 2012, Vol. 48
2012, Vol. 48文章信息
- 符利勇, 李永慈, 李春明, 唐守正
- Fu Liyong, Li Yongci, Li Chunming, Tang Shouzheng
- 利用2种非线性混合效应模型(2水平)对杉木林胸径生长量的分析
- Analysis of the basal area for Chinese Fir plantation using two kinds of nonlinear mixed effects model(two levels)
- 林业科学, 2012, 48(5): 36-43.
- Scientia Silvae Sinicae, 2012, 48(5): 36-43.
-
文章历史
- 收稿日期:2011-03-18
- 修回日期:2011-07-06
-
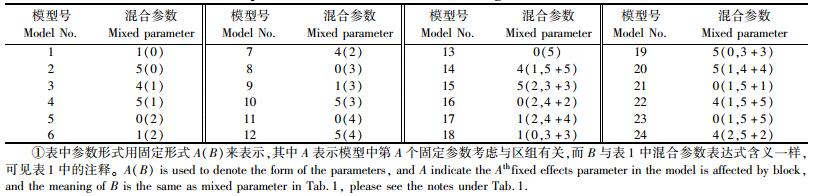
作者相关文章



2. 北京林业大学理学院 北京 100083
2. College of Science, Beijing Forestry University Beijing 100083
非线性混合效应模型(nonlinear mixed effects model,简称NLMEM)这个概念最早是Sheiner等(1980)提出来的,该模型包含固定效应参数(fixed-effects parameter)和随机效应参数(random effects parameter)2类参数,是依据回归函数依赖于这2类参数的非线性关系而建立的。NLMEM在处理纵向数据、多水平数据及重复数据上有着突出的优势,因此被引入到多门学科中,如医学、工学及农学等(Chen, 2005)。根据随机效应的嵌套个数,可以把NLMEMs分为单水平NLMEMs、嵌套2水平NLMEMs及嵌套多水平NLMEMs。单水平NLMEMs是指模型中随机效应不考虑嵌套并且是由1个影响因子产生的NLMEMs;2个相互嵌套随机效应因子产生的NLMEMs称为2水平NLMEMs;3个或3个以上逐级嵌套的随机效应因子产生的NLMEMs称为多水平NLMEMs。
在林业上,国外大部分学者运用单水平NLMEMs分析树木优势高生长量、断面积及蓄积等(Fang et al., 2001;Budhathoki et al., 2008;Jordan et al., 2005; Hall et al., 2001; Lappi, 1997; Sharma et al., 2007),都得出了相同的结论,即NLMEMs比传统的非线性模型精度高。而针对嵌套2水平的NLMEMs,国外研究较少,如Jordan等(2005)利用嵌套2水平NLMEMs分析早材和晚材的微纤维倾斜角,得出考虑嵌套2水平NLMEMs拟合效果优于传统的非线性回归模型和单水平NLMEMs。在国内只有少数几个学者对NLMEMs进行了研究,如李永慈等(2004)利用线性及NLMEMs对树高生长进行了分析;李春明等(2010)利用NLMEMs对杉木(Cunninghamia lanceolata)优势木平均高进行了研究。他们研究的都是单水平NLMEMs,对于嵌套2水平NLMEMs的研究国内还尚未见报道。
嵌套2水平NLMEMs比单水平NLMEMs增加了1类随机效应因子,并且2类随机效应因子之间是相互嵌套的。本文中这2类因子分别是区组和样地。嵌套2水平NLMEMs把回归模型中随机误差分解成3部分:第1水平随机效应因子产生的随机效应、第2水平因子产生的随机效应和随机误差,这样可提高模型的预测精度。另外在利用嵌套2水平NLMEMs对杉木胸高断面积进行研究时,可根据各个区组和样地产生的随机效应值来评价它们对杉木胸高断面积的影响程度。
本文除了利用嵌套2水平NLMEMs对杉木胸高断面积进行研究外,同时在模型1的基础上还考虑了固定效应参数受某些因子水平的影响,即因子的每个水平都有一个固定参数值与之相对应(又称对固定效应参数分级),因此模型2充分考虑了影响因子不同水平对固定效应影响差异,从而进一步提高了模型的预测精度。这种方法在国内外林业研究中还尚未见报道,但许多实例证明它比嵌套2水平的NLMEMs(模型1)精度还要高。
1 嵌套2水平非线性混合模型概述一般性嵌套多水平非线性混合模型(multilevel nonlinear mixed effects model)是指随机效应以逐级嵌套形式出现在模型中的非线性混合模型,简称MNLMEM(模型1)。MNLMEMs模型比单水平NLMEMs更为复杂,对于嵌套2水平的NLMEMs,模型表达式为:
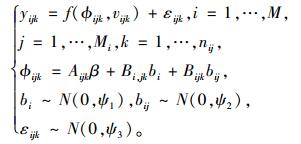
|
(1) |
式中:M为第1水平因子的分组数;Mi为第1水平因子第i分组数对应的第2水平因子的分组数;nij为第1水平因子第i分组数对应的第2水平第j分组数的重复观测次数;β为p维的固定效应;bi为第1水平因子的随机效应,大小为q1维,假定服从期望为0、方差为ψ1的正态分布;bij为第2水平因子的随机效应,大小为q2维,假定服从期望为0、方差为ψ2的正态分布;εijk为第1水平因子第i分组第2水平因子第j分组对应第k次观测时的误差项,假定服期望为0、方差为ψ3的正态分布,ψ3一般取σ2I;yijk为第1水平因子第i分组第2水平因子第j分组对应第k次的相应变量观测值;ϕijk为回归参数向量,为了计算简单通常与β,bi及bij呈线性关系;vijk为第1水平因子第i分组第2水平因子第j分组对应第k次的解释变量观测值;Aijk,Bi, jk}及Bijk分别为固定效应β、随机效应bi及bij设计矩阵。

|
对于考虑固定参数受影响因子而变化的嵌套2水平NLMEMs见模型2,模型2是在模型1的基础上进一步优化,除了把固定效应β变为βi(i=1, 2,…,M)或βij(i=1, 2,…,M, j=1, 2,…,Mi)外,其他参数和变量与模型1完全相同。如果考虑固定参数受第1水平因子的影响则为βi,受第2水平因子的影响则为βij。由于本文试验区域主要是用来研究初植密度对杉木生长量的影响,各区组是按照不同初植密度来划分的,而样地是在各个区组中随机设置,因此本文只考虑各固定效应受区组的影响。
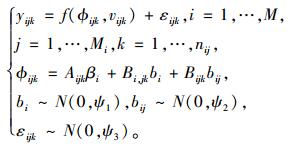
|
(2) |
选择江西省大岗山实验局人工杉木林的固定样地进行研究。试验地的地理坐标为27°30′—27°50′ N, 114°30′—114°45 E,温暖湿润,属亚热带季风湿润类型。太阳总辐射年平均为486.9 kJ·cm-2;年均气温15.8~17.7 ℃,年平均降水量1 591 mm;该区属于地带性低山丘陵红壤、黄壤类型及其亚类的分布区。根据初植密度不同把杉木分为5个区组,在第5个区组中调查了3个样地部分杉木优势高、胸径,其他4个区组分别调查了2个样地,连续调查10年,对应的杉木年龄为3, 4, 5, 6, 7, 8, 9, 10, 12和14年。从每个样地中选出1株杉木作为检验样本,其他杉木数据用于模型计算。根据建模数据,分别计算出各样地杉木平均优势高、胸高断面积和林分密度指数。5个区组的初植密度为1 667, 3 333, 5 000, 6 667和10 000株·hm-2,样地大小为0.06 hm2。
2.2 研究方法利用模型1和模型2对杉木胸径生长量进行研究,2个水平因子分别为区组和样地。运用的参数估计方法是极大似然法,假定随机效应bi,bij和随机误差εij都服从正态分布,且相互独立;并且各自的期望都为0,随机效应对应的方差ψ1及ψ2为一般情形,随机误差对应的方差ψ3为独立等方差。
利用建模数据,分别计算出模型1和模型2对应的所有混合模型参数,并利用指标AIC(akaike information criteria)及BIC(bayesian information criteria)的大小对这些混合模型进行比较(这些指标满足“越少越好”的原则),选择出模型1及模型2中各自的最优模型。设l为对数极大似然函数,n为观测总数,d为模型中固定参数个数,指标的计算公式如下:
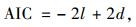
|
(3) |

|
(4) |
利用模型1和模型2对应的最佳混合模型以及回归模型对检验样本胸径生长量进行预测,并利用相关指数(R2)、均方根误差(RMSE)及平均绝对误差(|E|)3个指标对这3种预测结果进行评价。3个评价指标中,相关指数越大且均方根误差及平均绝对误差越小,证明模型拟合精度越高。为了更清楚地比较回归模型和混合模型的效果,笔者还对11个检验样本的胸高断面积实际值、回归模型预测值、模型1预测值、模型2预测值两两进行了总体均值配对检验,同时还给出了模型1、模型2及回归模型预测胸径生长量对应的残差分布图。所有计算均在S-PLUS 2000上实现。
2.3 模型选择李春明等(2010)利用单水平NLMEMs对华北落叶松(Larix olgensis)断面积生长量进行了研究,选择Richards和Schumacher等4种形式的模型作为基本模型,利用最小二乘回归参数估计方法对4种基础模型进行拟合,选择确定系数、均方根误差和平均绝对残差对模拟结果进行比较分析,最后确定Schumacher断面积模型[式(5)]作为构建混合模型的基础模型效果最好,本文同样选用该模型作为构建嵌套2水平NLMEMs的基础模型。基础模型[式(5)]中有6个固定效应参数,针对模型1,这6个固定效应参数可以3种形式出现在模型中,分别为不考虑随机效应、考虑单水平随机效应及考虑2水平随机效应。对于不考虑随机效应的参数称为非混合参数,而考虑单水平或2水平随机效应的参数称为混合参数。针对模型2,这6个固定效应参数可以4种形式出现在模型中,其中非混合参数包含2种情况:不考虑受第1水平因子的影响、考虑受第1水平因子的影响;混合参数包含2种情况:考虑单水平随机效应和考虑2水平随机效应。本文研究的混合模型至少包含1个考虑2水平随机效应的参数。由于基础模型含有6个参数,因此对于模型1能衍生出665种嵌套2水平NLMEMs,具体为:混合参数都考虑2水平随机效应时有

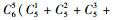
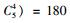


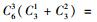
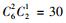
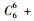
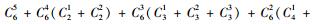
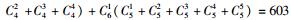
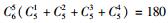

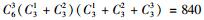
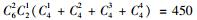
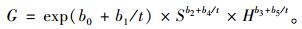
|
(5) |
式中:G为年龄t时杉木的胸高断面积;S为林分密度指数;H为杉木优势高;t为杉木年龄。胸高断面积及密度指数的计算公式如下:
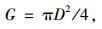
|
(6) |
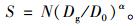
|
(7) |
式中:D为杉木胸径;N为单位面积杉木株数;Dg为样地中林分平方平均直径;D0为林分标准直径;α为杉木林自然疏率。
3 结果与分析 3.1 模型1的计算及分析 3.1.1 模型1中最佳拟合模型选择对模型1衍生出的665种嵌套2水平NLMEMs进行计算时,只有57种模型计算收敛,这些收敛模型的具体参数结构见表 1。从表 1中可看出:当混合参数全考虑2水平随机效应时,混合模型参数最多为2个,大于2个时模型不收敛;当混合参数部分考虑2水平随机效应时,要使得模型收敛,混合参数最多为3个,并且考虑2水平随机效应的混合参数只能为1个。通过计算可知:在这57个收敛模型中,对数似然函数值logLik集中分布在[-200, -100]之间,平均值为-172.616,其中模型号为22的AIC及BIC值最小(AIC=244.5,BIC=282.3),而对数似然函数值最大(logLik=-108.3),因此把衍生出来的第22号模型作为模型1的最佳拟合模型,模型表达式如下:
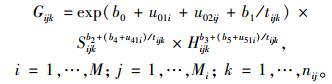
|
(8) |
式中:M为区组水平数;Mi为第i区组中对应的样地水平数;nij为第i区组中第j个样地对应的研究对象观测次数。
|
|
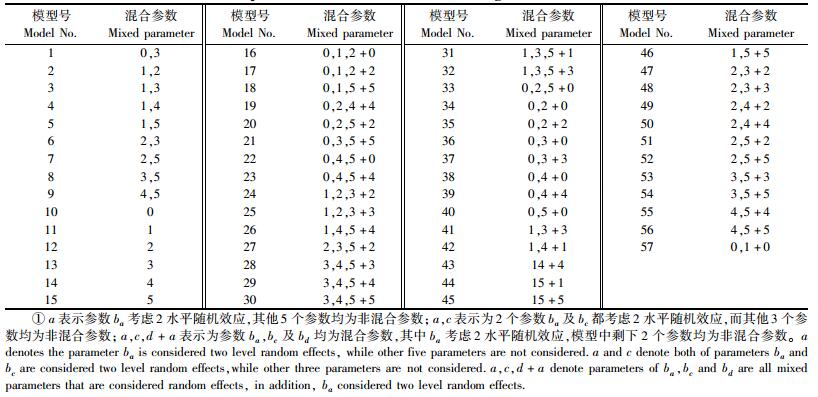
运用S-SPLUS软件计算出模型1对应的最佳模型[式(8)]中各自固定效应参数值b0, b1, b2, b3, b4, b5(表 2)和随机效应参数值u01, u04, u05, u02(表 3,4)及方差ψ1, ψ2及ψ3。由于该模型2水平随机效应分别是由区组和样地2个因子产生的,因此各混合参数的第1水平随机效应个数等于区组个数,即为5个,混合参数b0对应的第2水平随机效应u02个数为样地个数,即11个。表 2为模型中6个固定效应的估计值,同时还列出了固定效应各自的参数统计量。表 3给出了由各区组产生的随机效应值,从表 3中可看出:区组1产生的随机效应最大,而区组3产生的随机效应最小。表 4给出了由各样地间产生的随机效应值,相对于区组,表 4中各样地间产生的随机效应非常小。
|
|

|
|

通过计算分别得到第1水平随机效应方差ψ1、第2水平随机效应方差ψ2及随机误差方差ψ3的估计量:
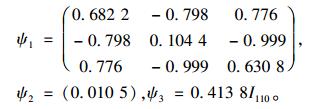
|
(9) |
运用S-SPLUS软件对模型2衍生出的2 703种模型进行计算,结果有24种模型计算收敛,各模型具体的参数结构见表 5。从表 5中可看出:所有收敛模型只考虑了1个固定效应参数与区组有关,对于考虑2个或2个以上时计算都不收敛,并且在每种收敛模型中考虑2水平的混合参数只有1个。所有收敛模型对应的对数似然函数值logLik集中分布在[-200, -100]之间,平均值为-160.425,其中以模型号为23的AIC及BIC最小(AIC=231.2,BIC=271.7),而对数似然函数值最大(logLik=-100.6),因此把衍生出来的第23号模型作为模型2的最佳拟合模型,模型表达式如下:
|
|


|
(10) |
式中:M为区组水平数;Mi为第i区组中对应的样地水平数;nij为第i区组中第j个样地对应的研究对象观测次数。
3.2.2 模型2对应的最佳拟合模型参数计算运用S-SPLUS软件计算出模型2对应的最佳模型[式(10)]中各自固定效应参数值b0, b1, b2, b3, b4, b5和随机效应参数值u11,u51,u52及方差ψ1,ψ2及ψ3。由于在式(10)中只考虑固定效应b0与区组有关,因此对应的b0有5个取值,而其他固定效应只有1个取值(表 6)。表 7为第1水平随机效应u11和u51的取值,表 8为第2水平随机效应u52的取值。从表 8中可看出:第2水平随机效应u52都很小,接近于零,因此可以认定当利用式(10)来分析胸径生长量时,样地产生的随机效应可以忽略不计。对应的第1水平随机效应方差ψ1、第2水平随机效应方差ψ2及随机误差方差ψ3的估计值见式(11):
|
|
|
|

|
|

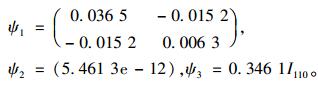
|
(11) |
通过建模数据,运用最小二乘回归参数估计方法对模型[式(5)]进行拟合,得到的参数估计值分别为:b0=4.581 6,b1=-16.019 6,b2=-0.925 3,b3=2.558,b4=1.704 2,b5=3.091 1。然后利用回归模型、模型1[式(8)]及模型2[式(10)]对检验样本的胸高断面积进行预测,并且计算出各自的相关指数、均方根误差及平均绝对误差(表 9)。从表 9中可看出:回归模型对应的相关指数(R2=0.995 9)比模型1(R2=0.999 3)及模型2(R2=0.999 2)要小,相应的均方根误差(RMSE=2.076 5)及绝对误差(|E|=5.094 3)比模型1(RMSE=0.783 1, |E|=0.517 7)及模型2(RMSE=0.373 6, |E|=0.265 3)都要大,模型1与模型2的相关指数非常接近,但模型2的均方根误差及绝对误差比模型1却要小很多,表明模型1和模型2的拟合效果比回归模型要好,而且模型2拟合的效果最好。表 10为检验样本胸高断面积实际值、回归模型拟合值、模型1拟合值及混合模型2拟合值之间两两进行总体均值配对检验时的统计表。图 1为回归模型、混合模型1及混合模型2预测时的残差分布图。
|
|

|
|
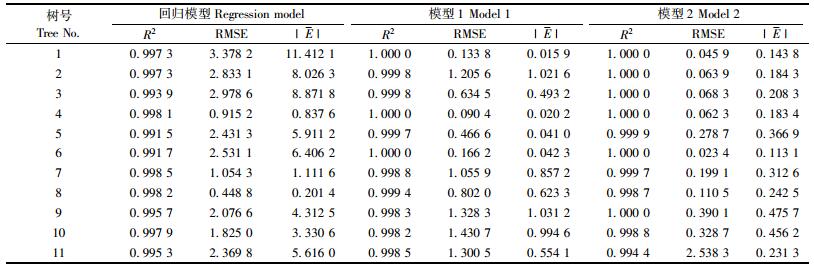
从表 10中可以看出:样本胸高断面积实测值与回归模型预测值的样本成对检验时P < 0.05, 彼此差异显著;而与模型1及模型2的预测值样本成对检验时P>0.05,彼此差异不显著。回归模型预测值与模型1及模型2预测值差异显著(P < 0.05),模型1与模型2之间差异不显著(P>0.05)。通过两两成对检验,可得知混合模型预测值比回归模型要好,而模型2(P=0.615)比模型1(P=0.543)更接近真实值,故用模型2来预测杉木胸高断面积效果更好,图 1进一步证实了此结论。
|
|


|
图 1 回归模型、模型1和模型2的残差分布 Fig.1 The residual distribution of regression model, Model 1 and Model 2 |
NLMEMs在分析重复数据及多水平数据方面有着突出的优势,本文利用2种嵌套2水平NLMEMs对杉木胸径生长量进行分析,模型1为单纯的嵌套2水平NLMEMs,而模型2是在模型1的基础上考虑了模型中固定效应参数取值与特定影响因子水平有关。文中产生2个水平随机效应的因子分别是区组和样地,并且模型2中考虑固定效应与区组有关。与一般的NLMEMs不同,混合模型考虑了不同区组及样地对杉木胸高断面积的影响,并且混合模型还把随机误差分解成3部分,即由区组产生的随机效应、由样地产生的随机效应和随机误差。利用嵌套2水平NLMEMs(模型1)分析时,既能提高精度,又可以分析区组及样地对杉木胸高断面积的影响,模型2是在模型1的基础上对模型进一步优化,它考虑了模型中固定效应参数还与某些因子有关,因此从理论上来讲更能提高模型预测精度。本文简要地介绍了模型1和模型2,对于更多地了解多水平NLMEMs算法见参考书(Pinheiro et al., 2000)。
本文选用式(5)作为构建嵌套2水平NLMEMs的基础模型,由于基础模型中有6个固定效应,因此模型1能衍生出665种2水平模型而模型2可以衍生出2 703种。通过对这些模型的计算得知模型1有57种模型计算收敛,而模型2有24种,这可能是由于本文试验数据与NLMEMs算法有关系。模型2收敛的数量比模型1要少,这可能是由于模型2在模型1的基础上增加了4个待估参数,从而使得运算更为复杂。通过对各种收敛模型进行比较分析,最后确定对于模型1式(8)为最佳拟合模型,对于模型2式(10)为最佳拟合模型。为了比较回归模型、模型1和模型2的拟合效果,运用了这3种模型分别对11个检验样本进行了分析,通过相关指数、均方根误差及平均绝对误差3个评价指标以及样本均值配对检验,最后得出了模型2拟合效果最好,这与理论分析相吻合,因此在实际运用时可选用模型2来预测杉木胸高断面积。
嵌套2水平NLMEMs不仅可以提高拟合精度,而且还可用于分析各区组及样地对杉木胸高断面积的影响程度。文中5个区组主要是由杉木的初植密度不同而划分的,分别为1 667, 3 333, 5 000, 6 667和10 000株·hm-2。对于模型1,从表 3中可看出:区组1产生的随机效应都比其他区组大,因此初植密度对该区组中杉木胸高断面积贡献率最大;区组3产生的随机效应最小,因此初植密度对该区组杉木的胸高断面积正贡献最小。区组5中随机效应u01和u51为负最大,因此它对杉木胸高断面积负贡献率最大。在表 4中各样地间的随机效应相差不大,这表明各样地间的立地条件、坡度、坡向等影响因子相差不大。对于模型2,从表 7中可看出:区组5产生的随机效应最大,因此利用模型2来预测杉木的胸高断面积时,区组5对杉木的胸高断面积贡献率最大,而区组3产生的随机效应最小,因此区组3对胸高断面积影响较小。在表 8中,各样地产生的随机效应都非常小并且接近零,因此可得出运用模型2分析杉木胸高断面积时,各样地对杉木的影响较少,可以忽略不计。
本文中假定2个水平之间的随机效应及随机误差之间相互独立,并且2个随机效应的方差ψ1和ψ2为无结构类型方差(unstructured),随机误差的方差为独立等方差。在实际中,由于各种不同的试验设计及抽样调查,从而ψ1和ψ2还满足一些特殊结构,比如复合对称、自相关等,这些还需要进一步研究。
| [] | 李春明, 唐守正. 2010. 基于非线性混合模型落叶松云冷杉林分断面积模型. 林业科学, 46(7): 106–113. DOI:10.11707/j.1001-7488.20100716 |
| [] | 李永慈, 唐守正. 2004. 用Mixed和Nlmixed过程建立混合生长模型. 林业科学研究, 17(3): 297–283. |
| [] | Budhathoki C B, Lynch T B, Guldin J M. 2008. Nonlinear mixed modeling of basal area growth for shortleaf pine. Forest Ecology and Management, 255(8/9): 3440–3446. |
| [] | Chen Z. 2005. The full EM algorithm for the MLEs of QTL effects and positions and their estimated variances in multiple-interval mapping. Biometrics, 61(2): 474–480. DOI:10.1111/biom.2005.61.issue-2 |
| [] | Fang Z, Bailey R L. 2001. Nonlinear mixed effects modeling for slash pine dominant height growth following intensive silvicultural treatments. Forest Science, 47(3): 287–300. |
| [] | Hall D B, Bailey R L. 2001. Modeling and prediction of forest growth variables based on multilevel nonlinear mixed models. Forest Science, 47(3): 311–321. |
| [] | Jordan L, Daniels R F, Clark Ⅲ, et al. 2005. Multilevel nonlinear mixed-effects models for the modeling of earlywood and latewood microfibril angle. Forest Science, 51(4): 357–371. |
| [] | Lappi J. 1997. A longitudinal analysis of height/diameter curves. Forest Science, 43(4): 555–570. |
| [] | Pinherio J C, Bates D M. 2000. Mixed effects models in S and S-PLUS. Statistics and Computing, Springer, New York, NY. |
| [] | Sharma M, Parton J. 2007. Height-diameter equations for boreal tree species in Ontario using a mixed-effects modeling approach. Forest Ecology and Management, 249(3): 187–198. DOI:10.1016/j.foreco.2007.05.006 |
| [] | Sheiner L B, Beal S L. 1980. Evaluation of methods for estimating population pharmacokinetic parameters. I.Michaelis-menten model: routine clinical pharmacokinetic data.Journal of Pharmacokinetics and Biopharmaceutics, 8(6): 553–571. |