 2012, Vol. 48
2012, Vol. 48文章信息
- 张雄清, 雷渊才, 雷相东, 陈永富, 冯淼
- Zhang Xiongqing, Lei Yuancai, Lei Xiangdong, Chen Yongfu, Feng Miao
- 基于计数模型方法的林分枯损研究
- Predicting Stand-Level Mortality with Count Data Models
- 林业科学, 2012, 48(8): 54-61.
- Scientia Silvae Sinicae, 2012, 48(8): 54-61.
-
文章历史
- 收稿日期:2011-09-07
- 修回日期:2011-11-27
-
作者相关文章



2. 中国林业科学院林业研究所 北京 100091;
3. 国家知识产权局专利局专利审查协作北京中心 北京 100083
2. Research Institute of Forestry, CAF Beijing 100091;
3. Patent Examination Cooperation Center of the Patent Office, SIPO Beijing 100083
林分枯损模型是全林分生长模型的一个重要组成部分。林分枯损是个自然过程,在森林生态系统演替中发挥着重要作用(Franklin et al., 1987)。引起林分枯损的因素有很多,Vanclay(1995)根据林分枯损原因将林分的枯损分为正常枯损(regular mortality)和非正常枯损(irregular mortality)2类。正常枯损主要是因为林木对水分、养分、光照条件的竞争而导致的(Peet et al., 1987);非正常枯损主要是由于人为的随机干扰或者自然灾害,如森林火灾、大风、雪灾、干旱以及森林病虫害等导致的(Kneeshaw et al., 1998;Alenius et al., 2003)。正是由于非正常枯损的随机性,许多学者在研究枯损时,通常只对正常枯损的林分进行研究(Amateis et al., 1997;Monserud et al., 1999;Eid et al., 2001;Yao et al., 2001;Yang et al., 2003)。
林分枯损估计,很多学者通常先利用Logistic回归模型估计单木枯损率(Cao, 2000;Zhao et al., 2004;Zhang et al., 2010;向玮等, 2008),然后通过各单木累加得到样地中林木枯损总株数,这个估计过程不仅需要详细的单木信息,而且存在误差积累的缺点。而根据林分枯损与林分因子、立地条件等关系直接建立林分枯损模型可以克服这一缺点,因此如何建立一个精确的林分枯损模型尤为重要。
调查间隔期内可能有大量的样地没有发生林分枯损现象(Monserud et al., 1999;Eid et al., 2001),这意味着在林分枯损的数据中包含有大量的零数据,即林分枯损数据的结构是离散的。如果继续用最小二乘方法分析,会产生较大的偏差。为此,一些学者提出利用两阶段法(two-stage approach)来研究林分枯损(Woollons, 1998;Eid et al., 2003;Diéguez-Aranda et al., 2005),即第一步通过Logistic模型求得林分枯损的概率,第二步建立林木枯损株数模型。然而利用Logistic模型判定林分枯损时,得到的是概率值,需要通过一个概率阈值将其转化为二分类变量才能判断枯损与否,而目前没有一个公认的确定概率阈值的方法。
从林木枯损株数的数据结构上分析,可以把它归类为计数模型。Poisson模型作为计数模型分析的一种基本方法,广泛应用于医药学、灾害等领域(Perdeck, 1998;Jesper et al., 2006;叶小华等, 2005)。然而由于Poisson回归均值和同方差的假设条件过于严格,很多数据达不到这个要求,一些研究者提出利用负二项回归模型来拟合(Liu et al., 2008;许飞, 2009)。而在实际问题研究中,一些研究对象数据过于离散,此时Poisson模型和负二项回归模型不太适合,有时即便强行实现,也会给分析结果带来失真的解释(曾平等, 2008)。零膨胀模型和Hurdle模型在处理离散数据时,能够解决数据中出现的异质性问题。Lambert(1992)对零膨胀模型做了深入研究之后,零膨胀模型在医学、生物统计、灾害等方面的研究层出不穷(Hall, 2000;Barry et al., 2002;Cunningham et al., 2005;Nie et al., 2006;Levin et al., 2009;徐昕等, 2009;郭福涛, 2010)。然而据查阅相关文献,国外有少量关于零膨胀模型和Hurdle模型在林业上的应用研究(Rathbun et al., 2006;Fortin et al., 2007),国内却仅在森林火灾上有所研究(郭福涛等,2010),对于林分枯损模型的应用研究未见报道。
为此,本文利用吉林省汪清林业局金沟岭林场落叶松固定调查样地数据,应用Poisson模型、负二项回归模型、零膨胀模型和Hurdle模型对落叶松林分枯损进行模拟研究,并对这些模型的模拟结果进行分析比较,试图找出合适的林分枯损模型,为林分枯损模型的研究提供一种可行性方法。
1 研究区域概况与数据收集 1.1 研究区域概况研究区位于吉林省汪清林业局金沟岭林场。地理坐标为123°56′—131°04′N,43°05′—43°40′E,属长白山系的中低山丘陵区,海拔550~1 100 m,母岩为玄武岩,土壤为暗棕色森林土。温带大陆性季风气候,降水量670 mm,年平均温度1.5 ℃,1月份平均气温-18.3 ℃,积温2 114 ℃。该区植物为长白山植物区系的一部分,从优势树种看,此地区人工林以长白落叶松(Larix olgensis)为主。
1.2 数据整理本研究用长白落叶松为1962年人工造林,共有20块固定样地,样地面积在0.077 5~0.25 hm2之间。样地每隔2~3年复测1次,本研究采用的数据来自于1988—2006年的调查数据。样地主要调查因子有胸径、方位角、林分年龄、平均树高、郁闭度、坡向、坡位、坡度、海拔、土层厚度等。考虑到样地的连续调查次数,本研究数据可以组成114个样本,其中随机选取65个样本用于建模,49个样本用于模型检验。落叶松林分主要变量因子见表 1,枯损株数直方图见图 1。由图 1可以看出,未枯损的林分超过50%,即数据结构中含有大量的0,数据呈较离散状态。
|
|

|
图 1 林木枯损株数直方图 Fig.1 Histogram of stand mortality |
林分枯损株数主要与年龄(A)、密度、优势木平均高(H)有关(González et al., 2004),其中密度指标包括株数密度(N)、林分断面积(B)和相对植距(Rs=(10 000/N)0.5/H)。因此本研究围绕着这3个变量应用不同的模型方法分析林分枯损。
2.1 Poisson模型Poisson模型是分析计数型数据的一种最简单的方法,其概率质量函数如下:

|
(1) |
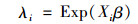
|
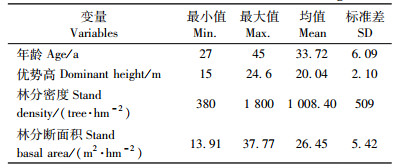
式中:Exp()是以自然对数为底的指数函数;Yi为随机变量;λi为Poisson分布的期望;Xi为自变量(年龄、密度、优势木平均高、相对植距等);β为参数向量。
则Poisson模型的似然函数为:
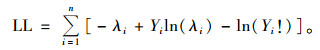
|
(2) |
式中:ln()是以自然对数为底的对数函数;n为样本数。
2.2 负二项(NB)模型负二项模型是Poisson模型的广义形式(Evans et al., 2000),不同的是多了个离散参数,能够解释数据的异质性,因此,它比Poisson分布更具有适用性(MacNeil et al., 2009)。负二项模型的概率质量函数为:
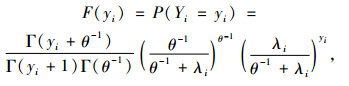
|
(3) |
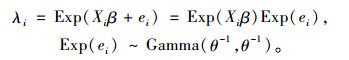
|
式中:ei为方差异质性部分,Γ为伽马函数,θ为离散参数。其对数似然函数为:

|
(4) |
在现实生活中,会有很多的过离散数据,零膨胀模型就是为了拟合零过多数据而发展起来的(Lambert 1992;Welsh et al., 1996),其基本思想是把事件发生数的发生看成2种可能的情形:第1种对应零事件的发生假定服从贝努里分布;第2种对应事件假定服从Poisson分布或负二项分布。在零膨胀模型中,零数据有2个主要来源:一是那些从未可能发生的零部分;二是在Poisson或负二项理论分布下没有发生的离散部分(Eskelson et al., 2009)。实际上,Logit模型常用来拟合零部分,离散部分可以用Poisson模型或负二项模型来模拟。设有一个服从零膨胀分布的离散随机变量y(样地中林木枯损数),pi为零部分的概率,它的概率质量函数为:
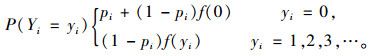
|
(5) |
在式(5)中,一般认为0 < pi < 1,是对模型的多零部分的解释(徐昕等,2009)。在零部分中常用Logit模型来拟合,即: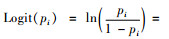
1) 零膨胀Poisson模型(ZIP) 在式(5)中,如果yi服从一个参数为λi的Poisson分布,那么就可以得到ZIP模型。当p=0时,ZIP模型将变成一个普通的Poisson模型。ZIP模型的概率质量函数为:
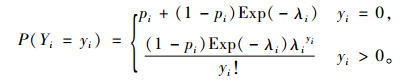
|
(6) |
式中:(1-pi)-P[Yi~Poisson(λi)],其对数似然函数为:
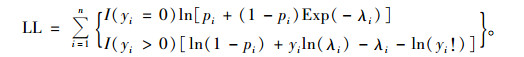
|
(7) |
2) 零膨胀负二项模型(ZINB) 在计数模型中,负二项分布是泊松分布的广义形式。同样,也可以将ZIP模型推广到ZINB模型,即:在离散部分,负二项模型来模拟。ZINB的概率质量函数为:
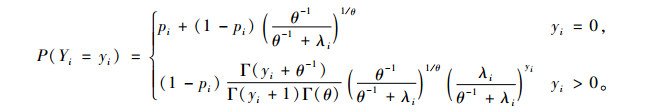
|
(8) |
式中:当θ→0时,ZINB模型就退化为ZIP模型。
2.4 Hurdle模型Hurdle模型最早由Mullahy(1986)提出,Hurdle模型又称为两部分(two-part)模型(Heilbron, 1994):第1部分模拟零个数,如二分类模型(如Logit模型)、Poisson模型、负二项模型等;第2部分是模拟正数计数,如Poisson模型、负二项模型等。Hurdle模型与零膨胀模型相似,都可以看做是2个统计过程的混合,但是Hurdle模型与零膨胀模型的区别是:Hurdle模型假设零数据来源于1个统计过程,而零膨胀模型有2个来源(Liu et al., 2008)。
在本研究中,第1部分(Hurdle部分)利用常用的Logit模型(与零膨胀模型零部分一样),第2部分分别利用Poisson模型和负二项模型进行比较研究,记为Hurdle-Poisson模型和Hurdle-NB模型。
1) Hurdle-Poisson模型 Hurdle-Poisson模型是Hurdle模型中较为常用的一种,其概率质量函数为:
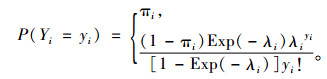
|
(9) |
式中:πi=P(yi=0),λi=Exp(Xiβ)。根据其概率质量函数,可以推导出Hurdle-Poisson模型的对数似然函数是这2部分之和:

|
(10) |
式中:I=0(yi=0),I=1(yi > 0)。
2) Hurdle-NB模型 Hurdle-NB模型是Hurdle模型的另一种形式,在截尾非零计数部分用负二项模型来拟合,其概率质量函数为:
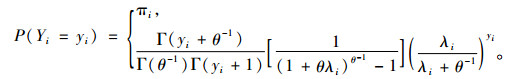
|
(11) |
由上述概率函数可推导出Hurdle-NB模型的对数似然函数为:
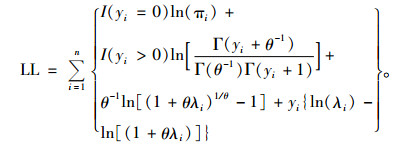
|
(12) |
本研究中上述几类模型参数的估计均利用R软件中Pscl软件包完成。对于零膨胀模型,用zeroinfl()函数执行;而对于Hurdle模型,则是用hurdle()函数完成(Cameron et al., 2005;Zeileis et al., 2008)。
3 模型评价为了比较Poisson模型、负二项模型、零膨胀模型和Hurdle模型的拟合情况,通过平均误差(MD)和AIC值(akaike information criterion)统计量进行比较。MD绝对值和AIC值越小,说明模型越好,即:
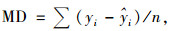
|
(14) |
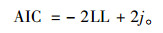
|
(15) |
式中:n为样本数;yi为随机变量观测值;
Vuong检验在复合模型(ZIP,ZINB)和一般计数模型(Poisson/NB模型)的比较分析中有相当高的检验效能(郭福涛等, 2010),因此,本文也选用了Vuong检验择优方法。该方法在2个模型解释能力相等的假设下得到Z统计量并进行似然比检验,根据Vuong的检验值和p值判断选优,极大地提高了模型择优的效果(Vuong, 1989)。本研究利用R软件中Vuong(模型A、模型B)函数求得Vuong检验值。如果Vuong检验值大于1.96,则说明在显著水平0.05条件下模型A优于模型B;如果Vuong检验值小于-1.96,则相反。
4 结果与分析经过模型参数的检验,剔除不显著的变量,Poisson模型、负二项模型、零膨胀模型和Hurdle模型的参数估计值及统计检验见表 2和表 3。由表 2可知,各参数估计在0.05水平上显著,林分枯损与林龄、密度显著相关。林龄、相对植距变量的参数估计为负值,说明随着林龄的增加,枯损株数减少;同样,随着相对植距的增加,枯损株数减少。
|
|

|
|

负二项模型AIC值(498.007 1)、MD绝对值(0.478 5)均小于Poisson模型的AIC值(1 872.698 0)、MD绝对值(1.040 8)。另外,Vuong检验的检验值为-5.073 5,p值为1.953 3e-07,在0.01置信水平上极显著,说明负二项模型模拟效果优于Poisson模型(表 3),这也验证了对于处理离散的数据,负二项模型比Poisson模型更适用。
由表 3可知:4个模型的各参数估计在0.05水平上均显著。与表 2的结果一样,林分枯损与林龄、密度显著相关。不论是离散部分还是零部分,林龄、相对植距变量的参数估计为负值,表明随着林龄的增加,枯损株数减少;同样,随着相对植距的增加,枯损株数减少;随着林分断面积增加,枯损株数增加。ZINB模型AIC值(454.335 4)、MD绝对值(0.000 2)均小于ZIP模型的AIC值(979.722 8)、MD绝对值(0.020 9)。而且,Vuong检验的检验值为3.044,p值为0.001 2,在0.01置信水平上极显著,说明ZINB模型比ZIP模型好。Hurdle-NB模型AIC值(454.329 5)、MD绝对值(0.000 2)也都比Hurdle-Poisson模型的AIC值(979.722 8)、MD绝对值(0.020 9)小。根据Vuong检验,检验值为3.044,p值为0.001 2,在0.01置信水平上极显著,说明Hurdle-NB模型优于Hurdle-Poisson模型好。另外,由表 3还发现,ZIP模型与Hurdle-Poisson模型拟合结果差别不大,ZINB模型与Hurdle-NB模拟结果差别也不大,Hurdle-NB模型略优于ZINB模型,但不显著(Vuong检验值为-0.485 3,p值为0.313 7)。
图 2给出了6个模型的残差图,由图可知ZINB模型、Hurdle-NB模型残差分布比较均匀,大都落在-1到1之间,而以Poisson模型为基础的3个模型(Poisson模型、ZIP模型、Hurdle-Poisson模型)的残差分布比较散,有的数值超过了10,残差波动较大,拟合效果相对较差。

|
图 2 林木枯损株树残差图 Fig.2 Residuals of stand mortality for six models |
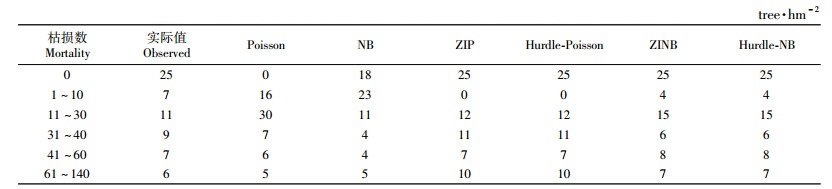
表 4为实际的林分枯损分布和预测枯损分布对照。表 4说明,零膨胀模型和Hurdle模型拟合预测效果最好,NB模型相对较差,而Poisson模型预测效果最差,进一步验证了零膨胀模型和Hurdle模型在预测过离散数据时的优越性。综合以上分析,本文选择Hurdle-NB模型为落叶松林分枯损最优模型。
|
|
根据上面计算出来的林木枯损株数,利用第一期的林分密度,可以得到第2期林分密度预测值。根据选择出的最优模型利用验证数据得到图 3和图 4。图 3是最优模型模拟所得的林分密度残差正态分位图。由图 3可知,残差分布近似正态。Hurdle-NB模型拟合所得的林分密度决定系数(R2)为0.98,均方根误差(RMSE)为145.95。结果表明利用Hurdle-NB模型拟合所得的林分密度比较接近实际值,预测效果较好,这也进一步验证了Hurdle-NB模型的准确性(图 4)。

|
图 3 Hurdle-NB模型的林分密度残差正态分位图 Fig.3 Normal Q-Q plot of stand density residual for Hurdle-NB model |

|
图 4 林分密度实际值和预测值线性相关图 Fig.4 Predicted value and observed value of stand density |
林分枯损模型是全林分模型的重要组成部分。本文以吉林省汪清林业局金沟岭林场落叶松为研究对象,分析林分枯损。林分枯损与林龄、密度显著相关,随着林龄的增加,枯损株数减少。这可能是由于汪清落叶松林分大部分都属于中龄林时期,生命力比较旺盛,年龄增加使得林分更趋于稳定,枯损株数少。相对植距是株数密度和林分优势高的反函数,相对植距增加(株数密度减少),枯损株数减少,说明林分株树密度减少,林分内各林木都有足够的空间,互相因为养分、水分的竞争少了,枯损株数也就少了。林分断面积反映了大小和株数密度,其增加也导致了枯损株数增加(Diéguez-Aranda et al., 2005)。
Poisson模型和负二项模型是计数模型的2个基本方法;然而对离散的数据(图 1),这2类模型预测精度较差,尤其是Poisson模型对数据的要求过于严格。负二项模型是Poisson模型的广义形式,离散参数的存在,使得负二项模型能够解释数据的异质性,因此,它比Poisson模型更有适用性(MacNeil et al., 2009)。
零膨胀模型对于处理离散数据有独特的优势,实际上它是由2个模型组成的:一是判断是否发生枯损的模型,二是模拟计数个数的模型(Long et al., 2006)。另外,相对Poisson模型和负二项模型,零膨胀模型的另一个优势是在模拟非零数据的同时对零数据进行研究(Karazsia et al., 2008)。零膨胀负二项模型优于Poisson模型、负二项模型和零膨胀Poisson模型(表 2,3)。当零数据相对较多而离散时,零膨胀Poisson模型能够较为精确地反映出数据的规律,然而当零数据膨胀时,零膨胀负二项模型模拟效果比零膨胀Poisson模型好(Long et al., 2006)。零膨胀Poisson模型中Poisson部分只有一个变量——期望(McCullagh et al., 1989),当该分布的方差大于期望时,零膨胀Poisson分布不能够充分地拟合林分死亡率数据。
Hurdle模型是处理离散数据的另一种方法。对于Hurdle模型,Logit部分用来描述林分枯损的概率,而零膨胀模型的Logit部分用来估计林分枯损的概率,这数据来自于从没枯损的林分(结构零部分)或者部分枯损(离散部分)的概率(Liu et al., 2008)。根据表 3,Hurdle-NB模型优于Hurdle-Poisson模型,Hurdle模型与零膨胀模型的结果相似,Hurdle-NB模型略优于零膨胀负二项模型,Hurdle-NB预测林分密度的R2较高。因此,利用Hurdle-NB模型分析落叶松林分枯损具有一定的可行性。
| [] | 郭福涛, 胡海青, 金森, 等. 2010. 基于负二项和零膨胀负二项回归模型的大型安岭地区雷击火与气象因素的关系. 植物生态学报, 34(5): 571–577. |
| [] | 向玮, 雷相东, 刘刚, 等. 2008. 近天然落叶松云冷杉林单木枯损模型研究. 北京林业大学学报, 30(6): 90–98. |
| [] | 徐昕, 尹占华, 郭念国. 2009. 零膨胀模型在非寿险中应用. 统计教育(4): 31–33. |
| [] | 许飞. 2009. 负二项回归模型在过离散型索赔次数中的应用研究. 统计教育: 53–55. |
| [] | 叶小华, 荀鹏程, 于浩, 等. 2005. 传染病链二项分布资料的Poisson回归模型. 中国卫生统计, 22(6): 377–379. |
| [] | 曾平, 刘桂芬, 曹红艳. 2008. 零膨胀模型在心肌缺血节段数影响因素研究中的应用. 中国卫生统计, 25(5): 464–466. |
| [] | Alenius V, Hokka H, Salminen H, et al. 2003. Evaluating estimation methods for logistic regression in modelling individual-tree mortality//Amaro A, Reed D, Soares P. Modelling Forest Systems. CAB International, Wallingford. |
| [] | Amateis R L, Burkhart H E, Jiping L. 1997. Modeling survival in juvenile and mature loblolly pine plantations. Forest Ecology and Management, 90(1): 51–58. DOI:10.1016/S0378-1127(96)03833-9 |
| [] | Barry S C, Welsh A H. 2002. Generalized additivemodeling and zero inflated count data. Ecological Modeling, 157(2): 179–188. |
| [] | Cameron A C, Trivedi P K. 2005. Micro-econometrics: methods and applications. Cambridge University Press, Cambridge. |
| [] | Cao Q V. 2000. Prediction of annual diameter growth and survival for individual trees from periodic measurements. Forest Science, 46(1): 127–131. |
| [] | Cunniningham R B, Lindenmayer D B. 2005. Modeling count data of rare species: some statistical issues. Ecology, 86(5): 1135–1142. DOI:10.1890/04-0589 |
| [] | Diéguez-Aranda U, Castedo-Dorado F, Álvarez-González J G, et al. 2005. Modelling mortality of Scots pine(Pinus sylvestris L.) plantations in the northwest of Spain. European Journal of Forest Research, 124(2): 143–153. DOI:10.1007/s10342-004-0043-5 |
| [] | Eid T, Øyen B H. 2003. Models for prediction of mortality in even-aged forest. Scandinavian Journal of Forest Research, 18(1): 64–77. |
| [] | Eid T, Tuhus E. 2001. Models for individual tree mortality in Norway. Forest Ecology and Management, 154(1): 69–84. |
| [] | Eskelson B N I, Temesgen H, Barrett T M. 2009. Estimating cavity tree and snag abundance using negative binomial regression models and nearest neighbor imputation methods. Canadian Journal of Forest Research, 39(9): 1749–1765. DOI:10.1139/X09-086 |
| [] | Evans M, Hastings N, Peacock B. 2000. Statistical distributions. John Wiley, New York, USA, 221. http://link.springer.com/article/10.1057/jors.1977.161 |
| [] | Fortin M, DeBlois J. 2007. Modeling tree recruitment withzero-inflated models: the example of hardwood stands in Southern Quebec, Canda. Forest Science, 53(4): 529–539. |
| [] | Franklin J F, Shugart H H. 1987. Tree death as an ecological process. Bioscience, 37(8): 550–556. DOI:10.2307/1310665 |
| [] | González J G A, Dorado F G, Gonzalez A D R, et al. 2004. A two-step mortality model for even-aged stands of Pinus radiate D.Don in Galicia(Northwestern Spain). Annals of Forest Science, 61(5): 439–448. DOI:10.1051/forest:2004037 |
| [] | Hall D B. 2000. Zero-inflated Poisson and binomial regression with random effects: a case study. Biometrics, 56: 1030–1039. DOI:10.1111/j.0006-341X.2000.01030.x |
| [] | Heilbron D. 1994. Zero-altered and other regression models for count data with added zeros. Biometrical Journal, 36(5): 531–547. DOI:10.1002/(ISSN)1521-4036 |
| [] | Jesper R, Igor R. 2006. A note on estimation of intensities of fire ignitions with incomplete data. Fire Safety Journal, 41(5): 399–405. DOI:10.1016/j.firesaf.2006.02.006 |
| [] | Karazsia B T, Manfred H, Dulmen V. 2008. Regression models for count data: illustrations using longitudinal predictors of childhood injury. Journal of Pediatric Psychology, 33(10): 1076–1084. DOI:10.1093/jpepsy/jsn055 |
| [] | Kneeshaw D D, Bergeron Y. 1998. Canopy gap characteristics and tree replacement in the southeastern boreal forest. Ecology, 79(3): 783–794. DOI:10.1890/0012-9658(1998)079[0783:CGCATR]2.0.CO;2 |
| [] | Lambert D. 1992. Zero-inflated Poisson regression, with an application to defects in manufacturing. Technometrics, 34(1): 1–14. DOI:10.2307/1269547 |
| [] | Levin K A, Davies C A, Topping G V A, et al. 2009. Inequalities in dental caries of 5-year-old children in Scotland, 1993—2003. European Journal of Public Health, 19(3): 337–342. DOI:10.1093/eurpub/ckp035 |
| [] | Liu W, Cela J. 2008. Count data models in SAS. Statistics and Data Analysis in SAS Global Forum. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.176.1766 |
| [] | Long J S, Freese J. 2006. Regression models for categorical dependent variables using stata. 2nd ed. College Station, TX: Stata Press. http://dialnet.unirioja.es/servlet/libro?codigo=370670 |
| [] | MacNeil M A, Carlson J K, Beerkircher L R. 2009. Shark depredation rates in pelagic longline fisheries: a case study from the Northwest Atlantic. ICES Journal of Marine Science, 66(4): 708–719. DOI:10.1093/icesjms/fsp022 |
| [] | McCullagh P, Nelder J A. 1989. Generalized linear models. 2nd ed. Monograph on Statistics and Applied Probability 37. Chapman and Hall, New York, NY, 511. https://link.springer.com/chapter/10.1007/978-1-4419-0925-1_19 |
| [] | Monserud R A, Sterba H. 1999. Modeling individual tree mortality for Austrian forest species. Forest Ecology and Management, 113(2): 109–123. |
| [] | Mullahy J. 1986. Specification and testing of some modified count data models. Journal of Econometrics, 33(3): 341–365. DOI:10.1016/0304-4076(86)90002-3 |
| [] | Nie L, Wu G, Brockman F J, et al. 2006. Integrated analysis of transcriptomic and proteomic data of desulfovibrio vulgaris: zero-inflated Poisson regression models to predict abundance of undetected proteins. Bioinformatics, 22(13): 1641–1647. DOI:10.1093/bioinformatics/btl134 |
| [] | Peet R K, Christensen N L. 1987. Competition and tree death. BioScience, 37(8): 586–595. DOI:10.2307/1310669 |
| [] | Perdeck A C. 1998. Poisson regression as a flexible alternative in the analysis ofring-recovery data. Eyring Newsletter, 2: 30–36. |
| [] | Rathbun S L, Fei S. 2006. A spatial zero-inflated Poisson regression model for oak regeneration. Environmental and Ecological Statistics, 13(4): 409–426. DOI:10.1007/s10651-006-0020-x |
| [] | Vanclay J K. 1995. Growth models for tropical forests: a synthesis or models and methods. Forest Science, 41(1): 7–42. |
| [] | Vuong Q H. 1989. Likelihood ratio tests for model selection andnon-nested hypotheses. Econonmetrica, 57(2): 307–333. DOI:10.2307/1912557 |
| [] | Welsh A H, Cunningham R B, Donnelly C F, et al. 1996. Modelling the abundance of rare species: statistical models for counts with extra zeros. Ecological Modeling, 88(10): 297–308. |
| [] | Woollons R C. 1998. Even-aged stand mortality estimation through a two-step regression process. Forest Ecology and Management, 105(2): 189–195. |
| [] | Yang Y, Titus S J, Huang S. 2003. Modeling individual tree mortality for white spruce in Alberta. Ecological Modelling, 163(3): 209–222. DOI:10.1016/S0304-3800(03)00008-5 |
| [] | Yao X, Titus S J, Macdonald S E. 2001. A generalized logistic model of individual tree mortality for aspen, white spruce, and lodegepole pine inAlberta mixedwood forests. Canadian Journal of Forest Research, 31(2): 283–291. |
| [] | Zeileis A, Kleiber C, Jackman S. 2008. Regression models for count data in R. Journal of statistical software, 27(8): 1–25. |
| [] | Zhang X, Lei Y, Cao Q V. 2010. Compatibility of stand basal area predictions based on forecast combination. Forest Science, 56(6): 552–557. |
| [] | Zhao D, Borders B, Wilson M. 2004. Individual-tree diameter growth and mortality models for bottomland mixed-species hardwood stands in the lower Mississippi alluvial valley. Forest Ecology and Management, 199(2/3): 307–322. |