


提出一种改进的基于显著性检测图联合估计恰可失真(JND)阈值的视觉感知模型,将人眼注意力机制引入JND模型,通过感知特点建模得到更为精确的JND模型.首先通过改进的显著性检测算法得到相应的显著图,在计算JND阈值的过程中,使用显著图来分配不同的权重给JND模型,并针对色度和亮度的不同给予不同的权重.基于空域的JND模型主要用在计算图像中的平坦区域;而基于DCT域的JND模型更加适合计算纹理区域的阈值,新的模型还同时考虑加入对比敏感度函数和各种掩蔽效应因子.将改进的JND模型融合到新的视频编码软件HM 16.4中,实验结果表明,与HEVC标准的数据对比,视觉感知质量没有明显下降.
Based on existing saliency detection algorithm, a model of joint estimation just noticeable distortion(JND) was proposed. This model not only makes full use of the advantage of the JND model, based on pixel domain and transform domain, but also employs the character of human visual system. The saliency detection algorithm used for saliency map, is employed to assign different weights to JND model, based on different brightness and color. The JND model based on pixel domain is mainly used on plain area, and the JND model, with masking effect and contrast sensitivity function, based on transform domain is used on texture area. The proposed model is introduced into the HEVC sample platform HM16.4. Experiments show that the proposed JND model, compared to HEVC standard, have the similar subjective quality.
视频编码技术主要针对空间、时间和统计冗余进行压缩编码.近年来,研究人员针对人类视觉系统(HVS,human visual system)的一些特性,将感知编码技术引入传统的视频编码框架,以获得更高的编解码性能[1].所形成的感知视频编码(PVC, perceptual video coding)技术,着重于通过挖掘人眼对于图像的主观感知状态和人类天生的视觉选择性注意机制等来消除人类主观视觉冗余[2].其中,恰可失真(JND, just noticeable distortion)和SM都是当前的研究热点.目前常见的JND模型可以分为两类:基于空域的JND模型[3]和变换域的JND模型(如DCT域或小波域JND模型).
基于空域的JND模型直接给出具体每一像素的最小可察觉失真值.如文献[1]分别计算亮度自适应因子和纹理掩蔽效应因子,然后将2个因子的最大值作为JND阈值.在此基础,Yang等[2]提出了扩展的JND模型(非线性叠加掩蔽模型),将亮度掩蔽和纹理融合在一起用于运动估计等内容.
Ahumada等[4]在提出的DCT域的JND模型中融合了对比敏感函数, 其还包括亮度自适应因子和各种掩蔽效应因子. Watson等[5]提出了DCTune模型,通过融合了亮度和对比度掩蔽效应到基本阈值中. Ahumada等[6]提出了将时空域JND(ST-JND)的模型嵌入感知视频编解码器中,并使其兼容当前的H.264编解码框架. Naccari等[7]通过估计频域的扭曲模型调整频域变换参数,得到有效的DCT域JND模型.
显著性模型用于描述人眼视觉注意力区域. Itti等[8]在神经生理学和解剖的基础上结合Treisman的特征整合理论提出了自底向上建模的视觉注意模型.由于现实中大量的视频以压缩形式被获取,Goferman等[9]提出了面向压缩域的视频显著检测算法,利用一个移动窗口中的离散余弦变换(DCT)系数和运动信息修缮显著图模型,取得了较好的效果.
笔者提出改进的基于显著性引导的JND模型(SJ-JND模型):联合考虑空域的JND模型和DCT域的JND模型,并分别对视频图像纹理、边界和平坦区域分别估计出更为精确的显著性区域;在此基础,得到图像不同区域的重要程度,对于较为显著的区域给予更小的JND权重,并用于视频编码.
1 DCT域和空域的JND模型空域的JND模型主要由亮度自适应因子和对比度掩蔽效应组成.而现有的DCT域的JND模型通常是在DCT域下计算JND阈值,然后再反DCT变换到空域JND阈值. DCT域的JND模型可以由基本阈值和各种调节因子组成.亮度的空域JND阈值[3]为
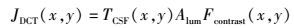
|
(1) |
其中(x, y)为对应的元素坐标. TCSF(x, y)对应于亮度和色度的基本阈值. Fcontrast为由空间域对比度敏感函数生成的对比度掩蔽因子. Alum为亮度自适应效应,CSF反映了对比度敏感与空间频率之间的关系.
2 SJ-JND模型框架在文献[10]基础上,提出的SJ-JND模型主要由2个影响因子组成:联合估计JND模型和显著性检测阈值.有

|
(2) |
图 1所示为SJ-JND模型生成流程的3个部分.第1部分是图像颜色空间转换.第2部分是图像的显著性检测.第3部分是图像进行DCT变换,在DCT域下生成JND模型,然后把JND阈值反变换回空域.最后.利用式(2) 计算得到SJ-JND阈值.

|
图 1 SJ-JND基础架构 |
SJ-JND模型中式(3) 为亮度的空域JND阈值,式(4) 为色度的空域JND阈值:

|
(3) |
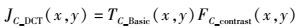
|
(4) |
变换块的第(x, y)坐标处对应的空间频率λx, y计算如下:

|
(5) |

|
(6) |
参数δi和δi分别表示为像素的水平和垂直视角.变换系数块的维数是N.等式(6) 中的K表示观看距离与图像高度的比值,H表示图像高度.
经过实验,得到色度分量的CSF函数曲线的色度基本阈值公式为

|
(7) |
根据实验,其中参数α为1/256,当色度分量为α*时,β=280,b*=-31.979 5和c=2.06.对于色度分量为b*时,β=320,b=-22.441 3和c=1.74.
2.2 改进的对比度掩蔽效应模型2.2.1 改进的亮度对比度掩蔽因子得到的亮度对比度掩蔽效应因子计算如式下.

|
(8) |
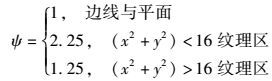
|
(9) |
其中,式(8) 中参数CL(x, y, p)代表亮度变换块的系数.而式(9) 说明了亮度对比度掩蔽效应在不同类型块所得到的掩蔽因子不同.
2.2.2 改进的色度对比度掩蔽因子在这里,每个变换块的第(x, y)坐标的对比掩蔽因子计算公式如下:
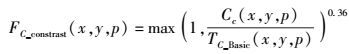
|
(10) |
其中:Cc(x, y, p)表示第P帧的(x, y)位置变换块的系数,TC_Basic(x, y, p)表示为第P帧的(x, y)位置色度分量的基本阈值.
3 改进的显著性探测算法3.1 改进的局部和全局相结合的显著性探测根据Goferman等[9]提出的基于上下文感知的显著性算法, 当图像中的一个像素值所在的小块区域(图像块)与其周围的小块区域的特征存在较大差异的时候,当前的小区域块可以被认为是显著性区域.因此,位置欧氏距离可以用来检测两块的远近程度,如果当前显著的图像块pi与图像块pj距离较远,则认为p不是显著块.块之间的相异度计算公式如下:

|
(11) |
这里的c为3.块之间的dP_ED(pi, p′j)越大和cdP_ED(pi, p′j)越小,则当前块越显著.在单一的t尺度下,像素值的显著性计算公式为
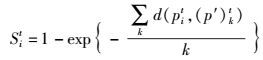
|
(12) |
在选择图像块时,要把尺度因素考虑进来.则式(19) 可以改写为

|
(13) |
在不同尺度下,像素i的平均显著性值为
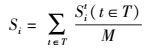
|
(14) |
参数Sit定义在(14).实验中,首先把输入的图像进行调整到同一个尺度,然后计算其显著性值.图像块的划分是以7×7为单位的,块之间存在重叠. M设置为49.
3.3 改进的显著性上下文信息常见的混合视频编码系统并未考虑人类视觉特性中注意力对于压缩的影响.根据上述特性,在SJ-JND中,对于注意力焦点远点应该尽量压缩,对于注意力焦点周围应该减少压缩权重.利用这一原理,像素i的显著性重新定义为
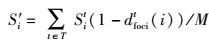
|
(15) |
其中dfocit(i)表示在尺度为t时,像素i与最近的显著性像素的位置欧氏距离.
4 实验结果和讨论为了验证模型的效果,实际测试中使用测试序列分别为:BasketballDrive、BQTerrace、Cactus、ParkScene、PeopleOnStreet.序列PeopleOnStreet分辨率为2 560×1 600,其他都为1 920×1 080.采用main profile,采用全I帧编码方式.为了表明提出模型的有效性,跟标准HM16.4模型和Wang[10]的模型做比较.
4.1 主观评估方案为了确保主观测试的可靠性, 采用ITU-R BT. 500标准[11]中定义的测试方法DSQS(double stimulus quality scale)主观视觉评测方案.
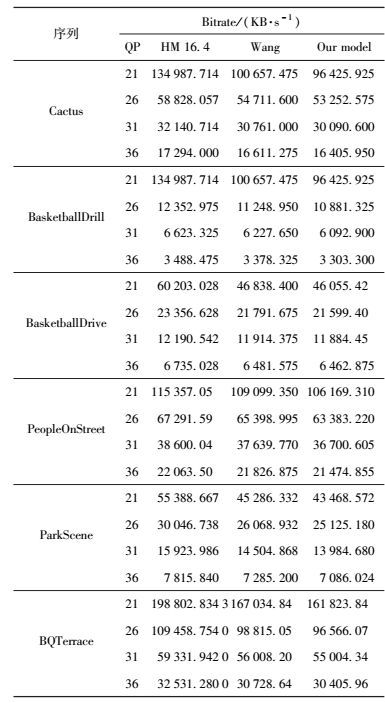
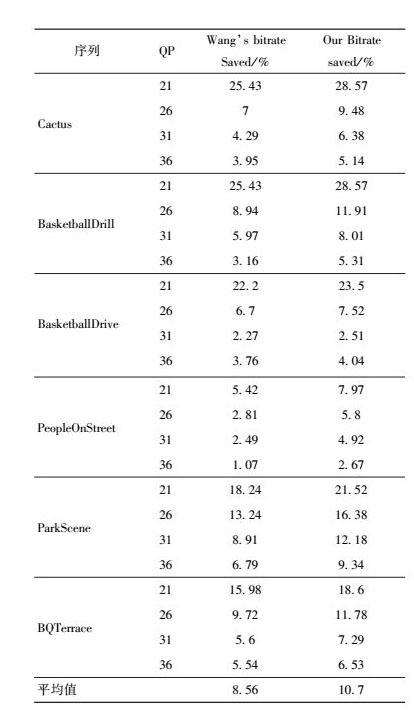
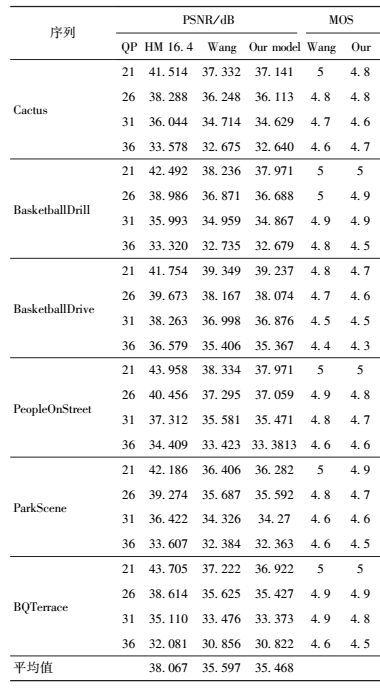
4.2 基于SJ-JND模型的测试结果表 1和表 2显示了提出的SJ-JND模型用于视频压缩时比参考模型和标准有更多的比特率下降,其中比特率降低了2.51% ~ 28.57%, 对比标准软件的比特平均节省10.7%,Wang等提出模型的比特率平均节省8.56%,SJ-JND模型的比特率平均节省了2.14%左右.从表 3可以看出,SJ-JND与Wang等提出的模型PSNR平均下降了0.129 dB.从实验结果可以看出,在主观视觉质量没有降低的前提下,使用SJ-JND模型可使图像压缩率得到极大提高.
|
|
表 1 各个模型的码率大小 |
|
|
表 2 模型的码率节省 |
|
|
表 3 PSNR大小和MOS评分 |
提出基于显著性图引导联合估计JND阈值的模型,对不同区域得到不同的JND阈值,并且除了由亮度自适应因子和对比度掩蔽因子组成外,还加入CSF函数.将图像分解为结构和纹理分量,动态给予不同权重.最后对不同区域进行JND阈值估计,还考虑了图像中感兴趣区域的分布.实验结果表明,改进的JND模型与HEVC标准的数据对比,视觉感知质量没有明显的下降.提出的模型与现有的模型对比存在更好的压缩性能,能够容忍更多的视频数据失真.提出的模型在DCT域建模JND还存在分块不合理等问题,在未来的工作中,可以进一步改善.
| [1] | Chou C H, Li Y C. A perceptually tuned subband image coder basedon the measure of just-noticeable-distortion profile[J].IEEE Transaction on Circuits and Systems for Video Technology, 1995, 5(6): 467–476. doi: 10.1109/76.475889 |
| [2] | Yang X K, Lin W S, Lu Z, et al. Just-noticeable distortion profile with nonlinear additivity model for perceptual masking in color images[C]//IEEE International Conference on Acoustics, Speech, and Signal Processing. Hongkong:[s.n.], 2003:609-612. |
| [3] | Xu Shengyang, Yu Mei, et al. Just noticeable coding distortion model for HEVC video coding[J].Journal of Optoelectronics and Laser, 2015, 26(12): 2381–2392. |
| [4] | Ahumada A J, Peterson H A. Luminance-mode based DCT quantization for color image compression[J].Human Vision, Visual Processing, and Digital Display Ⅲ, 1992(1666): 365–374. |
| [5] | Watson A B, Yang G Y, Solomon J A, et al. Visibility of wavelet quantization noise[J].IEEE Transaction on Image Processing, 1997, 6(8): 1164–1175. doi: 10.1109/83.605413 |
| [6] | Ahumada A J, Peterson H A. Luminance-mode based DCT quantization for color image compression[J].Human Vision, Visual Processing, and Digital Display Ⅲ, 1992: 365–374. |
| [7] | Naccari M, Pereira F. Advanced H. 264/AVC-based perceptual video coding:architecture, tools, and assessment[J].Circuits and Systems for Video Technology, IEEE Transactions on, 2011, 21(6): 766–782. doi: 10.1109/TCSVT.2011.2130430 |
| [8] | Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis[J].IEEE Transaction on Pattern Analysis and Machine Intelligence, 1998, 20(11): 1254–1259. doi: 10.1109/34.730558 |
| [9] | Goferman S, Zelnik-Manor L, Tal A. Context-aware saliency detection[J].Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2012, 34(10): 1915–1926. doi: 10.1109/TPAMI.2011.272 |
| [10] | Wang Huiqi, Wang Lin, Hu Xuelin, et al. Perceptual video coding based on saliency and just noticeable distortion for H.265/HEVC[C]//Wireless Personal Multimedia Communications (WPMC), International Symposium on. Sydney:[s.n.], 2014:106-111. |
| [11] | Recommendation I. 500-11-2002, Methodology for the subjective assessment of the quality of television pictures[S]. Geneva, Switzerland:International Telecommunication Union, 2002:1-47. |