外地人、本地市民、外地人和本地人数量差不多,本文分别赋值为“1、3、2”,并将1作为参照组。样本范围内,邻居以外地人为主的农民工6248人,占比接近半数,邻居本地人外地人数量差不多的农民工4069人,邻居以本地市民为主的农民工仅为2787人。
(3) 健康档案。问卷还询问被访者在本地居住的社区是否建立了居民健康档案,被访者回答的选项包括“没建”“听说过、没建”“听说过、已经建立”“不清楚”,本文将已经建立设定为1,即已经建立健康档案,其他情况均设定为0,即没有建立健康档案。样本范围内,已经在社区建立健康档案的农民工3251人,尚未建立健康档案的农民工10676人。
(4) 社区文体活动。问卷询问被访者是否在本地参加过社区文体活动,被访者回答是或否,本文分别赋值为1和0。样本范围内,未参加社区文体活动的农民工10417人,参加过社区文体活动的农民工3510人。
3.控制变量。依据2014年社会融合与心理专项调查问卷,并借鉴已有文献的做法,本文控制了可能影响农民工城市身份认同的变量,包括:年龄、受教育程度(小学及以下为参照、初中、高中、大学及以上)、婚姻状态(未婚为参照组、在婚、离异/丧偶)、健康状况(非常好为参照组、很好、好、一般、差)、住房状况(租房为参照组、保障房、自有住房)等个人基本特征;收入水平、失业保险及就业身份等就业特征;老家宅基地等情况;本地方言水平(听得懂也会讲为参照组、听得懂会讲一点、听得懂但不会讲、不懂本地话)、本地流动时间、流动范围(跨省流动为参照组、省内跨市、市内跨县)等流动特征。此外,本文还控制了农民工所属的行业①,考虑到不同地区农民工的社区状况以及城市身份认同现状及相关政策可能有所不同,故以虚拟变量形式对城市进行控制。变量的描述性统计见表 1。
① 行业类别依据《国民经济行业分类》(GB/T4754-2011)共划分为20类。
| 变量类型 | 观测值 | 平均值 | 标准差 | 最小值 | 最大值 |
| 被解释变量 | |||||
| 城市身份认同 | 13925 | 0.2 | 0.4 | 0 | 1 |
| 核心解释变量 | |||||
| 社区类型 | |||||
| 农村社区(参照组) | 13925 | 0.313 | 0.464 | 0 | 1 |
| 商品房社区 | 13925 | 0.148 | 0.355 | 0 | 1 |
| 经济适用房社区 | 13925 | 0.037 | 0.189 | 0 | 1 |
| 机关事业单位社区 | 13925 | 0.014 | 0.119 | 0 | 1 |
| 工矿企业社区 | 13925 | 0.032 | 0.175 | 0 | 1 |
| 未经改造的老城区 | 13925 | 0.153 | 0.36 | 0 | 1 |
| 城中村或棚户区 | 13925 | 0.135 | 0.342 | 0 | 1 |
| 城郊接合部 | 13925 | 0.168 | 0.374 | 0 | 1 |
| 邻居构成情况 | |||||
| 外地人为主 | 13104 | 0.477 | 0.5 | 0 | 1 |
| 外地人和本地人数量差不多 | 13104 | 0.311 | 0.463 | 0 | 1 |
| 本地市民为主 | 13104 | 0.213 | 0.409 | 0 | 1 |
| 健康档案 | 13927 | 0.233 | 0.423 | 0 | 1 |
| 社区文体活动 | 13927 | 0.252 | 0.434 | 0 | 1 |
| 个人特征 | |||||
| 年龄 | 13927 | 32.533 | 8.791 | 15 | 60 |
| 受教育程度 | 13927 | 2.336 | 0.789 | 1 | 4 |
| 性别 | 13927 | 0.549 | 0.498 | 0 | 1 |
| 婚姻状态 | 13927 | 1.757 | 0.458 | 1 | 3 |
| 健康状况 | 13927 | 3.761 | 0.971 | 1 | 5 |
| 住房状况 | 13927 | 1.158 | 0.534 | 1 | 3 |
| 就业特征 | |||||
| 收入水平 | 13927 | 8.527 | 0.575 | 2.303 | 12.612 |
| 失业保险 | 13927 | 0.216 | 0.411 | 0 | 1 |
| 就业身份 | 13927 | 0.066 | 0.248 | 0 | 1 |
| 老家宅基地 | 13927 | 1.505 | 0.928 | 0 | 9.8 |
| 流动特征 | |||||
| 本地方言水平 | 13927 | 2.178 | 1.096 | 1 | 4 |
| 本地居留时间 | 13927 | 4.167 | 4.403 | 0 | 33 |
| 流动范围 | 13927 | 1.5 | 0.566 | 1 | 3 |
1.基准模型——Probit模型。由于本文主要的被解释变量为二值变量,本文采用Probit模型进行估计。该模型的表达式为:

|
(1) |
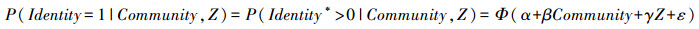
|
(2) |
如公式(1)所示,Identity*为潜变量,当Identity*>0时,Identity=1,否则Identity=0。进一步由公式(2)可知,Identity表示农民工的城市身份认同;Community表示社区状况等;Z为控制变量。α、β、γ为待估参数,ε为随机扰动项。
2.倾向得分匹配法(PSM)。考虑到农民工的社区状况可能并不满足随机抽样,而是由个体特征决定的自选择过程,用其作为解释变量直接回归,可能会因为非随机抽样而产生选择性偏误。为此,本文利用倾向得分匹配法构造反事实框架纠正潜在的偏误。
倾向得分(Propensity Score)的概念由Rosenbaum和Rubin首次提出。他们将倾向得分定义为个体在控制可观测到的混淆变量后,受到某种解释变量影响的条件概率。利用控制倾向评分所得出的现象之间的因果关系可以排除混淆变量的影响,获取二者之间的净效应[23]。具体步骤为(以社区类型为例):第一步,估计倾向得分值,根据一些可以观测到的混淆变量,运用Logit模型预测农民工居住在高端社区的概率。第二步,使用多种匹配方法,根据倾向得分进行匹配。第三步,基于匹配样本,比较处理组和控制组农民工城市身份认同的平均差异,得到社区状况对农民工城市身份认同的因果关系系数,即处理组平均处理效应(Average Treatment Effect on Treated,ATT),由式(3)表示:
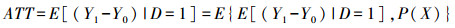
|
(3) |
其中,D指的是包含1和0的“处理变量”,当D=1时,个体进入处理组,当D=0时,个体进入控制组;P(X)表示倾向得分值;Y1和Y0分别表示处理组和控制组的估计结果。
四、实证结果与分析 (一) 基准回归表 2汇报了基于Probit模型的社区状况对农民工城市身份认同影响的基准回归结果①。第(1)列的核心解释变量为社区类型,第(2)列的核心解释变量为邻居构成情况,第(3)列的核心解释变量为健康档案,第(4)列的核心解释变量为社区文体活动,第(5)列将上述四个核心解释变量均纳入回归模型。整体来看,模型运行良好,各列的Wald卡方值均在1%的统计水平上通过了显著性检验,且除社区文体活动外的绝大多数核心解释变量的影响方向与显著性未发生明显变化,反映出模型估计结果较强的稳健性。
① 考虑到Probit模型估计结果只包含解释变量显著性和参数符号方面的信息,如无特殊说明,本文汇报各解释变量的边际效应。
| 变量 | 被解释变量:城市身份认同 | ||||
| (1) | (2) | (3) | (4) | (5) | |
| 农村社区(参照组) | |||||
| 商品房社区 | 0.053***(0.011) | 0.054***(0.012) | |||
| 经济适用房社区 | 0.092***(0.019) | 0.088***(0.020) | |||
| 机关事业单位社区 | 0.168***(0.033) | 0.161***(0.034) | |||
| 工矿企业社区 | 0.069***(0.022) | 0.075***(0.022) | |||
| 未经改造的老城区 | 0.024**(0.011) | 0.027**(0.011) | |||
| 城中村或棚户区 | 0.026*(0.014) | 0.029*(0.015) | |||
| 城郊接合部 | 0.025**(0.010) | 0.029***(0.010) | |||
| 外地人为主(参照组) | |||||
| 本外地人相当 | 0.022***(0.008) | 0.020***(0.008) | |||
| 本地市民为主 | 0.094***(0.010) | 0.086***(0.010) | |||
| 健康档案 | 0.050***(0.008) | 0.043***(0.008) | |||
| 社区文体活动 | 0.020**(0.008) | 0.010(0.008) | |||
| 其他解释变量 | 控制 | 控制 | 控制 | 控制 | 控制 |
| 农民工所在城市 | 控制 | 控制 | 控制 | 控制 | 控制 |
| 农民工所属行业 | 控制 | 控制 | 控制 | 控制 | 控制 |
| Wald卡方值 | 1185.250*** | 1168.873*** | 1145.142*** | 1126.620*** | 1250.869*** |
| Pseudo R2 | 0.093 | 0.096 | 0.091 | 0.088 | 0.103 |
| 观测值 | 13925 | 13104 | 13925 | 13925 | 13104 |
| 注:括号内为稳健标准误; ***、**、*分别代表在1%、5%、10%的统计水平上显著。 | |||||
① 相比于居住在农村社区的农民工,居住在其他社区会显著提升农民工的城市身份认同。从回归系数上来看,机关事业单位社区、经济适用房社区、工矿企业社区、商品房社区回归系数位居前列,说明上述几种社区对农民工认同城市身份的正向影响更大;相比之下,城中村或棚户区、未经改造的老城区、城郊接合部虽然也有助于农民工形成对城市的身份认同,但正向影响偏弱,且未经改造的老城区、城中村或棚户区估计结果的显著性略低,仅分别在5%和10%的统计水平上显著。②相比于邻居以外地人为主的农民工,邻居本外地人数量相当、以本地市民为主,会显著促进农民工形成城市身份认同,且估计结果均在1%的统计水平上显著。从回归系数上来看,邻居以本地市民为主的农民工更倾向于认同城市身份。这一结果表明,周边邻居中本地市民越多,农民工越容易认同城市身份。③相比于未建立健康档案的农民工,已经在社区建立健康档案的农民工对城市身份的认同度更高,且估计结果在1%的统计水平上显著。这显示出社区健康档案这类公共医疗卫生服务的重要作用。④第(4)列估计结果显示,参与社区文体活动对形成城市身份认同有显著正向影响,但将四个核心解释变量均纳入模型的第(5)列结果显示,参与社区文体活动对城市身份认同无显著影响。
在控制变量方面①,①农民工自身健康状况对城市身份认同具有显著正向影响。②相比于租房农民工,居住在保障房的农民工更不倾向于认同城市身份,而已购商品房的农民工对城市身份的认同度更高。③相比于没有失业保险的农民工,拥有失业保险的农民工更倾向于认同城市身份。④就业身份为雇主的农民工对城市身份的认同度更高。⑤本地方言水平越高,流动范围越小,在本地居留时间越长,越认同城市身份。
①控制变量的估计结果因篇幅所限,本文未列出,有兴趣的读者可向作者索取。
(二) 纠正选择性偏误1.倾向得分匹配法。使用倾向得分匹配法需要进行平衡性检验,目的是确保经过匹配后,处理组和控制组样本除农民工社区状况外,其他解释变量不存在显著的系统性差异,如果检验通过,则意味着这是一个合理的反事实[24]。Sianesi在研究中指出,经过匹配之后处理组和控制组的解释变量分布应该没有系统性差异,因此Pseudo R2应该明显下降,并且解释变量的LR test应该被拒绝[25]。此外,解释变量的标准化偏误也会明显降低,一般而言,匹配后解释变量的标准化系数应低于20%。
如表 3所示,在匹配完成后,本文进行了平衡性检验。以社区类型为例,匹配前,Pseudo R2为0.105,LR test为1587.270,对应的P值为0.000,结果在1%的统计水平上显著,标准化偏误的平均数与中位数分别为19.5%和10.1%。经过核匹配后,Pseudo R2下降到0.002,LR test的数值同样显著下降,且结果不显著,标准化偏误的平均数和中位数均低于3%。以上结果表明,倾向得分匹配显著弱化了解释变量的系统性差异,匹配过程是成功的。与之过程相似,其他核心解释变量的匹配过程也是成功的。
| 变量 | 匹配方法 | Pseudo R2 | LR test | P>Wald卡方值 | Mean Bias(%) | Med Bias(%) |
| 社区类型 | 匹配前 | 0.105 | 1587.270 | 0.000 | 19.5 | 10.1 |
| 核匹配 | 0.002 | 15.430 | 0.219 | 2.5 | 1.7 | |
| 邻居类型 | 匹配前 | 0.074 | 997.100 | 0.000 | 17.0 | 10.7 |
| 核匹配 | 0.000 | 2.460 | 0.998 | 1.1 | 0.9 | |
| 健康档案 | 匹配前 | 0.045 | 681.520 | 0.000 | 11.9 | 10.5 |
| 核匹配 | 0.000 | 1.700 | 1.000 | 0.9 | 0.9 | |
| 社区文体活动 | 匹配前 | 0.029 | 457.950 | 0.000 | 9.8 | 5.6 |
| 核匹配 | 0.001 | 8.080 | 0.779 | 1.6 | 1.3 |
最后,本文测算了匹配之后得出的ATT。如表 4所示,在消除了样本间可观测的系统性差异后,虽然在不同匹配方法之下,ATT的数值略有差异,但足以证明,居住在高端社区、社区邻居以本地市民为主、建立健康档案能够显著提升农民工的城市身份认同,参与社区文体的作用不显著。这一结果与基准分析结果相一致,证实了实证结果的稳健性。
| 社区状况 | 匹配方法 | 处理组 | 控制组 | ATT | 标准差 | t统计量 |
| 社区类型 | 近邻匹配 | 0.289 | 0.236 | 0.053*** | 0.011 | 4.95 |
| 核匹配 | 0.289 | 0.230 | 0.059*** | 0.010 | 6.04 | |
| 半径匹配 | 0.285 | 0.222 | 0.063*** | 0.010 | 6.21 | |
| 邻居类型 | 近邻匹配 | 0.319 | 0.228 | 0.092*** | 0.011 | 8.19 |
| 核匹配 | 0.319 | 0.225 | 0.095*** | 0.010 | 9.24 | |
| 半径匹配 | 0.317 | 0.225 | 0.092*** | 0.011 | 8.69 | |
| 健康档案 | 近邻匹配 | 0.251 | 0.196 | 0.055*** | 0.010 | 5.58 |
| 核匹配 | 0.251 | 0.199 | 0.053*** | 0.009 | 5.90 | |
| 半径匹配 | 0.250 | 0.197 | 0.053*** | 0.009 | 5.79 | |
| 社区文体活动 | 近邻匹配 | 0.244 | 0.243 | 0.001 | 0.010 | 0.08 |
| 核匹配 | 0.244 | 0.241 | 0.004 | 0.009 | 0.37 | |
| 半径匹配 | 0.244 | 0.242 | 0.002 | 0.010 | 0.17 | |
| 注:***代表在1%的统计水平上显著;近邻匹配采取有放回形式的一对四匹配。 | ||||||
2.逆向概率加权与逆向概率加权调整法。值得注意的是,倾向得分匹配法有一定的局限性[26]。若第一阶段模型存在误设,抑或是可观测变量选择不当、过少,则容易引起估计偏差。为此,陈强指出对于倾向匹配法的估计结果需要保持谨慎态度[26]。
本文在PSM基础上,进一步参考Ma等的研究,利用逆向概率加权法加以修正[27]。逆向概率加权(Inverse Probability Weighting,IPW)与PSM的基本原理相似,所不同的是IPW并不直接使用倾向得分进行估计,而是对倾向得分较低的个体赋予更高的权重,倾向得分较高的个体赋予更低的权重,从而使处理组和控制组协变量的分布更加接近,这样所得的ATT更具稳健性[27]。此外,一些学者对IPW进行了优化,如增强逆向概率加权法(Augmented Inverse Probability Weighting,AIPW)、回归调整法(Regression Adjustment,RA)和逆向概率加权调整法(Inverse Probability Weighting-Regression Adjustment,IPWRA),其中的典型代表之一便是IPWRA[28]。已有学者指出,IPWRA的最大优势在于估计结果具有双重稳健性,即只要农民工社区状况的决定方程或农民工城市身份认同的结果方程其中之一是正确的,ATT的估计结果就能够保持一致[27-28]。
如表 5所示,本文运用IPW和IPWRA两种方法计算ATT,结果显示,IPW与IPWRA所得的ATT和PSM所得的ATT在数值层面有一定差异,但显著性与方向上高度一致,这也从侧面证实了实证结果的稳健性。
| 社区状况 | IPW | IPWRA | |||||
| ATT | 标准差 | T值 | ATT | 标准差 | T值 | ||
| 社区类型 | 0.049*** | 0.011 | 4.57 | 0.061*** | 0.010 | 5.94 | |
| 邻居类型 | 0.098*** | 0.010 | 9.47 | 0.097*** | 0.010 | 9.48 | |
| 健康档案 | 0.052*** | 0.009 | 6.01 | 0.052*** | 0.009 | 6.01 | |
| 社区文体活动 | 0.015 | 0.009 | 1.58 | 0.014 | 0.009 | 1.56 | |
| 注:***代表在1%的统计水平上显著。 | |||||||
上述分析已经证实,社区状况会显著影响农民工的城市身份认同。不过,上述结果只是总体上的平均效应,并未考虑农民工群体的内部差异。众所周知,新生代农民工与老一代农民工存在明显不同。老一代农民工进城务工往往是养家糊口的无奈之选,大多基于生存理性,目标仅仅是打工挣钱,他们人虽在城市,但根却在农村;而新生代农民工则已经从生存理性过渡到发展理性阶段[14],他们大多怀揣城市梦,希望有朝一日能够融入城市、扎根城市。可见新老农民工对社区状况的期望与实际感受可能有所不同,因此,本文接下来探究社区状况对城市身份认同影响的代际差异。按照惯例,本文将出生于1980年以前的农民工划定为老一代农民工,出生于1980年及以后的农民工划定为新生代农民工。样本范围内,新生代农民工8607人,占比为61.80%;老一代农民工5320人,占比为38.20%。
如表 6所示,总体上,社区状况对新老农民工城市身份认同的影响存在鲜明差异。社区类型、邻居构成情况对老一代农民工影响更为明显,健康档案则对新生代农民工的影响更为明显,而社区文体活动对老一代农民工的影响不具备统计上的显著性,对新生代农民工的影响在10%的统计水平上显著。具体而言,以第(5)列结果来看,高端社区会使新生代农民工认同城市身份的概率显著提升4.2%,会使老一代农民工认同城市身份的概率提升6.5%;邻居以本地市民为主会使新生代农民工认同城市身份的概率显著提升5.8%,会使老一代农民工认同城市身份的概率提升8.4%;健康档案会使新生代农民工认同城市身份的概率显著提升4.5%,会使老一代农民工认同城市身份的概率提升4.0%;社区文体活动会使新生代农民工认同城市身份的概率显著提升1.9%,对老一代农民工的城市身份认同影响不显著。
| 变量 | 被解释变量:城市身份认同 | ||||
| (1) | (2) | (3) | (4) | (5) | |
| Panel A:新生代农民工 | |||||
| 社区类型 | 0.040***(0.010) | 0.042***(0.010) | |||
| 邻居构成情况 | 0.065***(0.010) | 0.058***(0.010) | |||
| 健康档案 | 0.045***(0.010) | 0.045***(0.010) | |||
| 社区文体活动 | 0.025***(0.010) | 0.019*(0.010) | |||
| Wald卡方值 | 703.144 | 710.190 | 694.627 | 690.214 | 743.704 |
| Pseudo R2 | 0.092 | 0.097 | 0.092 | 0.090 | 0.103 |
| 观测值 | 8606 | 8029 | 8606 | 8606 | 8029 |
| Panel B:老一代农民工 | |||||
| 社区类型 | 0.068***(0.013) | 0.065***(0.013) | |||
| 邻居构成情况 | 0.091***(0.013) | 0.084***(0.013) | |||
| 健康档案 | 0.054***(0.013) | 0.040***(0.013) | |||
| 社区文体活动 | 0.012(0.013) | 0.001(0.014) | |||
| Wald卡方值 | 506.610*** | 474.779*** | 463.339*** | 451.736*** | 528.609*** |
| Pseudo R2 | 0.099 | 0.097 | 0.092 | 0.089 | 0.108 |
| 观测值 | 5319 | 5075 | 5319 | 5319 | 5075 |
| 注:括号内为稳健标准误;***、**、*分别代表在1%、5%、10%的统计水平上显著。 | |||||
上述结果表明,对于老一代农民工而言,社区的“硬件”条件更为重要,例如社区类型、邻居构成情况等基础环境;相比之下,新生代农民工则更加注重社区的服务性与参与性,关注社区的“软件”,例如社区提供的公共服务以及组织的文体活动等。
(四) 稳健性检验考虑到实证分析中可能出现的内生性问题,本文通过尽可能控制更多解释变量,并以虚拟变量形式控制农民工所在城市、所属行业,考虑到农民工的社区状况是自我选择的结果,还运用倾向得分匹配法和逆向概率加权法构建反事实框架纠正选择性偏误。为了进一步考量实证结果的可信度,本文运用两种方法进行稳健性检验。结果见表 7。
| 变量 | 调整为2013年数据城市身份认同 | 调整被解释变量 | ||
| Belong-city | City-member | City-part | ||
| (1) | (2) | (3) | (4) | |
| 社区类型 | 0.100***(0.039) | 0.125***(0.026) | 0.128***(0.027) | 0.124***(0.027) |
| 邻居构成情况 | 0.324***(0.033) | 0.132***(0.027) | 0.133***(0.027) | 0.138***(0.028) |
| 健康档案 | 0.093***(0.036) | 0.040(0.025) | 0.046*(0.025) | 0.097***(0.026) |
| 社区文体活动 | -0.103(0.071) | 0.069***(0.025) | 0.023(0.025) | 0.042(0.026) |
| Wald卡方值 | 1322.083*** | 1346.843*** | 1217.353*** | 1168.310*** |
| Pseudo R2 | 0.182 | 0.055 | 0.051 | 0.052 |
| 观测值 | 14430 | 13104 | 13104 | 13104 |
| 注:括号内为稳健标准误;***、**、*分别代表在1%、5%、10%的统计水平上显著。 | ||||
1.调整数据。本文使用国家卫生健康委员会开展的2013年社会融合与心理专项调查进行重新回归。值得注意的是,2013年问卷对城市身份认同的衡量略有差异,问卷向被访者询问了“您认为自己是哪里人?”被访者回答的选项包括“本地人、新本地人、老家人、不知道自己是哪里人”,本文将本地人赋值为1,其他均赋值为0。2013年社会融合与心理专项调查当中,认同城市身份的农民工1696人,所占比例为11.33%。可见由于衡量方式的差异,2013年和2014年社会融合与心理专项调查在农民工城市身份认同方面存在差异,因此,本文并未利用两年数据组成混合截面数据,仅将2013年社会融合与心理专项调查数据做稳健性检验。
如表 7第(1)列所示,使用2013年社会融合与心理专项调查的估计结果与前文分析基本一致。居住在高端社区、邻居以本地市民为主、建立健康档案会显著提升农民工对本地的身份认同,而社区文体活动对城市身份认同无显著影响。
2.调整变量。本文运用三个与被解释变量高度相关的变量进行稳健性检验。2014年社会融合与心理专项调查向被访者询问:“我感觉自己是否属于这个城市(belong-city),我觉得我是这个城市的成员(city-member),我把自己看作是这个城市的一部分(city-part)。”三个变量的衡量方式一致,均要求被访者在“完全不同意、不同意、基本同意、完全同意”四个选项中作出选择,四个选项分别被赋值为“1、2、3、4”。由于三个变量是典型的排序变量,因此,本文使用Ordered Probit模型进行回归。如表 7第(2)~(4)列所示,调整被解释变量后,估计结果与前文也保持一致,充分表明回归结果是稳健的。
五、结论与启示社区是城市社会的基本单元,是农民工融入城市社会的组织载体与空间场域。本文基于布迪厄提出的场域理论,从社区场域视角理解社区影响农民工城市身份认同的内在逻辑。随后,本文利用国家卫生健康委员会开展的2014年社会融合与心理专项调查展开严谨的实证分析。研究表明:社区状况是影响农民工城市身份认同的重要因素,居住在高端社区、社区邻居以本地市民为主、建立健康档案的农民工更倾向于认同城市身份,而社区文体活动对农民工城市身份认同无显著影响。考虑到社区状况很可能是农民工自身特征决定的“自选择”过程,运用倾向得分匹配法和逆向概率加权法构建反事实框架纠正潜在的选择性偏误,并通过调整数据、调整变量等方法进行稳健性检验,结论依然成立。进一步来讲,社区状况对农民工城市身份认同存在鲜明的代际差异。社区类型、邻居构成情况对老一代农民工影响更为明显,健康档案、社区文体活动则对新生代农民工的影响更为明显。这一结果表明,老一代农民工更加关注社区类型、邻居构成情况等社区的基础环境,新生代农民工则更加关注社区公共服务与社区文体活动等社区的软环境。综上可知,本文蕴含的政策启示在于,应当利用好社区这一空间载体、充分发挥社区在构建农民工城市身份认同的抓手作用。具体来讲:
第一,夯实社区硬件基础,补齐低端社区的短板。一方面,要加快推进城中村、棚户区等改造进程,通过改善社区面貌、优化社区硬件设施,提升城市社区的整体水平。另一方面,优化公共服务资源的空间配置,注重将公共服务及配套资源向农民工集中的低端社区倾斜,补齐低端社区短板。此外,还应逐步扩大住房保障覆盖面,增进本外地居民的居住空间融合,避免因大量农民工聚集在低端社区形成居住区隔,甚至形成城市内部的“新二元社会结构”。
第二,逐步转变社区管理模式,不断健全社区服务功能。社区应逐步从管理型社区向服务型社区转变,坚持以人为本的发展理念,秉持基本公共服务均等化的基本原则,为农民工提供均等的公共服务。不仅如此,社区还应当逐步成为农民工的服务平台,除了提供基本的卫生和医疗服务,还可以提供就业服务,例如可通过社区信息公开栏或者互联网途径(如微博、微信等)发布一些针对农民工的就业信息、维权信息等。以此让农民工切身感受到来自社区的关心,强化其社区主体成员身份的感知度,进而提升对城市的归属感与认同感。
第三,逐步消除对农民工的刻板印象,积极引导农民工社区参与。其一,要从制度与法律上赋予农民工的公民权,消除对农民工的刻板印象,社区方面应改变原有的防范性管理模式,承认农民工社区居民身份。其二,要以开放和包容的姿态推进城市社区建设,通过开展多类型社区文体活动(例如社区运动会、邻里聚餐会等)、发展多层次社区组织,搭建农民工与城市居民交流互动的平台,促进农民工与当地居民互帮互助、和谐共处,拉近两者的社会距离。
| [1] |
钱龙, 卢海阳, 钱文荣. 身份认同影响个体消费吗?——以农民工在城文娱消费为例[J]. 南京农业大学学报(社会科学版), 2015(6): 51-60. |
| [2] |
张淑华, 李海莹, 刘芳. 身份认同研究综述[J]. 心理研究, 2012(1): 21-27. DOI:10.3969/j.issn.2095-1159.2012.01.004 |
| [3] |
Tajfel H, Billig M G, Bundy R P. Social Categorization and Intergroup Behavior[J]. European Journal of Social Psychology, 1971(1): 149-178. |
| [4] |
Akerlof G A, Kranton R E. Economics and Identity[J]. Quarterly Journal of Economics, 2000(3): 715-753. |
| [5] |
李书娟, 徐现祥. 身份认同与经济增长[J]. 经济学(季刊), 2016(3): 941-962. |
| [6] |
续继, 黄娅娜. 性别认同与家庭中的婚姻及劳动表现[J]. 经济研究, 2018(4): 136-150. |
| [7] |
郭星华, 李飞. 漂泊与寻根:农民工社会认同的二重性[J]. 人口研究, 2009(6): 74-84. |
| [8] |
卢海阳, 梁海兵. "城市人"身份认同对农民工劳动供给的影响——基于身份经济学视角[J]. 南京农业大学学报(社会科学版), 2016(3): 66-76. |
| [9] |
李荣彬, 张丽艳. 流动人口身份认同的现状及影响因素研究——基于中国106个城市的调查数据[J]. 人口与经济, 2012(4): 78-86. |
| [10] |
祝仲坤, 冷晨昕. 住房状况、社会地位与农民工的城市身份认同——基于社会融合调查数据的实证分析[J]. 中国农村观察, 2018(1): 96-110. |
| [11] |
崔岩. 流动人口心理层面的社会融入和身份认同问题研究[J]. 社会学研究, 2012(5): 141-160, 244. |
| [12] |
刘建娥. 乡—城移民社会融合的实践策略研究——社区融入的视角[J]. 社会, 2010(1): 127-151. |
| [13] |
肖云, 邓睿. 新生代农民工城市社区融入困境分析[J]. 华南农业大学学报(社会科学版), 2015(1): 36-45. |
| [14] |
刘传江, 周玲. 社会资本与农民工的城市融合[J]. 人口研究, 2004(5): 12-18. DOI:10.3969/j.issn.1000-6087.2004.05.002 |
| [15] |
唐有财, 侯秋宇. 身份、场域和认同:流动人口的社区参与及其影响机制研究[J]. 华东理工大学学报(社会科学版), 2017(3): 1-10. DOI:10.3969/j.issn.1008-7672.2017.03.001 |
| [16] |
皮埃尔布迪厄, 华康德. 实践与反思:反思社会学导引[M]. 北京: 中央编译出版社, 2004.
|
| [17] |
田北海, 耿宇瀚. 生活场域与情境体验:农民工与市民社会交往的影响机制研究[J]. 学习与实践, 2014(7): 94-104. |
| [18] |
孙炳耀. 对居民社区行动场域的理论解析[J]. 哈尔滨工业大学学报(社会科学版), 2013(6): 18-24. |
| [19] |
尹广文. 多元主体参与社区场域中的协同治理实践——基于四种典型的社区治理创新模式的比较研究[J]. 云南行政学院学报, 2016(5): 125-130. DOI:10.3969/j.issn.1671-0681.2016.05.021 |
| [20] |
赵晓红, 鲍宗豪. 新型城镇化背景下新生代农民工的社区认同——一个社会学的分析框架[J]. 华东理工大学学报(社会科学版), 2016(6): 9-15. DOI:10.3969/j.issn.1008-7672.2016.06.002 |
| [21] |
赵迎军. 从身份漂移到市民定位:农民工城市身份认同研究[J]. 浙江社会科学, 2018(4): 93-102. |
| [22] |
杨菊华. 中国流动人口的社会融合研究[J]. 中国社会科学, 2015(2): 61-79. |
| [23] |
Rosenbaum P R, Rubin D B. The Central Role of the Propensity Score in Observational Studies for Causal Effects[J]. Biometrika, 1983, 70(1): 41-55. |
| [24] |
陈飞, 翟伟娟. 农户行为视角下农地流转诱因及其福利效应研究[J]. 经济研究, 2015(10): 163-177. DOI:10.3969/j.issn.1005-913X.2015.10.077 |
| [25] |
Sianesi B. Making Advanced Statistical Software Freely Available to Practitioners[J]. Nuclear Instruments & Methods in Physics Research, 2004, 213(10): 693-698. |
| [26] |
陈强. 高级计量经济学及Stata应用[M]. 2版. 北京: 高等教育出版社, 2014.
|
| [27] |
Ma W, Renwick A, Bicknell K. Higher Intensity, Higher Profit? Empirical Evidence from Dairy Farming in New Zealand[J]. Journal of Agricultural Economics, 2018, 69(3): 739-755. DOI:10.1111/1477-9552.12261 |
| [28] |
Linden A, Uysal S, Ryan A, et al. Estimating Causal Effects for Multivalued Treatments: A Comparison of Approaches[J]. Statistics in Medicine, 2016, 35(4): 534-552. DOI:10.1002/sim.6768 |