
文章信息
- 梁琨, 刘全祥, 潘磊庆, 沈明霞
- LIANG Kun, LIU Quanxiang, PAN Leiqing, SHEN Mingxia
- 基于高光谱和CARS-IRIV算法的‘库尔勒香梨’可溶性固形物含量检测
- Detection of soluble solids content in 'Korla fragrant pear' based on hyperspectral imaging and CARS-IRIV algorithm
- 南京农业大学学报, 2018, 41(4): 760-766
- Journal of Nanjing Agricultural University, 2018, 41(4): 760-766.
- http://dx.doi.org/10.7685/jnau.201709030
-
文章历史
- 收稿日期: 2017-09-18




2. 南京农业大学食品科技学院, 江苏 南京 210095
2. College of Food Science and Technology, Nanjing Agricultural University, Nanjing 210095, China
‘库尔勒香梨’作为梨果中主要的品种之一, 其内部品质如糖度, 以可溶性固形物含量(soluble solids content, SSC)作为重要评价指标。SSC值通常由糖度仪测得, 这种方法虽然准确, 但是具有破坏性、低效性、耗时性等缺点[1]。高光谱成像技术将图像信息与光谱信息相结合, 可以同时获取样本每个波长下的图像信息和每个像素点的光谱信息, 作为一种比较新颖强大的检测技术已广泛应用于农产品的无损检测[2]。高光谱成像采集的全波段光谱信息通常包含来自环境和仪器引起的噪声, 并且变量之间存在严重的冗余性和共线性, 导致校准模型运算复杂并影响预测的结果[3], 对光谱变量进行降维及优选可以获得更优化的模型[4]。
目前, 针对高光谱成像技术的梨果SSC的特征变量筛选问题, 已经有学者进行了相关研究。李江波等[5]利用竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)、遗传算法(genetic algorithms, GA)和蒙特卡罗无信息变量消除算法(Monte Carlo-uninformative variable elimination, MC-UVE)对‘鸭梨’的光谱特征变量进行筛选, 并建立SSC含量的偏最小二乘(partial least squares, PLS)预测模型, 结果表明CARS-PLS预测模型的精度最高且筛选变量最少。Fan等[6]采用CARS算法选取特征波长后, 利用连续投影算法(successive projections algorithm, SPA)进一步筛选有效特征变量, 建立梨子SSC的预测模型, 结果表明该方法在有效简化模型的同时提高了模型预测精度。詹白勺等[7]为了降低‘库尔勒香梨’高光谱与SSC指标之间的非线性关系, 探究了GA、GA-SPA、CARS等不同的变量选择方法和线性与非线性校正模型精度, 结果表明以CARS算法获得的特征变量建立的最小二乘支持向量机(least squares support vector machines, LS-SVM)预测模型效果较好, 但是对于LS-SVM而言, CARS算法提出的特征变量并不是最优的变量。因此, 开发新型的非线性变量提取方法是进一步研究的重要内容。
为了进一步探究‘库尔勒香梨’的高光谱特征波段的优选方法, 以建立优化的SSC预测模型, 本文分别采用CARS算法、迭代保留信息变量算法(iteratively retaining informative variables, IRIV)以及CARS-IRIV算法进行特征变量筛选, 并利用PLS和LS-SVM算法建立‘库尔勒香梨’SSC的预测模型。比较不同的筛选变量算法并结合预测模型的精度, 获得‘库尔勒香梨’SSC高光谱成像技术检测的优选特征变量以及优化模型, 为实现‘库尔勒香梨’SSC的高光谱成像技术在线检测奠定理论基础。
1 材料与方法 1.1 样本及样本划分试验所选用的‘库尔勒香梨’采购于南京市浦口区水果市场, 选择形状大小均匀、表皮完整没有损伤的样本共94个。对样本进行初步清洗去除表面尘土, 依次编号放置于室温(20±1) ℃中静置24 h, 以消除温度对模型预测精度的影响。为了在划分样本校正集和预测集时兼顾考虑到光谱向量和浓度向量, 样本的划分采用Galvão等[8]提出的SPXY(sample set partitioning based on joint X-Y distances)算法选择63个样本作为校正集, 剩余31个样本作为预测集。
1.2 仪器与设备数显糖度计折射仪(PAL-1型, 日本Atago公司)用来测定‘库尔勒香梨’SSC值。高光谱成像检测系统由成像光谱仪(ImSpectorV10E型, 芬兰Specim公司)、CCD摄像机(GEV-B1621M-TC000型, 美国Imperx公司)、线性卤素灯光源(21 V/150 W, 美国Illumination公司)、步进电机移动平台(中国台湾IsuzuOptic公司)、采集暗箱以及计算机等组成。成像光谱仪波长范围:358~1 021 nm; 光谱分辨率:0.51 nm; 图像分辨率:1 632 × 1 232像素; 传送带移动速度:0.8 mm·s-1; 曝光时间:50 ms; 物距:390 mm。
1.3 光谱采集在进行高光谱成像系统采集时, 将每个样本横放于传输平台上, 沿果品赤道附近大约每隔120°分3次采集高光谱图像, 同时考虑到样本个体形状和大小不同, 在试验中选取样本每个采样区相同大小50 × 50像素的感兴趣区域(ROI)提取光谱。利用ENVI 5.1软件提取ROI的平均光谱值作为漫反射光谱, 将同一样本3个采集区域的漫反射光谱值的平均值作为此样本最终的漫反射光谱。
为减少光照不均匀与CCD相机暗电流的影响, 需要对获得的高光谱图像进行黑白校正。根据以下公式算出校正后的图像I:
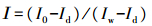
|
(1) |
式中:I0为原始高光谱图像; Id为盖上镜头盖并关闭光源采集的反射率接近于0的校正图像; Iw为采集标准白板(反射率99%, Spectralon, Labsphere Inc., USA)的校正图像。
1.4 样品SSC参考值测定使用蒸馏水对PAL-1型数字折射仪零点矫正。在每个样本的对应3个高光谱采集区域各切取果皮下约1 cm厚度的果肉, 放于3层纱布中人工压汁并过滤后滴入折射仪测试窗口上, 分别记录3个SSC值并取平均值作为该样本最终SSC参考值, 获取的94个样本的SSC参考值见表 1。
| 样本集 Data set |
样本数 Number of samples |
SSC/°Brix | |||
| 最小值Minimum | 最大值Maximum | 平均值Mean | 标准偏差Standard deviation | ||
| 校正集Calibration set | 63 | 8.78 | 12.76 | 10.87 | 0.97 |
| 预测集Prediction set | 31 | 9.52 | 12.11 | 10.95 | 0.54 |
CARS是一种快速有效的变量选择算法[9]。它模仿达尔文进化论中“适者生存”的原则, 以PLS模型回归系数的绝对值作为每个变量重要性的指标, 选择全光谱中有效变量的最优组合。对于m个样本p维变量的原始光谱数据, CARS主要包括以下4个步骤:
1) 基于蒙特卡罗采样法(Monte Carlo sampling, MCS), 随机抽取校正集样本的80%作为建立PLS模型的样本, 得到第i个波长的回归系数|Ki|(i=1, 2, …, p)。
2) 应用指数衰减函数(exponentially decreasing function, EDF)去除|Ki|较小的波长点, 变量的保留率为rj=ae-bj(j=1, 2, …, N)。其中:j表示第j次蒙特卡罗采样; N表示蒙特卡罗采样总次数; 参数a、b为常数, 由r1=1且rN=2/p计算得到, 公式如下:
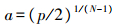
|
(2) |
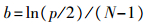
|
(3) |
3) 基于自适应重加权采样(adaptive reweighted sampling, ARS)技术进一步对变量进行筛选。模仿达尔文进化论中的“适者生存”法则, 采用评价权重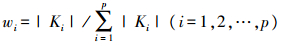
4) 循环上述1)至3)步骤直到蒙特卡罗采样次数达到预先设定的N值。
5) 比较每次蒙特卡罗采样得到变量子集的RMSECV值, 选择RMSECV值最小时对应的变量子集作为CARS的最优变量子集。
1.5.2 迭代保留信息变量算法(IRIV)IRIV是一种基于二进制矩阵重排过滤器(BMSF)提出的特征变量选择算法[10], 将所有变量分为强信息变量、弱信息变量、无信息变量、干扰变量4类。IRIV算法需要经过多次迭代, 每次迭代的目的是保留强信息变量和弱信息变量, 消除无信息变量和干扰变量, 最后反向消除获得最佳变量集。对于m个样本p维变量的原始光谱数据, 由以下4个步骤筛选变量:
1) 生成一个m行p列只包含1和0的矩阵A, 1和0分别表示变量是否用于建模, 矩阵A中1和0的个数相同。在矩阵A的每一行建立PLS模型, 以5折交叉所得RMSECV值作为评价标准, 得到m×1大小的向量记为RMSECV0。将矩阵A中第i列(i=1, 2, …, p)中的1换为0、0换成1得到矩阵B, 同样在矩阵B的每一行建立PLS模型, 得到m×1大小的向量记为RMSECVi。
2) 定义φ0和φi以评估每个变量的重要性, 公式如下:
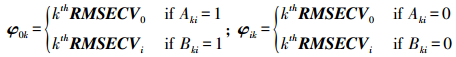
|
(4) |
式中:kth表示向量中的第k行, 则kthRMSECV0和kthRMSECVi分别表示向量RMSECV0和RMSECVi中第k行的值; φ0和φi的均值记为Mi, in和Mi, out, 将两均值相减得到DMi。若DMi < 0则为强信息变量或弱信息变量; 若DMi>0则为无信息变量或干扰变量。定义P=0.05为阈值进行Mann-Whitney U检验[11], 最终将变量分为4类。
3) 每次迭代均保留强信息变量和弱信息变量, 剔除无信息变量和干扰变量。返回步骤1)进行下一轮迭代, 直到只剩下强信息变量和弱信息变量。
4) 对t个保留变量进行反向消除。首先, 对t个变量建立PLS模型得到RMSECVt。然后, 通过消除第j个变量(j=1, 2, …, t)对t-1个变量建立PLS模型得到RMSECV-j, 若RMSECV-j小于RMSECVt则消除第j个变量, 否则保留。循环此过程, 剩下的变量为最终选取的特征变量。
1.6 数据处理与模型评价利用各变量筛选方法提取的特征变量建立PLS和LS-SVM模型, 数据预处理、特征变量选取以及预测模型的建立均使用MATLAB 2012a软件完成。模型预测精度的评价参数如下:校正集相关系数(Rc)、校正集均方根误差(root mean square error of calibration, RMSEC)、预测集相关系数(Rp)、预测集均方根误差(root mean square error of prediction, RMSEP)、交叉验证均方根误差(RMSECV)和预测相对分析误差(residual predictive deviation, RPD)。较好的预测模型应该具有较高的Rc、Rp、RPD值, 和较低的RMSECV、RMSEC和RMSEP值。Nicolaï等[12]指出, 当RPD值为1.5~2.0时仅能够区分目标变量值的大小; 当RPD值为2.0~2.5时能够粗略的定量预测; 当RPD值为2.5~3.0时模型具有较高预测精度。
2 结果与分析 2.1 光谱预处理以400~1 000 nm内的光谱作为有效光谱, 共包含1 109个变量。采用标准化、均值中心化、Sacitzky-Golay(SG)平滑滤波、标准正态变量变换(SNV)、多元散射校正(MSC), 以及SG+SNV和SG+MSC多种方法对有效光谱进行预处理, 并分别建立PLS模型, 经比较后发现SG+MSC预测效果最佳, 因此后续处理算法均基于该预处理方法进行。图 1是样本有效光谱和SG+MSC预处理后的光谱反射率图像, 可以看出有3处明显的吸收谷, 500与680 nm处的波谷与水果表面色素产生颜色吸收及反射相关[13], 而960 nm附近的波谷主要由水分和碳水化合物的吸收引起[14]。

|
图 1 400~1 000 nm波段的有效光谱(a)和经SG+MSC预处理后的光谱(b) Figure 1 Original reflectance spectral(a)and reflectance spectral after SG+MSC processing(b) in the region of 400-1 000 nm |
CARS算法的目的是消除无关的变量并减少变量之间的共线性。在本研究中, 蒙特卡罗抽样运行的次数设置为50次, 选择变量个数由5折交叉验证建立的PLS模型中RMSECV最小值确定。图 2-a反映出由于指数衰减函数EDP的作用, 前10次的蒙特卡罗采样中变量数减少速度较快, 随后逐渐减慢, 表明算法在变量筛选中具有“粗选”和“精选”2个过程。图 2-b反映出随着蒙特卡罗采样次数的增加, RMSECV值呈先减小后增大的趋势, 并且在第23次采样时(图 2-b标记位置)达到最小值, 因此选择该点对应的65个特征变量(图 2-a标记位置)作为CARS算法筛选的特征变量。

|
图 2 CARS选择变量数(a)与RMSECV值(b)随采样次数增加的变化趋势 Figure 2 The changing trend of the number of variables(a)and the RMSECV values(b) with the increasing of sampling runs by CARS |
IRIV算法的目的是剔除无关变量和干扰变量, 保留与SSC值相关的特征变量。该算法利用5折交叉验证方法建立PLS模型选择特征变量, PLS模型中最大主因子数为10。IRIV算法一共进行了7轮, 如图 3所示, 前3轮迭代变量个数迅速减少, 从1 109个变量减少到了116个, 然后变量个数减少的速度放缓, 第6轮迭代后完全剔除了无信息变量和干扰变量, 进行反向消除操作。经过第7轮的反向消除最终选择了34个与SSC值相关的特征变量。

|
图 3 IRIV迭代保留变量个数 Figure 3 The number of retained variables by IRIV iterative |
考虑到CARS选择的特征变量较多, 而且蒙特卡罗采样过程具有随机性, CARS算法提取的特征变量也是不固定的, 可能存在无关变量没有完全消除的情况, 故以该方法提取的特征变量建立的模型结果不稳定[15]。IRIV算法将随机产生的变量子集建立一系列子模型, 部分子模型中出现比率较高的变量在多次迭代计算中被保留较高的权重, 因此可以稳定保留强有效变量信息, 但是由于该算法需要经过多次迭代, 因此计算量相对较大[16]。鉴于此, 本文提出利用IRIV算法对CARS算法提取的特征波长进一步筛选处理, 减少由于CARS算法产生的随机性问题, 将提取的特征变量进一步分为强信息变量、弱信息变量、无信息变量、干扰变量4类, 使与SSC值相关的信息变量被筛选的概率增大, 从而稳定预测模型精度。同时, IRIV算法针对CARS算法提取的特征变量进行筛选, 可以解决其计算量大的问题。将CARS提取的65个特征波长作为IRIV算法的输入变量, 经过IRIV进一步筛选后得到31个特征变量, 仅占全光谱波长变量的2.8%, 特征变量个数与分布见图 4。与单纯利用IRIV算法提取特征变量过程相比, 可以看出迭代次数减少, 因此减少了计算量(图 4-a), 图 4-b中CARS-IRIV选择特征波长主要分布在610 nm、730 nm(O—H键4倍伸缩振动及C—H键5倍伸缩振动)、870 nm(C—H键的4倍伸缩振动)和960 nm(糖及水中的O—H键的3倍伸缩振动)附近[17], 而可溶性固形物的主要成分蔗糖的分子结构含有C—H和O—H化学键, 进一步证实采用CARS-IRIV选择的特征变量进而建立SSC预测模型的合理性。

|
图 4 CARS-IRIV选择变量数(a)与变量分布(b) Figure 4 The number of variables(a)and the distribution of variables(b)by CARS-IRIV |
以全光谱(full-spectra, FS)、CARS、IRIV和CARS-IRIV选择的变量作为PLS模型的输入变量, 以不同潜变量因子(LVs)分别建立PLS模型并计算RMSECV值, 根据最小的RMSECV确定最佳LVs, PLS预测模型结果如表 2所示。其中基于FS、CARS、CARS-IRIV建立的PLS模型的Rc值均在0.97以上, RMSEC值均小于0.25, 说明这3种变量选择方法结合PLS模型均具有较好的校正效果。而IRIV算法建立PLS模型预测精度相对较低(RPD值为1.988), 这可能是由于IRIV算法在全光谱中进行迭代筛选过程较为复杂所致[18]。IRIV-PLS模型的预测精度低于FS-PLS模型, CARS-PLS与CARS-IRIV-PLS模型的预测精度均高于FS-PLS模型, RPD值分别为2.546和2.601。在IRIV、CARS、CARS-IRIV 3种特征变量提取方法中, CARS-IRIV建立PLS模型预测精度最高, 具有最高的Rp值(0.835)和最小的RMSEP值(0.373), 并且CARS-IRIV选择变量个数最少, 该算法简化模型的同时提高了模型预测精度。但是, 各特征变量提取方法结合PLS模型的RPD值为1.988~2.601, 因此建立PLS模型只能粗略地进行SSC值的定量预测。
| 变量选择方法 Method of variable selection |
变量数 Variables |
LVs | 校正集Calibration set | 预测集Prediction set | ||||
| Rc | RMSEC/°Brix | Rp | RMSEP/°Brix | RPD | ||||
| FS | 1 109 | 17 | 0.976 | 0.211 | 0.792 | 0.387 | 2.506 | |
| IRIV | 34 | 12 | 0.950 | 0.301 | 0.751 | 0.488 | 1.988 | |
| CARS | 65 | 12 | 0.971 | 0.233 | 0.826 | 0.381 | 2.546 | |
| CARS-IRIV | 31 | 11 | 0.970 | 0.233 | 0.835 | 0.373 | 2.601 | |
以FS、CARS、IRIV和CARS-IRIV方法选择的变量作为输入变量, 选择径向基核函数(RBF)作为LS-SVM的核函数, LS-SVM模型的回归误差权重γ和RBF核函数的参数σ2通过单纯形法寻优结合留一交叉验证获得[19], LS-SVM模型的结果如表 3所示。在表 3中IRIV-LS-SVM、CARS-LS-SVM和CARS-IRIV-LS-SVM模型的预测精度均高于FS-LS-SVM模型, RPD值分别为2.994、3.160和3.233, 其中CARS-IRIV-LS-SVM模型效果最优, Rp值和RMSEP值分别为0.889和0.300。对比LS-SVM模型与PLS模型, LS-SVM模型的预测精度均高于PLS模型预测精度, 其中IRIV-LS-SVM模型预测结果变化最明显, RPD值从1.988提升到2.994, 说明由IRIV算法提取的特征变量更适合于建立非线性LS-SVM模型。除FS外其他3种特征变量提取方法结合LS-SVM模型的RPD值均大于2.5, 具有较高的定量预测精度。
| 变量选择方法 Methods of variable selection |
变量数 Variables |
γ | σ2 | 校正集Calibration set | 预测集Prediction set | ||||
| Rc | RMSEC/°Brix | Rp | RMSEP/°Brix | RPD | |||||
| FS | 1 109 | 2.35×109 | 4.71×107 | 0.997 | 0.078 | 0.829 | 0.343 | 2.828 | |
| IRIV | 34 | 1.51×104 | 3.20×107 | 0.979 | 0.203 | 0.856 | 0.324 | 2.994 | |
| CARS | 65 | 2.99×105 | 1.56×104 | 0.972 | 0.232 | 0.874 | 0.307 | 3.160 | |
| CARS-IRIV | 31 | 1.13×106 | 1.47×104 | 0.976 | 0.213 | 0.889 | 0.300 | 3.233 | |
对比表 2和表 3中的特征变量提取方法, 从变量个数来看, IRIV、CARS和CARS-IRIV方法有效地减少了变量个数, 分别筛选出34、65和31个变量; 从建模结果来看, CARS-IRIV结合PLS或LS-SVM模型的预测精度均高于CARS。说明虽然CARS能够有效保留强信息变量且减小变量集的共线性, 但筛选后的变量仍有无关信息或干扰信息的存在, 所以对于CARS变量进一步筛选是必要的[20], 并且对于CARS变量的进一步筛选可以在保证预测精度的情况下继续减少变量个数, CARS-IRIV选择的变量个数占CARS的47.69%。IRIV虽然从全波长变量筛选特征波长的复杂度较高、运算时间较长, 但结合LS-SVM模型仍具有较高的预测精度, 在CARS变量选择的基础上再进行IRIV变量筛选不仅缩短了运算的时间而且提高了模型预测的实时性。综上所述, CARS-IRIV能够作为一种有效的高光谱数据特征变量提取方法, 利用该方法可以准确预测‘库尔勒香梨’SSC值, 同时提高检测的实时性。
3 结论本文以‘库尔勒香梨’SSC为研究指标, 采用CARS、IRIV和CARS-IRIV方法对400~1 000 nm波长内光谱进行特征变量的筛选, 并分别构建PLS与LS-SVM模型, 比较不同变量选择方法的预测精度。研究发现CARS-IRIV选择的变量个数占CARS的47.69%, 减少特征变量个数并且稳定保留有效变量信息, 减少由于CARS算法产生的随机性问题, 从而稳定预测模型精度。同时, LS-SVM模型比PLS模型有更高的预测精度, CARS-LS-SVM、IRIV-LS-SVM、CARS-IRIV-LS-SVM模型的RPD值均大于2.5, 说明这3种变量筛选方法结合LS-SVM建立模型均有较高的预测精度, 其中CARS-IRIV-LS-SVM模型预测精度最高, 其相关系数Rc=0.976, Rp=0.889, 均方根误差RMSEC=0.213, RMSEP=0.300, 预测相对分析误差RPD=2.823。CARS-IRIV-LS-SVM模型结合高光谱成像技术可以快速有效地对‘库尔勒香梨’SSC进行预测, 为实现其高光谱在线检测提供了理论依据, 同时也为其他果品中SSC值的检测提供一种参考方法。
| [1] | Li J B, Huang W Q, Zhao C J, et al. A comparative study for the quantitative determination of soluble solids content, pH and firmness of pears by Vis/NIR spectroscopy[J]. Journal of Food Engineering, 2013, 116(2): 324-332. DOI: 10.1016/j.jfoodeng.2012.11.007 |
| [2] | Zhang B H, Huang W Q, Li J B, et al. Principles, developments and applications of computer vision for external quality inspection of fruits and vegetables:a review[J]. Food Research International, 2014, 62(62): 326-343. |
| [3] | Xu H, Qi B, Sun T, et al. Variable selection in visible and near-infrared spectra:application to on-line determination of sugar content in pears[J]. Journal of Food Engineering, 2012, 109(1): 142-147. DOI: 10.1016/j.jfoodeng.2011.09.022 |
| [4] | Balabin R M, Smirnov S V. Variable selection in near-infrared spectroscopy:benchmarking of feature selection methods on biodiesel data[J]. Analytica Chimica Acta, 2011, 692(1/2): 63-72. |
| [5] |
李江波, 彭彦昆, 陈立平, 等. 近红外高光谱图像结合CARS算法对鸭梨SSC含量定量测定[J].
光谱学与光谱分析, 2014, 34(5): 1264-1269.
Li J B, Peng Y K, Chen L P, et al. Near-infrared hyperspectral imaging combined with CARS algorithm to quantitatively determine soluble solids content in 'Ya' pear[J]. Spectroscopy and Spectral Analysis, 2014, 34(5): 1264-1269. (in Chinese with English abstract) |
| [6] | Fan S X, Huang W Q, Guo Z M, et al. Prediction of soluble solids content and firmness of pears using hyperspectral reflectance imaging[J]. Food Analytical Methods, 2015, 8(8): 1936-1946. DOI: 10.1007/s12161-014-0079-1 |
| [7] |
詹白勺, 倪君辉, 李军. 高光谱技术结合CARS算法的库尔勒香梨可溶性固形物定量测定[J].
光谱学与光谱分析, 2014, 34(10): 2752-2757.
Zhan B S, Ni J H, Li J, et al. Hyperspectral technology combined with CARS algorithm to quantitatively determine the SSC in Korla fragrant pear[J]. Spectroscopy and Spectral Analysis, 2014, 34(10): 2752-2757. DOI: 10.3964/j.issn.1000-0593(2014)10-2752-06 (in Chinese with English abstract) |
| [8] | Galvão R K H, Araujo M C U, José G E, et al. A method for calibration and validation subset partitioning[J]. Talanta, 2005, 67(4): 736-740. DOI: 10.1016/j.talanta.2005.03.025 |
| [9] | Li H D, Liang Y Z, Xu Q S, et al. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration[J]. Analytica Chimica Acta, 2009, 648(1): 77-84. DOI: 10.1016/j.aca.2009.06.046 |
| [10] | Yun Y H, Wang W T, Tan M L, et al. A strategy that iteratively retains informative variables for selecting optimal variable subset in multivariate calibration[J]. Analytica Chimica Acta, 2014, 807(1): 36-43. |
| [11] | Mann H B, Whitney D R. On a test of whether one of two random variables is stochastically larger than the other[J]. Annals of Mathematical Statistics, 1947, 18(1): 50-60. DOI: 10.1214/aoms/1177730491 |
| [12] | Nicolaï B M, Beullens K, Bobelyn E, et al. Nondestructive measurement of fruit and vegetable quality by means of NIR spectroscopy:a review[J]. Postharvest Biology and Technology, 2007, 46(2): 99-118. DOI: 10.1016/j.postharvbio.2007.06.024 |
| [13] | Wouters N, de Ketelaere B, de Baerdemaeker J, et al. Hyperspectral waveband selection for automatic detection of floral pear buds[J]. Precision Agriculture, 2013, 14(1): 86-98. DOI: 10.1007/s11119-012-9279-0 |
| [14] | Li B C, Hou B L, Zhang D W, et al. Pears characteristics(soluble solids content and firmness prediction, varieties)testing methods based on visible-near infrared hyperspectral imaging[J]. Optik, 2016, 127(5): 2624-2630. DOI: 10.1016/j.ijleo.2015.11.193 |
| [15] | Fan S X, Guo Z M, Zhang B H, et al. Using Vis/NIR diffuse transmittance spectroscopy and multivariate analysis to predicate soluble solids content of apple[J]. Food Analytical Methods, 2016, 9(5): 1333-1343. DOI: 10.1007/s12161-015-0313-5 |
| [16] |
宋相中, 唐果, 张录达, 等. 近红外光谱分析中的变量选择算法研究进展[J].
光谱学与光谱分析, 2017, 37(4): 1048-1052.
Song X Z, Tang G, Zhang L D, et al. Research advance of variable selection algorithms in near infrared spectroscopy analysis[J]. Spectroscopy and Spectral Analysis, 2017, 37(4): 1048-1052. (in Chinese with English abstract) |
| [17] | Liu D, Sun D W, Zeng X A. Recent advances in wavelength selection techniques for hyperspectral image processing in the food industry[J]. Food Bioprocess Technology, 2014, 7(2): 307-323. DOI: 10.1007/s11947-013-1193-6 |
| [18] |
张航, 刘国海, 江辉, 等. 基于近红外光谱技术的乙醇固态发酵过程参数定量检测[J].
激光与光电子学进展, 2017, 54(2): 314-320.
Zhang H, Liu G H, Jiang H, et al. Quantitative detection of ethanol solid-state fermentation process parameters based on near infrared spectroscopy[J]. Laser and Optoelectronics Progress, 2017, 54(2): 314-320. (in Chinese with English abstract) |
| [19] | Khanmohammadi M, Karami F, Mir-Marqués A, et al. Classification of persimmon fruit origin by near infrared spectrometry and least squares-support vector machines[J]. Journal of Food Engineering, 2014, 142(6): 17-22. |
| [20] | Tang G, Huang Y, Tian K D, et al. A new spectral variable selection pattern using competitive adaptive reweighted sampling combined with successive projections algorithm[J]. Analyst, 2014, 139(19): 4894-4902. DOI: 10.1039/C4AN00837E |