
文章信息
- 梁敬东, 崔丙剑, 姜海燕, 沈毅, 谢元澄
- LIANG Jingdong, CUI Bingjian, JIANG Haiyan, SHEN Yi, XIE Yuancheng
- 基于word2vec和LSTM的句子相似度计算及其在水稻FAQ问答系统中的应用
- Sentence similarity computing based on word2vec and LSTM and its application in rice FAQ question-answering system
- 南京农业大学学报, 2018, 41(5): 946-953
- Journal of Nanjing Agricultural University, 2018, 41(5): 946-953.
- http://dx.doi.org/10.7685/jnau.201801055
-
文章历史
- 收稿日期: 2018-01-31




2. 南京农业大学国家信息农业工程技术中心, 江苏 南京 210095
2. National Engineering and Technology Center for Information Agriculture, Nanjing Agricultural University, Nanjing 210095, China
问答系统融合了信息检索、自然语言处理等技术,可以对用户问题进行分析后直接返回答案[1],是很多领域用来解决常见问题的有效途径[2-4]。目前我国农技服务还不完善,农民在水稻种植过程中遇到的很多问题难以得到及时解决。构建一个水稻FAQ问答系统,对农民在水稻种植过程中遇到的问题进行分析,计算其与水稻FAQ中问题的相似度,找出与其最匹配的问题,并将对应的答案返回给用户,将对提高水稻产量和质量有重要意义。
句子相似度计算是FAQ问答系统的核心。目前,汉语句子相似度计算方法主要有以下3类[5]:
1) 基于字符串的方法。该方法是通过比较2个句子中词语的重复和相似程度、词序相似度等信息来衡量句子相似度[6-7]。常见方法有编辑距离、余弦相似度等。
2) 基于向量空间模型的方法。该方法把句子用向量来表示,计算2个句子的相似度就是计算2个向量的距离。传统的向量空间模型一般都是基于词袋模型(bag of words,BOW),其基本思想是对于1个文档,假设文中每个词语的出现都与上下文无关,忽略词序、语法和句法等要素。具体的方法有VSM[8]、LSA[9]等。近年来文本向量化的一种主流方法是神经网络词向量[10],一些用于生成词向量的工具如word2vec[11]、GloVe等[12]也被提出。基于神经网络的词向量模型可以从大规模的文本数据中自动学习数据的本质信息,得到低维实数向量,很好地解决了传统的词向量模型因为词语独立性假设带来的语义建模困难和维度爆炸问题。基于神经网络词向量计算句子相似度的相关研究均取得了良好的效果:如李晓等[13]在word2vec的基础上融合了句子的结构信息来计算句子相似度;He等[14]在word2vec的基础上使用卷积神经网络进行句子相似度研究。
3) 基于语义资源的方法。该方法利用语义资源库如WordNet、HowNet(知网)等来度量词语间的相似性,计算句子的相似度。贾可亮等[15]首先计算句子1中每个词语与句子2中每个词语之间的相似度,把最大相似度值之和除以句子1的长度作为句子1对句子2的相似度;同理计算句子2对句子1的相似度,最后把2个相似度的平均值作为2个句子的相似度。
由于单一算法具有一定的不足,有学者综合运用2种或多种方法的多重信息融合的句子相似度算法[16-17]。本文在综合分析常用句子相似度计算方法的基础上,建立一种结合word2vec和LSTM神经网络的句子相似度模型,并在水稻FAQ中的问句上进行验证,探讨该模型在水稻FAQ问答系统中应用的可行性,并基于该模型开发面向农户的水稻FAQ问答系统,研究结果将为农户提供简洁实用的智能化问答服务,以解决农户在水稻种植过程中遇到的问题。
1 水稻“常问问题-答案”的采集和处理 1.1 常问问答对的获取选择“专家在线系统”“种植问答网”“南京市农业委员会”等网站,用Python语言编写网络爬虫进行数据抓取。共抓取到涉及水稻栽培、施肥、除草、病虫害防治等方面的2万余对问答数据,选取其中3 007个优质问答对存入数据库作为常问问题集和答案。比如一个问答对:
问题:水稻催芽最适温度是多少?
答案:温度控制在25~28 ℃。
1.2 问句分词中文的词语之间是连续的,需要首先对文本进行分词。目前中文分词技术已十分成熟,多数分词工具如中国科学院的ICTCLAS,哈尔滨工业大学的LTP、jieba等,准确率都达到了95%以上。本文使用jieba分词器,并加入农业领域词典,使得领域词汇如“穗颈瘟”“稻曲病”等可以被正确切分。分词前后的问句如表 1所示,词间用空格作为分割。
| 处理前的问句Pre-processing questions | 处理后的问句Post-processing questions |
| 水稻施肥过多,出现青黑现象,怎样处理? | 水稻 施肥 过多 出现 青黑 现象 怎样 处理 |
| 影响水稻分蘖的环境条件有哪些? | 影响 水稻 分蘖 的 环境 条件 有 哪些 |
| 稻田有大量福寿螺,怎样防治? | 稻田 有 大量 福寿螺 怎样 防治 |
本试验使用word2vec对句子进行向量化表示,以作为LSTM神经网络的输入。
word2vec[11]有2种模型:CBOW(continuous bag-of-words model,连续词袋模型)和Skip-Gram(continuous skip-gram model)。CBOW依据上下文预测当前单词,而Skip-Gram则是根据当前单词预测上下文。2种模型的结构都包括3层:输入层、投影层和输出层,如图 1所示[18]。输入层和输出层是词语的one-hot编码,w(t)代表当前词语,w(ti)(0<i≤k)代表w(t)的上下文,k代表窗口大小,即上下文词语的数量。训练开始前,先随机初始化输入层权重矩阵W和输出层权重矩阵W′,训练过程中通过不断减小输出层结果与真实结果的误差来迭代更新W和W′。模型训练结束后得到输入层权重W,即词向量表,W的维度即为词向量的维度。每个词语的one-hot编码与W的内积即为该词语的向量值。相似或相关的词语其上下文语境也相似,word2vec考虑了词语的上下文信息,因此可以得到包含词语语义信息的词向量。

|
图 1 word2vec的2种模型 Figure 1 The two models of word2vec |
采用CBOW模式,词向量维度设置为100,训练窗口设置为5,在农业领域语料库中训练词向量模型。训练结束后,抽取几个词语的前3个近似词,结果如表 2所示。如与“水稻”最相似的是“早稻”,原因是这2个词语有相似的上下文语境。由此可以看出,word2vec模型能很好地从语义层面计算2个词语的相似度。
| 输入词 Input word |
近似词 Similar words |
余弦距离 Cosine distance |
| 水稻 | 早稻 小麦 超级稻 |
0.729 0.720 0.676 |
| 插秧 | 栽秧 移栽 栽插 |
0.839 0.776 0.769 |
| 拔节 | 拔节期 孕穗 抽穗 |
0.792 0.783 0.766 |
RNN(recurrent neural networks)是一种具备保持信息能力的神经网络,可以将信息从网络结构的上一层传输到下一层。但在RNN的训练中,存在梯度消失问题[19]。Hochreiter等[20]提出了一种特殊类型的RNN,即LSTM,用一个记忆单元对原RNN中的隐层节点进行替换,可以学习长期依赖信息。这个记忆单元由记忆细胞、输入门、遗忘门和输出门组成,其中记忆细胞用来存储和更新历史信息,3个门结构通过Sigmoid函数来决定信息的保留程度。记忆单元的结构如图 2所示[21]。

|
图 2 LSTM记忆单元结构 Figure 2 Structure of LSTM memory cell |
LSTM的计算过程如公式(1)—公式(6)所示。

|
(1) |
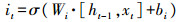
|
(2) |
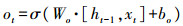
|
(3) |

|
(4) |
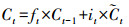
|
(5) |
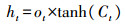
|
(6) |
式中:σ、tanh为Sigmod函数和双曲正切函数;W、b为权重矩阵和偏置向量;x、h为记忆单元的输入和输出;ft、it、ot为遗忘门、输入门和输出门;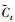
公式(1)—(3)分别是遗忘门、输入门和输出门的计算过程,根据当前时刻的输入数据xt和上一时刻的输出信息ht-1,分别乘以各自的权重矩阵,再与各自的偏置量相加,最后经过Sigmod作用得到3个门的结果。公式(4)和(5)用来更新记忆细胞状态,首先通过tanh对ht-1和xt进行计算,得到当前时刻记忆单元的候选值
LSTM神经网络的结构决定了其对处理序列化数据很有优势,可以有效保持较长时间的记忆,更好地获取整个句子的语义特征,而且已在许多自然语言处理任务如情感分析、机器翻译中成功应用,因此本试验选用LSTM来计算句子的相似度。
2.2 句子相似度模型构建以LSTM为基础设计句子相似度模型,由输入层、嵌入层、LSTM层、全连接层和输出层5部分组成,模型结构如图 3所示。输入层把每个词语用其在词典中的位置编号表示得到一个词语编号序列,并统一为同等长度,然后传递给嵌入层。嵌入层采用word2vec模型将词语编号序列映射为词向量序列后作为LSTM层的输入。2个LSTM对之前部分处理得到的序列数据进行学习,将学习到的结果拼接后作为全连接层的输入,并使用Dropout[22]来防止过拟合,使用Batch normalization[23]来提高收敛速度,最终输出2个句子的相似度值。

|
图 3 句子相似度模型结构图 Figure 3 Structure of the model of sentence similarity |
模型的输入为2个句子及其相似性标签。首先将3 007个水稻常问问题进行人工组合并标注其相似性,具体的处理步骤如下:
1) 问题归类。把3 007个常问问题集用集合QS={q1,q2,…,q3 007}表示,其中qn(1≤n≤3 007)代表 1个具体问题。对QS进行归类,把相似的问题归为一类,得到653类问题,即QS′={Q1,Q2,…,Q653},其中Qm={qm1,qm2,…,qmk}(1≤m≤653,1≤k)代表由1个或多个不同问法的相似问题组成的一类问题的集合,qmk代表问题类Qm中的1个具体问题。
2) 问题组合。对于QS′中的1个子集合Q1={q11,q12,…,q1k}中的1个具体问题q11,与q11相似的问题有{q12,q13,…,q1k},共有k-1个。与q11不相似的问题存在于Q1的补集CQSQ1中,由2部分组成:一是随机从CQSQ1中取出(k-1)/2个问题;二是从CQSQ1中取出与q11有最多相同关键字的前(k-1)/2个问题。这样可以尽量避免使神经网络认为2个句子相同关键词越多越相似,从而更好地从语义层面学习2个句子的特征。
具体流程如图 4所示。

|
图 4 数据集构造流程图 Figure 4 The flow chart of dataset construction |
经过以上处理,得到32 072个问题对,其中question 1和question 2表示分词处理后的2个问题,similarity表示其相似性,1代表相似,0代表不相似(表 3)。
| 问句1 Question 1 | 问句2 Question 2 | 相似性Similarity |
| 水稻 稻瘟病 如何 防治 | 水稻 稻瘟病 的 防治 方法 有 哪些 | 1 |
| 如何 治疗 水稻 细菌性条斑病 | 当前 水稻 细菌性条斑病 综合 防治 措施 有 哪些 | 1 |
| 水稻 恶苗病 有 哪些 特征 | 水稻 恶苗病 最 有效 的 防治 方法 有 哪些 | 0 |
| 稻田 养鸭 需要 注意 什么 | 水稻田 养鱼 有 什么 特别 注意 的 问题 | 0 |
试验环境为:CPU Intel(R)Core(TM)i5-3210M四核;内存8 G;操作系统Deepin15.4 64位。试验把32 072个问题对按7 : 2 : 1的比例划分为训练集、验证集和测试集,使用随机梯度下降法[24]对模型权重进行更新,BatchSize设为16,epoch设为100,训练情况如图 5所示。随着训练轮数的增加,验证集上损失函数值呈下降趋势,预测损失逐步变小,同时准确率呈上升趋势,说明模型在不断迭代更新参数过程中性能得以优化。当训练轮数达到80左右时,准确率达到了95.3%,损失函数值降到了13.0%,准确率和损失值都基本达到收敛状态。

|
图 5 损失函数值和准确率在验证集上的变化情况 Figure 5 The change of loss function value and accuracy in the validation dataset |
除了本试验中的基于word2vec和LSTM的相似度计算方法外,还比较了前文提到的基于word2vec和CNN的方法[14]、基于HowNet的方法[15]以及基于词向量余弦距离的方法。以上3种方法分别对应简称w2v_CNN、HowNet和w2v_cosine,其中w2v_cosine是把1个句子中的多个词语的词向量加和求平均作为句子向量,然后计算2个句子向量的余弦距离作为2个句子的相似度值。
试验采用时间复杂度、准确率和ROC(receiver operating characteristic curve)来衡量模型的性能。时间复杂度由每种算法在测试集上进行10次相似度计算的平均时长决定。
准确率=正确识别出问题对的相似性数量/问题对的总数量。
相似度值为1个[0, 1]之间的实数,越接近于1表示相似性越高,反之则越低。为计算模型的准确率,需要把相似度值根据一定规则转换为0或1。目前并没有一个权威的标准可以衡量句子的相似度[25],一般是通过人为设定阈值作为相似或者不相似的分界[17, 26]。本文在0.1~0.9范围内以0.01为间隔设置阈值,当相似度值大于该阈值时认为2个句子相似,否则不相似,以此统计每种算法在不同阈值下的准确率,最后取各种算法的最高准确率进行比较。
用ROC来评估模型的好处是当测试集中正负样本的分布变化时,ROC能够保持不变,可以更好地判断模型的优劣。模型的分类效果越好,ROC越靠近坐标轴的左上角。
3.2.3 结果与分析从表 4可以看出,相比较于其他方法,本文基于word2vec和LSTM的相似度模型对句子相似度的计算结果更符合人的直观印象。
| 测试问句Test questions | 相似度值Similarity value | |||
| HowNet | w2v_cosine | 本文方法Method of this paper | ||
| 1 | 水稻 烂秧 的 主要 原因 是 什么 水稻 防止 烂秧 的 主要 途径 是 什么 |
0.771 | 0.913 | 0.601 |
| 2 | 水稻 出现 早穗 现象 的 主要 原因 是 什么 水稻 出现 早穗 现象 是 什么 原因 |
0.786 | 0.916 | 0.918 |
| 3 | 水稻 为什么 要 进行 浸种 催芽 水稻 浸种 前 为什么 要 晒种 晒种 要 注意 什么 |
0.527 | 0.826 | 0.218 |
| 4 | 稻瘟病 的 防治 方法 水稻 稻瘟病 防治 要点 |
0.460 | 0.873 | 0.997 |
| 5 | 北方 水稻 稻曲病 的 认 别 与 防治 措施 有 哪些 水稻 稻瘟病 的 识别 方法 有 哪些 |
0.513 | 0.802 | 0.001 |
各方法在测试集上的性能如表 5和图 6所示。模型在准确率和ROC曲线上的表现显著优于其他几种方法。HowNet分类效果最差,原因是HowNet对农业领域词汇收录较少,无法计算未收录词语之间的相似度;w2v_cosine分类效果较差的原因是word2vec虽然解决了文本表示面临的数据稀疏和词语间语义关系建模困难的问题,但是机械地把词向量组合起来作为句子的向量,并不能代表句子的语义,往往会出现2个句子相同或相近的关键词越多则相似度越高的现象;虽然w2v_CNN方法也取得了较高的准确率,但是由于CNN更适合用于图像处理,对于序列化的文本数据,LSTM更有优势,可以更好地获取整个句子的语义特征,因此本文的句子相似度模型在准确率和ROC曲线上有更好的表现。在时间效率上,本文的模型虽与w2v_consine方法有较大差距,但明显优于HowNet和w2v_CNN。
| 方法 Methods |
测试组数 Number of test groups |
正确组数 Correct number of groups |
准确率/% Accuracy |
耗时/s Spend time |
| HowNet | 3 207 | 1 726 | 53.8 | 53.20 |
| w2v_cosine | 3 207 | 2 177 | 67.9 | 0.75 |
| w2v_CNN | 3 207 | 2 787 | 86.9 | 19.36 |
| 本文方法 | 3 207 | 2 985 | 93.1 | 8.32 |

|
图 6 各方法的ROC曲线 Figure 6 ROC curves of different methods |
在基于word2vec和LSTM的句子相似度模型的基础上开发1个水稻FAQ问答系统,系统采用B/S体系结构,前端提供用户交互页面,后端使用MongoDB进行问答数据的存储。系统使用Django框架进行逻辑功能开发,主要功能包括:问句处理、问句相似度计算及答案抽取。该系统界面简洁直观,使用方便。
4 结论本研究将深度学习中的word2vec和LSTM引入到水稻FAQ问答系统的问句相似度计算中。用word2vec模型对词语向量化,使得相近或相关的词语其空间距离也更接近,较好地解决了传统文本表示存在的语义不足和维度灾难问题。利用LSTM神经网络对处理序列化数据的优势,可以更好地获取句子的语义特征。通过在3万余个水稻相关的问题对上进行模型训练和测试,测试集准确率达到了93.1%,因此本文方法明显优于HowNet、w2v_cosine和w2v_CNN。
基于该相似度模型开发的水稻FAQ问答系统,能准确匹配用户问题和水稻FAQ中的问题,并自动返回对应答案,不仅对水稻生产具有实际指导意义,而且促进了智慧农业的发展。
但本研究还存在一些不足,主要有2个方面:一是知识库构建部分需要花费大量人力;二是该模型的时间复杂度较高,实际应用中存在效率较低的问题。如何自动或半自动构建知识库、提高系统的效率将是下一步工作研究的重点。
| [1] |
郑实福, 刘挺, 秦兵, 等. 自动问答综述[J].
中文信息学报, 2002, 16(6): 46-52.
Zheng S F, Liu T, Qin B, et al. Overview of question answering[J]. Journal of Chinese Information Processing, 2002, 16(6): 46-52. DOI: 10.3969/j.issn.1003-0077.2002.06.007 (in Chinese with English abstract) |
| [2] |
沈奎林, 邵波, 赵华. 利用微信构建图书馆智能问答系统[J].
图书馆学研究, 2015(8): 75-80.
Shen K L, Shao B, Zhao H. Using WeChat to build a library intelligent question answering system[J]. Researches on Library Science, 2015(8): 75-80. (in Chinese with English abstract) |
| [3] |
张生泽, 王庆阳, 袁克虹. 基于电子病历大数据的问答系统[J].
医学信息学杂志, 2017, 38(3): 7-11.
Zhang S Z, Wang Q Y, Yuan K H. Question answering system based on the big data of electronic medical records[J]. Journal of Medical Informatics, 2017, 38(3): 7-11. DOI: 10.3969/j.issn.1673-6036.2017.03.002 (in Chinese with English abstract) |
| [4] |
郑颖, 金松林, 张自阳, 等. 基于本体的小麦病虫害问答系统构建与实现[J].
河南农业科学, 2016, 45(6): 143-146.
Zheng Y, Jin S L, Zhang Z Y, et al. Construction of question answering system related to wheat diseases and insect pests based on ontology[J]. Journal of Henan Agricultural Sciences, 2016, 45(6): 143-146. (in Chinese with English abstract) |
| [5] |
陈二静, 姜恩波. 文本相似度计算方法研究综述[J].
数据分析与知识发现, 2017, 6(6): 1-11.
Chen E J, Jiang E B. Review of studies on text similarity measures[J]. Data Analysis and Knowledge Discovery, 2017, 6(6): 1-11. (in Chinese with English abstract) |
| [6] |
杨思春. 一种改进的句子相似度计算模型[J].
电子科技大学学报, 2006, 35(6): 956-959.
Yang S C. An improved model for sentence similarity computing[J]. Journal of University of Electronic Science and Technology of China, 2006, 35(6): 956-959. (in Chinese with English abstract) |
| [7] |
钱丽萍, 汪立东. 基于中心短语及权值的相似度计算[J].
郑州大学学报(理学版), 2007, 39(2): 149-152.
Qian L P, Wang L D. Similarity measure based on center phrase and word weight[J]. Journal of Zhengzhou University(Natural Science Edition), 2007, 39(2): 149-152. DOI: 10.3969/j.issn.1671-6841.2007.02.035 (in Chinese with English abstract) |
| [8] | Salton G, Wong A, Yang C S. A vector space model for automatic indexing[J]. Communications of the ACM, 1975, 18(11): 613-620. DOI: 10.1145/361219.361220 |
| [9] | Landauer T K, Dumais S T. A solution to Plato ' s problem:the latent semantic analysis theory of acquisition, induction, and representation of knowledge[J]. Psychological Review, 1997, 104(2): 211-240. DOI: 10.1037/0033-295X.104.2.211 |
| [10] | Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003, 3(6): 1137-1155. |
| [11] | Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[EB/OL].[2014-04-20]. http://arxiv.org/pdf/1301.3781v3.pdf. |
| [12] | Pennington J, Socher R, Manning C D. GloVe: global vectors for word representation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. New York: Association for Computational Linguistics, 2014: 1532-1543. https://nlp.stanford.edu/projects/glove/ |
| [13] |
李晓, 解辉, 李丽杰. 基于Word2vec的句子语义相似度计算研究[J].
计算机科学, 2017, 44(9): 256-260.
Li X, Xie H, Li L J. Research on sentence semantic similarity based on Word2vec[J]. Computer Science, 2017, 44(9): 256-260. (in Chinese with English abstract) |
| [14] | He H, Gimpel K, Lin J. Multi-perspective sentence similarity modeling with convolutional neural networks[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2015: 1576-1586. http://ttic.uchicago.edu/~kgimpel/papers/he+etal.emnlp15.pdf |
| [15] |
贾可亮, 樊孝忠, 张禹. 基于HowNet语义相似度的FAQ研究[J].
计算机应用, 2007, 27(9): 2256-2257.
Jia K L, Fan X Z, Zhang Y. Research of FAQ based on the semantic similarities of HowNet[J]. Journal of Computer Applications, 2007, 27(9): 2256-2257. (in Chinese with English abstract) |
| [16] |
赵妍妍, 秦兵, 刘挺, 等.基于多特征融合的句子相似度计算[C]//全国第八届计算语言学联合学术会议论文集.北京: 清华大学出版社, 2005: 168-174.
Zhao Y Y, Qin B, Liu T, et al. Sentence similarity computing based on multi-feature fusion[C]//Proceedings of the Eighth China National Conference on Computational Linguistics. Beijing: Tsinghua University Press, 2005: 168-174(in Chinese with English abstract). http://cpfd.cnki.com.cn/Article/CPFDTOTAL-ZGZR200508001028.htm |
| [17] |
张琳, 胡杰. FAQ问答系统句子相似度计算[J].
郑州大学学报(理学版), 2010, 42(1): 57-61.
Zhang L, Hu J. Sentence similarity computing for FAQ question answering system[J]. Journal of Zhengzhou University(Natural Science Edition), 2010, 42(1): 57-61. (in Chinese with English abstract) |
| [18] |
熊富林, 邓怡豪, 唐晓晟. Word2vec的核心架构及其应用[J].
南京师范大学学报(工程技术版), 2015, 15(1): 43-48.
Xiong F L, Deng Y H, Tang X S. The architecture of Word2vec and its applications[J]. Journal of Nanjing Normal University(Engineering and Technology Edition), 2015, 15(1): 43-48. DOI: 10.3969/j.issn.1672-1292.2015.01.008 (in Chinese with English abstract) |
| [19] | Hochreiter S. Recurrent neural net learning and vanishing gradient[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 1998, 6(2): 107-116. DOI: 10.1142/S0218488598000094 |
| [20] | Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. DOI: 10.1162/neco.1997.9.8.1735 |
| [21] | Zaremba W, Sutskever I, Vinyals O. Recurrent neural network regularization[EB/OL].[2015-08-24]. http://arxiv.org/pdf/1409.2329v5.pdf. |
| [22] | Srivastava N, Hinton G, Krizhevsky A, et al. Dropout:a simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958. |
| [23] | Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]/Proceedings of the 32nd International Conference on Machine Learning. Lille: IMLS, 2015: 448-456. |
| [24] | Bottou L. Large-scale machine learning with stochastic gradient descent[C]//Proceedings of the 19th International Conference on Computational Statistics. Berlin: Springer-Verlag, 2010: 177-186. |
| [25] |
毛宇.中医药症状的中文分词与句子相似度研究[D].杭州: 浙江大学, 2017.
Mao Y. Research of Chinese word segmentation and sentence similarity on traditional Chinese medicine symptom[D]. Hangzhou: Zhejiang University, 2017(in Chinese with English abstract). http://cdmd.cnki.com.cn/Article/CDMD-10335-1017066894.htm |
| [26] |
黄姝婧, 张仰森. 基于多特征融合的句子相似度计算方法[J].
北京信息科技大学学报, 2017, 32(5): 45-49.
Huang S J, Zhang Y S. Sentence similarity calculation method based on multiple-features[J]. Journal of Beijing Information Science and Technology University, 2017, 32(5): 45-49. (in Chinese with English abstract) |