 2009, Vol. 45
2009, Vol. 45文章信息
- 李春明.
- Li Chunming
- 混合效应模型在森林生长模型中的应用
- Application of Mixed Effects Models in Forest Growth Model
- 林业科学, 2009, 45(4): 131-138.
- Scientia Silvae Sinicae, 2009, 45(4): 131-138.
-
文章历史
- 收稿日期:2008-03-11
-
作者相关文章


森林生长和收获模型是描述林木或林分生长规律的一组方程式,模型预测的可靠性直接影响森林经营决策,因此在林业中如何提高模型的估计精度就显得尤为重要(李永慈, 2004)。随着森林计算工具和应用统计技术的发展和应用,用来改善并提高各项林分因子估计准确性的森林定量化模型在近些年不断增加,但是这些模型存在着一定的问题。首先,这些模型在进行模拟时通常都是假定误差是服从独立同分布的,然而现实的观测数据很难满足这种条件,势必会对估计结果有很大的影响。其次,过去大多数模型关心的是研究对象的确定性和平均行为,忽略了个体或群体之间存在的序列相关性及差异性。例如以往所建立全林整体模型很好地反映了林分总体的平均生长变化规律,但却忽略了林木个体之间及样地之间的差异;而单木生长模型很好地反映了个体的生长变化趋势而忽略了总体的平均变化趋势(Fox et al., 2001)。再次,以往大部分生长收获数据是通过设置固定样地,对固定样地内的不同观测对象在一定时间内或其他条件下进行多次观测或者对同一观测对象进行不同部位及不同角度的多次测量(例如同一株树木不同时间内胸径及不同高度直径的生长情况)而获得的,这些纵向及重复观测数据普遍存在着不一致性或不均衡性,势必会对生长及收获模型的准确性造成影响(Chi et al., 1989)。
混合效应模型由固定效应和随机效应2部分组成,既可以反映总体的平均变化趋势, 又可以提供数据方差、协方差等多种信息来反映个体之间的差异。另外在处理不规则及不平衡数据及在分析数据的相关性方面具有其他模型无法比拟的优势,在分析重复测量和纵向数据及满足假设条件时体现出灵活性。最近,特别是计算混合效应模型软件的快速发展已经表明混合效应模型将成为生长和收获模拟的重要工具。这一方法在最近20年内得到了快速的发展,在医学、农业、经济、林业及其他领域有了广泛的应用(Littell et al., 1996)。
目前在国内混合效应模型这一方法有了系统的研究,但是在林业应用较少,文献仅见Tang等(2001)和李永慈等(2004)的研究。本文就树高生长、断面积及蓄积等3方面的国内外研究现状进行总结,并就未来的应用前景进行展望。
1 混合效应模型简介 1.1 模型基本形式 1.1.1 线性混合效应模型在模型函数关系中,混合效应模型的固定和随机效应以线性关系出现被称为线性混合效应模型,以下简称LME(linear mixed effect)。LME可被看成是固定效应模型与随机效应模型相结合来解释在同一群体内观测资料的相关性及差异性。
LME的一般函数形式是以矩阵形式出现,具体的形式如(1)式:

|
(1) |
式中:yi是第i个研究对象上的ni维因变量,m是研究对象的数量,Xi和Zi是ni×p和ni×q维设计矩阵,β是p维固定效应向量,bi是q维随机效应向量,εi是ni维残差向量,D是q×q维协方差矩阵,∑i是ni×ni维协方差矩阵。bi的分布假定服从均值为0,方差协方差矩阵为D的正态分布。单一水平LME形式(1)可被推广到多水平模型形式(Pinheiro et al., 2000)。
LME的统计推论是以参数向量β,协方差矩阵D和∑i为基础的, 其理论和计算方法可参考Vonesh等(1997)及Verbeke等(2000)的多水平模型。
1.1.2 非线性混合效应模型非线性混合效应模型是通过考虑回归函数依赖于固定和随机效应的非线性关系而建立的,以下简称NLME(nonlinear mixed effect)。NLME模型可被看成是对在数据分析中忽略群体性的简单非线性模型和缺乏描述种群平均趋势的非线性模型的一种折衷。
单水平NLME模型的形式如(2)式(Pinheiro et al., 2000):
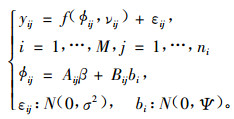
|
(2) |
式中:yij是第i个研究对象中第j次观测的因变量值,M是研究对象的数量,ni是在第i个研究对象上观测的次数,f是真实值,是一个研究对象中具体参数向量ϕij和变值向量νij的可微函数,εij是服从正态分布的误差项,β是(p×1)维固定效应向量,bi是带有方差协方差矩阵Ψ的(q×1)维随机效应向量,Aij是Bij相应的设计矩阵。(2)式通常被假定为是与不同研究对象相对应的观测资料是相互独立的并且在群体内产生的误差与bi无关。
(2) 式的单水平NLME可被扩展到多水平NLME。以两水平模型为例,(2)式可被扩展成如式(3):
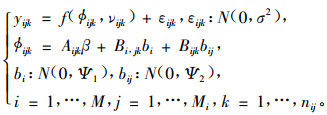
|
(3) |
式中:yijk是第i个第1水平的群体中第j个第2水平群体中第k次观测的因变量值,M是第1水平群体的数量,Mi是在第i个第1水平群体内第2水平群体的数量,nij是在第i个第1水平内第j个第2水平群体中观测的次数,f是真实值,是一个研究对象中具体参数向量ϕijk和变值向量νijk的可微函数,εijk是服从正态分布并与随机效应无关的误差项,β是(p×1)维固定效应向量,Aijk是其设计矩阵,第1水平随机效应bi是独立同分布的带有方差协方差矩阵Ψ1的q1维随机效应向量。同样,第2水平随机效应bij是独立同分布的带有方差协方差矩阵Ψ2的q2维随机效应向量,并与bi无关。Bi, jk和Bijk是随机效应的设计矩阵。
1.2 方差协方差结构在应用混合模型时,首先要确定随机效应的方差矩阵结构。在各种不同的软件中,给出了典型的结构。SPSS提供了线性混合模块随机效应的方差矩阵结构,包括AR1(First-Order Autoregressive), CS(Compound Symmetry)、HF(Huynh-Feldt), ID(Scaled Identity), UN(Unstructured)及VC(Variance Components)等几种,但SPSS没有提供非线性混合模型模块。SAS提供了线性和非线性混合模块,并且线性和非线性混合模型模块采用了不同的随机效应结构表达形式,具体可参考文献李永慈(2004)。S-Plus提供了线性和非线性混合模块,并且线性和非线性混合模块采用相同的形式来描述随机方差结构,具体的形式有General Symmetric, Diagonal, ID, CS和Block Diagonal等。尽管各种统计软件提供了多种描述随机效应方差的结构,对于在林业研究中,如何选择随机效应方差结构却没有一个统一的规则,应根据具体的模型形式来定。
除了要确定随机效应方差协方差结构,还要确定误差效应方差协方差结构。在各种统计软件中,SPSS与SAS采用的误差方差协方差结构与随机效应相同;但S-Plus中误差的方差协方差结构与随机效应的不同,采用的是再分解的方式来描述,具体可参考文献Davidian等(1995)。
1.3 估计和评价方法LME或NLME的线性化形式可利用SAS软件的PROC MIXED模块或S-Plus的lme模块实现。在S-Plus中的lme和SAS中的PROC MIXED模块可任选极大似然和限制极大似然法进行参数估计。2个软件缺省的方法是限制极大似然方法(Pinheiro et al., 2000)。
NLME的参数估计包括EM运算法则、重要性抽样、渐近似然方法及限制似然方法等。NLME的理论和计算可参考文献Vonesh等(1997)和Davidian等(1993)。NLME可利用SAS软件的PROC NLMIXED或S-Plus的nlme模块实现。在S-Plus的nlme模块或SAS软件的PROC NLMIXED模块缺省的是极大似然方法(Pinheiro et al., 2000)。
在混合模型研究中,经常要选择一些统计方法对不同混合效应模型拟合效果(Pinheiro et al., 2000)进行评价和衡量。最常用的包括2种:Akaike Information Criterion(AIC)和Bayesian Information Criterion(BIC)。AIC是与普通最小二乘中调整系数相似的一个评价指标,而BIC又被称为Schwarz Bayesian Criterion。在SPSS,SAS和S-Plus中这2个评价指标均可计算,这2个值越小说明模型的拟合效果越好。
2 在森林生长模型中的应用 2.1 单木水平模型 2.1.1 树高生长模型包括树高/直径关系模型和树高/年龄关系模型。
1)树高/直径关系模型
① Nanos等(2004)为西班牙海岸松(Pinus pinaster)构造了NLME的树高/直径关系模型。与其他NLME不同的是,作者利用的是地统计学方法(利用航片和卫片)获取样地上具体的单位面积林分株数同时考虑林分之间空间变化的相关性,而不是来自地面的调查。具体形式如(4)式:

|
(4) |
式中:Hij为具体树木的树高,a, b, c为固定效应参数,Ni为单位面积林分株数,vi为随机效应参数,dij为胸高直径,εij为随机误差。
② Calama等(2004)模拟了西班牙4个不同区域石松(Pinus pinea)的单木树高/直径关系模型。具体做法是首先对5种函数模型利用普通的最小二乘法进行拟合,然后选择平均残差和均方根误差最小的函数作为基础模型,并在此基础上构造NLME。另外把林分密度、优势木高度及直径分布百分比作为随机效应,区域效应作为名义变量加入到模型中。最后研究结果认为带有随机样地和区域效应的NLME提高了估计精度。模型形式如(5)式:
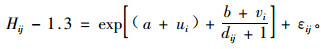
|
(5) |
式中:Hij为具体树木的树高,a, b为固定参数,ui, vi为随机效应参数,dij为胸高直径,εij为随机误差。
③ Mehtätalo(2004)利用NLME模拟了某一时间段内挪威云杉(Picea abies) Korf形式的树高/直径关系曲线。作者首先对模型线性化然后进行模拟,最后利用新的林分数据对模拟的结果进行检验。结果表明,混合效应模型方法比传统的模拟技术效果要好的多,并且认为林分的树高生长趋势主要依赖于林分的平均直径而不是林龄。Korf模型线性化后的具体模型形式如(6)式:
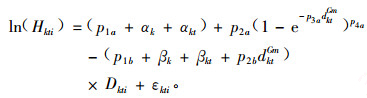
|
(6) |
式中:Hkti为树木高度,Dkti为树木直径,dktGm为林分的平方平均直径,p1a, p1b, p2b为固定的种群水平参数,αk, βk为随机林分水平参数,αkt, βkt为在林分内时间水平的参数,εkti为树木水平的误差项。
④ Budhathoki等(2005)构造了美国萌芽松(Pinus echinata)树高/直径关系的NLME,结果表明由于考虑了随机效应的影响,残差要比只考虑固定效应的小。具体形式如(7)式:
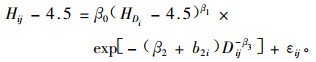
|
(7) |
式中:Hij样地i内树木j的高度,Dij样地i内树木j的胸高直径,HDi样地i的优势木平均高,βi固定效应参数,b2i为随机效应参数,εij为样地i内树木j的残差。
⑤ Dorado等(2006)利用Schnute方程研究了西班牙西北地区辐射松(Pinus radiata)树高/直径关系的NLME模型,并利用新的林分数据进行了验证。结果表明,与传统的估计方法相比,NLME方法提高了树高估计的准确性。所采用的模型形式如(8)式:
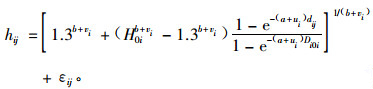
|
(8) |
式中:a, b为固定参数,vi, ui为具体样地的随机参数,hij为样地i树木j的树高,dij为相应的胸高直径,D0i, H0i为样地i的优势木高度和直径,εij为样地i树木j的估计误差。
⑥ Lynch等(2005)分析了美国德克萨斯州东部50个林分561株黑樱桃(Quercus pagoda)的树高/胸径数据,构建了LME模型,并且利用新的林分测量数据对模型进行了验证。所选择的模型与Lappi(1988)利用的模型相似,是Korf函数的线性化。研究结论认为采用随机效应方法模拟的精度要比只采用固定效应参数的高。具体模型形式如(9)式:
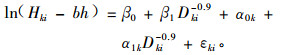
|
(9) |
式中:Hki为在林分k内第i株数木的树高;bh为胸高,通常指1.3 m处;Dki为在林分k内第i株数木的胸高直径;β0, β1为固定效应参数;α0k, α1k为林分k内随机效应参数;εki为在林分k内第i株数木的随机残差。
⑦ Mahadev等(2007)首先利用加拿大安大略省8个树种的固定样地数据,选择Chapman-Richards为基本函数,通过变换自变量,构造了几种树高/直径关系曲线,利用普通非线性最小二乘法进行模拟,从中选择出一个拟合精度较高的模型为基本模型。在确定随机效应参数时首先认为这几个参数都是随机的,然后其中一个是随机的进行模拟,最后以AIC值最小为标准。最后利用混合效应和固定效应2种方法分别进行模拟并对模拟精度进行比较。结果表明, 带有随机效应参数的混合效应模型要比相应的固定效应模型误差小,拟合精度高。具体的模型形式见(10)式:

|
(10) |
式中:hij为树高,θ, β, δ, φ, γ为固定参数,ui为随机参数,SHT为林分的优势木平均高,TPH为林分密度(单位面积株数),BA为林分的公顷断面积,Dij为林木的直径,εij为残差。
这几个模型虽然模型形式不同,但是研究的基本思路是首先选择了模拟精度较高的传统模型形式构建混合效应模型,同时考虑林分的随机效应并进行模拟和精度评价,然后再与传统的模型进行精度比较。研究结论均认为混合模型较传统模型在模型精度上有较大的提高,并且在预测能力上有较大的优势。
2)树高/年龄关系模型
① Lappi等(1988)最早在林业上利用NLME来预测沼泽松(Pinus eilliottii)单木水平和样地水平上林分的优势木和亚优势木高度。所采用的模型是Richards式,然后利用残差来确定估计参数的方差结构,此研究是一个多水平NLME的例子。具体形式如(11)式:

|
(11) |
式中:hki(t)是林分k在年龄t时第i株树的优势高;μ(t)是在年龄t时林分的平均高;bk(t)是在年龄t时的随机林分效应;εki(t)是独立于bk(t)的随机树木效应。
② Hall等(2001)以美国乔治亚州的火炬松(Pinus taeda)为研究对象,利用多水平NLME方程组构造了Chapman-Richard形式的树高生长曲线。考虑样地和树木水平上的随机效应,所采用的参数估计方法是线性化估计方法而不是极大似然或限制极大似然方法。研究结果认为,与传统的模拟方法相比,多水平NLME在模型估计精度上有较大的优势,但不能够直接模拟存在于研究对象内随机效应误差的方差和协方差矩阵。模型组形式如(12)式:
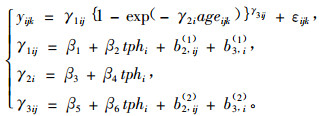
|
(12) |
式中:tphi为样地i的公顷株数/100,γ1ij为渐近参数,γ2ij为尺度参数,γ3ij为形状参数,γ1和γ3是随样地和树木的变化而变化的,b2,ij(1)和b2, ij(2)是指随机的树木效应,b3, i(1)和b3, i(2)是随机的样地效应。
这2种模型都同时考虑了样地和树木的随机效应,可看成是林分水平模型也可看成是单木水平模型。与传统的回归模型相比,既能够提供优势木的平均水平,又能够反映由于样地和树木不同对优势高的影响,并且在模拟精度上大大提高。
2.1.2 材积生长模型作为利用NLME构造森林蓄积函数的先驱者,Gregoire等(1996)为美国东部德克萨斯州枫香(Liquidambar styraciflua)单木的累积树干材积构造了一个NLME。在这个模型中作者利用2个随机效应参数进行拟合,目的是把累积树干材积用平滑的曲线表示出来同时尽可能的考虑树木内部和树木之间的波动性。结论认为要比利用一个随机效应模型好,并且有效地消除了树木之间的关联性对模型精度的影响。具体模型形式如(13)式:
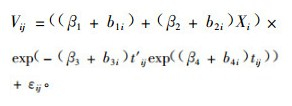
|
(13) |
式中:Vij是第i株树木的第i部位的累积树干材积,Xi=Di2Hi/1 000, tij=dij/Di, t′ij=tij/1 000, Di为第i株树木的胸高直径,Hi为第i株树木的树高。
2.2 林分水平模型 2.2.1 树高生长模型包括树高/年龄关系模型和树高/直径关系模型。
1)树高/年龄关系模型
① Fang(2001a;2001b)利用修改的三参数Richard生长模型为不同经营方式下(比如采伐、施肥和燃烧)美国乔治亚州和佛罗里达州沼泽松的优势高生长论证了NLME的一般方法论。作者首先为了避免优势高和地位指数之间的不相容性,把两者结合成一个模型。然后在构造NLME时考虑了样地和经营措施的随机效应,并详细描述了模型中哪个参数应作为固定效应哪个应作为随机效应的确定方法、样地内的方差协方差结构及利用共变模型确定样地之间的可变性等。最后利用AIC值来衡量模型的估计精度,并且把单变量的混合效应模型推广到多变量水平。研究结论认为NLME方法要比传统方法预测的精度高。修改的Richard生长模型形式如(14)式:
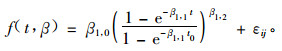
|
(14) |
式中:β1, 0, β1, 1, β1, 2为参数,t为林龄,t0为标准林龄(本文取25年),εij为随机误差。
② 李永慈等(2004)以江西省大岗山实验局5个不同初植密度3个重复的杉木(Cunninghamia lanceolata)优势高生长数据为研究对象,建立了对数Schumacher混合生长模型和Logistic混合生长模型。结果表明,变换后的Schumacher混合模型很好地拟合了变换后的树高生长过程,非线性Logistic混合模型很好地拟合了原始树高生长过程。模型形式如(15)式和(16)式。
变换后的Schumacher形式:
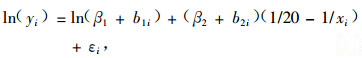
|
(15) |
Logistic形式:
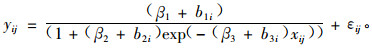
|
(16) |
式中:yi, yij指的是优势木高度,βi为固定参数,b1i, b2i, b3i为随机效应参数,Xi, xij为林分年龄,εi, εij为随机误差。
③ Calegario等(2005)利用从1992到2001年间测量的115个固定样地(测量了3~10次)数据,考虑样地的随机效应,为采用不同无性繁殖技术处理的巴西桉树(Eucalyptus)构造了Logistic形式的优势高和林龄关系的NLME。利用AIC,BIC及对数似然比检验方法对模拟结果进行精度分析。结果表明,采用3参数Logistic函数的NLME方法描述桉树无性繁殖的优势木高度具有相当大的灵活性,产生了依赖于无性繁殖方法和周围环境的多形地位指数曲线,并且构造了适宜的方差协方差矩阵。研究结果进一步说明带有样地效应的NLME对优势高的拟合效果很好。具体形式如(17)式:
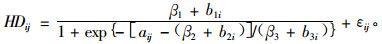
|
(17) |
式中:HDij为第j次测量第i个样地的优势木高;aij为第j次测量第i个样地的林龄;βi为固定效应参数,b1i, b2i, b3i为随机效应参数,εij为随机误差,εij:N(0, σ2)。
以上3个模型都利用了林分优势木平均高与林龄的关系建立的混合效应生长方程,并且把每个参数都看成了随机效应和固定效应的结合,很好地解释了由于林分密度、经营状况及不同繁殖条件不同而造成的不同林分之间优势高的不同,另外也提高了预测精度。
2)树高/直径关系模型
Uzoh等(2006)考虑位置效应、样地效应和树木直径的随机效应,构建了美国西部310个永久固定样地上的美国黄松(Pinus ponderosa)同龄林分的树高生长量模型。模拟结果显示树高生长量模型呈现单峰山状倾斜形状,利用地位指数作为变量较其他变量对树高生长影响的效果明显。所采用的模型形式是把树高的定期年平均生长量转化成对数形式后建立的LME,具体形式如(18)式:
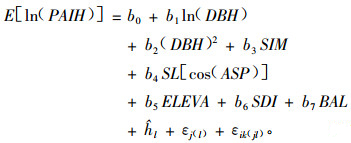
|
(18) |
式中:E[ln(PAIH)]为5年期间的树高定期年平均生长量的自然对数的期望值;DBH为初始期胸高直径;SDI为Meyer地位指数;SL为林分的平均坡度;ASP为林分坡度的平均弧度;ELEVA为林分的海拔;SDI为林分密度指数;BAL为主要树种较大树木的公顷断面积;ĥl为l位置的固定效应参数;εj(l)为位置l内样地j的随机误差;εik(jl)为位置l内样地j内树木i的第k次测量的随机误差;bi为估计的固定参数。
2.2.2 断面积生长模型1) Gregoire等(1987)在Ferguson等(1978)工作的启发下,为断面积收获模型估计了4个不同的协方差结构: ①不相关及同方差样地的效应;②自回归时间效应;③不相关及异方差样地效应和自回归时间效应;④相关和异方差样地效应及自回归时间效应。最后发现广义最小二乘方法估计很好。作者虽然考虑了复杂的误差结构但并没有提高模型的估计精度。
2) Fang等(2001a;2001b)模拟了在几种不同经营措施(比如采伐、施肥和燃烧)下美国乔治亚州和佛罗里达州沼泽松林分的断面积混合效应模型。模拟结果表明,考虑经营措施效应的混合模型方法要比传统方法预测的精度高。具体模型形式如(19)式:
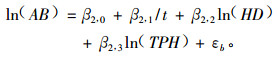
|
(19) |
式中:BA为林分的断面积,β2, i为随机效应参数,t为林龄,HD为林分优势木平均高,TPH为公顷株数,εb为误差。
3) Budhathoki等(2005)采用混合的均匀协方差结构并考虑样地的随机效应构造了美国萌芽松的断面积LME模型。结果认为,与只在β7参数上考虑随机效应的模型相比,在β1和β7上同时考虑随机效应获得的AIC和BIC和SD值要小,说明当增加样地的随机效应参数时能够改善生长模型的适应性。具体形式如(20)和(21)式:
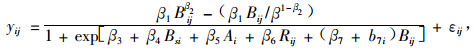
|
(20) |
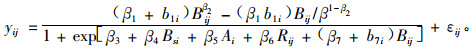
|
(21) |
式中:yij为样地i在树木j上的断面积年平均生长量;Bij是样地i在树木j上的断面积;Ai样地i的林龄;Rij样地i在树木j上林分的平均直径与每木胸高直径比率;Bsi样地i的林分断面积;B为在经营期望的林分最大断面积;βi为固定效应参数;b7i为随机效应参数;εij为样地内误差(样地i内树木j的残差)。
这3个断面积混合模型采用了不同的随机效应的方差协方差结构对模型进行了模拟和预估,分析了样地效应对模型精度的影响,都得出了考虑样地及树木效应会提高模型的估计精度。
2.2.3 蓄积生长模型在利用混合模型研究森林蓄积时,研究者采用了混合模型和联立方程组相结合的办法,结果在很大程度上提高了蓄积的估计精度,具体的研究如下。
1) Fang等(2001a;2001b)利用NLME方法预测了经过不同经营措施处理的美国乔治亚州和佛罗里达州沼泽松林分的蓄积生长趋势。作者首先是建立优势木平均高和林分断面积NLME模型,然后再利用估计的优势木平均高和林分断面积来预测林分的蓄积。结果表明,在优势木平均高模型中考虑了林分的随机效应及优势木平均高、断面积和蓄积三者之间的相关性,则使林分的蓄积的误差限从52.6%减小到5.8%。具体模型形式如(22)式:

|
(22) |
式中:V为单位面积蓄积,HD为林分的优势木平均高,BA为公顷断面积,εv为误差项。
2) Hall等(2004)介绍了利用多元多水平的NLME描述分布在美国的乔治亚州和佛罗里达州沼泽松样地水平的木材收获预测方法。主要工作是利用一个三元的NLME同时模拟优势木高、公顷断面积和公顷株数,并利用这几个预测值输入到蓄积模型中来对林分未来的生长和收获做预测。具体模型形式如(23),(24)和(25)式:

|
(23) |

|
(24) |
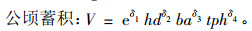
|
(25) |
式中:θijkl(EV), θijkl(Rate), θijkl(Shape), δi为固定参数,在模拟时把随机效应同时考虑进去;hd为林分的优势木平均高;ba为公顷断面积;tph为公顷株数;Ageijk为林龄,AgeR为林分的标准年龄(本文取25年)。
3) Zhao等(2005)利用多水平的NLME方法模拟了经过4种不同经营措施处理的火炬松林分的蓄积生长。结论认为,控制采伐和施肥措施导致了最大的蓄积生长量,NLME对于处理非均衡的和不完整的重复测量数据是很有用的。具体模型形式如(26)式:
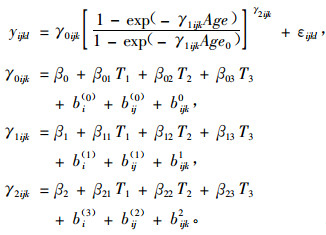
|
(26) |
式中:yijkl为位置i内第j个区组第k个样地第l次测量的林分蓄积,γ0ijk, γ1ijk, γ2ijk为参数,Age为林龄,Age0为标准林龄此处为25年,εijkl为残差。假如经营措施为施肥,则T1=1,否则T1=0;假如经营措施为使用除草剂,则T2=1,否则T2=0;假如经营措施为使用除草剂加施肥,则T3=1,否则T3=0。
3 结语1) 广义的线性模型理论仅能够帮助我们讨论固定参数的估计,无助于我们讨论随机参数的估计及推断。混合效应模型作为一种处理残差项不满足独立性、方差齐性、正态性等的新的统计方法,在我国森林生长模型研究方面应用较少,但森林生长模型数据通常具有多次重复测量、多层次等特征,因此具有很大的应用潜力。随机效应参数的引入使得混合模型对误差分布的刻画更为精细,为研究者提供了新的研究课题(唐守正,2002)。
2) 混合效应模型对于提高我国森林资源一类清查和二类调查中各项因子的预估精度具有重要意义。另外在外业调查时由于工作量问题,采用抽样方法来推断总体时可采用混合模型的方法,这样可以更准确的估计总体又能够反映个体之间及个体内部的差异,其应用在森林经理调查中具有重要意义。
3) 在林业生产中经常要对森林进行各种经营措施,在科学研究中要设立不同立地条件、不同初植密度、不同区组的样地,这些不同措施对林分因子的影响就成为林业工作者关心的重点。而由于加入了随机效应,混合模型方法可以对这些影响及各组成误差进行解释并能够进行准确的量化研究,便于指导林业生产。
4) 目前在林业文献中,影响模型推断结果的协方差结构的NLME程序规范性文件还很缺乏。因此,对于适当的和灵活的方差协方差结构规范的重要性引起了很多学者的注意(Jordan et al., 2005)。
5) 很多统计软件还没有混合模型的模块,即使有此模块但功能并不完善。在我国,混合效应模型在林业中的应用逐步得到重视,相信随着计算机统计软件关于混合效应模型算法的不断完善,其在林业领域各个学科的应用会越来越广阔。
李永慈. 2004.基于混合模型和度量误差模型方法研究生长收获模型的参数估计问题.北京林业大学学位论文, 16. http://d.wanfangdata.com.cn/Thesis/Y668348
|
李永慈, 唐守正. 2004. 用Mixed和Nlmixed过程建立混合生长模型. 林业科学研究, 17(3): 279-283. DOI:10.3321/j.issn:1001-1498.2004.03.003 |
唐守正, 李勇. 2002. 生物数学模型的统计学基础. 北京: 科学出版社.
|
Budhathoki C B, Lynch T B, Guldin J M.2005 February 28-March 4.Individual tree growth models for natural even-aged Shortleaf Pine(Pinus echinata Mill.). Proceedings of the 13th Biennial Southern Silvicultural Conference, Memphis, TN.
|
Calama R, Montero G. 2004. Interregional nonlinear height-diameter model with random coefficients for stone pine in spain. Canada Journal Forest Resource, 34: 150-163. DOI:10.1139/x03-199 |
Calegario N, Daniels R F, Maestri R, et al. 2005. Modeling dominant height growth based on nonlinear mixed-effects model: a clonal Eucalyptus plantation case study. Forest Ecology and Management, 204: 11-21. DOI:10.1016/j.foreco.2004.07.051 |
Chi E M, Reinsel G C. 1989. Models for longitudinal data with random effects and ar(1) errors. Journal American Statistics Association, 84: 452. DOI:10.1080/01621459.1989.10478790 |
Davidian M, Gallant A R. 1993. The nonlinear mixed effects model with a smooth random effects density. Biometric, 80: 475-488. DOI:10.1093/biomet/80.3.475 |
Davidian M, Giltinan D M. 1995. Nonlinear models for repeated measurement data. New York: Chapman & Hall.
|
Dorado F C, Ulises D A, Marcos B A., et al. 2006. A generalized height-diameter model including random components for radiata pine plantations in northwestern Spain. Forest Ecology and Management, 229: 202-213. DOI:10.1016/j.foreco.2006.04.028 |
Fang Z, Bailey R L. 2001a. Nonlinear mixed effects modeling for slash pine dominant height growth following intensive silvicultural treatments. Forest Science, 47: 287-300. |
Fang Z, Bailey R L, Shiver B D. 2001b. A multivariate simultaneous prediction system for stand growth and yield with fixed and random effects. Forest Science, 47: 550-562. |
Ferguson I S, Leech J W. 1978. Generalized least squares estimation of yield functions. Forest Science, 24: 27-42. |
Fox J C, Ades P K, Bi H. 2001. Stochastic structure and individual-tree growth models. Forest Ecology and Management, 154: 261-276. DOI:10.1016/S0378-1127(00)00632-0 |
Gregoire T G. 1987. Generalized error structure for forestry yield models. Forest Science, 33: 423-444. |
Gregoire T G, Schabenberger O. 1996a. A nonlinear mixed-effects model to predict cumulative bole volume of standing trees. Journal Apply Statistics, 23: 257-271. DOI:10.1080/02664769624233 |
Hall D B, Bailey R L. 2001. Modeling and prediction of forest growth variables based on multilevel nonlinear mixed models. Forest Science, 47: 311-321. |
Hall D B, Clutter M. 2004. Multivariate multilevel nonlinear mixed effects models for timber yield predictions. Biometrics, 60: 16-24. DOI:10.1111/biom.2004.60.issue-1 |
Jordan L, Daniels R F, III A C, et al. 2005. Multilevel nonlinear mixed-effects models for the modeling of earlywood and latewood microfibril angle. Forest Science, 51: 357-371. |
Lappi J, Bailey R L. 1988. A height prediction model with random stand and tree parameters: an alternative to traditional site methods. Forest Science, 34: 907-927. |
Little R C, Milliken G A, Stroup W W, et al. 1996. SAS system for mixed models. Cary, NC: SAS institute Inc.
|
Lynch T B, Holley A G, Stevenson D J. 2005. A random-parameter height-diameter model for Cherry-bark Oak. South Journal Apply Forest, 29: 22-26. |
Mahadev S, John P. 2007. Height-diameter equations for boreal tree species in Onario using a mixed-effects modeling approach. Forest Ecology and Management, 249: 187-198. DOI:10.1016/j.foreco.2007.05.006 |
Mehtätalo L. 2004. A longitudinal height-diameter model for Norway Spruce in Finland. Canada Journal Forest Resource, 34: 131-140. DOI:10.1139/x03-207 |
Nanos N, Rafael C, Gregorio M., et al. 2004. Geostatistical prediction of height-diameter models. Forest Ecology and Management, 195: 221-235. DOI:10.1016/j.foreco.2004.02.031 |
Pinheiro J C, Bates D M. 2000. Mixed effects models in S and S-plus. Newyork: Springer Verlag.
|
Tang S Z, Meng F R. 2001. Analyzing parameters of growth and yield models for Chinese Fir provenances with a linear mixed approach. Silvae Genetica, 50: 140-145. |
Uzoh F C C, Oliver W W. 2006. Individual tree height increment model for managed even-aged stands of Ponderosa Pine throughout the western United States using linear mixed effects models. Forest Ecology and Management, 221: 147-154. DOI:10.1016/j.foreco.2005.09.012 |
Verbeke G, Geert M. 2000. Linear mixed models for longitudinal data. Newyork: Springer Verlag.
|
Vonesh E F, Chinchilli V M. 1997. Linear and nonlinear models for the analysis of repeated measurements. New York: Marcel Dekker Inc.
|
Zhao D, Wilson M, Borders B E. 2005. Modeling response curves and testing treatment effects in repeated measures experiments: a multilevel nonlinear mixed-effects model approach. Canada Journal Forest Resource, 35: 122-132. DOI:10.1139/x04-163 |