
Gibbs Sampling-based Sparse Estimation Method over Underwater Acoustic Channels
https://doi.org/10.1007/s11804-024-00415-4
-
Abstract
The estimation of sparse underwater acoustic (UWA) channels can be regarded as an inference problem involving hidden variables within the Bayesian framework. While the classical sparse Bayesian learning (SBL),derived through the expectation maximization (EM) algorithm,has been widely employed for UWA channel estimation,it still differs from the real posterior expectation of channels. In this paper,we propose an approach that combines variational inference (Ⅵ) and Markov chain Monte Carlo (MCMC) methods to provide a more accurate posterior estimation. Specifically,the SBL is first re-derived with Ⅵ,allowing us to replace the posterior distribution of the hidden variables with a variational distribution. Then,we determine the full conditional probability distribution for each variable in the variational distribution and then iteratively perform random Gibbs sampling in MCMC to converge the Markov chain. The results of simulation and experiment indicate that our estimation method achieves lower mean square error and bit error rate compared to the classic SBL approach. Additionally,it demonstrates an acceptable convergence speed.Article Highlights● There is a gap between the channel estimation results based on sparse Bayesian learning and the true posterior estimates.● We propose an efficient method combining variational inference and Monte Carlo Markov chains to provide more accurate channel estimates.● Variational factors are employed to approximate the full conditional probability distributions of the hidden variables and sequentially sampled.● The effectiveness of the proposed method is verified by simulation and experiment. -
1 Introduction
Channel estimation plays a crucial role in underwater acoustic (UWA) communication. In terms of implementation, existing methods can be categorized into two classes: frequency-domain and time-domain approaches. The frequency-domain class (Wang and Dong, 2006; Zheng et al., 2010) involves the design of specific frame structures, such as the dual Unique Word (UW) design in a single-carrier frequency-domain equalization (SC-FDE) system, which transform the channel matrix into a diagonal matrix in the frequency domain. While these methods are relatively simple to implement and have low complexity, their applicability and performance are limited in certain scenarios. Alternatively, time-domain techniques have emerged as the dominant approach in channel estimation due to their flexibility and accuracy. These techniques allow estimation using training sequences without any additional constraints. Among them, estimators based on the least square (LS) (Coleri et al., 2002) and minimum mean square error (MMSE) (Kang et al., 2003) criteria are widely used. However, their performance is also constrained without consideration for the sparsity of the UWA channel.
Compressive sensing is a crucial technique in sparse channel estimation, covering greedy methods (Panayirci et al., 2019; Wang et al., 2021), norm-constrained approaches (Li et al., 2016; Tsai et al., 2018; Wu et al., 2013), and Bayesian methods. Among them, sparse Bayesian learning (SBL) holds particular importance within the Bayesian framework. It was initially introduced in (Tipping and Michael, 2001) and subsequently applied to UWA channel estimation in (Cho, 2022; Feng et al., 2023; Jia et al., 2022). It was based on a linear model, employed a hierarchical probability distribution, and iteratively solved the posterior expectation of the channel vector. So far, the SBL has been further developed in various scenarios. A block-based SBL (BSBL) was presented in (Zhang and Rao, 2011), which further considered the temporal correlation of measurement vectors. Additionally, a joint SBL (JSBL) was proposed to enable joint channel and data detection in quasi-static channels in (Prasad et al., 2014), and then a Kalman filtering-based SBL (KSBL) was derived for time-varying cases that adopted a first-order autoregressive model.
The classical sparse Bayesian learning (SBL) was derived using the expectation maximization (EM) algorithm (Tipping and Michael, 2001). It estimated the hidden variable through maximum likelihood or maximum a posteriori estimation. However, even after convergence, there was still a discrepancy between the estimated value and the real posterior expectation. Additionally, the aforementioned optimization-based SBL algorithm cannot address this issue. Therefore, we introduce a SBL method that incorporates variational inference (Ⅵ) (Zhang et al., 2018) and Markov chain Monte Carlo (MCMC) (Casella and George, 1992) to enhance the estimation accuracy of the UWA channel.
The Ⅵ is a method that infers hidden variables by approximating their posterior distribution with a simpler variational distribution. It is noted that the EM algorithm is a special instance of Ⅵ when the posterior distribution of the hidden variables is known. Thereby, the SBL can also be approximately derived from Ⅵ. Although the formulas for EM and Ⅵ yield identical results, they carry different physical interpretations. On the other hand, MCMC is also an inference method that allows random sampling from a given analytic posterior distribution. It constructs a Markov chain that converges to a smooth distribution consistent with the target posterior distribution. In comparison to EM and Ⅵ, MCMC often demonstrates better performance. Gibbs sampling is an efficient implementation of the MCMC method, the performance of which in various scenarios has been further analyzed and developed. In previous work (Gelfand and Lee, 1993), a summary of some preliminary findings regarding the computational burden under various implementations of the Gibbs sampler is provided. The results reveal that the Metropolis-within-Gibbs method appears to be superior and exhibits less runtime compared to the other methods in both provided cases. Another study (Goudie and Mukherjee, 2016) presented a Gibbs sampler for learning the structure of directed acyclic graph (DAG) models. In contrast to the standard Metropolis-Hastings sampler, it draws complete sets of parents for multiple nodes from appropriate conditional distributions, providing an efficient method for making large moves in graph space, allowing faster mixing while retaining asymptotic guarantees of convergence. Recently, in a work by Martino et al. (2018), it is shown that the auxiliary samples can be recycled in the Gibbs estimator, thus increasing efficiency without additional cost. This advancement has the potential to improve the overall performance of Gibbs sampling.
In this study, we first derive SBL based on Ⅵ, approximating the posterior distribution of the channel, hyperparameters, and noise variance. Subsequently, we substitute the real posterior distribution with the variational distribution and determine the full conditional probability distributions for various variables. Finally, random Gibbs sampling in MCMC is efficiently performed to guarantee the convergence of Markov chain. The results of simulation and experiment demonstrated that compared to the classical SBL approach, the channel impulse response could be reconstructed more effectively.
This paper is organized as follows. Section 2 describes the model for UWA channel estimation and SBL; Section 3 details the Gibbs sampling-based sparse channel estimation method; the results of simulation and experiment are shown in Section 4 and Section 5, respectively. Finally, Section 6 concludes the whole paper.
2 System model
Consider a single-input single-output (SISO) UWA single-carrier communication system. The original binary bits are encoded, interleaved and mapped to produce the transmitted vector x = [x1, x2, …, xN]T ∈ CN × 1, where N is the number of symbols and (•)T indicates the transpose operation. Suppose the baseband length of the UWA channel is L and the observed length is M. The model for channel estimation at the receiver can be expressed as
$$ \boldsymbol{y}=\boldsymbol{\varPhi} \boldsymbol{h}+\boldsymbol{n} $$ (1) where y = [y1, y2, …, yM]T ∈ CM × 1 denotes the observed vector and n = [n1, n2, …, nM]T ∈ CM × 1 represents the noise vector with mean of zero and variance of σ2.
$$ \boldsymbol{\varPhi}=\left[\begin{array}{ccccc} x_1 & 0 & \cdots & & 0 \\ x_2 & x_1 & \cdots & & 0 \\ \cdots & \cdots & & \ldots & \ldots \\ x_M & x_{M-1} & \cdots & & x_{M-L+1} \end{array}\right] \in C^{M \times L} $$ (2) In SBL, the element hl of the channel vector h = [h1, h2, …, hL]T ∈ CL × 1 to be estimated is assumed to be independent and identically distributed (i.i.d.), which is adjusted by corresponding element αl in hyperparameter vector α = [α1, α2, …, αL]T ∈ CL × 1. The probability distribution can be expressed as
$$ p\left(\boldsymbol{h} \mid \boldsymbol{\alpha}^{-1}\right)=\prod\limits_{l=1}^L \mathcal{C N}\left(h_l \mid 0, \alpha_l\right)=\prod\limits_{l=1}^L\left(2 {\rm{ \mathsf{ π} }} \alpha_l\right)^{-\frac{1}{2}} \exp \left(-\frac{\left|h_l\right|^2}{2 \alpha_l}\right) $$ (3) where $\mathcal{C N}$ denotes the complex Gaussian distribution. In addition, both α−1 and σ−2 are assumed to obey the prior distribution of Gamma, satisfying
$$ p\left(\boldsymbol{\alpha}^{-1}\right)=\prod\limits_{l=1}^L \mathcal{G}\left(\alpha_l^{-1} \mid a, b\right) $$ (4) $$ p\left(\sigma^{-2}\right)=\mathcal{G}\left(\sigma^{-2} \mid c, d\right) $$ (5) The $\mathcal{G}$ denotes the Gamma distribution with a, b, c and d being known parameters. Meanwhile, the likelihood function in Eq. (1) obeys an M-dimensional independent complex Gaussian distribution, i.e.,
$$ p\left(\boldsymbol{y} \mid \boldsymbol{h}, \sigma^{-2}\right)=\left(2 {\rm{ \mathsf{ π} }} \sigma^2\right)^{-\frac{M}{2}} \exp \left(-\frac{\|\boldsymbol{y}-\boldsymbol{\varPhi} \boldsymbol{h}\|_2^2}{2 \sigma^2}\right) $$ (6) where ‖•‖2 represents the 2-norm of a vector. To date, the probability model of SBL in UWA channel estimation has been built. According to Eqs. (3)‒(6), the joint distribution of all variables can be expressed as
$$ p\left(\boldsymbol{y}, \boldsymbol{h}, \boldsymbol{\alpha}^{-1}, \sigma^{-2}\right)=p\left(\boldsymbol{y} \mid \boldsymbol{h}, \sigma^{-2}\right) p\left(\boldsymbol{h} \mid \boldsymbol{\alpha}^{-1}\right) p\left(\boldsymbol{\alpha}^{-1}\right) p\left(\sigma^{-2}\right) $$ (7) 3 Gibbs sampling-based sparse channel estimation method
In this section, the SBL will first be re-derived through Ⅵ. In Eq. (7), the unknown h, α−1, σ−2 together form the set of hidden variables Ω ={h, α−1, σ−2}. Accordingly, we can define the mean-field variational distribution qΩ (Ω)= qh (h)qα−1 (α−1)qσ-2 (σ−2). The idea of Ⅵ lies in minimizing
$$ \mathcal{K L}\left(q_{\Omega}(\Omega) \| p(\Omega \mid \boldsymbol{y})\right)=-\int_{\Omega} q_{\Omega}(\Omega) \ln \left(\frac{p(\Omega \mid \boldsymbol{y})}{q_{\Omega}(\Omega)}\right) \mathrm{d} \Omega $$ (8) where $\mathcal{K L}$ refers to the divergence and p (Ω | y) is the real posterior distribution. This objective can be achieved by updating each variational factor in turn (Zhang et al. 2018), as summarized in Eqs. (9)‒(11).
$$ \ln q_{\boldsymbol{h}}(\boldsymbol{h}) \propto \int_{\boldsymbol{\alpha}^{-1}} \int_{\sigma^{-2}} \ln \left(p\left(\boldsymbol{y} \mid \boldsymbol{h}, \sigma^2\right) p(\boldsymbol{h} \mid \boldsymbol{\alpha})\right) \mathrm{d} \boldsymbol{\alpha}^{-1} \mathrm{~d} \sigma^{-2} $$ (9) $$ \ln q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1}\right) \propto \int_{\boldsymbol{h}} \int_{\sigma^{-2}} \ln \left(p(\boldsymbol{h} \mid \boldsymbol{\alpha}) p\left(\boldsymbol{\alpha}^{-1}\right)\right) \mathrm{d} \boldsymbol{h} \mathrm{d} \sigma^{-2} $$ (10) $$ \ln q_{\sigma^{-2}}\left(\sigma^{-2}\right) \propto \int_{\boldsymbol{h}} \int_{\boldsymbol{\alpha}^{-1}} \ln \left(p\left(\boldsymbol{y} \mid \boldsymbol{h}, \sigma^2\right) p\left(\sigma^{-2}\right)\right) \mathrm{d} \boldsymbol{h} \mathrm{d} \boldsymbol{\alpha}^{-1} $$ (11) Bringing Eqs. (2)‒(6) into Eqs. (9)‒(11), it is obtained that qh (h) follows the complex Gaussian distribution, as well as qα−1 (α−1) and qσ−2 (σ−2) obey the Gamma distribution,
$$ q_{\boldsymbol{h}}(\boldsymbol{h})=C \mathcal{N}\left(\boldsymbol{h} \mid \boldsymbol{\mu}_{\boldsymbol{h}}, \boldsymbol{\varSigma}_{\boldsymbol{h}}\right) $$ (12) $$ q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1}\right)=\prod\limits_{l=1}^L \mathcal{G}\left(\alpha_l^{-1} \left\lvert\, a+\frac{1}{2}\right., b+\frac{1}{2}\left(\Sigma_{\boldsymbol{h}, i}+\mu_{\boldsymbol{h}, i}^2\right)\right) $$ (13) $$ q_{\sigma^{-2}}\left(\sigma^{-2}\right)=\mathcal{G}\left(\sigma^{-2} \left\lvert\, c+\frac{M}{2}\right., d+\frac{1}{2}\left(\|\boldsymbol{y}-\boldsymbol{\varPhi} \boldsymbol{h}\|_2^2+\operatorname{tr}\left(\boldsymbol{\varPhi} \boldsymbol{\varSigma}_{\boldsymbol{h}} \boldsymbol{\varPhi}^{\mathrm{H}}\right)\right)\right) $$ (14) where (•)H stands for the conjugate transpose and tr (•) represents the trace of a matrix. The μh, i and Σh, i is the ith element of μh and the ith diagonal element of Σh respectively.
$$ \boldsymbol{\mu}_{\boldsymbol{h}}=\mu_{\sigma^{-2}} \boldsymbol{\varSigma}_{\boldsymbol{h}} \boldsymbol{\varPhi}^{\mathrm{H}} \boldsymbol{y} $$ (15) $$ \boldsymbol{\varSigma}_{\boldsymbol{h}}=\left(\mu_{\sigma^{-2}} \boldsymbol{\varPhi}^{\mathrm{H}} \boldsymbol{\varPhi}+\boldsymbol{A}\right)^{-1} $$ (16) Here μσ−2 is the mean of distribution qσ−2 (σ−2) and A is a diagonal array consisting of the mean μαl−1 of distribution qα−1 (α−1),
$$ \mu_{\sigma^{-2}}=\frac{c+\frac{M}{2}}{d+\frac{1}{2}\left(\|\boldsymbol{y}-\boldsymbol{\varPhi} \boldsymbol{h}\|_2^2+\operatorname{tr}\left(\boldsymbol{\varPhi} \boldsymbol{\varSigma}_{\boldsymbol{h}} \boldsymbol{\varPhi}^{\mathrm{H}}\right)\right)} $$ (17) $$ \mu_{\alpha_l^{-1}}=\frac{a+\frac{1}{2}}{b+\frac{1}{2}\left(\Sigma_{\boldsymbol{h}, i}+\mu_{\boldsymbol{h}, i}^2\right)} $$ (18) $$ \boldsymbol{A}=\left[\begin{array}{cccc} \mu_{\alpha_1^{-1}} & & & \\ & \mu_{\alpha_2^{-1}} & & \\ & & \ddots & \\ & & & \mu_{\alpha_L^{-1}} \end{array}\right] $$ (19) Eqs. (12)‒(19) exhibit the results of approximating the SBL with the variational distribution. Depending on Gibbs sampling (Casella and George, 1992), when starting from an initial sample Ω0 ={h(0), α−1, (0), σ−2, (0)} of the target distribution p (Ω | y), and sequentially sampling the full conditional probability distributions p (h | y, α−1, (i−1), σ−2, (i−1)), p (α−1| y, h(i), σ−2, (i−1)), and p (σ−2| y, h(i), α−1, (i)) with respect to variables h, α−1, σ−2, we construct a randomly wandering Markov chain with its smooth distribution corresponding to p (Ω | y). The Ωi ={h(i), α−1, (i), σ−2, (i)} denotes the ith finished sample of hidden variables, and x(i) indicates the ith sample value of x.
As Ⅵ minimizes the $\mathcal{K L}$ divergence between qΩ (Ω) and p (Ω | y), accordingly, we can sample from qΩ (Ω) instead of p (Ω | y). Thus, the full conditional probability distributions of h, α−1, σ−2 are now expressed as
$$ \left.\frac{q_{\Omega}(\Omega)}{q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1)}\right) q_{\sigma^{-2}}\left(\sigma^{-2}\right)}\right|_{\boldsymbol{a}^{-1, (i-1)}, \sigma^{-2, (i-1)}} \propto q_{\boldsymbol{h}}\left(\boldsymbol{h} \mid \boldsymbol{\alpha}^{-1, (i-1)}, \sigma^{-2, (i-1)}\right) $$ (20) $$ \left.\frac{q_{\Omega}(\Omega)}{q_{\boldsymbol{h}}(\boldsymbol{h}) q_{\sigma^{-2}}\left(\sigma^{-2}\right)}\right|_{\boldsymbol{h}^{(i)}, \sigma^{-2, (i-1)}} \propto q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1} \mid \boldsymbol{h}^{(i)}, \sigma^{-2, (i-1)}\right) $$ (21) $$ \left.\frac{q_{\Omega}(\Omega)}{q_{\boldsymbol{h}}(\boldsymbol{h}) q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1}\right)}\right|_{\boldsymbol{h}^{(i)}, \boldsymbol{\alpha}^{-1, (i)}} \propto q_{\sigma^{-2}}\left(\sigma^{-2} \mid \boldsymbol{h}^{(i)}, \boldsymbol{\alpha}^{-1, (i)}\right) $$ (22) In Eqs. (20) ‒ (21) and (22), we begin by dividing the joint variational distribution qΩ (Ω) by the prior variational distributions of the irrelevant variables, yielding the conditional distributions of the target variable. Next, we determine the full conditional probability distribution of by incorporating the current values of the remaining variables.
For instance, in the ith iteration, we first compute the full conditional probability distribution of the channel. Since $q_{\Omega}(\Omega)=q_{\boldsymbol{h}}(\boldsymbol{h}) q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1}\right) q_{\sigma^{-2}}\left(\sigma^{-2}\right)$ and the current values of hyperparameters and noise variance are from the (i − 1) iteration, the result on the first side of Eq. (20) is equal to $q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1} \mid \boldsymbol{h}^{(i)}, \sigma^{-2, (i-1)}\right) $. Then simply sample from qh(h|α−1, (i−1), σ−2, (i − 1)), $q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1} \mid \boldsymbol{h}^{(i)}, \sigma^{-2, (i-1)}\right)$ and $q_{\sigma^{-2}}\left(\sigma^{-2} \mid \boldsymbol{h}^{(i)}, \boldsymbol{\alpha}^{-1, (i)}\right)$ in turn, satisfying
$$ q_{\boldsymbol{h}}\left(\boldsymbol{h} \mid \boldsymbol{\alpha}^{-1, (i-1)}, \sigma^{-2, (i-1)}\right)=\mathcal{C N}\left(\boldsymbol{h} \mid \boldsymbol{\mu}_{\boldsymbol{h}}^{(i)}, \boldsymbol{\varSigma}_{\boldsymbol{h}}^{(i)}\right) $$ (23) where
$$ \boldsymbol{\mu}_{\boldsymbol{h}}^{(i)}=\sigma^{-2, (i-1)} \boldsymbol{\varSigma}_{\boldsymbol{h}} \boldsymbol{\varPhi}^{\mathrm{H}} \boldsymbol{y} $$ (24) $$ \boldsymbol{\varSigma}_{\boldsymbol{h}}^{(i)}=\left(\sigma^{-2, (i-1)} \boldsymbol{\varPhi}^{\mathrm{H}} \boldsymbol{\varPhi}+\boldsymbol{A}^{(i-1)}\right)^{-1} $$ (25) The A(i−1) is composed of the sampled values of the hyperparameters at this point,
$$ \boldsymbol{A}^{(i-1)}=\left[\begin{array}{llll} \alpha_1^{-1, (i-1)} & & & \\ & \alpha_2^{-1, (i-1)} & & \\ & & \ddots & \\ & & & \alpha_L^{-1, (i-1)} \end{array}\right] $$ (26) Besides, $q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1} \mid \boldsymbol{h}^{(i)}, \sigma^{-2, (i-1)}\right)$ and $q_{\sigma^{-2}}\left(\sigma^{-2} \mid \boldsymbol{h}^{(i)}, \boldsymbol{\alpha}^{-1, (i)}\right)$ satisfy
$$ \begin{aligned} & q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1} \mid \boldsymbol{h}^{(i)}, \sigma^{-2, (i-1)}\right) \\ & \quad=\prod\limits_{l=1}^L \mathcal{G}\left(\alpha_l^{-1} \left\lvert\, a+\frac{1}{2}\right., b+\frac{1}{2}\left(\Sigma_{\boldsymbol{h}, i}^{(i)}+\mu_{\boldsymbol{h}, i}^{2, (i)}\right)\right) \end{aligned} $$ (27) $$ \begin{aligned} & q_{\sigma^{-2}}\left(\sigma^{-2} \mid \boldsymbol{h}^{(i)}, \boldsymbol{\alpha}^{-1, (i)}\right) \\ & \quad=\mathcal{G}\left(\sigma^{-2} \left\lvert\, c+\frac{M}{2}\right., d+\frac{1}{2}\left(\left\|\boldsymbol{y}-\boldsymbol{\varPhi} \boldsymbol{h}^{(i)}\right\|_2^2+\operatorname{tr}\left(\boldsymbol{\varPhi} \boldsymbol{\varSigma}_{\boldsymbol{h}}^{(i)} \boldsymbol{\varPhi}^{\mathrm{H}}\right)\right)\right) \end{aligned} $$ (28) Assume that the total iterations of the method are I and the times consumed before the Markov chain reaches smooth distribution are P. The final estimated value of UWA channel is
$$ \hat{\boldsymbol{h}}=\sum\limits_{i=P+1}^I \frac{1}{I-P} \boldsymbol{h}^{(i)} $$ (29) Define x(i) ~p (x) to be sampling from the distribution p (x) in the ith iteration. The procedure of the Gibbs sampling-based channel estimation method is summarized in Algorithm 1:
Input: y, Φ, I, P. Initialize: a, b, c, d, $\Omega_0=\left\{\boldsymbol{h}^{(0)}, \boldsymbol{\alpha}^{-1, (0)}, \sigma^{-2, (0)}\right\}$. While i ≤ I, execute (a) Update $q_{\boldsymbol{h}}\left(\boldsymbol{h} \mid \boldsymbol{\alpha}^{-1, (i-1)}, \sigma^{-2, (i-1)}\right)$ with Eqs. (24)‒(26) and $\boldsymbol{h}^{(i)} \sim q_{\boldsymbol{h}}\left(\boldsymbol{h} \mid \boldsymbol{\alpha}^{-1, (i-1)}, \sigma^{-2, (i-1)}\right)$ (b) Update $q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1} \mid \boldsymbol{h}^{(i)}, \sigma^{-2, (i-1)}\right)$ with Eq. (27) and $\boldsymbol{\alpha}^{-1, (i)} \sim q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1} \mid \boldsymbol{h}^{(i)}, \sigma^{-2, (i-1)}\right)$ (c) Update $q_{\sigma^{-2}}\left(\sigma^{-2} \mid \boldsymbol{h}^{(i)}, \boldsymbol{\alpha}^{-1, (i)}\right)$ with Eq.(28) and $\sigma^{-2, (i)} \sim q_{\sigma^{-2}}\left(\sigma^{-2} \mid \boldsymbol{h}^{(i)}, \boldsymbol{\alpha}^{-1, (i)}\right)$ (d) i = i + 1. Endwhile (e) Calculate the expectation of the channel with Eq. (29). Output: $\hat{\boldsymbol{h}}$. 4 Simulation results
In this section, we evaluated the performance using the SC-FDE system. The simulation was conducted in baseband, employing a block length of 512 symbols (N = 512). The simulated channel, illustrated in Figure 1, consisted of L = 48 taps. In the subsequent analysis, the parameters c and d were set to 0, while a was 1 and b was 0.000 1 to ensure a relatively large variance for the channel. We set the number of iterations to 500 for both the SBL and our proposed method. Additionally, we adopted the Gibbs sampling method with P = 200, which utilized the last 300 samples to estimate the expectation of the channel.
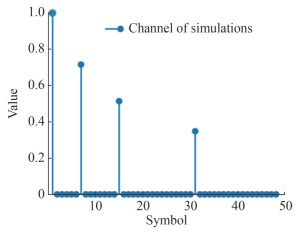 Figure 1 UWA channel of simulations
Figure 1 UWA channel of simulationsFigures 2‒4 displayed the comparison between the SBL and the proposed channel estimation method in terms of mean square error (MSE) and bit error rate (BER) with varying observed length M. For the BER simulation, we uniformly used the MMSE equalizer. The dashed line in the figure indicated the simulation results obtained with an ideal channel. As shown in Figures 2(a), 3(a), and 4(a), the Gibbs sampling-based approach outperformed SBL at various signal-to-noise ratios (SNRs), especially at lower M. According to Figures 2(b), 3(b) and 4(b), it also better reduced the BERs of the system. When M was 276 and the SNR was 8 dB, the gap with the system using ideal channel was less than 0.2 dB, which proved the effectiveness of the method.
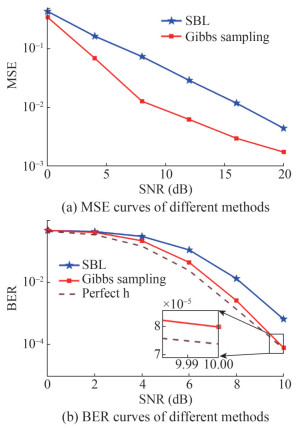 Figure 2 Simulation performance with M = 76
Figure 2 Simulation performance with M = 76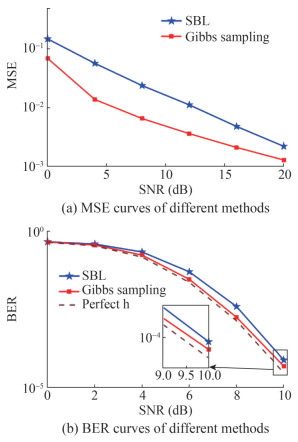 Figure 3 Simulation performance with M = 176
Figure 3 Simulation performance with M = 176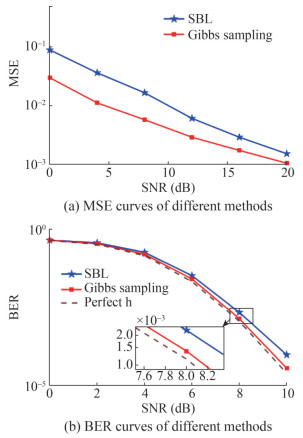 Figure 4 Simulation performance with M = 276
Figure 4 Simulation performance with M = 276To analyze the convergence of Markov chains during Gibbs sampling, we took the MSE of channel expectation in neighboring iterations as a measure, defined as Q, satisfying
$$ Q=\left\|\boldsymbol{\mu}_{\boldsymbol{h}}^{(i)}-\boldsymbol{\mu}_{\boldsymbol{h}}^{(i-1)}\right\|_2^2 $$ (30) Figure 5 exampled the convergence for varying M and SNRs. When the value of Q stabilized near zero, it indicated that the Markov chain had achieved a steady distribution. Then, sampling could be performed on the posterior distribution of the channel to compute the expectation.
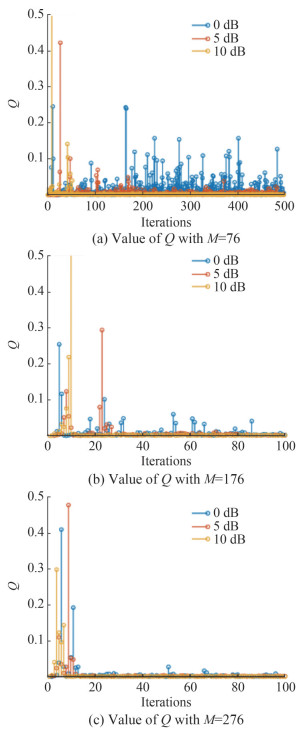 Figure 5 Comparison of convergence with Gibbs sampling under different M and SNR
Figure 5 Comparison of convergence with Gibbs sampling under different M and SNRThe results revealed that the Markov chain converged more rapidly as the observed length M increased at the same SNR. For instance, at 0 dB, convergence was not achieved within 500 iterations for M = 76, while it typically converged within 100 iterations for M = 276. Similarly, for the same observed length, faster convergence was observed at higher SNRs. When the SNR was 10 dB and M = 76, our method converged within 100 iterations, and for M = 176 or 276, convergence was achieved within 20 iterations.
As depicted in Figure 6, the Gibbs sampling method is capable of converging within 50 iterations at an observed length of 76. As the observed length increases, the convergence is further accelerated, and the amplitude of fluctuations decreases. Although it may have a relatively slower convergence rate compared to SBL, it is still considered acceptable.
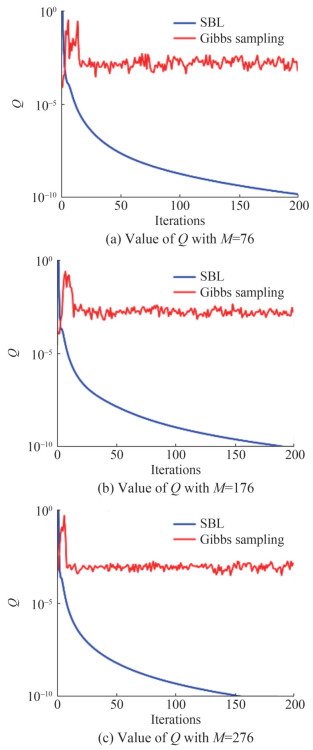 Figure 6 Comparison of convergence with two methods under different M
Figure 6 Comparison of convergence with two methods under different MIt is important to highlight that our main focus should be on the convergence speed of the two methods rather than the specific Q values they ultimately converge to. The convergence values primarily serve as an indicator of the convergence speed and not the estimated performance, which should be evaluated based on the results of MSE presented in Figures 2‒4. When the Gibbs sampling approach is employed, the channel undergoes updates along with samples of hyperparameters and noise variance during the iterative process by Equations (24) and (25). Therefore, the mean of the channel will also experience fluctuations around the real value. Once the magnitude of these fluctuations stabilizes, we can consider the Markov chain to have reached a stabilized state, and then use the smoothed samples to estimate the channel. In contrast, there is no random sampling process in the SBL method, which directly employs the EM algorithm to update the channel, ensuring that each iteration tends to converge with a diminishing Q value.
5 Experimental results
The algorithms were evaluated using data collected from an offshore UWA experiment carried out in the Yellow Sea in April 2022. The average water depth during the experiment was approximately 20 m. In this experiment, four hydrophones were deployed at fixed positions underwater, ranging from 3 to 7.5 meters deep at the receiver location. The transmitter ship was positioned at various distances to transmit signals using a SC-FDE system. The specific parameters used in the experiment are presented in Table 1.
Table 1 Setting of the experimental parametersParameter Value Observed length, M 216 Number of symbols in one block, N 512 Bandwidth, B (kHz) 4 Carrier frequency, fc (kHz) 12 Sampling rate, fs (kHz) 96 Modulation mode, β QPSK Figures 7 and 8 illustrated the time-frequency and channel characteristics of a received frame at distances of 800 m and 3 km, respectively. In Figures 7(a) and 8(a), each frame consisted of 5 data blocks and two linear frequency modulated (LFM) signals with a duration of 500 ms, which were utilized for Doppler compensation. Analysis of Figures 7(b) and 8(b) revealed that the Gibbs sampling-based method closely approximates the SBL for the main channel taps, while exhibiting greater suppression for taps with smaller amplitudes. Consequently, as the channel sparsity increases, the method’s advantages are expected to become more pronounced.
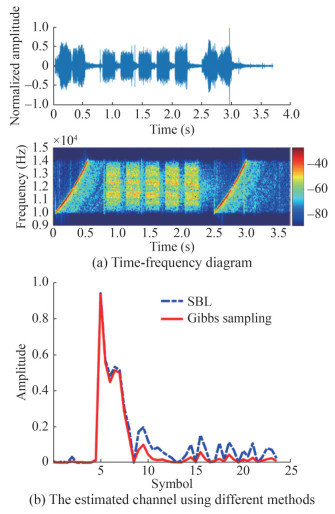 Figure 7 The received waveform and UWA channel at 800 m
Figure 7 The received waveform and UWA channel at 800 m Figure 8 The received waveform and UWA channel at 3 km
Figure 8 The received waveform and UWA channel at 3 kmFor the experiment, we transmitted 15 frames of signals at distances of 800 m and 3 km, respectively. In total, 30 frames, equivalent to 150 data blocks, were collected. The comparison of BER using SBL and Gibbs sampling was presented in Figure 9, with the adoption of the MMSE equalizer. At a distance of 800 m, the BER obtained with SBL was 7.83×10−3, while the Gibbs sampling-based method achieved a lower BER of 5.56×10−3. Similarly, at 3 km, the BER values were 6.19×10−3 for SBL and 5.46×10−3 for the Gibbs sampling-based method. These results confirm that the Gibbs sampling-based approach is capable of more efficient reconstruction of sparse channels, leading to improved BER performance.
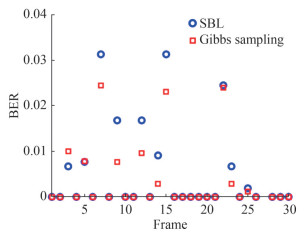 Figure 9 The BER comparison using SBL and Gibbs sampling
Figure 9 The BER comparison using SBL and Gibbs sampling6 Conclusion
In conclusion, we presented a Gibbs sampling-based method for sparse UWA channel estimation. Our method utilized variational distributions to approximate the real posterior distribution of the channel and performed random sampling. It demonstrated superior performance compared to the classical SBL approach. Through extensive simulations, our method achieved lower MSE and BER across different observed lengths. Specifically, at an observed length of 276 and an SNR of 8 dB, the performance gap with the ideal channel was less than 0.2 dB, highlighting its effectiveness. Moreover, our method exhibited faster convergence within 20 iterations for observed lengths greater than 176 and an SNR of 10 dB. Experimental results from the Yellow Sea further supported the superiority of our method, showing lower BER at distances of 800 m and 3 km compared to SBL.
Competing interest The authors have no competing interests to declare that are relevant to the content of this article. -
Figure 1 UWA channel of simulations
Figure 2 Simulation performance with M = 76
Figure 3 Simulation performance with M = 176
Figure 4 Simulation performance with M = 276
Figure 5 Comparison of convergence with Gibbs sampling under different M and SNR
Figure 6 Comparison of convergence with two methods under different M
Figure 7 The received waveform and UWA channel at 800 m
Figure 8 The received waveform and UWA channel at 3 km
Figure 9 The BER comparison using SBL and Gibbs sampling
Input: y, Φ, I, P. Initialize: a, b, c, d, $\Omega_0=\left\{\boldsymbol{h}^{(0)}, \boldsymbol{\alpha}^{-1, (0)}, \sigma^{-2, (0)}\right\}$. While i ≤ I, execute (a) Update $q_{\boldsymbol{h}}\left(\boldsymbol{h} \mid \boldsymbol{\alpha}^{-1, (i-1)}, \sigma^{-2, (i-1)}\right)$ with Eqs. (24)‒(26) and $\boldsymbol{h}^{(i)} \sim q_{\boldsymbol{h}}\left(\boldsymbol{h} \mid \boldsymbol{\alpha}^{-1, (i-1)}, \sigma^{-2, (i-1)}\right)$ (b) Update $q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1} \mid \boldsymbol{h}^{(i)}, \sigma^{-2, (i-1)}\right)$ with Eq. (27) and $\boldsymbol{\alpha}^{-1, (i)} \sim q_{\boldsymbol{\alpha}^{-1}}\left(\boldsymbol{\alpha}^{-1} \mid \boldsymbol{h}^{(i)}, \sigma^{-2, (i-1)}\right)$ (c) Update $q_{\sigma^{-2}}\left(\sigma^{-2} \mid \boldsymbol{h}^{(i)}, \boldsymbol{\alpha}^{-1, (i)}\right)$ with Eq.(28) and $\sigma^{-2, (i)} \sim q_{\sigma^{-2}}\left(\sigma^{-2} \mid \boldsymbol{h}^{(i)}, \boldsymbol{\alpha}^{-1, (i)}\right)$ (d) i = i + 1. Endwhile (e) Calculate the expectation of the channel with Eq. (29). Output: $\hat{\boldsymbol{h}}$. Table 1 Setting of the experimental parameters
Parameter Value Observed length, M 216 Number of symbols in one block, N 512 Bandwidth, B (kHz) 4 Carrier frequency, fc (kHz) 12 Sampling rate, fs (kHz) 96 Modulation mode, β QPSK -
Casella G, George E I (1992) Explaining the Gibbs sampler. The American Statistician 46(3): 167-174. https://doi.org/10.1080/00031305.1992.10475878 Cho YH (2022) Fast Sparse Bayesian learning-based channel estimation for underwater acoustic OFDM systems. Applied Sciences 12(19): 10175. https://doi.org/10.3390/app121910175 Coleri S, Ergen M, Puri A, Bahai, A (2002) Channel estimation techniques based on pilot arrangement in OFDM systems. IEEE Transactions on broadcasting 48(3): 223-229. https://doi.org/10.1109/tbc.2002.804034 Feng X, Wang J, Sun H, Qi J, Qasem Z A, Cui Y (2023) Channel estimation for underwater acoustic OFDM communications via temporal sparse Bayesian learning. Signal Processing 207: 108951. https://doi.org/10.1016/j.sigpro.2023.108951 Gelfand AE, Lee TM (1993) Discussion on the meeting on the Gibbs sampler and other Markov Chain Monte Carlo methods. Journal of the Royal Statistical Society. Series B 55(1): 72-73. https://doi.org/10.1111/j.2517-6161.1993.tb01469.x Goudie RJB, Mukherjee S (2016) A Gibbs sampler for learning DAGs. Journal of Machine Learning Research 17(2): 1-39 Jia S, Zou S, Zhang X, Tian D, Da L (2022) Multi-block Sparse Bayesian learning channel estimation for OFDM underwater acoustic communication based on fractional Fourier transform. Applied Acoustics 192: 108721. https://doi.org/10.1016/j.apacoust.2022.108721 Kang SG, Ha YM, Joo EK (2003) A comparative investigation on channel estimation algorithms for OFDM in mobile communications. IEEE Transactions on Broadcasting 49(2): 142-149. https://doi.org/10.1109/tbc.2003.810263 Li Y, Wang Y, Jiang T (2016) Norm-adaption penalized least mean square/fourth algorithm for sparse channel estimation. Signal processing 128: 243-251. https://doi.org/10.1016/j.sigpro.2016.04.003 Martino L, Elvira V, Camps-Valls G (2018) The recycling Gibbs sampler for efficient learning. Digital Signal Processing 74: 1-13. https://doi.org/10.1016/j.dsp.2017.11.012 Panayirci E, Altabbaa MT, Uysal M, Poor H V (2019) Sparse channel estimation for OFDM-based underwater acoustic systems in Rician fading with a new OMP-MAP algorithm. IEEE Transactions on Signal Processing 67(6): 1550-1565. https://doi.org/10.1109/tsp.2019.2893841 Prasad R, Murthy CR, Rao BD (2014) Joint approximately sparse channel estimation and data detection in OFDM systems using sparse Bayesian learning. IEEE Transactions on Signal Processing 62(14): 3591-3603. https://doi.org/10.1109/tsp.2014.2329272 Tipping, Michael E (2001) Sparse Bayesian learning and the relevance vector machine. Journal of machine learning research 1 (Jun): 211-244 Tsai Y, Zheng L, Wang X (2018) Millimeter-wave beamformed full-dimensional MIMO channel estimation based on atomic norm minimization. IEEE Transactions on Communications 66(12): 6150-6163. https://doi.org/10.1109/tcomm.2018.2864737 Wang Y, Dong X (2006) Frequency-domain channel estimation for SC-FDE in UWB communications. IEEE transactions on communications, 54(12): 2155-2163. https://doi.org/10.1109/glocom.2005.1578453 Wang Z, Li Y, Wang C, Ouyang D, Huang Y (2021) A-OMP: An adaptive OMP algorithm for underwater acoustic OFDM channel estimation. IEEE Wireless Communications Letters 10(8): 1761-1765. https://doi.org/10.1109/lwc.2021.3079225 Wu FY, Zhou YH, Tong F, Kastner R (2013) Simplified p-norm-like constraint LMS algorithm for efficient estimation of underwater acoustic channels. Journal of marine science and application 12(2): 228-234. https://doi.org/10.1007/s11804-013-1189-7 Zhang C, Bütepage J, Kjellström H, Mandt S (2018) Advances in variational inference. IEEE transactions on pattern analysis and machine intelligence 41(8): 2008-2026. https://doi.org/10.1017/9781009218245.011 Zhang Z, Rao BD (2011) Sparse signal recovery with temporally correlated source vectors using sparse Bayesian learning. IEEE Journal of Selected Topics in Signal Processing 5(5): 912-926. https://doi.org/10.1109/jstsp.2011.2159773 Zheng YR, Xiao C, Yang TC, Yang WB (2010) Frequency-domain channel estimation and equalization for shallow-water acoustic communications. Physical Communication 3(1): 48-63. https://doi.org/10.1016/j.phycom.2009.08.010
