
文章信息
- 张瑞红, 赵凯旋, 姬江涛, 朱雪峰
- ZHANG Ruihong, ZHAO Kaixuan, JI Jiangtao, ZHU Xuefeng
- 基于机器学习的奶牛颈环ID自动定位与识别方法
- Automatic location and recognition of cow's collar ID based on machine learning
- 南京农业大学学报, 2021, 44(3): 586-595
- Journal of Nanjing Agricultural University, 2021, 44(3): 586-595.
- http://dx.doi.org/10.7685/jnau.202010005
-
文章历史
- 收稿日期: 2020-10-06




随着大型奶牛养殖场的奶牛数量不断增加, 奶牛个体的健康和福利水平已成为影响奶牛产量的重要指标[1]。奶牛个体活动的实时感知和行为分析系统逐渐成为当今的研究热点[2-4], 奶牛个体身份识别是上述系统实现的前提和基础[5]。无线射频技术(radio frequency identification, RFID)是动物个体识别中常用的技术手段[6-7], 利用射频信号可以对目标对象进行自动识别并读取相关数据[8]。但这种技术需要将电子标签附着在动物身上, 影响动物福利, 且只有当奶牛的运动速度和活动区域在某个范围内, 才能达到较好的识别效果[9]。最重要的是, 这种技术所需的设备比较复杂, 成本较高[10]。基于图像处理的非接触个体识别技术不仅成本低, 而且随着特征提取方法和人工神经网络的不断发展, 其准确性和鲁棒性也得以不断提高[11-13]。
许多学者研究了采用图像或视频识别奶牛个体的方法。Xia等[14]提出1种基于稀疏表示分类器(sparse representation classifier, SRC)的牛脸识别系统, 通过使用主成分分析法提取特征, 结合稀疏表示分类器对奶牛脸部图像进行分类和识别。Zhao等[4]提出1种基于模板匹配的奶牛识别方法, 通过提取所有奶牛的躯干图像特征生成特征模板库, 将待测奶牛的躯干图像特征与模板库中的特征进行匹配实现奶牛个体的识别。但是, 浅层的结构和有限的特征难以有效解决复杂的分类问题[15], 因此学者们开始在深度学习的基础上解决分类识别问题。Kim等[16]基于奶牛的身体区域图像开发了1套奶牛识别系统, 通过将奶牛的躯干图像二值化处理, 并分块提取特征, 作为输入层训练人工神经网络识别奶牛个体。赵凯旋等[17]提出1种基于卷积神经网络的奶牛个体识别方法, 该系统从奶牛的躯干图像中提取48×48大小的矩阵作为特征值, 构建并训练1个6层的卷积神经网络, 在测试中有90.55%的图像被正确识别。Bergamini等[18]提出1种基于深度学习的牛脸识别框架, 该系统将同一头牛的2个视图分别放入卷积神经网络中提取特征, 并合并特征继续向后传递训练卷积神经网络模型。
在训练数据充足的前提下, 基于机器学习的分类识别方法能够最大程度地适应不同的场景。但是, 采用基于奶牛生物特征(牛脸、体斑等)图像训练识别模型时, 易受外界干扰, 算法复杂度高。另外, 网络的输出端对应牛群中奶牛的ID, 当奶牛的数量增加, 网络的规模将呈指数级增长, 一旦有新的奶牛加入, 整个网络需要重新训练[4]。而利用奶牛颈环ID识别奶牛身份不仅有效减小网络规模, 且标牌的识别相较于奶牛的生物图像分类具有更高的鲁棒性。因此, 本文提出1种基于机器学习的奶牛颈环ID自动定位与识别系统, 通过检测奶牛颈部佩戴的标牌以及识别标牌上的ID实现奶牛个体的识别。
1 试验数据试验视频采集自美国肯塔基大学Coldstream研究型奶牛场, 采集时间为2016年8月, 试验对象为处于泌乳期的荷斯坦奶牛。当奶牛挤完奶后回到牛棚的过程中, 会经过一段平坦的直线过道, 该过道使用4道电气围栏限制奶牛的活动区域(前后各2道), 过道的宽度为2 m。将尼康D5200相机安装在距离过道3.5 m、离地面1.5 m的三脚架上。采用35 mm镜头(尼康AF-S DX 35mm f/1.8G), 选择ISO 400、自动曝光、自动对焦模式。采用人工干预确保每次仅有1头奶牛通过过道。在奶牛通过相机视野的过程中相机以固定的时间间隔连续拍照, 图像的分辨率为6 000像素(水平)×4 000像素(垂直)。使用电子罗盘调整相机, 使其与奶牛的行走方向平行。在奶牛和相机之间有2条电子围栏, 每个围栏的宽度约为1 cm。图像采集时间为晴天的16:00至18:00。拍摄在自然光照条件下进行。所拍摄到的原始图像如图 1所示。拍摄的照片被存储在相机的本地存储卡中。被拍摄的奶牛均佩戴有如图 2所示的颈环, 该颈环包含4个正方形蓝色塑料块, 上面的数字构成奶牛的唯一4位标号, 其中标号数字为白色。最终共得到80头奶牛的1 782幅图像, 剔除无奶牛、标牌上有遮挡、过曝光的图像368幅, 剩余图像1 414幅。将图像分为训练集和测试集。训练集图像用于构建级联检测器和字符识别模型; 测试集图像用于模型的精度验证。随机选择58头奶牛的图像作为训练集, 共968幅; 剩余22头奶牛的图像作为测试集, 共446幅。由于奶牛通过视野时的运动速度不同, 所以个体间的样本数量不同。

|
图 1 原始图像 Fig. 1 The original image |

|
图 2 奶牛颈环结构示意图 Fig. 2 Schematic diagram of neck collar 1.卡扣Buckle; 2.颈带Neck band; 3.字符块Character block; 4.数字标号Digital label; 5.配重Weight. |
标牌定位是指从图像中找出奶牛颈部佩戴的标牌位置, 这是标牌识别的第一步, 也是关键的一步。级联检测器在人脸检测、行人检测、交通标志检测等任务中均具有较好的表现[19-21], 采用这种方法定位标牌能适应复杂的识别场景。由于奶牛的活动(例如行走、低头、扭头)会造成所佩戴标牌发生几何偏转, 直接对原始图像进行检测易产生较高的漏检率。对图像进行旋转再使用级联检测器能够显著提高标牌定位的召回率。
2.1 级联检测器级联检测器是一系列强分类器的串联组合, 其中每个强分类器是若干个弱分类器的加权并联组合, 负责判断样本是否具有某个特征。级联检测器工作时, 串联的强分类器会对滑动窗口中的样本进行特征检测, 根据检测结果将其标记为正样本或负样本。如果标记为负样本, 认为当前窗口中的区域不是所查找的目标, 检测窗口将会移动到下一个位置继续进行判断。如果标记为正样本, 则该样本进入下一级分类器的特征检测。如果所有强分类器都将图像标记为正样本, 那么检测器认为当前窗口中的区域即为所查找的目标。大部分的负样本会在前几个分类器中被剔除, 因此这种级联结构可以提高检测效率和准确率, 满足检测的实时性要求。级联目标检测器工作过程如图 3所示。奶牛所佩戴的标牌外形规则, 长宽比变化不大, 有利于采用级联检测器的滑动窗口查找对象。

|
图 3 级联目标检测器工作过程 Fig. 3 Working process of cascade detector |
训练之前首先准备用于训练的正、负样本。将训练集图像中含有目标的区域剪裁下来作为正样本。负样本选择与目标相关的背景图像以及与目标外观相似的非目标图像, 以提高检测器的工作性能。另外, 将每一次训练中误判为正样本的图像作为下一次训练的负样本, 可以提高级联检测器的检测精度。
2.2.2 样本特征Haar、局部二值模式(local binary pattern, LBP)和梯度方向直方图(histogram of oriented gradient, HOG)是级联检测器常用的特征描述子, 用来提取待检测图像的特征样本。其中, Haar特征是描述图像在特定方向上(水平、垂直、对角)具有明显像素模块梯度变化的特征, 而标牌图像中数字与背景之间的梯度变化方向是任意的, 不具有明显的规则。LBP特征是针对图像纹理细节的描述, 标牌中所包含的纹理信息较少, 而图像背景中的纹理信息丰富, 因此标牌区域的LBP特征与背景相比不具有明显的区分性。
HOG特征通过计算和统计图像局部区域的梯度直方图来构成特征。由于所有标牌图像中的数字分布位置是相同的, 因此标牌之间具有相似的局部梯度直方图, 且HOG特征对光学的形变和较小的几何形变能够保持良好的不变性, 因此, HOG特征更适合作为描述图像的特征样本。另外, 在相同的训练参数下对3种特征检测器进行试验, 结果表明HOG特征在精度和耗时方面的表现明显优于另外2种特征。因此采用HOG模式提取图像的特征样本。
2.2.3 分类器训练时采用GAB(Gentle AdaBoost)分类器。分类器的性能是决定检测器效果的关键, 其核心思想是训练不同的弱分类器并将其加权组合构成强分类器。GAB分类器使用“样本集中度”表示弱分类器对每个样本的分类结果, 使结果的度量从“绝对”变成“相似度”(概率)。采用加权平方和误差(weighted square error, WSE)计算权重误差:
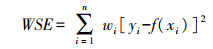
|
(1) |
式中: wi为权重; f(xi)为弱分类器对样本xi的输出值; yi为样本xi的标签。
通过WSE计算的权重误差“平滑”更新权重, 可以有效避免训练时的过拟合现象。
2.2.4 训练参数根据对标牌长度和高度的统计, 选择输出样本的宽和高分别为40和160像素。对模型性能影响较大的训练参数包括分类器的级数(Sn)、分类器每一级希望得到的最小检测率(Hmin)、分类器每一级希望得到的最大误检率(Fmax)。理论上, 级联检测器总的检测率(true positive rate, TPR)和误检率(false positive rate, FPR)的计算公式如下:
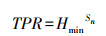
|
(2) |

|
(3) |
级联检测器的检测率和误检率随着级数的增加呈指数级增长, 因此, 当分类器的级数大于10, 最小检测率要尽量接近1, 最大误检率一般低于0.5即可。将最小检测率固定为0.995, 改变分类器的级数和每一级希望得到的最大误检率进行级联检测器的训练试验。
2.3 定位结果将测试集中的图像分别放入不同训练参数下的级联检测器中进行试验。若检测出来的图像中完整包含4个数字且标牌的面积占图像总面积的3/4以上, 认为是准确检测到的目标。
准确率和召回率是评价级联检测器性能的2个重要指标。准确率(precision, P)反映检测器的精度, 表示所有被分类为正样本的实例中实际为正样本的比例, 计算公式为:
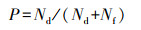
|
(4) |
式中: Nf表示误检为目标的负样本数; Nd表示级联检测器准确检测到的目标数。
召回率(recall, R)反映检测器的查全率, 表示所有正样本的实例中被正确分类为正样本的比例, 计算公式为:
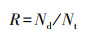
|
(5) |
式中: Nt表示实际存在的目标数。
训练结果(表 1)表明: 随着分类器级数的增加和每一级最大误检率的减小, 准确率逐渐提高, 召回率逐渐降低, 两者是相互矛盾的。另外, 级联检测器的准确率表现较好, 训练模型的准确率最高达到97.34%。但召回率较低, 表现最好的召回率仅为47.27%。
| 最大误检率 Maximum falsedetection rate |
分类器级数 Number ofclassifiers |
准确率/% Precision |
召回率/% Recall |
最大误检率 Maximum falsedetection rate |
分类器级数 Number ofclassifiers |
准确率/% Precision |
召回率/% Recall |
|
| 0.45 | 19 | 88.99 | 44.09 | 0.35 | 12 | 86.61 | 47.05 | |
| 0.45 | 21 | 96.05 | 38.64 | 0.25 | 13 | 97.28 | 40.68 | |
| 0.35 | 15 | 91.07 | 46.36 | 0.30 | 13 | 97.34 | 41.59 | |
| 0.35 | 13 | 91.07 | 46.36 | 0.40 | 13 | 85.60 | 47.27 |
图 4-A为正确检测出来的标牌图像。由于HOG特征对光学形变保持良好的不变性, 所以级联检测器正确检测到不同光照强度下的标牌。图 4-B为部分误检的负样本图像。负样本图像主要包括2类: 一类是与标牌具有相似的局部梯度特征的背景图像, 例如奶牛体部的花纹、背景中的栏杆等; 另一类是检测出的图像仅包含部分标牌, 未能包含所有数字, 这种情况下的图像往往检测到2张标牌, 一张是完全包含标牌的目标图像, 另一张是包含部分标牌的负样本图像。其原因是负样本图像中包含部分正确的局部梯度特征, 但是与正样本的交并比(intersection over union, IoU)小于设定的阈值, 因此作为误检的负样本出现。通过增加分类器的级数和减小每一级最大误检率可有效减少上述负样本的数量。图 4-C为从漏检的图像中截取的像素为100×200的标牌图像。在拍摄过程中, 奶牛的活动(例如行走、低头、扭头)会造成所佩戴标牌发生几何位置的变化, 使标牌并不处于垂直位置。当这种变化量较大, 包含标牌图像的局部梯度特征也会发生变化, 导致级联检测器不能准确检测到图像中的标牌。

|
图 4 部分检测结果 Fig. 4 Partial test results |
针对上述标牌几何位置变化的问题, 提出1种多角度检测的识别方法, 对于未检测到目标的图像, 将其进行旋转, 使图像中的标牌近似处于竖直位置, 再进行检测。在未被检测出目标的图像中随机选择201张图像, 经统计图像在-40°、-30°、-20°、-10°、10°、20°、30°、40°(逆时针为正)旋转角度下级联检测器正确检测出的目标数分别为0、0、7、55、94、30、6、3。通过旋转未定位到标牌的图像, 共检测出195个目标。当图像逆时针旋转10°时, 检测出的目标数最多, 当旋转角度为-10°时次之, 其次是20°, 其余旋转角度下检测到的目标数较少。考虑到检测的实时性要求, 确定多角度检测的具体流程如图 5所示。将图像送入检测器中进行检测, 若检测到目标则检测结束; 若未检测出目标时, 将图像进行旋转再次送入检测器中检测, 旋转角度α依次取10°、-10°、20°和-20°; 若图像经过4次旋转依然未检测到目标, 则检测结束。经过判断是否检测到目标和对图像的旋转操作, 可以有效提高目标的检测率和检测效率。

|
图 5 多角度检测的流程 Fig. 5 Process of multi-angle detection |
采用多角度检测的方法对测试集图像进行测试试验。从表 2可以看出: 多角度检测方法在不明显降低准确率的前提下显著提高召回率, 召回率从之前的38%~47%提高到74%~81%。其中当最大误检率为0.25, 分类器级数为13时, 准确率达到96.98%, 召回率达到80.23%, 是综合准确率和召回率因素表现最好的级联检测器模型。
| 最大误检率 Maximum falsedetection rate |
分类器级数 Number ofclassifiers |
准确率/% Precision |
召回率/% Recall |
最大误检率 Maximum falsedetection rate |
分类器级数 Number ofclassifiers |
准确率/% Precision |
召回率/% Recall |
|
| 0.45 | 19 | 67.49 | 74.55 | 0.35 | 12 | 86.65 | 81.14 | |
| 0.45 | 21 | 94.27 | 74.77 | 0.25 | 13 | 96.98 | 80.23 | |
| 0.35 | 15 | 98.24 | 76.14 | 0.30 | 13 | 95.98 | 75.91 | |
| 0.35 | 13 | 90.31 | 78.41 | 0.40 | 13 | 79.81 | 76.36 |
但是, 多角度检测方法只能识别出图像中发生平面内旋转的标牌, 对于绕平面发生旋转的目标依然不能将其准确识别出来。但是这种情况在所有图像中所占比例较少。
2.5 与非监督学习方法的对比传统目标检测方法主要基于颜色特征和边缘特征, 本文提出的级联检测器标牌定位方法是1种基于HOG特征的监督学习算法, 将本方法与基于颜色特征和边缘特征的奶牛颈环ID定位方法进行比较。由于图像中包含大量的背景信息, 背景中的草地、树木、奶牛身上的花纹等的边缘都会对定位造成大量干扰(图 6), 且待检测目标较小, 不具有明显的特征, 因此采用基于边缘特征的检测方法未能检测出标牌。

|
图 6 基于边缘特征的标牌定位方法 Fig. 6 Sign location method based on edge feature |
基于颜色特征的颈环标牌定位过程包含以下步骤: 1)将原始RGB图像转换为HSV图像并进行归一化; 2)根据蓝色标牌在HSV空间的颜色分量范围, 将同时满足条件0.6 < H < 1、0.5 < S < 1和0.2 < V < 1的像素点值置为1, 其余置为0;3)对图像进行膨胀和腐蚀操作以平滑图像轮廓; 4)计算各连通域的面积并找出面积最大的连通域, 填充其内部区域; 5)将经过上述处理的二值图像与原始RGB图像的灰度图像相乘, 从而获得标牌的灰度图像; 6)经过多次试验, 设置全局阈值为0.4, 将灰度图像转换为二值图像; 7)统计每行和每列的白色像素个数, 去除多余的背景像素, 根据定位结果找到原始RGB图像中的标牌位置。对测试集的图像进行测试, 结果显示该方法的准确率为36.34%, 召回率为31.97%, 定位精度显著低于基于级联检测器的标牌定位方法。图 7为采用基于级联检测器和基于颜色特征的检测方法对同一张图像的定位结果对比。采用基于颜色特征的目标检测方法进行定位时, 影响定位精度的因素有标牌上的污渍沾染和光照强度变化等。污渍沾染和光照强度变化会引起标牌部分区域或整体区域亮度较低, 所对应的HSV分量不在指定的阈值区间内, 从而导致该区域未能根据颜色特征定位到标牌。

|
图 7 基于级联检测器(A)和基于颜色特征(B)的检测方法对比 Fig. 7 Comparison of detection methods based on cascade detector(A)and color feature(B) |
检测出来的标牌图像亮度不均、包含大量冗余信息, 不能直接作为字符识别模型的输入。所以对图像进行字符分割, 将单个字符从整张图像中分割出来。字符分割包含以下几个步骤。
1) 灰度化处理。通过标牌定位获得的图像为RGB图像, 为了减少数据处理时的冗余数据量, 保留主要信息, 对图像进行灰度化处理。采用加权平均法将R、G、B这3个分量合成为1个值:
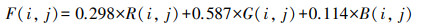
|
(6) |
2) 灰度变换。部分图像亮度较低导致图像中的数字不清晰, 为了改善图像质量, 对灰度图像进行线性变换, 增加图像的对比度。经过多次试验, 发现图像的灰度直方图主要集中在前半段, 因此将灰度图像中[0.05, 0.6]之间的灰度值映射到[0 1]中。
3) 二值化分割。采用最大类间方差法(Otsu)自动选择灰度图像二值化最佳阈值, 将灰度图像转换为二值化图像, 实现图像中数字与背景分割(白色像素代表目标, 黑色像素代表背景), 从而提取出字符。
4) 去除四周背景像素。通过统计图像左右两侧、上下两侧的每一行和每一列的黑白跳变个数以及白色像素的个数确定图像四周的背景区域, 并将其裁去。
5) 形态学处理。估计图像中目标面积与总面积的比值, 若大于某一阈值(t1), 对图像进行开运算; 若小于阈值(t2), 对图像进行闭运算。开运算和闭运算均采用2×2的单位矩阵作为模板。经过多次试验, 当t1=0.365、t2=0.235时形态学操作效果最好。删除图像中面积小于50的连通区域, 以去除多余的干扰像素。
6) 断开连续的文字。若图像中的干扰像素存在于2个数字之间使其处于连通状态, 会对后续的字符分割造成较大的影响。因此以第1行为起点, 统计连续出现白色像素的行数, 若大于图像高度的1/3, 则在上述行中寻找白色像素最少的那一行作为断开点, 将此行所有像素置为0(背景)。
7) 字符分割。由于图像中部分字符内部不连通, 故采用统计直方图的方法分割字符。以第1行为起点, 统计连续出现白色像素的行数, 若大于图像高度的1/5, 则将上述行裁剪下来作为分割出来的单个字符; 否则认为是干扰像素, 将上述行的像素值置为0(背景)并裁去。继续分割直到分割出4个字符。
8) 字符归一化。为了便于后续的字符识别, 将分割出来的图像采用双三次差值法归一化为28×28。
经过上述操作, 彩色的标牌图像被分割成4张分别包含单个字符的二值图像, 且图像中的字符为白色, 背景为黑色。
3.2 字符分割结果将级联检测器检测出来的正样本进行字符分割处理, 得到单个字符图像。级联检测器定位得到的354张标牌图像共分割出1 062张字符图像, 其中8张标牌中的9个字符对应的字符图像是空白的, 标牌的完整检出率为97.74%, 字符的检出率为99.15%。
造成部分标牌分割失败的原因主要有2个: 1)部分图像由于整体亮度较低或者光照不均匀, 二值化分割后字符内部断开, 经过形态学变换等处理后, 导致对应的字符丢失。2)对于连通的字符, 未能找到正确的分割点, 将2个字符分割到同一张图像中, 从而缺少1张字符图像。图 8为分割失败的标牌。

|
图 8 分割失败的标牌 Fig. 8 Signs of failed segmentation A. 未完整分割出字符的标牌图像The sign image with incomplete character segmentation; B. 由于连通字符未正确断开造成分割失败的标牌图像Sign images that fail to be segmented due to improper disconnection of connected characters. a. 原图像The original image; b. 二值化后的图像Image after binarization; c. 形态学处理后的图像Morphologically processed image; d. 最终分割出来的4张字符图像4 character images finally segmented. |
根据单个字符图像的像素信息判断字符的分类, 是标牌识别的最后一步。常见的字符识别方法有模板匹配法、特征分析匹配法、机器学习法[22]。本文所要识别的标牌字符相较于车牌字符识别具有更大的挑战性。在拍摄奶牛侧视行走图像时, 在奶牛和相机之间有2个约1 cm宽的电子围栏, 围栏在部分标牌上留下白色直线, 对标牌上的字符识别造成影响。另外, 标牌的几何位置变化导致字符的几何形态的改变、标牌上可能存在的污渍等, 都增加了字符识别的难度。
卷积神经网络作为深度学习中的一种, 在处理图像和辨别语音方面有着相当大的优越性[23], 能适应图像中目标的位置移动、大小调整、拉伸弯折的变化, 且图像可以直接作为网络的输入, 避免了传统识别算法中复杂的特征提取和数据重建的过程。
4.1 卷积神经网络的构建卷积神经网络的基本结构有输入层、卷积层、池化层、全连接层及输出层[24]。卷积层是卷积神经网络的核心, 对输入图像进行卷积运算并加上偏置项, 通过激活函数得到其特征图[25]。池化层在卷积层之后, 对卷积操作得到的特征图进行降采样, 提取最显著的特征。全连接层整合得到的局部特征, 计算样本属于每个类别的概率, 通过误差反向传播算法(back propagation), 调整网络各层的权重和偏置参数, 从而完成卷积神经网络的训练。
LeNet-5是LeCun等[26]在1998年提出的卷积神经网络算法, 用于解决手写数字的识别问题。本文的字符识别任务与LeNet-5的识别任务相似, 都是对数字的识别, 但是用已训练好的LeNet-5模型识别本文中的数字, 没有达到理想的效果。其原因包括以下方面: 1)本文所识别的数字为打印体, 与手写数字的特征存在一定差异。2)用于训练LeNet-5的mnist数据集图像中的数字较细, 位置集中, 且四周有留白, 没有多余的干扰像素。而本文所识别的数字图像的有效信息可能分布在整个图像中, 数字四周可能会有干扰像素。图 9为mnist数据集中的手写数字图像和本文要识别的数字图像。

|
图 9 手写数字图像(A)和本文要识别的数字图像(B) Fig. 9 Handwritten digital images(A)and digital imagesto be recognized in this article(B) |
本文在LeNet-5模型的基础上进行了一些改进, 构建1个新的数字识别模型, 改进后的基本结构如图 10所示。为了达到足够的感受野并减少计算量, 卷积神经网络中采用3层卷积层(C1、C3、C5), 每一层的卷积核大小均为3×3, 步长为1。经过多次调整参数, 发现当3个卷积层的特征图个数分别为8(C1)、16(C3)、32(C5)时, 模型的识别率和效率最高。由于图像中的数字位置分布不均匀, 需要保留边界信息, 因此采用数字0填充图像矩阵边界, 使输出图像与输入图像具有相同的尺寸。卷积后的特征图进行批量标准化处理(batch normalization), 以提高网络的训练速度。采用非线性激活函数ReLU增加神经网络模型的稀疏性, 使网络能够拟合复杂的非线性函数。最大池化层(S2、S4)的池化子区域的大小为2×2, 步长为2。全连接层的输出为10, 对应10个分类。采用softmax回归函数对全连接层的输出进行归一化。采用交叉熵损失函数(cross entropy)计算损失, 更新神经网络各层的权重和偏置参数。

|
图 10 卷积神经网络结构 Fig. 10 Structure of convolutional neural network |
在深度学习中, 用来训练的数据规模越大, 模型的泛化能力和识别准确性越好。考虑到从上一步分割出来的数据量较少, 且存在数据不平衡问题, 所以在训练模型之前通过图像数据增强来扩大用于训练的数据量。在真实场景下, 奶牛标牌上的数字通常会发生几何位置的变化, 因此在增强数据时, 通过对原始数据进行随机的平移和旋转变换得到新的数据, 旋转角度为(-10°, 10°), 沿垂直和水平方向均进行平移, 平移距离为(-3, 3)。经过数据增强后, 最终每个数字的图像数量均在4 000张左右, 总的图像数据量在36 000张左右。
训练时的优化算法采用动量随机梯度下降算法(stochastic gradient descent momentum, SGDM), 优化算法的作用是对损失函数进行迭代优化。SGDM算法引入一阶动量加速梯度下降, 抑制振荡, 加快收敛。训练时初始学习率为0.01。
为了更客观地评估模型的准确性, 采用十折交叉验证训练卷积神经网络。具体实现方法: 将数据集分成10份, 轮流将其中9份作为训练集, 另外1份作为验证集, 将10次结果的均值作为评价模型精度的标准。10次训练中验证集的平均正确率为98.10%。
4.3 字符识别结果将测试集图像中分割得到的字符图像放入训练好的字符识别模型中测试模型的性能。结果显示: 在正确分割出的1 053张字符图像中共准确识别出983个字符, 字符识别的准确率为93.35%;在346张标牌中, 正确且完整地识别出300张, 标牌识别的准确率为86.71%。基于卷积神经网络的字符识别模型能够适应不同干扰情况下的识别任务, 例如围栏在部分标牌上留下的白色直线、分割过程中未被去除的多余干扰像素以及缺失的部分像素信息。
但是, 对于分割失败造成的字符重叠, 模型无法正确识别出其中的任何一个字符。部分字符图像上的干扰像素或缺失部分对于模型的判断具有误导性, 例如在字符“0”中间存在的白色直线会使模型误认为是“8”。表 3所示为部分识别正确和识别错误的字符图像。
| 指标 Index |
正确识别的字符图像 Correctly identified character images |
错误识别的字符图像 Wrongly identified character images |
|||||||||||||||
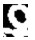 |
 |
 |
 |
 |
 |
 |
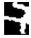 |
 |
 |
 |
 |
 |
 |
 |
 |
||
| 实际值 The actualvalue |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 1 | 4 | 5 | 6 | 9 | |
| 识别结果 Identification results |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 8 | 7 | 7 | 8 | 5 | 6 | |
本文的试验数据是在奶牛的饲养场景下采集的。在奶牛挤完奶后回到牛棚的过程中, 会经过一段平坦的直线过道, 在奶牛通过视野的过程中相机以固定的时间间隔连续拍照, 从而获取不同奶牛的多幅侧视行走图像。奶牛通过相机视野时奶牛的活动(例如行走、低头、扭头)不受人为干预, 拍摄是在自然光照条件下进行的。在实际应用场景中, 如果能根据多幅图像的识别结果最终处理成一个正确的标牌数字输出, 即可认为完成了奶牛标牌的识别任务。
因此将同一头奶牛的侧视行走图像放在同一个文件夹中, 采用最大误检率为0.25、分类器级数为13的级联检测器模型结合多角度检测方法检测同一个文件夹中的所有图像。然后采用投票制, 找出出现次数最多的识别结果作为最终输出。测试结果表明, 测试集的22头奶牛中21头奶牛的身份ID被正确识别, 系统的检测精度为95.45%。其中有一头奶牛未被正确识别出身份ID的原因是标牌上的数字上有大面积污渍, 造成多幅标牌图像均未分割出完整的字符, 导致识别失败。
奶牛的侧视行走图像中包含奶牛的多项体况信息, 例如跛足、呼吸检测、体况评分等, 通过识别侧视图像中奶牛颈部佩戴的颈环ID标牌识别奶牛个体, 可以将奶牛的体况信息和身份信息一一对应, 从而实现基于图像处理的奶牛多种信息融合感知系统。
5 结论1) 提出1种基于HOG特征的级联检测器结合多角度检测的定位方法, 能够解决复杂场景下由于目标偏转引起的检测率较低的问题。最终标牌定位的准确率为96.98%, 召回率为80.23%。相较于传统的标牌定位方法具有较高的精度和良好的鲁棒性。
2) 提出1种标牌的分割算法, 将单个字符的二值图像从标牌中分割出来。标牌的完整检出率为97.74%, 字符的检出率为99.15%。
3) 在LeNet-5的基础上优化了卷积神经网络的结构和参数, 通过图像数据增强技术增加了训练集中的字符图像并用于训练字符识别模型。单个字符识别准确率达到93.35%, 对连续图像序列中奶牛标牌ID的识别率为95.45%, 识别模型对光线变化、污渍沾染、旋转角度等具有良好的鲁棒性, 具有代替传统动物个体识别方法的潜力。
| [1] |
王海彬, 王洪斌, 肖建华. 奶牛精细养殖信息技术进展[J]. 中国奶牛, 2009(3): 15-17. Wang H B, Wang H B, Xiao J H. Advances in information technology of dairy cow fine breeding[J]. China Dairy Cattle, 2009(3): 15-17 (in Chinese). DOI:10.3969/j.issn.1004-4264.2009.03.005 |
| [2] |
何东健, 刘冬, 赵凯旋. 精准畜牧业中动物信息智能感知与行为检测研究进展[J]. 农业机械学报, 2016, 47(5): 231-244. He D J, Liu D, Zhao K X. Review of perceiving animal information and behavior in precision livestock farming[J]. Transactions of the Chinese Society for Agricultural Machinery, 2016, 47(5): 231-244 (in Chinese with English abstract). |
| [3] |
Shen W Z, Cheng F, Zhang Y, et al. Automatic recognition of ingestive-related behaviors of dairy cows based on triaxial acceleration[J]. Information Processing in Agriculture, 2020, 7(3): 427-443. DOI:10.1016/j.inpa.2019.10.004 |
| [4] |
Zhao K, Jin X, Ji J, et al. Individual identification of Holstein dairy cows based on detecting and matching feature points in body images[J]. Biosystems Engineering, 2019, 181: 128-139. DOI:10.1016/j.biosystemseng.2019.03.004 |
| [5] |
Yajuvendra S, Lathwal S S, Rajput N, et al. Effective and accurate discrimination of individual dairy cattle through acoustic sensing[J]. Applied Animal Behaviour Science, 2013, 146(1/2/3/4): 11-18. |
| [6] |
Cappai M G, Rubiu N G, Nieddu G, et al. Analysis of fieldwork activities during milk production recording in dairy ewes by means of individual ear tag(ET) alone or plus RFID based electronic identification(EID)[J]. Computers and Electronics in Agriculture, 2018, 144: 324-328. DOI:10.1016/j.compag.2017.11.002 |
| [7] |
于啸. 奶牛精量饲喂控制系统的研究[D]. 长春: 吉林大学, 2016. Yu X. Study on precise feeding control system for dairy cattle[D]. Changchun: Jilin University, 2016(in Chinese with English abstract). |
| [8] |
许译丹. 基于射频识别与传感技术的种鹅个体产蛋识别及定位方法研究[D]. 大庆: 黑龙江八一农垦大学, 2019. Xu Y D. Research on identification and location method of egg laying of individual goose based on RFID and sensing technology[D]. Daqing: Heilongjiang Bayi Agricultural University, 2019(in Chinese with English abstract). |
| [9] |
Voulodimos A S, Patrikakis C Z, Sideridis A B, et al. A complete farm management system based on animal identification using RFID technology[J]. Computers and Electronics in Agriculture, 2010, 70(2): 380-388. DOI:10.1016/j.compag.2009.07.009 |
| [10] |
Chapinal N, Tucker C B. Validation of an automated method to count steps while cows stand on a weighing platform and its application as a measure to detect lameness[J]. Journal of Dairy Science, 2012, 95(11): 6523-6528. DOI:10.3168/jds.2012-5742 |
| [11] |
Shen W Z, Hu H Q, Dai B S, et al. Individual identification of dairy cows based on convolutional neural networks[J]. Multimedia Tools and Applications, 2020, 79: 14711-14724. DOI:10.1007/s11042-019-7344-7 |
| [12] |
何东健, 刘建敏, 熊虹婷, 等. 基于改进YOLO v3模型的挤奶奶牛个体识别方法[J]. 农业机械学报, 2020, 51(4): 250-260. He D J, Liu J M, Xiong H T, et al. Individual identification of dairy cows based on improved YOLO v3[J]. Transactions of the Chinese Society for Agricultural Machinery, 2020, 51(4): 250-260 (in Chinese with English abstract). |
| [13] |
丁静, 沈明霞, 刘龙申, 等. 基于机器视觉的断奶仔猪腹泻自动识别方法[J]. 南京农业大学学报, 2020, 43(5): 969-978. Ding J, Shen M X, Liu L S, et al. Automatic recognition of diarrhea in weaned piglets based on machine vision[J]. Journal of Nanjing Agricultural University, 2020, 43(5): 969-978 (in Chinese with English abstract). DOI:10.7685/jnau.201908003 |
| [14] |
Xia M, Cai C. Cattle face recognition using sparse representation classifier[J]. ICIC Express Letters, Part B: Applications, 2012, 3: 1499-1505. |
| [15] |
Bengio Y. Learning deep architectures for AI[J]. Foundations & Trends® in Machine Learning, 2009, 2(1): 1-127. |
| [16] |
Kim H T, Choi H L, Lee D W, et al. Recognition of individual Holstein cattle by imaging body patterns[J]. Asian Australasian Journal of Animal Sciences, 2005, 18(8): 1194-1198. DOI:10.5713/ajas.2005.1194 |
| [17] |
赵凯旋, 何东健. 基于卷积神经网络的奶牛个体身份识别方法[J]. 农业工程学报, 2015, 31(5): 181-187. Zhao K X, He D J. Recognition of individual dairy cattle based on convolutional neural networks[J]. Transactions of the Chinese Society of Agricultural Engineering, 2015, 31(5): 181-187 (in Chinese with English abstract). DOI:10.3969/j.issn.1002-6819.2015.05.026 |
| [18] |
Bergamini L, Porrello A, Dondona A C, et al. Multi-views embedding for cattle re-identification[C]//2018 14th International Conference on Signal-Image Technology & Internet-Based Systems(SITIS), November 26-29, 2018, Las Palmas de Gran Canaria, Spain. IEEE, 2018: 184-191.
|
| [19] |
崔华, 张骁, 郭璐, 等. 多特征多阈值级联AdaBoost行人检测器[J]. 交通运输工程学报, 2015, 15(2): 109-117. Cui H, Zhang X, Guo L, et al. Cascade AdaBoost pedestrian detector with multi-features and multi-thresholds[J]. Journal of Traffic and Transportation Engineering, 2015, 15(2): 109-117 (in Chinese with English abstract). DOI:10.3969/j.issn.1671-1637.2015.02.014 |
| [20] |
刘春生. 复杂大背景下交通标志快速鲁棒的检测和识别研究[D]. 济南: 山东大学, 2016. Liu C S. Research of fast and robust traffic sign detection and recognition in complicated environment[D]. Jinan: Shandong University, 2016(in Chinese with English abstract). |
| [21] |
Sun Y, Wang X G, Tang X O. Deep convolutional network cascade for facial point detection[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition, June 23-28, 2013, Portland, OR, USA. IEEE, 2013: 3476-3483.
|
| [22] |
陈学保. 车牌字符识别算法的研究[D]. 重庆: 重庆大学, 2013. Chen X B. Research on the algorithm of license plate character recognition[D]. Chongqing: Chongqing University, 2013(in Chinese with English abstract). |
| [23] |
张弛, 沈明霞, 刘龙申, 等. 基于机器视觉的新生仔猪目标识别方法研究与实现[J]. 南京农业大学学报, 2017, 40(1): 169-175. Zhang C, Shen M X, Liu L S, et al. Newborn piglets recognition method based on machine vision[J]. Journal of Nanjing Agricultural University, 2017, 40(1): 169-175 (in Chinese with English abstract). DOI:10.7685/jnau.201602017 |
| [24] |
周飞燕, 金林鹏, 董军. 卷积神经网络研究综述[J]. 计算机学报, 2017, 40(6): 1229-1251. Zhou F Y, Jin L P, Dong J. Review of convolutional neural network[J]. Chinese Journal of Computers, 2017, 40(6): 1229-1251 (in Chinese with English abstract). |
| [25] |
易超人, 邓燕妮. 多通道卷积神经网络图像识别方法[J]. 河南科技大学学报(自然科学版), 2017, 38(3): 41-44. Yi C R, Deng Y N. Image recognition method of multi-channel convolutional neural network[J]. Journal of Henan University of Science & Technology(Natural Science), 2017, 38(3): 41-44 (in Chinese with English abstract). |
| [26] |
LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. DOI:10.1109/5.726791 |