 2007, Vol. 43
2007, Vol. 43文章信息
- 甘敬, 朱建刚, 张国祯, 余新晓.
- Gan Jing, Zhu Jiangang, Zhang Guozhen, Yu Xinxiao.
- 基于BP神经网络确立森林健康快速评价指标
- Establishing Indices for Rapid Assessment of Forest Health Based on BP Neural Networks
- 林业科学, 2007, 43(12): 1-7.
- Scientia Silvae Sinicae, 2007, 43(12): 1-7.
-
文章历史
- 收稿日期:2007-10-22
-
作者相关文章



2. 北京市园林绿化局 北京 100029
2. Beijing Municipal Bureau of Parks and Afforestation Beijing 100029
"森林健康"是西方国家针对人工林林分结构单一、病虫害抵抗力差、水土保持功能薄弱等问题提出的理念(Kolb et al., 1994; 朱建华等, 2003; 王彦辉等, 2007)。自该理念提出后, 在理论和实践方面均取得了长足发展。森林健康评价作为森林健康研究的重要环节, 是森林健康经营管理的基础。目前国内外已有不少森林健康评价的研究成果(O'Laughlin, 1996; Ferretti, 1997; 肖风劲等, 2003; 陈高等, 2004), 由于评价指标过于繁多, 评价技术复杂, 多由研究人员完成, 一般林业工作人员难以掌握, 这些成果并不适用于森林经营管理实践。因此, 急需一套能够在现地得到健康等级的森林健康快速评价(rapid assessment of forest health, 简称RAFH)指标。
人工神经网络(artificial neural networks, 简称ANNs)是20世纪40-50年代产生、80年代发展起来的模拟人脑生物过程的人工智能技术。它是由大量的、简单的神经元广泛互连形成的复杂的非线性系统(胡守仁, 1993)。它不需要任何先验公式, 就能从已有数据中自动地归纳规则, 获得这些数据的内在规律, 具有自学习性、自组织性、自适应性和很强的非线性映射能力, 特别适合于因果关系复杂的非确定性推理、判断、识别和分类等问题(闵惜琳等, 2001)。BP网络是一种多层前向型神经网络, 其权值的调整采用反向传播(back propagation)学习算法, 体现了神经网络理论中最为精华的部分(Anderson, 1995; 飞思科技产品研发中心, 2005)。因此, 在拟定RAFH指标后, 通过对训练样本的模式识别来构建一个BP神经网络, 观察其能否收敛, 并以测试样本为新的输入项进行模拟, 将模拟值与森林健康精准评价(precision assessment of forest health, 简称PAFH)结果(期望值)进行误差分析比较, 是一条从客观上检验拟定指标是否合理、可行的最佳途径。本文拟定了RAFH指标, 并基于BP神经网络检验了指标的合理性, 旨在为森林可持续经营实践提供理论依据。
1 试验地概况试验地设在北京市中美合作"八达岭森林健康试验示范项目"区——北京延庆县东南部的八达岭林场(115°57'-116°03'E, 40°18'-40°22'N), 总面积2 940 hm2, 海拔400~1 250 m。年均气温10.8℃, 年降水量454 mm。土壤以典型褐土、碳酸盐褐土及淋溶褐土为主。该林场从20世纪50年代起实施封山育林与人工造林, 目前已形成较好的恢复生态系统, 森林覆盖率达60.7%。项目区林分类型主要有黑桦(Betula davurica)、色木(Acer mono)、核桃楸(Juglans mandshurica)、暴马丁香(Syringa reticulata)等天然次生林以及油松(Pinus tabulaeformis)、华北落叶松(Larix principis-rupprechtii)、侧柏(Platycladus orientalis)、刺槐(Robinnia pseudoscacia)、小叶杨(Populus simonii)等人工林。山地阳坡有大面积的山杏(Prunus armeniaca)、山桃(Amygdalus davidiana)、黄栌(Cotinus coggygria)、胡枝子(Lespedeza bicolor)等灌丛。
2 研究方法 2.1 指标拟定及试验设计森林健康快速评价(RAFH)突出的特点是指标简易可测、方法易于掌握、结果获取迅速, 其首要问题是评价指标的确立。RAFH的指标确立需要应对以下几个问题:
1) RAFH指标无法从森林健康精准评价(PAFH)指标体系中筛选得到由于RAFH和PAFH是2套不同的研究模式, 因此RAFH的指标确立有别于PAFH, 如果从PAFH指标体系中筛选RAFH指标, 将会由于指标信息缺失(如生产力指标虽然重要, 但因不符合快速评价的简易性原则而被剔除)而造成可信度大大降低。
2) RAFH指标无法从"RAFH指标体系"中筛选得到由于RAFH简易原则的限制, 其指标选取具有很大的主观性, 由此造成RAFH指标之间的统计规律破坏, 所建立的RAFH指标框架不能称之为"体系", 通过统计方法进行的指标筛选将失去意义。
3) 主观拟定的RAFH指标需要进行客观检验运用主观拟定的RAFH指标进行评价, 所得的结果能否与PAFH评价结果基本一致(RAFH结果肯定会与PAFH产生误差, 但RAFH要求误差在较小的范围内即为合理), 需要进行客观验证。
基于此, 本研究采用专家会议调查法于2007年7月进行了RAFH指标调查。根据对来自北京林业大学、中国林业科学研究院、北京市园林绿化局、中国科学院植物研究所、八达岭林场、西山林场等单位近30位专家的咨询结果, 最终拟定林分层次结构、土壤厚度和病虫害程度作为森林健康快速评价(RAFH)的3个指标。依据层次分析法(analytic hierarchy process, 简称AHP)(Satty, 1990)的建模原理, 建立RAFH递阶层次结构模型(图 1)。

|
图 1 森林健康快速评价递阶层次结构模型 Fig. 1 Hierarchy model of rapid assessment of forest health |
林分层次结构完备、合理是森林生态系统完整性的重要体现。赵惠勋等(2000)将林分层次结构分为5层:主林层、演替层、更新层、灌木层、活地被物层。笔者认为一个完整、健康的森林生态系统应该全部包括这5个层次, 单层或缺少其中几层都应视为林分不够健康。森林生态系统稳定性的一个重要特点是能够抵抗外界干扰, 具有抗干扰力、耐害力和自我恢复力, 而某一林分的病虫害程度能够指示这种能力, 无病虫害或病虫害程度较低反映出林分稳定性较好。土壤厚度能直接反映土壤的发育程度, 与土壤肥力密切相关, 是野外土壤肥力鉴别的重要指标(王绍强等, 2001)。土层较厚说明其能够提供给林分正向演替较为有利的环境, 林分持续健康发展的潜力较大。以上3个指标均简易可测, 可在现地迅速获得。
以拟定的RAFH 3个指标值为网络输入项, 以PAFH的健康等级值为目标输出项, 基于BP神经网络进行指标合理性检验。如果网络能够收敛, 并有很好的模拟输出, 说明指标合理、可行, 否之则反。
2.2 外业调查及数据分析方法"八达岭森林健康试验示范项目"实施中, 将八达岭林场范围划分为121个小班, 在各小班内根据地形以半径5.64或7.98 m布设圆形样地, 面积为100或200 m2。2004年6-9月、2005年7-8月以及2006年7月分3次调查了地形因子、立地类型、植物因子、土壤因子、动物因子、经营情况及森林更新情况等内容。林分层次结构调查采用赵惠勋等(2000)提出的5层划分法, 分别记录主林层、演替层、更新层、灌木层及活地被物层的完备情况(具备某层则该层记为1, 否则为0), 然后将某小班样地所具有的层次数量累加, 定为该小班林分层次结构分值; 病虫害程度调查依据受害株枝枯率大小(黄少彬等, 2000; 刘有莲等, 2003), 分无受害、轻度受害、中度受害和重度受害4级, 对样地内每株病虫害状况进行记录; 土壤厚度调查在样地内挖剖面记录A+B层厚度, 当有BC过渡层时, 记录A +B+BC/2的厚度。
林分层次结构、土壤厚度直接采用外业调查结果, 为了准确验证拟定指标的合理性(本文重在研究指标本身, 而非评价过程), 病虫害程度通过调查数据计算隶属等级相对位置间接得到, 其过程为:首先根据每木病虫害等级按数量比例统计得到某样地的病虫害隶属度向量B=(b1, b2, b3, …, bi), bi为隶属于各等级的株数数量比例, 本文视为隶属于各等级的隶属度(i=1, 2, 3, 4);然后依据胡守忠等(1995)、熊德国等(2003)提出的模糊综合评价隶属度加权平均原则推求该样地病虫害程度隶属等级的相对位置Y:
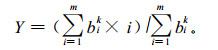
|
(1) |
式中:i为各等级的秩; m为等级数; k为待定系数(取1或2), 目的是控制较大的bi所起的作用。
对于目标输出项的精准评价结果, 采用谷建才(2006)通过健康距离法计算得到的121个森林经营小班的健康距离值。经与实际情况对比, 本文认为此评价结果可信度较高, 可作为理论真值。
将121组数据分为训练样本和测试样本, 将前101组数据作为训练样本来构建网络, 以后面20组数据作为测试样本来检验目标输出与模拟输出的误差。
2.3 神经网络模型构建关键步骤1) 建立网络 采用newff函数来确定网络层数、每层中的神经元数和传递函数, 其语法为net=newff (PR, [S1, S2, …, Si], {TF1, TF2, …, TFi}, BTF, BLF, PF), 其中PR是一个由每个输入向量的最大最小值构成的R×2矩阵; Si是第i层网络的神经元个数; TFi是第i层网络的传递函数, 缺省为tansig, 可使用的传递函数有tansig、logsig或purelin; BTF是训练函数, 可在如下函数中选择:trainlm、trainbfg、trainrp、traingd等; BLF是学习函数, PF性能函数, 取默认值即可。newff在确定网络结构后会自动调用init函数用缺省参数来初始化网络中各个权重和偏置量, 产生一个可训练的前馈网络, 即该函数的返回值net。
2) 训练网络 网络建立起来后, 需要选择合适的训练函数对其训练。标准的BP网络是根据Widrow-Hoff规则, 采用梯度下降算法, 在非线性多层网络中, 反向传播计算梯度。但标准BP网络自身存在限制与不足, 如需要较长的训练时间、会收敛于局部极小值等, 其算法需要改进。苏高利等(2003)就BP网络改进算法的训练速度和内存消耗情况作了比较, 结果表明, Levenberg-Marquardt算法具有相对最好的收敛速度。Levenberg-Marquardt优化方法的训练函数为trainlm, 其训练参数有:训练次数epochs、训练步长show、误差函数指标goal、训练时间time、最小梯度min-grad、减少内存系数mem-reduc以及μ的初始值、增加系数、减小系数和最大值。网络训练的语法为[net, tr, Y, E, Pf, Af]=train(net, P, T, Pi, Ai, VV, TV), 其中等式右半部分为输入, net为建立的网络; P为网络输入项; T为目标输出项; Pi为初始输入延迟, 默认为0;Ai为初始层次延迟, 默认为0;VV为网络结构确定向量, 默认为空; TV为网络结构测试向量, 默认为空。等式左半部分为返回值, net为训练后的网络; tr为训练记录; Y为输出信号; E为网络误差; Pf为最终输入延迟; Af为最终层延迟。
3) 模拟输出 网络训练好以后, 还需要用测试样本对其测试, 以检查网络的泛化能力和仿真能力, 其语法为[Y, Pf, Af, E, perf]=sim(net, P, Pi, Ai, T), 其中等式右半部分为输入项, 各项定义如前所述。等式左半部分为返回值, Y为模拟输出, perf为网络性能。
2.4 模拟结果精度检验方法分别采用误差百分比法、线性回归检验法和Nash-Sutcliffe效率法(牛志明等, 2001)检验模拟值与期望值的吻合程度。
1) 误差百分比法 采用计算式
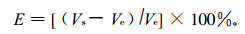
|
(2) |
式中:E为网络模拟误差百分比, Ve为期望值, Vs为模拟值。若E为正值, 说明网络模拟值偏大; 若E为负值, 说明网络模拟值偏小; 若E为0, 则说明网络模拟值与期望值正好吻合。
2) 线性回归检验法 将期望值作为被解释变量, 将模拟值作为解释变量, 建立一元线性回归方程:Y=aX+b, 对回归方程进行统计检验, 包括回归方程的拟合优度检验、回归方程的显著性检验、回归系数的显著性检验。如果模拟值与期望值线性关系显著、回归方程合理, 则观察斜率a和截距b:a越接近1, b值越接近0, 表示模拟值与期望值之间吻合度越高。
3) Nash-Sutcliffe效率法 采用计算式
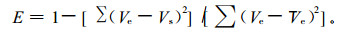
|
(3) |
式中:E为网络模拟效率, Ve为期望均值。网络模拟效率与线性回归方程拟合优度检验的统计量R2, 即判定系数较为相似, 只是残差值的求算方式不同。E值越接近1, 网络模拟效率越高, 模拟值与期望值的吻合度越高。
3 结果与分析 3.1 BP神经网络收敛效果BP网络建立及训练程序如下:
P=xlsread('TrP.xls'); %读取训练样本输入项
T=xlsread('TrT.xls'); %读取训练样本目标输出项
P=P.'; %转置
T=T.'; %转置
[PN, minp, maxp, TN, mint, maxt]=premnmx(P, T); %归一化处理
PR=minmax(PN); %求取最大最小数构造矩阵
net=newff(PR, [n 1], {'tansig''purelin'}, 'trainlm'); %BP网络建立
net.trainParam.show=50;%设置训练步长
net.trainParam.epochs=5 000;%设置最大训练次数
net.trainParam.goal=0.001;%设置目标误差
net.trainParam.lr=0.01;%设置学习速率
[net, tr, YN, E]=train(net, PN, TN)%训练网络
上述newff函数中隐含层神经元的个数n需要凭经验确定或在训练过程中不断试验得出, 目前尚没有统一的标准。因此本文对n取不同值进行了训练试验, 收敛效果见表 1。
|
|
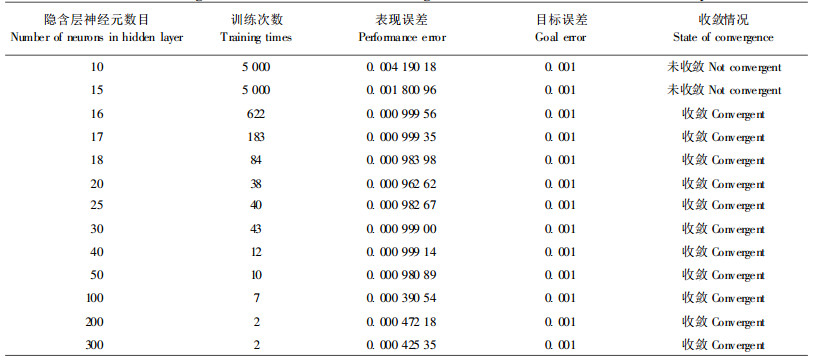
由表 1可知, 对于本研究而言, 在n ≥ 16时, 网络能较好地收敛, 说明该网络输入项的3个指标与目标输出项的非线性相关程度极高。表 1训练结果表明, 在其他条件不变时, BP网络隐含层神经元的数目越多, 训练误差越小, 训练时间越短, 这与张圣楠等(2005)的试验结论一致。但本研究发现, 随着隐含层数目增多, 内存消耗增大。
表 1中, 当n=100时, BP网络经过7次训练达到收敛, 训练误差较小(对应于某一神经元数目条件下的BP网络训练误差并不是固定不变的, 每次训练均会产生微小波动), 训练时间短。在n >100取值时, 训练误差变化不大而内存消耗增大, 因此, 本文确定隐含层神经元数目n为100。当n取16和100时, 对应的BP网络收敛曲线见图 2。

|
图 2 隐含层神经元数目分别为16、100时的网络收敛曲线 Fig. 2 Convergence curves of networks consisting of 16 and 100 neurons in hidden layer respectively |
为模拟仿真输出结果, 编写程序如下:
P1=xlsread('TeP.xls'); %读取测试样本输入项
P1=P1.'; %转置
[PN1]=tramnmx(P1, minp, maxp); %归一化处理
[YN1]=sim(net, PN1);%仿真模拟
[Y1]=postmnmx(YN1, mint, maxt); %将模拟值还原为原量纲
模拟输出结果见表 2。
|
|
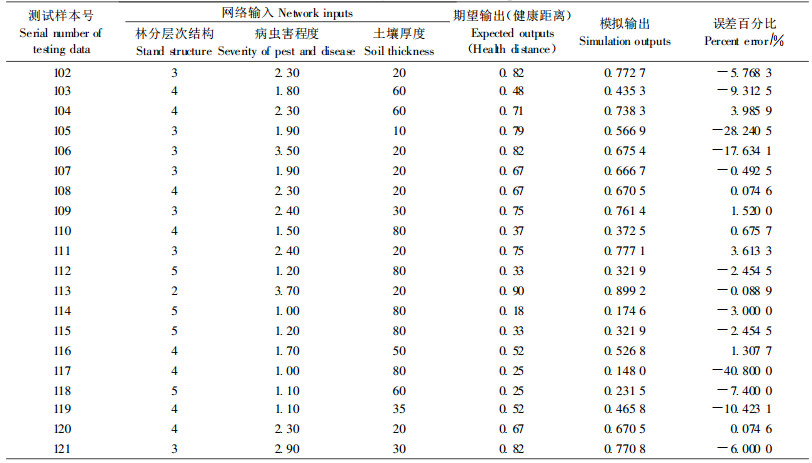
网络模拟值与期望值的误差百分比如表 2所示。除了105、106和117号测试样本的模拟值与期望输出有较大误差外, 其余测试样本的模拟值与期望输出均吻合较好, 能够满足RAFH的需要。
计算相对误差均值、Nash-Sutcliffe效率, 并对模拟值与期望值作线性回归检验, 结果如表 3所示。
|
|

由表 3可知, 拟合优度检验统计量R2, 即判定系数为0.926 8, 表明期望值被模型解释的部分较多, 不能被解释的部分较少。由于回归方程F检验统计量对应的概率P值及回归系数T检验统计量对应的概率P值均近似为0, 如果显著性水平α为0.05, P值小于其显著性水平, 因此认为期望值与模拟输出之间的线性关系显著, 回归方程合理。回归方程斜率为0.968 3, 接近于1, 且截距为0.049 0, 接近于0, 说明模拟值与期望值高度吻合。Nash-Sutcliffe效率为0.905 4, 同样表明模拟值与期望值之间吻合度较高。
4 结论与讨论运用主观拟定的森林健康快速评价(RAFH)指标进行评价, 所得的结果能否与精准评价(PAFH)评价结果基本一致, 需要进行验证。研究发现在隐含层神经元n ≥ 16时, 网络能较好地收敛, 说明该网络输入项——林分层次结构、病虫害程度和土壤厚度3个指标的训练样本值与目标输出项——森林健康精准评价(PAFH)结果的非线性相关程度高。以3个指标的测试样本值为新的网络输入项进行模拟, 采用误差百分比法、线性回归检验法和Nash-Sutcliffe效率法对模拟结果进行精度检验, 得到模拟值与期望值的相对误差均值为-6.140 9%, 回归方程斜率为0.968 3, 截距为0.049 0, Nash-Sutcliffe效率为0.905 4, 均表明二者之间吻合较好。因此, 林分层次结构、病虫害程度和土壤厚度可以作为森林健康快速评价(RAFH)的指标。
本文意在确立森林健康快速评价(RAFH)指标, 这是RAFH面临的首要问题, 而评价指标的标准、权重以及评价方法的确定不是本文的重点。基于BP神经网络的RAFH指标合理性检验过程有别于RAFH过程, 检验过程重在对评价指标本身的研究, 而非评价过程的研究。因此, 在样本数据获取时, 为了准确验证拟定指标的合理性, 本文对森林病虫害程度的数据处理采取了模糊综合评价中推求目标隶属等级相对位置的方法。在森林健康经营管理实践中, RAFH过程应避免这种繁琐的数学计算, 突出简易性, 因此可采用受害立木株数比例来确定病虫害程度, 而林分层次结构和土壤厚度采用本文方法即可。
本文确立的森林健康快速评价(RAFH)指标属于"无限制可比型"(即可认为任何林分类型之间具有可比性), 而非"限制可比型"(如生物量、叶面积指数等指标只能够在同种林分类型内部进行比较, 而不能在不同林分类型之间作比较), 因此具有较为广泛的适用性。另外本文确立的RAFH指标只能用于森林经营小班尺度的评价, 在尺度扩大时, 如景观层次的森林健康快速评价, 需要根据实际情况进行调整或替换。
陈高, 代力民, 姬兰柱, 等. 2004. 森林生态系统健康评估Ⅰ:模式、计算方法和指标体系. 应用生态学报, 15(10): 1743-1749. DOI:10.3321/j.issn:1001-9332.2004.10.008 |
飞思科技产品研发中心. 2005. 神经网络理论与MATLAB7实现. 北京: 电子工业出版社.
|
谷建才.2006.华北土石山区典型区域主要类型森林健康分析与评价.北京林业大学博士学位论文
|
胡守仁. 1993. 神经网络导论. 长沙: 国防科技大学出版社.
|
胡守忠, 顾建勤. 1995. 模糊综合评价法及应用. 中国纺织大学学报, 21(1): 74-80. |
黄少彬, 孙丹萍, 朱承美. 2000. 园林植物病虫害防治. 北京: 中国林业出版社.
|
刘有莲, 黄寿昌. 2003. 橘光绿天牛危害九里香绿化球调查及防治. 中国森林病虫, 22(2): 16-18. DOI:10.3969/j.issn.1671-0886.2003.02.008 |
闵惜琳, 刘国华. 2001. 用MATLAB神经网络工具箱开发BP网络应用. 计算机应用, 21(8): 163-164. |
牛志明, 解明曙, 孙阁, 等. 2001. ANSWER2000在小流域土壤侵蚀过程模拟中的应用研究. 水土保持学报, 15(3): 56-60. DOI:10.3321/j.issn:1009-2242.2001.03.016 |
苏高利, 邓芳萍. 2003. 论基于MATLAB语言的BP神经网络的改进算法. 科技通报, 19(2): 130-135. DOI:10.3969/j.issn.1001-7119.2003.02.012 |
王绍强, 朱松丽, 周成虎. 2001. 中国土壤土层厚度的空间变异性特征. 地理研究, 20(2): 161-169. DOI:10.3321/j.issn:1000-0585.2001.02.005 |
王彦辉, 肖文发, 张星耀. 2007. 森林健康监测与评价的国内外现状和发展趋势. 林业科学, 43(7): 78-85. |
肖风劲, 欧阳华, 傅伯杰, 等. 2003. 森林生态系统健康评价指标及其在中国的应用. 地理学报, 58(6): 803-809. DOI:10.3321/j.issn:0375-5444.2003.06.001 |
熊德国, 鲜学福. 2003. 模糊综合评价方法的改进. 重庆大学学报, 26(6): 93-95. |
张圣楠, 郭文义, 肖力墉. 2005. 基于MATLAB的BP网络的设计与训练. 内蒙古科技与经济, 17: 95-98. |
赵惠勋, 周晓峰, 王义弘, 等. 2000. 森林质量评价标准与评价指标. 东北林业大学学报, 28(5): 58-61. DOI:10.3969/j.issn.1000-5382.2000.05.014 |
朱建华, 张再福, 吴建勤. 2003. 桉树白蚁综合防治技术. 中国森林病虫, 22(1): 10-12. DOI:10.3969/j.issn.1671-0886.2003.01.004 |
Anderson J A. 1995. An introduction to Neural Networks. London: MIT Press, 5-9.
|
Ferretti M. 1997. Forest health assessment and monitoring issues for consideration. Environmental Monitoring and Assessment, 48(1): 45-72. DOI:10.1023/A:1005748702893 |
O'Laughlin J. 1996. Forest ecosystem health assessment issues:definition, measurement, and management implications. Ecosystem Health, 2(1): 19-39. |
Satty T L. 1990. How to make a decision:the analytic hierarchy process. European Journal of Operational Research, 48(1): 9-26. DOI:10.1016/0377-2217(90)90057-I |
Kolb T E, Wagner M R, Covington W W. 1994. Concepts of forest health utilitarian and ecosystem perspectives. Journal of Forest, (6): 10-15. |