 2007, Vol. 43
2007, Vol. 43文章信息
- 陈尔学, 李增元, 谭炳香, 梁毓照, 张则路.
- Chen Erxue, Li Zengyuan, Tan Bingxiang, Liang Yuzhao, Zhang Zelu.
- 高光谱数据森林类型统计模式识别方法比较评价
- Validation of Statistic Based Forest Types Classification Methods Using Hyperspectral Data
- 林业科学, 2007, 43(1): 84-89.
- Scientia Silvae Sinicae, 2007, 43(1): 84-89.
-
文章历史
- 收稿日期:2005-05-25
-
作者相关文章


2. 吉林省汪清林业局 汪清 133200
2. Wangqing Forest Bureau of Jilin Province Wangqing 133200
由于光谱分辨率大幅度提高,高光谱数据比多光谱具有更强的潜在的地物识别能力,在林业遥感应用上表现为潜在的森林类型识别能力。但在有限训练样本条件下,遥感数据维数的增高使样本/维数比率大大降低,采用常规的统计模式识别方法反而无法得到较好的分类结果。为此,国际上对基于统计模式识别理论的高光谱数据分类问题进行了深入地研究,提出了一些旨在解决或减轻维数灾难问题的理论和方法(Landgrebe, 2000; Duda et al., 1973; Richards, 1986; Fukunaga et al., 1970; Foley et al., 1975; Kazakos, 1978; Swain et al., 1973; Devijiver et al., 1982; Lee et al., 1993; Hoffbeck et al., 1996; Friedman, 1989; Kettig et al., 1976),积累了非常宝贵的经验,并发展了功能强大的分类工具(Landgrebe, 1993; 2003)。这些理论方法和工具是通过十几年的研究逐步发展起来的,有着深厚的数理统计和信息论基础。理解、分析评价这些算法和工具对于发展新的分类算法有重要作用。遗憾的是,国内对这些技术的引进、消化和吸收都十分欠缺。在这种技术水平条件下,要想在高光谱数据处理和分类算法上实现创新是比较困难的。本文对国外先进、成熟的高光谱分类技术进行了较为详细、系统地分析总结,并采用在我国东北试验区获取的美国EO-1 Hyperion高光谱数据,对国外先进的高光谱统计模式识别技术进行了比较评价研究。
1 试验区及数据 1.1 试验区遥感数据获取情况试验区位于吉林省汪清林业局所辖林区内。在图版Ⅰ-1中,汪清林业局的范围由Landsat ETM+影像表示。所获取的EO-1 Hyperion高光谱数据成像时间为2001年7月14日,以蓝色长方形表示,呈一窄条状,其主要覆盖区域是浪溪林场。图中白色图形是浪溪林场的林相图,该区域是外业获取地面实况数据和分类方法评价的实际区域。为了外业获取地面实况数据的需要,特获取了2.5 m空间分辨率SPOT-5全色数据,其成像时间为2004年4月28日,在图中用红色长方形表示其覆盖区域。EO-1高光谱数据空间分辨率为30 m,总波段数为242。在和SPOT-5正射校正影像配准前,需要经过无效波段去除、绝对辐射值转换、坏行及条纹修复等预处理过程。

|
图版Ⅰ Plate Ⅰ 1.吉林省汪清林业局试验区遥感数据获取情况示意图。2.a:SPOT-5全色正射影像图,b:影像为a中一个小窗口(红色方框)的放大显示;影像上叠加的粉红色多边形为利用eCognition(R)软件的图像分割功能处理得到的多边形矢量图层,每个多边形是外业获取地面实状数据的最小单元;黄色多边形是林相图小班边界。3.外业调查区域在试验区的分布(a)及其中一个调查区域优势树种属性彩色显示(b)。4.基于LOOC和DBFE特征空间的ML与ECHO分类结果影像,a为ML结果,b为ECHO结果。 1.Remote sensing data acquired for the test site in the region of Wangqing Forest Bureau of Jilin Province.2.a:Orthrectified SPOT-5PAN image.b:Shows one window on a(red color box)in full resolution; One vector layer of polygons, which was produced with the segmentation function of eCognition(R) software, is overlaid onto the image.Each polygon is surveyed as the minimum ground true data collection unit; The polygons in yellow color are the boundary of the minimum forest management unit in China.3.Seven field work regions are shown on the SPOT-5 PAN image as pink color polygons in a and the field survey result of one of the seven region, the GISvector layer, is shown on b with different colors showing different forest types.4.Classification result images of ML and ECHO using LOOC and in DBFE transformed feature space.a is the result of ML and b is the result of ECHO. |
首先利用SPOT-5图像处理专用软件GEOimage®对SPOT-5全色影像进行正射校正处理, 控制点从1:5万地形图上寻找。数字高程模型(DEM)比例尺也是1:5万,从国家测绘局基础地理信息中心购买。DEM像元大小为25 m, 正射校正在东西向残差绝对值的平均值为40 m,而在南北向为30 m。正射校正后的SPOT-5影像覆盖范围如图版Ⅰ-1中红色长方形所示。覆盖浪溪林场的窗口影像如图版Ⅰ-2a所示, 该图一个子窗口(红线框)的全分辨率显示如图版Ⅰ-2b所示。由于影像分辨率为2.5 m,可以比较清楚地看到主要地物的空间分布特征。比如,道路和裸地为白色,特征很鲜明;在稀疏的林地上可以看到孤立大树的树冠,呈深灰色;树木稠密的区域呈深黑色,但由于受低光谱分辨率的限制,难于确定树种组成。对图版Ⅰ-2a影像利用eCognition®软件进行分割处理,得到多边形矢量图层如图版Ⅰ-2b所示,用粉红色多边形表示。每个多边形代表了一个在空间上具有一定的同质性的自然林分。以这种形式确定的林分更加接近森林空间分布的自然状态,其面积通常也要比小班小得多。图版Ⅰ-2b中黄色为林相图小班边界。显然林相图小班作为一个经营单位,其平均属性难于精确地代表林分的自然状态,因此本文以影像分割得到的多边形为单元进行地面实况数据的调查。
外业调查工作主要设备为装有GPS系统的手持电脑PDA系统。PDA装有森林资源调查专用软件,可以精确地导航定位,并直接将调查因子记录到数据库中。采用角规调查和人工测量相结合的方法,调查因子包括:土地覆盖类型、有林地的优势树种平均胸径和树高、林分内主要树种及其组成成数(10分法)、林分的郁闭度及优势树种的龄组。对所有面积大于400 m2的多边形都进行以上内容的调查。将调查结果更新到地理信息系统,最终结果以ARC/INFO Coverage矢量格式提供。由于正射校正误差在30~40 m左右,而GPS定位误差也在10~15 m左右,直接对面积较小的多边形进行定位是很困难的。因此在外业调查中,先对面积比较大的多边形的中心进行定位,根据打印图件的影像特征对多边形的覆盖范围做出估计并进行调查。对面积较小的多边形,以GPS导航位置为参考,结合影像纹理特征及多边形之间的位置关系确定调查点的具体位置和测树范围。
根据调查结果统计出该试验区出现的主要优势树种包括柞树(Quercus mongolicus)、白桦(Betula platyphylla)、臭松(Abies nephrolepis)、落叶松(Larix gmelinii)、樟子松(Pinus sylvestris)和杨树(Populus spp.)。调查到的森林类型包括:柞树林、白桦林、杨树林、臭松林、落叶松林、樟子松林、混交林、阔叶林、针叶林、杂木林。其中指明树种名称的类型,该树种的成数大于5成;针叶林是指针叶树种的成数大于阔叶树种的成数,但没有一个针叶树种的成数超过5成;阔叶林是指阔叶树种的成数大于针叶树种的成数,但没有一个阔叶树种的成数超过5成;混交林是指林分由针叶、阔叶树种组成,但没有树种的成数大于5成;杂木林是指以槭属(Acer)与榆属(Ulmus)以及水曲柳(Fraxinus mandshurica)、核桃楸(Juglans mandshurica)等阔叶树种为主的落叶森林植物群落。
外业共调查了7个区域,各区域在浪溪林场的分布如图版Ⅰ-3a所示。图版Ⅰ-3b给出了其中一个区域的矢量显示,多边形的填充色彩表示不同的优势树种类型。图版Ⅰ-3b给出的优势树种类型是在所有7个区域中出现的类型,在图版Ⅰ-3b所示的区域中有些树种并没有出现。该试验区内大面积分布的树种并不多,统计结果表明:所调查林分以阔叶林为最多,占外业调查林分总面积的52.86%;其次是混交林,占22.44%;再次是柞树林,占13.41%;白桦林占4.09%;落叶松林、臭松林和樟子松林的总和仅占3.23%。这基本代表了该试验区内林分类型的实际分布面积比例情况。
1.3 高光谱与SPOT-5全色影像的配准以1:5万地形图为参考寻找控制点建立多项式几何校正方程(F1),用于高光谱影像(A)的几何校正处理,这样校正后的高光谱影像(B)和正射校正过的全色影像(C)之间基本配准。为了达到A与C之间的精确配准,可以采用影像匹配的方法。从B中抽取和SPOT-5全色影像光谱范围最为接近的一个波段,记为影像D;对影像C进行12倍缩小处理,得到像元大小为30 m的SPOT-5影像(E)。在影像D与E之间采用基于标准化自相关系数的模板匹配方法,自动寻找若干匹配点,建立影像D与E之间的坐标转换方程,可以使D与E之间的配准精度在1个像元之内,由于E已经过正射校正,因此就可以得到影像D的几何校正方程(F2)。根据F1和F2就可以推导出影像A的几何校正方程(F3)。利用F3对高光谱影像A进行几何校正重采用处理,就可以得到可以和SPOT-5全色影像精确配准的高光谱几何校正结果影像(G)。由于外业调查的多边形是在正射校正的SPOT-5影像上生成的,因此外业测量的地面实况数据就可以配准到高光谱影像G上。
2 高光谱统计模式识别方法 2.1 高光谱统计模式识别中的高阶统计量估计从理论分析和实践应用可知,一种陆地表面覆盖类型的光谱特征通常难于用单一一条光谱曲线充分表达(Landgrebe, 2000)。农作物、森林、自然植被、土壤、矿物以及城镇目标等人们感兴趣的地物,在自然界中以不同的状态存在,其辐射能力以不同的光照状态被传感器捕获。这导致不应该用一个单一平均(或典型)光谱响应,而是用一系列的光谱响应表示地物的光谱特征。实际上,描述这一系列光谱响应的特性指标,比如,这些光谱响应如何以平均光谱为中心上下变动,和平均光谱响应一样都可以作为地物类型识别的指标。实际在理论上已经证实,一个确定的统计分布可以通过一系列的具有各种阶数的统计量来完整地描述。通常只利用前两阶统计量(平均值和协方差)的主要原因在于,利用有限的训练样本估计高阶统计量存在很大的困难。为训练分类器获取所必需的类别标识样本是非常费时、费力的;更为困难的是,由于地球表面覆盖具有很强的变化性和动态性,类别标识过程需要针对不同的数据分别进行,而不能将基于A数据获得的分类器直接用于B数据的分类处理。由于高阶统计量需要非常庞大数量的类别标识样本点才能得到足够高的估计精度,因此利用高于两阶的统计量是不太现实的(Landgrebe, 2000)。随着光谱波段数的增加,已知类别标识样本点的数量是否充足问题变得更为突出。因此研究评价可以有效克服小样本统计模式识别问题的特征提取方法、二阶统计参数估计方法对于高光谱数据分类精度的提高有重要作用。
2.2 特征提取和特征选择方法尽管KL变换(又称主成分变换)从信号表达的角度来说是最优的,可以生成均方误差最小的主成分特征;但从类别可分性上来说,KL变换生成的特征不是最佳的,甚至被KL方法抛弃的那些分量有可能正是能够把不同的类别区分开来的分量(Duda et al., 1973)。Fisher线性判别分析采用的是典范分析方法(Richards, 1986)。若均值向量很小或没有差别,由典范分析得到的特征向量是不可信的;而且若一个类的均值向量和其他类的均值向量差异很大,就会导致无效的特征提取。Fukunage等(1970)认识到最佳的代表特征不一定是最佳的识别特征,进而提出了Fukunage-Koontz方法。该方法适用于类别间协方差差别大而无或有较小均值差异的情况,若存在较大的均值差异,将导致不正确的结果(Foley et al., 1975)。Kazakos(1978)提出的线性标量特征提取方法,只能提取一个特征,无法一般化为提取多个特征。Heydorn(1971)提出的删除冗余特征的方法,只能在原始特征空间进行,虽然先对数据进行线性变化,然后再应用该方法也可以达到特征提取的目的。基于统计距离的特征选择方法也已有深入的研究和广泛的应用(Swain et al., 1973; Devijver et al., 1982),其存在的主要问题是:1)随着维数的增加,需要搜索的特征组合会指数上升,很快导致令人无法接受的处理时间,虽然也有一些寻求亚优特征组合的算法可以从一定程度上降低处理时间; 2)特征选择只是在原始特征上进行,而最佳特征向量可能不在原始特征空间,这种情况下该方法是无效的。总之,以上特征提取和选择方法,无法预测内在的可分辨维,即无法决定可以达到在原始特征空间同样的分类精度的最小的变换空间的特征数,难于回答“应该选择多少个特征就可以满足分类需要了?”的问题。Lee等(1993)提出的决策面特征提取(DBFE)方法可以很好地解决这些问题,而且当平均值和协作方差阵很小时也可以得到正确的结果。本文将对DBFE特征提取方法的有效性进行评价。
2.3 小样本条件下二阶统计参数的有效估计方法当利用高斯最大似然法进行分类时,每个类别的平均向量和协方差矩阵是未知的,必须利用训练样本估计。对于p-维的数据,除非样本数大于p+1,否则协方差估计都是无效的。高光谱遥感应用,特征向量的维数很大,而训练样本数目总是非常有限。这种较低的样本/维数比率会降低协方差矩阵的估计精度,从而成为阻碍高斯最大似然法用于高维数据分类的重要因素。Hoffbeck等(1996)提出了一种协方差矩阵的优化估计方法,称为“去一协方差矩阵估计法”(leave one out covariance matrix estimation, LOOC)。试验证明:当训练样本数较少时,LOOC方法与直接利用样本协方差矩阵、公共协方差矩阵得到的分类精度相比有明显的提高;LOOC方法比类似的RDA(regularized discriminant analysis)方法(Friedman, 1989)可以得到较高的分类精度,并且处理时间有很大降低(Hoffbeck et al., 1996)。
2.4 分类方法多光谱数据分类典型的做法是将一个“简单对称性”的决策依据应用于每个分辨单元(像元),这意味着每个像元仅仅依据其光谱测量值进行分类。这种方法的基本假设是感兴趣目标与一个像元大小相比要大得多。否则,一个像元的大部分区域会有2个或更多的类别组成,使统计模式识别方法无法使用,比如说,事先确定的类别将不足以描述自然的真实状态。由于抽样间隔一般和像元大小是相当的(为保持系统分辨率),通常每个目标由若干个像元组成的阵列组成,这说明空间连续的客观目标间存在统计依赖性(Kettig et al., 1976)。基于“简单对成性”的分类方法称为“无记忆”分类法,而考虑空间连续目标统计依赖性的分类方法称为“记忆”分类法。在遥感影像分类中,常用的一些统计模式识别方法,如最大似然法(ML)、最小距离法(MED)和光谱角分类法(SAM)都属于“无记忆”分类法(Kettig et al., 1976)。
ECHO(extraction and classification of homogeneous object)是一种典型的基于图像分割的“记忆”分类法。ECHO先将统计上相似的像元归并在一起形成一个目标,然后再对目标进行分类。由于每个同质/平滑区域代表了一个统计“样本群”(若干个来自同一个群体的观察值),可利用“样本群”分类器进行分类。这样对目标的分类不仅利用了组成该目标的每个像元的光谱信息,而且还利用了像元周围其他邻近像元的上下文关系信息。这种将光谱信息和空间上下文信息综合应用的分类方法可以提高分类精度(Kettig et al., 1976)。关于ECHO的具体算法,童庆禧等(2006)有较为详细的介绍,由于篇幅所限,本文就不再赘述。本研究将对ECHO分类算法进行试验评价,并将其分类精度和其他常规方法进行对比。
2.5 高光谱森林类型统计模式识别方法评价方案通过以上分析,筛选得到了几种先进的高光谱统计模式识别方法。为了比较评价这几种方法的有效性,设计了3套具体的分类方案,具体方法如表 1。所有的分类方案在分类处理的最初阶段都采用相同的训练样本和精度检验样本,这些样本的获取参考外业测量得到的地面实状数据。以下评价结果中给出了由精度检验样本计算得到的各类别的分类精度和所有类别的总分类精度。
|
|
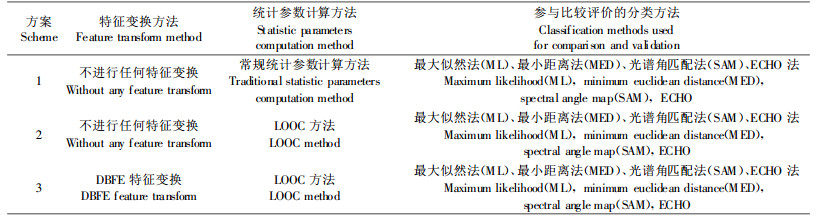
方案1得到的分类结果如表 2所示。该表没有列出ML方法和ECHO方法的分类结果,因为这2种方法根本就无法正常运行。ML方法和ECHO方法都采用了二阶统计量(协方差矩阵),但由于臭松、人工落叶松训练样本分别为76、61个,无法对协方差矩阵进行求逆运算,因此无法实现分类处理过程。这种分类结果证实了由训练样本有限引起的高光谱数据分类的典型问题:小样本使得基于二阶统计量的分类器无效,更谈不上精度问题。MED和SAM算法只基于一阶统计量(平均向量),因此可以实现分类,但分类精度都在50%以下。因此在对于本试验这种小样本-多类别-高维数据的分类问题,不采用有效的特征提取方法和更先进的统计参数计算方法是不可能得到满意的分类结果的。
|
|

方案2得到的分类结果见表 3。和方案1一样仍然是在原始数据空间对4种分类方法进行精度评价,只是所采用的统计方法有类改变,这里采用LOOC方法计算协方差矩阵,而不是采用常规的方法。显然LOOC解决了小样本情况下协方差矩阵无法求逆问题,ML和ECHO方法都可以实现正常的分类处理,而且ML和ECHO的分类精度都要比MED和SAM的高。这里MED和SAM的分类精度和方案1是相同的,因为LOOC只是改进了二阶统计量的计算方法,并没有改变平均向量的值,因此对只采用平均向量进行分类的MED和SAM方法的分类精度没有任何影响。表 3中,ML法的分类总精度达到了68.8%,ECHO达到了70.2%,这有力地证明了LOOC统计计算方法的有效性,同时证实了二阶统计量对提高分类精度的作用。
|
|

表 4是方案3各分类方法的分类精度。该方案首先利用DBFE特征提取方法将高光谱数据由原始特征空间转换到变换特征空间,从变换特征空间中提取前10个特征分量用于分类处理,并且所采用的统计参数计算方法是LOOC法。和方案2相比,由于采用了特征提取处理技术,ML总分类精度由68.8%提高到72.8%;而ECHO分类精度由70.2%提高到77.6%。SAM分类精度由49.6%提高到67.2%,但MED方法分类精度有所降低。总的来看,采用DBFE特征提取方法可以有效地提高基于二阶统计量的分类器的总分类精度。从表 3和表 4都可以看出,ECHO是4种方法中分类精度最高的分类方法。ECHO是一种综合考虑了空间-光谱信息的面向目标或对象的分类方法,和基于像元的分类方法相比,通常可以获得较高的分类精度。
|
|

从以上3个方案的分析可以看出,由于臭松、人工落叶松的分类样本数很低,而且一些树种实际上无法和其他类别区分开来,因此导致了一些类别的分类精度极低。采用如下类别归并方案对训练样本和精度检验样本进行类别合并处理:1)白桦归并到阔叶林;2)臭松、落叶松、人工落叶松归并到针叶林。经过类别归并后得到的待分类优势树种类别包括:柞树林、阔叶林、针叶林、针阔混交林4种,其他非森林类型仍然保持不变。这里只对ML和ECHO 2种方法进行分类精度比较评价,因为前面的分析已经证实基于一阶统计的MED和SAM方法分类不如基于二阶统计的方法效果好。类别的合并使得样本/维数比率提高,可以从一定程度上减轻小样本-高光谱数据分类的维数灾难问题,再加上采用有效的特征提取和二阶统计参数计算方法,分类精度必然会有一定的提高。从表 5也可以看出,ML的总分类精度达到了86.4%,而ECHO的总分类精度更高,达到了91.1%。表 5中,ML对4种森林类型的分类精度分别为66.5%、78.8%、64.4和68.1%,都在60%以上。而表 4中,ML对8种森林类型的识别精度只有2种在60%以上。同样对比表 5和表 4可以看出:ECHO不仅在总分类精度上有较大提高,而且对4种森林类型的分类精度都在73%以上。另外,从表 5中2种分类方法的对比来看,无论是总分类精度还是各类别精度,ECHO都要比ML高,这再次说明了ECHO方法的优越性。图版Ⅰ-4是对应表 5的2种处理方法的分类结果,2种分类方法的结果基本是一致的,只是ECHO分类结果的类别噪声相对要小得多,不需要再对分类结果进行类别滤波处理。
|
|

本文利用在我国东北地区获取的美国卫星EO-1 Hyperion高光谱数据, 基于详实的地面实状观测数据,对国外发展的几种先进的高光谱统计模式识别方法进行了比较评价研究。结果表明:1)基于二阶统计量的分类器一般要比仅基于一阶统计的分类器表现优越;2)通过特征提取降低高光谱数据的维数,可以减小样本/维数比率,是提高小样本-高光谱分类精度的不可缺少的处理步骤,试验中所采用的DBFE特征提取方法具有这种特性;3)在有限样本条件下,采用更有效的二阶统计量计算方法可以解决由于样本数少而导致的协方差矩阵计算病态问题,试验结果证实了LOOC方法可以有效地提高分类精度;4)综合利用空间-光谱信息的分类方法(ECHO)在试验中一致表现出较高的分类精度,这和从理论分析得到有关该算法优越性的结论是一致的;5)采用DBFE特征变换方法对高光谱数据进行特征提取,利用所提取特征的前6~10个分量特征,并利用LOOC算法进行二阶统计量的计算,然后采用ECHO方法进行分类处理,是本研究所建议的高光谱森林类型分类方案。
童庆禧, 张兵, 郑兰芬. 2006. 高光谱遥感——原理、技术与应用. 北京: 高等教育出版社, 217-218.
|
Devijver P, Kittler J.1982. Pattern recognition: a statistical approach. Prentice/Hall International
|
Duda R O, Hart P E. 1973. Pattern classification and scene analysis. John Wiley & Sons. |
Foley D H, Sammon J W. 1975. An optimal set of discriminant vectors. IEEE Trans Computer, C-24(3): 281-289. DOI:10.1109/T-C.1975.224208 |
Friedman J H. 1989. Regularized discriminant analysis. J Am Statistical Assoc, 84: 165-175. DOI:10.1080/01621459.1989.10478752 |
Fukunaga K, Koontz W L G. 1970. Application of the Karhunen-Loeve expansion to feature selection and ordering. IEEE Trans Computer, C-19(4): 311-318. DOI:10.1109/T-C.1970.222918 |
Heydorn R P. 1971. Redundancy in feature extraction. IEEE Trans Computer: 1051-1054. |
Hoffbeck J P, David A. 1996. Landgrebe, covariance matrix estimation and classification with limited training data. IEEE Transaction on Pattern Analysis and Machine Intelligence, 18(7): 763-767. DOI:10.1109/34.506799 |
Kazakos D. 1978. On the optimal linear feature. IEEE Trans Information Theory, IT-24(5): 651-652. |
Kettig R L, Landgrebe D A. 1976. Classification of multispectral image data by extraction and classification of homogeneous objects. IEEE Transactions on Geoscience Electronics, GE-14(1): 19-26. |
Lee C, Landgrebe D A.1993. Feature extraction based on decision boundaries.PhD dissertation in School of Electrical Engineering, Purdue University, West Lafayette, Indiana
|
Landgrebe D A. 1993. A perspective on the analysis of hyperspectral data, proceedings of the international geoscience and remote sensing symposium (IGRASS'93). Tokyo: 1362-1364. |
Landgrebe D A. 2003. Signal theory methods in multispectral remote. Sensing, Wiley: NJ.
|
Landgrebe D A. 2000. On the relationship between class definition precision and classification accuracy in hyperspectral analysis. Proceedings of IEEE. Geoscience and Remote Sensing Symposium, Honolulu, Hawaii
|
Richards J A. 1986. Remote sensing digital image analysis. Springer-Verlag. |
Swain P H, King R C. 1973. Two effective feature selection criteria for multispectral remote sensing. Proc First Int Joint Conf on Pattern Recognition: 536-540. |