 2022, Vol. 44
2022, Vol. 44

2. 中国人民解放军32258部队,湖南 衡阳 421000
2. No.32258 Unit of PLA, Henyang 421000, China
在海上无人化场景中,无人水面艇、无人水下艇和无人机作为一种新型的海上智能体,可以用来执行侦察、反潜、巡逻、打击,以及搜救、导航、勘察等任务。无人装备视觉系统的作用是代替人眼,对海上目标以及障碍物进行检测、跟踪和测量,并进行场景和行为的解读。基于视觉的海上船艇目标检测是海上无人装备视觉系统最主要的任务之一,是实现无人装备对海上目标进行识别和跟踪的基础,通过提高无人装备视觉侦察系统的海上舰船目标分割能力,可以极大地提升海上国防能力,因此研究海上舰船目标的智能感知方法,对海上无人装备的发展具有重要意义。
在舰船目标检测中,关键是准确识别和精准定位。与常规舰船目标检测识别相比,对舰船目标图像进行像素级分割可以获得更加精确的舰船目标位置状态、形状以及类别,不仅帮助提高舰船目标定位和识别性能,还有助于对舰船目标进行后续的跟踪处理。当前图像分割方法主要可以分为传统方法和深度学习的方法,传统的图像分割算法,如阈值法、边缘检测法和区域法等仅适用于分割简单的图像。近年来,深度学习在各个领域得到了迅速发展,深度卷积神经网络(DCNN)已经成为自然图像处理中的主流算法,深度学习技术的完善使得基于深度学习的图像分割方法在速度与精度上都领先于传统的分割方法,经历了Alex Net,VGG和 Res Net等特征提取网络的发展,真正意义上的基于深度学习的首个图像分割算法为全卷积神经网络(FCN)。后续出现了DeepLab系列算法和 PSPNet等。医学图像分割模型有 U-net等。实例分割算法有 Bharath Hariharan 等提出的 SDS 算法和 Kaiming He 等提出的Mask R-CNN实例分割算法。海面监控和海面国防场景的海上目标图像具有天气复杂、干扰大、速度要求高、数据量大的特点,传统的分割算法无法满足海面监控、海面国防场景的需求,且通用的自然图像分割方法也难以直接适用于海上舰船目标分割处理。
面向上述问题,提出适用于海上无人装备的舰船目标智能感知算法,针对通用的图像分割方法中存在的高层语义特征丰富、空间分辨率降低,导致尺度差异大舰船目标(特别是小目标)的不精确分割问题,提出了基于膨胀卷积(dilated convolution)的多尺度特征融合模块,该模型在提高网络深度获得更加丰富的语义信息的同时可以获得多尺度的图像特征图,有利于提高多尺度目标的分割精度;针对不同目标像素身份判别和单个目标不同部位包含不同特征导致的多类混淆预测问题,设计了一个身份识别辅助网络分支,通过该辅助网络可以预先获取更多的全局上下文信息,引导编码器对不同身份目标的特征进行关注,预先对同一场景内可能存在的目标类别进行判断,提高身份识别的准确率。
1 主要方法 1.1 方法框架基于编码器-解码器结构海上舰船目标图像智能分割算法的整体框架图如图1所示。整体分为编码器提取高层特征、解码器还原像素结构两大部分。其中,多尺度特征融合模块通过对不同区域感受野的特征提取,解决特征分辨率降低、多尺度目标分割不准确的问题,身份识别辅助网络针对编码器提取的高层语义信息进行类别监督训练,赋予高层语义信息中更多身份类别信息,提高目标实例分割的准确率。

|
图 1 方法框架图 Fig. 1 The overall frame diagram of the proposed method |
编码器模块的网络结构以深度卷积神经网络为主干网络进行特征提取,以常用的ResNet50为主干网络,随着网络深度的增加,感受野的大小不断增加、特征层的大小逐渐减小、特征层的深度不断增加,以此提取到高层语义特征。但随着特征高层语义信息的丰富,空间分辨率不断降低,丢失的空间位置信息越来越多,对此,在ResNet50的第3网络模块输出的特征图(大小为14×14×1024)为基础特征层,构建多尺度特征融合模块。
根据不同感受野关注不同尺度目标的基本原理,在基础特征层的基础上,以不同方式构建不同大小感受野的卷积块。如图1所示,多尺度特征融合模块共包括5部分:1×1卷积、3×3膨胀卷积(膨胀率r=1)、3×3膨胀卷积(膨胀率r=2)、3×3膨胀卷积(膨胀率r=4)和全局平均池化;其中1×1卷积和全局平均池化分别从最小和全局2个感受野进行特征提取,中间3部分虽然都采用的3×3卷积,但通过不同的膨胀率在不改变运算量的情况下,改变感受野的大小,如图2所示。

|
图 2 膨胀卷积示意图 Fig. 2 Schematic diagram of dilated convolution |
5个不同感受野的特征提取模块分别专注于不同尺度的目标和上下文信息,分别经对应的卷积操作后,各连接1个BN层(BatchNormalization)和Relu激活后,将5个特征层直接叠加相连,并连接1×1卷积层改变通道数,得到融合的包含高层语义的多尺度特征层。
1.3 身份识别辅助网络与常规的语义分割相比,针对海上舰船目标的实例分割除了要分割出目标与海天背景,还需要对各目标身份进行进一步判别,而现有的分割方法都只是注重于像素级的监督训练确保像素分割的准确性,对分割实例的身份信息没有注重,这就导致了现有方法难以理解没有全局上下文信息的特征,出现同一目标分割成不同身份和不同身份目标分割成同一目标的问题。针对此问题,设计一个身份识别辅助网络,帮助网络获得更多的上下文信息和场景类别先验信息,具体见图1。在编码器模块所提取的高层语义特征基础上,通过全连接层以交叉熵损失函数进行多类别分类的监督训练,如下式:
| $ {L_{}} = - \sum\limits_{i = 1}^n {q(\theta )\log p_\theta ^{}}。$ | (1) |
高层语义特征的提取,一方面在编码-解码的像素分类结构下进行监督训练,以像素分割的准确度为训练目标,另一方面在多分类交叉熵损失函数的监督下训练,以准确识别图中拥有舰船目标的类别为训练目的。两者之间看似不相关联,但准确分类识别的训练目的是引导高层特征层关注图中几个不同身份类别的特征,关注图中拥有该部分特征的区域,为像素级分割提供辅助性作用,有利于像素级分割和实例分割的进行。
1.4 解码器网络结构由图1可知,解码器网络的输入一部分来自编码器中包含多尺度特征信息的高层语义特征,另一部分来自深度卷积网络中的包含更丰富空间和细节信息的低层特征,兼顾了像素级分割对特征分辨率和空间分辨率的双重需求。将两部分特征分别通过上采样和1×1卷积统一各自的特征大小和通道数,并通过叠加相连的方式将两部分特征融合,再经过4倍的上采样得到和原输入图像大小一致的输出,通过交叉熵损失函数进行监督训练。
2 实验结果与分析利用构建的海上舰船目标分割数据集进行实验验证,并与其他主流分割方法进行性能对比,验证所提方法的有效性。本实验在Ubantu16.04系统RTX2080Ti显卡下,利用Pytorch训练平台进行训练调试。
2.1 评价指标在分割任务中,所有像素点都会生成一个预测类别,通常使用交并比和准确率2个指标对方法进行评价。
交并比(IoU)的计算为2个集合交集比并集的结果,即真实值与预测值集合的交并集。在交并比的基础上,计算均交并比(mIOU),分割图像一般都有好几个类别把每个分类得出的IOU分数进行平均就可以得到均交并比,也就是mIoU。
准确率(Acc)在混淆矩阵的基础上计算,Acc = (TP+TN)/(TP+TN+FP+FN)。其中,TP为混淆矩阵中的真阳性,TN为真阴性,FP为假阳性,FN为假阴性。
2.2 实验结果与分析本文通过仿真手段构建一个多类别的海上舰船目标分割数据集,利用Labelme的数据标注软件制作数据标签,整个数据集共包含6类舰船目标加上背景,共7类。总的数据量为300张,按照90%,10%随机划分为训练集和测试集,通过数据增强对训练集的图像进行旋转、翻转、裁剪、随机噪声进行数据扩充。
本文以主流的分割算法Deeplabv3,fcn_unet和pspnet_unet为对比方法进行实验验证,实验定量和可视化结果如表1~表3所示。
|
|
表 1 各方法的IOU结果对比表 Tab.1 Comparison of IOU results of methods |
|
|
表 2 各方法的Acc结果对比表 Tab.2 Comparison of Acc results of methods |
|
|
表 3 各方法分割结果可视化对比 Tab.3 Visual comparison of segmentation results of each method |












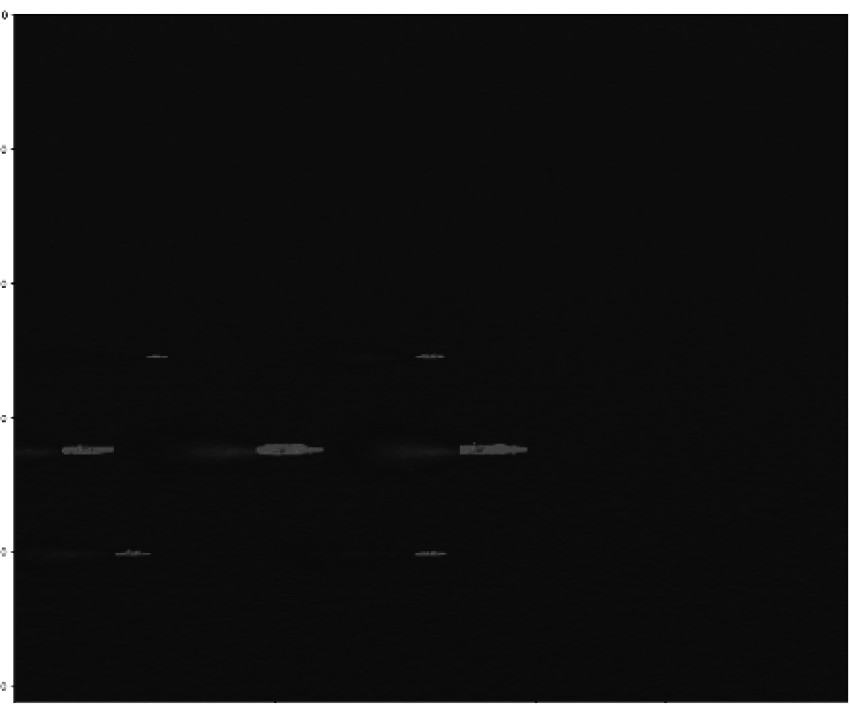


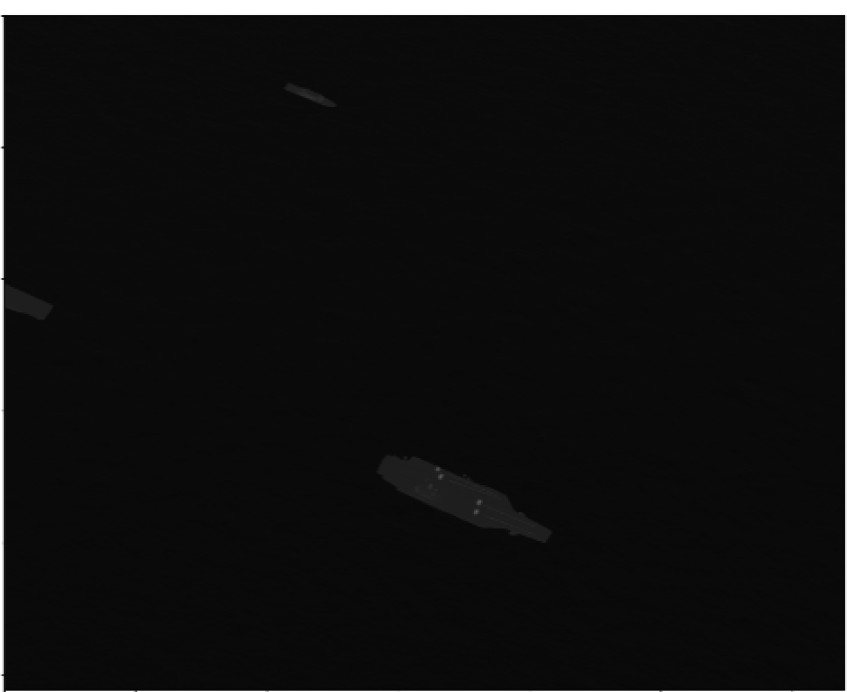








通过以上实验对比可以看出,本文方法在海上目标分割的准确度和身份识别的准确度上较对比方法均有较明显的性能优势。通过多尺度特征融合模块,在对比方法中出现的小目标漏检问题,在本文方法中并没有出现,对尺度差异较大的目标具有较好分割表现。通过身份识别辅助网络的增加,在对比方法中出现的同一目标分割成多个目标类别和不同类别判断成同一身份目标的问题,在本文方法中得到明显解决,对像素级分割后的实例身份判断具有较好的识别表现。
3 结 语以深度卷积神经网络的特征提取能力为基础,针对海上舰船目标分割存在的实际问题,分别设计了多尺度特征融合模块和身份识别辅助网络,重点解决分割中存在的目标尺度不一和身份判别的困难,通过自构建的海上舰船目标分割数据集进行验证。实验结果表明,与主流的图像分割算法相比,本文方法能较好实现舰船目标的分割和身份判断。但限于数据集的限制,下一步会积累无人艇视角下的舰船目标图像,构建无人艇专用的分割数据集,进一步验证所提方法的有效性。
| [1] |
KRIZHEVSKY A, SUTSKEVER I, HINTON G. ImageNet classification with deep onvolutional neural networks[J]. Advances in Neural Information Processing Systems, 2012, 25(2).
|
| [2] |
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. Computer Science, 2014.
|
| [3] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016.
|
| [4] |
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 39(4): 640-651. |
| [5] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[J]. Computer Science, 2014(4): 357-361. |
| [6] |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[J]. 2017.
|
| [7] |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[J]. European Conference on Computer Vision, 2018, 801-818. |
| [8] |
KAIMING H, GEORGIA G, PIOTR D, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 1-1. |
| [9] |
HAMAGUCHI R, FUJITA A, NEMOTO K, et al. Effective use of dilated convolutions for segmenting small object instances in remote sensing imagery[C]// 2018 IEEE Winter Conference on Appliation on Compoter Vision, 2018.
|
| [10] |
RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]// International Conference on Medical Image Computing & Computer-assisted Intervention. 2015.
|
| [11] |
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 6230–6239.
|
| [12] |
REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks.[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149. |
| [13] |
BADR INARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481–2495.
|
| [14] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous-convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 40(4): 834-848. |
| [15] |
XIONG W, LV Y, CUI Y, et al. A discriminative feature learning approach for remote sensing image retrieval[J]. Remote Sensing, 2019, 11(3): 281.
|