 2019, Vol. 40
2019, Vol. 40



2. 哈尔滨工业大学(深圳)计算机科学与技术学院, 深圳 518055;
3. 海军军医大学(第二军医大学)长征医院风湿免疫科, 上海 200433;
4. 南通大学信息科学技术学院通讯工程教研室, 南通 226001
2. College of Computer Science and Technology, Harbin Institute of Technology, Shenzhen, Shenzhen 518055, Guangdong, China;
3. Department of Rheumatology and Immunology, Changzheng Hospital, Naval Medical University(Second Military Medical University), Shanghai 200433, China;
4. Department of Communication Engineering, School of Information Science and Technology, Nantong University, Nantong 226001, Jiangsu, China
电子病历(electronic medical record,EMR)记录了患者的整个医疗过程,它包含有患者大量的诊疗信息[1],是生物医学临床研究的重要数据来源。EMR命名实体识别(named entity recognition,NER)作为生物医学文本挖掘的第一步,对医学知识库的构建、药物安全性检测和临床决策支持系统等的研究有着重要意义。挖掘出的临床数据不仅可以用于临床科研,还有助于为患者制定个性化的精准医疗服务[2]。
通常,NER的方法学研究主要分为3大类:(1)基于词典和规则的方法。这种方法在数据量少时效果较好且识别速度快,但是该方法对词典规模及词典覆盖率的依赖性较大且编写规则需要耗费大量的人力和物力。现在大多情况下将规则和机器学习方法结合使用。(2)传统机器学习的方法,其主流方法有条件随机场(conditional random field,CRF)、支持向量机(support vector machine,SVM)等。程健一等[3]基于2014 i2b2/UTHealth中的任务,提出基于SVM和CRF的双层分类模型对EMR去隐私化。(3)深度学习方法。深度神经网络是一种挖掘潜在有用特征的多层神经网络,每一层输出都是该语句的一种抽象表示,语言本身就是一种抽象的表达,因此,在大量训练数据的基础上生成基于向量的特征表示,利用神经网络进行NER是目前学者正在探索的一种方法[4]。由于中英文语言特征的差异,中文实体识别首先要对文本进行分词,分词错误则会导致在NER上的错误累加。因此,已有研究证明基于字符的方法在中文NER上优于基于词的模型[5]。不会导致分词错误累加是字符级模型的优点,但从另一方面来说也是这种方法的缺点,因为有些单词信息蕴含的语义信息可以使字符级模型在识别实体时产生歧义,如将“上腹部疼痛”识别成“上”和“腹部疼痛”。因此我们使用一种基于字和词混合网格的Lattice-长短记忆神经网络(long short-term memory neural network,LSTM)结构[6],这种结构能够实现对句中专有名词的识别,并将潜在的单词信息整合到基于字符的LSTM-CRF模型中。为了完成2018年全国知识图谱与语义计算大会(China Conference on Knowledge Graph and Semantic Computing,CCKS)[7]的测评任务,我们提出使用基于Re-entity的CRF、双向长短记忆神经网络(bi-directional long short-term memory neural network,BiLSTM)-CRF和Lattice-LSTM 3种方法,针对EMR中的解剖部位(body)、独立症状(osign)、症状表现(signs)、药物(drug)和手术治疗(treatment)5类实体进行NER。实验结果证明与词序列信息的混合模型Lattice-LSTM相比,字符粒度CRF使用更少的特征工程,并与基于字符的BiLSTM-CRF模型相比能更好地利用上下文中单词的潜在语义信息。
1 资料和方法 1.1 实验语料本研究使用CCKS2018任务一“电子病历命名实体识别”发布的中文EMR语料,共600篇已标注的训练数据(train)和400篇未标注的测试数据。表 1描述了CCKS2018测评任务发布的中文EMR数据规模,在600篇训练数据中共有9 472个身体解剖部位标注实体。
|
|
表 1 CCKS2018数据规模 Tab 1 Data scale of CCKS2018 |
1.2 CRF模型
CRF被广泛用于生物医学实体识别任务,它是一种判别式无向图模型,根据提供的特征对数据的标注进行学习,通过复杂的函数映射或决策叠加等机制,最后画出一个比较明显的边界区分实体和非实体。通俗来讲就是直接对P(Y|X)建模,根据观测序列X(x1, x2, …, xn)对标记序列Y(y1, y2, …, yn)进行建模训练[8]。
广义的CRF是指满足P(Yv|X, Yw, w≠v) =P(Yv|X, Yw, w~v)的马尔科夫随机场。条件概率P(Y|X)的定义为
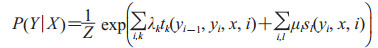
|
其中,
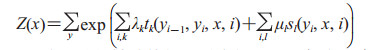
|
tk为i处的转移特征,对应权重λk,每个yi都有k个特征,转移特征针对的是前后标签之间的限定。sl为i处的状态特征,对应权重μl,每个yi都有l个特征,Z(x)是规范化因子。
为准确提取EMR中实体,不仅需要根据语料选择适合的学习方法,还要给出特征集,丰富的特征工程可以有效提高模型的学习能力和识别准确率。本研究基于对中文EMR文本的分析选取以下特征集:
(1)字符特征。中文字符本身可以作为一种基本特征,反映中文字符的基本信息[9]。为避免分词错误导致错误累加,我们使用字符级的分字结果作为语言符号特征引入。
(2)词性特征。通过分析EMR自由文本可以发现很多实体由多个名词嵌套组成,例如“剑突下压痛”由解剖位置“剑突下”和症状表现“压痛”组成。疾病名、症状等名词可能出现在动词等词性后面,因此将词性标注作为一类特征。
(3)词典特征。因为EMR的专业性比较强,为减少实体的错切分率,引入专业词典具有重要意义。在英文NER领域,MeSH、UMLS、SNOMED-CT、RxNORM等通用词典发挥了重要作用。由于中文领域缺乏公开且完整的医学词典,因此,我们从网络和书本中整理并构建了EMR基本元素(item)、解剖位置(body)、症状(symptom)、中文临床药物标准知识库(normalized Chinese clinical drug,NCCD)[10] 4个词典。词典规模如表 2所示。例如NCCD包括CONCEPT-NAME、CONCEPT-ID、CONCEPT-CLASS-ID等属性,本研究整理了CONCEPT-NAME药名属性共28 008个作为词典特征加入。
|
|
表 2 词典规模 Tab 2 Dictionary scale |
(4)三元特征。在CRF++工具的特征模板中采用%x [row, col]的格式,row表示与当前位置相对应的行数,col表示当前位置相对应的列数[11]。本研究使用的特征模板见表 3。
|
|
表 3 特征模板 Tab 3 Feature template |
U00~U14为一元特征,本研究选择当前字符的前后2个字符作为上下文特征,窗口为5,U15~U18是将相邻的2个一元特征分别进行组合合并为二元特征,U20~U22为将当前字符的前后3个字符进行组合形成三元特征,当训练模型时会自动生成相邻特征的自由组合。
1.3 Re-entity方法由于现有分词方法比较适合通用数据,对EMR这种专业性强的文本的分词效果较差,因此为避免分词错误带来的错误累加提出了Re-entity方法。先训练出基于以上特征的CRF模型,然后将该模型用于CCKS2017的诊疗经过中共2 205条未标注的EMR文本,预测完成后抽取识别的实体,最后将这些实体与已标注数据集中的实体混合整理成词典,利用该词典对训练数据再进行分词,保证已知命名实体在文本分词时不被切割,提高分词准确率,然后基于以上结果重新训练模型。
1.4 BiLSTM-CRFHochreiter和Schmidhuber[12]于1997年提出的LSTM最初是为了解决循环神经网络(recurrent neural network,RNN)训练伴随的梯度缓慢和梯度爆炸,为保持信息完整引入了记忆细胞[13],记录历史上下文信息。近年LSTM方法被广泛应用于自然语言处理领域,目前NER的主流模型是BiLSTM-CRF,结构如图 1所示。BiLSTM是将每个序列呈现前向和后向2个单独的隐藏状态,分别捕获过去和未来的信息,然后连接2个隐藏状态合成最终输出。该模型在多项任务中取得了好成绩。Lample等[14]提出了2种神经网络方法,一种是基于BiLSTM和CRF,另一种是受移位归约解析器(shift-reduce parser)启发提出的基于转换(transition)的方法构建和标记分段。模型的2个词信息分别来源于从监督语料库中学习到的基于字符的词和从未标注数据中学习到的无监督词。该模型分别在4种语言下获得了目前NER的最好性能。我们使用BiLSTM模型自动从训练数据中学习特征,并在最后的输出层中使用CRF替换softmax函数进行分类决策,CRF中的转移特征会考虑输出标注之间的关联性和合理性。

|
图 1 BiLSTM-CRF结构图 Fig 1 BiLSTM-CRF structure BiLSTM: Bi-directional long short-term memory neural network; CRF: Conditional random field; O: Placeholder; B: Beginning of entity; l: Forward hidden layer; r: Backward hidden layer; c: Final out of hidden layer; 1, 2, 3, 4: Character sequence. The arrows indicate model running direction |
1.5 Lattice-LSTM
基于字符的模型可以避免词模型在分词阶段的错误累加,但有时也会导致信息丢失,因为有些上下文中的词序列蕴含的语义信息可辅助模型性能的提高。而Lattice结构可以利用字符和词序列信息、门控结构选择最相关的字符和单词以获得更好的NER结果。该模型整体思路是利用Lattice-LSTM表示输入句子中的词汇词(lexicon word),然后将潜在的词信息融合到基于字符粒度的LSTM-CRF模型中。
如图 2所示,通过输入句子与词典D进行匹配构造单词-字符的Lattice结构。词典D是由大规模经过分词后的中文文本Gigaword(https://catalog.ldc.upenn.edu/LDC2011T13)使用Word2vec训练后得到的。例如“疼痛”“腹部”“腹部疼痛”等存在于词典D中的单词可用于消除上下文中潜在的命名实体歧义。按照顺序一个一个字符组合还能组成“无腹部”一词,而该词不在Lattice词格中,因此在进行匹配时就可以避免这种歧义实体的发生。

|
图 2 单词-字符Lattice Fig 2 Word-character Lattice The arrows indicate character combination |
1.5.1 Lattice-LSTM整体结构
如图 3所示,使用基于字符的LSTM-CRF作为主干模型,模型中的“红色细胞(

|
图 3
Lattice-LSTM结构图
Fig 3
Lattice-LSTM structure
LSTM: Long short-term memory neural network; c: Character vector; h: Hidden layer vector; : Potential word information. The black arrows indicate model running direction, and the green arrows indicate dynamical route information from different paths to each character |
1.5.2 Lattice模型
使用英文领域效果最好的NER模型LSTM-CRF作为主模型[15],在此基础上集成了词序列信息和用于控制信息流的附加门。输入的句子S可以表示为S=c1, c2, c3, …, cm(cj表示句中第j个字符,共有m个字符),也可以表示为S=w1, w2, w3, …, wn(wi表示句中第i个单词结果,共有n个单词)。t(i, k)表示句中第i个单词的第k个字符的索引j。
模型的输入是字符序列及其与词典D中单词匹配的所有字符子序列。如图 4所示cjc的计算考虑到了词格中的单词序列wb, ed。
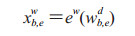
|

|
图 4 Lattice模型 Fig 4 Lattice model O: Placeholder; B: Beginning of entity.xjc: Character input vector; cjc: Character cell vector; hjc: Hidden vector; x2, 3w: Word embedding of abdominal pain; c2, 3w : Recurrent state of x2, 3w from the beginning of the sequence. The arrows indicate information sources |
其中ew是词向量查找表,cb, ew表示每一个xb, ew的递归状态,w表示词,下标b, e分别表示词w在序列中的开始和结束位置。
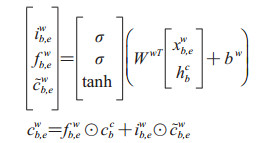
|
其中ib, ew和fb, ew是LSTM的输入和遗忘门集合。WwT和bw是模型参数,σ表示sigmoid函数,tanh是输出的激活函数。求出词序列的cb, ew之后,每个隐含层的cjc的计算即受到多路径信息流的影响,例如“痛”这个字符的c3c的计算即会受x3c和c2, 3w及上一个隐含层输出的影响,使用附加门控制cb, ew到cb, ec的信息流,即根据当前字符和词汇信息计算输入到字符的词汇信息的权重。
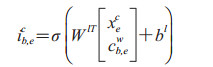
|
然后利用如下公式计算当前位置索引为j的字符向量融合了潜在单词后的更新状态。
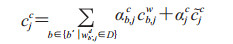
|
最后在模型最上层加一层CRF保证最终标注的合理性。
1.6 评估标准评估方法使用精确率、召回率及F1-measure作为评测指标,并根据系统预测结果与人工标注的金标准结果的比较分为严格指标和松弛指标,本研究仅讨论严格指标。参赛系统的预测标注集合记为S={s1, s2, …, sm},其中m是预测序列集S的字符(s)数,人工标注的金标准结果集合记为G={g1, g2, …, gn},n表示金标准集合G的字符(g)数。集合元素为一个个实体,表示为四元组〈d, posb, pose, c〉,其中d表示文档,posb和pose分别对应实体提及在文档d中的起止下标,c表示实体提及所属预定义类别。
严格指标:我们定义si∈S与gj∈G严格等价,当且仅当
(1)si.d=gj.d
(2)si.posb=gj.posb
(3)si.pose=gj.pose
(4)si.c=gj.c
基于以上等价关系,我们定义集合S与G的严格交集为∩s。由此得到严格指标
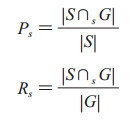
|
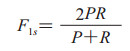
|
CRF模型实验首先以模型①(CRF-onlychar)作为baseline,baseline模型只使用了原始文本做字符特征在CRF++ 0.58工具中进行NER。模型②(CRF-POS-Dic)在baseline模型的基础上加入词性标注(part-of-speech,POS)和词典Item、Body、Symptom作为特征扩展。模型③(CRF-POS-Dic-NCCD)则在模型②的基础上加入词性标注和3个词典的基础上引入NCCD。模型④(CRF-POS-Dic-NCCD-Re-entity)是在模型③的基础上加入Re-entity分词方法降低分词错误率。以上4个特征扩展模型的实验结果如图 5所示。

|
图 5 CRF特征扩展实验结果 Fig 5 Experimental results of CRF feature extension CRF: Conditional random field; POS: Part-of-speech; Dic: Item +body+symptom (dictionary); NCCD: Normalized Chinese clinical drug |
模型①中仅使用字符特征进行CRF模型训练,得到76.96%的F1-measure。模型②中添加词性标注和词典特征之后,F1-measure提高到85.80%。模型③在模型②的基础上引入NCCD提高临床药物药品名的识别率,F1-measure提升到86.13%。最后在模型④中加入了可改善词性标注分词错误的Re-entity方法,在CRF模型中获得了最高的F1-measure(86.51%)。训练集和测试集中有很多词典中没有的实体,因此单纯使用词典匹配的方法会过度依赖词典规模和词典覆盖率,CRF模型作为机器学习模型能够学习识别出词典中没有的实体,同时也能根据实体上下文环境对实体作出比较准确的分类。因此以CRF模型为基础融合词典、词性标注等特征和Re-entity方法可以弥补各单独NER模型的不足。
但CRF这种传统机器学习方法也有明显的缺点,即过度依赖训练集的规模和质量及有效特征的选择。因此本研究进行了后续神经网络模型的训练。
2.2 BiLSTM-CRF模型加入预训练向量的实验结果本研究使用向量训练工具Word2vec基于大规模医学专业文本训练了2个字符向量集,准备了2个训练语料库,第1个是电子版的内科学、外科学、妇产科学和儿科学4本医学专业书(以下简称nwfe_emd),第2个语料是2017年CCKS竞赛发布的未标注EMR数据(以下简称unlabel_emd)。用Python进行数据清洗,去掉与专业内容无关的部分,然后进行字符粒度分割,分割后作为模型输入在Word2vec中进行预训练分别得到nwfe_emd和unlabel_emd 2个字符向量集。字符分割后训练的向量集规模如表 4所示。
|
|
表 4 语料库规模 Tab 4 Corpus size |
首先验证向量维度对模型效果的影响,本研究基于unlabel_emd语料库分别训练了维度为100、200、300和400的向量集。在BiLSTM-CRF模型中基于epoch在40、60和80的参数设置下分别进行不同维度向量的对比实验,结果如图 6所示。

|
图 6 不同向量维度下实验结果图 Fig 6 Experimental results at different embedding dimensions |
由图 6可知,随着向量维度的增加,3组epoch在不同维度的向量实验中表现出相同的趋势。在一定范围内,F1-measure随着向量维度的增加呈上升趋势,在维度为300时表现出最好的结果,然而在维度为400时F1-measure相比维度300下降,表明并不是向量维度越高模型效果越好,需要根据具体任务要求进行实验,依据具体性能和实验所需时间等方面的需求选择合适的向量维度,因此本实验选择维度300向量作为该模型的baseline参数进行后续实验。
Lattice-LSTM模型是在字符粒度神经网络模型LSTM模型的基础上结合了词的信息,并且没有经过分词,也避免了分词错误导致的错误累加。
2.3 Lattice-LSTM中引入预训练向量的实验结果Lattice-LSTM模型提供了预训练字符向量集和词向量集,字符向量gigaword_chn.all.a2b.uni.ite50.vec是基于大规模标准分词后的中文语料库Gigaword使用Word2vec工具训练的向量集合,向量集规模为704 400个字符和词,包括5 700个单字符向量、29 150个双字符向量和278 100个三字符向量。词向量ctb.50d.vec是基于CTB 6.0(Chinese Treebank 6.0)语料库训练得到的。该模型实验在保持词向量ctb.50d.vec不变的前提下分别使用gigaword_chn.all.a2b.uni.ite50.vec、nwfe_emd和unlabel_emd 3个字符向量集进行对比实验,实验结果如表 5所示。
|
|
表 5 Lattice-LSTM基于不同字符向量实验结果 Tab 5 Different character embeddings experiment results of Lattice-LSTM |
从表 5可知,基于大规模经过标准分词的中文语料库训练的向量集gigaword_chn.all.a2b.uni.ite50.vec在Lattice-LSTM模型的训练中获得最好效果,F1-measure为89.75%。本研究的字符向量是基于字符分割的语料库训练的,F1-measure稍低于使用gigaword_chn.all.a2b.uni.ite50.vec的模型。字符分割后的语料在训练空间向量时相比分词无法充分利用上下文的词信息,训练出的向量会丢失词与上下文之间的语义信息。因此选择使用gigaword_chn.all.a2b.uni.ite50.vec向量模型作为后续对比实验的baseline模型。
2.4 不同输入长度对比实验结果分别对CRF、BiLSTM-CRF和Lattice-LSTM 3种模型开展训练数据输入句子长度变化的实验,txt-level是以篇为单位,即1篇EMR作为1个输入;sent-level是以句号“。”为分隔符,即以句号“。”结尾的一个句子为模型的输出。结果如图 7所示。

|
图 7 句子级和篇级F1-measure比较 Fig 7 Comparison of F1-measure between sent-level and txt-level BiLSTM: Bi-directional long short-term memory neural network; CRF: Conditional random field; LSTM: Long short-term memory neural network; ④CRF: CRF-POS-Dic-NCCD-Re-entity; POS: Part-of-speech; Dic: Item+body+symptom (dictionary); NCCD: Normalized Chinese clinical drug; Sent-level: Sentence level; Txt-level: Text level |
由图 7可见,CRF对输入句子长度不敏感,句子级和篇级在该模型中的F1-measure分别为86.50%和86.51%。BiLSTM-CRF和Lattice-LSTM表现出相同的趋势,句子级的结果均较篇级好。在BiLSTM-CRF中句子级的F1-measure比篇级高2.51%,而在Lattice-LSTM中句子级比篇级高7.03%,也证明在基于字符的模型中加入潜在单词信息的有效性。在该模型中随着输入句子长度的增加,Lattice词格中的词组也在递增,Lattice的精度会下降[6],因此句子级的Lattice-LSTM NER模型在本实验中得到了89.75%的最高值。
2.5 模型实验结果对比表 6列出了CRF、BiLSTM和Lattice-LSTM 3个模型框架中的全部实验结果。前4个模型是CRF模型框架下的特征扩展实验结果,模型⑤和⑥是BiLSTM-CRF模型框架下的不同输入长度的实验结果,模型⑦和⑧是Lattice-LSTM模型中的不同输入长度对比实验结果。
|
|
表 6 不同模型的实验结果 Tab 6 Results of different models |
由表 6可知,当添加词性标注、词典等特征后,F1-measure比只用字符特征提高了8.84%,item、body、symptom等专业词典的加入可在数据预处理时提高分词准确性及模型的识别准确率。NCCD是Wang等[10]针对国内药物参考国际通用的Rxnorm模型建立的NCCD,本研究在模型②的基础上抽取出药名部分作为词典特征加入,可有效提高药物的F1-measure。在以上特征的基础上加入Re-entity方法,F1-measure从86.13%提高到86.51%。
在BiLSTM-CRF模型中,模型的复杂度会随着模型训练而增加,此时模型在训练集上的训练误差逐渐减小,但当模型复杂到一定程度且数据量不够大时,模型在训练集以外的数据集上的误差反而开始增大,发生过拟合现象[16]。本实验训练数据只有600篇,数据量较小,因此该模型在本次任务中只得到84.93%的F1-measure。本研究中,CRF模型和BiLSTM-CRF模型均是基于字符级别的,虽然改善了词级别模型的分词错误,但也漏掉了很多潜在有用的词序列语义信息。Lattice-LSTM则是在字符级模型的基础上融合了文本中潜在的单词信息,在本任务中获得89.75%的F1-measure,本研究的结果高于CCKS2018竞赛任务一“电子病历命名实体识别”所有参赛团队的最优值89.25%(https://biendata.com/competition/CCKS2018_1/leaderboard/)。
3 讨论本研究在总结英文领域NER的研究进展及详细了解中文EMR文本特点的基础上进行中文EMR NER研究,在对比现有实验方法后选择CRF、BiLSTM-CRF和Lattice-LSTM 3个模型框架。首先基于CRF进行对比实验:将EMR数据处理成CRF++ 0.58工具包所需数据格式之后进行模型训练,选择只使用字符特征的模型作为baseline模型;然后将自主整理构建的EMR基本元素(item)、解剖部位(body)、NCCD等医学专业词典,作为词典特征引入baseline模型进行特征扩展实验;最后在选择最佳特征工程的基础上加入Re-entity方法,改善词粒度模型在分词过程中因医学专业性导致的分词错误。其次是神经网络模型的实验研究,神经网络模型可缓解CRF模型过度依赖训练集规模和质量及有效特征工程的弊端。在神经网络模型中,本研究利用大规模未标注文本进行了无监督学习,基于不同语料获取了不同参数级别的向量。首先验证了字符向量维度对BiLSTM-CRF模型性能的影响,结果显示,该模型在向量维度为300时效果最好。在Lattice-LSTM模型的向量实验中,使用Gigaword语料库训练出的字符向量在NER模型中的效果优于基于字符分割语料库构建的向量,因为Gigaword语料库训练出的向量集充分利用了词序列的语义信息。
中文EMR NER研究仍处于发展阶段,未来仍有很多工作需要开展:(1)本研究实验数据仅有600篇已标注训练数据和400篇测试数据,数据量小且病种结构单一。在后续工作中我们将扩充数据量并参考英文医学标准库,构建更全面的中文专业词典以辅助系统性能的提高。(2)选择更高质量的语料库进行字符粒度和词粒度向量集的训练,引入CRF模型[17]和神经网络模型中进行模型优化,并在已完成NER模型的基础上进行EMR中药物到NCCD的映射工作。
综上所述,本研究在传统CRF模型的基础上,提出了一种基于Re-entity新分词方法的CRF模型,该方法可减少分词在医学专业文本上的错误,并融合一系列的字符、词性标注、自构建医学专业词典等特征,利用NCCD提高药物的识别率,从而整体提高CRF模型的中文EMR中命名实体的整体识别准确性。在BiLSTM-CRF模型中对比了不同维度向量对系统性能的影响,维度为300的向量获得最好表现。在Lattice-LSTM模型的不同字符向量集的对比实验中,经过金标准分词的大规模中文语料库——Gigaword语料库训练出的向量能更好地利用上下文中词序列蕴含的潜在语义信息,提高模型识别效果。在字符级神经网络模型的基础上融入单词序列信息构建Lattice词格结构并结合CRF,该模型在独立于分词的情况下能利用文本中潜在的单词信息,其识别准确率较单纯基于字符粒度或基于词粒度的模型均更具优越性。在以上模型对比实验的基础上,对比验证不同输入长度对模型效果的影响,结果表明CRF模型对输入句长不敏感,神经网络模型在较短句长下的效果优于较长的篇级输入模型,Lattice-LSTM在句子级的句子输入实验中获得最高的F1-measure。
| [1] |
杨锦锋, 于秋滨, 关毅, 蒋志鹏. 电子病历命名实体识别和实体关系抽取研究综述[J]. 自动化学报, 2014, 40: 1537-1562. |
| [2] |
叶枫, 陈莺莺, 周根贵, 李昊旻, 李莹. 电子病历中命名实体的智能识别[J]. 中国生物医学工程学报, 2011, 30: 256-262. DOI:10.3969/j.issn.0258-8021.2011.02.014 |
| [3] |
程健一, 关毅, 何彬. 基于SVM和CRF双层分类器的英文电子病历去隐私化[J]. 智能计算机与应用, 2016, 6: 17-19, 24. |
| [4] |
张海楠, 伍大勇, 刘悦, 程学旗. 基于深度神经网络的中文命名实体识别[J]. 中文信息学报, 2017, 31: 28-35. DOI:10.3969/j.issn.1003-0077.2017.04.005 |
| [5] |
LI H, HAGIWARA M, LI Q, JI H. Comparison of the impact of word segmentation on name tagging for Chinese and Japanese[C/OL]//Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC'14). Reykjavik: LREC, 2014: 2532-2536.[2019-01-28]. http://www.lrec-conf.org/proceedings/lrec2014/index.html.
|
| [6] |
ZHANG Y, YANG J. Chinese NER using Lattice LSTM[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers). Melbourne: ACL, 2018: 1554-1564.
|
| [7] |
中国中文信息学会语言与知识计算专业委员会.全国知识图谱与语义计算大会[C/OL].天津: CCKS, 2018.[2019-01-28]. http://www.ccks2018.cn/?page_id=16.%20doi:%20http://www.ccks2018.cn/?page_id=16.
|
| [8] |
PAN Y F, HOU X, LIU C L. Text localization in natural scene images based on conditional random field[C/OL]//10th International Conference on Document Analysis and Recognition. Catalonia: ICDR2009, 2009: 6-10. doi: 10.1109/ICDAR.2009.97.
|
| [9] |
张祥伟, 李智. 基于多特征融合的中文电子病历命名实体识别[J]. 软件导刊, 2017, 16: 128-131. |
| [10] |
WANG L, ZHANG Y, JIANG M, WANG J, DONG J, LIU Y, et al. Toward a normalized clinical drug knowledge base in China-applying the RxNorm model to Chinese clinical drugs[J]. J Am Med Inform Assoc, 2018, 25: 809-818. DOI:10.1093/jamia/ocy020 |
| [11] |
曾冠明.基于条件随机场的中文命名实体识别研究[D].北京: 北京邮电大学, 2009. http://www.cqvip.com/Main/Detail.aspx?id=29419200
|
| [12] |
HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Comput, 1997, 9: 1735-1780. DOI:10.1162/neco.1997.9.8.1735 |
| [13] |
李洋, 董红斌. 基于CNN和BiLSTM网络特征融合的文本情感分析[J]. 计算机应用研究, 2018, 38: 3075-3080. DOI:10.3969/j.issn.1001-3695.2018.10.045 |
| [14] |
LAMPLE G, BALLESTEROS M, SUBRAMANIAN S, KAWAKAMI K, DYER C. Neural architectures for named entity recognition[Z/OL]. arXiv: 1603.01360v3[cs.CL]. (2016-04-07)[2019-01-28]. https://arxiv.org/pdf/1603.01360.pdf.
|
| [15] |
MA X, HOVY E. End-to-end sequence labeling via bidirectional LSTM-CNNs-CRF[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: ACL, 2016: 1064-1074.
|
| [16] |
陶砾, 杨朔, 杨威. 深度学习的模型搭建及过拟合问题的研究[J]. 计算机时代, 2018(2): 14-17, 21. |
| [17] |
隋明爽, 崔雷. 结合多种特征的CRF模型用于化学物质-疾病命名实体识别[J]. 现代图书情报技术, 2016(10): 91-97. DOI:10.11925/infotech.1003-3513.2016.10.10 |