|
类人概念学习:机器学习下一个飞跃?
浙江大学智能系统与控制研究所,杭州 310007
近年来,深度学习的飞速发展让计算机在许多任务中表现出接近甚至达到人类水准的认知能力。然而,关于深度学习仍然存在一些争议,其中一点就是深度学习对于大规模训练样本的要求。相比于深度学习,人类并不需要见到成百上千的某一类物体才能记住其特性和类别。因此,仍有许多专家从这一点出发试图构造更接近于人类思考方式的学习模型。 类人概念学习2015年12月,来自纽约大学、多伦多大学以及麻省理工学院的3位学者在《Science》上发表《Human- level concept learning through probabilistic program induction》的封面文章(图 1),引起了机器学习领域的广泛关注。该文构造了一个基于贝叶斯理论的概率模型,在累积足够先验知识的基础上,可以识别只见过一次的字符,也可以依照该字符结构写出新的字符,充分体现了其类人概念学习的思路。具体来讲,文章主要有以下两个亮点:1)在oneshot learning分类实验中(即各类别只给定一个训练样本并要求分类测试样本),该方法达到了人类认知水平并且超越了近年来在机器学习各个问题中引领鳌头的深度学习算法;2)基于该方法采样生成的字符并通过了图灵测试,仅有25%的人可以成功分辨给定字符是由计算机生成还是由人类手写得到。图 2给出了两组图灵测试的示例,1和2所示的分别是人类和计算机仿照示例字符写出的,能分辨出哪组是计算机写的么?  图1 当期《Science》封面 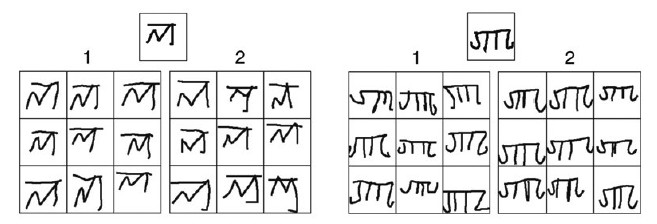 图2 图灵测试示例,左侧第1 组为计算机生成,右侧第2 组为计算机生成,其余为人类书写(图片来源:《Science》) 该文提出的方法称为贝叶斯程序学习(bayesian program learning),其目的是基于先验知识实现极少量样本下的感知学习,文章的出发点是模仿人类的环境感知能力,构造类人概念学习模型。例如对于图 3的A和B,人类均可以在只给定一个样本的情况下找出同类样本(i);其次,人们可以创造出相近物体(ii),也可以感知物体的结构与关系(iii);最后,人类还可以根据已有知识创造出新的类别(iv)。为使计算机实现类似感知性能,作者基于贝叶斯概率模型,在图 3中B所示的手写字符集上实现了具有以下3个特性的Bayesian Program Learning方法: 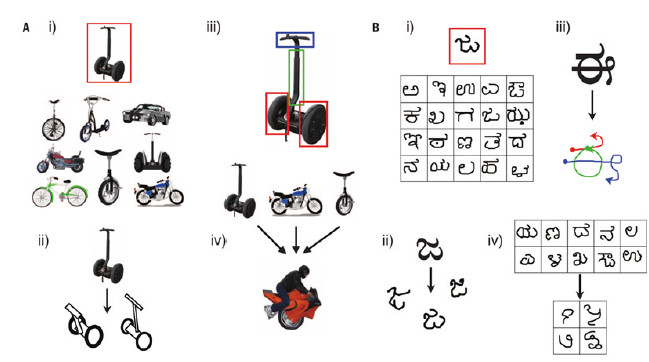 图3 人类可从少量样本中获取大量知识(图片来源:《Science》) 1)组合性(compositionality),将任务进行拆分,从笔画、逻辑关系等学习字符的构造。 2)因果性(causality),学习字符生成时的抽象因果结构。 3)自主学习(learns to learn),利用层次化先验知识降低新学习任务难度。 贝叶斯程序学习与深度学习《Human- level concept learning through probabilistic program induction》一文的发表引发了业界对于深度学习算法与非深度学习算法之间优劣对比的新一轮讨论。深度学习奠基人之一——Geoffrey Hinton在接受《麻省理工学院科技评论》采访时指出,该文的工作是令人印象深刻的,他认为该文中从少量样本进行学习的思路可与深度学习和睦相处,并期望可以对两者的优点进行结合。该文作者与Hinton的观点一致,认为通过分析任务特性,可结合深度学习与此文提供的贝叶斯方法实现更高效率且高精度的感知学习。 机器学习的任务可看作是对于高阶复杂函数的拟合过程,并且这个高阶复杂函数往往没有对应解析形式,而函数拟合过程中有两个因素会对其产生重要影响:一是待拟合函数本身在高维空间中分布的平滑性,二是观测样本的数量。 对于分类问题而言,函数的平滑性实际上反应了同类样本之间的方差,方差越小的情况下则分布更平滑。对于《Human-level concept learning through probabilistic program induction》一文中给出的手写字符,本文认为这是一个数据分布平滑但观测样本少的例子,因为同类样本之间笔画是相同的,只是在书写时会有一定差异,因此,文章可通过贝叶斯网络表征先验的结构化知识,建模方差较小的数据之间的内联关系,从而实现极少样本下的函数拟合。 然而,在函数不平滑时,建模人类的先验知识可能需要耗费巨大精力且几乎难以覆盖全部样本空间,而深度学习的优势就是在观测样本数量足够多时可以很好地逼近目标函数。最近以4∶1战胜李世乭并获得举世瞩目的AlphaGo就是对深度学习这一能力的最佳体现,由于围棋中一颗棋子的位置也许也会造成输赢的变化,所以围棋的盘面在高维空间中并非平滑分布,可见深度学习有能力通过大量样本拟合非平滑的函数。对于许多图像、视频等从真实世界中获取的观测数据来说,其光滑性也难以保证,所以深度学习目前也在这些领域占据着最优的表现。 结合以上的分析,也有理由相信平衡考虑样本的平滑性及其观测数量是结合贝叶斯程序学习与深度学习方法优势的关键。以图 3为例,B中给出的手写字符一例中,字符的各个子成分可以直接通过样条插值获得,然而A中真实世界图像的成分则无法基于这些人工参数得到。因此,也许可以采用深度学习方法对A中各个零件进行特征表示,然后在其基础上基于文中的方法实现特征之间的组合。由于零件的差异性远小于其组建的物体整体的差异性,因此可以在利用人类的先验知识的建模部分平滑性结构的基础上降低对于观测数量的要求。 机器学习未来趋势机器学习的难点在于使用尽可能少的标注数据拟合复杂度高的不平滑函数。《Human-level concept learning through probabilistic program induction》一文通过在函数平滑性较好的示例展示了一个基于先验知识和少量样本进行学习和认知启发性思路,期待后续这一思路可以进一步被扩展到更复杂的问题中。同时预测未来研究的主流可能包含以下几个方向: 1)先验知识与深度学习相结合。将先验知识建模在深度学习中,基于先验知识获取部分数据内联关系,从而减小深度学习所要求的训练样本数量。 2)标注数据与非标注数据相结合。当先验知识难以建模的时候,基于大量观测数据的学习方法依然占据着目前学习的主流,而数据获取的昂贵性主要体现在其标注的获取,非标注数据的获取是廉价且方便的,若能借助非标注数据实现对于高维复杂函数的部分拟合,则可缓解深度学习对于标注数据数量的要求。 3)感知任务与操作任务相结合。人类的感知工作的一个目的是为操作任务而服务,而人类在执行操作任务的时候有时只需要对环境有大概认知即可。以视觉感知为例,感知任务样本之间差异性巨大,因此需要大量标注样本,相比而言,操作任务真值的复杂度则小许多,例如不管在什么环境中,人类的行走方式是大致不变的。若能直接从输入出发,在获得一定程度的感知技能的基础上直接拟合操作任务的函数,则有可能降低对于感知任务数据的需求。 (责任编辑 刘志远) |