 2012, Vol. 48
2012, Vol. 48文章信息
- 赵磊, 倪成才, GordonNigh
- Zhao Lei, Ni Chengcai, Gordon Nigh
- 加拿大哥伦比亚省美国黄松广义代数差分型地位指数模型
- Generalized Algebraic Difference Site Index Model for Ponderosa Pine in British Columbia, Canada
- 林业科学, 2012, 48(3): 74-81.
- Scientia Silvae Sinicae, 2012, 48(3): 74-81.
-
文章历史
- 收稿日期:2010-08-30
- 修回日期:2010-10-21
-
作者相关文章



2. 中国林业科学研究院资源信息研究所 北京 100091;
3. British Columbia Ministry of Forests, Lands and Natural Resources Operations, Forest Analysis and Inventory Branch, P.O.BOX9512, Stn.Prov.Govt. Victoria, B.C. V8W 9C2, Canada
2. Institute of Forest Resources Information Techniques, CAF Beijing 100091;
3. British Columbia Ministry of Forests, Lands and Natural Resources Operations, Forest Analysis and Inventory Branch, P.O.BOX9512, Stn.Prov.Govt. Victoria, B.C. V8W 9C2, Canada
森林的可持续经营管理需要对森林生产力有着精确的估计。常用立地生产力的指标为地位指数,即指数年龄时的优势木树高。描述优势木树高和年龄关系的统计模型称为地位指数模型,地位指数模型可将现实林分的优势木树高转化为指数年龄时的树高。构建地位指数模型的主要方法之一为代数差分法(algebraic difference approch, ADA)(Bailey et al., 1974)。ADA法要么仅能构造出有多个水平渐进极值的单形曲线族,要么仅能构造出仅有1个水平渐进极值的多形曲线族。针对这一不足,Cieszewski等(2000a)又提出广义代数差分法(generalized ADA, GADA)。由于GADA法能够构建具有可变水平渐进极值的多形地位指数曲线族,因而受到了广泛关注(Amaro et al., 1998; Barrio, 2005)。差分型地位指数模型在国内研究中已经有所应用(段爱国等, 2004),但在模型构建、拟合方法和数据质量上还存在不足。总的来看,国内对于多形地位指数模型有着比较深入的研究(吴承祯等, 2002; 陈信旺等, 2005; 郑曼等, 2008; 陈绍玲, 2008),但对于差分型地位指数模型的构建方法、参数估计技术和模型的具体应用尚缺乏系统的研究。
本研究的数据来源于加拿大哥伦比亚省(British Columbia)美国黄松(Pinus ponderosa)林分79个临时样地的纵向剖面解析木数据,数据被随机地分成模型拟合和模型验证2部分。基于3种常用的理论生长模型,导出并拟合了8个差分型地位指数模型,ADA法和GADA法各有4个模型。差分型地位指数模型常用的参数估计方法为“直接最小二乘法”,此法在拟合差分型模型时存在统计逻辑上的缺陷(倪成才等, 2010),因而本文采用Cieszewski等(2000b)提出的“分类变量回归法”。模型筛选采用拟合统计量与图形分析相结合的方法,并着重突出了图形分析的重要性。本研究的目的是建立加拿大哥伦比亚省美国黄松的差分型地位指数模型,并对模型的筛选和应用进行较为全面的分析研究。
1 材料与方法 1.1 数据来源本文数据来源于加拿大哥伦比亚省美国黄松林分的抽样调查资料。按照加拿大林业研究的标准,哥伦比亚省林业局于2000和2001年夏天建立了100个临时样地。样地设置时充分考虑了现有林分的立地质量、年龄、密度以及物种的丰富度等因素,从中选取具有代表性的林分作为样地。样地分布遍及了哥伦比亚省内的美国黄松林分,基本涵盖了整个哥伦比亚省黄松林分的立地水平。样地形状为圆形,面积为0.01 hm2(半径5.64 m)。每个样地严格挑选1株未受损伤的、未受压的、健康的优势木或亚优势木作为样木。由于有些样地无法选出符合标准、能够充分反映样地立地水平的样木,或在内业解析分析中发现样木存在不规则的生长时期而剔除,最终得到79个样地的解析木数据,仍具有充分的代表性和广泛性。样木伐倒后,对于树桩和树干部分采取纵切的方法,由髓心直接查出树高-年龄值,对于不适合做纵切的树梢部分采取轮生枝法确定每年的树高生长量,因此可以精确得到1株样木每年的树高值。这样获得的树高-年龄数据的方法,其精确性要远远高于通常采用的截取圆盘进行树干解析的方法,数据的详细介绍见文献(Nigh, 2004)。
图 1给出了79株样木的树高生长过程曲线以及其平均高随年龄变化曲线(粗线),它们的变化趋势对于后面模型的选择和评估有着重要作用。由图 1可以看到,在150~200年的年龄区间内,缺乏较高立地质量(优势木高在30 m以上)上的数据,这可能会影响到备选模型在此区间上的预测性能。

|
图 1 优势木树高及其平均高随年龄变化曲线 Fig.1 Dominant height and mean structure (thick line) against age |
通常有3种基本方法构建地位指数曲线(Barrio, 2005):导向曲线法、参数预估法和代数差分法, 其中,代数差分法已逐渐成为立地质量曲线拟合时首选的方法(段爱国等, 2004)。差分型地位指数模型的推导方法目前有3种: 1) Clutter(1963)提出的导数积分法;2) Bailey等(1974)提出的代数差分法(ADA法);3) Cieszewski等(2000a)提出的广义代数差分法(GADA法)。用这3种方法推导时,必须在基本模型里预先指定“与立地相关参数”(site-dependent parameter, SDP)和“与立地无关参数”(site-independent parameter, SIP)(倪成才等, 2010)。相比于导数积分法,ADA法和GADA法由于原理简单而得到了广泛应用。
ADA法在基本模型中仅确定1个参数为SDP,其他参数为SIP。由基本模型y1=f(t1, SDP, SIP)解出SDP=φ(y1, t1, SIP),然后重新代入基本模型y2=f(t2, SDP, SIP)中,即推出差分型地位指数模型y2=g(y1, t1, t2, SIP)。ADA法的核心在于消去基本模型中的1个SDP参数, 但由于基本模型中有多个参数,有可能存在多个参数为SDP的情况。针对ADA法这一不足,Cieszewski等(2000a)提出了GADA法。
GADA法允许指定多个参数为SDP,即y1=f(t1, SDP1, SDP2, …, SIP)。推导时首先要假设1个新的参数χ与每个SDP有简单的函数关系[SDP1=ψ(χ), SDP2=η(χ), …],代换基本模型中的SDP参数,基本模型即变为y1=ρ(t1, χ, SIP)。然后,与ADA法相同,解出χ=φ(t1, y1, SIP)后重新代入基本模型即可。GADA法的核心在于建立新参数χ与SDP的简单函数关系以及解出参数χ的表达式,在求解χ的表达式时往往要使用韦达定理。显然,如果仅假设参数χ与1个SDP参数有相等的函数关系,这时GADA法就等同于ADA法,因此ADA法可以理解为GADA法的一个特例。
由ADA法、GADA法推导出的差分型地位指数模型均具有差分型生长方程的优良性质(倪成才等, 2010),即: 1)当t2=t1时,y2=y1;2)对于任意给定的t2,由不同的t1计算所得的y2均相同,与t1取值无关,称为参考林龄无关性(reference-age invariance)。因此该类模型可以考虑到不同林分生长过程间的差异并有效地保持生长与收获间的一致性。与总体平均模型相比,在不增加模型参数的前提下,能够显著降低模型拟合的均方差(mean squared error, MSE),并表现出更好的预测能力。对于GADA法来说,还可以假设1个基本模型中的水平渐进极值参数和1个与曲线形状有关的参数为SDP,从而推导出多形的、具有可变水平渐进极值的差分方程,因此GADA法在理论思想上要先进于ADA法。
1.3 模型选择目前,已经有大量的数学模型被应用于拟合优势木树高和年龄间的关系。对于地位指数模型来说,最重要和最理想的性质有以下几点(Barrio, 2005): 1)逻辑性,即年龄为零时树高应为零,地位指数应等于指数年龄时的树高;2) S形生长趋势;3)具有水平渐进极值;4)多形性;5)形式简单,即模型拥有较少的参数;6)基准年龄无关性。其中,多形性和基准年龄无关性是最为重要的性质,满足以上这些性质要依赖于模型的构建方法和基本模型的性质。
表 1列出了本文采用ADA法和GADA法推导的8个差分型地位指数模型,其中E1~E4是由ADA法推导出的4个在林业上常用的传统代数差分方程,E5~E8是由GADA法推导出的4个广义代数差分方程。其中,模型E1,E2,E5,E6基于Lundqvist-Korf模型(Lundgvist, 1957)推导而来,模型E3,E7基于Hossfeld Ⅳ模型(Cieszewski et al., 1989)推导而来,模型E4,E8基于Chapman-Richards模型(Richards, 1959)推导而来。模型E1, E2, E4(Barrio, 2005), E3(Adame et al., 2006), E5, E8(Cañellas et al., 2008), E6, E7(Cieszewski et al., 2000b)均已有过相应的研究和应用。上述8个备选模型均满足多形性和基准年龄无关性要求。
|
|

关于差分型地位指数模型中SIP参数的估计,常用的方法有4种(倪成才等, 2010): 1)直接最小二乘估计法;2)分类变量回归法;3)混合效应模型法;4)度量误差模型法。假设差分型地位指数模型为y2=f(y1, t1, t2, SIP),4种方法中直接最小二乘估计法最为简单,因此得到了广泛应用;但此法由于对y1和y2不同的属性假设而存在统计逻辑上的缺陷(倪成才等, 2010)。为克服这一缺陷,常采用双树高双年龄的数据结构(段爱国等, 2004),而这样的数据结构又会造成拟合误差被严重低估。混合效应模型法(Ni et al., 2007)应用时须假设SDP服从一个已知的统计分布,在该假设不满足时不能应用。度量误差模型法(Wang et al., 2004)中,虽然y1和y2并无因变量和应变量之分,但同样要求构造特殊的数据结构,而数据结构是否影响参数的估计尚在研究之中。因此以上方法皆不便于应用。
本文将采用分类变量回归法来拟合模型,分类变量回归法是Cieszewski等(2000b)针对于直接最小二乘估计法的不足提出来的。假设共有n个样地的数据,则共需要n个分类变量,拟合的模型形式为:
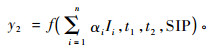
|
式中:Ii为分类变量,对于第i个样地取值为1,其他为0。除参数向量SIP外, 方程还含有n个参数,分别为α1~αn,拟合该模型时相当于同时拟合n条曲线,每条曲线均具有自己的αi值和共同的参数向量SIP。在应用时,首先要在原始数据的基础上添加n个分类变量,然后使用SAS软件的ETS MODEL过程拟合出参数估计值。分类变量回归法对于αi的估计充分利用了第i个样地的所有数据,估计效率上要高于其他方法。
1.5 模型比较对于模型性能的比较,要从统计指标和生物学2方面均衡考虑。基于这一点,本文对于不同模型的比较分析主要包括以下3个方面: 1)拟合质量;2)模型验证;3)图形分析。
拟合质量是指模型在拟合时表现出的统计特征。模型的选择是一个复杂的过程,并不存在一个广泛接受的模型选择指标,因而不能依靠一个指标去判定模型的表现。本文选用了5个常用的统计指标,应用于模型拟合质量的评估:平均误差(MR)、绝对平均误差(AMR)、均方根误差(RMSE)、决定系数(R2)和线性回归指标(Amaro et al., 1998),其中线性回归指标包括3个方面:截距α、斜率β和调整后的确定系数Radj2。各统计指标的计算公式见表 2。鉴于各统计指标不同的统计意义和可靠性,本文在比较模型拟合质量时,着重考虑AMR、RMSE和R2这3个统计指标,其余指标作为辅助参考。
|
|

由于建模数据拟合出的模型不一定能很好地预测未参与建模立地上的优势木树高,因此需要使用与建模数据相对独立的数据对模型进行验证。首先将原始数据随机地分为2部分,分别用于模型拟合和模型验证。本文共有79个样地的原始数据,随机抽出50个样地的数据用于模型拟合,余下29个样地的数据用于模型验证。使用拟合好的地位指数模型预测29个样地的优势木树高时,需要给定一个指数年龄及相应观测树高。为确保验证的可靠性,分别选用60, 80, 100, 120, 140年作为指数年龄。由优势木高预测值和观测值计算各项统计指标,然后取各指数年龄统计指标的平均值作为评估指标。
最后,考虑到具有相似优良统计特征的模型可能表现出完全不同的曲线形式(Huang, 1999),可利用图形分析的方法对模型的表现做进一步评估,这对于模型的选择有着重要的辅助参考作用(Barrio, 2005)。具体方法是将拟合曲线叠加到样木树高生长过程曲线图上进行比较分析。在模型筛选过程中,要综合考虑统计指标和图形的表现进行判断。本文依据统计指标和图形分析选择模型的基本原则为: 1)统计指标及图形分析均表现不佳时,放弃该模型;2)统计指标相类似时,选择图形分析效果好的模型;3)图形分析效果相似时,选择统计指标效果好的模型。
1.6 模型应用筛选出最佳模型后,实践中任意一组树高、年龄数据应用该模型估计地位指数时,需要给定一个指数年龄,而地位指数和指数年龄也可以被应用于估计任意期望年龄时的优势木树高。因此,挑选一个可信的指数年龄在实践应用中非常重要。为确保指数年龄在预测其他年龄、树高时的可靠性,首先在最佳模型的基础上,选取不同的指数年龄(10,20…200)及相应树高观测值估计其他年龄时的树高,由预测树高值和观测树高值计算预测的相对误差(RE%)(Barrio, 2005)。计算公式如下:
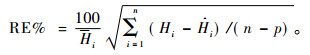
|
然后,由相对误差随不同指数年龄的变化趋势分析选取可信的指数年龄。需要注意的是,计算相对误差时采用的是模型验证的数据。
另外,由于最佳模型不一定适用于估计任意年龄区间林分的立地质量,因此本文基于最佳模型和原始数据中的每一组树高、年龄数据,估计了可信指数年龄时的地位指数,并绘制了变化趋势的图像,以便于分析随时间推移模型对地位指数预测的稳定性和一致性,最终找出可以做出可信预测的林分年龄区间。
2 结果与分析 2.1 统计分析备选模型的参数估计值和相关的统计指标见表 3。模型拟合时的MR均小于0.06,AMR均小于0.8,RMSE均小于1.1, R2均大于0.98,线性回归指标中α浮动稍大,在-0.4~0.18之间,斜率β表现良好,均在0.999左右,Radj2也均大于0.98。总体上,模型都表现出了良好的统计特征。验证数据获得的各项统计指标要稍逊于拟合数据,但各项统计指标在数值浮动上表现出了与拟合统计指标的一致性,这证明了拟合模型能够很好地预测未参与建模林分的立地质量。
|
|
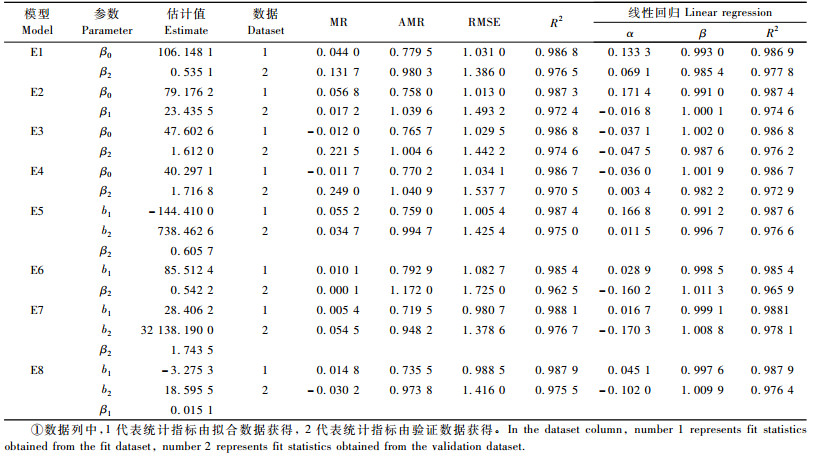
综合考虑各项统计指标,所有备选模型中,由GADA法推导出的模型E7, E8, E5表现出了最佳的统计特征,其中模型E7,E8最好,E5稍逊;而由ADA法推导的模型E1,E2,E3,E4表现要稍逊于上述3个模型。通过GADA法推导出的模型E6,尽管表现出了较好的MR指标,但总体上仍表现出了最差的统计特征(AMR, RMSE,R2指标表现最差)。模型E6表现较差的原因可能是其所依赖的生物学假设并不符合模型生长的内在机制。由于GADA法中需要引入新参数并假设新参数与SDP参数有简单的函数关系,而这样的函数关系可能与基本模型的机制相矛盾,从而使模型表现出较差的拟合效果。但总体来说,GADA法推导出的模型在统计指标上的表现要优于ADA法推导的模型,这在一定程度上表明了广义差分型地位指数模型具有更高的预测性能,也说明了GADA法假设基本模型中有多个与立地相关参数(SDP)的合理性。
2.2 图形分析图 2显示了由拟合的所有模型绘制的地位指数曲线。所有模型的曲线都是指数年龄为100年、地位指数分别为11, 19,27,35 m时的地位指数曲线。曲线覆盖了由原始数据绘制的树高、年龄曲线,涵盖了数据变化的整个范围,这一步骤对于模型评估有着重要的作用。

|
图 2 备选模型在指数年龄为100年时的地位指数曲线 Fig.2 Site index curves at reference age of 100 years for all the models tested |
图形分析的主要作用在于揭示统计指标所不能反映出来的模型缺陷以及模型比较时模型间的区别。由图 2可见,模型E3和E4显然由于趋向于水平渐进极值过快(曲线走平)而未能很好地模拟高质量地位指数立地上林木的生长过程(最上面的粗线),因此模型E3和E4首先被淘汰。需要注意的是,模型E3,E4和模型E1具有着相似的统计特征,但在曲线形式上却有着很大的差异。模型E6和E2也被淘汰,因为这2个模型对低质量地位指数(最下面的粗线)的拟合效果不好,曲线形式过于平直(尤其是E6),没有很好地遵循观察值随时间变化的轨迹。
余下的模型E1,E5,E7和E8仅从图形上看,除200年时模型E1,E5的曲线增长率略高于E7,E8外,基本无其他显著区别。综合考虑统计分析的结果,模型E7,E8与模型E1,E5相比,表现出了更优良且相似的统计指标,因此选择模型E7, E8做进一步的比较分析。
将E7, E8的曲线叠加在同一图内进行细致的比较分析(图 3),模型E7,E8主要在描述高质量和低质量地位指数的曲线上存在差异。由于缺乏最好立地质量上老龄树木的数据,因此不便于依据高质量地位指数曲线的差异做出判断。比较二者低质量地位指数的曲线,模型E8并没有很好地遵循观察值随时间的变化轨迹,略微低估了优势木在老龄时的树高,因此被淘汰。

|
图 3 模型E7和E8地位指数曲线的比较 Fig.3 Comparison between site index curves generated by E7 and E8 |
综上所述,通过GADA法推导的模型E7, 在统计学和生物学方面均表现出了令人满意的效果。基于这点,本文建议采用模型E7应用于加拿大哥伦比亚省美国黄松林分的树高生长预测和立地质量分类。
2.3 应用分析在实践中应用模型E7时,需要选择一个指数年龄来估计地位指数和预测优势木树高。指数年龄的确定,一般要综合考虑树高生长是否趋于稳定、采伐年龄、自然成熟龄等因素。对于哥伦比亚省的美国黄松天然林,已采用的地位指数年龄为胸高年龄50年(Nigh, 2004)。本文采用不同的指数年龄来预测优势木树高,并计算相应的预测相对误差。相对误差随指数年龄变化的趋势如图 4所示,80~160的年龄区间具有较低的相对误差。另外,选取指数年龄时不仅要考虑相对误差,而且需要考虑相应观测值的数目,因为指数年龄应当具有一定的代表性。基于这2点,图 4中阴影部分应当为选取指数年龄的最佳年龄区间。因此选择100年为指数年龄,此时由地位指数换算其他年龄时树高的相对误差最小(约为10%),而原来采用的50年胸高年龄所导致的估算误差稍大(约为15%)。显然,100年时的树高生长趋于稳定,也不会超出天然美国黄松的采伐年龄,选取100年作为指数年龄预测其他年龄时的优势木树高将会有最佳的预测效果和较高的可靠性。

|
图 4 模型E7对地位指数预测的相对误差及总观测值数目随年龄的变化 Fig.4 Relative error in site index prediction for model E7 and numbers of observation against age |
图 5显示了用模型E7估计地位指数(指数年龄100年)时,由不同林分获得的地位指数随年龄变化的趋势。由图 5可见对幼龄林分地位指数估计的不稳定性。由于树木早期高生长的不稳定性,而且树木早期的高生长往往受立地质量以外的因素影响较大,所以模型对于幼龄林分地位指数的估计有着高度的不稳定性。在林分年龄大于30年时,模型对于地位指数的估计开始趋向于稳定。同时,考虑到本次调查的优势木中,只有少数样木年龄达到了200年,因此确定30~200年是对地位指数可以做出可信估计的林分年龄区间。在林龄超过200年时使用该模型须谨慎考虑,在林龄低于30年时不应使用该模型,因为估计的不稳定性可能会造成对年幼林分立地质量分类的错误判读。

|
图 5 模型E7对地位指数的估计随年龄变化的趋势 Fig.5 Consistency of site index estimates over age for model E7 |
模型E7在具体应用时,将使用以下数学表达式:
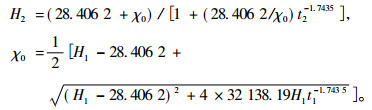
|
(1) |
式中:H2代表t2时树高的预测值;H1和t1为已知的树高年龄值。要预测某个年龄为t时的优势木树高,需要给定地位指数S和相应的指数年龄(本文中是100年),将方程(1)中H1替换为S,t1替换为100,容易得到:
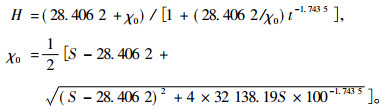
|
同样,如果要估计指数年龄为100年时的地位指数,给出优势木的树高和年龄观察值H1, t1即可,将方程(1)中H2替换为S,t2替换为100,容易得到:
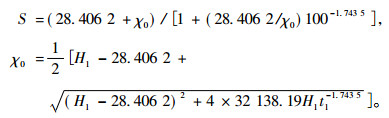
|
基于理论生长模型,本文采用ADA法和GADA法推导了8个差分型地位指数模型。模型拟合时采用分类变量回归的参数估计方法,模型比较时均衡考虑了统计学和生物学的特征,通过统计分析和图形分析筛选出了最佳的模型,并对模型的应用进行了深入分析,得到以下3点结论:1)广义差分型地位指数模型具有更高的预测性能,说明GADA法更适合作为地位指数模型的推导方法;2)基于Hossfeld Ⅳ模型,通过GADA法推导的模型E7确定为最佳模型,推荐采用该模型对加拿大哥伦比亚省30~200年的美国黄松林分进行树高生长预测和立地质量分类;3)依据该模型预测的相对误差,确定100年为最佳指数年龄。
| [] | 陈绍玲. 2008. 马尾松人工林多形地位指数曲线模型的建模方法. 中南林业科技大学学报, 28(2): 125–128. |
| [] | 陈信旺, 庄晨辉, 江希钿. 2005. 福建柏人工林地位指数曲线模型的研究. 华东森林经理, 19(1): 7–10. |
| [] | 段爱国, 张建国. 2004. 杉木人工林优势高生长模拟及多形地位指数方程. 林业科学, 40(16): 13–19. |
| [] | 倪成才, 于福平, 张玉学, 等. 2010. 差分生长模型应用分析与研究进展. 北京林业大学学报, 32(4): 314–322. |
| [] | 吴承祯, 洪伟, 林成来. 2002. 马尾松人工林Sloboda多形地位指数模型的研究. 生物数学学报, 17(4): 489–493. |
| [] | 郑曼, 陈永富. 2008. 桉树短周期工业原料林立地指数模型研究. 林业科学研究, 21(3): 415–418. |
| [] | Adame P, Cañellas I, Roig S, et al. 2006. Modelling dominant height growth and site index curves for rebollo oak (Quercus pyrenaica Willd.). Ann For Sci, 63(8): 929–940. DOI:10.1051/forest:2006076 |
| [] | Amaro A, Reed D, Tomé M, et al. 1998. Modeling dominant height growth: Eucalyptus plantations in Portugal. Forest Science, 44(1): 37–46. |
| [] | Bailey R L, Clutter J L. 1974. Base-age invariant polymorphic site curves. Forest Science, 20(2): 155–159. |
| [] | Barrio Anta M. 2005. Site quality of pedunculate oak(Quercus robur L.)stands in Galicia(northwest Spain). Eur J of Forest Research, 124(1): 19–28. DOI:10.1007/s10342-004-0045-3 |
| [] | Cañellas I, Montero G, Gea-Izquierdo G. 2008. Site index in agroforestry systems: age-dependent and age-independent dynamic diameter growth models for Quercus ilex in lberian open oak woodlands. Canadian Journal of Forest Research, 38(1): 101–113. DOI:10.1139/X07-142 |
| [] | Cieszewski C J, Bella I E. 1989. Polymorphic height and site index curves for lodgepole pine in Alberta. Canadian Journal of Forest Research, 19(7): 1151–1160. |
| [] | Cieszewski C J, Bailey R L. 2000a. Generalized algebraic difference approach: theory based derivation of dynamic site equations with polymorphism and variable asymptotes. Forest Science, 46(1): 116–126. |
| [] | Cieszewski C J, Harrison M, Martin S T. 2000b. Examples of practical methods for unbiased parameter estimation in self-referencing functions//Cieszewski C J. Proceedings of the First International Conference on Measurements and Quantitative Methods and Management. Jekyll Island, Georgia, November 17-18. |
| [] | Clutter J L. 1963. Compatible growth and yield models for loblolly pine. Forest Science, 9(3): 354–371. |
| [] | Huang S. 1999. Development of compatible height and site index models for young and mature stands within an ecosystem-based management framework//Amaro A, Tome M. Empirical and process-based models for forest tree and stand growth simulation. Educes Salamandra Novas Technologies, Lisboa, 61-98. |
| [] | Lundqvist B. 1957. On the height growth in cultivated stands of pine and spruce in northern Sweden. Medd Fran Statens Sko-gforsk Band, 47(2): 1–64. |
| [] | Ni C, Zhang L. 2007. An analysis and comparison of estimation methods for self-referencing equations. Canadian Journal of Forest Research, 37(8): 1472–1484. DOI:10.1139/X06-285 |
| [] | Nigh G. 2004. A comparison of fitting techniques for ponderosa pine height-age models in British Columbia. Ann For Sci, 61(7): 609–615. DOI:10.1051/forest:2004064 |
| [] | Richards F J. 1959. A flexible growth function for empirical use. J Exp Bot, 10(2): 290–301. DOI:10.1093/jxb/10.2.290 |
| [] | Wang Y, Huang S, Yang R C, et al. 2004. Error-in-variable method to estimate parameters for reciprocal base-age invariant site index models. Canadian Journal of Forest Research, 34(9): 1929–1937. DOI:10.1139/x04-070 |