 2012, Vol. 48
2012, Vol. 48文章信息
- 符利勇, 张会儒, 唐守正
- Fu Liyong, Zhang Huiru, Tang Shouzheng
- 基于非线性混合模型的杉木优势木平均高
- Dominant Height for Chinese Fir Plantation Using Nonlinear Mixed Effects Model
- 林业科学, 2012, 48(7): 66-71.
- Scientia Silvae Sinicae, 2012, 48(7): 66-71.
-
文章历史
- 收稿日期:2011-10-27
- 修回日期:2012-04-24
-
作者相关文章



非线性混合效应模型(nonlinear mixed effects models,NLMEMs)这个概念最早是Sheiner等(1980)提出来的,该模型包含固定效应参数(fixed-effects parameter)和随机效应参数(random effects parameter),是通过回归函数依赖于这2类参数的非线性关系而建立的。NLMEMs的一般表达式为:
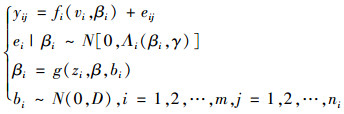
|
(1) |
式中:yij表示第i个研究对象第j观测的响应变量值;fi是关于参数向量βi和预测变量vi的非线性函数;ei是ni维误差项,假定对于所有的i,ei都服从正态分布并满足E(ei|βi)=0,Var(ei|βi)=Λi(βi, γ);Λi是ei的条件方差,为ni×ni维矩阵,与回归参数向量βi及固定效应γ有关;βi=g(zi, β, bi)为回归向量参数,与p×1维的固定效应β及q×1维的未观测随机效应bi呈函数关系,一般情况只考虑βi与β, bi之间的线性关系,即
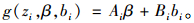
|
(2) |
式中:Ai与Bi为设计矩阵。通常是运用极大似然算法或限制极大似然算法(Harville,1977;Pinheiro et al., 2000)来求解式(1) 中的未知参数,因此必须先求出yi的边缘密度函数p(yi):
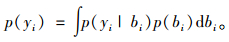
|
(3) |
式中:p(yi|bi)是给定bi时yi的条件分布;p(bi)是随机效应bi的密度函数。
在NLMEMs中,由于随机效应是以非线性形式出现在函数中,尽管p(yi|bi)和p(bi)服从正态分布,但p(yi)不一定服从正态分布,因此该积分求解难度很大。在这种情况下,为了得到yi的条件分布,许多学者提出了不同的计算方法,如广义最小二乘估计法(generalized least squares estimation) (Wolfinger, et al., 1997)、线性化算法(Kuhn et al., 2005;Lindstrom et al., 1988)、高斯-埃尔米特求积法(Gaussian-Hermite quadrature)(Lindstrom et al., 1990;Davidian et al., 2003)、拉普拉斯近似法(Laplacian approximation) (Vonesh,1990;Vaida et al., 2005)等。在这些方法中,线性化算法相对比较实用,不但运算简单,计算速度快,而且计算精度也较高,因此许多学者首选线性化算法来求解NLMEMs,并且一些统计软件如SAS, S-SPLUS等也应用了此算法。
NLMEMs在处理纵向数据、多水平数据及重复数据上有着突出的优势,因此被引入到多门学科,如医学、工学及农学等。在林业上,国外一些学者利用NLMEMs来分析树木优势木平均高生长量、断面积及蓄积等(Fang et al., 2001;Budhathoki et al., 2008;Lewis et al., 2005;Hall et al., 2001;Lappi,1997;Sharma et al., 2007),他们都得出了相同的结论,即NLMEMs比传统的非线性模型精度要高。在国内只有少数几个学者对NLMEMs进行了研究,如李永慈等(2004)利用线性及非线性混合模型对树高生长进行了分析,李春明等(2010)利用NLMEMs对杉木(Cunninghamia lanceolata)优势木平均高进行了研究。他们都是应用了S-PLUS中的nlme函数或SAS中的NLINMIX宏和NLMIXED模块对NLMEMs进行计算,而没有涉及具体的NLMEMs算法。由于S-SPLUS中的nlme模块以及SAS中的NLINMIX宏和NLMIXED模块都包含了多种NLMEMs的算法,因此在使用这些模块前必须全面掌握模块中所含的各种算法。本文介绍了2种常见的求解NLMEMs的线性化算法来分析杉木优势木平均高,分别为一阶线性化算法(first-order linearization, 简称FO算法)和一阶条件期望线性化算法(first-order conditional expectation linearization,简称FOCE算法),并根据实际例子比较了这2种算法的拟合精度。文中所有算法均是在SAS中的NLINMIX模块上实现的。
1 FO算法一阶线性化算法简称FO算法,是Sheiner等(1980)提出的,该算法是基于线性混合模型理论来求解的。在模型中,由于随机效应bi是以非线性形式出现在函数中,因此对函数fi(vi, βi)在点bi处进行一阶泰勒展开,其中假定bi和ei相互独立且服从正态分布,bi满足E(bi)=0。在式(1) 中,令:

|
(4) |
其中:Λi1/2(βi, γ)是矩阵Λi(βi, γ)的Cholesky分解,εi满足E(εi)=0及Var(εi)=Ini,并且bi与εi相互独立。因此一阶线性化模型可以写为:
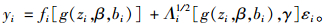
|
(5) |
保留fi[g(zi, β, bi)]一阶泰勒展开式的前2项及Λi1/2[g(zi, β, bi), γ]展开式的第1项,则模型近似为:
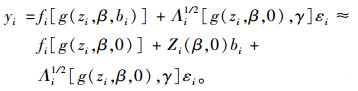
|
(6) |
而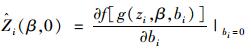
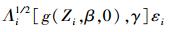
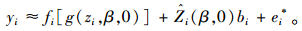
|
(7) |
根据式(7) 可以得到yi的数学期望和方差,分别为:
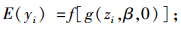
|
(8) |
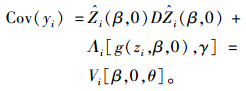
|
(9) |
而θ=[λ′, vech(D)′]′,为D和Λi(i=1, 2, …, m)中待估参数向量。
因此根据yi的边缘分布可得到模型的对数似然函数L(β, θ):

|
(10) |
利用EM算法或Newton-Raphson算法求得参数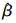

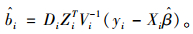
|
(11) |
式中: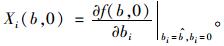
一阶条件期望线性化算法简称FOCE算法,它是Lindstrom等(1990)提出的。该算法是在FO算法的基础上对函数f(β, bi)在bi=bi*及β=处进行一阶泰勒展开,同样假定bi和ei相互独立,且服从正态分布。保留f[g(zi, β, bi)]一阶泰勒展开式的前3项及Λi1/2[g(zi, β, bi), γ]展开式的第1项,则模型近似为:
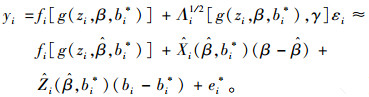
|
(12) |
式中: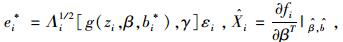
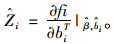
令:

|
(13) |
把式(12) 代入到式(13) 可得:
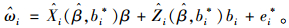
|
(14) |
故把NLMEMs问题转化成求解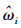
在FOCE算法中,主要包括2个步骤:罚最小二乘步(PNLS)和线性混合效应步(LME)(Pinheiro et al., 2000),模型中的未知参数是由这个2个步骤相互交替运算得到。
第1步(PNLS):在已知σ2和θ的情况下,通过极小化下面的罚目标函数(式15) 得到固定效应β和随机效应bi的估计值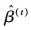
目标函数为:
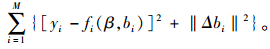
|
(15) |
第2步(LME):在已知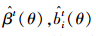
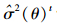
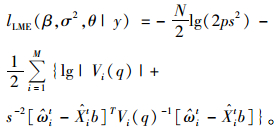
|
(16) |
式中: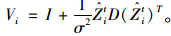
已知参数θt,重新返回到PNLS步,计算第t+1次的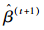

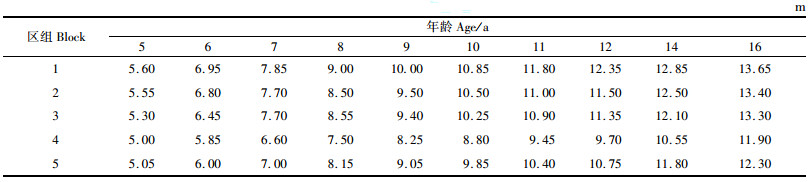
选择中国林业科学研究院林业研究所设在江西省大岗山实验局的固定样地杉木人工林进行研究。试验地的地理坐标为27°30′—27°50′ N,114°30′—114°45′ E,温暖湿润,属于亚热带季风湿润类型。太阳总辐射年平均为486.9 kJ·cm-2, 年均气温15.8~17.7 ℃,年平均降水量1 591 mm。该区属于地带性低山丘陵红壤、黄壤类型及其亚类的分布区。根据初植密度不同把杉木分为5个区组,在每个区组中分别调查了3个样地的杉木优势木平均高,连续调查10年,对应的杉木年龄为5,6,7,8,9,10,11,12,14和16年。其中把每个区组的2个调查试验样地数据的优势木平均高用来模型计算(表 1),另一个样地的试验数据作为检验样本(表 4)。5个区组的初植密度分别为1 667,3 333,5 000,6 667和10 000株·hm-2,样地大小为0.06 hm2。
|
|
|
|

本文选用极大似然估计,对于随机效应bi的误差结构这里只考虑无结构情形,对应SAS程序中即type=un见式(17);也可以根据实际需要选择相应的误差结构。SAS中考虑多种方差类型,如自相关或复合对称等,只要在SAS程序中把type=un语句换成AR(1) 及CS等对应的代码(Littell et al., 1996)。误差项的方差结构本文只考虑了独立同分布情形见式(18),它与随机效应的方差结构一样也可以考虑多种情况。
随机效应方差结构为无结构时对应的方差形式为:

|
(17) |
式中:σi2为第i个随机效应的方差,σij为第i个随机效应与第j个随机效应的协方差。i=1, 2, …,q;j=1, 2,…,q。
误差项的方差结构为独立同分布时,方差的形式为:
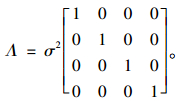
|
(18) |
本文主要目的是介绍NLMEMs的2种线性化算法来分析杉木优势木平均高,并结合实例对2种线性化算法进行比较,确定这2种线性化算法在分析杉木优势木平均高时哪种效果最好。根据表 1中的数据利用2种算法分别求出模型中的未知参数(表 2、表 3),利用式(19) 分别求出各检验样本优势树高的拟合值。然后利用相关指数、均方根误差及平均绝对误差3个评价指标对2种算法的模拟精度进行比较,3种评价指标的计算公式见式(20~22)。为了更清楚地比较这2种线性化算法,本文还画出了各自算法预测优势木平均高时的残差分布图。
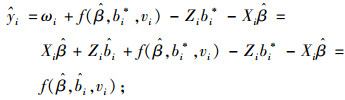
|
(19) |
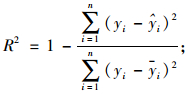
|
(20) |

|
(21) |
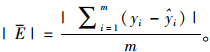
|
(22) |
|
|

|
|
林业上常用Logistic分布族来分析林分优势木平均高与年龄的关系,这类模型含有3个参数,常见的一种Logistic模型为:
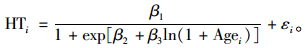
|
(23) |
本文选择模型(23) 作为研究杉木优势木平均高的基础模型,产生随机效应的因子是区组。在确定模型中哪些参数为混合参数时,国外一些学者(Meng et al., 2009; Huang et al., 2001)研究得出当模型(23) 中β1和β3为混合参数时,拟合优势树高的精确度最高。因此本文把式(24) 作为混合模型来对杉木优势木平均高进行研究。

|
(24) |
式中:HTi为第i区组的杉木优势木平均高;Agei为第i区组的年龄;β1, β2及β3为固定效应参数;b1i和b3i为随机效应参数。
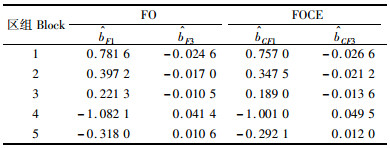
4 结果与分析根据表 1中数据,利用2种线性化算法分别求出NLMEMs中各自参数,见表 2和表 3。表 2分别为2种算法计算出的固定效应参数β1,β2和β3,方差参数sb1,sb3, σb1b3和S及评价指标AIC、AICC和BIC。表 3为2种算法计算出的随机效应估计量。从表 2和表 3中各参数的估计量可看出:2种线性化算法相差不大,对于评价指标AIC, AICC和BIC,FOCE算法略小于FO算法。
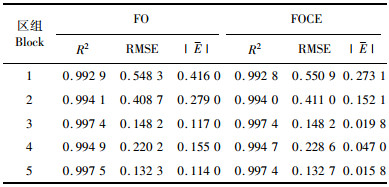
已知模型中的未知参数,根据式(19) 分别计算出2种算法各区组杉木优势木平均高的预测值。从表 4中可以看出:用2种线性化算法来预测的5个区组优势木平均高与实际调查的杉木优势木平均高拟合度较高,并且FO算法和FOCE算法二者所预测的优势木平均高非常接近,从而可得到,利用FOL算法和FOCE算法对模型参数进行估计时,二者效果相差不是很大。根据表 4中的预测值,利用式(20~22) 分别计算出2种算法各自的相关指数、均方根误差及平均绝对误差。从表 5中可以看出:2种算法的相关指数非常高,平均值分别为0.995 4,0.995 3,这证明2种算法对拟合杉木优势木平均高时精确度很高。对于均方根误差和平均绝对误差,FOCE算法比FO算法略小,从而证明这2种算法计算结果比较接近。
|
|
为了更能反映2种算法对真实值的拟合程度,画出了用这2种算法预测所有区组优势木平均高时对应的残差分布图(图 1、图 2)。从图中可以看到,这2种算法的残差分布趋势大体一样,FO算法的残差主要集中在区间-0.13~0.24,FOCE算法的残差主要集中在区间-0.13~0.25,从而进一步表明这2种线性化算法对杉木优势木平均高进行拟合时,效果非常接近。

|
图 1 FO算法残差分布 Fig.1 The residual distribution of FO algorithm |

|
图 2 FOCE算法残差分布 Fig.2 The residual distribution of FOCE algorithm |
本文主要目的是介绍2种线性化算法的NLMEMs对杉木优势树高进行分析,并且根据杉木优势树高的拟合精度对这2种线性化算法进行比较。本文在理论上对2种线性化算法做简要介绍,在这2种算法中,FO算法只考虑的随机效应以非线性形式出现在模型中,而FOCE算法同时考虑了固定效应和随机效应以非线性形式出现在模型中。从本文实际例子拟合结果可看出,这2种线性化算法对拟合杉木优势树高精确度非常高,并且这2种算法拟合效果相差也不大。从理论上来讲,在FO算法中,个体间的差异只能通过线性项Zi(β, 0)bi来解释,并且当随机效应bi之间的差异很大时,该模型利用式(6) 进行参数估计时效果将会很差,得到的固定参数估计量将为有偏,并且精确度也很低。在本文实例中,由于随机效应参数本身比较小,并且随机效应之间相差不是很大,因此不考虑固定效应以非线性出现在模型中对拟合结果影响不大,这可能与林场保护良好并且样地之间的立地条件相差不大有关。当随机效应很大或随机效应之间差别很大时,这2种线性化算法的计算结果将会有明显的差异。
本文是在随机效应方差D的结构为一般情形且误差项方差结构为独立同分布时对未知参数进行求解,通常这2种方差的结构有多种情况,如独立等方差、自相关及复合对称等,这根据实际情况及研究目的而选定它们的各自结构,同时本文还假定随机效应bi和误差项εi相互独立,但在有些情况下二者不一定相互独立,因此要运用其他算法来对未知参数进行求解,还需进一步研究。
| [] | 李春明, 张会儒. 2010. 利用非线性混合模型模拟杉木林优势木平均高. 林业科学, 46(3): 89–95. DOI:10.11707/j.1001-7488.20100314 |
| [] | 李永慈, 唐守正. 2004. 用Mixed和Nlmixed过程建立混合生长模型. 林业科学研究, 17(3): 279–283. |
| [] | Budhathoki C B, Lynch T B, Guldin J M. 2008. Nonlinear mixed modeling of basal area growth for shortleaf pine. For Sci, 255(8): 3440–3446. |
| [] | Davidian M, Giltinan D M. 2003. Nonlinear models for repeated measurement data: an overview and updata. J Agric Biol Environ Statist, 8(4): 387–419. DOI:10.1198/1085711032697 |
| [] | Fang Z, Bailey R L. 2001. Nonlinear mixed effects modeling for slash pine dominant height growth following intensive silvicultural treatments. For Sci, 47(3): 287–300. |
| [] | Hall D B, Bailey R L. 2001. Modeling and prediction of forest growth variables based on multilevel nonlinear mixed models. For Sci, 47(3): 311–321. |
| [] | Harville D A. 1977. Maximum likelihood approaches to variance component estimation and to related problems. J Amer Statist Assoc, 72(358): 320–338. DOI:10.1080/01621459.1977.10480998 |
| [] | Huang S, Morgan D J, Klappstein G, et al. 2001.A growth and yield projection system (GYPSY) for natural and regenerated lodgepole pine stands in alberta.Alberta Sustainable Resource Development Tech Rep Publ T/485.193. |
| [] | Kuhn E, Lavielle M. 2005. Maximum likelihood estimation in nonlinear mixed effects models. Comut. Statis Data Anal, 49(4): 1020–1038. DOI:10.1016/j.csda.2004.07.002 |
| [] | Lappi J. 1997. A longitudinal analysis of height/diameter curves. For Sci, 43(4): 555–570. |
| [] | Lewis J, Richard F D, Clark A, et al. 2005. Multievel nonlinear mixed-effects models for the modeling of earlywood and latewood microfibril angle. For Sci, 51(4): 357–371. |
| [] | Lindstrom M J, Bates D M. 1988. Newton-Raphson and EM algorithms for linear mixed-effects models for repeated-measures data. Journal of the American Statistical Association, 83(404): 1014–1022. |
| [] | Lindstrom M J, Bates D M. 1990. Nonlinear mixed effects models for repeated measures data. Biometrics, 46(3): 673–687. DOI:10.2307/2532087 |
| [] | Littell R C, Milliken G A, Stroup W W, et al. 1996. SAS system for mixed models. SAS Institute Inc., Cary, NC. |
| [] | Meng S X, Huang S. 2009. Improved calibration of nonlinear mixed-effects models demonstrated on a height growth function. For Sci, 55(3): 239–248. |
| [] | Pinheiro J C, Bates D M. 2000. Mixed-effects models in S and S-PLUS. Springer-Verlag, New York, NY, 528. |
| [] | Sharma M, Parton J. 2007. Height-diameter equations for boreal tree species in Ontario using a mixed-effects modeling approach. For Ecol Manag, 249(3): 187–198. DOI:10.1016/j.foreco.2007.05.006 |
| [] | Sheiner L B, Beal S L. 1980. Evaluation of methods for estimating population pharmacokinetic paramteres. I.Michaelis-menton model routine clinical pharmacokinetic data.Journal of Pharmacokinetics and Biopharmaceutics, 8(6): 553–571. |
| [] | Vaida F, Meng X L. 2005. Two slice EM algorithms for fitting generalized linear mixed models with binary response. Statistical Modelling, 5(3): 229–242. DOI:10.1191/1471082X05st097oa |
| [] | Vonesh E F. 1990. A note on the use of Laplace's approximation for nonlinear mixed-effects models. Biometrika, 83(2): 447–452. |
| [] | Wolfinger R D, Lin X. 1997. Two taylor-series approximation methods for nonlinear mixed models. Comput Statist Data Anal, 25(4): 465–490. DOI:10.1016/S0167-9473(97)00012-1 |